概述
在RagflowPlus v0.3.0 版本推出之后,反馈比较多的问题是:检索时,召回块显著变少了。
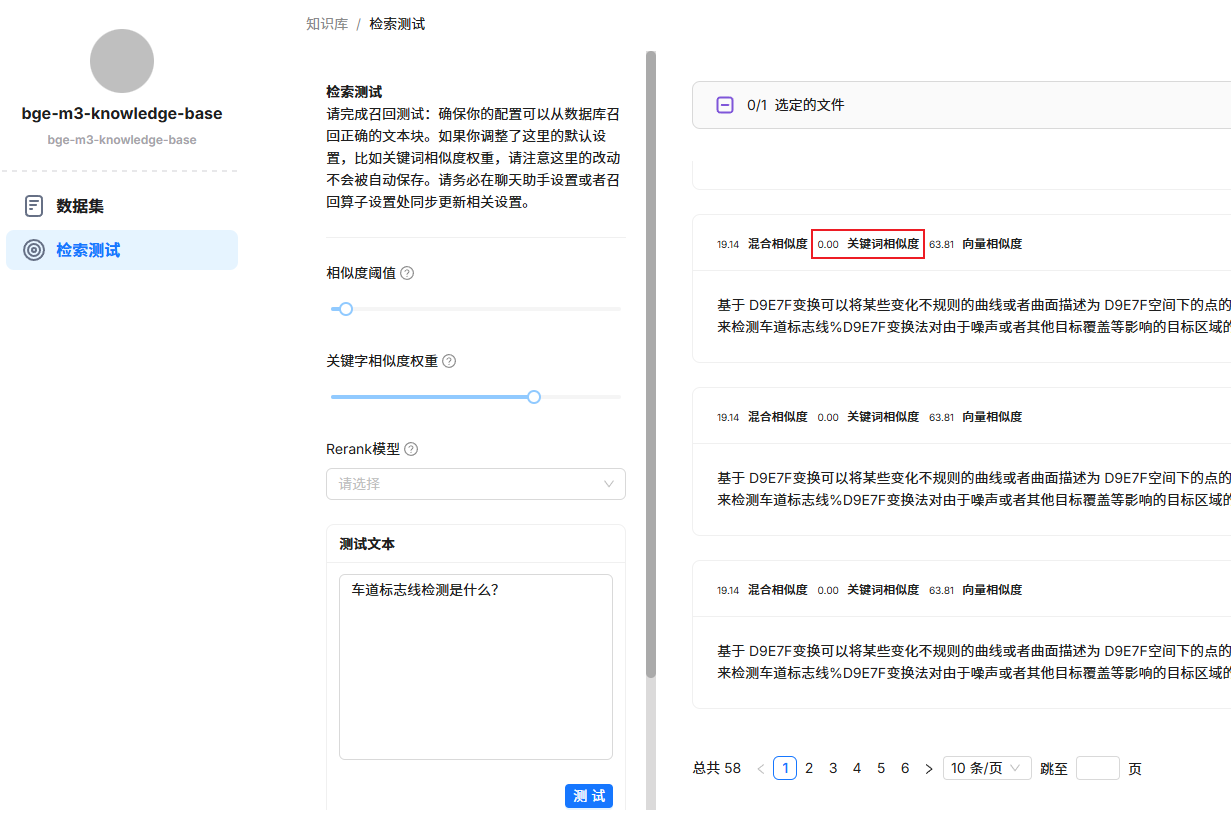
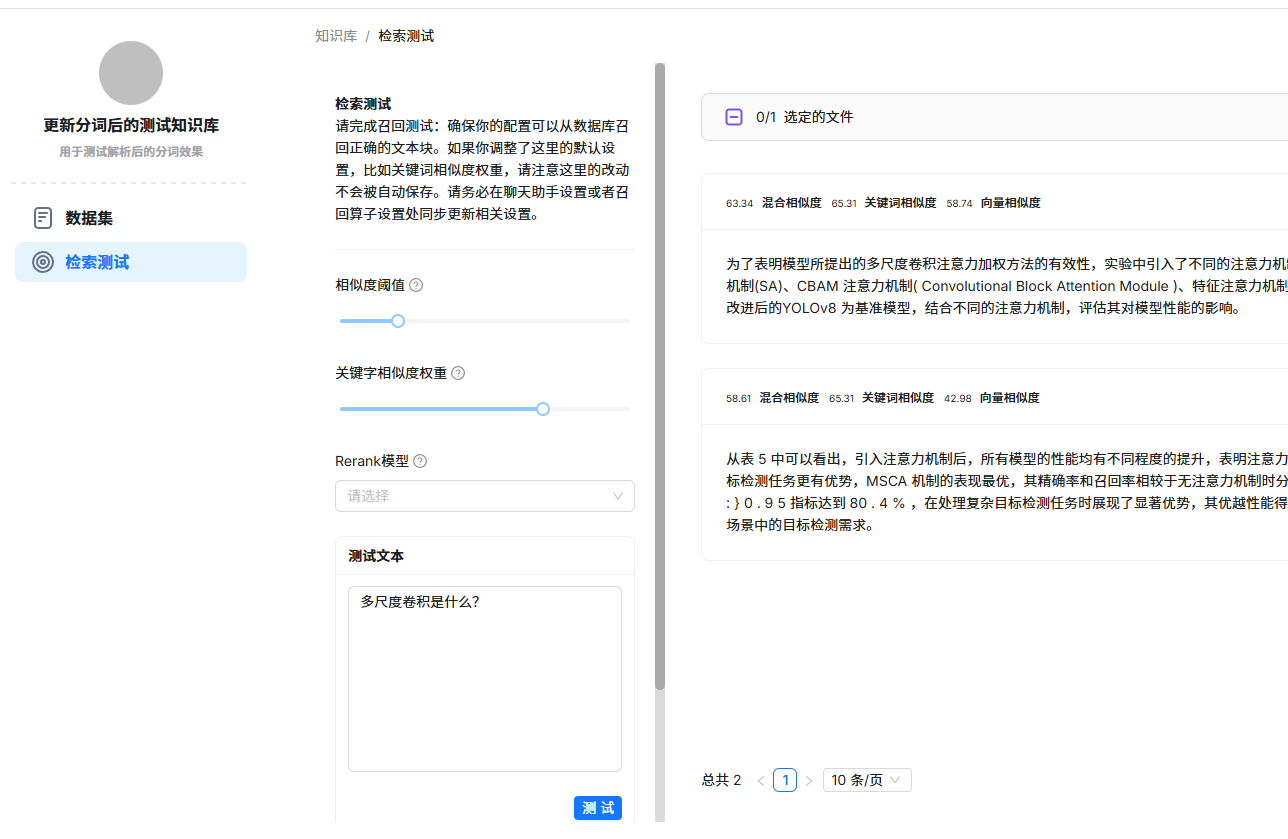
如上图所示,进行检索测试时,关键词相似度得分为0,导致混合相似度(加权相加得到)也被大幅拉低,低于设定的相似度阈值,出现无法召回的情况。
因此,问题的核心在于关键词相似度计算异常。本文通过抽丝剥茧的方式,来剖析该问题。
检索流程分析
首先,需要先了解,在前端点击测试按钮后,后端发生了什么?
