【Python连接数据库基础 02】SQLAlchemy核心实战:SQL表达式构建与执行完全指南
关键词:SQLAlchemy Core、SQL表达式、数据库查询、Python ORM、表达式语言、数据库操作、查询构建、SQLAlchemy教程
摘要:本文深入讲解SQLAlchemy Core的核心功能,从基础的表定义到复杂的SQL表达式构建。通过生动的类比和实际案例,帮助你掌握SQLAlchemy表达式语言的精髓,学会用Python代码优雅地构建和执行各种SQL查询,提升数据库操作的效率和可维护性。
引言:为什么选择SQLAlchemy Core?
想象一下,你正在用积木搭建一座复杂的城堡。传统的SQL就像是直接用胶水粘合积木块,一旦粘好就很难修改。而SQLAlchemy Core就像是一套智能的积木系统,每个积木块都可以灵活组合,随时拆卸重组,最终搭建出你想要的任何结构。
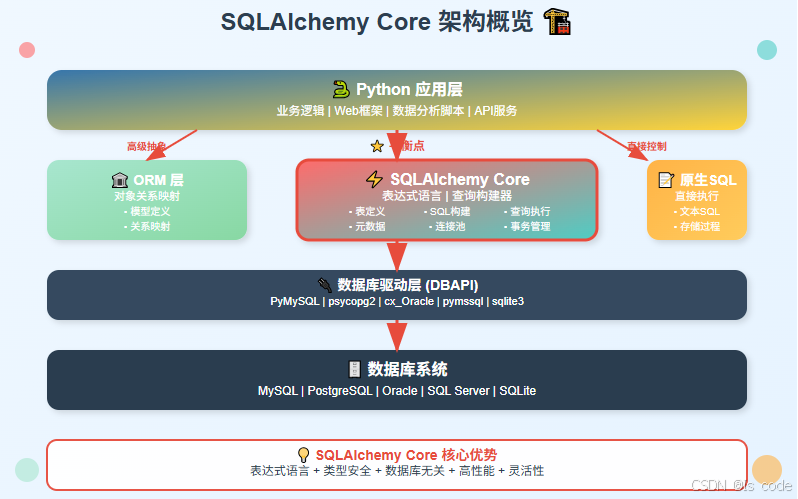
SQLAlchemy Core位于原生SQL和ORM之间,它提供了一种"表达式语言",让你既能享受SQL的强大功能,又能获得Python代码的灵活性和可维护性。
第一步:理解SQLAlchemy Core的核心概念
什么是表达式语言?
表达式语言就像是"SQL的Python翻译版"。它把SQL的各个组成部分(表、字段、条件、函数等)都变成了Python对象,你可以像搭积木一样组合它们。
# 传统SQL写法
sql = "SELECT name, price FROM products WHERE price > 100 AND category = 'electronics'"# SQLAlchemy Core表达式语言写法
from sqlalchemy import select, and_query = select([products.c.name, products.c.price]).where(and_(products.c.price > 100,products.c.category == 'electronics')
)
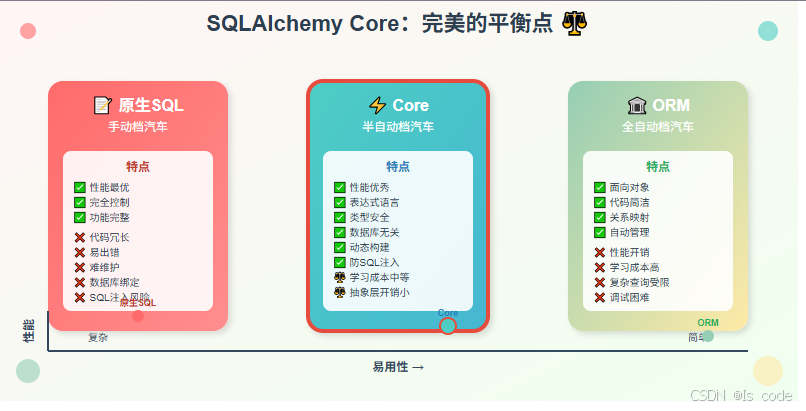
Core vs ORM:选择的艺术
SQLAlchemy Core就像是"半自动档汽车",比手动档(原生SQL)更容易操作,比全自动档(ORM)更灵活可控。
第二步:环境准备与基础配置
安装和导入
# 安装SQLAlchemy
# pip install sqlalchemy pymysqlfrom sqlalchemy import (create_engine, MetaData, Table, Column, Integer, String, Float, DateTime, Boolean,select, insert, update, delete, and_, or_, func
)
from datetime import datetime
import pandas as pd# 创建引擎 - 就像配置数据库连接的"工厂"
engine = create_engine('mysql+pymysql://root:password@localhost/shop_db',echo=True, # 开发时显示生成的SQLpool_size=10,max_overflow=20
)# 创建元数据对象 - 就像数据库结构的"蓝图"
metadata = MetaData()
定义表结构
# 定义用户表 - 就像设计数据库的"图纸"
users = Table('users', metadata,Column('id', Integer, primary_key=True),Column('username', String(50), unique=True, nullable=False),Column('email', String(100), unique=True, nullable=False),Column('password_hash', String(255), nullable=False),Column('created_at', DateTime, default=datetime.utcnow),Column('is_active', Boolean, default=True),Column('last_login', DateTime)
)# 定义产品表
products = Table('products', metadata,Column('id', Integer, primary_key=True),Column('name', String(100), nullable=False),Column('description', String(500)),Column('price', Float, nullable=False),Column('category', String(50), nullable=False),Column('stock', Integer, default=0),Column('created_at', DateTime, default=datetime.utcnow),Column('updated_at', DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
)# 定义订单表
orders = Table('orders', metadata,Column('id', Integer, primary_key=True),Column('user_id', Integer, nullable=False),Column('product_id', Integer, nullable=False),Column('quantity', Integer, nullable=False),Column('total_price', Float, nullable=False),Column('status', String(20), default='pending'),Column('created_at', DateTime, default=datetime.utcnow)
)# 创建所有表
metadata.create_all(engine)
print("数据库表创建完成!")
第三步:基础CRUD操作 - 数据的增删改查
插入数据:像填写表单一样简单
