一、PyTroch简介
PyTorch 是由 Meta(原 Facebook)开发的开源深度学习框架,以动态计算图和易用性著称,广泛应用于计算机视觉、自然语言处理等领域。其核心特性包括:
动态计算图:支持运行时灵活调整计算流程,便于调试和实验;
张量操作:通过 torch.Tensor 实现高效的多维数组运算,支持 GPU 加速;
自动微分:autograd 模块可自动计算梯度,简化反向传播实现;
模块化设计:nn.Module 提供神经网络层、损失函数等预置组件,加速模型开发。
PyTorch的前身是Torch,其底层和Torch框架一样,使用Python重新写后提供Python接口。
二、安装
登录到PyTroch官网,根据自己的实际环境配置PyTroch,获取安装命令。
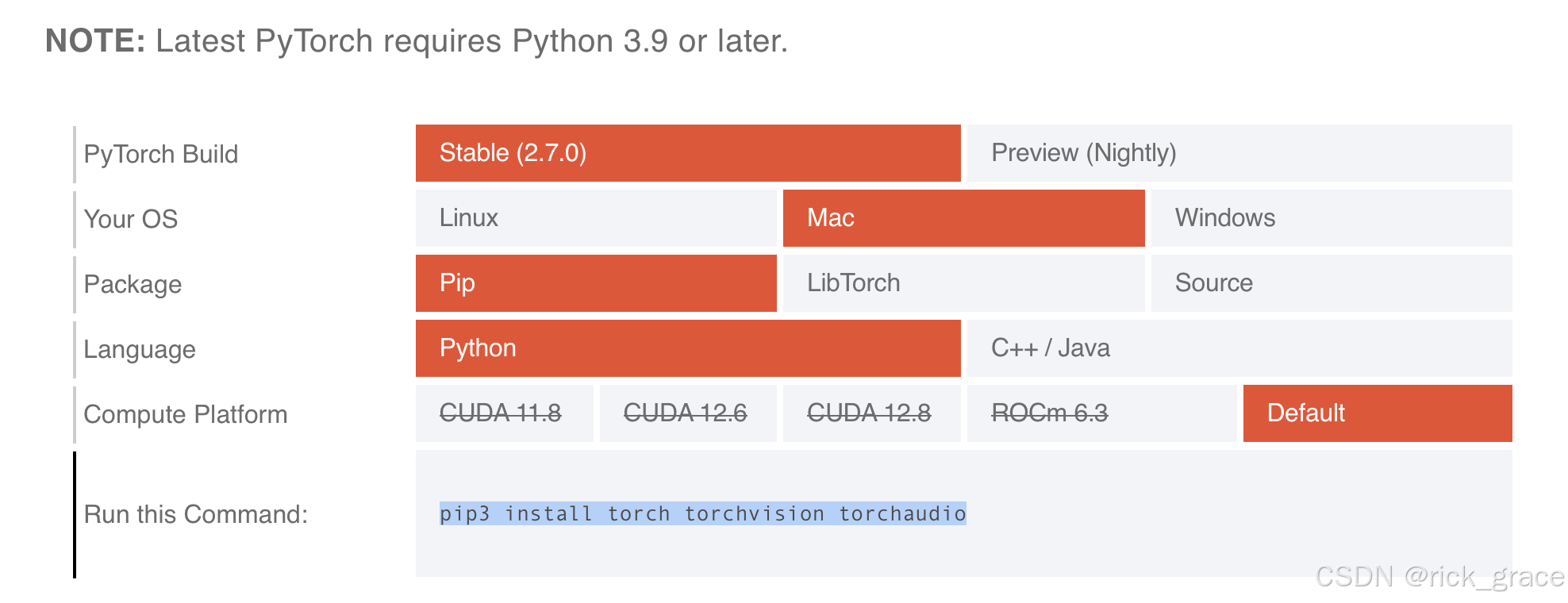
pip3 install torch torchvision torchaudio
三、案例
以下是一个经典学习 Demo——手写数字识别(MNIST 数据集)的代码框架:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import matplotlib# 设置matplotlib支持中文显示
matplotlib.rcParams['font.family'] = ['Arial Unicode MS', 'sans-serif']
# 确保显示负号
matplotlib.rcParams['axes.unicode_minus'] = False# 数据加载
train_data = torchvision.datasets.MNIST(root='./data', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.MNIST(root='./data', train=False, download=True,transform=torchvision.transforms.ToTensor())# 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size)# 定义简单神经网络
class Net(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(28 * 28, 10)def forward(self, x):return self.fc(x.view(x.size(0), -1))# 训练模型
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 用于记录训练过程的列表
train_losses = []
test_accuracies = []# 训练循环
num_epochs = 10
for epoch in range(num_epochs):model.train() # 设置为训练模式running_loss = 0.0for inputs, labels in train_loader:# 清零梯度optimizer.zero_grad()# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化loss.backward()optimizer.step()running_loss += loss.item()# 计算平均损失并记录epoch_loss = running_loss / len(train_loader)train_losses.append(epoch_loss)# 在测试集上评估模型model.eval()correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()# 计算准确率并记录accuracy = 100 * correct / totaltest_accuracies.append(accuracy)# 打印每轮的平均损失和准确率print(f'Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}, Accuracy: {accuracy:.2f}%')# 在测试集上评估最终模型
model.eval()
correct = 0
total = 0
with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'最终测试集准确率: {100 * correct / total:.2f}%')# 保存模型
torch.save(model.state_dict(), 'mnist_model.pth')
print("模型已保存为 mnist_model.pth")# 可视化训练过程
plt.figure(figsize=(12, 5))# 绘制训练损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs + 1), train_losses, 'b-', label='训练损失')
plt.title('训练损失随轮次变化')
plt.xlabel('轮次')
plt.ylabel('损失')
plt.legend()
