引言
人工智能(AI)——一个熟悉又神秘的词汇。我们常听说它可以生成诗歌、编写代码、创作艺术,甚至回答各种问题。然而,当你想亲手实现一个“AI 模型”时,却可能感到无从下手。这篇教程正是为你准备的,将带你从零开始,逐步掌握从“AI 新手”到“能够搭建 AI 模型”的核心技能。
一、AI 的基本概念
1.什么是 AI 模型?
AI 模型是通过训练得到的一种程序,能够利用海量数据学习规律,并在此基础上完成各种任务。它的工作原理就像教一个孩子认水果:通过反复观察图片,孩子学会了“香蕉是黄色的”“苹果是圆的”,从而即使面对未见过的水果图片,也能做出正确判断。
AI模型:学生- 数据:课本
- 模型训练:学生做练习题
- 模型评估:学生考试
2.模型如何学习?
模型学习的核心步骤如下:
- 喂数据:提供大量样本,让模型了解世界的“规律”。
- 定义目标:明确任务,例如判断图片中是狗还是猫。
- 反复训练:模型不断调整其“参数”(类似脑回路),以优化对数据的理解。
- 测试与应用:在实际场景中运行模型,评估其效果。
3.AI 模型的类型
根据任务的性质,AI 模型主要分为以下几类:
- 分类模型:识别类别,例如垃圾邮件分类。
- 回归模型:预测数值,例如房价预测。
- 生成模型:创造内容,例如生成图像或文本。
4.什么是“大模型”?
“大模型”是相对于传统 AI 模型而言的,指的是参数规模大、学习能力强的模型。它们拥有强大的数据处理和推理能力,能够应对复杂任务。例如,GPT 系列模型不仅可以完成写作任务,还能实现编程、回答问题等多种功能,表现得更加“聪明”。
二、开发环境准备
在开始训练模型前,我们需要搭建一个“工作环境”,就像进入厨房前需要准备好工具一样。以下是必备的“厨具”:
1.安装 Python
Python 是 AI 开发的首选语言,因其简单易用的特点深受开发者喜爱。前往 Python 官网 下载最新版本并安装。安装时务必勾选 “Add Python to PATH” ,确保后续工具可以正常运行。
2.安装开发工具
推荐以下两款工具,便于你编写和调试代码:
Jupyter Notebook:一个交互式环境,适合初学者边调试边学习AI代码。VS Code:功能强大的代码编辑器,支持插件扩展,适合处理更复杂的项目。
3.安装必要的 Python 库
在终端运行以下命令,安装 AI 开发常用的库:
pip install numpy pandas matplotlib seaborn scikit-learn tensorflow这些库的用途:
NumPy:用于高效的数学计算和数组操作。Pandas:强大的数据处理与分析工具。Matplotlib/Seaborn:用于数据可视化,展示数据分布和关系。Scikit-learn:经典的机器学习库,支持分类、回归和聚类等任务。TensorFlow:深度学习框架,用于构建和训练神经网络。
三、数据是 AI 的“粮食”
1.数据集来源
在 AI 项目中,数据是模型的基础,就像粮食之于人类。没有数据,模型就无法“成长”。下面是常见的数据来源:
- 开源平台:如
Kaggle和UCI Machine Learning Repository提供了丰富的高质量数据集,适合各种任务和领域。 Sklearn自带数据集:内置数据集,如加利福尼亚房价、鸢尾花数据集,简单易用,适合初学者入门练习。
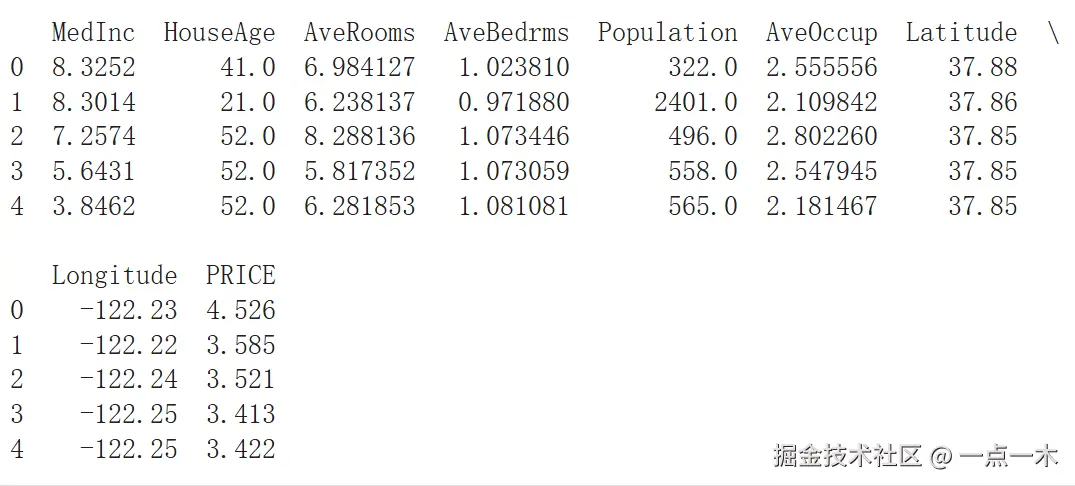
本教程选用:加利福尼亚房价数据集
from sklearn.datasets import fetch_california_housing
import pandas as pd
# 加载 California Housing 数据集
housing = fetch_california_housing()
data = pd.DataFrame(housing.data, columns=housing.feature_names)
data['PRICE'] = housing.target
# 查看数据
print(data.head())运行结果:
2.数据探索与可视化
在训练模型之前,数据探索是至关重要的一步。通过探索,我们可以了解数据的结构、分布特征以及特征间的关系,为后续的数据清洗和建模奠定基础。
