目录
一、表中的增删查改
1.1直接插入
1.2更新
1.3替换
二、Retrieve
2.1Select列
2.1.1where子句
2.1.2结果排序
三、Update
四、Delete
五、截断表
六、插入查询结果
6.1案例:对表中数据去重
七、聚合函数
八、分组统计group by子句
一、表中的增删查改
创建creat
-- 创建一张学生表
CREATE TABLE students (id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,sn INT NOT NULL UNIQUE COMMENT '学号',name VARCHAR(20) NOT NULL,qq VARCHAR(20)
);
1.1直接插入
insert [into] table_name [向哪些列中插入] values (列中插入对应的数据)
- 如果将values左侧的指定列插入忽略了就是那就是全列插入

1.2更新
插入一条信息,如果主键或者唯一键发生冲突,则更新数据

1.3替换
如果插入的新数据和旧数据发生冲突,先将旧数据删掉,重新插入新数据,如果没有冲突直接插入

二、Retrieve
2.1Select列
全列查询
select * from 表名
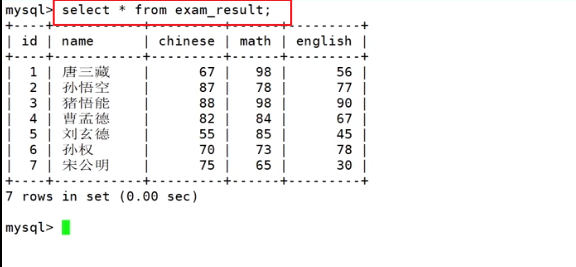
- 不建议全列查询,原因数据库服务端在服务器上的,在公司中数据库中的数据很多,如果全列查询,网络传输数据需要占用大量的网络资源,并且本地电脑会造成刷屏现象
指定列查询
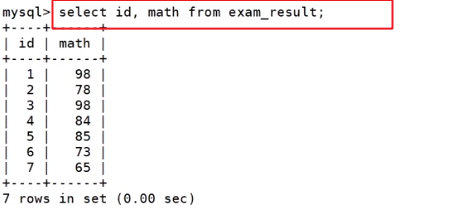
select也可以进行表达式运算

重新指定名称显示出来

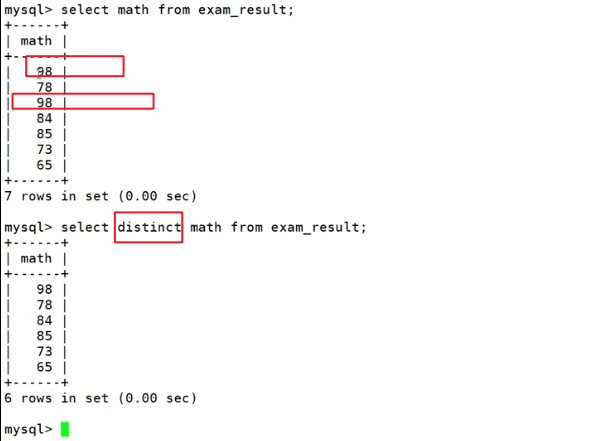
对所要查询的结果进行去重
2.1.1where子句
where语句就相当于C语言中的if语句,列出满足条件的信息
比较运算符

