1. ArrayList和LinkedList的区别?
- 底层结构:ArrayList 是基于动态数组实现,支持索引快速访问;LinkedList 是基于双向链表实现,依赖指针访问前后元素。
- 插入与删除效率:在尾部操作时,两者性能相近;但在中间或头部插入/删除时,ArrayList 需要移动元素,性能较差,而 LinkedList 只需要调整指针,效率更高。
- 随机访问:ArrayList 支持通过索引快速访问(O(1)),而 LinkedList 访问需要遍历链表(O(n))。
- 内存占用:ArrayList 占用的是连续内存空间,整体空间消耗较少;LinkedList 每个节点额外存储两个指针,空间开销更大。
- 适用场景:如果场景中以频繁访问和尾部操作为主,优先使用 ArrayList;若涉及大量插入删除操作,特别是中间位置,LinkedList 更合适。
- 线程安全性:两者默认都不是线程安全的,如需并发安全需通过同步封装或使用线程安全类如
CopyOnWriteArrayList。Vector 是线程安全的 List 实现,但已较少使用。
2. 讲下HashMap?
在 jdk 1.7 版本之前,HashMap 数据结构是数组和链表,HashMap 通过哈希算法将元素的键(Key)映射到数组中的槽位(Bucket)。如果多个键映射到同一个槽位,它们会以链表的形式存储在同一个槽位上,因为链表的查询时间是 O(n),所以冲突很严重,一个索引上的链表非常长,效率就很低了。
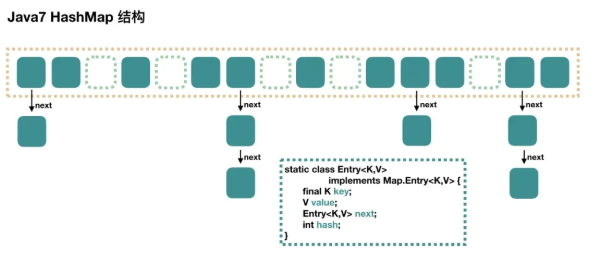
在 jdk 1.8 版本,HashMap 结构是数组 + 链表 + 红黑树,以优化高冲突情况下的性能。当某个桶中的链表长度超过 8 且数组容量 ≥ 64 时,该链表会被转换为红黑树,从而查找效率从 O(n) 提升为 O(logn);若树中节点数减少至 ≤ 6,则会退化回链表,以降低维护红黑树的资源开销。同时,jdk 1.8 将链表的插入方式改为尾插法,保证了遍历顺序的稳定性。尽管尽管在多线程环境下仍不安全,但相比 jdk1.7 的头插 + 纯链表方式,jdk 1.8 的 HashMap 在性能和冲突处理机制上都有明显提升。
3. 讲下ConcurrentHashMap?
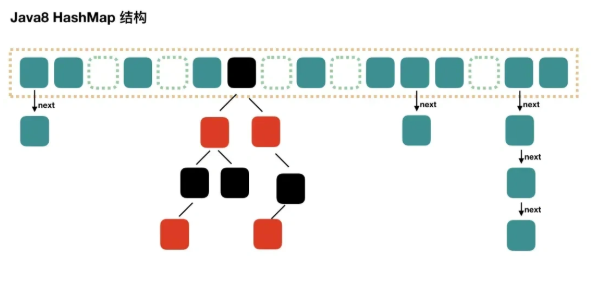
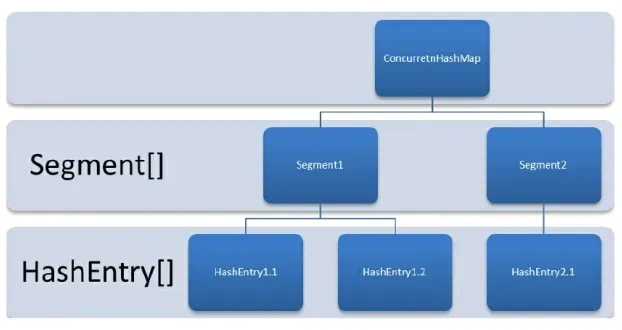
在 jdk 1.7 中,ConcurrentHashMap 采用分段锁机制(Segment)实现并发控制,其底层结构是“Segment 数组 + HashEntry 数组 + 链表”。Segment 是一种可重入锁(ReentrantLock),每个 Segment 管理一部分桶(
HashEntry[]),从而实现多个线程对不同 Segment 并发访问时互不干扰。每个 HashEntry 维护一个链表,用于处理哈希冲突。整体上,这种设计通过降低锁的粒度提升了并发性能,但由于锁粒度依然较大、扩容较复杂。
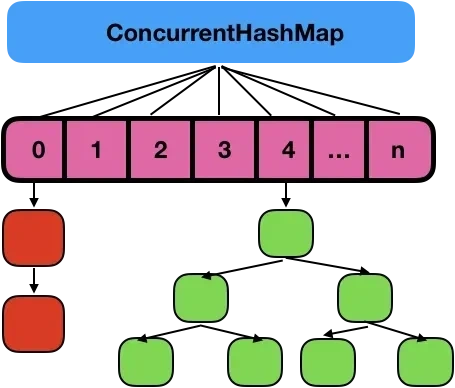