查看最新版本的Ragflow(v0.19.0),相较之前的版本,检索逻辑基本没有变化。
目前看来,这部分基本处于固定成熟状态。
1. 请求接收
前端点击按钮,会通过retrieval_test接口发送Post请求。
前端请求传递以下参数:
- similarity_threshold:相似度阈值,低于此阈值将不会被检索出来。
- vector_similarity_weight:关键字相似度权重,数值越大则越突出关键字搜索结果
- question:输入的测试文本
- doc_ids:选中的文档id号,就是在一次检索之后,可通过选中特定文档信息再进行检索
- kb_id:当前知识库的id号
- page:分页显示当前页
- size:分页显示单页条目数
请求参数实例如下:
{"similarity_threshold": 0.2,"vector_similarity_weight": 0.30,"question": "测试问题","doc_ids": [],"kb_id": "1848bc54384611f0b33e4e66786d0323","page": 1,"size": 10
}
后端通过api\apps\chunk_app.py的retrieval_test函数来接收响应。
2. 检索准备
后端接收到请求后,会先验证知识库的权限,当前用户处于知识库创建人的团队,才能执行检索操作。
具体检索方式通过rag\nlp\search.py的retrieval函数进行检索。
具体检索逻辑在rag\nlp\search.py的search函数中实现。
3. 检索问题预处理
在使用es检索之前,需要先对问题进行预处理,包含以下步骤:
- 1.中文和英文混合输入时,之间添加空格(add_space_between_eng_zh)
- 2.使用正则表达式替换特殊字符为单个空格,并将文本转换为简体中文和小写(question)
- 3.移除疑问词,比如“什么”、“怎么样”、“如何”(rmWWW)
移除疑问词会让匹配更加精准,比如问题是“目标检测是什么”,它会把“是什么”这样泛问的词汇移除,留下“目标检测”这样的名词进行后续匹配。
之后,会进行关键词提取。
关键词是先通过分词器,对问题的进行切分,具体的分词器逻辑先略过,后文会提到。
提取完关键词后,还会进行同义词查找的操作。
具体的是通过同义词字典来查询,字典默认路径为rag\res\synonym.json
