文章目录
- 二叉树进阶面试题(2)
- Leetcode_144 二叉树的前序遍历(使用非递归)
- Leetcode_94 二叉树的中序遍历(使用非递归)
- Leetcode_145 二叉树的后序遍历(使用非递归)
二叉树进阶面试题(2)
本篇文章将继续进行二叉树的进阶面试题的讲解,其中,本部分将重点针对于二叉树的前序遍历、中序遍历、后序遍历如何非递归遍历进行讲解。
之所以要这么晚才来将非递归的前中后序遍历是因为,使用c语言进行递归转非递归是很困难的。因为递归过程涉及到回退。非递归的本质就是通过循环的逻辑来模拟实现递归,这个过程中有很多方法。
但是今天我们的三种遍历当时都将使用栈这个数据结构进行实现。如果使用c语言,那我们还得自行手撕一个栈的数据结构出来,这是很麻烦的。而且栈的一些接口的使用也不是那么的方便。但是c++就不一样了,我们可以使用STL库里面的stack。
Leetcode_144 二叉树的前序遍历(使用非递归)
原题:https://leetcode.cn/problems/binary-tree-preorder-traversal/description/
我们先来将前序遍历的非递归。
前序遍历的过程可以总结为一句话:根 左子树 右子树,然后对于子树而言,又是遵循这个规则。使用递归去实现就很好理解了,但是我们现在需要的是非递归。
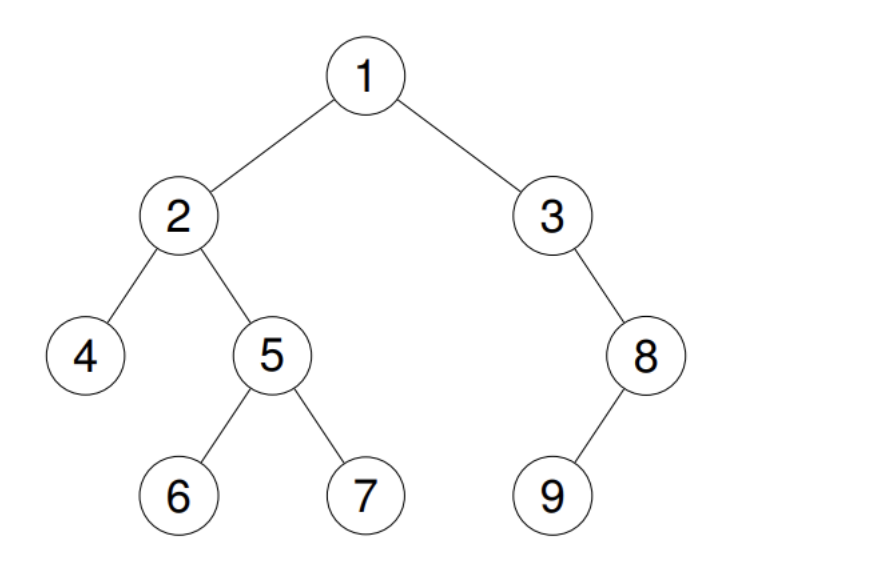
假设现在有这么一个树,我们应该如何进行非递归的前序遍历呢?
