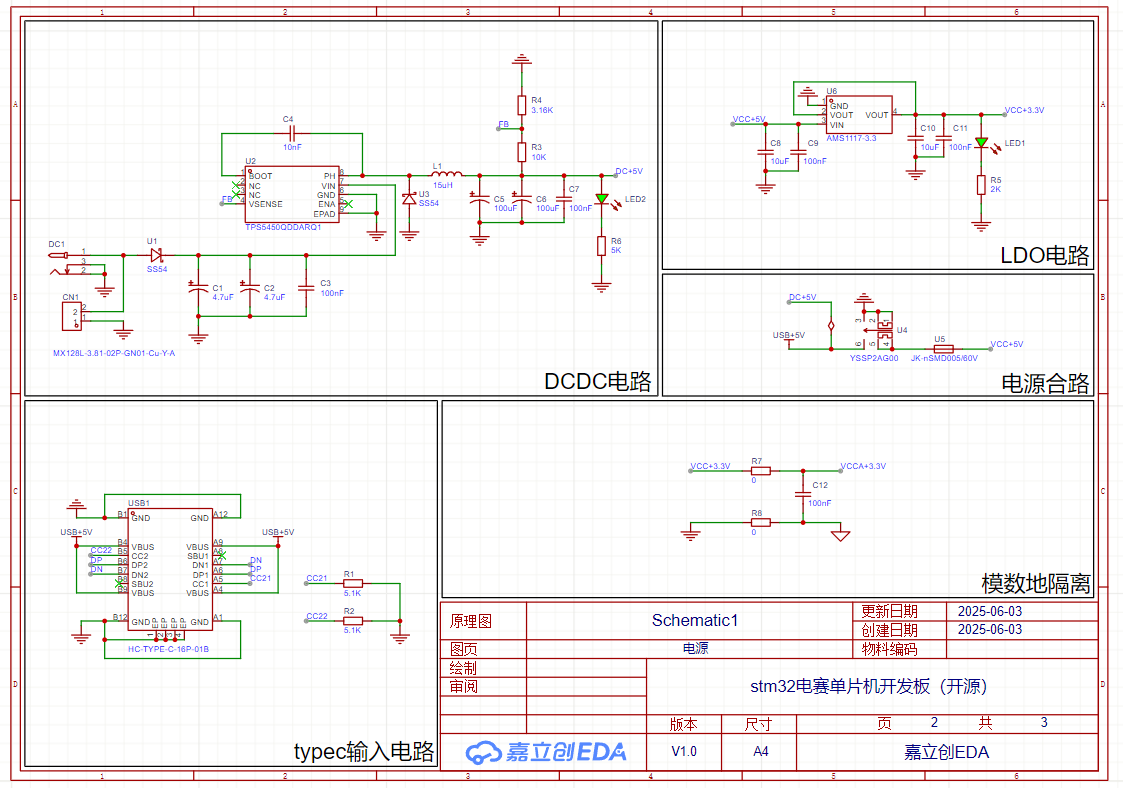
一、重复前缀:串操作的 “循环加速器”
如果你写过汇编代码,一定遇到过需要重复处理大量数据的场景:
- 复制 1000 字节的内存块
- 比较两个长达 200 字符的字符串
- 在缓冲区中搜索特定的特征值
手动用loop指令编写循环?代码冗长不说,效率还低 —— 因为 CPU 对rep前缀有专门的硬件优化。
x86 提供了 3 种重复前缀,它们是串操作指令的 “循环加速器”,能让数据批量处理变得又快又简单:
本文需要运用的知识(需要详细了解可点击对应的点):
- Flags寄存器
- 串操作指令
二、无条件循环王者:REP(Repeat)
2.1 核心功能与 “无脑循环” 逻辑
REP的英文名是 “Repeat”,顾名思义:无条件重复执行后续的串操作指令,直到计数器CX归零。
它就像一个 “死循环”,只要CX不为 0,就一直干活,典型场景包括:
- 内存复制(
MOVSB/MOVSW) - 内存填充(
STOSB/STOSW) - I/O 批量传输(
INSB/OUTSB)
2.2 执行流程可视化
用伪代码表示rep movsb的执行过程:
初始化:CX=重复次数, DF=方向, SI=源地址, DI=目标地址
循环开始: while (CX > 0) { 复制DS:SI → ES:DI (1字节/字/双字) SI += 步长(DF=0时+1/+2/+4,DF=1时-1/-2/-4) DI += 步长 CX -= 1 }
循环结束
流程图:
2.3 必知必会的三个关键点
-
位数限制:
- 16 位模式:使用
CX(16 位),最大重复 65535 次 - 32 位模式:使用
ECX(32 位),前缀变为REP(自动扩展) - 64 位模式:使用
RCX(64 位),但传统 BIOS 引导程序常用 16 位模式
- 16 位模式:使用
-
方向标志
DF:- 必须提前用
cld(DF=0,地址递增)或std(DF=1,地址递减)设置 - 例:复制字符串时用
cld,从低地址向高地址复制;若反向复制(如重叠内存块),用std
- 必须提前用
-
段寄存器配置:
- 源地址固定为
DS:SI,目标地址固定为ES:DI - 若数据段和目标段相同(如在同一段内复制),需手动设置
es = ds:mov ax, ds mov es, ax ; 确保ES=DS
- 源地址固定为
2.4 实战:用REP MOVSB复制 100 字节
[org 0x7c00] ; 引导扇区加载地址(16位实模式)
start: ; 1. 初始化段寄存器 mov ax, 0x07C0 mov ds, ax ; 数据段=代码段(引导扇区默认) mov es, ax ; 目标段=数据段(同一段内复制) ; 2. 设置参数 mov si, source_buffer ; 源地址:0x7C00 + source_buffer偏移 mov di, dest_buffer ; 目标地址 mov cx, 100 ; 复制100字节 cld ; 地址递增(SI/DI每次+1) ; 3. 执行批量复制 rep movsb ; 自动循环100次,每次复制1字节 jmp $ ; 卡死在这里,方便观察结果 source_buffer: db 0x55, 0xaa, 0x00 ; 示例数据(前3字节为引导标志) times 97 db 0x00 ; 补满100字节 dest_buffer: times 100 db 0x00 ; 目标缓冲区(初始化为0) ; 引导扇区填充 times 510-($-$$) db 0 db 0x55, 0xaa ; 有效引导扇区标志