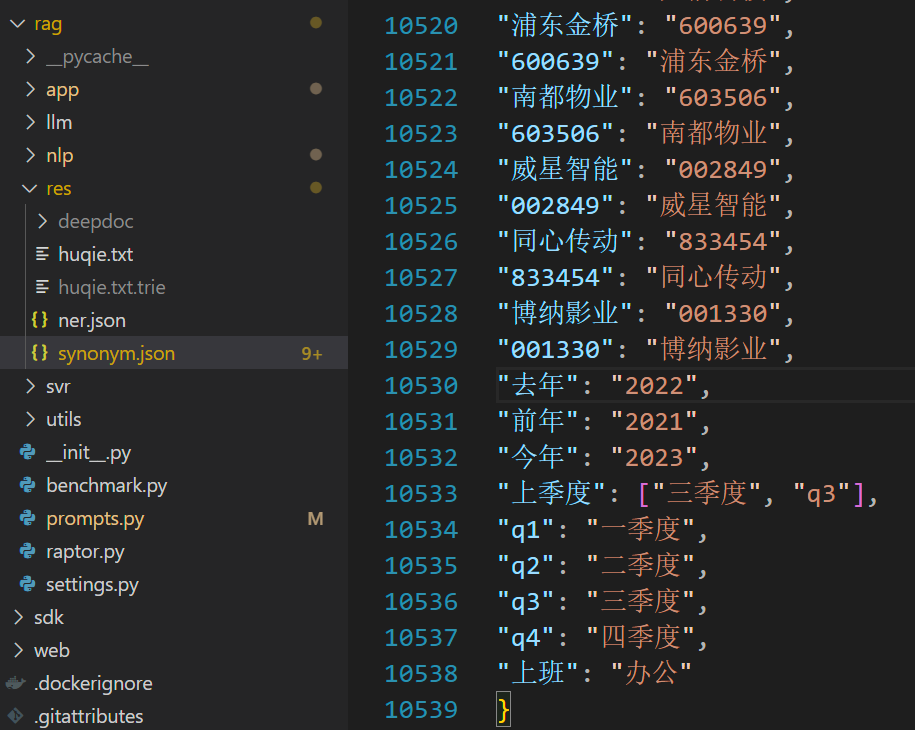
从该文件中,可以看到,里面内置了所有A股的名称和股票编号(原开发团队看来真的喜欢炒股)。
另外,今年同义词为2023,显然,前年写的文件还没更新,在某些情况下,会造成错误查询的问题。对于这个小bug,我也提交了一个pr给上游仓库。
得到同义词后,会同样对同义词进行分词操作,最后,集合所有关键词及同义词,数量上限32个。
4. 混合检索
在处理完关键词之后,原问题会通过嵌入模型变成向量形式。
最终,通过关键词和向量进行混合检索,这里设置的关键词检索权重和向量检索权重为5%/95%。
注意,该权重不是外部传递的相似度权重,而是内置的检索权重,无法通过外部方式进行修改。
# 生成查询向量
matchDense = self.get_vector(qst, emb_mdl, topk, req.get("similarity", 0.1))
q_vec = matchDense.embedding_data
# 在返回字段中加入查询向量字段
src.append(f"q_{len(q_vec)}_vec")
# 创建融合表达式:设置向量匹配为95%,关键词为5%
fusionExpr = FusionExpr("weighted_sum", topk, {"weights": "0.05, 0.95"})
# 构建混合查询表达式
matchExprs = [matchText, matchDense, fusionExpr]# 执行混合检索
res = self.dataStore.search(src, highlightFields, filters, matchExprs, orderBy, offset, limit, idx_names, kb_ids, rank_feature=rank_feature)
5. 重排序
重排序是对检索块进行评分排序,即混合相似度高的块会被优先排到前面。
在重排序过程中,会进行三种相似度的计算。
无论是否设置重排序模型,都会经过重排序的步骤:
- 如果设置了重排序模型,相似度值会通过重排序模型得到。
- 如果未设置重排序模型,会通过余弦相似度进行计算。
# 执行重排序操作
if rerank_mdl and sres.total > 0:sim, tsim, vsim = self.rerank_by_model(rerank_mdl, sres, question, 1 - vector_similarity_weight, vector_similarity_weight, rank_feature=rank_feature)
