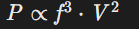背景
在当代数字化浪潮中,日志数据的高效处理对于企业运维监控和数据分析至关重要。本博文聚焦于ELK(Elasticsearch、Logstash、Kibana)技术栈与Kafka集群的深度对接,旨在探讨如何通过这一架构优化,实现高效、可靠且可扩展的日志处理解决方案,以应对日益增长的数据量和复杂多变的业务需求,同时减轻Logstash压力并降低其与Filebeat的耦合性,提升整个系统的性能与稳定性,为企业的数据驱动决策提供坚实的技术支撑。
Kafka集群特性适配 :Kafka具备高吞吐量(如单机每秒可处理10w + /s)、高可用性(通过多副本机制保障数据不丢失)、强扩展性(可方便地进行集群扩展以应对数据增长)以及丰富的生态集成能力(与多种编程语言和工具兼容良好)等特点,使其成为对接ELK的理想选择。其强大的消息队列功能能够很好地满足日志数据海量、实时性要求高的处理需求,确保数据在产生端(如Filebeat采集的日志)和消费端(如Logstash后续处理)之间的高效流转和可靠存储。
一、 架构图解
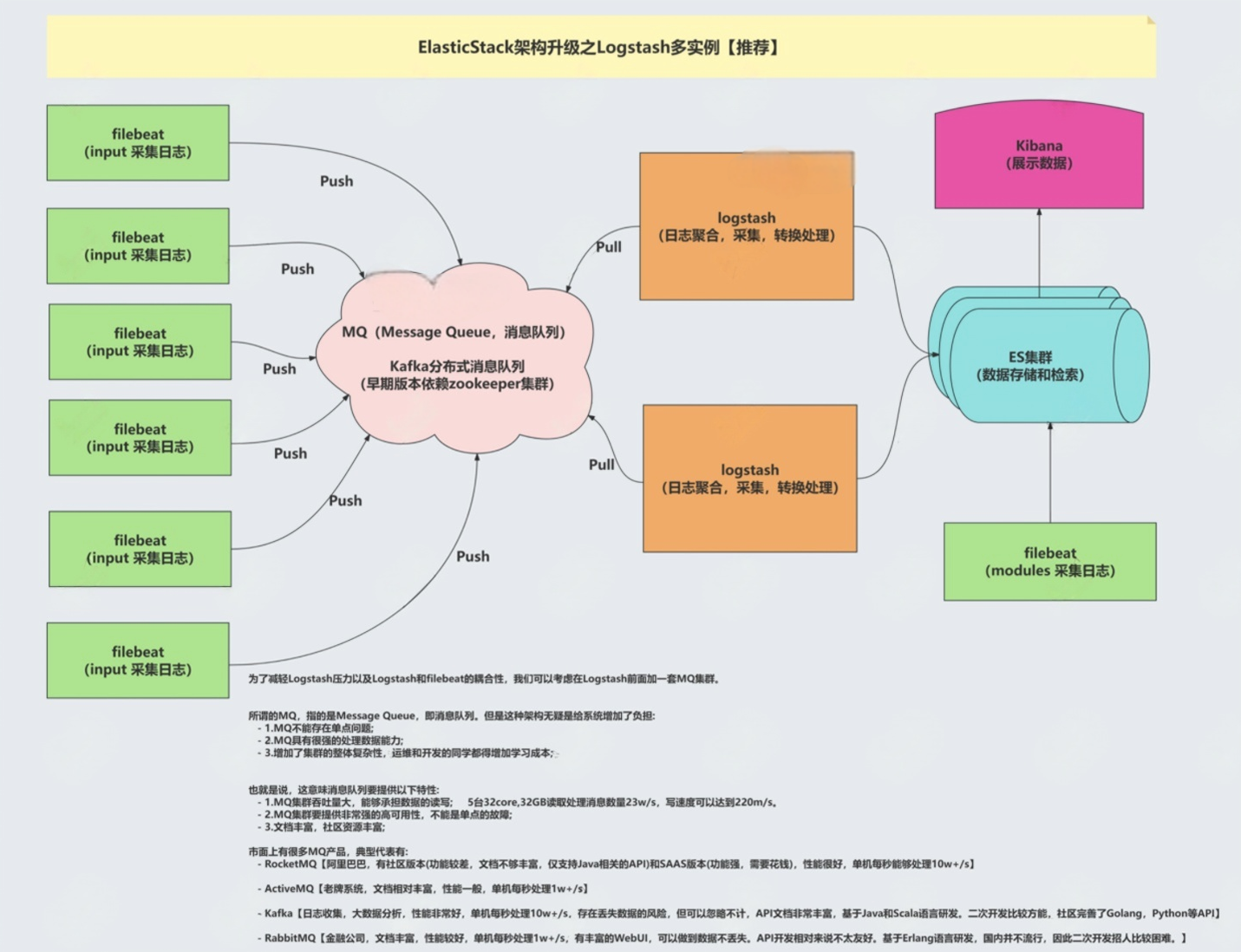
为了减轻Logstash压力以及Logstash和filebeat的耦合性,我们可以考虑在Logstash前面加一套MQ集群。
所谓的MQ,指的是Message Queue,即消息队列。但是这种架构无疑是给系统增加了负担:
- 1.MQ不存在单点问题;
- 2.MQ具有很强的处理数据能力;
- 3.增加了集群的整体复杂性,运维和开发的同学都得增加学习成本;也就是说,这意味消息队列要提供以下特性:
- 1.MQ集群吞吐量大,能够承担数据的读写;5台32core,32GB读取处理消息数量23w/s,写速度可以达到220m/s,
- 2.MQ集群要提供非常强的高可用性,不能是单点的故障;
- 3.文档丰富,社区资源丰富;市面上有很多MQ产品,典型代表有:
- RocketMQ【阿里巴巴,有社区版(功能较差,文档不够丰富,仅支持Java相关的API)和SAAS版本(功能强,需要花钱),性能很好,单机每秒能够处理10w+/s】
- ActiveMQ【老牌系统,文档相对丰富,性能一般,单机每秒处理1w+/s】
