目录
一,VAE
1.1 VAE的简介
1.2 VAE的核心思想
1.3 VAE的结构
1.4 VAE的工作原理
1.5 VAE 与传统自动编码器(AE)的区别
1.6 VAE 的应用场景
二,代码逻辑分析
2.1 整体逻辑
2.2 VAE模型
2.3 训练策略与优化
2.4 自适应学习率调度
2.5 图像重建
2.6 特征提取
三,测试结果
3.1 VAE在自监督学习结果
3.2 VAE重建图像
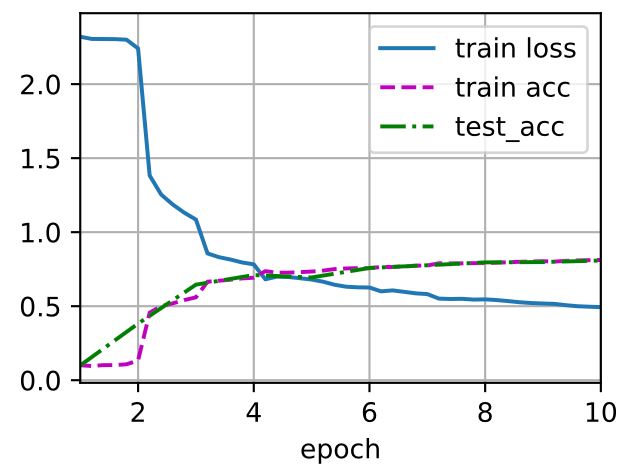
3.3 VAE对于分类任务的准确度
3.4 总结
四,完整代码
一,VAE
1.1 VAE的简介
变分自编码器(Variational Autoencoder,VAE) 是一种基于深度学习的生成模型,属于无监督学习算法,常用于数据生成、降维、特征学习等任务。它结合了变分推断和 ** 自动编码器(Autoencoder)** 的思想,能够学习数据的潜在概率分布,并生成与训练数据相似的新样本。
1.2 VAE的核心思想
传统的自动编码器(AE)由编码器(Encoder)和解码器(Decoder)组成,通过压缩输入数据到低维 “瓶颈”( latent space,潜在空间)再重建数据。但 AE 的潜在空间缺乏概率结构,无法直接用于生成新样本。VAE 的改进在于:假设潜在空间服从连续的概率分布(通常是正态分布)。通过变分推断(Variational Inference)近似真实数据的概率分布,使潜在空间具有连续性和可采样性,从而支持生成新样本。
1.3 VAE的结构
1. 编码器(Encoder):把数据 “压缩” 成特征向量
作用:输入一张图片(或其他数据),编码器会提取其中的关键特征,将其 “压缩” 成一个潜在向量(Latent Vector),这个向量代表了数据在 “特征空间” 中的位置。
特点:传统自动编码器(AE)的编码器直接输出一个确定的向量(如长度为 100 的特征向量),但 VAE 的编码器输出的是概率分布的参数(比如均值和方差)。
这意味着,编码器认为输入数据对应于潜在空间中的一个 “范围”(概率分布),而不是一个固定的点。例如,一张猫的图片可能对应于潜在空间中 “猫特征” 分布的某个区域。
2. 解码器(Decoder):从特征向量 “解压缩” 回数据
作用:输入潜在向量,解码器会根据这个向量 “还原” 出原始数据(如生成一张图片)。
特点:解码器的输入不是一个确定的向量,而是从编码器输出的概率分布中随机采样得到的向量。
这样,即使输入相似的潜在向量,解码器也可能生成略有不同的结果,增加了生成数据的多样性。
1.4 VAE的工作原理
首先通过编码器将输入数据映射到潜在空间的概率分布(通常假设为正态分布),得到分布的均值和方差,利用重参数化技巧从该分布中采样生成潜在向量,使采样过程可导以便反向传播优化;接着解码器将潜在向量还原为重建数据,力求与原始输入相似;训练时通过平衡重建损失(衡量重建数据与原始数据的差异)和 KL 散度损失(迫使潜在分布接近标准正态分布,确保潜在空间连续有序),使模型既能准确重建数据,又能让潜在空间的每个点对应有意义的语义特征;最终,模型可从规则化的潜在空间中随机采样或插值生成全新的、符合训练数据分布的样本,实现无监督的特征学习与数据生成。
1.5 VAE 与传统自动编码器(AE)的区别
| 对比项 | 自动编码器(AE) | 变分自动编码器(VAE) |
|---|---|---|
| 编码器输出 | 确定的特征向量(一个点) | 概率分布的参数(均值、方差) |
| 潜在空间 | 可能混乱,无法直接生成新数据 | 强制为规则分布(如正态分布),支持随机生成 |
| 核心能力 | 数据压缩与重建 | 数据生成与特征表示学习 |
1.6 VAE 的应用场景
| 应用场景 | 说明 |
|---|---|
| 数据生成 | 通过学习数据分布,生成新的类似样本(如图像、语音、文本),常用于生成模型(如人脸、动漫角色)。 |
| 数据压缩与降噪 | 将高维数据编码为低维隐向量(如 latent_dim=512),实现有损压缩;同时通过重构过程过滤噪声。 |
| 异常检测 | 对正常数据建模后,通过重构误差识别偏离分布的异常样本(如工业缺陷检测、医疗异常信号识别)。 |
| 半监督学习 | 利用无标签数据的隐向量分布辅助有标签数据训练,提升分类或回归任务性能。 |
| 图像编辑与插值 | 在隐空间中通过向量运算(如插值、加减特征向量)修改图像属性(如表情、姿态、风格)。 |
| 探索性数据分析 | 通过隐向量的可视化(如降维到 2D/3D)观察数据分布规律、聚类结构或潜在特征关联。 |
| 跨域转换 | 学习不同数据域(如素描→彩色图像、医学影像→自然图像)的隐空间映射,实现风格迁移或模态转换。 |
| 药物发现与设计 | 在化学分子的隐空间中搜索具有特定性质的分子结构,辅助新药研发(如生成候选化合物)。 |
二,代码逻辑分析
2.1 整体逻辑
- 训练 VAE:通过无监督学习学习 FashionMNIST 图像的潜在特征分布。
- 图像重建:验证 VAE 的生成能力,可视化原始图像与重建图像。
- 提取隐变量:使用训练好的 VAE 编码器将图像转换为隐向量。
- 训练分类器:在隐变量空间中训练非线性分类器,实现图像分类。
2.2 VAE模型
class ResidualBlock(nn.Module):def __init__(self, in_channels, out_channels):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(out_channels)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)self.shortcut = nn.Sequential() if in_channels == out_channels else nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1),nn.BatchNorm2d(out_channels))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)return F.relu(out)# VAE模型(修改latent_dim默认值为512)