逻辑运算符
- AND:多个条件必须都为 TRUE(1),结果才是 TRUE(1)
- OR:任意一个条件为 TRUE(1), 结果为 TRUE(1)
- NOT:条件为 TRUE(1),结果为 FALSE(0)
按照英语成绩小于60分来筛选出名字、英语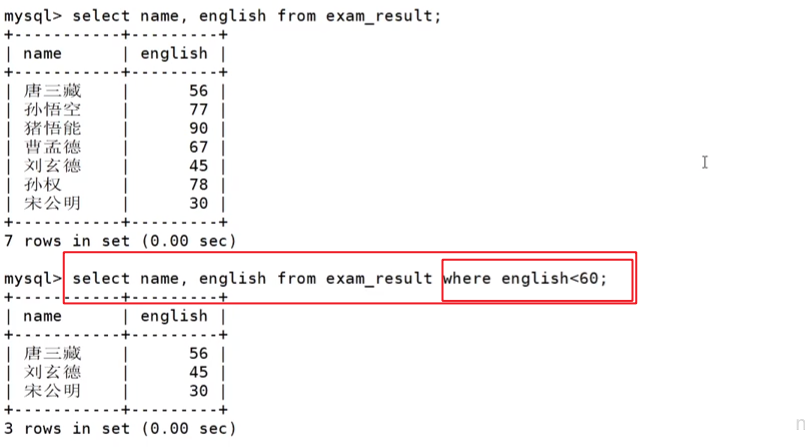
按照语文成绩在80到90分之间的条件来筛选出名字和语文成绩

按照姓孙的条件来筛选出姓孙的人

按照语文成绩好于英语成绩的条件筛出名字、语文成绩、英语成绩

按照200分以下的条件来筛选名字、总成绩
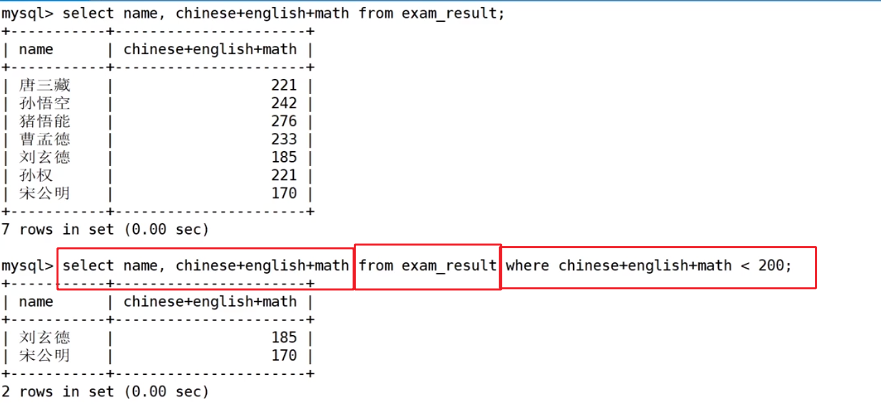
有人就想到对列进行重名,在where条件筛选时用重命名,这样行吗

可以看到是不行的,为什么呢?这就需要先了解sql语句执行的顺序
先执行的是form exam_result语句,因为需要知道从哪个表中选,在执行where total < 200语句,要进行筛选就需要知道筛选条件,所以在执行total < 200,还没有进行重命名,所以就不知道total是谁

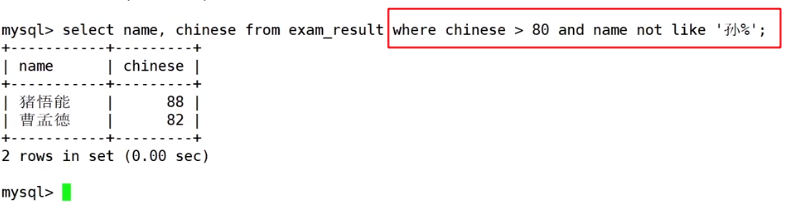
筛选出语文成绩大于80并且不姓孙的人
2.1.2结果排序
先筛选出人名和数学成绩,再按数学成绩升序显示出来