plt.grid(True)# 绘制测试准确率曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs + 1), test_accuracies, 'r-', label='测试准确率')
plt.title('测试准确率随轮次变化')
plt.xlabel('轮次')
plt.ylabel('准确率 (%)')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.savefig('training_visualization.png')
plt.show()# 可视化一些测试样本预测结果
plt.figure(figsize=(10, 10))
model.eval()# 获取一批测试数据
dataiter = iter(test_loader)
images, labels = next(dataiter)# 预测这批数据
outputs = model(images)
_, predicted = torch.max(outputs, 1)# 展示前25个样本
for i in range(25):plt.subplot(5, 5, i + 1)plt.imshow(images[i].squeeze().numpy(), cmap='gray')plt.title(f'预测: {predicted[i]}\n实际: {labels[i]}',color=("green" if predicted[i] == labels[i] else "red"))plt.axis('off')plt.tight_layout()
plt.savefig('prediction_samples.png')
plt.show()四、案例详解
手写数字识别模型训练流程
1. 整体流程图
2. 详细步骤解析
步骤一:数据准备
加载MNIST数据集并准备数据加载器,用于批量处理数据。
# 数据加载
train_data = torchvision.datasets.MNIST(root='./data', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.MNIST(root='./data', train=False, download=True,transform=torchvision.transforms.ToTensor())# 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size)
关键点:
torchvision.datasets.MNIST:加载MNIST手写数字数据集DataLoader:创建数据加载器,支持批量处理batch_size=64:每批处理64个样本shuffle=True:打乱训练数据顺序,提高模型泛化能力
步骤二:构建神经网络模型
定义一个简单的全连接神经网络。
class Net(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(28 * 28, 10)def forward(self, x):return self.fc(x.view(x.size(0), -1))# 实例化模型
model = Net()
关键点:
- 模型结构简单:将28×28的图像展平后,通过一个全连接层映射到10个输出(0-9的数字)
x.view(x.size(0), -1):将每个批次的图像(batch_size, 1, 28, 28)展平为(batch_size, 784)
步骤三:定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
关键点:
CrossEntropyLoss:分类问题的标准损失函数SGD:随机梯度下降优化器lr=0.01:学习率,控制每次参数更新的步长
步骤四:训练循环
这是核心部分,包含完整的训练过程。
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):model.train() # 设置为训练模式running_loss = 0.0for inputs, labels in train_loader:# 清零梯度optimizer.zero_grad()# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化loss.backward()optimizer.step()running_loss += loss.item()# 计算平均损失并记录epoch_loss = running_loss / len(train_loader)train_losses.append(epoch_loss)# 在测试集上评估模型model.eval()correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()# 计算准确率并记录accuracy = 100 * correct / totaltest_accuracies.append(accuracy)# 打印每轮的平均损失和准确率print(f'Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}, Accuracy: {accuracy:.2f}%')
关键点:
-
每个训练轮次(epoch)中的步骤:
model.train():设置模型为训练模式optimizer.zero_grad():清除上一批次的梯度outputs = model(inputs):前向传播,获取预测结果loss = criterion(outputs, labels):计算损失loss.backward():反向传播,计算梯度optimizer.step():更新模型参数
-
每轮训练后的评估:
model.eval():设置模型为评估模式with torch.no_grad():不计算梯度,提高效率_, predicted = torch.max(outputs.data, 1):获取预测类别- 计算并记录准确率
步骤五:模型评估
在所有训练完成后,对模型进行最终评估。
model.eval()
correct = 0
total = 0
with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'最终测试集准确率: {100 * correct / total:.2f}%')
步骤六:可视化训练过程
使用matplotlib绘制训练过程中的损失和准确率变化。
# 可视化训练过程
plt.figure(figsize=(12, 5))# 绘制训练损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs + 1), train_losses, 'b-', label='训练损失')
plt.title('训练损失随轮次变化')
plt.xlabel('轮次')
plt.ylabel('损失')
plt.legend()
plt.grid(True)# 绘制测试准确率曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs + 1), test_accuracies, 'r-', label='测试准确率')
plt.title('测试准确率随轮次变化')
plt.xlabel('轮次')
plt.ylabel('准确率 (%)')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.savefig('training_visualization.png')
plt.show()
可视化样本预测结果:
# 可视化一些测试样本预测结果
plt.figure(figsize=(10, 10))
model.eval()# 获取一批测试数据
dataiter = iter(test_loader)
images, labels = next(dataiter)# 预测这批数据
outputs = model(images)
_, predicted = torch.max(outputs, 1)# 展示前25个样本
for i in range(25):plt.subplot(5, 5, i + 1)plt.imshow(images[i].squeeze().numpy(), cmap='gray')plt.title(f'预测: {predicted[i]}\n实际: {labels[i]}', color=("green" if predicted[i] == labels[i] else "red"))plt.axis('off')plt.tight_layout()
plt.savefig('prediction_samples.png')
plt.show()
步骤七:保存模型
torch.save(model.state_dict(), 'mnist_model.pth')
print("模型已保存为 mnist_model.pth")
3. 核心概念总结
- 数据批处理:通过DataLoader实现批量加载和处理数据,提高训练效率
- 梯度下降:模型通过不断计算损失并调整参数,使损失值最小化
- 前向传播:将输入数据送入模型,得到预测结果
- 反向传播:根据损失值计算梯度,并将梯度从输出层反向传递到输入层
- 参数更新:根据计算出的梯度,通过优化器更新模型参数
- 训练-评估循环:交替进行训练和评估,监控模型性能变化
4. 训练技巧
- 学习率选择:学习率过大会导致不收敛,过小会导致训练速度慢
- 批大小选择:较大的批大小可提高训练速度,但可能需要更多内存
- 训练轮次:根据模型性能变化确定合适的训练轮次,避免过拟合
- 模型评估:定期在测试集上评估模型,及时发现问题
5. 改进方向
- 模型结构:可以使用更复杂的网络结构,如卷积神经网络(CNN)
- 数据增强:通过旋转、缩放等方式增加训练样本的多样性
- 学习率调度:在训练过程中动态调整学习率
- 正则化:添加dropout或L2正则化,减少过拟合风险
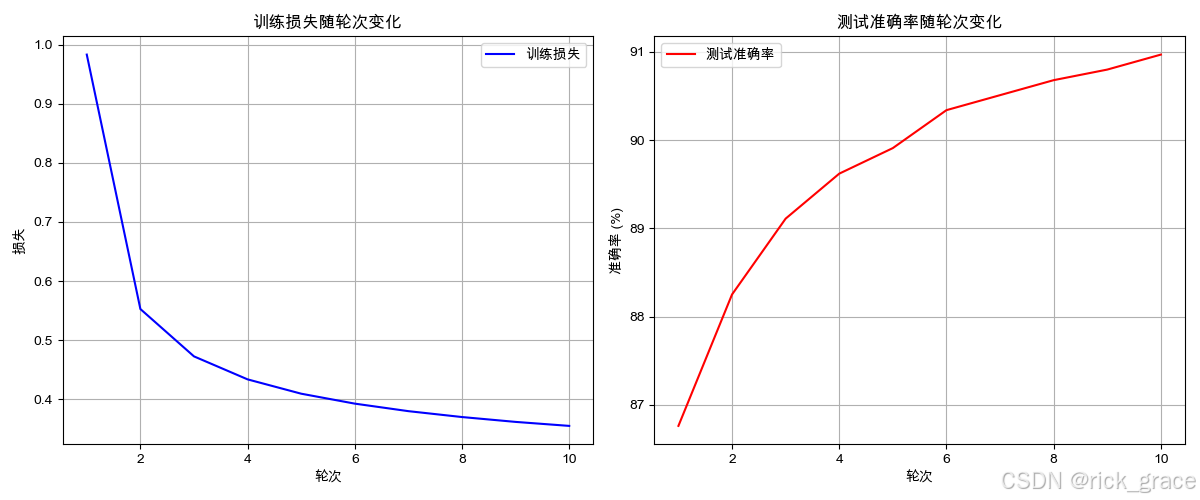
6. 最终成果
- 训练损失曲线:
- 左侧图表:显示训练损失随训练轮次变化的曲线
- 右侧图表:显示测试准确率随训练轮次变化的曲线
训练过程数据记录:
- 每个训练轮次都记录训练损失和测试准确率
- 每轮结束时显示当前轮次的损失和准确率
2.预测样本结果:
- 展示25个测试样本及其预测结果
- 正确预测的标签显示为绿色,错误预测的标签显示为红色

可视化的优点: - 直观地了解模型的学习过程
- 观察模型在哪些数字上容易出错
- 判断模型是否过拟合或欠拟合
- 为模型调优提供依据
- 模型文件:
mnist_model.pth
通过上述步骤,我们完成了一个简单的手写数字识别模型的训练和评估,该模型在MNIST测试集上能达到约90%的准确率。
对于这个简单的单层线性网络来说,接近90%的准确率已经很不错了。如果你想进一步提高准确率,可以考虑使用卷积神经网络(CNN)结构,它更适合处理图像数据。
扩展
扩展一:使用己训练好的模型文件,识别真实手写数字图片
import torch
import torchvision.transforms as transforms
from PIL import Image, ImageOps
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import cv2
import os
import sys# 设置matplotlib支持中文显示
matplotlib.rcParams['font.family'] = ['Arial Unicode MS', 'sans-serif']
# 确保显示负号
matplotlib.rcParams['axes.unicode_minus'] = False# 定义与训练模型相同的网络结构
class Net(torch.nn.Module):def __init__(self):super().__init__()self.fc = torch.nn.Linear(28 * 28, 10)def forward(self, x):return self.fc(x.view(x.size(0), -1))def preprocess_image(image_path):"""预处理图像以适应MNIST模型输入"""# 读取图像img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)if img is None:print(f"无法读取图像: {image_path}")return None# 显示原始图像plt.figure(figsize=(10, 5))plt.subplot(1, 3, 1)plt.title("原始图像")plt.imshow(img, cmap='gray')# 二值化处理_, binary_img = cv2.threshold(img, 128, 255, cv2.THRESH_BINARY_INV)plt.subplot(1, 3, 2)plt.title("二值化图像")plt.imshow(binary_img, cmap='gray')# 保存二值化图像用于调试cv2.imwrite('binary_image.png', binary_img)# 查找轮廓contours, _ = cv2.findContours(binary_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 创建一个彩色图像用于绘制边界框color_img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)# 存储提取的数字图像digit_images = []bounding_boxes = []# 处理每个轮廓for contour in contours:# 过滤掉太小的轮廓if cv2.contourArea(contour) < 100:continue# 获取边界框x, y, w, h = cv2.boundingRect(contour)# 保存边界框信息(用于后续绘制结果)bounding_boxes.append((x, y, w, h))# 绘制边界框cv2.rectangle(color_img, (x, y), (x + w, y + h), (0, 255, 0), 2)# 提取数字区域digit = binary_img[y:y+h, x:x+w]# 添加边框,确保数字居中padding = int(max(w, h) * 0.3)digit_padded = np.pad(digit, ((padding, padding), (padding, padding)), 'constant', constant_values=0)# 调整为28x28大小,符合MNIST模型输入要求digit_resized = cv2.resize(digit_padded, (28, 28), interpolation=cv2.INTER_AREA)# 保存处理后的数字图像digit_images.append(digit_resized)# 显示带有边界框的图像plt.subplot(1, 3, 3)plt.title("检测到的数字")plt.imshow(cv2.cvtColor(color_img, cv2.COLOR_BGR2RGB))# 保存带有边界框的图像cv2.imwrite('output_image_with_boxes.png', color_img)plt.tight_layout()plt.savefig('preprocessed_image.png')plt.show()return digit_images, bounding_boxes, color_imgdef load_model(model_path):"""加载训练好的模型"""# 检查模型文件是否存在if not