(1) 数据基本信息
# 查看数据统计信息
print(data.describe())运行结果:
(2) 可视化分布
import matplotlib.pyplot as plt
import seaborn as sns
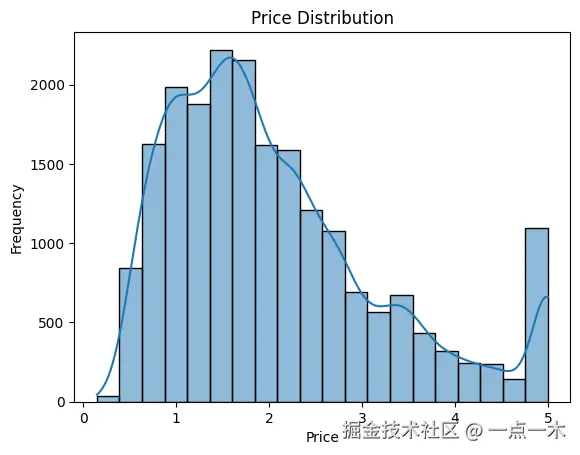
# 绘制房价分布图
sns.histplot(data['PRICE'], kde=True, bins=20)
plt.title("Price Distribution") # 房价分布
plt.xlabel("Price") # 房价
plt.ylabel("Frequency") # 频数
plt.show()运行结果:
(3) 相关性分析
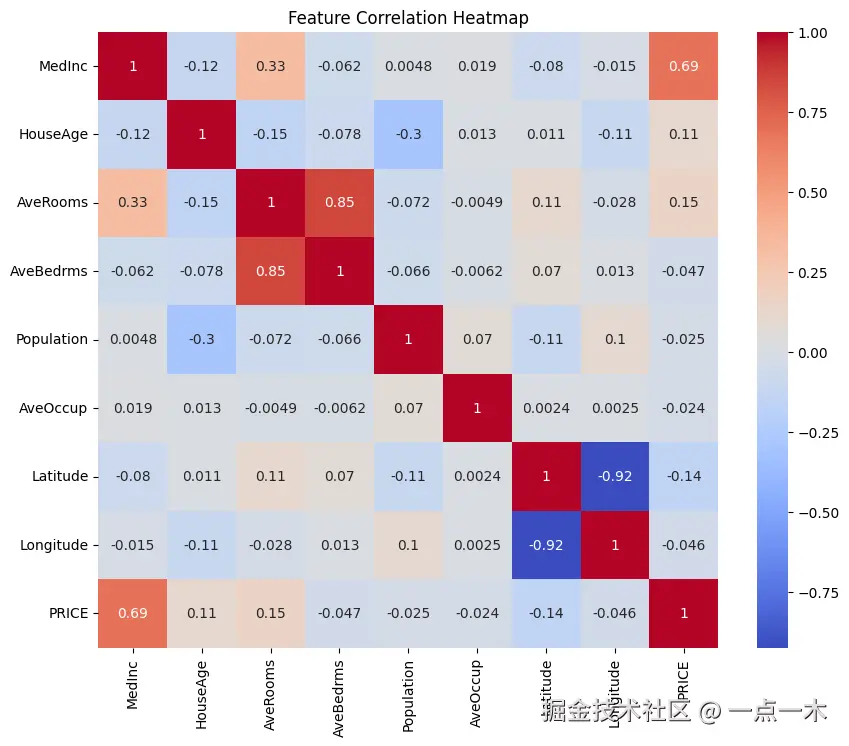
# 绘制特征相关性热力图
plt.figure(figsize=(10, 8))
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
plt.title("Feature Correlation Heatmap") # 特征相关性热力图
plt.show()运行结果:
3.数据清洗与预处理
在训练模型之前,数据需要经过“加工”,以便让模型更高效地学习。常见的清洗与预处理步骤包括检查缺失值、处理异常值和标准化特征。
(1) 检查缺失值
# 检查缺失值
print(data.isnull().sum())运行结果:
(2) 数据标准化
from sklearn.preprocessing import StandardScaler
# 特征标准化
scaler = StandardScaler()
features = data.drop('PRICE', axis=1)
target = data['PRICE']
features_scaled = scaler.fit_transform(features)四、训练一个简单模型
我们从最基础的线性回归模型开始。尽管它不是“大模型”,但简单直观,可以帮助你快速了解 AI 模型的训练流程,并打下坚实的基础。
1.划分训练集和测试集
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features_scaled, target, test_size=0.2, random_state=42)2.训练线性回归模型
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 初始化模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"均方误差(MSE):{mse}")
print(f"R2 分数:{r2}")运行结果:

3.模型效果解读
MSE(均方误差) :衡量预测值与真实值之间的平均偏差,值越小表示模型表现越好。R²分数:表示模型解释数据方差的比例,值越接近 1,说明模型拟合度越高。
恭喜你!🎉 你已经成功训练了第一个
AI模型!接下来,我们将进入深度学习的世界,训练更强大的“大模型”。
五、深度学习初探
在上一部分,我们学习了基础的线性回归模型。现在,让我们进入更强大的深度学习领域,训练一个多层神经网络,使模型更智能、更深刻。
1.什么是深度学习?
深度学习(Deep Learning)是基于“神经网络”的机器学习方法,特别擅长从复杂数据中提取特征并作出精准预测。
如果线性回归是“单核处理器”,那么深度学习就是“多核加速器”。它模拟人脑的神经元,用层层堆叠的“神经网络”来处理数据。换句话说,深度学习就是“开挂的人脑仿真”。
- 输入层:接收数据(例如,图片的像素值)。
- 隐藏层:逐步提取数据特征,就像拆解复杂问题成多个小问题。
- 输出层:输出结果(例如,判断图片中是猫还是狗)。
2.构建一个简单神经网络
我们将使用 TensorFlow 搭建一个简单的两层神经网络来预测房价。以下代码展示了如何构建和训练这个神经网络:
(1) 引入 TensorFlow 并定义网络结构