def insert_sample_data():"""插入示例数据"""with engine.connect() as conn:# 插入用户数据 - 就像填写用户注册表单user_data = [{'username': 'alice', 'email': 'alice@example.com', 'password_hash': 'hash123'},{'username': 'bob', 'email': 'bob@example.com', 'password_hash': 'hash456'},{'username': 'charlie', 'email': 'charlie@example.com', 'password_hash': 'hash789'}]# 批量插入 - 就像批量处理表单insert_stmt = insert(users)result = conn.execute(insert_stmt, user_data)print(f"插入了 {result.rowcount} 个用户")# 插入产品数据product_data = [{'name': 'iPhone 15', 'price': 5999.0, 'category': 'electronics', 'stock': 50},{'name': 'MacBook Pro', 'price': 12999.0, 'category': 'electronics', 'stock': 20},{'name': '咖啡杯', 'price': 29.9, 'category': 'home', 'stock': 100},{'name': '笔记本', 'price': 15.5, 'category': 'office', 'stock': 200}]conn.execute(insert(products), product_data)print("产品数据插入完成")# 提交事务conn.commit()# 执行数据插入
insert_sample_data()
查询数据:像搜索引擎一样灵活
def demonstrate_queries():"""演示各种查询操作"""with engine.connect() as conn:# 1. 基础查询 - 就像在商店里浏览商品print("=== 基础查询 ===")basic_query = select([products.c.name, products.c.price])result = conn.execute(basic_query)print("所有产品:")for row in result:print(f" {row.name}: ¥{row.price}")# 2. 条件查询 - 就像设置购物筛选条件print("\n=== 条件查询 ===")expensive_products = select([products.c.name, products.c.price]).where(products.c.price > 1000)result = conn.execute(expensive_products)print("价格超过1000的产品:")for row in result:print(f" {row.name}: ¥{row.price}")# 3. 复合条件 - 就像设置多个筛选条件print("\n=== 复合条件查询 ===")electronics_in_stock = select([products]).where(and_(products.c.category == 'electronics',products.c.stock > 10))result = conn.execute(electronics_in_stock)print("有库存的电子产品:")for row in result:print(f" {row.name}: ¥{row.price}, 库存: {row.stock}")# 4. 排序和限制 - 就像设置搜索结果的显示方式print("\n=== 排序和限制 ===")top_expensive = select([products.c.name, products.c.price]).order_by(products.c.price.desc()).limit(3)result = conn.execute(top_expensive)print("最贵的3个产品:")for row in result:print(f" {row.name}: ¥{row.price}")# 执行查询演示
demonstrate_queries()
聚合查询:像数据分析师一样思考
def demonstrate_aggregations():"""演示聚合查询"""with engine.connect() as conn:# 1. 统计查询 - 就像做市场调研print("=== 统计分析 ===")# 统计各类别产品数量category_count = select([products.c.category,func.count(products.c.id).label('product_count'),func.avg(products.c.price).label('avg_price'),func.sum(products.c.stock).label('total_stock')]).group_by(products.c.category)result = conn.execute(category_count)print("各类别统计:")for row in result:print(f" {row.category}: {row.product_count}个产品, "f"平均价格: ¥{row.avg_price:.2f}, "f"总库存: {row.total_stock}")# 2. 价格区间分析 - 就像做价格分布分析print("\n=== 价格区间分析 ===")price_ranges = select([func.case([(products.c.price < 50, '低价位'),(products.c.price < 500, '中价位'),(products.c.price < 5000, '高价位')], else_='奢侈品').label('price_range'),func.count(products.c.id).label('count')]).group_by('price_range')result = conn.execute(price_ranges)print("价格区间分布:")for row in result:print(f" {row.price_range}: {row.count}个产品")# 执行聚合查询演示