os.path.exists(model_path):print(f"模型文件不存在: {model_path}")return None# 创建模型实例model = Net()try:# 加载模型参数model.load_state_dict(torch.load(model_path))model.eval() # 设置为评估模式print(f"成功加载模型: {model_path}")return modelexcept Exception as e:print(f"加载模型失败: {e}")return Nonedef predict_digits(model, digit_images):"""使用模型预测图像中的数字"""if not digit_images:print("没有检测到任何数字")return []predictions = []confidence_scores = []transform = transforms.Compose([transforms.ToTensor(),])# 预测每个数字for digit_img in digit_images:# 转换为PIL图像pil_img = Image.fromarray(digit_img)# 应用变换tensor = transform(pil_img)tensor = tensor.unsqueeze(0) # 添加批次维度# 进行预测with torch.no_grad():outputs = model(tensor)probabilities = torch.nn.functional.softmax(outputs, dim=1)confidence, predicted = torch.max(probabilities, 1)predictions.append(predicted.item())confidence_scores.append(confidence.item())return predictions, confidence_scoresdef draw_results(image, predictions, bounding_boxes, confidence_scores):"""在图像上绘制预测结果"""result_img = image.copy()for i, ((x, y, w, h), pred, conf) in enumerate(zip(bounding_boxes, predictions, confidence_scores)):# 绘制预测结果和置信度text = f"{pred} ({conf:.2f})"cv2.putText(result_img, text, (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)# 显示结果图像plt.figure(figsize=(10, 8))plt.imshow(cv2.cvtColor(result_img, cv2.COLOR_BGR2RGB))plt.title("预测结果")plt.axis('off')plt.savefig('prediction_result.png')plt.show()return result_imgdef main():# 检查命令行参数if len(sys.argv) > 1:image_path = sys.argv[1]else:# 提示用户输入图像路径image_path = input("请输入手写数字图像的路径: ")# 模型路径model_path = '/Users/luoshixiang/Documents/project/AI/mnist_model.pth'# 加载模型model = load_model(model_path)if model is None:return# 预处理图像processed_result = preprocess_image(image_path)if processed_result is None:returndigit_images, bounding_boxes, color_img = processed_result# 预测数字predictions, confidence_scores = predict_digits(model, digit_images)if not predictions:print("未能成功预测任何数字")return# 输出预测结果print("预测结果:")for i, (pred, conf) in enumerate(zip(predictions, confidence_scores)):print(f"数字 {i+1}: {pred}, 置信度: {conf:.4f}")# 在图像上绘制结果result_img = draw_results(color_img, predictions, bounding_boxes, confidence_scores)# 保存结果图像cv2.imwrite('final_prediction.png', result_img)print("结果已保存为 'final_prediction.png'")if __name__ == "__main__":main()扩展二:使用卷积神经网络(CNN)来提升手写数字识别模型的能力
为什么CNN更适合图像识别?
