我的初衷:我想学习AI。具体的方向是这样的:原本传统的平台业务去对接智能体。比如发票业务,发票的开具、审核、计税、回款等。根据用户在业务系统前台界面输入若干提示词 或者 语音输入简短语音信息,可以通过智能体给出需要处理的逻辑或者要调用的接口或服务来对接系统内置的各种服务和接口。
学习背景:
希望通过学习AI,特别是智能体(Agent)的开发,将传统平台业务(如发票开具、审核、计税、回款等)与智能交互结合,通过用户输入提示词或语音,自动触发相应的业务逻辑、接口或服务。这是一个非常有前景的方向,结合了自然语言处理(NLP)、智能体架构和系统集成。以下是一个系统化的学习和实施建议,尽量简洁且实用,涵盖技术栈、学习路径和实现思路。
1. 明确核心技术方向
我的需求主要涉及以下AI和相关技术领域:
-
自然语言处理(NLP):理解用户输入的提示词或语音,解析意图。
-
语音识别(ASR)与语音合成(TTS):处理语音输入和可能的语音反馈。
-
智能体(Agent)开发:构建能够根据用户意图调用业务逻辑或接口的智能体。
-
系统集成:将智能体与现有业务系统的服务、接口对接。
-
业务流程自动化(RPA+AI):将AI与规则引擎结合,处理发票相关业务逻辑。
2、短期目标:搭建一个简单的意图识别模型
短期目标:用Hugging Face的BERT或Rasa搭建一个简单的意图识别模型,通过一个针对发票业务场景的例子说明它的具体效果。清晰展示意图识别模型的作用、效果,并提供简化的实现思路。

如图示,经斟酌,选用Rasa。
- 意图识别模型的作用
意图识别模型的目的是从用户输入的自然语言(文本或转录后的语音)中,识别出用户的意图(Intent)和关键信息(Entities),从而触发相应的业务逻辑或API调用。在你的发票业务场景中,模型需要:
-
识别意图:例如,用户想“开具发票”“查询回款”还是“审核发票”。
-
提取实体:例如,金额、税率、发票类型、收款方等关键信息。
-
效果:将用户的模糊输入转化为结构化的指令,供后续系统处理。
预期效果:
-
用户输入:“开一张1000元的发票,税率13%。”
-
模型输出:
-
意图:create_invoice(开具发票)
-
实体:amount=1000, tax_rate=13%
-
-
后续:系统根据输出调用开票API,完成业务操作。

基本步骤
-
安装和初始化 Rasa 项目:设置开发环境,创建 Rasa 项目。
-
配置意图和训练数据:定义“开票”和“查询”意图,添加训练数据。
-
训练 Rasa 模型:训练意图识别模型,测试效果。
-
添加自定义动作:实现模拟 API 调用,处理“开票”和“查询”逻辑。
-
测试端到端流程:用 Rasa Shell 测试输入和 API 调用。
-
(可选)扩展功能:支持多轮对话或语音输入。
- 意图识别模型和智能体的区别
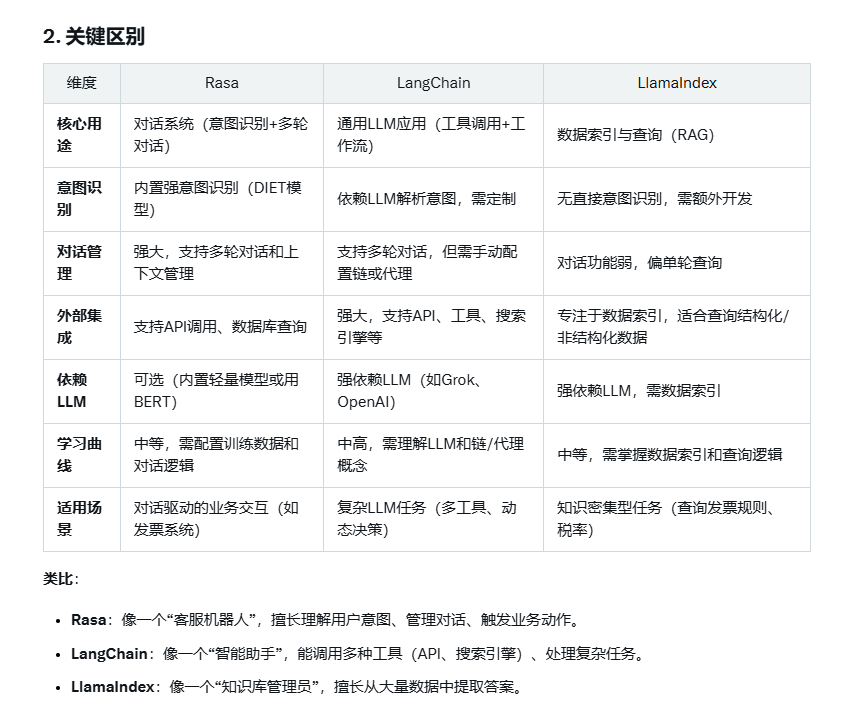
Rasa 与 LangChain 或 LlamaIndex 的相关定义与区别,调研如下:
核心定义与功能
-
Rasa:
-
定义:一个开源的对话系统框架,专注于构建基于意图识别和对话管理的智能体,支持多轮对话和业务逻辑集成。
-
核心功能:
-
意图识别与实体提取:解析用户输入(如“开1000元发票,税率13%” → 意图:create_invoice,实体:{amount: 1000, tax_rate: 0.13})。
-
对话管理:通过领域文件(domain.yml)和故事(stories.yml)处理多轮对话。
-
动作执行:支持自定义动作(如调用API、查询数据库)。
-
技术栈:内置轻量级NLP模型(DIET)或可集成BERT等,支持Python开发。
-
-
特点:
-
专注于对话系统,适合快速搭建端到端的交互式智能体。
-
自带意图识别和对话管理,开箱即用。
-
需手动配置训练数据(如nlu.yml)和对话逻辑。
-
-
-
LangChain:
-
定义:一个开源的大模型应用开发框架,用于构建基于大型语言模型(LLM)的智能体,强调与外部工具、记忆和数据源的集成。
-
核心功能:
-
LLM集成:连接大模型(如Grok、LLaMA、OpenAI)处理复杂语言任务。
-
工具调用:支持调用API、数据库、搜索引擎等(如调用发票API)。
-
记忆管理:维护对话上下文,适合多轮交互。
-
链式工作流:通过“链”(Chains)或“代理”(Agents)组合语言理解和动作。
-
-
特点:
-
高度灵活,适合与大模型结合,处理复杂任务。
-
依赖外部LLM,需API密钥或本地模型。
-
更通用,不局限于对话系统,可用于文档分析、知识库查询等。
-
-
-
LlamaIndex:
-
定义:一个开源的数据索引与查询框架,专注于将大模型与外部数据(如文档、数据库)结合,适合知识密集型任务。
-
核心功能:
-
数据索引:将业务数据(如发票规则、税率表)索引为向量,供LLM高效查询。
-
查询引擎:基于用户输入,从索引数据中检索答案或触发动作。
-
LLM集成:类似LangChain,连接大模型处理语言任务。
-
-
特点:
-
专注于数据增强生成(RAG,Retrieval-Augmented Generation),适合需要查询业务数据的场景。
-
对话功能较弱,主要用于单轮查询或知识提取。
-
需与LLM结合,依赖外部模型。
-
-