三、相等时循环:REPZ/REPE(双胞胎指令)(或 REPE,Repeat While Zero/Equal)(-->>标志位寄存器)
3.1 “找不同” 神器:只在相等时继续
REPZ和REPE是完全等价的指令(Z代表 Zero,E代表 Equal),功能是:
当CX≠0且当前操作结果 “相等”(ZF=1)时,继续重复执行串操作指令。
一旦出现 “不相等”(ZF=0)或CX=0,立即停止循环。
典型场景:字符串比较(找到第一个不相等的字符位置)。
3.2 标志位魔法:ZF 如何控制循环
以REPE CMPSB为例(比较两个字节是否相等):
- 第一次执行
CMPSB:比较DS:SI和ES:DI的字节 - 若相等(ZF=1)且
CX>0:SI/DI移动,CX-1,继续循环 - 若不等(ZF=0):立即终止循环,此时
SI/DI停留在第一个不等的位置
3.3 循环结束后的 “状态密码”
- 若
ZF=1且CX=0:所有比较的字节都相等(字符串完全相同) - 若
ZF=0:找到了第一个不相等的字节,SI/DI指向该位置的下一个地址 - 易错点:
CX存储的是剩余次数,实际执行次数 = 初始CX- 最终CX
3.4 实战:用REPE CMPSB判断字符串是否全等
; 比较string1和string2是否完全相同(区分大小写)
mov si, string1
mov di, string2
mov cx, 20 ; 假设最长20字符
cld
repe cmpsb ; 相等时继续比较 jz full_match ; ZF=1且CX=0 → 完全相同
; 否则,ZF=0 → 找到第一个不等的位置
; 此时SI指向string1的不等字符,DI指向string2的不等字符 full_match: ; 执行字符串相等的逻辑
四、不等时循环:REPNZ/REPNE(反逻辑搭档)(或 REPNE,Repeat While Not Zero/Not Equal)
4.1 “找相同” 专家:只在不等时继续
REPNZ和REPNE也是等价指令(NZ代表 Not Zero,NE代表 Not Equal),功能是:
当CX≠0且当前操作结果 “不相等”(ZF=0)时,继续重复执行串操作指令。
一旦出现 “相等”(ZF=1)或CX=0,立即停止循环。
典型场景:字符串搜索(找到第一个匹配的字符位置)。
4.2 与REPZ的灵魂对比表
| 特性 | REPZ/REPE | REPNZ/REPNE |
|---|---|---|
| 重复条件 | ZF=1 且 CX≠0 | ZF=0 且 CX≠0 |
| 目标 | 寻找第一个不相等的位置 | 寻找第一个相等的位置 |
| 适用场景 | 字符串比较(找不同) | 字符串搜索(找相同) |
| 等价关系 | 完全等价(别名) | 完全等价(别名) |
4.3 避坑指南:SCASB后的地址 “偏移”
当使用REPNZ SCASB搜索字符时:
- 每次