我们非递归的逻辑本质上就是模拟递归,我们来看看递归的代码:
void preorderTraversal_R(TreeNode* root){if(root == nullptr) return;cout << root->val << endl;preorderTraversal_R(root->left);preorderTraversal_R(root->right);
}
我们把每个节点当作一个子树的根节点:
我们发现,在递归的调用过程中,碰到一个根节点,就打印一次,然后先不断地往左子树去递归深入。然后直到左子树为空的时候,这个时候就已经没办法再递归深入了,就只能回退到上一层深入左子树的栈帧位置,然后再调用到右子树位置,右子树继续左深入和回退。
我们就是要使用非递归的逻辑来模仿这个过程,但是会面临着一个问题就是:
如何找到回退的位置?递归是通过函数调用函数,回退栈帧实现的。我们现在不使用递归,如何能够回退到上一层栈帧呢?这个时候就要借助数据结构stack了。
假设就是上面那个树:
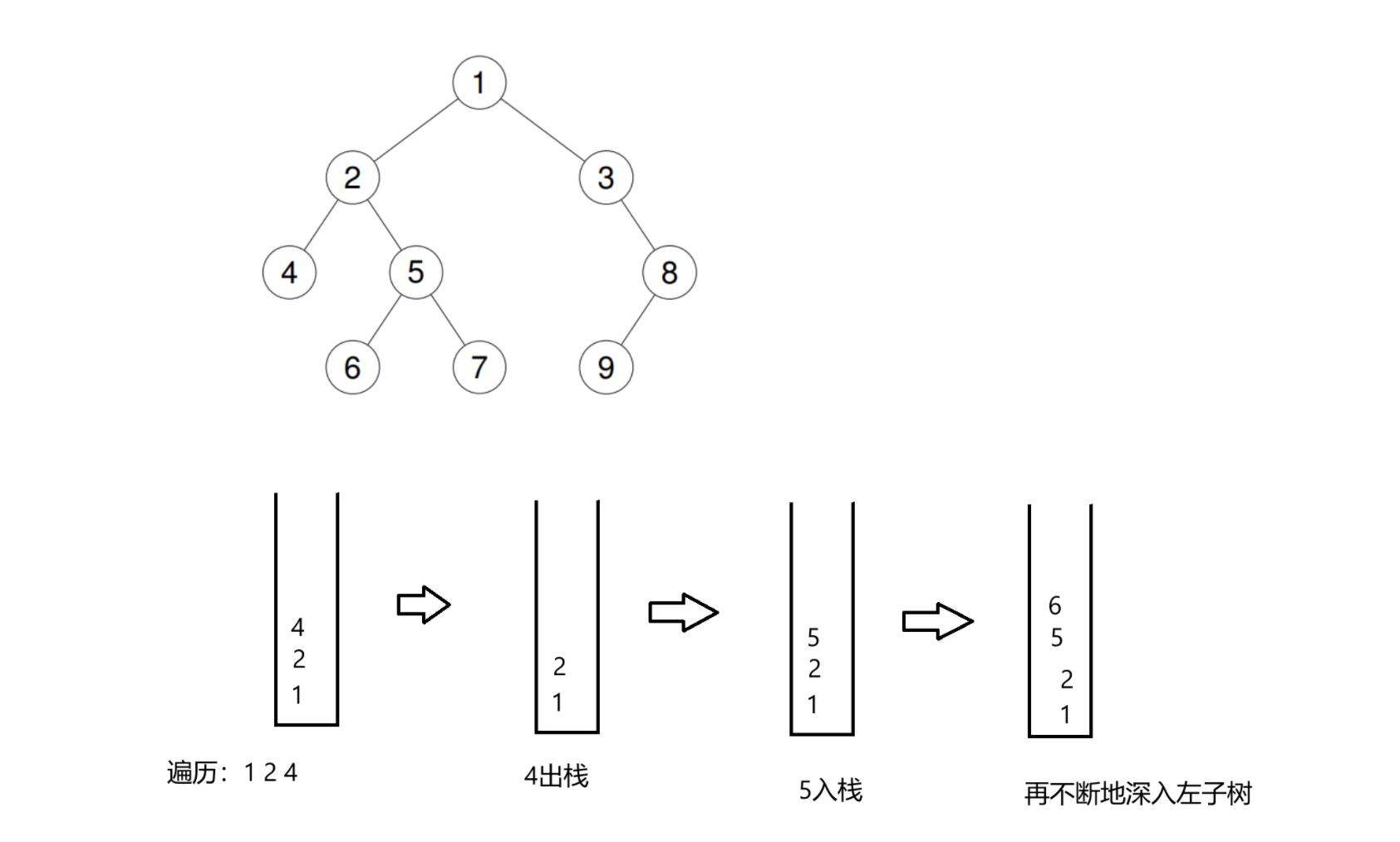
这里的逻辑没有画完,但是已经足够展现出二叉树的遍历逻辑了。
但是这里只是展现出了大致逻辑,其实在写代码的时候还会面临很多问题,这时候我们就先看代码实现,然后再来讲细节:
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr) return v;stack<TreeNode*> st;st.push(root);v.push_back(root->val);while(!st.empty()){TreeNode* top = st.top();//深入左子树while(top->left){st.push(top->left);v.push_back(top->left->val);top = top->left;}//找到右子树(一定要找到)while(!st.empty()){top = st.top();st.pop();if(top->right){st.push(top->right);v.push_back(top->right->val);break;}}}return v;}