LangChain 的本质
-
LangChain 是什么:
-
LangChain 是一个 Python/JavaScript 框架,旨在简化基于 LLM 的应用开发。
-
核心功能:
-
连接 LLM:通过 API 或本地模型调用大模型(如 Grok、LLaMA、GPT-4)处理语言任务。
-
工具集成:支持调用外部工具(如 API、数据库、搜索引擎)。
-
记忆管理:维护对话上下文,支持多轮交互。
-
工作流管理:通过“链”(Chains)或“代理”(Agents)组织复杂的任务流程。
-
-
关键点:LangChain 本身不包含语言处理能力,依赖外部 LLM 提供语言理解和生成能力。
-
-
是否需要对接大模型 API:
-
是的,LangChain 的核心语言处理功能依赖外部大模型。你需要:
-
通过 API 调用:例如,连接 OpenAI 的 GPT-4 API、xAI 的 Grok API(需 API 密钥)或 Google 的 Gemini API。
-
本地部署模型:运行开源模型(如 LLaMA、Mistral)在本地服务器,但需要较高算力(GPU)。
-
-
如果不配置 LLM,LangChain 无法独立处理语言任务(如解析“开1000元发票,税率13%”)。
-
2. “小模型AI”(Rasa) vs “大模型AI” (LangChain)的理解
-
Rasa(小模型AI):
-
Rasa 的默认模型(DIET)是轻量级,适合资源有限的环境或快速开发。
-
但它可以集成大模型(如 BERT 或 Grok),所以不完全局限于“小模型”。
-
优点:训练快、部署简单、数据需求低,适合你的短期目标(快速搭建意图识别原型)。
-
局限:对复杂、模糊输入的处理能力不如大模型,需较多标注数据优化。
-
-
LangChain(大模型AI):
-
LangChain 通常依赖大模型(如 Grok),这些模型有更强的语言理解能力和泛化能力。
-
优点:能处理非结构化输入、支持复杂逻辑、集成多种工具,适合你的中期目标(构建复杂智能体)。
-
局限:依赖外部 LLM,计算成本高,配置复杂,初期上手门槛较高。
-
类比:
-
Rasa 像一个“轻量级机器人”,擅长处理特定任务(意图识别、对话管理),用小模型快速完成标准化工作。
-
LangChain 像一个“全能助手”,借助大模型处理复杂、灵活的任务,但需要更多资源和配置。
3、中期目标:明确初阶的学习及操作路径
-
识别意图:处理用户输入,如“开具一张1000元的发票,税率13%”(意图:create_invoice)和“查询发票编号12345”(意图:query_invoice)。
-
提取实体:如金额(amount)、税率(tax_rate)、发票编号(invoice_number)。
-
调用API:通过自定义动作对接模拟API,完成开票或查询。
-
后续扩展:支持语音输入(集成语音识别API,如讯飞)。