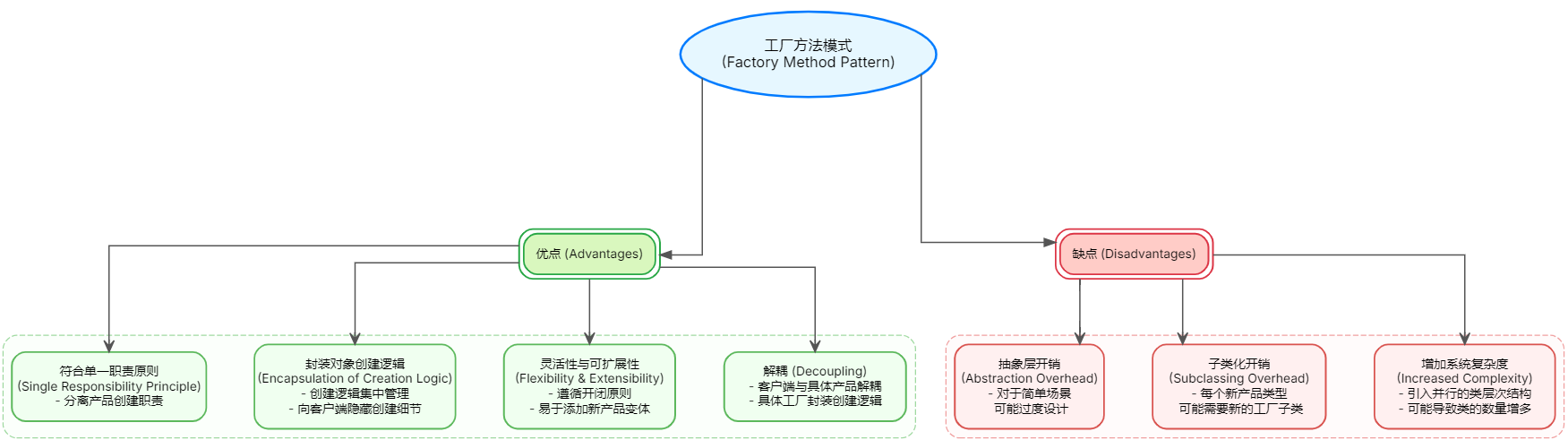
6.1 消息存储机制
日志分段(Log Segment)
Kafka的消息日志以分段(Segment)形式存储,每个Segment包含一个数据文件(.log)和两个索引文件(.index和.timeindex):
- 数据文件:按时间顺序存储消息的二进制内容。
- 偏移量索引文件:记录消息的Offset到物理位置的映射。
- 时间戳索引文件:记录时间戳到Offset的映射。
日志分段文件示例:
00000000000000000000.log
00000000000000000000.index
00000000000000000000.timeindex
00000000000000100000.log
00000000000000100000.index
00000000000000100000.timeindex
文件名前缀为该Segment的起始Offset。
磁盘顺序读写优化
Kafka利用操作系统的页缓存(Page Cache)和零拷贝(Zero Copy)技术提升性能:
- 页缓存:消息写入时先写入Page Cache,由操作系统异步刷盘,避免频繁IO。
- 零拷贝:Consumer消费消息时,数据直接从Page Cache传输到网络套接字,无需经过用户空间,减少数据拷贝次数。
数据删除策略
Kafka支持两种日志清理策略:
- 基于时间:删除超过
log.retention.hours的日志段。 - 基于大小:当日志总大小超过
log.retention.bytes时,删除最早的日志段。
清理流程由Log Cleaner线程后台执行,采用标记-清除算法:
// 伪代码:Log Cleaner工作流程
while (true) {// 选择需要清理的日志段LogSegment segment = selectSegmentToClean();// 创建清理后的临时日志段LogSegment cleanedSegment = new LogSegment();// 遍历原始日志段,保留最新版本的消息for (Message message : segment) {if (isLatestVersion(message)) {cleanedSegment.append(message);}}// 替换原始日志段replaceSegment(segment, cleanedSegment);
}
6.2 网络通信协议
Kafka自定义协议
Kafka客户端与Broker之间通过TCP协议通信,使用自定义二进制协议:
- 请求格式:包含请求头(Request Header)和请求体(Request Body)。
- 请求头:包含API Key(标识请求类型)、API Version、Correlation ID(用于匹配响应)等。
- 请求体:具体请求参数,如ProduceRequest、FetchRequest等。
- 响应格式:与请求类似,包含响应头和响应体。
TCP连接管理
- Producer连接:Producer通过
bootstrap.servers配置连接到任意Broker,获取集群元数据后,直接与目标Topic的Leader Partition所在Broker建立连接。 - Consumer连接:Consumer同样先获取元数据,然后根据分区分配结果,与对应Broker建立连接。
心跳机制
Consumer Group通过心跳机制维持与Coordinator的连接:
- 心跳线程:Consumer内部有一个专门的心跳线程,定期向Coordinator发送心跳请求。
- Session超时:若Coordinator在
session.timeout.ms(默认10秒)内未收到心跳,认为Consumer已下线,触发Rebalance。 - Poll间隔:Consumer必须在
max.poll.interval.ms(默认300秒)内调用poll()方法,否则也会触发Rebalance。
心跳机制源码关键部分:
// KafkaConsumer中的心跳线程
private class HeartbeatThread extends Thread {public void run() {while (!closed) {try {// 发送心跳sendHeartbeat();// 休眠heartbeat.interval.msThread.sleep(heartbeatIntervalMs);} catch (InterruptedException e) {// 处理中断}}}
}
6.3 源码导读
核心模块概述
Kafka源码主要分为以下模块:
- clients:客户端实现,包括Producer、Consumer、AdminClient等。
- core:Broker核心实现,包括请求处理、日志管理、副本同步等。
