Whole-body Humanoid Robot Locomotion with Human Reference
- 研究动机
- 解决方案
- 技术路线
- 基于AMP从人类参考运动中学习
- 人形机器人端到端强化学习
- 实验结果
Whole-body Humanoid Robot Locomotion with Human Reference
研究动机
- 传统机器人控制算法通常依赖对环境的准确建模,这在鲁棒性和通用性方面会带来重大挑战,尤其是在未知或动态变化的环境中,传统控制算法的性能可能会显著下降,限制了它们在更广泛的应用场景中的实用性。此外,对准确建模的依赖需要高水平的专业知识来构建和维护这些模型,增加了开发和调试的复杂性。
- 传统机器人控制算法在适应性、灵活性和用户友好性方面尽管表现出色,但在特定环境中的卓越性能也限制了它们的应用,促使研究人员探索替代方法以克服这些障碍,设计更智能和更具适应性的机器人控制策略。
解决方案
介绍了全新的人形机器人Adam,并提供新的方法和实验验证,用于人形机器人的学习、适应和优化,为人形机器人研究和开发开辟了一条新途径。
- 开发并详细描述了一种创新的仿生人形机器人 Adam,其四肢不仅活动范围接近人类,还在成本低廉和维护方便方面具有显著优势。
- 设计并验证新的全身模仿学习框架,用于人形机器人,该框架有效地解决了人形机器人强化学习训练中遇到的复杂奖励函数设置问题,大大减少Sim2Real差距,并提高人形机器人的学习能力和适应性。
技术路线
基于AMP从人类参考运动中学习
模仿学习框架基于AMP,其中判别器 D D D输出从智能体采样得到的状态转移与从参考演示采样得到的状态转移之间的相似度。为确保具有相似状态转移的机器人能够执行相似的运动风格,选择输入判别器的观测值至关重要。判别器观测值包含每个驱动关节的位置、速度以及人形机器人的双手和双脚的位置。在每个时间步中,从演示中采样状态转移并输入至判别器中,以获取专家预测巡视,从而使判别器能够区分它们。
L e x p e r t = E ( o t D , o t + 1 D ) ∼ D [ ( D ( o t D , o t + 1 D ) − 1 ) 2 ] \mathcal{L}_{expert}=\mathbb{E}_{(o_t^D,o_{t+1}^D)\sim \mathcal{D}}[(D(o_t^D,o_{t+1}^D)-1)^2] Lexpert=E(otD,ot+1D)∼D[(D(otD,ot+1D)−1)2]
从策略中采样的状态转移也同样计算:
L p o l i c y = E ( o t D , o t + 1 D ) ∼ π [ ( D ( o t D , o t + 1 D ) + 1 ) 2 ] \mathcal{L}_{policy}=\mathbb{E}_{(o_t^D,o_{t+1}^D)\sim \pi}[(D(o_t^D,o_{t+1}^D)+1)^2] Lpolicy=E(otD,ot+1D)∼π[(D(otD,ot+1D)+1)2]
对参考轨迹上的梯度进行惩罚以稳定训练,
L G P = E ( o t D , o t + 1 D ) ∼ π [ ∣ ∣ ▽ D ( o t D , o t + 1 D ) ∣ ∣ 2 ] \mathcal{L}_{GP}=\mathbb{E}_{(o_t^D,o_{t+1}^D)\sim \pi}[||\bigtriangledown \mathcal{D}(o_t^D,o_{t+1}^D)||^2] LGP=E(otD,ot+1D)∼π[∣∣▽D(otD,ot+1D)∣∣2]
总的AMP损失为:
L A M P = 1 2 L e x p e r t + 1 2 L p o l i c y + λ G P L G P \mathcal{L}_{AMP}=\frac{1}{2}\mathcal{L}_{expert}+\frac{1}{2}\mathcal{L}_{policy}+\lambda_{GP}\mathcal{L}_{GP} LAMP=21Lexpert+21Lpolicy+λGPLGP
AMP损失函数指导判别器对样本进行评分,对于真实的参考动作给出接近+1的分数,而对于由策略生成的动作则接近-1。策略的目标是生成足够逼真的动作,使判别器给出更高的分数,以此展示其接近模仿参考动作的能力。随后,策略训练中的模仿奖励公式表示为
r I = m a x [ 0 , 1 − 1 4 ( D ( o t D , o t + 1 D ) − 1 ) 2 ] r_{I}=max[0,1-\frac{1}{4}(D(o_t^D,o_{t+1}^D)-1)^2] rI=max[0,1−41(D(otD,ot+1D)−1)2]
人形机器人端到端强化学习
同时,参考运动中的运动方向通常仅限于局部坐标系。为了便于在世界坐标系下控制、生成更加自然的步伐,并在复杂地形上实现从仿真到现实的更有效过渡,我们引入了协调任务奖励。任务奖励由三部分组成:命令奖励、周期奖励和正则化奖励。命令奖励迫使机器人沿命令方向单独移动,其公式为
r c o m = ∑ λ i e x p ( − ω ( ∣ v d e s i − v t i ∣ ) ) , i ∈ ( x , y , y a w ) r_{com}=\sum \lambda_i exp(-\omega(|v_{des}^i-v_t^i|)),i\in(x,y,yaw) rcom=∑λiexp(−ω(∣vdesi−vti∣)),i∈(x,y,yaw)
为促进达到期望的步态性能,引入与模仿奖励相一致的周期性奖励。这种方法自然地促进了机器人保持稳定步态。然而,如果希望步态具有变异性,建议省略此奖励函数。本文通过摆动相(脚在空中移动)和支撑相(脚牢固地着地)来制定周期性奖励。每个周期性奖励项由系数 α i \alpha_i αi、相位指示符 I i ( ϕ ) I_i(\phi) Ii(ϕ)、相位奖励函数 V i ( s t ) V_i(s_t) Vi(st)组成, ϕ \phi ϕ表示周期时间, i i i表示相位是支撑相还是摆动相。摆动相和支撑相按顺序排列,并通过设定比例 ρ ∈ ( 0 , 1 ) \rho \in(0,1) ρ∈(0,1)共同覆盖整个周期时长。这种配置确保摆动相持续的时间相当于 ρ \rho ρ,紧接着是支撑相,其持续时间为 1 − ρ 1-\rho 1−ρ。单脚奖励如下所示:
r p e r = ∑ α i E [ I i ( ϕ ) ] V i ( s t ) r_{per}=\sum \alpha_i \mathbb{E}[I_i(\phi)]V_i(s_t) rper=∑αiE[Ii(ϕ)]Vi(st)
V s t a n c e ( s t ) = e x p ( − 10 F f 2 ) V_{stance}(s_t)=exp(-10F_f^2) Vstance(st)=exp(−10Ff2)
V s w i n g ( s t ) = e x p ( − 200 v f 2 ) V_{swing}(s_t)=exp(-200v_f^2) Vswing(st)=exp(−200vf2)
其中 F f F_f Ff是每个足部的正压力, v f v_f vf是每个足部的速度。为建模相位指示器 I i ( ϕ ) I_i(\phi) Ii(ϕ),使用Von Mises分布的数学期望。相位指示器如图所示。

相位指示器形式化为
Q 1 = I s t a n c e ( ϕ + θ l e f t ) Q_1=I_{stance}(\phi+\theta_{left}) Q1=Istance(ϕ+θleft)