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input
# 定义模型
nn_model = Sequential([Input(shape=(X_train.shape[1],)), # 显式定义输入层Dense(64, activation='relu'), # 第一层隐藏层Dense(32, activation='relu'), # 第二层隐藏层Dense(1) # 输出层,预测房价
])
# 编译模型
nn_model.compile(optimizer='adam', loss='mse', metrics=['mae'])
# 打印模型结构
nn_model.summary()运行结果:
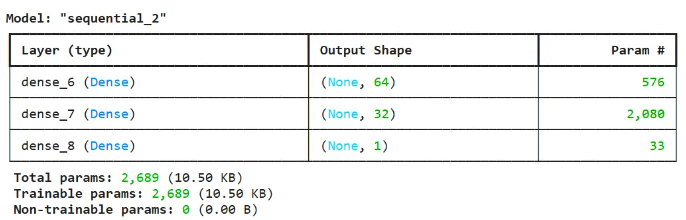
-
Dense:神经网络中的全连接层,64表示有 64 个神经元。activation='relu':激活函数,用于引入非线性,使模型能够学习复杂的模式。
-
adam:一种优化算法,可以高效地调整模型参数以最小化损失函数,从而更快地收敛到最佳解。 -
mse:均方误差(Mean Squared Error),一种用于回归任务的损失函数,衡量预测值与真实值之间的平均平方误差,值越小表示模型预测越准确。
(2) 训练神经网络
# 开始训练
history = nn_model.fit(X_train, y_train,epochs=100, # 训练100轮batch_size=32, # 每次使用32条数据validation_split=0.2, # 20%数据用于验证verbose=1 # 显示训练进度
)epochs:模型在训练数据上“学一遍”的次数,多次学习可以让模型表现更好。batch_size:模型一次处理的数据量,32是比较常用的值。validation_split:用一部分训练数据来测试模型的表现,确保模型没有只“记住”数据,而是能学会预测新数据。
运行结果:

3.测试模型性能
训练完成后,用测试集评估模型:
# 模型评估
test_loss, test_mae = nn_model.evaluate(X_test, y_test)
print(f"测试集均方误差(MSE):{test_loss}")
print(f"测试集平均绝对误差(MAE):{test_mae}")运行结果:

用模型预测房价
# 用测试集数据预测
predictions = nn_model.predict(X_test)
# 显示部分预测结果
for i in range(5):print(f"预测值:{predictions[i][0]:.2f}, 实际值:{y_test.iloc[i]:.2f}")运行结果:
预测值:0.11, 实际值:0.48
预测值:0.02, 实际值:0.46
预测值:0.12, 实际值:5.00
预测值:0.18, 实际值:2.19
预测值:0.01, 实际值:2.78解读预测结果:
- 如果预测值与实际值接近,说明模型的性能较好,能够准确地进行预测。
- 如果预测值与实际值相差较大,说明模型的预测能力不足。这种情况下,可能需要调整模型参数、改进数据预处理步骤,或者使用更复杂的模型来提升预测效果。
4.可视化训练过程
训练过程中,我们可以绘制损失值(Loss)和评估指标(MAE)的变化趋势,帮助我们判断模型是否收敛。
import matplotlib.pyplot as plt
# 绘制训练和验证损失
plt.plot(history.history['loss'], label='Training Loss') # 训练损失
plt.plot(history.history['val_loss'], label='Validation Loss') # 验证损失
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Loss Changes During Training') # 训练过程中的损失变化
plt.show()运行结果:
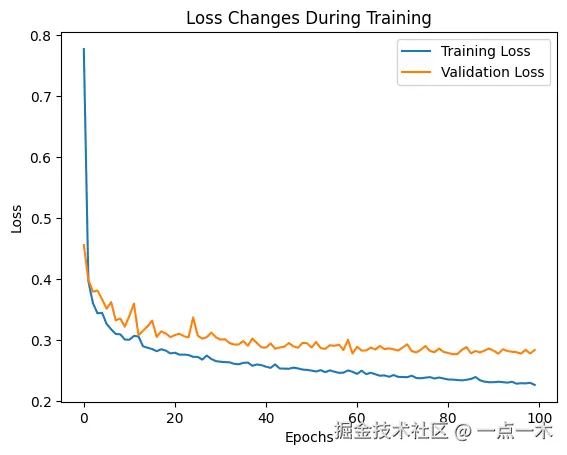
图表分析:
- 模型表现良好:如果训练损失逐渐减小,且验证损失稳定在较低的水平,说明模型学习效果较好,性能良好。
- 可能存在过拟合:如果训练损失持续减小,而验证损失明显增大,可能表明模型出现过拟合,即模型过度拟合训练数据,对新数据的泛化能力较差。
六、模型优化
在完成基础训练后,我们可以通过以下方法进一步提升模型性能。
1.什么是过拟合和欠拟合?
- 过拟合:模型在训练集上表现很好,但在测试集上效果较差,就像考试时只会做练习册上的题,对新题束手无策。
- 欠拟合:模型在训练集上的表现也不好,说明它的学习能力不足,连基本规律都没掌握。
解决方案:
- 正则化:在模型中添加约束(如
L1或L2正则化),限制模型的复杂度,防止过度拟合训练数据。 - 数据增强:通过对现有数据的变换(如翻转、旋转、缩放等)生成更多样本,提升模型的泛化能力。
- 早停法:监控验证集的损失,一旦验证损失开始升高,及时停止训练,避免过拟合。
2.添加正则化
在模型中添加正则化方法可以有效防止过拟合。例如:
Dropout:通过随机“关闭”一部分神经元(让它们暂时不参与计算),减少神经元间的依赖,从而提升模型的泛化能力。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Input
nn_model = Sequential([Input(shape=(X_train.shape[1],)), # 显式定义输入形状Dense(64, activation='relu'),Dropout(0.5), # 随机丢弃50%的神经元Dense(32, activation='relu'),Dense(1) # 输出层
])3.调整学习率
学习率是优化器中控制模型参数更新步伐的关键参数。
- 学习率过高:可能导致模型无法收敛,甚至出现震荡,无法找到最优解。
- 学习率过低:可能使模型收敛速度过慢,延长训练时间。
from tensorflow.keras.optimizers import Adam
# 使用较小的学习率
nn_model.compile(optimizer=Adam(learning_rate=0.001), loss='mse', metrics=['mae'])七、构建一个“简易大模型”
在这一部分,我们将基于深度学习架构,构建一个更复杂的模型,同时应用优化策略以提升性能。
1.增加网络深度
通过增加隐藏层的数量和每层的神经元规模,模型的表达能力会显著增强,从而更好地捕捉复杂的模式和特征关系。但需要注意,增加网络深度的同时可能导致过拟合,因此需要搭配正则化等策略。
nn_model = Sequential([Input(shape=(X_train.shape[1],)), # 明确定义输入形状Dense(128, activation='relu'), # 第一隐藏层Dense(64, activation='relu'), # 第二隐藏层Dense(32, activation='relu'), # 第三隐藏层Dense(1) # 输出层
])2.使用更多数据
当数据量有限时,模型可能难以学习到充分的特征。以下是两种有效的解决方法:
- 生成数据:通过数据增强技术(如旋转、翻转、缩放等)对现有数据进行变换,生成更多样本,从而提升模型的泛化能力。
- 迁移学习:利用在大规模数据集上预训练的模型,将其学习到的特征迁移到当前任务中,特别适用于小数据集的复杂问题。
3.增加模型参数与层数
“大模型”之所以强大,其核心在于拥有更多的神经元、更复杂的网络结构和更强的表达能力。增加模型的层数和神经元数量可以有效提升模型性能,但同时也需要注意防止过拟合。
以下是一个包含三层隐藏层的神经网络示例:
# 构建更深的神经网络
nn_model = Sequential([Input(shape=(X_train.shape[1],)), # 使用 Input 层显式定义输入形状Dense(256, activation='relu'), # 第一隐藏层,256个神经元Dense(128, activation='relu'), # 第二隐藏层Dense(64, activation='relu'), # 第三隐藏层Dense(1) # 输出层
