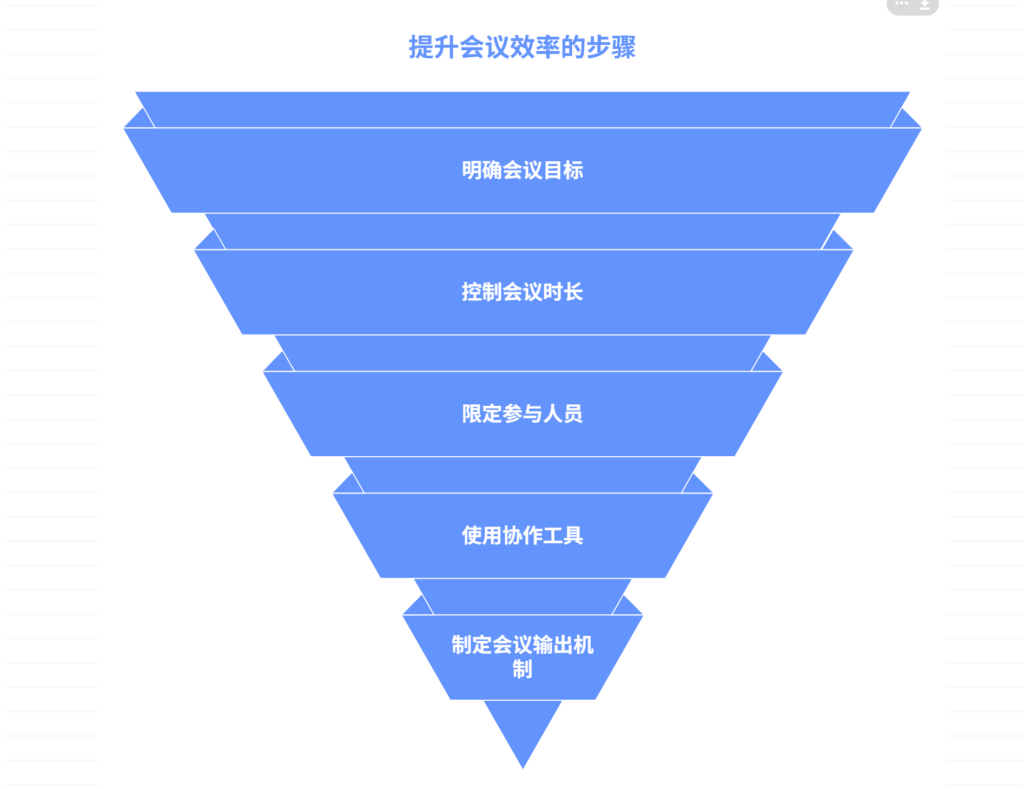
从自然语言监督中学习可迁移的视觉模型
虽然有点data/gpu is all you need的味道,但是整体实验和谈论丰富度上还是很多的,也是一篇让我多次想放弃的文章,因为真的是非常长的原文和超级多的实验讨论,隔着屏幕感受到了实验的工作量之大。
Abstract
最先进的计算机视觉系统被训练来预测一组固定的预定对象类别。 这种受限制的监督形式限制了它们的通用性和可用性,因为需要额外的标记数据来指定任何其他视觉概念。 直接从原始文本中学习图像是一种很有前途的选择,它利用了更广泛的监督来源。 我们证明了预测哪个标题与哪个图像相匹配的简单预训练任务是一种有效且可扩展的方法,可以在从互联网收集的4亿对(图像,文本)数据集上从头开始学习SOTA图像表示。 在预训练之后,使用自然语言来参考学习到的视觉概念(或描述新的概念),从而实现模型向下游任务的零样本转移。我们通过对30多个不同的现有计算机视觉数据集进行基准测试来研究这种方法的性能,这些数据集涵盖了OCR、视频中的动作识别、地理定位和许多类型的细粒度对象分类等任务。 该模型不平凡地转移到大多数任务,并且通常与完全监督的基线竞争,而不需要任何数据集特定的训练。 例如,我们在ImageNet zero-shot上匹配原始ResNet-50的精度,而不需要使用它所训练的128万个训练样本中的任何一个。
Introduction and Motivating Work
在过去几年中,直接从原始文本中学习的预训练方法彻底改变了NLP
与任务无关的目标,如自回归和masked语言建模,已经在计算、模型容量和数据方面扩展了许多数量级,稳步提高了能力。“文本到文本”作为标准化输入输出接口的发展使任务无关架构能够零射传输到下游数据集,从而消除了对专门输出头或数据集特定定制的需要。 像GPT-3在使用定制模型的许多任务中具有竞争力,而几乎不需要特定数据集的训练数据。
这些结果表明,在网络规模的文本集合中,现代预训练方法可获得的总体监督优于高质量的人群标记NLP数据集。然而,在计算机视觉等其他领域,在人群标记数据集(如ImageNet)上预训练模型仍然是标准做法(Deng et al., 2009)。 直接从网络文本中学习的可扩展预训练方法能否在计算机视觉领域取得类似的突破? 先前的工作令人鼓舞。
总之可以整理为,之前的很多工作其实并不是方法不行而是数据不够多,所以效果不好,并且泛化性能非常有限,而作者提出的方法称为CLIP(Contrastive LanguageImage Pre-training)在各个数据集上都表现出了很高的指标,有更强的鲁棒性。例如在ImageNet上,CLIP同监督训练的ResNet50达到了同等的水平。
通过4亿数据在大量数据集表现出了优秀的效果,但是后文中对比中在MNIST效果却很差,作者后文给出的原因是发现数据集很少有和MNIST相似的数据。所以后续文章作者也总结了很多CLIP的局限性,但是他依旧在很多数据集表现的很好这也是不能忽视的。
Approach
2.1 自然语言监督
以自然语言为(标签)指导模型学习具有很多优势。
首先,不需要人工标注,可以快速规模化。可以充分利用互联网上的信息。
