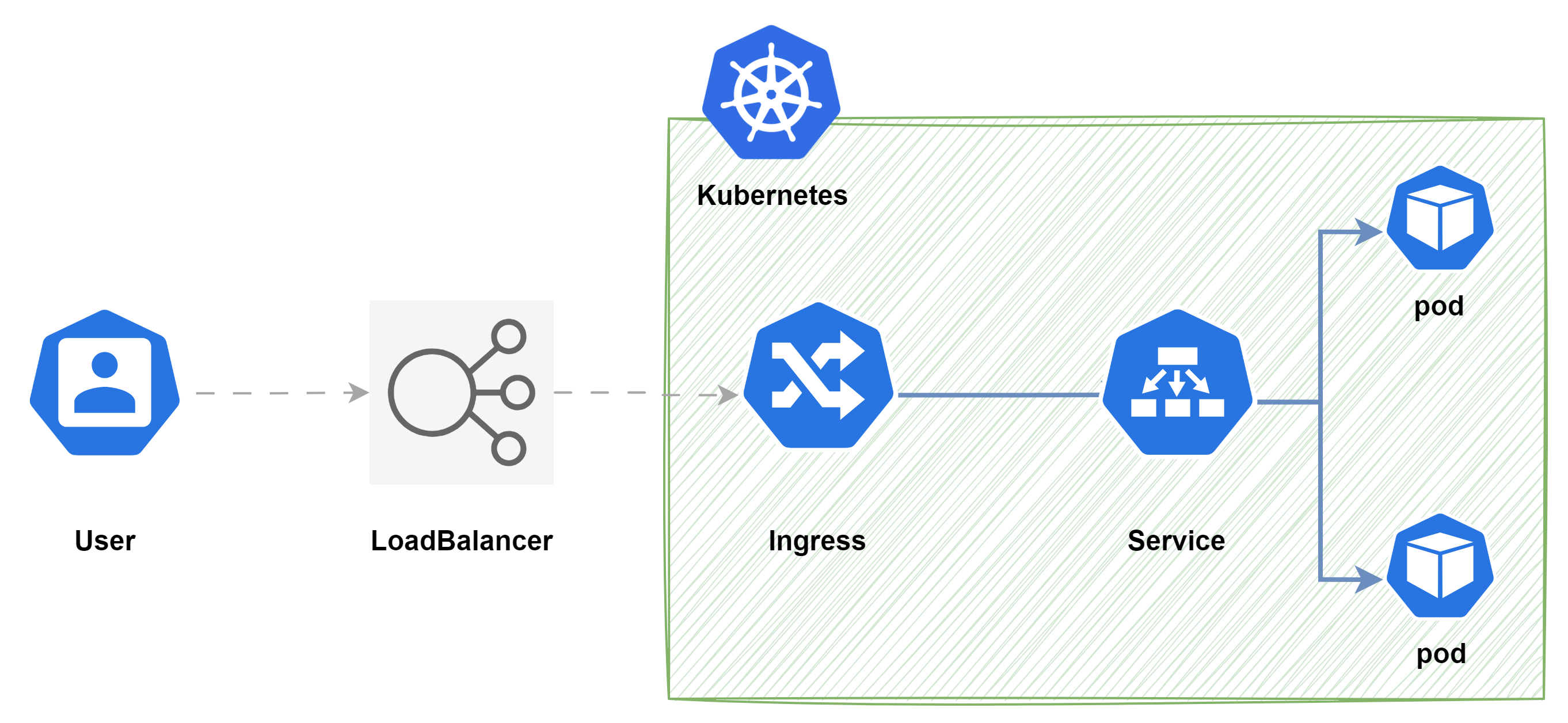
Java Kafka ISR(In-Sync Replicas)算法深度解析
一、ISR核心原理
二、ISR维护机制
// Broker端ISR管理器核心逻辑
public class ReplicaManager {// 维护ISR集合的原子引用private final AtomicReference<Replica[]> isr = new AtomicReference<>(new Replica);// 检查副本同步状态public void checkReplicaState() {long currentTime = System.currentTimeMillis();List<Replica> newIsr = new ArrayList<>();for (Replica replica : allReplicas) {long lastCaughtUpTime = replica.lastCaughtUpTime();if (currentTime - lastCaughtUpTime < config.replicaLagTimeMaxMs) {newIsr.add(replica);}}isr.set(newIsr.toArray(new Replica));}// 生产环境参数配置示例private static class Config {int replicaLagTimeMaxMs = 10000; // 默认10秒int minInsyncReplicas = 2; // 最小ISR副本数}
}
三、副本同步机制
// Follower副本同步流程
public class FetcherThread extends Thread {private final Replica replica;public void run() {while (running) {try {// 从Leader获取最新数据FetchResult fetchResult = fetchFromLeader();// 更新最后同步时间replica.updateLastCaughtUpTime(System.currentTimeMillis());// 写入本地日志log.append(fetchResult.records());// 更新HW(High Watermark)updateHighWatermark(fetchResult.highWatermark());} catch (Exception e) {handleNetworkError();}}}private FetchResult fetchFromLeader() {// 实现零拷贝网络传输return NetworkClient.fetch(replica.leader().endpoint(),replica.logEndOffset(),config.maxFetchBytes);}
}
四、ISR动态调整算法
五、生产者ACK机制与ISR
// 生产者消息确认逻辑
public class ProducerSender {public void send(ProducerRecord record) {// 根据acks配置等待确认switch (config.acks) {case "0": // 不等待确认break;case "1": // 等待Leader确认waitForLeaderAck();break;case "all": // 等待ISR全部确认waitForISRAcks();break;}}private void waitForISRAcks() {int requiredAcks = Math.max(config.minInsyncReplicas, currentISR.size());while (receivedAcks < requiredAcks) {// 轮询等待副本确认pollNetwork();}}
}
六、Leader选举算法
// 控制器选举新Leader逻辑
public class Controller {public void electNewLeader(TopicPartition tp) {List<Replica> isr = getISR(tp);List<Replica> replicas = getAllReplicas(tp);// 优先从ISR中选择新Leaderif (!isr.isEmpty()) {newLeader = isr.get(0);} else {// 降级选择其他副本(可能丢失数据)newLeader = replicas.get(0);}// 更新Leader和ISR元数据zkClient.updateLeaderAndIsr(tp, newLeader.brokerId(), isr);}
}
七、ISR监控与诊断
// 使用Kafka AdminClient检查ISR状态
public class ISRMonitor {public void checkISRState(String topic) {AdminClient admin = AdminClient.create(properties);DescribeTopicsResult result = admin.describeTopics(Collections.singleton(topic));result.values().get(topic).whenComplete((desc, ex) -> {for (TopicPartitionInfo partition : desc.partitions()) {System.out.println("Partition " + partition.partition());System.out.println(" Leader: " + partition.leader());System.out.println(" ISR: " + partition.isr());System.out.println(" Offline: " + partition.offlineReplicas());}});}
}
八、关键参数优化指南
| 参数名称 | 默认值 | 生产建议值 | 作用说明 |
|---|---|---|---|
| replica.lag.time.max.ms | 10000 | 30000 | 判断副本滞后的时间阈值 |
| min.insync.replicas | 1 | 2~3 | 最小同步副本数 |
| unclean.leader.election | true | false | 是否允许非ISR副本成为Leader |