- Kafka【日志收集,大数据分析,性能非常好,单机每秒处理10w+/s,存在丢失数据的风险,但可以忽略不计,API文档非常丰富,基于Java和Scala语言研发,二次开发比较方便,社区完善了Golang,Python等API】
- RabbitMQ【金融公司,文档丰富,性能较好,单机每秒处理1w+/s,可以做到数据不丢失,API开发相对来说不太友好,基于Erlang语言研发,国内并不流行,因此二次开发招人比较困难。】
二、 架构实现
首先我们需要有一套kafka集群,没有的话可以参考我之前的文章: Kafka集群部署实战_kafka部署方案-CSDN博客
1. filebeat生产kafka集群数据
# 编写filebeat并启动
[root@elk93 /etc/filebeat/config]# cat filebeat_tcp-to-kafka.yaml .
filebeat.inputs:
- type: tcphost: "0.0.0.0:9000"# 数据输出到kafka
output.kafka:# 指定kafka集群的地址hosts: - 10.0.0.91:9092- 10.0.0.92:9092- 10.0.0.93:9092# 指定topictopic: novacao-linux96-kafka
[root@elk93 /etc/filebeat/config]# rm -rf /var/lib/filebeat/
[root@elk93 /etc/filebeat/config]# filebeat -e -c `pwd`/filebeat_tcp-to-kafka.yaml# 发送测试数据
[root@elk91 ~]# echo helllllllllllllllo |nc 10.0.0.93 9000# kafka验证数据
[root@elk92 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.93:9092 --topic novacao-linux96-kafka --from-beginning
.....