else:sim, tsim, vsim = self.rerank(sres, question, 1 - vector_similarity_weight, vector_similarity_weight, rank_feature=rank_feature)
最终,混合相似度(sim)会由关键词相似度(tsim)和向量相似度(vsim)加权得到,这里的权重才会真正受到前端传递权重值的影响。
分词原理概述
理解完检索过程后,回到开篇提到的问题,就可以进一步定位:关键词相似度不足,实际原因就是解析块和问题的分词逻辑不一致。
在现版本中,解析时,文本的分词直接通过text.split()处理,即会将空格,制表符\t、换行符\n等字符,作为分隔依据,这样操作太过简单。
ragflow的分词器在rag\nlp\rag_tokenizer.py这个文件中,详细过程可参考以下注释:
1. 预处理:- 将所有非单词字符(字母、数字、下划线以外的)替换为空格。- 全角字符转半角。- 转换为小写。- 繁体中文转简体中文。
2. 按语言切分:- 将预处理后的文本按语言(中文/非中文)分割成多个片段。
3. 分段处理:- 对于非中文(通常是英文)片段:- 使用 NLTK 的 `word_tokenize` 进行分词。- 对分词结果进行词干提取 (PorterStemmer) 和词形还原 (WordNetLemmatizer)。- 对于中文片段:- 如果片段过短(长度<2)或为纯粹的英文/数字模式(如 "abc-def", "123.45"),则直接保留该片段。- 否则,采用基于词典的混合分词策略:a. 执行正向最大匹配 (FMM) 和逆向最大匹配 (BMM) 得到两组分词结果 (`tks` 和 `tks1`)。b. 比较 FMM 和 BMM 的结果:i. 找到两者从开头开始最长的相同分词序列,这部分通常是无歧义的,直接加入结果。ii. 对于 FMM 和 BMM 结果不一致的歧义部分(即从第一个不同点开始的子串):- 提取出这段有歧义的原始文本。- 调用 `self.dfs_` (深度优先搜索) 在这段文本上探索所有可能的分词组合。- `self.dfs_` 会利用Trie词典,并由 `self.sortTks_` 对所有组合进行评分和排序。