])
# 编译模型
nn_model.compile(optimizer=Adam(learning_rate=0.0001), loss='mse', metrics=['mae'])
# 训练模型
history = nn_model.fit(X_train, y_train,epochs=200, # 增加训练轮数batch_size=64, # 调整批量大小validation_split=0.2, # 20%数据用于验证verbose=1 # 显示训练过程
)4.监控训练过程
通过使用 EarlyStopping 回调函数,模型可以在验证损失不再降低时自动停止训练,从而有效防止过拟合并节省训练时间。您可以设置 patience 参数,允许验证损失在指定的轮次内未改善时终止训练。
from tensorflow.keras.callbacks import EarlyStopping
# 添加早停法
early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
history = nn_model.fit(X_train, y_train,epochs=200,batch_size=64,validation_split=0.2,callbacks=[early_stop] # 应用早停
)5.数据增强与扩展
当数据量不足以支撑复杂模型时,数据增强是一种有效的策略,可以通过对原始数据进行变换来生成更多样本,从而提高模型的泛化能力。
(1) 什么是数据增强?
数据增强是对原始数据进行各种变换(如旋转、缩放、裁剪、翻转等),以人为方式扩大数据集规模。它不仅可以提升模型在训练数据上的表现,还能增强模型对未见数据的鲁棒性。
(2) 数据增强示例
以下示例展示了如何在图像分类任务中使用 TensorFlow 的数据增强工具:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 定义数据增强器
datagen = ImageDataGenerator(rotation_range=20, # 随机旋转角度width_shift_range=0.1, # 水平平移height_shift_range=0.1, # 垂直平移horizontal_flip=True # 水平翻转
)
# 对训练数据应用数据增强
datagen.fit(X_train)非图像数据增强
对于非图像数据(如表格或时间序列数据),可以采用其他数据增强方法,例如:
- 添加随机噪声:在原始数据上加入少量随机噪声,模拟更多样本。
- 随机变换:对原始数据的特征进行随机缩放、平移等操作。
# 添加随机噪声
def add_noise(data, noise_level=0.1):noise = noise_level * np.random.normal(size=data.shape)return data + noise
# 应用噪声增强
X_train_augmented = add_noise(X_train)6.模型训练性能加速:使用 GPU/TPU
深度学习模型的训练可能非常耗时,尤其是在处理“大模型”时。使用 GPU(图形处理器)或 TPU(张量处理器)可以显著加速训练过程。
(1) 确保安装CUDA 和 cuDNN
如果使用 NVIDIA 显卡,请确保安装以下工具:
CUDA Toolkit:支持GPU加速计算。cuDNN:深度学习专用的高效库,优化神经网络运算。
(2) 检查 GPU 是否可用
import tensorflow as tf
print("GPU 是否可用:", tf.config.list_physical_devices('GPU'))(3) 使用 Google Colab
如果你没有本地 GPU,可以使用 Google 提供的免费 Colab 环境进行训练:
- 打开
Google Colab。 - 点击顶部菜单中的 “
Runtime” (运行时),选择 “Change runtime type” (更改运行时类型)。 - 在硬件加速器中选择
GPU,然后保存设置。 - 直接运行你的代码,即可使用免费的
GPU算力进行训练!