在 jdk 1.8 中,ConcurrentHashMap 不再使用 Segment 分段锁,而是通过 volatile、CAS 和少量 synchronized 实现线程安全。当添加元素时,若桶数组为空,则使用 CAS 初始化;若目标桶为空,也用 CAS插入;若已存在冲突,则对该桶使用 synchronized 加锁,插入或更新元素。为了提升查询效率,当桶中链表长度超过阈值 8 且数组容量大于等于 64 时,会将链表转为红黑树,查找复杂度由 O(n) 优化为 O(logn)。这种基于桶粒度加锁的方式,比 jdk 1.7 的 Segment 粒度更细,大大减少了锁竞争,从而提升了并发性能与扩展性。
| 情况 | 操作 |
|---|---|
| 桶为空 | CAS 插入新节点(无锁) |
| 桶不为空且非树 | synchronized 锁住链表头,插入或替换 |
| 桶为红黑树 | 按红黑树插入逻辑处理 |
| 桶为 ForwardingNode | 当前线程参与扩容 |
CAS 是一种原子操作,用于实现无锁并发。
if (当前值 == 期望值) {设置为新值
} else {不修改(可能重试)
}
在 ConcurrentHashMap 中,CAS 被用来在多线程下安全地插入节点或初始化 table,比如:
if (tabAt(table, i) == null) {if (casTabAt(table, i, null, new Node<>(...))) {break; // 插入成功}
}
volatile 是 Java 的内存可见性保证。
修饰变量后,每次读取都从主内存读取,每次写入都同步到主内存,确保线程看到的是最新值。
在 ConcurrentHashMap 中,桶数组 Node[] table 是一个 volatile 变量,确保线程之间对 table 的变更是可见的。
4. 讲下阻塞队列?
阻塞队列(BlockingQueue)是一种支持阻塞插入和阻塞获取操作的线程安全队列:当队列为空时,获取元素的线程会被阻塞;当队列满时,插入元素的线程会被阻塞。阻塞队列非常适合用于生产者 - 消费者模式,简化了线程间的同步控制。在
java.util.concurrent包中,常见的阻塞队列实现包括:
- ArrayBlockingQueue:基于数组的有界队列,按 FIFO 顺序排序。
- LinkedBlockingQueue:基于链表的队列,默认容量是
Integer.MAX_VALUE。- PriorityBlockingQueue:基于优先级的无界队列,不保证 FIFO。
- DelayQueue:只有当元素的延迟时间到期后才能被取出。
- SynchronousQueue:不存储任何元素,每次插入必须等待对应的移除。
| 方法 | 行为 | 当不能执行时会如何 |
|---|---|---|
put(E e) | 将元素放入队列 | 如果队列已满,会阻塞直到队列可用 |
take() | 从队列获取并移除元素 | 如果队列为空,会阻塞直到有元素可用 |
5. 讲下线程安全的List?