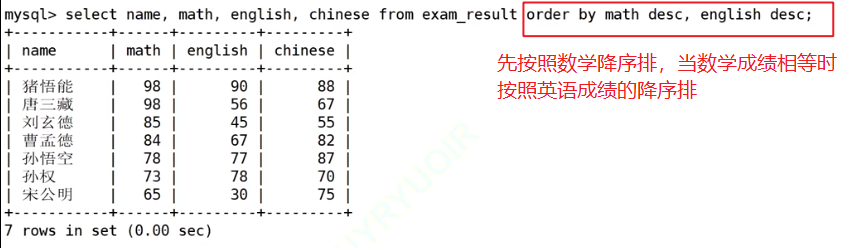
先筛出符合条件的人名、数学、英语、语文,然后先按照数学的降序、当数学相等时按照英语的降序来显示出来
筛出符合条件的人名和总分,以总分由高到低来显示出来
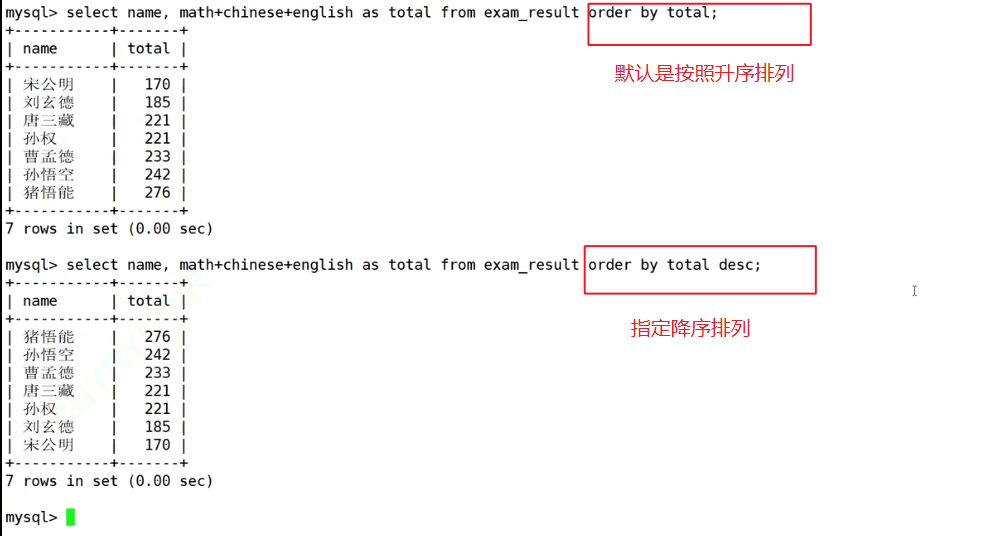
为什么这里可以用重命名?来分析一下子句的执行顺序
先执行from exam_result子句,在根据where语句筛出名字、总成绩,最后根据order语句按照顺序来显示出来,
所以先进行了重命名,然后才在order中使用重名命
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示