{"@timestamp":"2025-03-17T12:35:18.320Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.17.28"},"log":{"source":{"address":"10.0.0.91:55810"}},"input":{"type":"tcp"},"agent":{"name":"elk93","type":"filebeat","version":"7.17.28","hostname":"elk93","ephemeral_id":"73d1dee2-d555-4955-b689-75d602e1b5e0","id":"ced21de3-ed8a-4601-acba-07f0d7db5a5a"},"ecs":{"version":"1.12.0"},"host":{"name":"elk93"},"message":"helllllllllllllllo"}2. Logstash消费kafka集群数据
kibana基于开发工具创建账号
POST /_security/api_key
{"name": "Linux96", "role_descriptors": {"filebeat_monitoring": { "cluster": ["all"],"index": [{"names": ["novacao-logstash-kafka*"],"privileges": ["all"]}]}}
}
生成实例
{"id" : "QSYgpJUBD3ll3qToqN4V","name" : "Linux96","api_key" : "EWyBlHEHTnSQlALuB41hpw","encoded" : "UVNZZ3BKVUJEM2xsM3FUb3FONFY6RVd5QmxIRUhUblNRbEFMdUI0MWhwdw=="
}# 解码数据
[root@elk91 ~]# echo UVNZZ3BKVUJEM2xsM3FUb3FONFY6RVd5QmxIRUhUblNRbEFMdUI0MWhwdw== |base64 -d ;echo
QSYgpJUBD3ll3qToqN4V:EWyBlHEHTnSQlALuB41hpw# Logstash消费数据
[root@elk93 /etc/logstash/conf.d]# cat 09-logstash-to-ES_api-keys.conf