Collections.synchronizedList方法可以将任何普通的 List 转换为线程安全的 List,它通过对所有访问方法加锁来实现线程安全。这意味着所有对列表的操作都是原子性的,适用于需要简单线程安全处理的场景。但在使用时需要注意:在进行迭代操作时,仍需手动对列表进行同步,以避免并发修改异常。如果应用中存在频繁的读写操作,且对性能要求不是特别高,这种方式是一个相对简单可行的选择。
CopyOnWriteArrayList是 Java 提供的一个支持并发读写的线程安全集合,它在执行写操作(如添加、删除元素)时会复制一份底层数组,修改操作在副本上进行,从而保证读取过程不受影响。由于读操作无需枷锁,读性能非常高,非常适合读多写少的场景,比如缓存、白名单或配置信息的维护。
| 特性 | Collections.synchronizedList | CopyOnWriteArrayList |
|---|---|---|
| 实现方式 | 同步包装普通 List(加锁) | 读写分离(写时复制) |
| 读性能 | 一般(加锁) | 高(无需加锁) |
| 写性能 | 一般 | 较低(每次写操作都会复制) |
| 遍历时是否需加锁 | ✅ 需要手动加锁 | ❌ 不需要 |
| 适合场景 | 读写都较频繁的简单线程安全场景 | 读多写少的高并发场景 |
6. 讲下JVM内存区域?
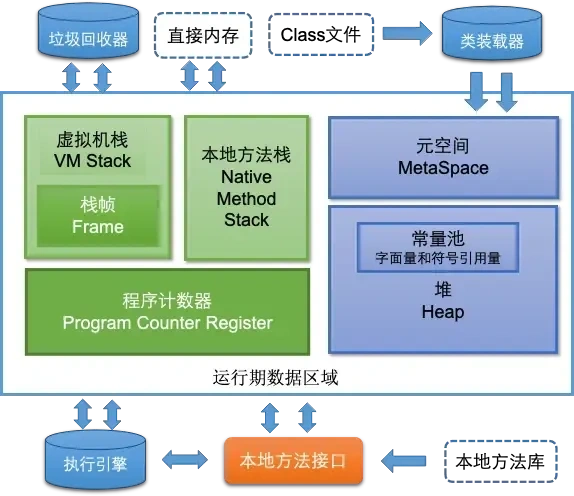
- 程序计数器:程序计数器是一个线程私有的内存区域,它用来记录当前线程正在执行的字节码指令地址。由于 JVM 的多线程是通过线程轮流切换并分配 CPU 执行时间的方式实现的,因此每个线程在被切换回来时,需要依靠程序计数器恢复到正确的执行位置。它是 JVM 中唯一一个不会发生 OutOfMemoryError 的区域。
- Java 虚拟机栈:也是线程私有的,每个线程创建时都会创建一个对应的栈。栈中保存的是方法调用的信息,每个方法执行时都会创建一个栈帧,包含局部变量表、操作数栈、动态链接等。当方法执行完后对应的栈帧就会被销毁。栈空间不足会抛出 StackOverflowError 或 OutOfMemoryError。
- 本地方法栈:本地方法栈和虚拟机栈类似,只不过它用于执行 native 本地方法。它同样是线程私有的,在使用如 JNI(Java本地接口)等调用 C/C++ 方法时会用到。这个区域在 JVM 规范中没有强制格式,因此不同 JVM 的实现可以有所不同。本地方法栈也可能出现 StackOverflowError 或 OutOfMemoryError。
- 堆:堆是 JVM 中最大的一块内存区域,用于存放所有对象实例和数组,是所有线程共享的区域。它是垃圾收集器的主要管理区域,因此也称“GC”堆。堆的空间是动态扩展的,但如果无法申请到内存空间,就会抛出 OutOfMemoryError。JDK 1.8 后,字符串常量池也被移到了堆中。
- 方法区:在 JDK 1.8 后被实现为元空间(Metaspace),不再使用 JVM 内部的内存,而是使用本地内存。它用于存储类的元数据,如类结构、方法信息、常量池等。元空间的大小只受系统本地内存限制,但如果内存不足,也可能抛出 OutOfMemoryError: Metaspace。
- 运行时常量池:运行时常量池也是方法区的一部分,用于存放编译时生成的各种字面量和符号引用。在运行时,类加载后这些内容会被放入常量池中,也支持动态生成常量(如 String.intern)。如果常量池太大,也可能导致内存溢出。
- 直接内存:直接内存不是 JVM 运行时数据区的一部分,但经常被 Java 程序使用,特别是在使用 NIO 类库时。它通过调用本地函数库直接分配堆外内存,避免了在 Java 堆和操作系统之间的数据复制,能提高 IO 性能。但过度使用也可能导致系统内存不足而抛出 OutOfMemoryError。