- streams:流处理框架实现。
- connect:数据集成工具实现。
- tools:命令行工具。
Producer启动流程
- 初始化阶段:
// KafkaProducer初始化流程 public KafkaProducer(Properties properties) {// 配置解析config = new ProducerConfig(properties);// 元数据管理器metadata = new Metadata(config.metadataMaxAgeMs());// 网络客户端client = new NetworkClient(...);// 记录累加器(消息缓冲区)accumulator = new RecordAccumulator(...);// 发送线程sender = new Sender(client, metadata, accumulator, ...);ioThread = new Thread(sender, "kafka-producer-network-thread");ioThread.start(); } - 消息发送阶段:
// 消息发送流程 public Future<RecordMetadata> send(ProducerRecord<K, V> record) {// 序列化键和值byte[] serializedKey = keySerializer.serialize(record.topic(), record.key());byte[] serializedValue = valueSerializer.serialize(record.topic(), record.value());// 确定分区int partition = partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);// 将消息添加到累加器RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback);// 如果批次已满,唤醒Sender线程发送if (result.batchIsFull || result.newBatchCreated) {this.sender.wakeup();}return result.future; }
Consumer元数据获取
Consumer启动时获取集群元数据的关键流程:
// 获取元数据的核心方法
private Cluster metadataFetch() {// 标记元数据需要更新metadata.requestUpdate();// 阻塞等待元数据更新完成long begin = time.milliseconds();long remainingWaitMs = metadataTimeout;do {// 发送元数据请求sendMetadataRequest();// 处理响应client.poll(remainingWaitMs, begin);// 检查元数据是否更新if (metadata.updateRequested()) {Cluster cluster = metadata.fetch();if (cluster != null)return cluster;}remainingWaitMs = metadataTimeout - (time.milliseconds() - begin);} while (remainingWaitMs > 0);throw new TimeoutException("Failed to update metadata after " + metadataTimeout + " ms.");
}
Broker请求处理
Broker处理客户端请求的核心类是KafkaApis,它通过多线程池实现请求的并发处理:
// KafkaApis处理请求的主循环
public void handle(RequestChannel.Request request) {try {switch (request.header.apiKey()) {case PRODUCE:handleProduceRequest(request);break;case FETCH:handleFetchRequest(request);break;case METADATA:handleMetadataRequest(request);break;// 其他请求类型处理default:request.responseChannel.sendResponse(new RequestChannel.Response(request, new ApiError(Errors.UNSUPPORTED_VERSION, "")));}} catch (Exception e) {// 异常处理}
}