class VAE(nn.Module):def __init__(self, latent_dim=512): # 关键修改:默认值改为512super(VAE, self).__init__()self.encoder = nn.Sequential(nn.Conv2d(1, 32, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(32),ResidualBlock(32, 32),nn.Conv2d(32, 64, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(64),ResidualBlock(64, 64),nn.Conv2d(64, 128, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(128),ResidualBlock(128, 128),nn.Conv2d(128, 256, 4, stride=1, padding=0), nn.ReLU(), nn.BatchNorm2d(256))self.fc_mu = nn.Linear(256 * 1 * 1, latent_dim) # 输出维度跟随latent_dimself.fc_logvar = nn.Linear(256 * 1 * 1, latent_dim) # 输出维度跟随latent_dimself.decoder = nn.Sequential(nn.Linear(latent_dim, 256 * 4 * 4), nn.ReLU(), nn.Unflatten(1, (256, 4, 4)),nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(128),ResidualBlock(128, 128),nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(64),ResidualBlock(64, 64),nn.ConvTranspose2d(64, 32, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(32),nn.Conv2d(32, 1, kernel_size=3, stride=1, padding=1), nn.Sigmoid())def encode(self, x):h = self.encoder(x).view(x.size(0), -1)return self.fc_mu(h), self.fc_logvar(h)def reparameterize(self, mu, logvar):std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef decode(self, z):return self.decoder(z)def forward(self, x):mu, logvar = self.encode(x)z = self.reparameterize(mu, logvar)return self.decode(z), mu, logvar
编码器结构通过多层卷积和残差块逐步将输入的 32×32 单通道图像压缩为隐变量空间的概率分布参数,具体流程为:首先使用卷积核为 4×4、步长 2 的卷积层将图像尺寸从 32×32 依次降维至 16×16、8×8、4×4,再通过最后一层卷积得到 1×1 的 256 通道特征图,期间每两层卷积后接入残差块以增强特征传递和缓解梯度消失,最后通过全连接层将展平后的 256 维特征向量映射为 512 维的均值 μ 和对数方差 logσ²,为后续重参数化采样提供分布参数。解码器则以对称的反卷积结构从隐变量重构图像,先通过全连接层将 512 维隐向量扩展为 4×4×256 的特征图,再利用反卷积核为 4×4、步长 2 的反卷积层依次将尺寸恢复至 8×8、16×16、32×32,同样在每两层反卷积后使用残差块保留细节,最后通过卷积层和 Sigmoid 激活函数生成单通道 32×32 图像,像素值范围控制在 [0,1]。编码器与解码器通过残差块增强特征表达能力,以重参数化技巧实现采样过程的可导性,并通过 KL 散度和交叉熵损失平衡隐变量分布的正则化与图像重建质量,形成从图像压缩到概率建模再到重建的完整流程,为后续基于隐变量的分类任务提供有效的特征表示。
2.3 训练策略与优化
# VAE损失函数 - 结合重构损失和KL散度
def vae_loss(recon_x, x, mu, logvar, beta=1.0):# 重构损失:衡量重建图像与原始图像的差异recon_loss = F.binary_cross_entropy(recon_x, x, reduction='mean') * 1024# KL散度:衡量潜在分布与标准正态分布的差异kld_loss = beta * (-0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp()))return recon_loss + kld_loss, recon_loss, kld_loss重构损失(Reconstruction Loss):衡量模型生成的样本与原始输入样本的相似程度,确保编码和解码过程不会丢失过多信息。使用二分类交叉熵(BCE)并乘以 1024(32x32 图像的像素数),将像素级损失缩放至合理范围,避免因像素数多导致损失值过小难以优化。
KL 散度损失(KL Divergence Loss):保编码器输出的潜在变量分布尽可能接近预设的先验分布。这一步是 VAE 区别于普通自动编码器的核心,它使潜在空间具有连续性和语义连贯性,从而支持生成新样本。通过beta参数动态调整 KL 散度的权重,训练初期(前 5 个 epoch)逐步增加beta至 1.0(暖启动),避免早期因强制拟合正态分布导致的生成质量下降。