demonstrate_aggregations()
第四步:高级查询技巧 - 像数据库专家一样操作
连接查询:像拼图一样组合数据
def demonstrate_joins():"""演示连接查询"""with engine.connect() as conn:# 首先插入一些订单数据order_data = [{'user_id': 1, 'product_id': 1, 'quantity': 1, 'total_price': 5999.0},{'user_id': 1, 'product_id': 3, 'quantity': 2, 'total_price': 59.8},{'user_id': 2, 'product_id': 2, 'quantity': 1, 'total_price': 12999.0},{'user_id': 3, 'product_id': 4, 'quantity': 5, 'total_price': 77.5}]conn.execute(insert(orders), order_data)conn.commit()print("=== 连接查询演示 ===")# 1. 内连接 - 查询用户订单详情user_orders = select([users.c.username,products.c.name.label('product_name'),orders.c.quantity,orders.c.total_price,orders.c.created_at]).select_from(users.join(orders, users.c.id == orders.c.user_id).join(products, products.c.id == orders.c.product_id))result = conn.execute(user_orders)print("用户订单详情:")for row in result:print(f" {row.username} 购买了 {row.quantity}个 {row.product_name}, "f"总价: ¥{row.total_price}")# 2. 左连接 - 查询所有用户及其订单数量(包括没有订单的用户)print("\n=== 用户订单统计 ===")user_order_stats = select([users.c.username,func.coalesce(func.count(orders.c.id), 0).label('order_count'),func.coalesce(func.sum(orders.c.total_price), 0).label('total_spent')]).select_from(users.outerjoin(orders, users.c.id == orders.c.user_id)).group_by(users.c.id, users.c.username)result = conn.execute(user_order_stats)for row in result:print(f" {row.username}: {row.order_count}个订单, "f"总消费: ¥{row.total_spent}")# 执行连接查询演示
demonstrate_joins()
子查询:像俄罗斯套娃一样嵌套
def demonstrate_subqueries():"""演示子查询"""with engine.connect() as conn:print("=== 子查询演示 ===")# 1. 标量子查询 - 查询价格高于平均价格的产品avg_price_subquery = select([func.avg(products.c.price)])above_avg_products = select([products.c.name,products.c.price]).where(products.c.price > avg_price_subquery)result = conn.execute(above_avg_products)print("价格高于平均价格的产品:")for row in result:print(f" {row.name}: ¥{row.price}")# 2. 表子查询 - 查询每个类别中最贵的产品print("\n=== 每个类别最贵的产品 ===")max_price_by_category = select([products.c.category,func.max(products.c.price).label('max_price')]).group_by(products.c.category).alias('max_prices')most_expensive_in_category = select([products.c.name,products.c.category,products.c.price]).select_from(products.join(max_price_by_category,and_(products.c.category == max_price_by_category.c.category,products.c.price == max_price_by_category.c.max_price)))result = conn.execute(most_expensive_in_category)for row in result:print(f" {row.category}: {row.name} - ¥{row.price}")# 3. EXISTS子查询 - 查询有订单的用户print("\n=== 有订单的用户 ===")users_with_orders = select([users.c.username]).where(select([orders.c.id]).where(orders.c.user_id == users.c.id).exists())result = conn.execute(users_with_orders)print("有订单的用户:")for row in result:print(f" {row.username}")# 执行子查询演示