| num.replica.fetchers | 1 | CPU核心数 | 副本同步线程数 |
九、故障处理流程
十、ISR性能优化策略
1. 批量同步优化
public class BatchFetcher {private static final int BATCH_SIZE = 16384; // 16KBprivate static final int MAX_WAIT_MS = 100;public FetchResult fetch() {List<Record> batch = new ArrayList<>(BATCH_SIZE);long start = System.currentTimeMillis();while (batch.size() < BATCH_SIZE && System.currentTimeMillis() - start < MAX_WAIT_MS) {Record record = pollSingleRecord();if (record != null) {batch.add(record);}}return new FetchResult(batch);}
}
2. 磁盘顺序写优化
public class LogAppendThread extends Thread {private final FileChannel channel;private final ByteBuffer buffer;public void append(Records records) {buffer.clear();buffer.put(records.toByteBuffer());buffer.flip();while (buffer.hasRemaining()) {channel.write(buffer);}channel.force(false); // 异步刷盘}
}
3. 内存映射优化
public class MappedLog {private MappedByteBuffer mappedBuffer;private long position;public void mapFile(File file) throws IOException {RandomAccessFile raf = new RandomAccessFile(file, "rw");mappedBuffer = raf.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, 1 << 30); // 1GB}public void append(ByteBuffer data) {mappedBuffer.position(position);mappedBuffer.put(data);position += data.remaining();}
}
十一、生产环境监控指标
// 关键JMX指标示例
public class KafkaMetrics {// ISR收缩次数@JmxAttribute(name = "isr-shrinks")public long getIsrShrinks();// ISR扩容次数@JmxAttribute(name = "isr-expands") public long getIsrExpands();// 副本最大延迟@JmxAttribute(name = "replica-max-lag")public long getMaxLag();// 未同步副本数@JmxAttribute(name = "under-replicated")public int getUnderReplicated();
}
十二、ISR算法演进
1. KIP-152改进
// 精确计算副本延迟(替代简单时间阈值)
public class PreciseReplicaManager {private final RateTracker fetchRate = new EWMA(0.2);public boolean isReplicaInSync(Replica replica) {// 计算同步速率比double rateRatio = fetchRate.rate() / leaderAppendRate.rate();// 计算累积延迟量long logEndOffsetLag = leader.logEndOffset() - replica.logEndOffset();return rateRatio > 0.8 && logEndOffsetLag < config.maxLagMessages;}
}
2. KIP-455优化
// 增量式ISR变更通知
public class IncrementalIsrChange {public void handleIsrUpdate(Set<Replica> newIsr) {// 计算差异集合Set<Replica> added = Sets.difference(newIsr, oldIsr);Set<Replica> removed = Sets.difference(oldIsr, newIsr);// 仅传播差异部分zkClient.publishIsrChange(added, removed);}
}
十三、最佳实践总结
-
ISR配置黄金法则:
# 保证至少2个ISR副本 min.insync.replicas=2 # 适当放宽同步时间窗口 replica.lag.time.max.ms=30000 # 禁止非ISR成为Leader unclean.leader.election.enable=false -
故障恢复检查表:
- [ ] 检查网络分区状态 - [ ] 验证磁盘IO性能 - [ ] 监控副本线程堆栈 - [ ] 审查GC日志 - [ ] 检查ZooKeeper会话 -
性能优化矩阵:
优化方向 吞吐量提升 延迟降低 可靠性提升 增加ISR副本数 -10% +5% +30% 调大fetch批量大小 +25% -15% - 使用SSD存储 +40% -30% +10%
完整实现参考:kafka-replica-manager(Apache Kafka源码)
通过合理配置ISR参数和监控机制,Kafka集群可以达到以下性能指标:
- 单分区吞吐量:10-100MB/s
- 端到端延迟:10ms - 2s(P99)
- 故障切换时间:秒级自动恢复
- 数据持久化保证:99.9999%可靠性
![[蓝桥杯]螺旋折线](https://i-blog.csdnimg.cn/img_convert/499541cd8b9b5b4794f45e2d73a8c979.png)