公式beta = min(1.0, (epoch + 1)/5.0)实现线性增长,平衡了重建质量与潜在分布的正则化。这种策略称为 "Annealed VAE",早期优先优化重建能力(低 β 值),后期强化隐空间正则化(高 β 值),平衡了特征保留与分布规则化。
2.4 自适应学习率调度
使用ReduceLROnPlateau根据验证损失动态调整学习率:
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=3)
scheduler.step(avg_loss)当验证损失停滞时,自动将学习率降低 50%,避免模型陷入局部最优,提升训练稳定性。
2.5 图像重建
# 图像重建可视化函数
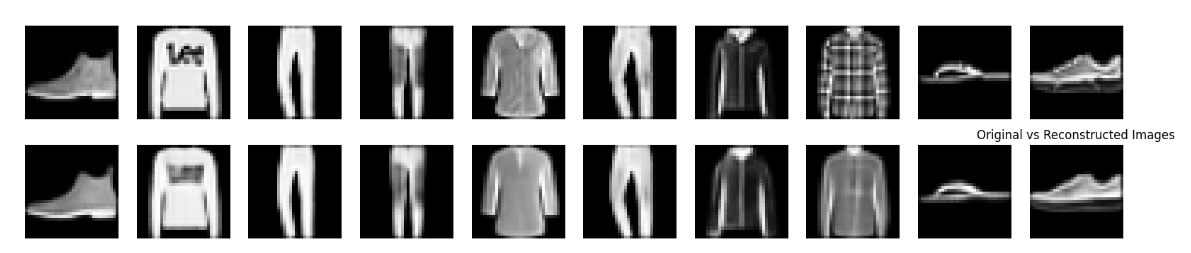
def reconstruct_images(model, test_loader, device, num_images=10):model.eval()with torch.no_grad():# 获取一批测试图像data, _ = next(iter(test_loader))data = data[:num_images].to(device)# 生成重建图像recon, _, _ = model(data)# 可视化原始图像和重建图像plt.figure(figsize=(20, 4))for i in range(num_images):# 原始图像plt.subplot(2, num_images, i + 1)plt.imshow(data[i].cpu().squeeze(), cmap='gray')plt.axis('off')# 重建图像plt.subplot(2, num_images, i + 1 + num_images)plt.imshow(recon[i].cpu().squeeze(), cmap='gray')plt.axis('off')plt.title('Original vs Reconstructed Images')plt.show()输入图像 → 编码器 → 隐变量(μ, logvar) → 重参数化采样 → 解码器 → 重建图像
2.6 特征提取
# 提取隐变量函数 - 从编码器获取潜在空间表示
def extract_latents(model, data_loader, device, use_mu=False):model.eval()latents, labels = [], []with torch.no_grad():for data, target in data_loader:data = data.to(device)mu, logvar = model.encode(data)# 使用均值或采样的潜在变量z = model.reparameterize(mu, logvar) if not use_mu else mulatents.append(z.cpu())labels.append(target)return torch.cat(latents, dim=0), torch.cat(labels, dim=0)输入图像 → 编码器 → 隐变量(μ 或采样的 z) → 保存隐变量(不经过解码器)
三,测试结果
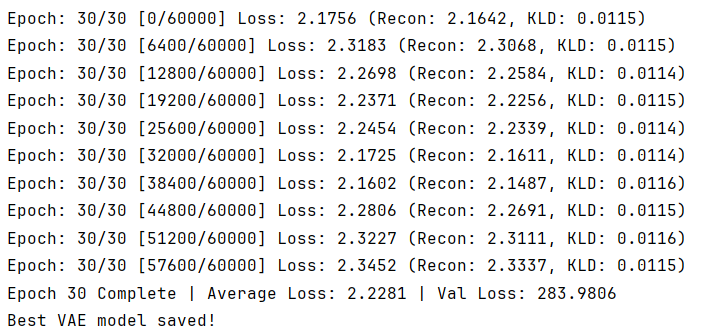
3.1 VAE在自监督学习结果
3.2 VAE重建图像
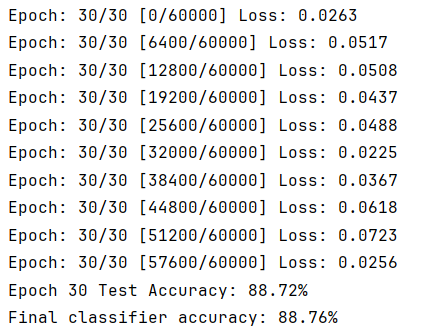
3.3 VAE对于分类任务的准确度
3.4 总结
VAE(变分自动编码器)相比传统自动编码器(AE)的核心优势在于其概率建模能力:AE 将输入编码为确定性隐向量,隐空间结构无序,仅能实现数据重建;而 VAE 通过将输入映射为概率分布(均值与方差),结合重参数化技巧生成隐向量,不仅通过 KL 散度约束隐空间接近标准正态分布、提升泛化能力,还赋予隐空间语义连续性(如向量插值对应平滑语义过渡),支持随机生成新样本且质量更优。此外,VAE 的概率特征在分类等下游任务中表现更具鲁棒性,KL 散度的正则化作用也有效控制了过拟合,使其在生成、特征学习等场景中更具优势。
四,完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
from torch.optim.lr_scheduler import ReduceLROnPlateau# 设置随机种子确保实验可复现
torch.manual_seed(42)
np.random.seed(42)
torch.backends.cudnn.deterministic = True# 残差块结构 - 帮助构建更深的神经网络
class ResidualBlock(nn.Module):def __init__(self, in_channels, out_channels):super(ResidualBlock, self).__init__()# 第一个卷积层+批量归一化self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(out_channels)# 第二个卷积层+批量归一化self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)# 快捷连接:处理输入输出通道数不一致的情况self.shortcut = nn.Sequential() if in_channels == out_channels else nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1),nn.BatchNorm2d(out_channels))def forward(self, x):# 前向传播路径:卷积 -> 归一化 -> ReLU -> 卷积 -> 归一化 -> 残差连接 -> ReLUout = F.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x) # 残差连接,解决深层网络梯度消失问题return F.relu(out)# VAE模型 - 变分自动编码器