};
这里其实深入遍历左子树是很简单的,从栈顶节点开始,不断地往左边走,然后把节点进行入栈并且插入到数组里面(插入到数组相当于访问)。
直到左边为空,说明需要回退到上一个根节点然后将右子树的根进行入栈,然后重复上面的操作。正常来讲,直接把右子树的根入栈就好了。
但就是因为右子树可能为空,如果按照我们代码这里的逻辑,如果只判断一次右子树为空不入栈是会出问题的:
比如这个树:

top走到4就没办法再深入了,这个时候就需要把右子树插入。但是4的右子树为空。这个时候如果只判断一次就不判断了,4会出栈,然后没有右子树的入栈。这个时候会回退到新的栈顶节点2。问题就来了,2是被访问过的,又没有出栈。那回退到2的时候按照这个逻辑走,又会不断地深入到左边。这是肯定不行的。所以为什么我们上面的代码是需要进行循环的逻辑去找到右子树插入。因为那些没有右子树的都需要被过滤掉。
但是回退找右子树的过程中,很可能一直回退到整个树的根节点都没有右子树,这个时候就没办法再回退了,这个时候对应的就是栈为空。所以我们是需要特殊判断的。
当然,这里再提供一个方法,这个方法会简单一些:
既然说先序遍历的过程一定是:根 左子树 右子树,那么我们是否可以像层序遍历的逻辑去走:
先把根节点入栈。取栈顶节点,访问后出栈,然后把出栈节点的右节点先入栈,再入栈左节点。然后又是取栈顶节点,再出栈,再入栈其右左节点…
我们发现这个是可行的,而且代码写起来也是非常的简单:
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr) return v;stack<TreeNode*> st;st.push(root);while(!st.empty()){TreeNode* STtop = st.top();v.push_back(STtop->val);st.pop();if(STtop->right != nullptr)st.push(STtop->right);if(STtop->left != nullptr)st.push(STtop->left);}return v;}
