目录
- 一、前言
- 二、结构
- 三、创建
- 3.1 根据 ` make`创建
- 3.2 通过数组创建
- 四、内置append追加元素
- 4.1 追加元素
- 4.2 是否扩容
- 4.2.1 不扩容
- 4.2.2 扩容
- 总结
一、前言
前段时间学了go语言基础,过了一遍之后还是差很多,所以又结合几篇不同资料重新学习了一下相关内容,对slice做个总结
二、结构
Slice(切片)是一种非常灵活的数据结构,又称动态数组,依托数组实现,可以方便的进行扩容、传递等
实际上切片的结构是一个结构体,在runtime/slice 包中定义
type slice struct {array unsafe.Pointerlen intcap int
}
结构体中包含三个字段
array: 指向底层数组的指针len: 切片的长度,指的是切片中实际存在的元素个数cap: 切片的容量,指的是切片中可以容纳的元素个数
根据 slice 的定义不难看出,slice 的底层实际是一个数组,访问切片元素实际上是通过移动指针操作来访问对应下标元素的
三、创建
3.1 根据 make创建
make函数是Go的内置函数,它的作用是为slice、map或chan初始化并返回引用。make仅仅用于创建slice、map和channel,并返回它们的实例。
make 源码
func makeslice(et *_type, len, cap int) unsafe.Pointer {mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))if overflow || mem > maxAlloc || len < 0 || len > cap {// NOTE: Produce a 'len out of range' error instead of a// 'cap out of range' error when someone does make([]T, bignumber).// 'cap out of range' is true too, but since the cap is only being// supplied implicitly, saying len is clearer.// See golang.org/issue/4085.mem, overflow := math.MulUintptr(et.Size_, uintptr(len))if overflow || mem > maxAlloc || len < 0 {panicmakeslicelen()}panicmakeslicecap()}return mallocgc(mem, et, true)