- 局部感知: 卷积层能够捕获图像的局部特征,如边缘、纹理等
- 参数共享: 同一个卷积核在整个图像上滑动,大大减少了参数数量
- 空间层次结构: 通过多层卷积和池化,模型能够学习从低级到高级的特征表示
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import matplotlib# 设置matplotlib支持中文显示
matplotlib.rcParams['font.family'] = ['Arial Unicode MS', 'sans-serif']
# 确保显示负号
matplotlib.rcParams['axes.unicode_minus'] = False# 数据加载
train_data = torchvision.datasets.MNIST(root='./data', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.MNIST(root='./data', train=False, download=True,transform=torchvision.transforms.ToTensor())# 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size)# 定义CNN网络结构
class CNN(nn.Module):def __init__(self):super().__init__()# 第一个卷积层: 输入1通道,输出32通道,卷积核大小3x3self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2)# 第二个卷积层: 输入32通道,输出64通道,卷积核大小3x3self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2)# 全连接层# 经过两次池化,图像尺寸从28x28变为7x7,通道数为64self.fc1 = nn.Linear(64 * 7 * 7, 128)self.relu3 = nn.ReLU()self.dropout = nn.Dropout(0.5) # 添加dropout防止过拟合self.fc2 = nn.Linear(128, 10) # 输出10个类别def forward(self, x):# 第一个卷积块x = self.conv1(x) # 输出: batch_size x 32 x 28 x 28x = self.relu1(x)x = self.pool1(x) # 输出: batch_size x 32 x 14 x 14# 第二个卷积块x = self.conv2(x) # 输出: batch_size x 64 x 14 x 14x = self.relu2(x)x = self.pool2(x) # 输出: batch_size x 64 x 7 x 7# 展平操作x = x.view(x.size(0), -1) # 输出: batch_size x (64*7*7)# 全连接层x = self.fc1(x)x = self.relu3(x)x = self.dropout(x)x = self.fc2(x)return x# 训练模型
model = CNN()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器# 用于记录训练过程的列表
train_losses = []
test_accuracies = []# 训练循环
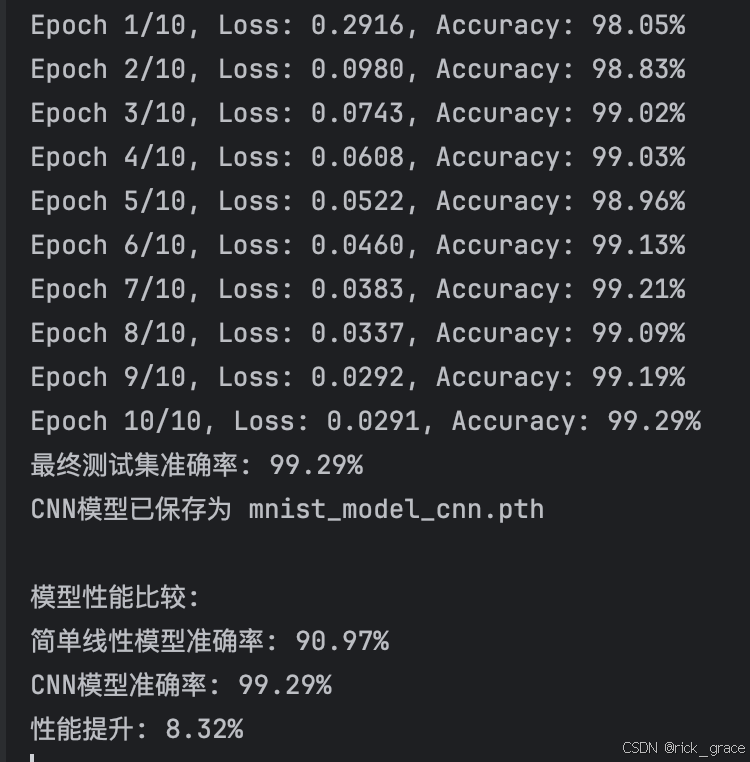