input { kafka {# 指定kafka集群的地址bootstrap_servers => "10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092"# 指定从kafka哪个topic拉取数据topics => ["novacao-linux96-kafka"]# 指定消费者组group_id => "linux96-001"# 指定拉取数据offset的位置点,常用值:earliest(从头拉取数据),latest(从最新的位置拉取数据)auto_offset_reset => "earliest"}
}filter {json {source => "message"}mutate {remove_field => [ "agent","@version","ecs","input","log" ]}
} output { # stdout { # codec => rubydebug # } elasticsearch {hosts => ["10.0.0.91:9200","10.0.0.92:9200","10.0.0.93:9200"]index => "novacao-logstash-kafka"api_key => "QSYgpJUBD3ll3qToqN4V:EWyBlHEHTnSQlALuB41hpw"ssl => truessl_certificate_verification => false}
}# 启用logstash
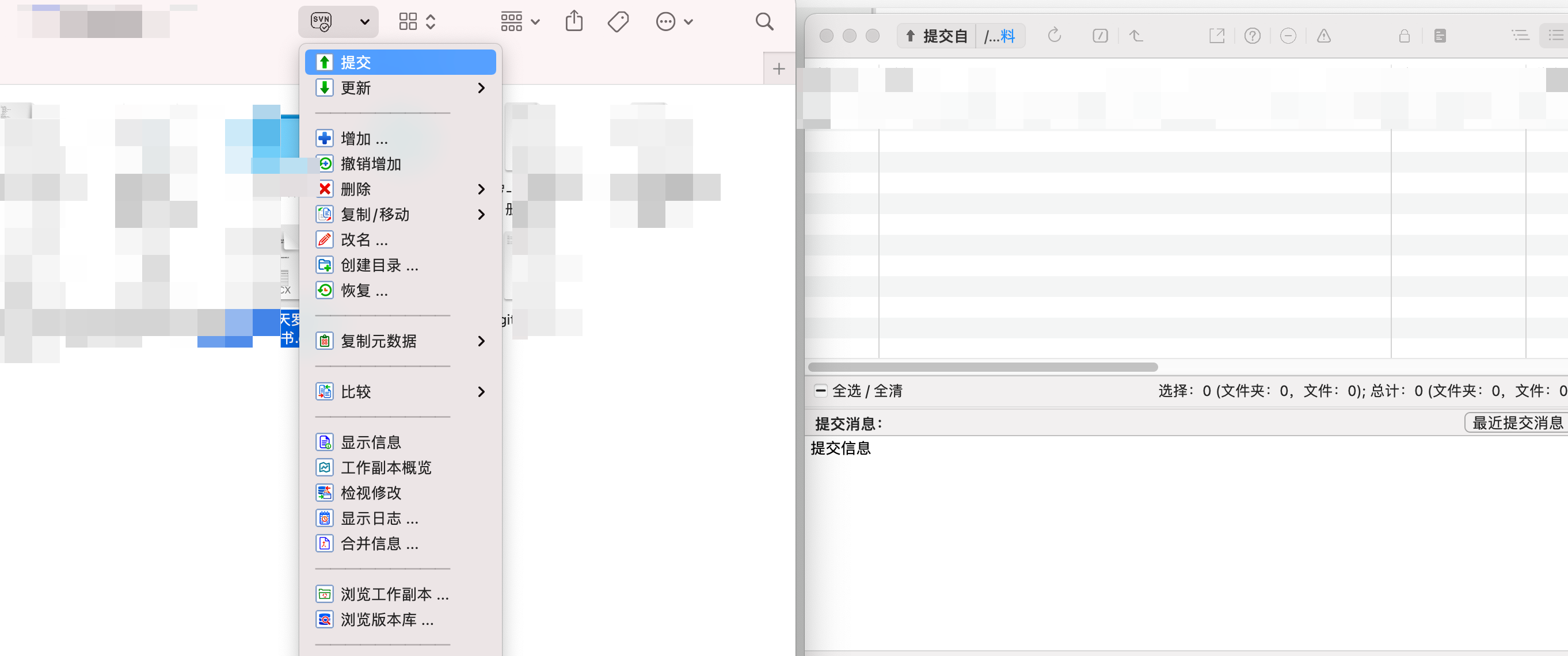
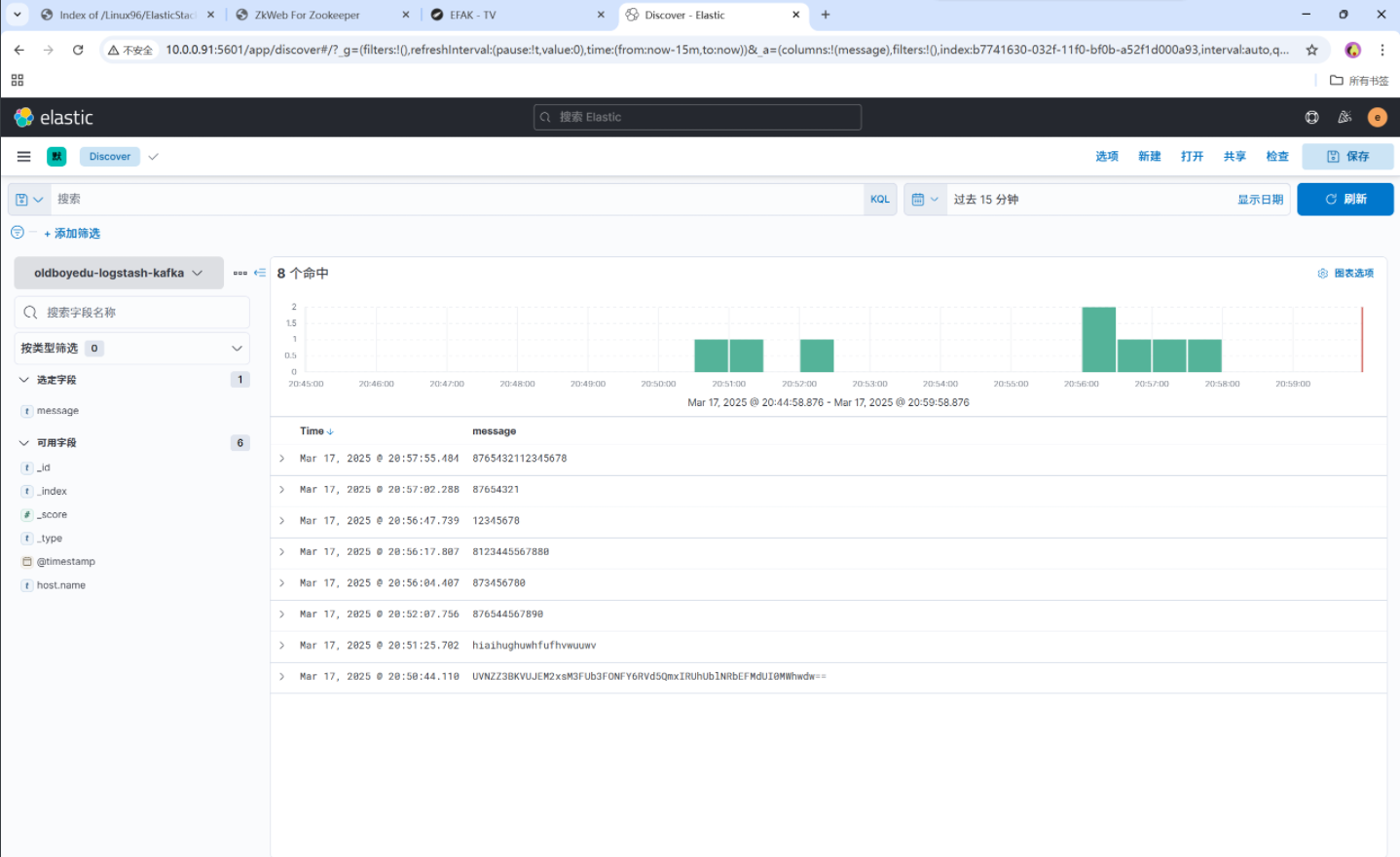
[root@elk93 /etc/logstash/conf.d]# logstash -rf 09-logstash-to-ES_api-keys.conf # kibana查看数据3. Kibana查看数据
三、 总结
此次博文深入浅出地讲解了ELK对接Kafka集群的实现细节和优势所在,为读者呈现了一套成熟、稳定且高效的日志处理架构方案。在大数据时代背景下,这一架构不仅能够有效应对海量日志数据的挑战,还为企业数字化转型过程中的数据治理和智能分析奠定了坚实基础。希望本文能为从事相关领域的技术人员提供有益的参考和借鉴,助力他们在实际工作中更好地运用这一技术组合,挖掘数据潜力,驱动业务创新发展。