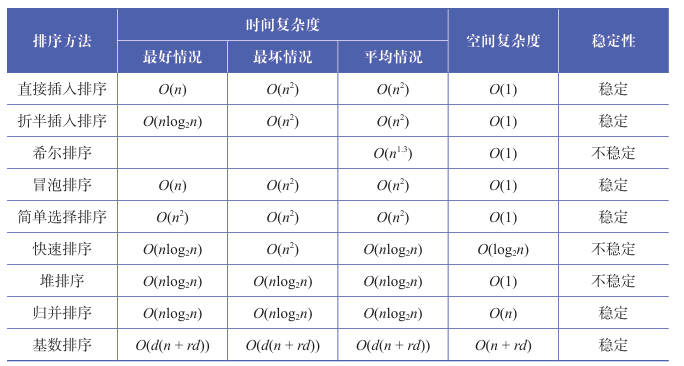
如何评估 RAG 的分块策略
我对 RAG(检索增强生成模型)进行了深入研究,深知分块在任何 RAG 流水线中都至关重要。
我接触过的许多人坚信更好的模型能够提升 RAG 的性能。有些人则对向量数据库寄予厚望。即便那些认同分块重要性的人,也认为它对系统的改进幅度有限。
大多数人认为,大上下文窗口会取代分块策略的需求。
但分块技术是长期存在的,它非常有效,是任何 RAG 项目的必备要素。
然而,一个关键问题仍未得到解答:如何为项目挑选最佳的分块策略呢?
常用的分块策略有很多:递归字符分割、语义分块以及代理分块,llm分块等等,甚至还主张将聚类作为代理分块的快速且廉价的替代方案。
但残酷的事实是,没有任何一种策略总是表现良好。你无法仅凭项目的性质来猜测哪种策略会奏效。
唯一的办法就是将它们都试一遍,找出最适合的那一个。
所以,这就是我的方法。
首先对文档进行抽样
如果你正在开发一个生产级应用,可能需要处理数百 GB 的数据。
但你不可能用所有这些数据来试验分块策略。
成本是一个显而易见的原因。评估过程会使用 LLM(大型语言模型)推理,无论是通过 API 调用还是本地托管的 LLM 推理,都需要花费一定的成本。
另一个问题是评估的耗时。你的项目通常都有时间限制,你可不想浪费数周时间来评估分块技术。
想低成本且快速地推进?那就抽样吧。
但一定要确保你的样本能够准确地代表总体。
说起来容易做起来难。但鉴于项目的性质,分层抽样可能是个不错的选择。
例如,如果你有 100 份客户交付的 PPT、50 份案例研究 PDF 文档以及 300 份会议记录,你可以从每个类别中各抽取 10% 作为样本。这样就能确保每个群体都在样本中有所体现。
一旦有了样本,就可以进入下一步了。
创建测试集
进行评估需要问题,LLM 将根据这些问题来评估答案。
最好是由人类专家手动创建这些问题集。然而,并非每个组织都有这样的条件。领域专家的时间宝贵,通常无法用于研发工作。
在这种情况下,你可以借助 LLM 来帮忙。
LLM 可以根据样本文档生成问题。尽管我一直说 RAG 中的增强功能不需要强大的 LLM,但这个步骤却需要。选择一个推理能力出色的模型来创建高质量的问题集。
下面的代码可以帮助你开始,根据具体需求进行调整。
def create_test_questions(documents: List[Document], num_questions: int = 10) -> List[Dict[str, str]]:"""从文档中生成测试问题"""questions = []# 为问题生成采样文本sample_texts = []for doc in documents[:3]: # 使用前 3 份文档words = doc.page_content.split()[:500] # 前 500 个单词sample_texts.append(" ".join(words))combined_text = "\n\n".join(sample_texts)prompt = f"""根据以下文本,生成 {num_questions} 个多样化的问题,这些问题可以通过提供的信息来回答。文本:{combined_text}只返回问题,每个问题占一行,不要编号或添加额外文本。"""response = llm.invoke(prompt)question_lines = [q.strip() for q in response.content.split('\n') if q.strip()]for i, question in enumerate(question_lines[:num_questions]):questions.append({"question": question,"question_id": f"q_{i+1}"})return questions