};
经过验证,发现这样确实可行,而且思路更简单,也更好想到。
只需要注意右节点要先入栈。因为栈是后进先出,所以左节点后入栈,先出栈,也就意味着左节点先被访问。
Leetcode_94 二叉树的中序遍历(使用非递归)
原题:https://leetcode.cn/problems/binary-tree-inorder-traversal/
中序遍历也就一句话:左子树 根 右子树
中序遍历其实和前序遍历是很像的。我们只需要稍微改一点代码就可以了。为什么这么说呢?
我们可以看到,前序遍历和中序遍历都要做的一件事情是,不断地左子树递归深入。中序遍历这么做的原因是本身就要先访问左子树。前序遍历这么做的是因为访问一个根节点后再左递归深入。这两个遍历的方式的最大区别就是在于:节点的访问时机。
前序遍历是遍历到一个节点,就先进行访问,然后再左递归深入。我们可以这么理解,前序遍历是把每一个节点当作根节点,在前序遍历的方式下,就需要对根节点先进行访问。
但是中序遍历肯定是不能边入栈边访问的。中序遍历的时机应该是回退的时候再来访问。这样子就是可以看做成把每个节点当成左节点。在中序的条件下,左节点应该先被访问。
其余的细节其实都是很相似的,回退的过程中也是一定要找到右子树进行入栈的,要不然也会出现前面前序遍历中讲到的问题的,我们来看看代码:
class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr) return v;stack<TreeNode*> st;st.push(root);while(!st.empty()){TreeNode* top = st.top();while(top->left){st.push(top->left);//不在这里访问top = top->left;}while(!st.empty()){top = st.top();st.pop();//访问时机v.push_back(top->val);if(top->right){st.push(top->right);break;}}}return v;}
};