其次,强大的zero-shot迁移学习能力。传统的机器学习对输入标签格式有特殊要求,在推理阶段需要遵循相同的格式。数据集的格式限制了模型的使用范围。传统的机器学习模型不能在数据集定义的格式之外的任务上使用。使用自然语言作为监督信号,能够处理任何以自然语言作为输入的任务。而自然语言是最直观、通用的输入格式。所以模型可以方便地迁移到其它场景。
第三,让CV模型学习到视觉概念的自然语言描述。将“苹果”图片和“苹果”单词建立联系,也就真正学习到了图片的语义信息。
第四,多模态。以自然语言作为桥梁,用一个大模型学习文本、图片甚至视频的理解。
2.2 创建足够大的数据集
现有数据集主要有3个,MS-COCO、Visual Genome、YFCC100M。前两者是人工标注的,质量高但是数据量小,大约只有0.1M。YFCC100M大约有100M图片,但是质量堪忧,有些标题只有无意义的名字,过滤后,这个数据集缩小至15M,大约和ImageNet差不多大。(显然这个数据量是不够的)
OpenAI自己构建了一个400M的数据集,使用500K个查询进行搜索,每个查询大约有20K个“图像—文本“对。该数据集被称为WIT(webimagetext),数据量和GPT-2使用的差不多。
2.3 有效的预训练方法
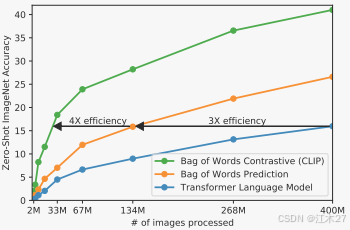
OpenAI的第一个尝试类似于VirTex,将基于CNN的图片编码器和文本transformer从头训练,去预测图片的标题。然而这个方法很快遇到了困难。从下图中可以看出,一个63M的语言模型,使用了基于ResNet50的图片编码器的两倍计算量,但是效率却是预测词袋的1/3(3x efficiency)。
很快,OpenAI尝试了第二种方案——对比学习。将文本和图片的embedding进行相似度比较,从图片2可以看出训练速度是预测词袋的4倍。
对方法的描述:给定一个大小为N的batch,CLIP需要预测这NxN个对是否属于同一语义。CLIP利用图片和文本编码器将图片和文本的embedding进行基于cosine距离的打分,使N个成对的分数变大,使N^2-N个非成对的分数减小。模型训练是基于对称的交叉熵说损失。下图展示了训练的伪代码:

代码过程描述:
第1-2行:利用图片编码器和文本编码器提取图片和文本的高维表征。
第3-4行:利用可学习线性变换(无偏置)将图片和文本表达映射到同一语义空间
第5行:内积进行相似度比较,同时乘上温度系数 exp(\tau) 。
第6-9行:分别沿图像(每一条文本同不同图片的相似度)和文本轴(每一条图片同文本的相似度)计算交叉熵,相加处以2得到对称损失。
第一个是我们从头开始训练CLIP,而不使用ImageNet权重初始化图像编码器或使用预训练权重初始化文本编码器。
第二个我们只使用线性投影将每个编码器的表示映射到多模态嵌入空间。 我们没有注意到两个版本之间的训练效率差异,并推测非线性投影可能仅在自监督表示学习方法中与当前图像的细节共同适应。本文没有使用非线性变换;
第三个是直接利用原始文本即单个句子;
第四个是图片的预处理只有大小变换后随机方形剪切;
最后,控制softmax中对数范围的温度参数τ在训练过程中被直接优化为对数参数化的乘法标量,以避免变成超参数。
2.4 选择和缩放模型
视觉:resnet或者transformer
文本:transformer
2.5 训练
训练了8个模型,不同的深度、宽度、patch等,32epoch、adam、batchsiz=32768、混合精度训练
训练完后对模型用更大的size进行了一个fintune了1epoch称其为CLIP模型