demonstrate_subqueries()
第五步:动态查询构建 - 像搭积木一样灵活
条件动态组合
class ProductSearchEngine:"""产品搜索引擎 - 演示动态查询构建"""def __init__(self, engine):self.engine = enginedef search_products(self, **filters):"""动态构建产品搜索查询"""# 基础查询 - 就像搭积木的底座query = select([products.c.id,products.c.name,products.c.price,products.c.category,products.c.stock])conditions = []# 动态添加条件 - 就像根据需要添加积木块if 'name' in filters and filters['name']:conditions.append(products.c.name.like(f"%{filters['name']}%"))if 'category' in filters and filters['category']:conditions.append(products.c.category == filters['category'])if 'min_price' in filters and filters['min_price'] is not None:conditions.append(products.c.price >= filters['min_price'])if 'max_price' in filters and filters['max_price'] is not None:conditions.append(products.c.price <= filters['max_price'])if 'in_stock' in filters and filters['in_stock']:conditions.append(products.c.stock > 0)# 组合所有条件if conditions:query = query.where(and_(*conditions))# 动态排序if 'sort_by' in filters:sort_column = getattr(products.c, filters['sort_by'], products.c.name)if filters.get('sort_desc', False):query = query.order_by(sort_column.desc())else:query = query.order_by(sort_column)# 分页if 'limit' in filters:query = query.limit(filters['limit'])if 'offset' in filters:query = query.offset(filters['offset'])return querydef execute_search(self, **filters):"""执行搜索并返回结果"""query = self.search_products(**filters)with self.engine.connect() as conn:result = conn.execute(query)return [dict(row) for row in result]# 使用搜索引擎
search_engine = ProductSearchEngine(engine)# 演示各种搜索场景
print("=== 动态查询演示 ===")# 1. 搜索电子产品
electronics = search_engine.execute_search(category='electronics')
print("电子产品:")
for product in electronics:print(f" {product['name']}: ¥{product['price']}")# 2. 价格区间搜索
affordable_products = search_engine.execute_search(min_price=10, max_price=100, sort_by='price'
)
print("\n价格在10-100之间的产品:")
for product in affordable_products:print(f" {product['name']}: ¥{product['price']}")# 3. 模糊搜索
phone_products = search_engine.execute_search(name='phone',in_stock=True,sort_by='price',sort_desc=True
)
print("\n包含'phone'的有库存产品:")
for product in phone_products:print(f" {product['name']}: ¥{product['price']}, 库存: {product['stock']}")
第六步:批量操作与性能优化
批量插入和更新
def demonstrate_bulk_operations():"""演示批量操作"""# 1. 批量插入 - 就像批量导入数据print("=== 批量插入演示 ===")# 生成大量测试数据import randomcategories = ['electronics', 'home', 'office', 'sports', 'books']bulk_products = []for i in range(1000):bulk_products.append({'name': f'产品_{i:04d}','price': round(random.uniform(10, 1000), 2),'category': random.choice(categories),'stock': random.randint(0, 100)})with engine.connect() as conn:# 使用executemany进行批量插入start_time = datetime.now()conn.execute(insert(products), bulk_products)conn.commit()end_time = datetime.now()print(f"批量插入1000条记录耗时: {(end_time - start_time).total_seconds():.2f}秒")# 2. 批量更新 - 就像批量调整价格print("\n=== 批量更新演示 ===")with engine.connect() as conn:# 给所有电子产品打9折update_stmt = update(products).where(products.c.category == 'electronics').values(price=products.c.price * 0.9,updated_at=datetime.utcnow())result = conn.execute(update_stmt)conn.commit()print(f"更新了 {result.rowcount} 个电子产品的价格")# 执行批量操作演示