- 先根据模糊条件进行筛选,然后再按照数学成绩的降序来显示
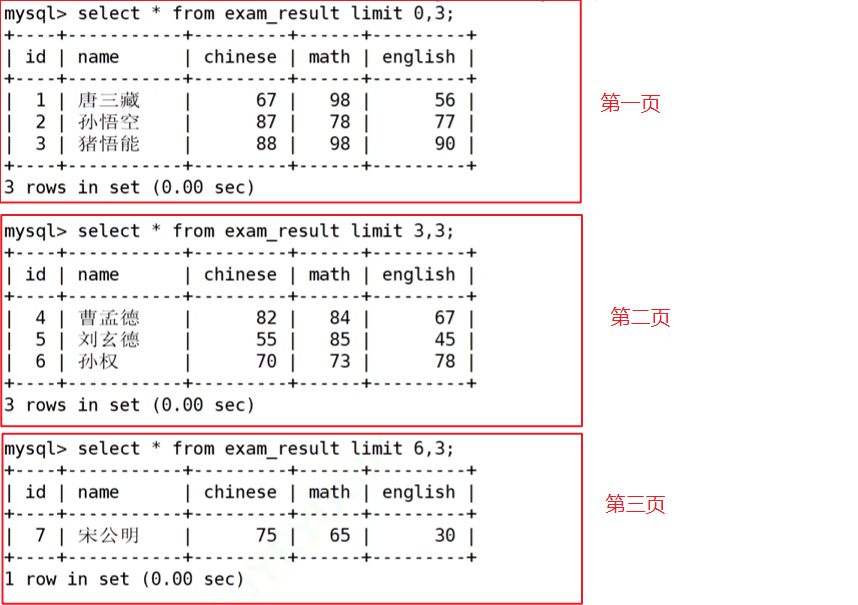
2.1.3筛选分页结果
从第n条开始筛选出s条信息
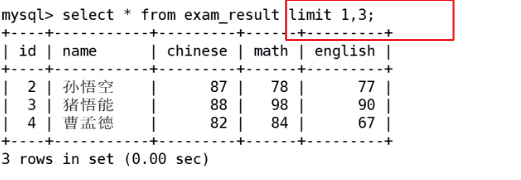
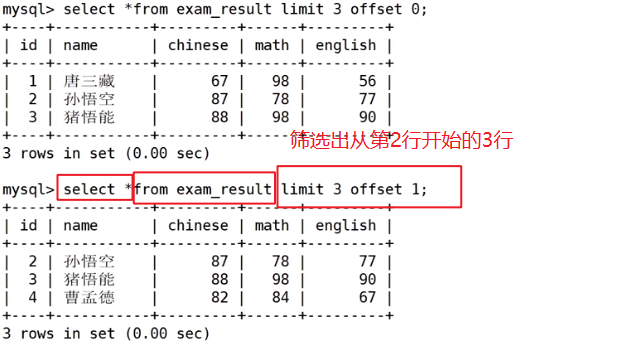
分页筛选
建议在对未知表进行查询时,进行分页筛选,因为避免因为表中数据过大,查询全表数据导致数据库卡死(数据是在磁盘上的,显示数据需要先将数据加载到内存上)
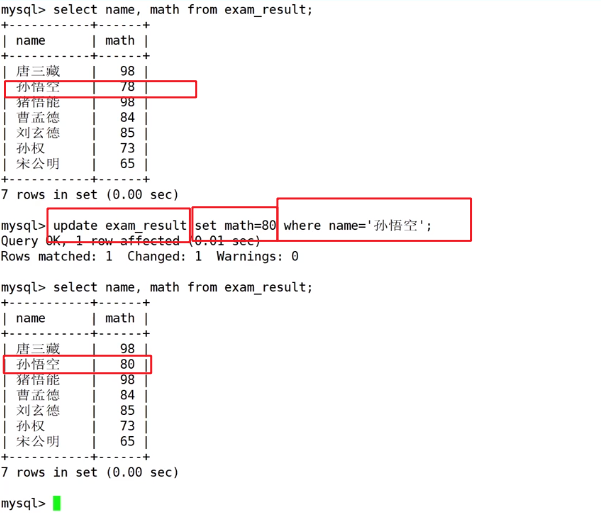
三、Update
update 表名 set 列名=值 where 谁的
将孙悟空的数学成绩更改为80
将曹孟德语文成绩修改为70、数学成绩修改为60
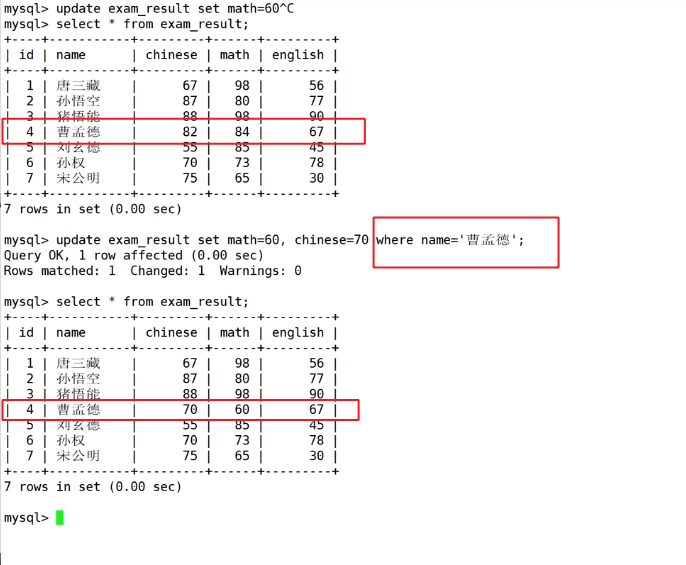
- 如果没有筛选条件所有人的数学和语文成绩都会被修改,全部修改要谨慎
将倒数后3名同学数学成绩加上30分
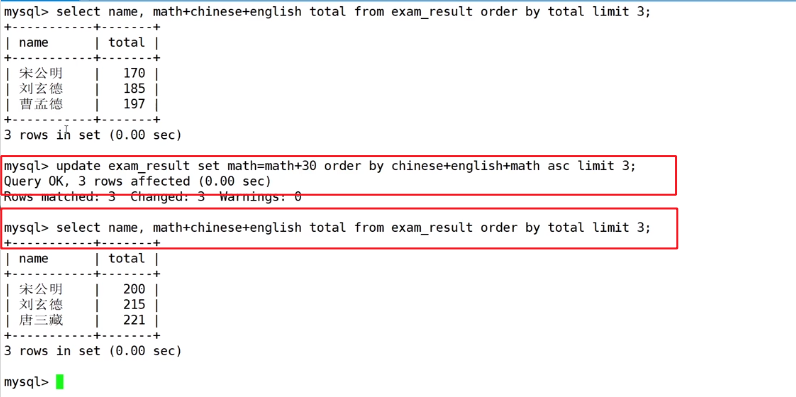
MySQL不支持+=,所以只能math=math+30,按照总成绩的升序排序,选出前3个,倒数后3名同学就选出来了。
