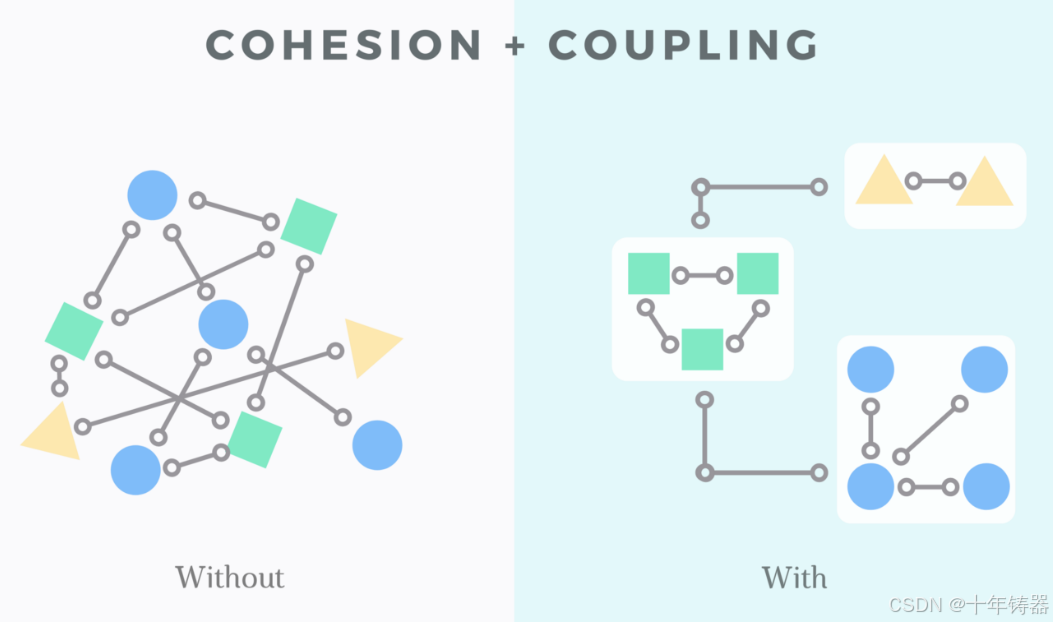
“高内聚、低耦合”是面向对象编程中非常重要的设计原则,它有助于提高代码的可维护性、扩展性和复用性。
1. 初衷:为什么会有这个原则?
在软件开发中,随着业务需求的复杂化,代码难免会变得越来越庞大。如果开发者将一大堆功能塞进一个方法或类中,代码会变得难以理解、难以维护。而且假如这些功能彼此之间密切依赖,甚至代码中充满硬编码的调用关系,那么代码的复用性和灵活性就会大幅降低。
为了解决这些问题,人们总结出了 “高内聚、低耦合”的原则。
2. 目的:这个原则想要解决什么问题?
- 高内聚的目标是让每个
模块或类内部专注于一个单一的职责(SRP:单一职责原则),这样模块实现的功能是清晰且明确的。例如,一个类只负责处理和客户相关的业务,而不应该处理订单、支付的逻辑。高内聚让代码易于理解和测试。 - 低耦合的目标是
减少模块或类之间不必要的依赖,避免类之间紧密地绑在一起。低耦合降低了修改代码时产生的连锁反应,增强了模块的可独立开发、独立使用的能力。
简单来说,高内聚强调“做好一件事”,低耦合强调“减少过分依赖”。也即
模块内高内聚,模块间低耦合,这个原则与关注点隔离SoC以及单一职责SRP原则是内涵相通的,在软件设计时,应融会贯通地使用.
3. 实际中如何应用:
-
高内聚:确保类或方法只负责一个职责。例如,一个类可以是“订单处理器”,另一个类可以是“库存管理器”;它们不应该 “混在一起”。方法也应该短小精悍,每个方法只做一件事,避免“重复劳动”。
-
低耦合:两个模块之间应该通过清晰的接口进行交互,而不是直接依赖对方的实现细节。例如,模块 A 应该通过抽象的接口来调用模块 B,而不应该直接访问 B 内部的实现逻辑。如果需要改变模块 B 的实现,模块 A 不需要做任何修改。
注意:高内聚和低耦合的实现,与软件架构的设计密切相关,要明确软件
分层的理念,在代码层,要特别避免A类调用B类,同时B类又调用A类的出现。类之间的依赖关系,要尽量单一和简单。
4. ABAP 示例
我们用一个简单的业务场景来说明——“客户的订单系统”。假设有一个功能需要创建订单并扣减库存,同时还要生成一份日志。我们将遵循高内聚低耦合的设计理念来实现。
不遵循高内聚低耦合的代码(反例):
CLASS zcl_order DEFINITION.PUBLIC SECTION.METHODS: create_order IMPORTING iv_customer_id TYPE string,iv_product_id TYPE string,iv_quantity TYPE i.
ENDCLASS.CLASS zcl_order IMPLEMENTATION.METHOD create_order." 处理订单逻辑WRITE: / 'Creating order for customer:', iv_customer_id.WRITE: / 'Product:', iv_product_id, 'Quantity:', iv_quantity." 减库存逻辑WRITE: / 'Reducing stock for product:', iv_product_id." 生成日志WRITE: / 'Logging order creation.'.ENDMETHOD.