demonstrate_bulk_operations()
查询优化技巧
def demonstrate_query_optimization():"""演示查询优化技巧"""with engine.connect() as conn:# 1. 使用索引提示print("=== 查询优化演示 ===")# 只选择需要的字段efficient_query = select([products.c.name,products.c.price]).where(products.c.category == 'electronics').limit(10)# 2. 使用编译查询提高重复执行效率compiled_query = efficient_query.compile(compile_kwargs={"literal_binds": True})print(f"编译后的SQL: {compiled_query}")# 3. 使用流式结果处理大量数据print("\n=== 流式处理大量数据 ===")large_query = select([products])result = conn.execution_options(stream_results=True).execute(large_query)count = 0for row in result:count += 1if count <= 5: # 只显示前5条print(f" {row.name}: ¥{row.price}")elif count == 6:print(" ...")print(f"总共处理了 {count} 条记录")# 执行查询优化演示
demonstrate_query_optimization()
第七步:实战案例 - 构建商品推荐系统
复杂业务查询实现
class ProductRecommendationEngine:"""商品推荐引擎 - 综合运用SQLAlchemy Core"""def __init__(self, engine):self.engine = enginedef get_user_purchase_history(self, user_id):"""获取用户购买历史"""query = select([products.c.category,func.count(orders.c.id).label('purchase_count'),func.sum(orders.c.total_price).label('total_spent')]).select_from(orders.join(products, orders.c.product_id == products.c.id)).where(orders.c.user_id == user_id).group_by(products.c.category)with self.engine.connect() as conn:result = conn.execute(query)return {row.category: {'count': row.purchase_count,'spent': row.total_spent} for row in result}def get_popular_products_in_category(self, category, limit=5):"""获取某类别的热门产品"""query = select([products.c.id,products.c.name,products.c.price,func.count(orders.c.id).label('order_count')]).select_from(products.outerjoin(orders, products.c.id == orders.c.product_id)).where(products.c.category == category).group_by(products.c.id, products.c.name, products.c.price).order_by(func.count(orders.c.id).desc()).limit(limit)with self.engine.connect() as conn:result = conn.execute(query)return [dict(row) for row in result]def get_price_similar_products(self, product_id, price_tolerance=0.2):"""获取价格相似的产品"""# 首先获取目标产品的价格target_price_query = select([products.c.price]).where(products.c.id == product_id)with self.engine.connect() as conn:target_price = conn.execute(target_price_query).scalar()if not target_price:return []# 查找价格相似的产品min_price = target_price * (1 - price_tolerance)max_price = target_price * (1 + price_tolerance)similar_query = select([products.c.id,products.c.name,products.c.price,products.c.category]).where(and_(products.c.price.between(min_price, max_price),products.c.id != product_id,products.c.stock > 0)).order_by(func.abs(products.c.price - target_price)).limit(5)result = conn.execute(similar_query)return [dict(row) for row in result]def recommend_for_user(self, user_id):"""为用户生成推荐"""# 1. 