四、Delete
delete from 表名 [where] [order by] [limit]
删除孙悟空的所有成绩
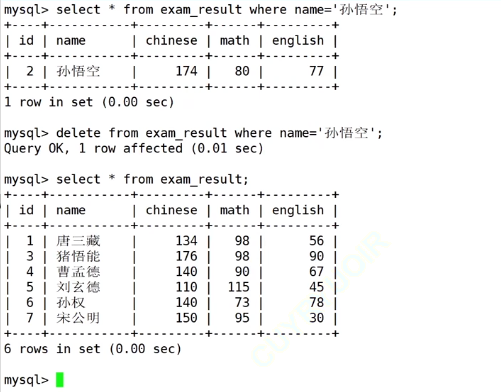
- 删除整个表中的内容,但并不会删除表结构
五、截断表
注意:这个操作慎用
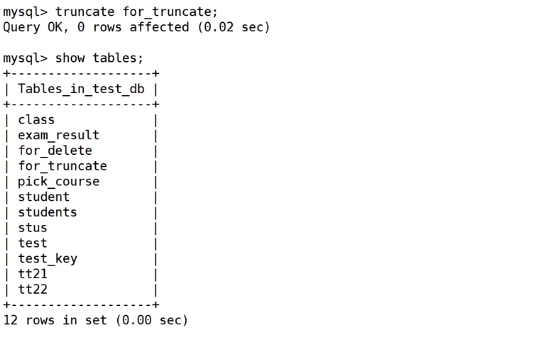
- 只能对整表操作,不能像 delete 一样针对部分数据操作;
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
- 会重置 AUTO_INCREMENT 项
六、插入查询结果
6.1案例:对表中数据去重
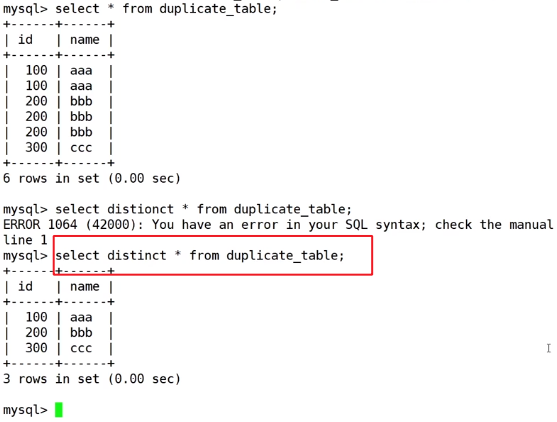
- 这里只是去重显示
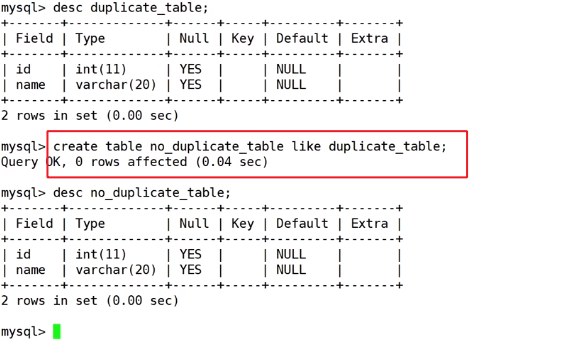
数据去重操作步骤:
1.创建一个和原表结构相同的表
2.将原表中不重复的数据筛选出来插入到新表中
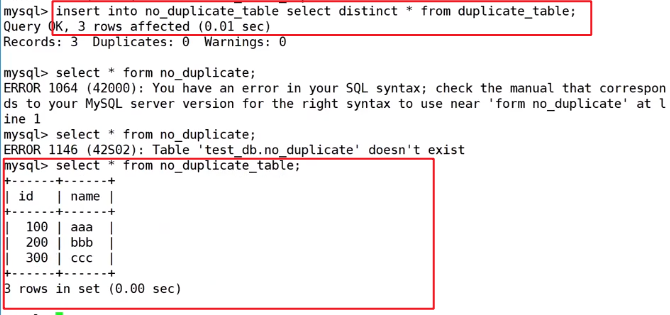
3.对原表进行重名,将新表名字改成旧表的名字