num_epochs = 10
for epoch in range(num_epochs):model.train() # 设置为训练模式running_loss = 0.0for inputs, labels in train_loader:# 清零梯度optimizer.zero_grad()# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化loss.backward()optimizer.step()running_loss += loss.item()# 计算平均损失并记录epoch_loss = running_loss / len(train_loader)train_losses.append(epoch_loss)# 在测试集上评估模型model.eval()correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()# 计算准确率并记录accuracy = 100 * correct / totaltest_accuracies.append(accuracy)# 打印每轮的平均损失和准确率print(f'Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}, Accuracy: {accuracy:.2f}%')# 在测试集上评估最终模型
model.eval()
correct = 0
total = 0
with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'最终测试集准确率: {100 * correct / total:.2f}%')# 保存模型
torch.save(model.state_dict(), 'mnist_model_cnn.pth')
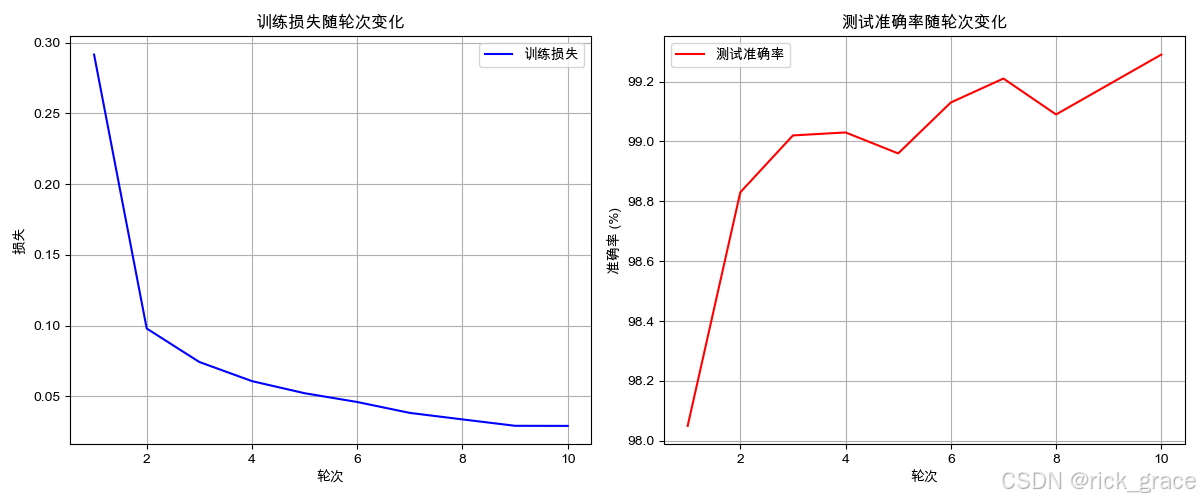
print("CNN模型已保存为 mnist_model_cnn.pth")# 可视化训练过程
plt.figure(figsize=(12, 5))# 绘制训练损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs + 1), train_losses, 'b-', label='训练损失')
plt.title('训练损失随轮次变化')
plt.xlabel('轮次')
plt.ylabel('损失')
plt.legend()
plt.grid(True)# 绘制测试准确率曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs + 1), test_accuracies, 'r-', label='测试准确率')
plt.title('测试准确率随轮次变化')
plt.xlabel('轮次')
plt.ylabel('准确率 (%)')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.savefig('training_visualization_cnn.png')
plt.show()# 可视化一些测试样本预测结果
plt.figure(figsize=(10, 10))
model.eval()# 获取一批测试数据
dataiter = iter(test_loader)
images, labels = next(dataiter)# 预测这批数据
outputs = model(images)
