1.构建环境
构建环境:
ubuntu 22.04
jdk 11
scala 2.12
maven 3.9
spark 3.5
2.构建
获取代码
pull代码后,切换到对应分支。
git checkout branch-3.5
编译
构建spark
mvn -DskipTests clean package \-Dhadoop.version=3.3.6 \-Phive -Phive-thriftserver -Pyarn -Pscala-2.12
参数说明
-DskipTests:跳过测试(提高速度)
-Phive:启用 Hive 支持
-Phive-thriftserver:构建 Hive Thrift Server(JDBC Server)
-Pscala-2.12:Spark 3.5 默认使用 Scala 2.12
-Dhadoop.version:可选指定目标 Hadoop 版本
构建结果
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Spark Project Parent POM 3.5.6-SNAPSHOT:
[INFO]
[INFO] Spark Project Parent POM ........................... SUCCESS [ 5.100 s]
[INFO] Spark Project Tags ................................. SUCCESS [ 6.722 s]
[INFO] Spark Project Sketch ............................... SUCCESS [ 7.578 s]
[INFO] Spark Project Local DB ............................. SUCCESS [ 8.549 s]
[INFO] Spark Project Common Utils ......................... SUCCESS [ 9.026 s]
[INFO] Spark Project Networking ........................... SUCCESS [ 11.460 s]
[INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 11.545 s]
[INFO] Spark Project Unsafe ............................... SUCCESS [ 10.493 s]
[INFO] Spark Project Launcher ............................. SUCCESS [ 12.353 s]
[INFO] Spark Project Core ................................. SUCCESS [02:11 min]
[INFO] Spark Project ML Local Library ..................... SUCCESS [ 25.905 s]
[INFO] Spark Project GraphX ............................... SUCCESS [ 28.294 s]
[INFO] Spark Project Streaming ............................ SUCCESS [ 42.562 s]
[INFO] Spark Project SQL API .............................. SUCCESS [ 29.525 s]
[INFO] Spark Project Catalyst ............................. SUCCESS [02:35 min]
[INFO] Spark Project SQL .................................. SUCCESS [03:45 min]
[INFO] Spark Project ML Library ........................... SUCCESS [02:02 min]
[INFO] Spark Project Tools ................................ SUCCESS [ 4.805 s]
[INFO] Spark Project Hive ................................. SUCCESS [ 57.008 s]
[INFO] Spark Project REPL ................................. SUCCESS [ 17.330 s]
[INFO] Spark Project Hive Thrift Server ................... SUCCESS [ 32.332 s]
[INFO] Spark Project Assembly ............................. SUCCESS [ 8.576 s]
[INFO] Kafka 0.10+ Token Provider for Streaming ........... SUCCESS [ 15.543 s]
[INFO] Spark Integration for Kafka 0.10 ................... SUCCESS [ 36.375 s]
[INFO] Kafka 0.10+ Source for Structured Streaming ........ SUCCESS [ 32.824 s]
[INFO] Spark Project Examples ............................. SUCCESS [ 37.571 s]
[INFO] Spark Integration for Kafka 0.10 Assembly .......... SUCCESS [ 5.331 s]
[INFO] Spark Avro ......................................... SUCCESS [ 35.194 s]
[INFO] Spark Project Connect Common ....................... SUCCESS [ 39.677 s]
[INFO] Spark Protobuf ..................................... SUCCESS [ 31.574 s]
[INFO] Spark Project Connect Server ....................... SUCCESS [ 41.291 s]
[INFO] Spark Project Connect Client ....................... SUCCESS [ 47.043 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 21:28 min
[INFO] Finished at: 2025-05-28T17:53:47+08:00
[INFO] ------------------------------------------------------------------------
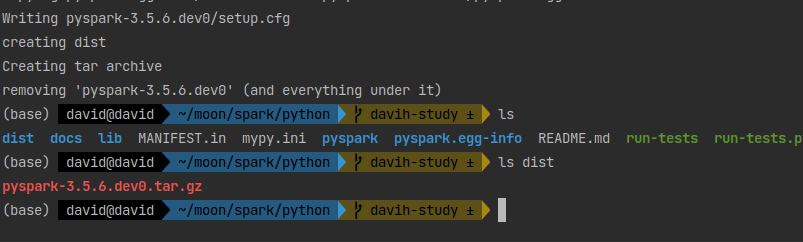
构建 PySpark 部分的 Python 包
cd python
python3 setup.py sdist
这会在 dist/ 目录下生成 pyspark-.tar.gz,你可以用 pip install 安装。
构建结果
3.安装包
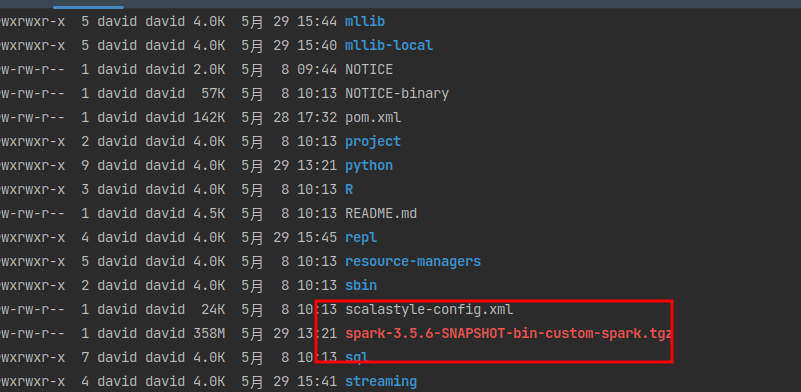
Spark 没有构建成一个 .tar.gz 包,而是构建出对应目录结构:
.