- 选择得分最高的分词方案作为该歧义段落的结果。iii.继续处理 FMM 和 BMM 结果中歧义段落之后的部分,重复步骤 i 和 ii,直到两个序列都处理完毕。c. 如果在比较完所有对应部分后,FMM 或 BMM 仍有剩余(理论上如果实现正确且输入相同,剩余部分也应相同),则对这部分剩余的原始文本同样使用 `self.dfs_` 进行最优分词。
4. 后处理:- 将所有处理过的片段(英文词元、中文词元)用空格连接起来。- 调用 `self.merge_` 对连接后的结果进行进一步的合并操作,尝试合并一些可能被错误分割但实际是一个完整词的片段(基于词典检查)。
5. 返回最终分词结果字符串(词元间用空格分隔)。
不难看出,实际的分词逻辑相当复杂,并且,ragflow还专门配置了一个词典,用来记录常见词汇,词频,词性等信息。
为加速查询速度,还构建了一个Trie树的形式(huqie.txt.trie)。
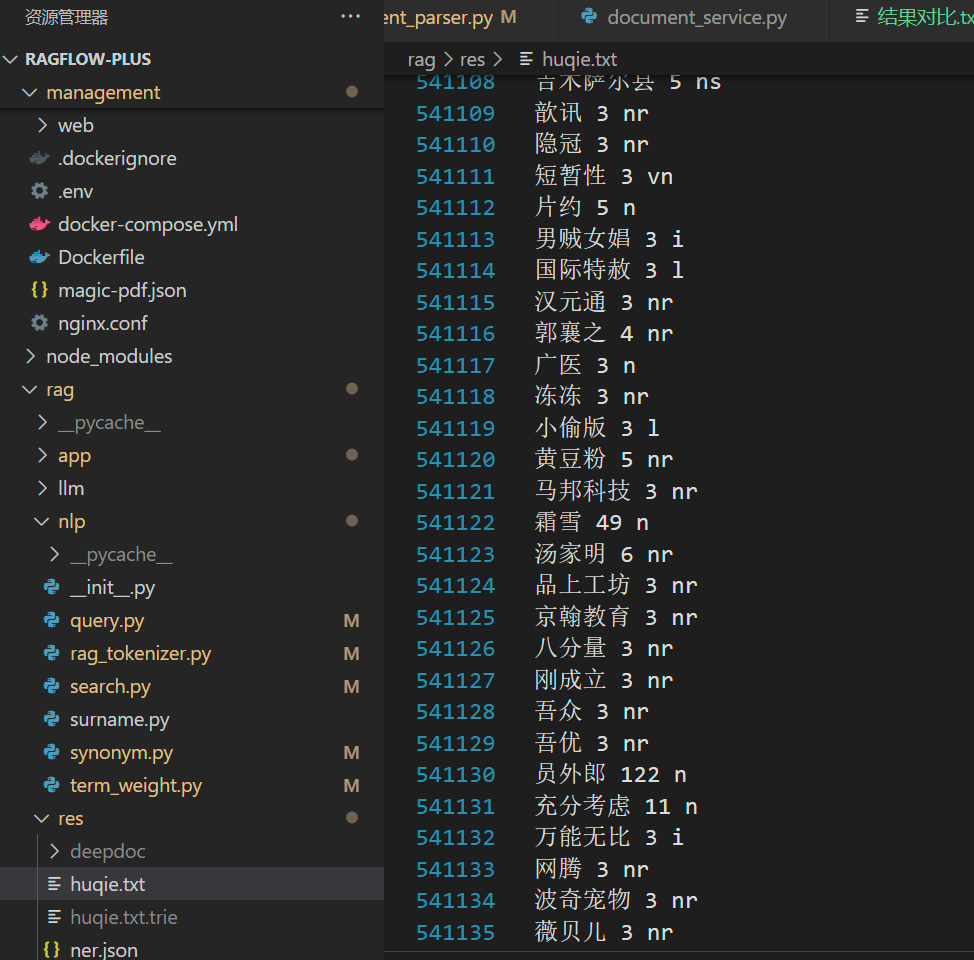
内容格式如下:
第一列:词语 (Token/Word)
第二列:词频 (Frequency/Weight)
第三列:词性标注 (Part-of-Speech Tag)
常见的词性代码有:
- n: 普通名词 (noun)
- nr: 人名 (noun, person name)
- ns:地名 (noun, place name)
- nt: 机构团体名 (noun, organization name)
- nz: 其他专有名词 (noun, other proper noun)
- v: 动词 (verb)
- a: 形容词 (adjective)
- d: 副词 (adverb)
- m: 数词 (numeral)
- q: 量词 (quantity)
- r: 代词 (pronoun)
- p: 介词 (preposition)
- c: 连词 (conjunction)
- u: 助词 (auxiliary)
- i: 成语 (idiom)
- l: 习用语 (lemma, fixed expression)
- t: 时间词 (time word)
- j: 简称略语 (abbreviation)
因此,参照原版的方式,直接将该分词器在解析过程中进行应用,即可修复此问题。
在最新的仓库提交中,在management\server\services\knowledgebases下面新增了rag_tokenizer.py文件,用来实现和原版一致的分词逻辑。