但是这里是不能直接使用前序的第二个方法的。因为第二种方法是根据前序遍历的先根性来进行设计的。那个方法访问完根节点后就要马上出栈,再入栈右左节点的。这点需要注意。
但是针对于中序遍历的特性,也可以提出另一种写法:
class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {stack<TreeNode*> st;vector<int> v;TreeNode* cur = root;while(cur){st.push(cur);cur = cur->left;}while(!st.empty()){TreeNode* top = st.top();st.pop();v.push_back(top->val);TreeNode* rightmove = top->right;while(rightmove){st.push(rightmove);rightmove = rightmove->left;}}return v;}
};
这个方法的思路就是,先把左路节点全部入栈。回退的时候访问节点,然后再把右子树的左路节点再入栈。这是根据中序遍历的特性设计的一种方案。
Leetcode_145 二叉树的后序遍历(使用非递归)
原题:·https://leetcode.cn/problems/binary-tree-postorder-traversal/
这个部分我们来看看后序遍历如何进行非递归的改造。后序遍历相对于前序和中序来说是会更复杂一点的,思路可以说是和前中序遍历根本就不一样。
后序遍历是不能像前中序遍历那样,先对单边的节点进行深入的。递归逻辑下这么做可以是因为函数栈帧会自动回退回去。但是这里我们如果是模拟后序遍历的过程,如果先单边地深入,这势必会出现一个问题。
就是一个树的左子树要想跳到右子树范围,是需要先回退到根节点然后再走到右子树的。由于这个过程是后序遍历,访问节点只能在回退的时候访问。那回退的时候再跳到右子树去,那么跟那个被访问的节点的关系就是根和右子树了。这肯定是不行的。
所以这里的逻辑应该是,根节点先入栈,但是并不进行访问。然后再把根节点的右子树和左子树入栈(如果有)。这个方式就很像前序遍历的方法2,区别就是根节点不会先访问后出栈。