├── bin/ # 启动脚本
├── sbin/ # 管理脚本
├── assembly/target/scala-2.12/jars/ # 所有 jar 包
├── python/ # PySpark 源码
├── python/dist/ # PySpark 安装包(如 pyspark-3.5.6.tar.gz)
└── ...
Spark 的可用构建输出主要分布在以下几个目录:
| 路径 | 说明 |
|---|---|
assembly/target/scala-2.12/ | 主 Spark 可执行包位置 |
assembly/target/scala-2.12/jars/ | 所有 Spark 模块 jar 包合集(可作为 $SPARK_HOME/jars) |
python/dist/ | PySpark 安装包(.tar.gz 或 .whl) |
bin/、sbin/ 等 | 原样保留,作为启动脚本使用 |
examples/ | 示例代码 |
conf/ | 示例配置文件 |
整理安装包
mkdir -p ~/spark-dist
cp -r bin sbin conf examples assembly/target/scala-2.12/jars python ~/spark-dist/
说明
spark发行版的安装包里有spark-*-yarn-shuffle.jar,构建出来没有。

移除原因
Apache Spark 从 3.3.0 版本开始移除 yarn-shuffle 模块,主要出于以下几个原因:
-
Shuffle 服务应该由资源管理器维护,不应绑定在 Spark 内部
Spark 的 YarnShuffleService 实际是一个 NodeManager 的 Auxiliary Service。
它与 Spark 的核心逻辑关系不大,属于 YARN 的职责范围。
把它放在 Spark 里维护带来了 依赖管理复杂度 和 构建臃肿。
开发者更推荐使用 YARN(或 Hadoop)自带的 Shuffle Service。 -
模块长期缺乏维护
yarn-shuffle 代码多年未更新,依赖老旧(如 Guava 版本问题)。
不少用户 构建 Spark 时会遇到兼容性或编译错误。
核心开发者决定将这个模块移除,避免成为项目技术债。 -
简化 Spark 构建系统(Maven/SBT)
每个多模块构建都增加 CI/CD 负担。
移除 rarely-used 模块有助于让 Spark 构建系统更清晰、精简。 -
社区使用比例极低
大多数 Spark on YARN 部署 直接使用 Hadoop 提供的 shuffle service。
官方发布版本中也 不再默认包含 spark-*-yarn-shuffle.jar。
移除影响
移除 yarn-shuffle 模块之后,依然可以正常将 Spark 任务提交到 YARN 上运行,不会影响 Spark on YARN 的核心功能。
| 功能 | 是否受影响 | 说明 |
|---|---|---|
提交 Spark 作业到 YARN(如 --master yarn) | ✅ 正常 | Spark Application 会以 ApplicationMaster 形式运行在 YARN 上 |
| 使用 YARN ResourceManager 进行资源调度 | ✅ 正常 | Driver / Executor 会作为 YARN 容器启动 |
| Spark on YARN 的集群模式和客户端模式 | ✅ 正常 | 均不依赖 yarn-shuffle |
依赖 Hadoop 自带的 shuffle-service | ✅ 推荐做法 | Hadoop 通常默认启用了该服务 |
| Executor 之间进行 shuffle 读取 | ✅ 正常 | 通过 Hadoop/YARN 提供的 Shuffle 服务支持 |
4.问题解决
1.报错禁止使用hive3.1.3
错误提示
[INFO] Finished at: 2025-05-28T17:03:46+08:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.3.0:enforce (enforce-versions) on project spark-hive-thriftserver_2.12:
[ERROR] Rule 3: org.codehaus.mojo.extraenforcer.dependencies.EnforceBytecodeVersion failed with message:
[ERROR] Found Banned Dependency: org.apache.hive:hive-service-rpc:jar:3.1.3
[ERROR] Use 'mvn dependency:tree' to locate the source of the banned dependencies.
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
原因
这个错误说明你在编译 Spark(特别是 spark-hive-thriftserver 模块)时,触发了 Maven Enforcer 插件的规则,禁止使用某个依赖:
Found Banned Dependency: org.apache.hive:hive-service-rpc:jar:3.1.3
Maven Enforcer 插件检测到 hive-service-rpc:3.1.3 是被禁止的字节码依赖(可能版本太新),因为它含有不兼容的 Java 字节码(比如编译时使用了 JDK 11+,但 Spark 要求是 JDK 8 字节码)。
解决方案
<enforceBytecodeVersion><maxJdkVersion>${java.version}</maxJdkVersion><ignoredScopes>test</ignoredScopes><ignoredScopes>provided</ignoredScopes><excludes><!--TODO(SPARK-44032): Remove the exclusion of threeten-extra when orc-core fixes the violation--><exclude>org.threeten:threeten-extra</exclude><!-- 排除 hive-service-rpc --><exclude>org.apache.hive:hive-service-rpc</exclude></excludes>
</enforceBytecodeVersion>
增加
<!-- 排除 hive-service-rpc -->
<exclude>org.apache.hive:hive-service-rpc</exclude>
5.补充
还有一个这个构建命令,等于上面所有操作。
./dev/make-distribution.sh \--name custom-spark \--tgz \--r \-Phive -Phive-thriftserver -Pyarn -Pscala-2.12 \-Dhadoop.version=3.3.6
如果不需要R目录,可以移除
--r