}
这段代码有这几个功能
- 计算需要的内存大小(使用
MulUintptr防止溢出) - 检查长度和容量有效性
- 调用
mallocgc分配内存
可以看到,makeslice 接收三个参数,分别为类型、长度、容量,用来判断指针cap 是否溢出,如果溢出则重新分配
make 示例
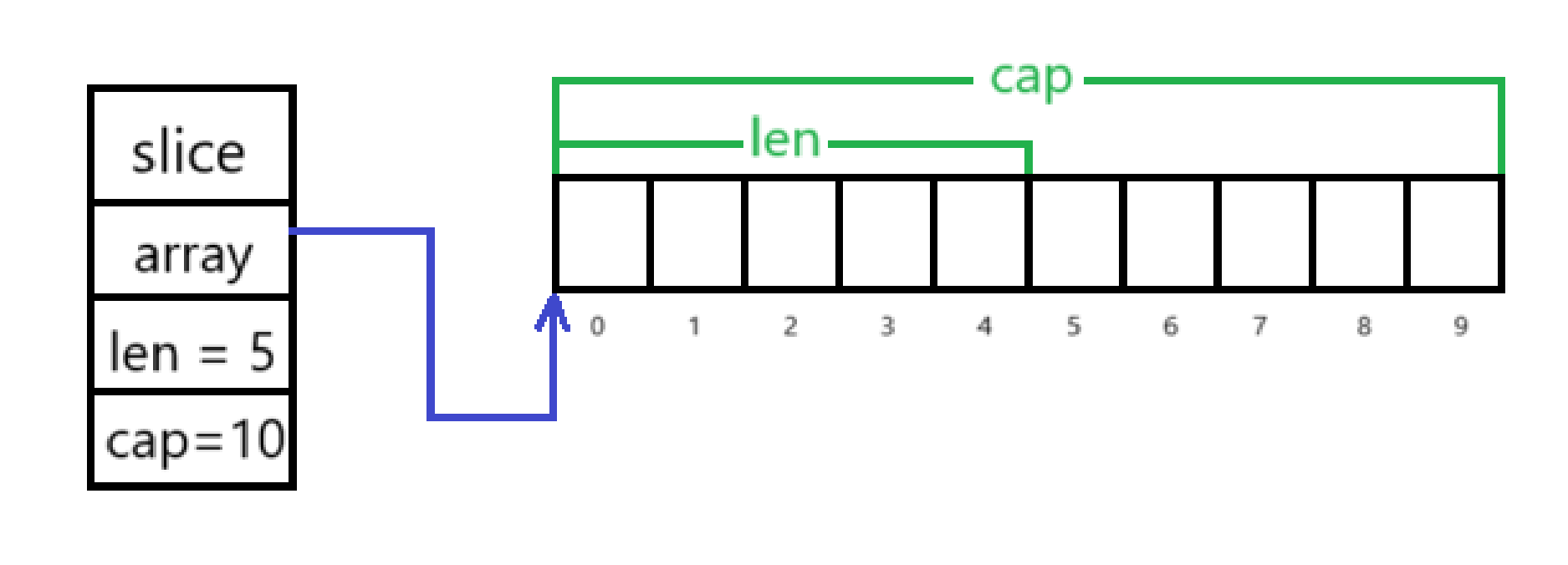
slice := make([]int, 5, 10)
这段代码的含义是:给 slice 分配一个 int 类型的底层数组,len(长度) 为5,
cap(容量) 为10
用图来表示其内部逻辑:
这时候可以通过访问数组下标添加元素
slice := make([]int, 5, 10)slice[0] = 100slice[1] = 200slice[2] = 300fmt.Println(slice) //[100 200 300 0 0]
需要注意,下标不可以超过长度,否则会引发panic,例如:
slice[5] = 500
panic: runtime error: index out of range [5] with length 5
make 的第二个参数 len 可以省略,表示 len = cap
slice := make([]int, 5)fmt.Println(len(slice)) //5fmt.Println(cap(slice)) //5
3.2 通过数组创建
通过数组创建切片,也就是截取数组中的一部分来作为切片(通过下标截取)
示例:
array := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}slice1 := array[1:4] //[1 2 3] len=3 cap=9slice2 := array[:2] //[0 1] len=2 cap=10slice3 := array[5:] //[5 6 7 8 9] len=5 cap=5
首先创建了一个数组 array ,再通过截取 array 得到切片