我们来试着走一下这个逻辑:
首先,按照上面讲的逻辑先入栈。
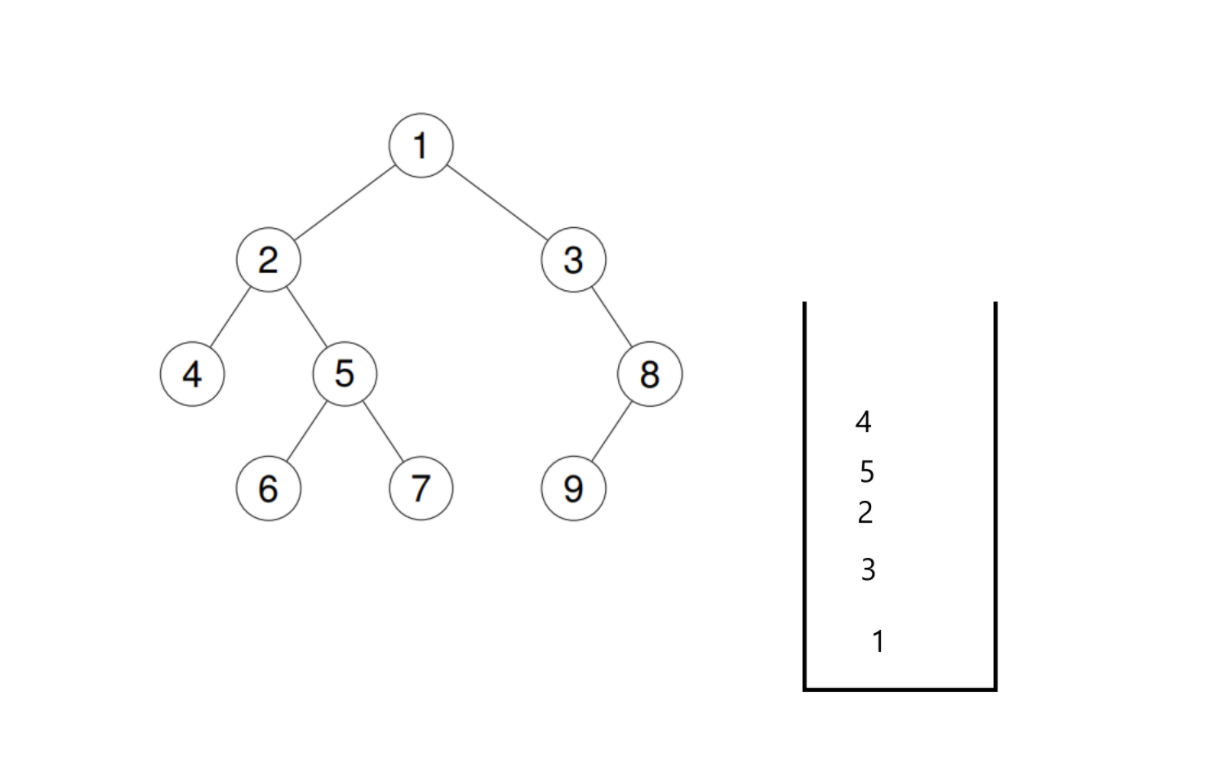
先入栈1,然后右左只有有一个不为空的就得入栈。然后再取栈顶节点进行上述操作。入栈到4后,发现4的右左都是空。这个时候就简单了,直接出栈并访问。
然后取栈顶节点,继续执行上述讲到的入栈操作。
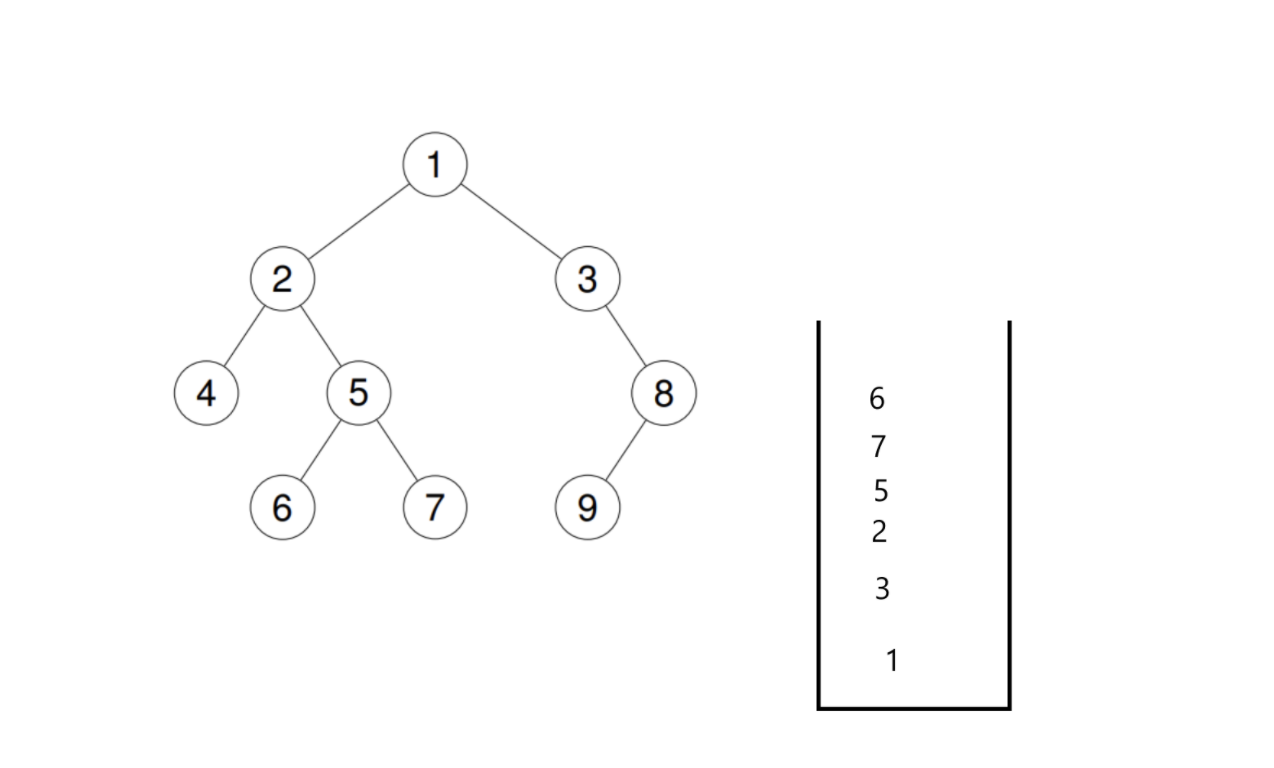
入栈到6后,左右为空,6出栈访问。再取栈顶节点7,也是一样,左右为空,出栈访问:
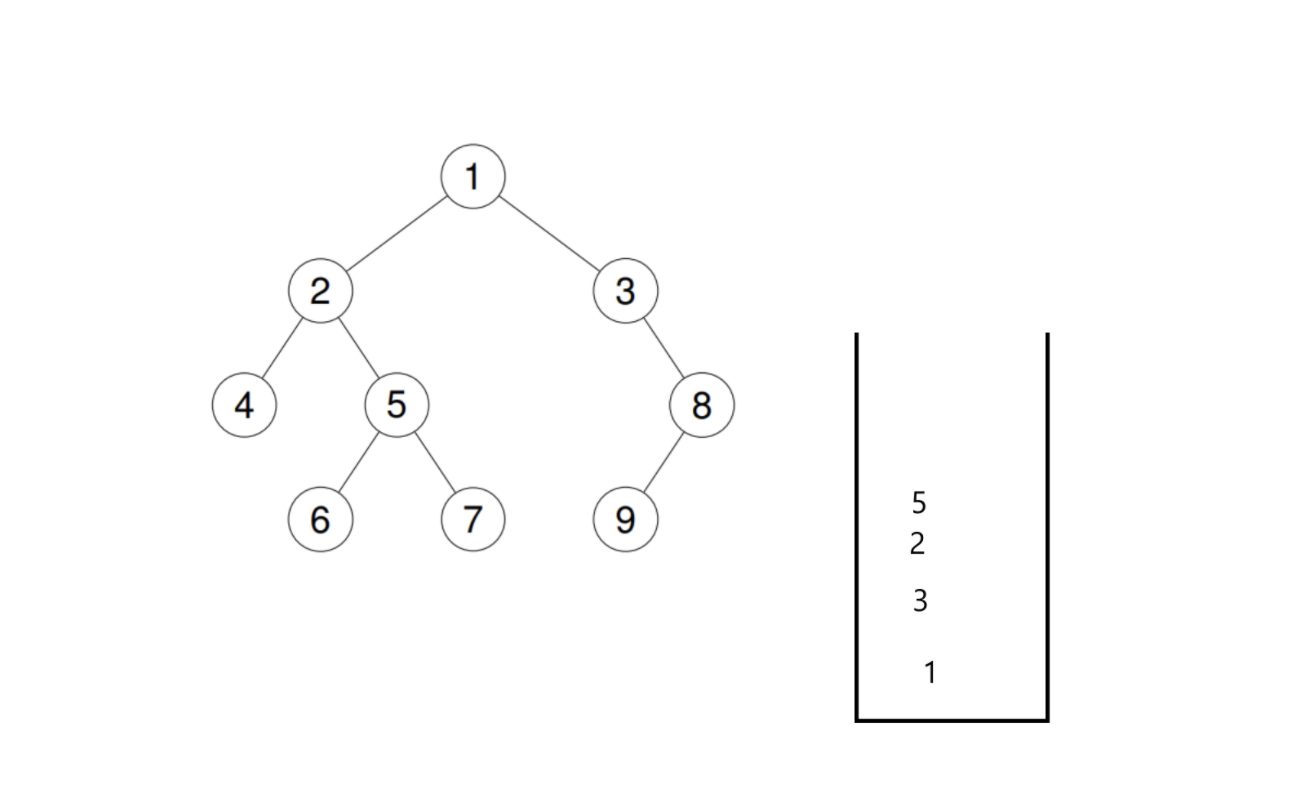
这个时候我们发现,栈顶节点又是5了。如果我们还是简单地执行上述的逻辑,那是会出问题的。因为5这个节点的左右子树已经被访问过了,按道理这一次回退到5的时候是应该直接访问5的。但是我们现在最大的问题就是,如何判断一个节点的左右子树已经被访问过了呢?这是一定要判断的,这里如果不进行判断,5的左右子树又会被重复访问,造成死循环了。
这个时候,我们只要能够解决掉这个判断节点的左右子树是否被访问的逻辑,那么这题就能够被解决了,但是本题的难度也就是在这个逻辑的处理上。
接下来,我们需要一起探索一下,如何找到这个判断逻辑。
第一种方法:
我们可以使用一个栈,记录着每一个节点的状态。如果一个节点的左右子树都没有被访问过,那就记录这个节点的状态为0。访问过了就记录为1。这样子再回退到某个节点的时候,就可以很轻松的判断出是否被访问过了。
我们可以使用两个栈,一个存放的就是节点,另一个存放的就是每个节点的对应的状态。如果一个节点出栈了,那他对应的状态也必须出栈。
我们来看看代码:
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {vector<int> v;if (root == nullptr) return v;stack<TreeNode*> st;stack<int> Status;st.push(root);Status.push(0);while (!st.empty()) {while (Status.top() == 