提示:
Google Colab提供的GPU算力适合中小型模型训练,适用于快速实验或学习场景。
八、模型部署
训练好模型后,你可能会问:“如何让我的 AI 模型在真实场景中运行?” 模型部署 就是让模型从代码中走出来,变成实际可以使用的服务或工具。
1.保存与加载模型
TensorFlow 提供了简单的接口来保存模型,以便后续使用或部署。以下是保存和加载模型的示例:
# 保存模型
nn_model.save('my_ai_model')
# 加载模型
from tensorflow.keras.models import load_model
loaded_model = load_model('my_ai_model')2.使用 Flask 构建 API 服务
通过 Flask 框架,可以将模型部署为 API 服务,接收 HTTP 请求并实时返回预测结果。以下是具体的实现步骤:
(1) 创建 API 服务
使用 Flask 创建一个简单的服务,加载训练好的模型,处理用户输入并返回预测结果。
from flask import Flask, request, jsonify
import numpy as np
from tensorflow.keras.models import load_model
# 加载模型
model = load_model('my_ai_model')
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():data = request.jsonfeatures = np.array(data['features']).reshape(1, -1)
prediction = model.predict(features)# 返回预测结果return jsonify({'success': True,'prediction': float(prediction[0][0]) # 将预测值转换为浮点数返回})
if __name__ == '__main__':app.run(debug=True)(2) 测试 API
启动 Flask 服务后,可以使用 Postman 或其他 HTTP 客户端工具(如 curl 或浏览器扩展)来发送请求,验证 API 是否正常工作。
POST /predict
{"features": [0.1, -0.2, 0.5, 0.3, 0.7, -1.1, 0.4, 0.9, 1.0, -0.5, 0.8, -0.6, 0.3]
}返回示例:
{"success": true,"prediction": 24.56
}3.使用 Streamlit 构建可视化界面
Streamlit 是一个易用的 Python 工具,可以快速构建数据可视化应用,非常适合将机器学习模型部署为交互式界面,供用户实时输入和查看预测结果。
Streamlit 的优势
- 简单直观:无需前端开发知识,直接用
Python编写,几行代码即可实现完整应用。 - 快速开发:支持实时刷新和交互式组件,适合快速原型开发。
- 支持丰富功能:内置输入框、文件上传、图表绘制等多种组件,满足数据应用需求。
import streamlit as st
import numpy as np
from tensorflow.keras.models import load_model
# 加载模型
model = load_model('my_ai_model')
# 设置标题
st.title("House Price Prediction") # 房价预测模型
# 输入特征值
features = []
for i in range(13):features.append(st.number_input(f"Feature {i+1}"))
if st.button("Predict"):# 使用模型进行预测prediction = model.predict(np.array(features).reshape(1, -1))st.write(f"Predicted Price:{float(prediction[0][0]:,.2f)}")运行 Streamlit:
streamlit run app.py结语
通过本教程,你已经完成了从零开始构建 AI 模型的完整流程。我们从 AI 的基础概念入手,学习了如何准备数据、训练模型、优化性能,以及将模型部署为实际应用。这不仅让你掌握了机器学习的核心技能,也为你进入更广阔的 AI 世界奠定了基础。
这一过程中,你了解了如何选择合适的算法、解决实际问题,以及将 AI 融入应用场景。最重要的是,你体验了从构思到实现,再到部署的完整开发链路,这正是 AI 项目的精髓所在。
虽然教程内容只是冰山一角,但它已经为你打开了 AI 的大门。未来,你可以探索更复杂的模型、更大的数据集,或者将这些知识应用到真实场景中,创造属于你的 AI 作品。
学习 AI 是一个持续进步的过程,而今天,你已经迈出了第一步。未来,AI 的可能性无限,希望你在这条路上越走越远,用 AI 技术改变生活、创造价值!
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。