七、聚合函数
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
|---|---|
| SUM([DISTINCT] expr) | 返回查询到的数据的总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值,不是数字没有意义 |
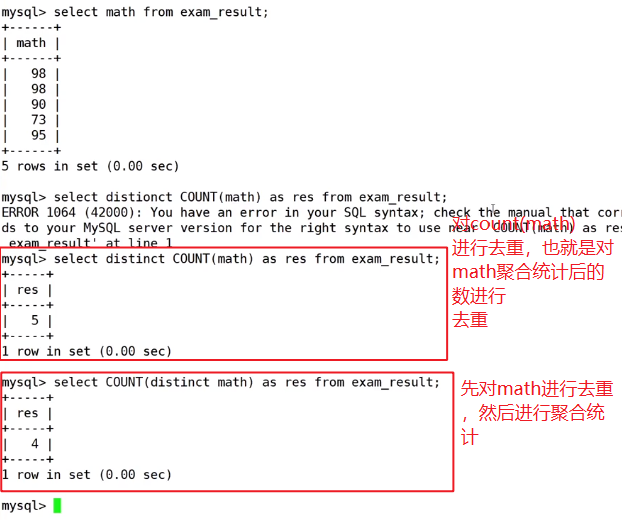
7.1count([distinct] expr)
统计有多少条信息,这里就是统计有多少个同学
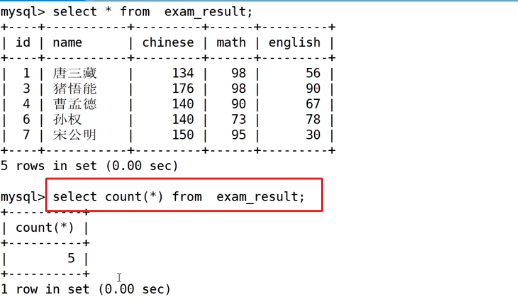
对去重后的数学成绩进行聚合统计
sum([distinct] expr)
算出数学成绩的平均值
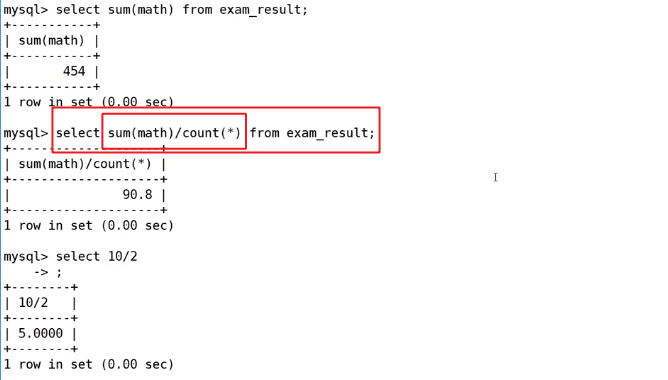
计算出英语成绩小于60分的总成绩