0 && (st.top()->left || st.top()->right)) {Status.top() = 1;TreeNode* STTop = st.top();if (STTop->right) {st.push(STTop->right);Status.push(0);}if (STTop->left) {st.push(STTop->left);Status.push(0);}}v.push_back(st.top()->val);st.pop();Status.pop();}return v;}
};
根节点入栈的时候,状态必须是0。因为此时只入栈了根节点,并没有把根节点的右左节点入栈,那状态必须是0。
然后开始执行逻辑:
只要栈不为空,就不断地取栈顶节点出来判断,如果状态是0,就可以判断右左子树是否为空。只要有一个不为空,那就将不为空的子树根节点入栈,并且将对应的节点的状态设置成1。如果两个都为空,这个时候就没有右左子树需要入栈,直接访问即可(插入到数组中)。
如果是回退到某个有子树的节点,但是状态为1,这个时候也是没有办法再进入循环的。也会直接访问。这个时候就很好的解决了判断节点是否被访问过的逻辑了。
第二种方法:
但是第一种方法是要使用两个栈进行操作的,而且最重要的问题是,等于是要多开一倍的空间。而且管控节点的栈的时候,必须管控状态的那个栈。一旦有遗漏就很容易出错了。
我们能不能想出一种办法,只需要一个变量来记录状态呢?根据这个状态我们就可以判断是否要对某个节点的左右子树进行入栈。
这是可以的,我们可以按照后序遍历的顺序记录上一个被访问的节点:
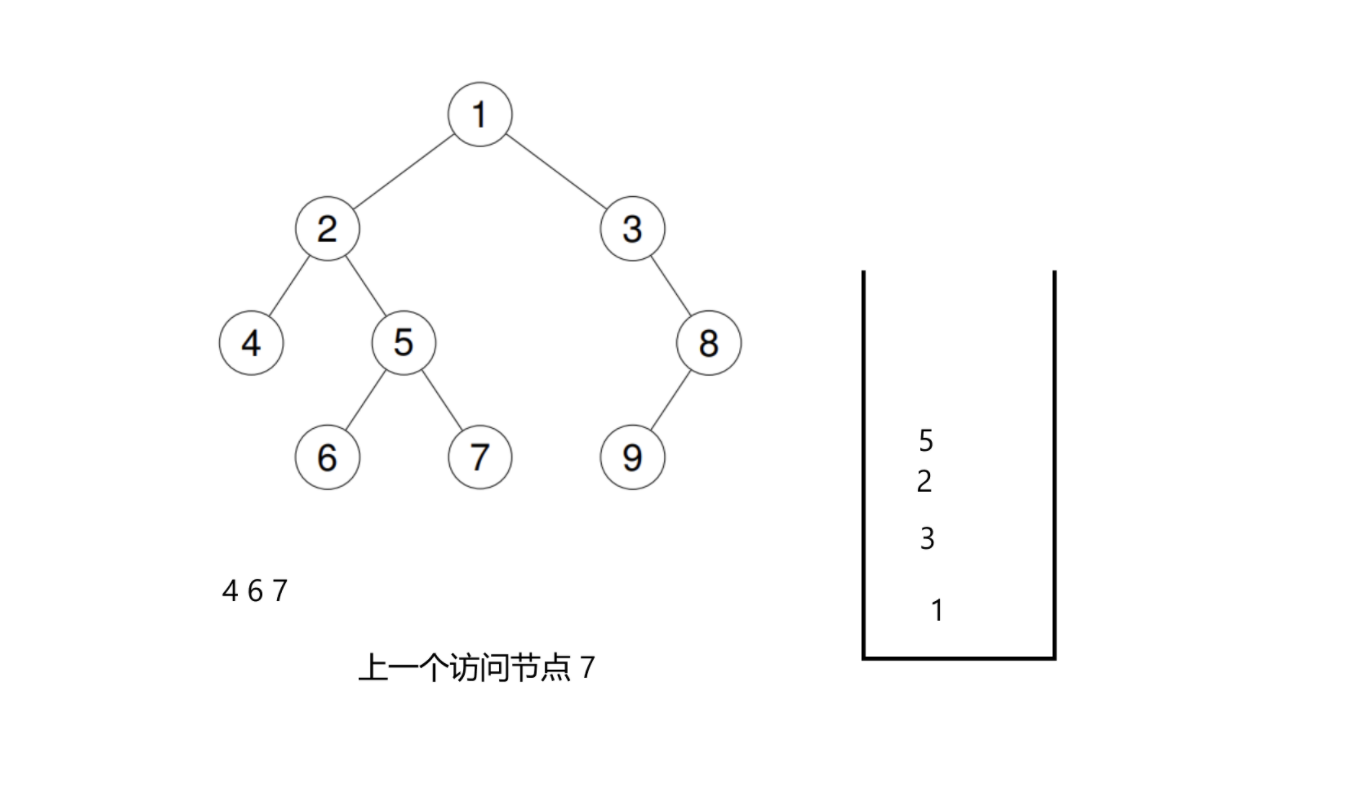
比如当前这个状态,已经访问了4 6 7三个节点,这个时候是第二次回到5这个节点了。我们这个时候急需判断是否还需要对它进行左右子树的入栈。
如果我们按照后序遍历的顺序,依次记录着当前栈顶节点是某个节点时,访问到的上一个节点。这个时候就很轻松了。我们发现此时上一个访问的节点是7,是5的右子树。所以可以直接判断这是5不需要再进行左右子树的插入的。然后后面的逻辑也是一样的。
为什么可以这么做呢?