7. Spring里@Autowired和@Resource注解有什么区别?
都用于依赖注入,但来源和注入机制不同。
@Autowired 是 Spring 提供的注解,默认按类型(byType)注入,也可以配合 @Qualifier 实现按名称注入;而 @Resource 属于 Java EE 的 JSR-250 规范,默认按名称(byName)注入,找不到同名时才会按类型匹配。
在使用上,@Autowired 不需要设置属性,主要依赖 Spring 容器;而 @Resource 通常通过设置 name 属性指定注入的 Bean 名称,适用于兼容 Java EE 的环境。
如果是在纯 Spring 项目中,@Autowired 更加常见灵活;但如果希望明确按名称注入或考虑与非 Spring 框架的兼容性,@Resource 会更合适。
8. 介绍下类加载器过程?
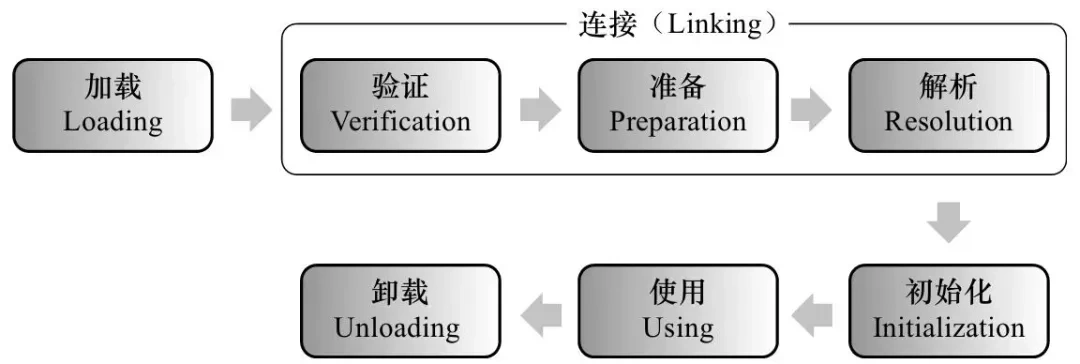
Java 中的类加载器过程是指 JVM 在运行期间,将 .class 字节码文件加载到内存中,并转换为可以被虚拟机执行的类对象的过程。这个过程大致可以分为以下几个阶段,并涉及到不同的类加载器:
- 加载:把
.class文件读进内存,变成 JVM 能识别的 Class 对象。通过类的全限定名(包名 + 类名)找到对应的 .class 文件,把二进制字节流转成 JVM 方法区里的运行时数据结构,并在堆中创建一个代表该类的java.lang.Class对象,用来访问方法区中该类的结构信息。- 链接:验证 + 准备 + 解析
- 验证:检查
.class文件是否符合 JVM 要求,确保安全、合法。包括文件格式校验、元数据校验、字节码验证、符号引用验证。- 准备:为类中静态变量分配内存,赋默认值(如0、null等)。不执行初始化赋值逻辑;
static final常量不会在这赋值(因为编译期已确定,直接放进常量池)。- 解析:将字节码中的符号引用(String形式)替换成直接引用(地址或偏移量)。比如把 “java/lang/String” → 指向内存中真正的 String 类;这样程序就可以快速定位方法或字段的位置。
- 初始化:最后一个阶段,真正执行类的静态初始化逻辑(
<clinit>()方法)。JVM 会执行静态变量的赋值语句、static{}代码块。构造器<clinit>是编译器生成的,不是手写的构造函数。- 使用:正常使用类。比如创建对象、调用静态方法、反射操作。
- 卸载:满足一定条件,类会被 JVM 从内存中“丢弃”,释放资源。条件必须同时满足三条:该类的所有实例都被 GC 回收、加载它的类加载器也被回收、Class 对象不再被任何地方引用(包括反射)。通常类很少被卸载,主要出现在动态类加载/热部署的场景中。