_, predicted = torch.max(outputs, 1)# 展示前25个样本
for i in range(25):plt.subplot(5, 5, i + 1)plt.imshow(images[i].squeeze().numpy(), cmap='gray')plt.title(f'预测: {predicted[i]}\n实际: {labels[i]}',color=("green" if predicted[i] == labels[i] else "red"))plt.axis('off')plt.tight_layout()
plt.savefig('prediction_samples_cnn.png')
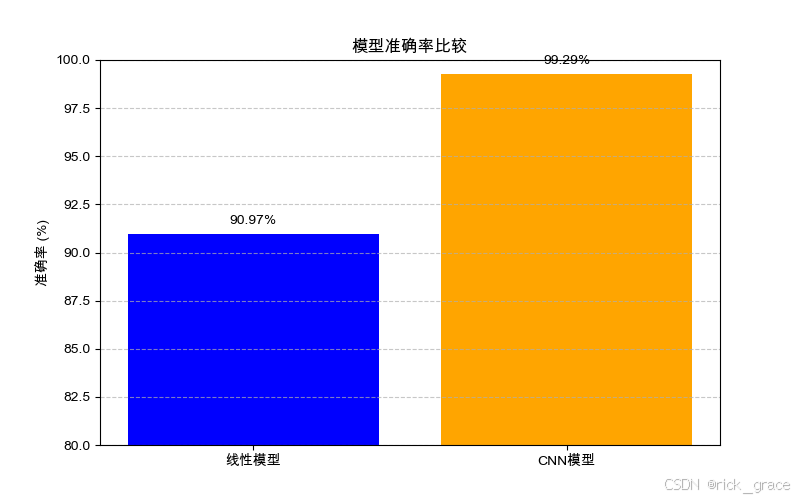
plt.show()# 比较CNN模型与简单线性模型的性能
try:# 加载之前的简单线性模型class Net(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(28 * 28, 10)def forward(self, x):return self.fc(x.view(x.size(0), -1))linear_model = Net()linear_model.load_state_dict(torch.load('mnist_model.pth'))linear_model.eval()# 评估线性模型correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:outputs = linear_model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()linear_accuracy = 100 * correct / total# 显示比较结果print(f'\n模型性能比较:')print(f'简单线性模型准确率: {linear_accuracy:.2f}%')print(f'CNN模型准确率: {accuracy:.2f}%')print(f'性能提升: {accuracy - linear_accuracy:.2f}%')# 绘制比较图表plt.figure(figsize=(8, 5))models = ['线性模型', 'CNN模型']accuracies = [linear_accuracy, accuracy]plt.bar(models, accuracies, color=['blue', 'orange'])plt.title('模型准确率比较')plt.ylabel('准确率 (%)')plt.ylim(80, 100) # 设置y轴范围以便更好地显示差异# 在柱状图上显示准确率值for i, v in enumerate(accuracies):plt.text(i, v + 0.5, f'{v:.2f}%', ha='center')plt.grid(axis='y', linestyle='--', alpha=0.7)plt.savefig('model_comparison.png')plt.show()except Exception as e:print(f"无法加载之前的模型进行比较: {e}")这个CNN模型包含:
- 两个卷积层,用于提取图像特征
- 两个池化层,用于降低特征维度并保留主要特征
- Dropout层,用于防止过拟合
- 全连接层,用于最终分类

其他
如果想进一步改进可视化效果,你还可以考虑:
添加交互式图表(使用Plotly库)
记录并可视化更多指标(如混淆矩阵)
添加实时可视化,在训练过程中动态更新图表