上面的代码使用了 Langchain 框架。该函数将文档分成每段 500 个单词的部分,并提示 LLM 生成问题。
准备评估
LLM 评估是一个广泛的话题,我们在这里只是浅尝辄止。
我将使用 RAGAS,这是一个用于评估 RAG 的框架。它功能丰富,但我们只需要其中一小部分指标来完成这项任务。
你可以使用以下命令安装 RAGAS。
pip install ragas
# uv add ragas
如果遇到错误,尝试将 RAGAs 降级到 ragas==0.1.9。
注意:与本文相关的所有代码都在 这个笔记本 中。我将在每个部分中仅讨论该代码库的一部分。
下面的代码创建并评估了一个简单的 RAG,使用了分块策略。它使用了 Langchain 框架和 Chroma DB 作为向量存储。但如果你使用的是其他向量存储,最好用你选择的向量存储来测试代码。
from typing import List, Dict
import time
import numpy as np
from tqdm import tqdm
from datasets import Dataset
from langchain_chroma import Chroma
from ragas import evaluate
from ragas.metrics import (answer_relevancy,faithfulness,context_precision,context_recall,answer_correctness
)def evaluate_strategy(strategy_name: str,strategy,documents: List,test_questions: List[Dict[str, str]],embeddings,llm,chroma_client,top_k: int = 5) -> 'EvaluationResult':"""评估单个分块策略参数:strategy_name:正在评估的策略名称strategy:具有 chunk_documents 方法的分块策略对象documents:要分块的文档列表test_questions:问题字典列表embeddings:向量存储的嵌入函数llm:用于答案生成的语言模型chroma_client:ChromaDB 客户端实例top_k:要检索的文档数量返回:包含指标和性能数据的 EvaluationResult 对象"""print(f"\n正在评估策略:{strategy_name}")# 1. 对文档进行分块chunks = strategy.chunk_documents(documents)print(f"创建了 {len(chunks)} 个分块")# 2. 创建向量存储collection_name = f"eval_{strategy_name}_{hash(str(time.time()))}"collection_name = collection_name.replace("-", "_").replace(" ", "_")vectorstore = Chroma(collection_name=collection_name,embedding_function=embeddings,client=chroma_client)# 将分块添加到向量存储vectorstore.add_documents(chunks)# 3. 使用测试问题进行评估evaluation_data = []for q_data in tqdm(test_questions, desc="处理问题"):question = q_data["question"]# 检索上下文start_time = time.time()retrieved_docs = vectorstore.similarity_search(question, k=top_k)retrieval_time = time.time() - start_timecontexts = [doc.page_content for doc in retrieved_docs]# 生成答案start_time = time.time()context_text = "\n\n".join(contexts)prompt = f"上下文:
{context_text}问题:{question}答案:"response = llm.invoke(prompt)answer = response.contentgeneration_time = time.time() - start_time# 为 RAGAS 准备数据evaluation_data.append({"question": question,"answer": answer,"contexts": contexts,"ground_truth": answer, # 使用生成的答案作为代理"retrieval_time": retrieval_time,"generation_time": generation_time})# 4. 运行 RAGAS 评估dataset = Dataset.from_list(evaluation_data)metrics = [answer_relevancy,faithfulness,context_precision,context_recall,answer_correctness]ragas_results = evaluate(dataset, metrics=metrics)# 5. 计算统计信息avg_chunk_size = np.mean([len(chunk.page_content) for chunk in chunks])avg_retrieval_time = np.mean([d["retrieval_time"] for d in evaluation_data])avg_generation_time = np.mean([d["generation_time"] for d in evaluation_data])# 计算总体得分(加权平均值)overall_score = (ragas_results["answer_relevancy"] * 0.25 +ragas_results["faithfulness"] * 0.25 +ragas_results["context_precision"] * 0.2 +ragas_results["context_recall"] * 0.2 +ragas_results["answer_correctness"] * 0.1)result = EvaluationResult(strategy_name=strategy_name,chunk_count=len(chunks),avg_chunk_size=avg_chunk_size,retrieval_time=avg_retrieval_time,generation_time=avg_generation_time,answer_relevancy=ragas_results["answer_relevancy"],faithfulness=ragas_results["faithfulness"],context_precision=ragas_results["context_precision"],context_recall=ragas_results["context_recall"],answer_correctness=ragas_results["answer_correctness"],overall_score=overall_score)# 清理try:chroma_client.delete_collection(collection_name)except:passreturn result
我们可以用几种分块技术运行这段代码,并收集结果。每个结果包含五个评估指标。我们还计算了这些指标的加权平均值作为总体得分。结果还会包含其他重要数据,如分块大小、分块数量、检索时间和生成时间。