9. MySQL如何避免全表扫描?
应针对查询频繁的字段建立合适的索引。通常可以为具有唯一性约束的字段(如商品编码、用户ID)建立唯一索引,为经常出现在
WHERE条件中的字段或字段组合建立普通索引或联合索引,以加快查询速度。同时,对经常用于ORDER BY或GROUP BY的字段加索引,也能避免额外的排序操作,提高执行效率。但需要注意,索引不是越多越好,索引会占用空间并影响写入性能,应合理设计并优先选择区分度高的字段建立索引。
10. MySQL如何实现如果不存在就插入,如果存在就更新?
在 MySQL 中,可以使用 INSERT … ON DUPLICATE KEY UPDATE 实现“如果不存在就插入,存在就更新”的功能。其原理是:当插入语句因主键或唯一索引冲突失败时,MySQL 会自动执行 UPDATE 语句来更新原有数据。例如,在用户表 users(id, name, age) 中,执行:
INSERT INTO users (id, name, age)
VALUES (1, 'Alice', 25)
ON DUPLICATE KEY UPDATE
name = VALUES(name),
age = VALUES(age);
如果 id = 1 不存在,则插入新纪录;如果已存在,则更新该记录的 name 和 age 字段。这种写法简洁高效,适用于需要“插入或更新”逻辑的场景。
11. 数据库访问量过大怎么办?
- 创建或优化索引:根据查询条件创建合适的索引,特别是经常用于 WHERE 子句的字段、ORDER BY 排序的字段、JOIN 连表查询的字典、GROUP BY 的字段,并且如果查询中经常涉及多个字段,考虑创建联合索引,使用联合索引要符合最左匹配原则,不然会索引失效。
- 查询优化:避免使用 SELECT *,只查询真正需要的列;使用覆盖索引,即索引包含所有查询的字段;联表查询最好要以小表驱动大表,并且被驱动表的字段要有索引,当然最好通过冗余字段的设计,避免联表查询。
- 避免索引失效:比如不要用左模糊匹配、函数计算、表达式计算等等。
- 读写分离:搭建主从架构,利用数据库的读写分离,Web 服务器在写数据的时候,访问主数据库(master),主数据库通过主从复制将数据更新同步到从数据(slave),这样当 Web 服务器读数据的时候,就可以通过从数据库获得数据。这一方案使得在大量读操作的 Web 应用可以轻松地读取数据,而主数据库也只会承受少量的写入操作,还可以实现数据热备份。
- 优化数据库表:如果单表的数据超过了千万级别,考虑是否需要将大表拆分为小表,减轻单个表的查询压力。也可以将字段多的表分解成多个表,有些字段使用频率高,有些低,数据量大时,会由于使用频率低的存在而变慢,可以考虑分开。
- 使用缓存技术:引入缓存层,如 Redis,存储热点数据和频繁查询的结果,但是要考虑缓存一致性的问题,对于读请求会选择旁路缓存策略,对于写请求会选择先更新 db,再删除缓存的策略。



![[网页五子棋][匹配对战]落子实现思路、发送落子请求、处理落子响应](https://i-blog.csdnimg.cn/img_convert/c404c12df96af79c63c6097083ebb9b2.png)