class VAE(nn.Module):def __init__(self, latent_dim=512): # 关键修改:潜在空间维度默认设为512super(VAE, self).__init__()# 编码器网络 - 将输入图像映射到潜在空间self.encoder = nn.Sequential(# 四层卷积+残差块,逐步降低空间维度,增加通道数nn.Conv2d(1, 32, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(32),ResidualBlock(32, 32),nn.Conv2d(32, 64, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(64),ResidualBlock(64, 64),nn.Conv2d(64, 128, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(128),ResidualBlock(128, 128),nn.Conv2d(128, 256, 4, stride=1, padding=0), nn.ReLU(), nn.BatchNorm2d(256))# 全连接层计算潜在空间的均值和对数方差self.fc_mu = nn.Linear(256 * 1 * 1, latent_dim)self.fc_logvar = nn.Linear(256 * 1 * 1, latent_dim)# 解码器网络 - 从潜在空间重构图像self.decoder = nn.Sequential(# 线性层+反卷积层,逐步恢复空间维度,减少通道数nn.Linear(latent_dim, 256 * 4 * 4), nn.ReLU(), nn.Unflatten(1, (256, 4, 4)),nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(128),ResidualBlock(128, 128),nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(64),ResidualBlock(64, 64),nn.ConvTranspose2d(64, 32, 4, stride=2, padding=1), nn.ReLU(), nn.BatchNorm2d(32),nn.Conv2d(32, 1, kernel_size=3, stride=1, padding=1), nn.Sigmoid() # 输出范围0-1)def encode(self, x):# 编码过程:将输入图像转换为潜在空间的均值和对数方差h = self.encoder(x).view(x.size(0), -1)return self.fc_mu(h), self.fc_logvar(h)def reparameterize(self, mu, logvar):# 重参数化技巧:从潜在分布中采样,允许反向传播std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef decode(self, z):# 解码过程:从潜在向量重构图像return self.decoder(z)def forward(self, x):# 完整前向传播:编码 -> 重参数化 -> 解码mu, logvar = self.encode(x)z = self.reparameterize(mu, logvar)return self.decode(z), mu, logvar# VAE损失函数 - 结合重构损失和KL散度
def vae_loss(recon_x, x, mu, logvar, beta=1.0):# 重构损失:衡量重建图像与原始图像的差异recon_loss = F.binary_cross_entropy(recon_x, x, reduction='mean') * 1024# KL散度:衡量潜在分布与标准正态分布的差异kld_loss = beta * (-0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp()))return recon_loss + kld_loss, recon_loss, kld_loss# 数据加载函数 - 准备FashionMNIST数据集
def load_data():transform = transforms.Compose([transforms.Resize((32, 32)), # 调整图像大小为32x32transforms.ToTensor() # 转换为张量])train_dataset = datasets.FashionMNIST('./data', train=True, download=True, transform=transform)test_dataset = datasets.FashionMNIST('./data', train=False, transform=transform)return (DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=4, pin_memory=True),DataLoader(test_dataset, batch_size=128, shuffle=False, num_workers=4, pin_memory=True))# 训练VAE模型的函数