我们先来看这个树的后序遍历的结果:[4,6,7,5,2,9,8,3,1]。
我们现在是能够保证我们的逻辑走出来的序列一定是后续的,只是需要判断是否需要入栈右左子树。在这个前提下,节点被访问的时机一定是节点处在栈顶的时候。
然后我们再来仔细地看看这个序列,我们发现,除了根节点,其余被访问的节点的前一个被访问的节点必然是它的左孩子或者右孩子。
所以当每次节点出栈(被访问)的时候,我们都进行记录。那么就可以很轻松完成判断逻辑了。
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr) return v;stack<TreeNode*> st;st.push(root);TreeNode* LastNode = nullptr;while(!st.empty()){TreeNode* top = st.top();while((LastNode != top->right && LastNode != top->left)&& (top->left || top->right)){if(top->right) st.push(top->right);if(top->left) st.push(top->left);top = st.top(); }LastNode = st.top();v.push_back(top->val);st.pop();}return v;}
};
很多人会直接写出这样的代码,但是发现是有问题的。
原因就在于对于LastNode的处理,如果我们设置LastNode为空,我们来看看这棵树是否能得到正确的序列:
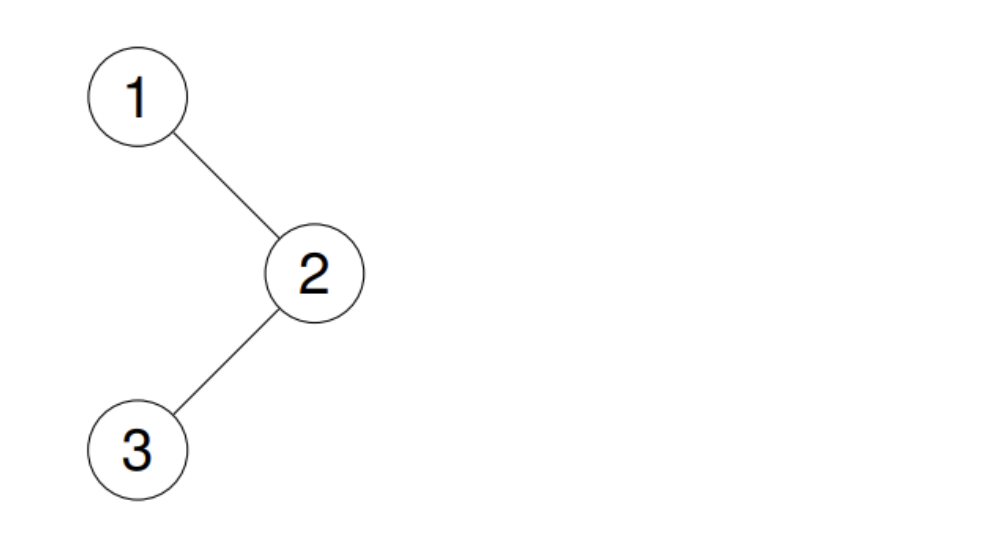
这个树,按照代码逻辑走,会发现输出的序列只有一个1。
这就是因为设置了LastNode为空的初始条件。然后在判断是否需要入栈右左子树的时候,发现LastNode为空正好和1的左节点(nullptr)匹配上了,这个时候循环条件的判断为false,这是不会进入循环的。
但是很明显,这个情况只会出现在根节点的左右子树为空的情况下才会有这个问题。因为在栈顶节点为其它的节点的时候,LastNode必然是上一个被访问的节点,不会为空。
所以只需要处理一下开头的时候出现这个问题即可。该如何做呢?
我们可以直接把LastNode的值设置为根节点root。这是没有任何影响的。虽然栈顶节点为根节点的时候,上一个访问的节点确实是空。但是我们的逻辑是,只有出栈被访问的时候,才会修改LastNode的值。
一般来说,根节点入栈后并不是马上要被访问的。真正需要通过这个LastNode来判断是否入栈右左节点的地方是第一次回退到有孩子,但是孩子又被访问过的节点的地方。这个时候状态才会真正派上用场。
就算树只有一个根节点,那也不怕,虽然上一个节点记录的是本身,但是左右孩子都是空,仍然不会进入循环。所以这个修改是可行的:
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr) return v;stack<TreeNode*> st;st.push(root);TreeNode* LastNode = root;while(!st.empty()){TreeNode* top = st.top();while((LastNode != top->right && LastNode != top->left)&& (top->left || top->right)){if(top->right) st.push(top->right);if(top->left) st.push(top->left);top = st.top(); }LastNode = st.top();v.push_back(top->val);st.pop();}return v;}
};
至此,我们就完成了二叉树后序遍历的非递归修改了。