avg([distinct] expr)
统计出英语总成绩+语文总成绩+数学总成绩的平均值

max([distinct] expr)
计算出英语成绩的最高分

min([distinct] expr)
计算出超过70分的最小成绩

八、分组统计group by子句
scott_data.sql:
将scott_data.sql导入到数据库中
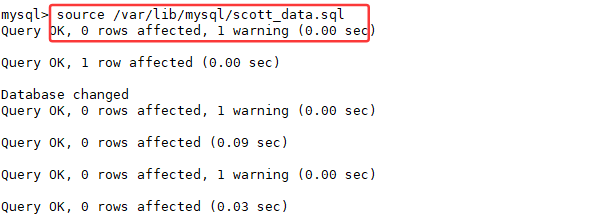
查看该数据库中有哪些表
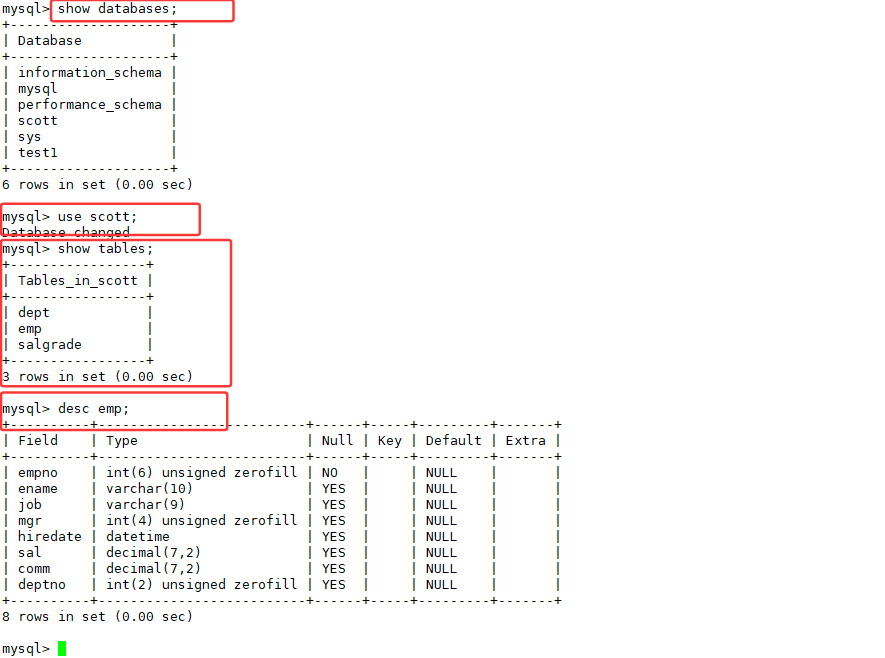
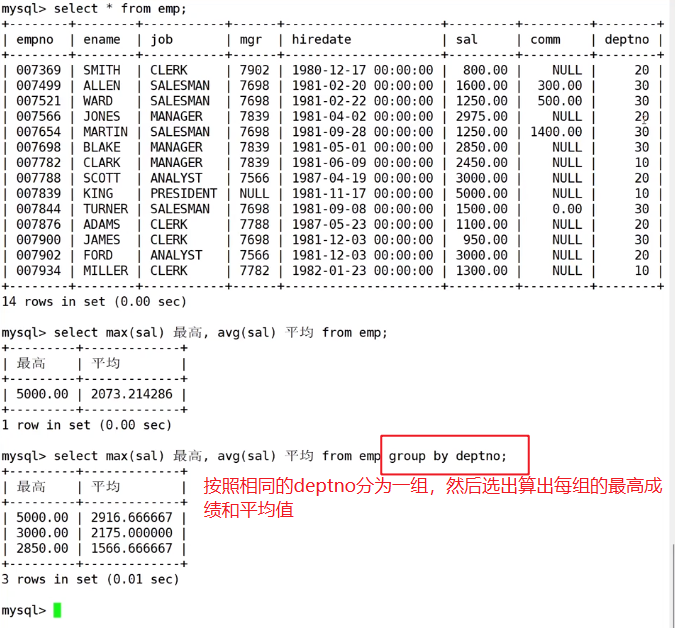
案例一:显示每个部门的平均工资和最高工资
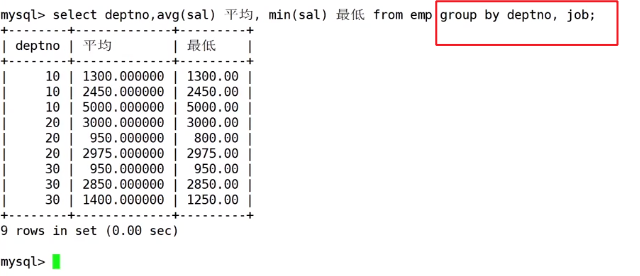
案例二:显示每个部门的每一个岗位的平均工资和最低工资
先按照部门分组,再按照岗位分组
由于相同部门下的相同岗位为一组的人名是不同的,所以是无法显示的