分析用户购买偏好purchase_history = self.get_user_purchase_history(user_id)if not purchase_history:# 新用户,推荐热门产品return self.get_popular_products_in_category('electronics')# 2. 找出用户最喜欢的类别favorite_category = max(purchase_history.keys(), key=lambda cat: purchase_history[cat]['spent'])# 3. 推荐该类别的热门产品recommendations = self.get_popular_products_in_category(favorite_category)return {'user_preferences': purchase_history,'favorite_category': favorite_category,'recommendations': recommendations}# 使用推荐引擎
recommender = ProductRecommendationEngine(engine)# 为用户1生成推荐
print("=== 商品推荐系统演示 ===")
user_recommendations = recommender.recommend_for_user(1)print(f"用户偏好分析:")
for category, stats in user_recommendations['user_preferences'].items():print(f" {category}: 购买{stats['count']}次, 消费¥{stats['spent']}")print(f"\n最喜欢的类别: {user_recommendations['favorite_category']}")print(f"\n推荐产品:")
for product in user_recommendations['recommendations']:print(f" {product['name']}: ¥{product['price']} (被购买{product['order_count']}次)")# 演示价格相似产品推荐
print(f"\n=== 价格相似产品推荐 ===")
similar_products = recommender.get_price_similar_products(1) # iPhone 15
for product in similar_products:print(f" {product['name']}: ¥{product['price']} ({product['category']})")
第八步:与Pandas集成 - 数据分析的完美搭档
SQLAlchemy + Pandas 强强联合
def demonstrate_pandas_integration():"""演示SQLAlchemy与Pandas的集成"""print("=== SQLAlchemy + Pandas 集成演示 ===")# 1. 直接从数据库读取到DataFramequery = select([products.c.category,products.c.price,products.c.stock])# 使用pandas读取SQL查询结果df = pd.read_sql(query, engine)print("产品数据统计:")print(df.describe())# 2. 按类别分析print("\n按类别分析:")category_stats = df.groupby('category').agg({'price': ['mean', 'min', 'max'],'stock': ['sum', 'mean']}).round(2)print(category_stats)# 3. 复杂分析查询analysis_query = """SELECT p.category,COUNT(p.id) as product_count,AVG(p.price) as avg_price,SUM(p.stock) as total_stock,COALESCE(SUM(o.quantity), 0) as total_soldFROM products pLEFT JOIN orders o ON p.id = o.product_idGROUP BY p.categoryORDER BY total_sold DESC"""analysis_df = pd.read_sql(analysis_query, engine)print("\n类别销售分析:")print(analysis_df)# 4. 将分析结果写回数据库# 创建分析结果表analysis_table = Table('category_analysis', metadata,Column('category', String(50), primary_key=True),Column('product_count', Integer),Column('avg_price', Float),Column('total_stock', Integer),Column('total_sold', Integer),Column('analysis_date', DateTime, default=datetime.utcnow))# 如果表不存在则创建analysis_table.create(engine, checkfirst=True)# 添加分析日期analysis_df['analysis_date'] = datetime.utcnow()# 写入数据库analysis_df.to_sql('category_analysis', engine, if_exists='replace', index=False)print("\n分析结果已保存到数据库")# 执行Pandas集成演示