SCASB会先比较AL与ES:DI,再根据DF移动DI - 若找到匹配字符(ZF=1),
DI已经指向下一个字符 - 所以需要手动
dec di,让DI回到匹配字符的地址:assembly
repnz scasb ; 未找到时循环 jz found_char dec di ; 修正DI到匹配字符的位置
4.4 实战:用REPNZ SCASB定位第一个空格
mov di, buffer ; 搜索缓冲区
mov al, 0x20 ; 空格的ASCII码
mov cx, 100 ; 最多搜索100字节
cld
repnz scasb ; 未找到空格时继续 jz space_found ; ZF=1 → 找到空格
; 否则,CX=0 → 未找到 space_found: dec di ; DI回退到空格的地址 ; 此处DI即为空格的位置
五、终极对比表:3 分钟吃透所有细节
| 前缀 | 全称 | 重复条件 | 适用指令 | 核心作用 | 结束时 ZF=1 含义 |
|---|---|---|---|---|---|
REP | Repeat | CX≠0 | MOVS/STOS/INS/OUTS | 无条件批量操作 | 无(不依赖 ZF) |
REPZ | Repeat While Zero | CX≠0 且 ZF=1 | CMPS/SCAS | 相等时继续(找第一个不等) | 所有操作都相等(CX=0) |
REPE | Repeat While Equal | 同上 | 同上 | 别名,功能完全相同 | 同上 |
REPNZ | Repeat While Not Zero | CX≠0 且 ZF=0 | 同上 | 不等时继续(找第一个相等) | 找到相等项(CX 可能非零) |
REPNE | Repeat While Not Equal | 同上 | 同上 | 别名,功能完全相同 | 同上 |
六、常见问题与反套路技巧
Q1:为什么REPZ和REPE是两个名字?
- 历史原因:早期 x86 架构中,
REPE用于CMPS(比较相等时重复),REPZ用于SCAS(扫描零值时重复),后来统一为等价指令。
Q2:如何计算重复次数?
- 字节操作(如
MOVSB):CX=字节数 - 字操作(如
MOVSW):CX=字节数÷2 - 例:复制 26 字节的字符串(字符 + 属性各 13 字节),
movsw需要cx=13。
Q3:忘记设置DF会怎样?
DF的初始值是 “随机的”(由上一条影响标志位的指令决定),可能导致SI/DI向反方向移动,数据越界或覆盖关键区域。
Q4:32 位模式下前缀会变化吗?
- 指令格式不变,但计数器变为
ECX,且MOVS等指令支持双字操作(MOVSD),步长变为 4 字节。
七、结语:从 “会用” 到 “精通” 的进阶之路
重复前缀是 x86 汇编中 “用对了省时省力,用错了 Debug 到崩溃” 的关键技术。掌握它们的核心:
- 牢记条件:
REP无脑循环,REPZ找不等,REPNZ找相等 - 检查三要素:
CX次数、DF方向、DS/ES段寄存器 - 善用标志位:循环结束后通过
ZF和CX判断结果
下次遇到批量数据处理时,试试用重复前缀代替手动loop—— 你会发现汇编代码可以既高效又优雅。
如果还有疑问,欢迎在评论区留言,我们一起拆解更多汇编 “黑魔法”!