本文构造了一个更简单的学习任务。利用对比学习的思想,只预测哪段文本作为一个整体是和图片成对出现的,不需要预测文本的确切内容。用对比学习的目标( contrastive objective)代替了预测学习的目标(predictive objective)。这个约束放宽了很多,学习需要的算力减少很多。
作者发现,仅仅把训练目标任务从预测型换成对比性,训练的效率就能提升4倍。如图所示。
2.6 使用CLIP
在下游任务测试时,有两种使用CLIP的方法。第一种,利用文本prompt进行预测,将预测的embedding同类别的embedding进行相似度匹配,实现分类任务;第二种,额外训练linear probe进行预测。
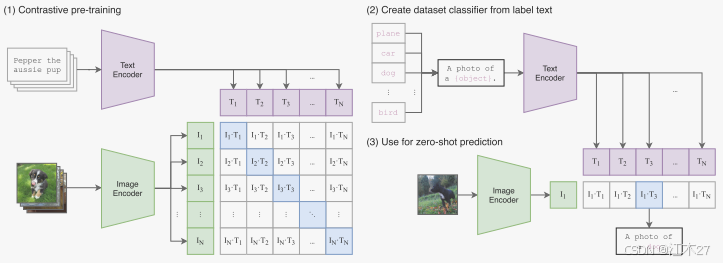
这张图片展示了基于对比学习训练(1)和使用零样本预测(2&3)。对比学习是利用文本—图像对数据,判别当前图片是否于文本匹配,从而学习图像的高维表征;零样本预测时,利用prompt构建不同类别的embedding,然后同图片匹配从而进行分类。
生成句子例如这是一张xx照片,然后通过text encoder 编码得到文本特征,然后用文本特征和图像特征进行cosine 相似度 进入softmax得到概率分布
总之,我认为的一个重要贡献是它打通了文本和图片理解的界限,催生了后面多模态的无限可能。后续的“以图生文”,“以文搜图”都有赖这一点。
Experiments
3.1 zero-short 迁移
作者动机:解决之前工作迁移其他任务困难的问题。
3.1.3对比其他方法
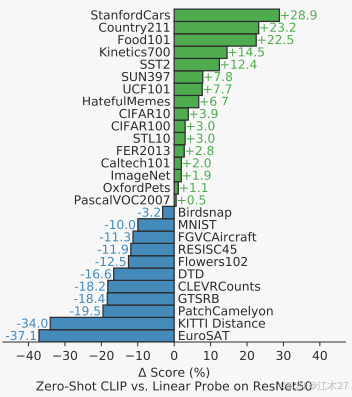
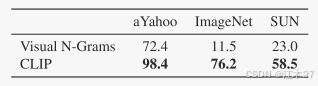
CLIP在零样本迁移效果和有监督的res50相当。CLIP同Visual N-Grams进行了横向对比。如Table1中所示,几乎在所有数据集上CLIP都远超过Visual N-Grams(体现CLIP的zero-shot能力)
3.1.4提示工程与集成
a photo of a {label}这种方法可以提升在imagenet上1.3%的准确率,prompt对于分类的性能很重要。因此OpenAI自己尝试了很多prompt去提升分类的准确率。比如在Oxford-IIIT Pet数据集中,使用prompt “A photo of a {label}, a type of pet.”就好于单单使用“A photo of a {label},”。还讲了一些在Food101、FGVC、OCR、satellite数据集上的经验。
3.2特征学习
特征学习是指在下游任务数据集上用全部的数据重新训练。有两种方式衡量预训练阶段学习到的特征好不好:
linear prob将预训练好的模型“冻住”,不改变其参数,在之上训练一个分类头。
finetune整个网络参数都可以调整,端到端地学习。微调一般更灵活,效果更好。
本文采用linear prob的方式。不需要大量调参,评测流程可以标准化。
总结
这里还有很多数据分布问题、模型不足、实验讨论、和人类对比等等,实验非常丰富,就不一一展开, 总的来说,原因花这么多人、gpu、数据实现的CLIP想必在gpt 4中也有很多该实验的影子和贡献,openai的这篇文章也给后续很多文章和领域提供了思路,值得一读吧。