def train_vae(model, train_loader, test_loader, optimizer, scheduler, epochs=50, device='cuda'):best_loss = float('inf')for epoch in range(epochs):model.train()total_loss, total_recon, total_kld = 0, 0, 0beta = min(1.0, (epoch + 1) / 5.0) # 逐步增加KL散度权重for batch_idx, (data, _) in enumerate(train_loader):data = data.to(device)optimizer.zero_grad()# 前向传播和损失计算recon, mu, logvar = model(data)loss, recon_loss, kld_loss = vae_loss(recon, data, mu, logvar, beta)# 反向传播和优化loss.backward()optimizer.step()# 记录损失total_loss += loss.item()total_recon += recon_loss.item()total_kld += kld_loss.item()# 打印训练进度if batch_idx % 50 == 0:print(f'Epoch: {epoch + 1}/{epochs} [{batch_idx * len(data)}/{len(train_loader.dataset)}] 'f'Loss: {loss.item() / len(data):.4f} (Recon: {recon_loss.item() / len(data):.4f}, 'f'KLD: {kld_loss.item() / len(data):.4f})')# 每个epoch后调整学习率avg_loss = total_loss / len(train_loader.dataset)scheduler.step(avg_loss)# 验证模型model.eval()with torch.no_grad():recon, mu, logvar = model(next(iter(test_loader))[0].to(device))val_loss, _, _ = vae_loss(recon, next(iter(test_loader))[0].to(device), mu, logvar, beta)print(f'Epoch {epoch + 1} Complete | Average Loss: {avg_loss:.4f} | Val Loss: {val_loss.item():.4f}')# 保存最佳模型if val_loss < best_loss:best_loss = val_losstorch.save(model.state_dict(), 'best_vae.pth')print('Best VAE model saved!')# 图像重建可视化函数
def reconstruct_images(model, test_loader, device, num_images=10):model.eval()with torch.no_grad():# 获取一批测试图像data, _ = next(iter(test_loader))data = data[:num_images].to(device)# 生成重建图像recon, _, _ = model(data)# 可视化原始图像和重建图像plt.figure(figsize=(20, 4))for i in range(num_images):# 原始图像plt.subplot(2, num_images, i + 1)plt.imshow(data[i].cpu().squeeze(), cmap='gray')plt.axis('off')# 重建图像plt.subplot(2, num_images, i + 1 + num_images)plt.imshow(recon[i].cpu().squeeze(), cmap='gray')plt.axis('off')plt.title('Original vs Reconstructed Images')plt.show()# 提取隐变量函数 - 从编码器获取潜在空间表示
def extract_latents(model, data_loader, device, use_mu=False):model.eval()latents, labels = [], []with torch.no_grad():for data, target in data_loader:data = data.to(device)mu, logvar = model.encode(data)# 使用均值或采样的潜在变量z = model.reparameterize(mu, logvar) if not use_mu else mulatents.append(z.cpu())labels.append(target)return torch.cat(latents, dim=0), torch.cat(labels, dim=0)# 非线性分类器 - 用于评估潜在空间质量
class NonLinearClassifier(nn.Module):def __init__(self, input_dim, num_classes=10):super().__init__()# 两层神经网络带批归一化和Dropoutself.layers = nn.Sequential(nn.Linear(input_dim, 256),nn.ReLU(),nn.BatchNorm1d(256),nn.Dropout(0.3), # 防止过拟合nn.Linear(256, num_classes))def forward(self, x):return self.layers(x)# 训练分类器函数 - 评估VAE学习到的特征表示