在返回结果之前,我们还会清理 Chroma DB,以免剩余数据影响后续策略的评估。
现在我们已经得到了评估数据,接下来可以对它们进行可视化,以便做出明智的决策,选择最佳的分块技术。
可视化评估结果
我至少会创建四种结果可视化的图表,以找到最佳的分块技术。
你可以对数据进行切片和分析,创建更有帮助的图表,但这些可以作为一个很好的起点。
在共享的笔记本中,我使用 Plotly 创建了这些图表。我也喜欢用它来创建仪表板。
以下是我要创建的图表及其用途。
性能排名
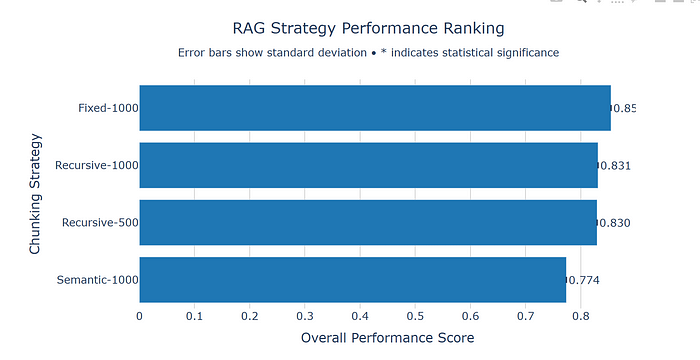
由于我们已经计算了总体得分以及五个单独评估指标的加权平均值,最合理的第一步就是将它们绘制在条形图中。
这张图表可以快速显示哪种策略表现最佳以及与其他策略的比较情况。
在上面的例子中,我们可以看到 fixed-1000 策略超过了其他三种策略。不过,除了 Semantic-1000 表现不佳外,差距似乎并不大。
分块分布与性能
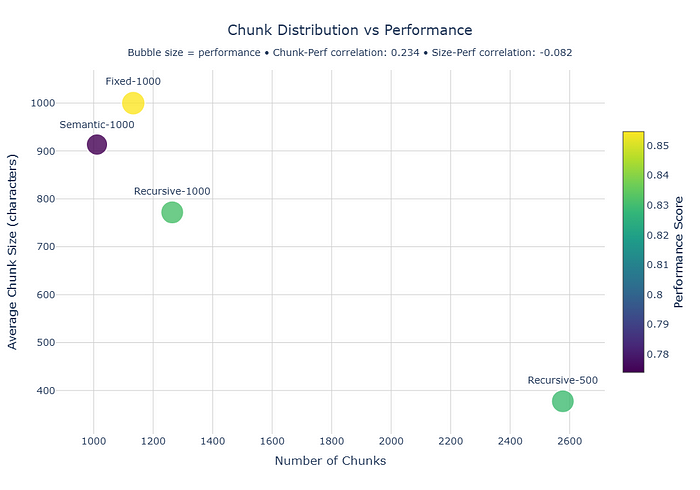
这个图表在很多方面都非常有用。
在一个图表中,我们可以看到总体性能、分块大小以及分块数量。
在 RAG 中,分块大小和数量至关重要。我们必须决定为用户输入检索多少个分块作为上下文。如果分块太大,检索到的内容可能会迅速填满 LLM 的上下文窗口。
过多的噪声可能会降低响应质量,即使上下文窗口足够大,能够容纳所有内容。
在我们的例子中,尽管 fixed-1000 策略的总体得分很高,但它创建的分块较少且较大。
在另一个极端,recursive-500 创建了过多的分块。但它们很小。然而,这种策略的表现也很好。如果我需要抽取许多文档并在生成最终答案之前对它们进行重新排序,我会选择这个策略。
指标雷达图
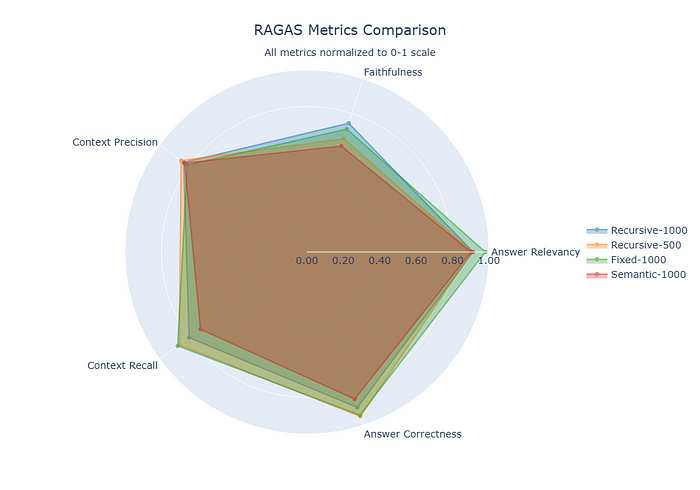
到目前为止,我们只讨论了总体得分。我们还没有关注细节。
在这个图表中,我们会关注细节。
雷达图可以揭示很多信息。对于特定应用来说,真实性可能是最重要的。然而,对于更随意的应用,高相关性得分就足够了。
你必须自己决定什么是最好的。但你需要在一个地方看到它们,而这是最好的方式。
处理时间分解
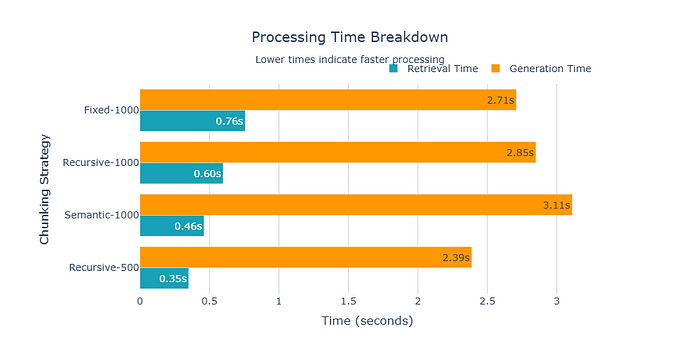
我接下来想看到的图表显示了每种策略完成所需的时间。这是一个我们需要做出的操作决策。
对于需要低延迟的应用程序来说,这个视图是必不可少的。
在我们的例子中,语义分块比其他两种策略花费的时间要长得多。递归-500 是最快的。
我们既有生成时间,也有检索时间。生成时间是创建分块所花费的时间。在实际应用中,这个数字可能会很大。因此,时间差可以为公司节省大量资金。
检索时间是导致延迟的因素。
再次强调,优先选择哪一个取决于你的具体应用。
我如何做决定(我的思考过程)
到目前为止,我们已经做了很多工作。
我们选择了样本以评估分块技术,创建了问题以评估系统,创建了一个可以改变分块技术并使用 RAG 进行评估的 RAG 流水线,最后用收集到的结果创建了图表。
现在怎么办?
让我们回顾一下我们的例子。
语义分块被排除在外。它的性能很差。它生成分块的时间也长得多。
固定-1000 的总体得分最高,但它的相关性得分主要提升了。如果这是我们最看重的,那它仍然是一个不错的选择。然而,考虑到较长的检索时间和较大的分块大小,我仍然会避免使用它。
两种递归方法在评估得分上都表现良好,但它们的分块大小、生成时间和检索时间差异很大。
我已经说过,如果我使用重新排序模型,我会选择递归-500。然而,有了处理时间的额外信息,我现在认为这是最佳选择。
最后
分块成就了 RAG,它是 RAG 的核心。
我们在分块技术上投入的时间越多,我们的 RAG 应用就会越有帮助。
然而,不同的应用需要优先考虑不同的方面。因此,我们需要系统地评估分块技术。