ENDCLASS.
问题:
create_order方法同时包含了“创建订单”“减库存”“生成日志”三种逻辑,职责不单一,内聚性很低。- 如果某一部分逻辑(如库存管理或者日志格式)需要修改,会影响整个方法,耦合度很高。
遵循高内聚低耦合的代码(改进):
我们将不同的职责拆分成多个类,每个类专注于自己的职责,并通过接口或方法交互。
" 订单类:只负责创建订单,不涉及库存或日志
CLASS zcl_order DEFINITION.PUBLIC SECTION.METHODS: create IMPORTING iv_customer_id TYPE stringiv_product_id TYPE stringiv_quantity TYPE i.
ENDCLASS.CLASS zcl_order IMPLEMENTATION.METHOD create.WRITE: / 'Order created: Customer ID:', iv_customer_id.WRITE: / 'Product:', iv_product_id, 'Quantity:', iv_quantity.ENDMETHOD.
ENDCLASS." 库存类:负责处理库存相关逻辑
CLASS zcl_stock_manager DEFINITION.PUBLIC SECTION.METHODS: reduce_stock IMPORTING iv_product_id TYPE stringiv_quantity TYPE i.
ENDCLASS.CLASS zcl_stock_manager IMPLEMENTATION.METHOD reduce_stock.WRITE: / 'Stock reduced: Product:', iv_product_id, 'Quantity:', iv_quantity.ENDMETHOD.
ENDCLASS." 日志类:负责记录日志
CLASS zcl_logger DEFINITION.PUBLIC SECTION.METHODS: log IMPORTING iv_message TYPE string.
ENDCLASS.CLASS zcl_logger IMPLEMENTATION.METHOD log.WRITE: / 'Log:', iv_message.ENDMETHOD.
ENDCLASS." 主程序:通过低耦合调用不同类完成订单逻辑
START-OF-SELECTION.DATA(lo_order) = NEW zcl_order( ).DATA(lo_stock_manager) = NEW zcl_stock_manager( ).DATA(lo_logger) = NEW zcl_logger( )." 创建订单lo_order->create( iv_customer_id = 'C001'iv_product_id = 'P001'iv_quantity = 5 )." 扣减库存lo_stock_manager->reduce_stock( iv_product_id = 'P001'iv_quantity = 5 )." 记录日志lo_logger->log( iv_message = 'Order created and stock reduced successfully.' ).
5. 分析改进的代码:
-
高内聚:
zcl_order只专注于订单创建的相关逻辑。zcl_stock_manager只负责库存的逻辑。zcl_logger专门负责日志记录。
每个类专注于自己的职责,内聚性高,逻辑更加清晰。
-
低耦合:
- 主程序中,订单、库存、日志模块是独立的,职责明确。如果以后需要改变日志记录的方法(如写入数据库而不是打印),只需要修改
zcl_logger类,不影响其他模块。
- 主程序中,订单、库存、日志模块是独立的,职责明确。如果以后需要改变日志记录的方法(如写入数据库而不是打印),只需要修改
-
可扩展性:
新增需求时比如“添加支付处理逻辑”,可以通过新增独立类实现,而不会影响现有代码。
在公司组织架构中的借鉴意义
高内聚低耦合虽然是软件设计领域的一个设计原则,但这一理念同样可以在公司管理和组织架构设计中有启发和借鉴意义。
-
高内聚:
- 明确职能: 在组织架构中,每个部门或团队应有明确的职能和专注点。这类似于一个软件模块的高内聚,将相关任务或功能集中在一起,减少跨部门的混淆和冗余。
- 专业性提升: 专注于特定功能的团队更能提高专业性和效率,因为他们能够深入探索特定领域,并积累专业知识。
-
低耦合:
- 灵活性: 部门之间的低耦合意味着各个团队可以自主运作而不依赖于其他团队的输入。这提升了灵活性,使得组织能够快速响应变化。
- 减少沟通成本: 通过减少部门之间的过度依赖关系,可以降低沟通成本和复杂性,提高决策速度。
实例
示例1:科技公司产品开发
一家科技公司可以通过高内聚低耦合的理念构建其产品开发团队。产品经理、设计师、开发人员和测试人员组成一个高度内聚的产品开发小组,专注于产品的设计、开发和测试。与此同时,这些小组与市场营销、客户支持等其他部门保持低耦合,使得开发团队能够快速响应市场需求,迭代和完善产品,而不被其他部门的流程所束缚。
示例2:地区分支机构管理
在一个国际企业中,各地区的分支机构可以实现高内聚,通过专注于区域市场的需求和特点来提升整体运营效率。同时,总部和各分支机构之间保持低耦合,使得各分支机构能够根据当地市场条件自主制定和调整策略,而不是依赖总部的统一指令。这种架构允许公司快速适应不同地区的市场变化。
总体而言,高内聚低耦合的理念在组织管理中鼓励明确分工和主动权的下放,帮助企业在快速变化的环境中保持适应性和创新能力。
总结:
本文总结了“高内聚、低耦合”的概念,总的来说“高内聚、低耦合”就是构建独立、单一职责模块的艺术,目的是让它们更容易维护和扩展。在实际开发中,拆分类和职责时掌握适度的平衡非常重要,既不要过度拆分(导致代码碎片化),也不要过度集中化(导致臃肿)。