修复好后,重新解析文件,再进行检索测试,可以看到能够正常检索计算。
知识库创建人权限问题
另外,v3.0.0版本还有一个问题,即在后台创建新的知识库时,创建人选择其它用户,解析完文件无法在前台正常检索。
梳理完检索过程,可以顺带解决这一问题。
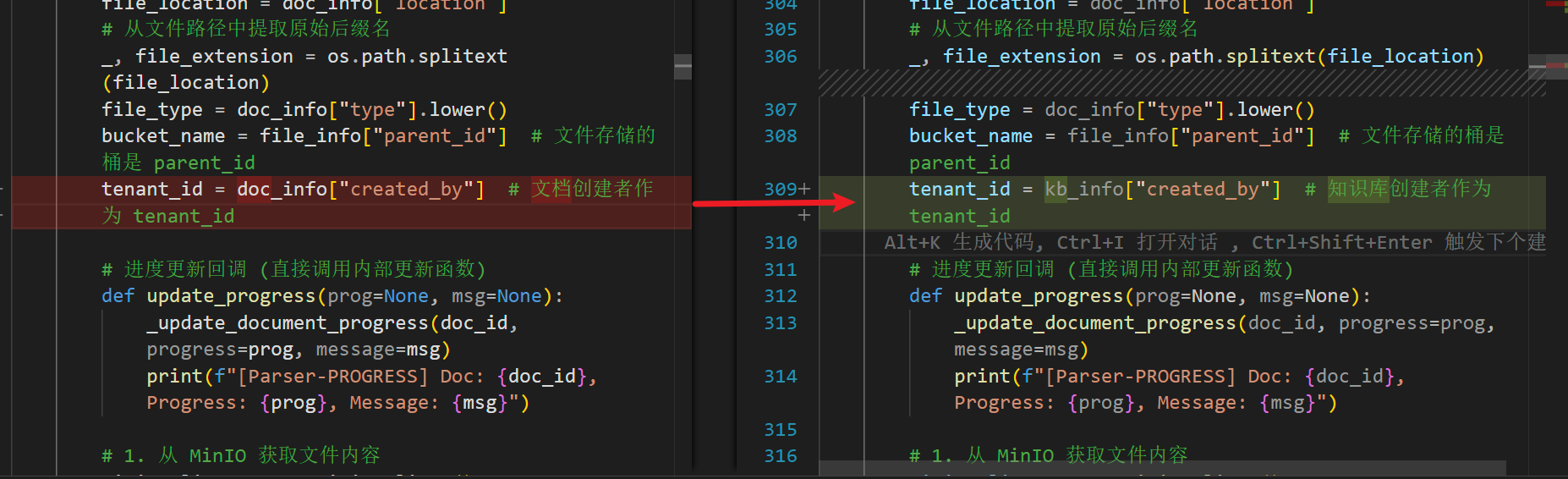
问题的原因是,ragflow进行检索时,默认是在es中寻找当前用户的序列(index_name函数)。
因此,解决该问题就需要在解析时,插入es的tenant_id从文档创建人的id改为知识库拥有者的id。
跨语言方案细节
看到此处,顺带一提ragflow v0.19.0版本中,新增了一个跨语言检索的功能。
细看代码,原来它是在rag\prompts.py中,新增了cross_languages的对应提示词。
本质上还是用语言模型来执行翻译操作。
这种方式显然有明显缺陷:
- 1.搜索需要等待模型响应完全,流程时间会显著增长
- 2.通过语言模型进行翻译,低参数模型可能存在幻觉问题。
ragflow 总是不计成本地用时间换性能,这是实地应用场景难以接受的。
后续,考虑用更轻量快速的方式,实现翻译功能。
友情提示
RagflowPlus目前仍处于早期状态,解析功能仍在高频更新中。
因此,不建议直接将其应用于生产环境,只有发展到ragflow的阶段,解析逻辑稳定,才适合去批量解析大量文件。否则,后续解析逻辑更新,仍需要重新对已有内容进行解析。
另外,有不少人问到“是否考虑加入知识图谱”的问题。
之前在仓库issue#119中进行过回复。
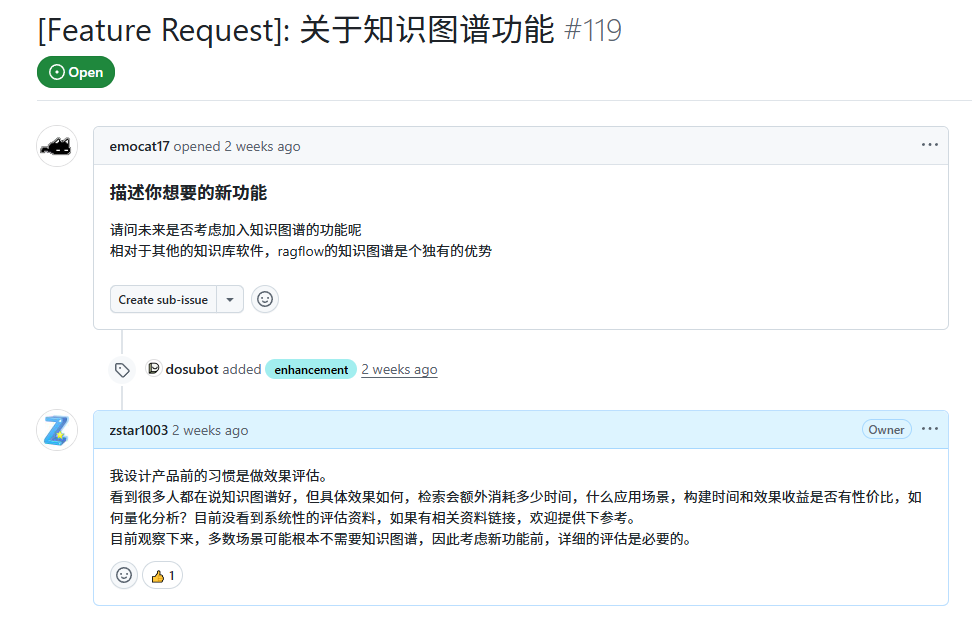
诚然,知识图谱可能在多跳问题中具备一定优势,但具体效果如何,怎样构建,都需要时间详细评估。
在这个普遍浮躁的互联网洪流中,保持慢工出细活的工作节奏,何尝不是新时代的工匠精神呢?


![BUUCTF[极客大挑战 2019]Havefun 1题解](https://i-blog.csdnimg.cn/direct/6f6fb22bf0c74355b23576dabbbd24aa.png)

![BUUCTF[HCTF 2018]WarmUp 1题解](https://i-blog.csdnimg.cn/direct/1cead5f2797a4d9a9e87abef42edd5bd.png)