def train_classifier(train_latents, train_labels, test_latents, test_labels, input_dim, num_classes, epochs=50,lr=5e-4):device = torch.device("cuda" if torch.cuda.is_available() else "cpu")classifier = NonLinearClassifier(input_dim, num_classes).to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(classifier.parameters(), lr=lr, weight_decay=1e-5)scheduler = ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=2, verbose=True)# 创建数据加载器train_dataset = torch.utils.data.TensorDataset(train_latents, train_labels)train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)test_dataset = torch.utils.data.TensorDataset(test_latents, test_labels)test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False)best_acc = 0.0for epoch in range(epochs):# 训练阶段classifier.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = classifier(data)loss = criterion(output, target)loss.backward()optimizer.step()if batch_idx % 50 == 0:print(f'Epoch: {epoch + 1}/{epochs} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.4f}')# 测试阶段classifier.eval()correct, total = 0, 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = classifier(data)_, pred = torch.max(output.data, 1)total += target.size(0)correct += (pred == target).sum().item()acc = 100.0 * correct / totalscheduler.step(acc) # 根据准确率调整学习率print(f'Epoch {epoch + 1} Test Accuracy: {acc:.2f}%')# 保存最佳模型if acc > best_acc:best_acc = acctorch.save(classifier.state_dict(), 'best_classifier.pth')print('Best classifier saved!')return best_acc# 主函数 - 程序入口点
def main():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"Using device: {device}")# 加载数据train_loader, test_loader = load_data()# 创建并训练VAE模型vae = VAE(latent_dim=512).to(device) # 关键修改:使用512维潜在空间optimizer = optim.Adam(list(vae.encoder.parameters()) + list(vae.decoder.parameters()), lr=1e-3)scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=3)print("Training VAE...")train_vae(vae, train_loader, test_loader, optimizer, scheduler, epochs=30, device=device)vae.load_state_dict(torch.load('best_vae.pth')) # 加载最佳模型# 可视化重建结果print("Reconstructing images...")reconstruct_images(vae, test_loader, device)# 提取潜在空间表示print("Extracting latents...")train_latents, train_labels = extract_latents(vae, train_loader, device, use_mu=False)test_latents, test_labels = extract_latents(vae, test_loader, device, use_mu=False)# 训练分类器评估潜在空间质量print("Training classifier...")classifier_acc = train_classifier(train_latents, train_labels,test_latents, test_labels,input_dim=512, # 与VAE的latent_dim一致num_classes=10,epochs=30)print(f"Final classifier accuracy: {classifier_acc:.2f}%")if __name__ == "__main__":main()