案例三:显示平均工资低于2000的部门和它的平均工资
步骤:
1.先将结果聚合出来(先统计出每一个部门的平均工资)
2.对聚合的结果进行判断(条件筛选出低于2000的部门)
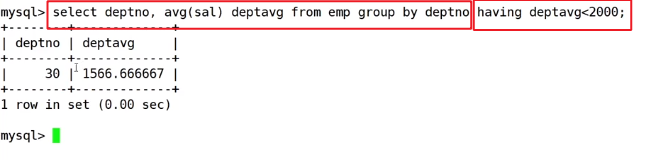
- having是对分组聚合统计的结果进行条件筛选
案例四:显示没有SMITH员工的条件下平均工资低于2000的部门和它的平均工资
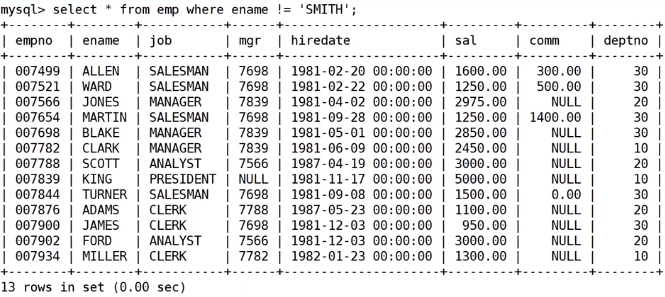
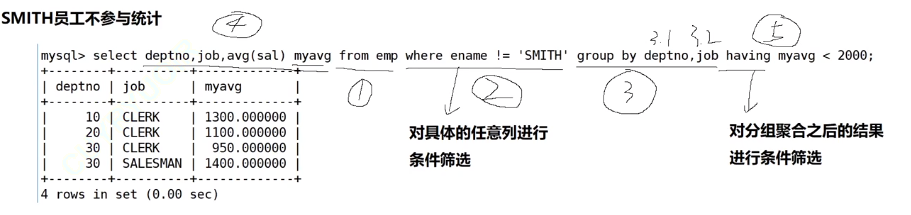
- where和having的区别在于条件筛选的阶段不同。
- 不要单纯的认为只有磁盘上的表结构才叫表,中间筛选出来的包括最终结果在逻辑上都是表。
![[蓝桥杯]螺旋折线](https://i-blog.csdnimg.cn/img_convert/499541cd8b9b5b4794f45e2d73a8c979.png)