Q 2 = I s t a n c e ( ϕ + θ r i g h t ) Q_2=I_{stance}(\phi+\theta_{right}) Q2=Istance(ϕ+θright)
其中 θ l e f t \theta_{left} θleft和 θ r i g h t \theta_{right} θright是左腿和右腿在周期时间中的偏移。为获得更自然的步伐风格,计算脚速度、高度差以及摆动相位中的对称性的奖励。脚速度跟踪奖励形式化为
q i = c l i p ( ϕ ρ − 0.5 , 0 , 1 ) q^i=clip(\frac{\phi}{\rho}-0.5,0,1) qi=clip(ρϕ−0.5,0,1)
r ( s t ) = 16 ( q i v f i ) 2 , 0 ≤ q i ≤ 0.6 r(s_t)=16(q^iv_f^i)^2,0\le q_i \le0.6 r(st)=16(qivfi)2,0≤qi≤0.6
脚速跟踪奖励鼓励机器人在摆动阶段进行更高的脚速。高度差奖励为
q i = ϕ ρ q^i=\frac{\phi}{\rho} qi=ρϕ
δ h = h f i − h f − i − 0.02 \delta h=h_f^i - h_f^{-i}-0.02 δh=hfi−hf−i−0.02
r ( s t ) = 2 e x p ( − 25 ∣ δ h ∣ ) , 0 ≤ q i ≤ 0.3 r(s_t)=2exp(-25|\delta h|),0\le q_i \le 0.3 r(st)=2exp(−25∣δh∣),0≤qi≤0.3
其中 h f i h_f^i hfi是脚尖的高度, i i i为另一只脚的高度。此函数的目的是仅在步态周期的某些早期阶段基于脚的高度差计算奖励。对称奖励如下所示
d t = p t l e f t − p t r i g h t d_t=p_t^{left}-p_t^{right} dt=ptleft−ptright
t f = ( E [ I l e f t ( ϕ ) ] > 0.5 ) ⋀ ( E [ I r i g h t ( ϕ ) ] > 0.5 ) tf=(\mathbb{E}[I_{left}(\phi)]>0.5)\bigwedge (\mathbb{E}[I_{right}(\phi)]>0.5) tf=(E[Ileft(ϕ)]>0.5)⋀(E[Iright(ϕ)]>0.5)
δ f t = t f ⋅ d t + ¬ t f ⋅ δ f t − 1 \delta f_t=tf \cdot d_t+\neg tf\cdot \delta f_{t-1} δft=tf⋅dt+¬tf⋅δft−1
δ l t = ¬ t f ⋅ δ f t + t f ⋅ d t \delta l_t=\neg tf \cdot \delta f_t + tf \cdot d_t δlt=¬tf⋅δft+tf⋅dt
r ( s t ) = 3.3 t f e x p ( − 10 ∣ ∣ d t + δ l t ∣ ∣ 1 ) r(s_t)=3.3tfexp(-10||d_t+\delta l_t||_1) r(st)=3.3tfexp(−10∣∣dt+δlt∣∣1)
其中 p t i p_t^i pti是足端效应器的三维位置, ¬ \neg ¬是取反符号。
为了增强从仿真到现实的转移鲁棒性,在综合奖励结构中加入了正则化奖励和域随机化。这些奖励施加了运动约束,强调了平滑性和安全性。

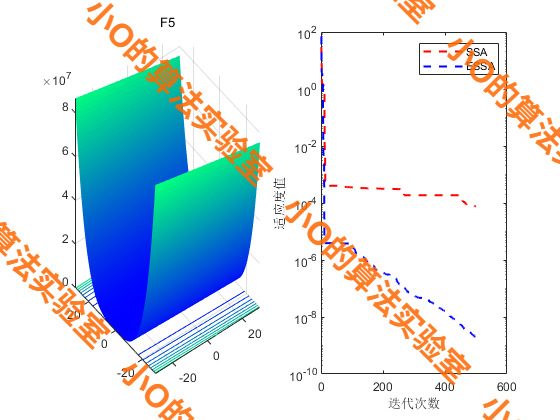
实验结果
请阅读原文。







![[网页五子棋][匹配模块]处理开始匹配/停止匹配请求(匹配算法,匹配器的实现)](https://i-blog.csdnimg.cn/img_convert/918b2416662848aede1bbcbf6613e574.png)