demonstrate_pandas_integration()
第九步:最佳实践与性能调优
连接管理和事务处理
from contextlib import contextmanager
from sqlalchemy.exc import SQLAlchemyError@contextmanager
def database_transaction(engine):"""数据库事务上下文管理器"""conn = engine.connect()trans = conn.begin()try:yield conntrans.commit()except Exception:trans.rollback()raisefinally:conn.close()def demonstrate_best_practices():"""演示最佳实践"""print("=== 最佳实践演示 ===")# 1. 使用事务确保数据一致性try:with database_transaction(engine) as conn:# 模拟下单流程# 检查库存stock_query = select([products.c.stock]).where(products.c.id == 1)current_stock = conn.execute(stock_query).scalar()if current_stock >= 1:# 减少库存update_stock = update(products).where(products.c.id == 1).values(stock=products.c.stock - 1)conn.execute(update_stock)# 创建订单new_order = insert(orders).values(user_id=1,product_id=1,quantity=1,total_price=5999.0)conn.execute(new_order)print("订单创建成功,库存已更新")else:raise ValueError("库存不足")except SQLAlchemyError as e:print(f"数据库操作失败: {e}")except ValueError as e:print(f"业务逻辑错误: {e}")# 2. 查询结果缓存from functools import lru_cache@lru_cache(maxsize=100)def get_category_products(category):"""缓存类别产品查询结果"""query = select([products.c.name, products.c.price]).where(products.c.category == category)with engine.connect() as conn:result = conn.execute(query)return [dict(row) for row in result]# 3. 预编译查询提高性能prepared_query = select([products.c.name, products.c.price]).where(products.c.category == 'electronics').compile()print(f"预编译查询: {prepared_query}")# 执行最佳实践演示
demonstrate_best_practices()
监控和调试
import logging
from sqlalchemy import eventdef setup_query_monitoring():"""设置查询监控"""# 配置SQL日志logging.basicConfig()logging.getLogger('sqlalchemy.engine').setLevel(logging.INFO)# 监控慢查询@event.listens_for(engine, "before_cursor_execute")def receive_before_cursor_execute(conn, cursor, statement, parameters, context, executemany):context._query_start_time = datetime.now()@event.listens_for(engine, "after_cursor_execute")def receive_after_cursor_execute(conn, cursor, statement, parameters, context, executemany):total = (datetime.now() - context._query_start_time).total_seconds()if total > 0.1: # 记录超过100ms的查询print(f"慢查询警告 ({total:.3f}s): {statement[:100]}...")# 设置监控
setup_query_monitoring()
总结:SQLAlchemy Core的核心价值
通过这篇文章,我们深入探索了SQLAlchemy Core的强大功能。它就像是一座连接Python和SQL世界的桥梁,让我们既能享受SQL的强大功能,又能获得Python代码的灵活性。
核心优势回顾
- 表达式语言:像搭积木一样构建SQL查询
- 动态查询:根据条件灵活组合查询逻辑
- 类型安全:Python的类型检查帮助避免SQL错误
- 数据库无关:一套代码适配多种数据库
- 性能优化:提供多种优化手段和监控工具
选择指南
- 简单查询:直接使用select、insert等基础操作
- 复杂业务:利用子查询、连接查询构建复杂逻辑
- 动态场景:使用条件组合构建灵活的搜索功能
- 数据分析:结合Pandas进行高效的数据处理
- 高性能:使用批量操作和查询优化技巧
SQLAlchemy Core为我们提供了一种优雅的方式来处理数据库操作,它既保持了SQL的强大功能,又融入了Python的简洁哲学。掌握了这些技能,你就能在数据库编程的道路上游刃有余!
扩展阅读
- SQLAlchemy Core官方文档
- SQL表达式语言教程
- SQLAlchemy性能优化指南
- 数据库查询优化最佳实践