切片可以指向同一个底层数组,也可以和数组指向同一个底层数组,所以这三个切片实际上是这样的↓
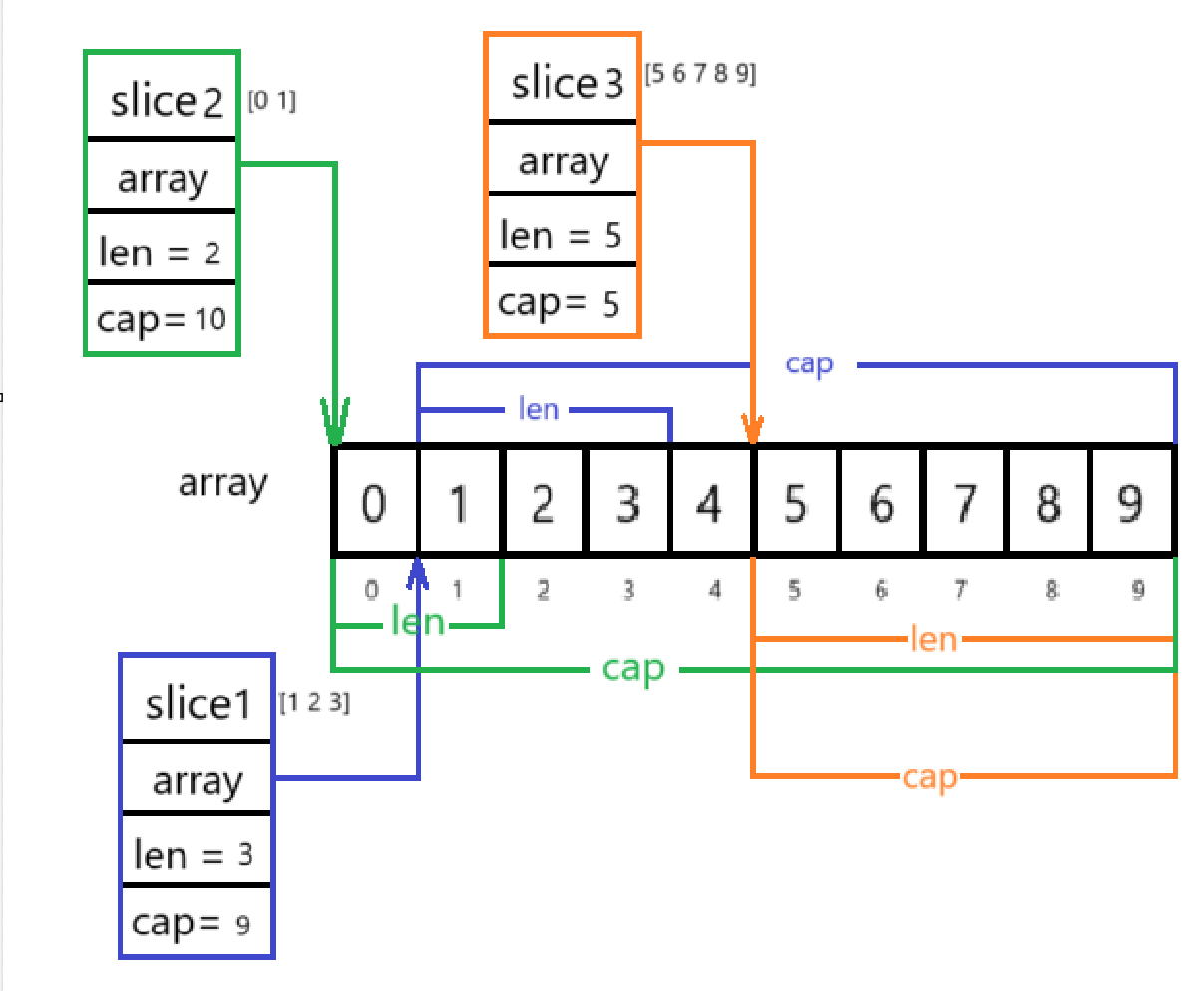
这时,如果改变其中任何一个切片的值,和它共用同一个底层数组的切片和数组都会收到影响(这导致了我们误以为在函数传参的时候切片是引用传递,实际上 go 语言中所有类型都是值传递)
len 和 cap 的计算
示例:
1. 基础用法
slice := array [ start : end : m ]
这段代码表示的含义是:slice 是数组 array 从下标 start 开始,到 end 结束(不包含end)的一段, slice 的长度(len)就是end - start, 容量(cap)是 m - start
2. m省略
如果 m 省略,那么 m = len( array ) ,容量就是 len( array ) - start
slice := array[ start : end ]
3. start 省略
如果 start 省略,表示从0开始,start = 0
array := [6]int{1, 2, 3, 4, 5, 6}slice := array[:4] //[1 2 3 4] len=4,cap=6
4. end省略
如果end省略,表示到 len( array ) 结束,end = len (array )
array := [6]int{1, 2, 3, 4, 5, 6}slice := array[3:] //[4 5 6] len=3,cap=3
四、内置append追加元素
4.1 追加元素
append 定义的源代码在 builtin.go 中
func append(slice []Type, elems ...Type) []Type
append接收两个参数,切片也就是要进行追加操作的切片
1. 追加一个元素
slice := make([]int, 0, 5)slice = append(slice, 1)fmt.Println(slice) //[1]fmt.Println(len(slice)) //1fmt.Println(cap(slice)) //5
2. 一次性追加多个元素
slice := make([]int, 0, 5)slice = append(slice, 1, 2, 3)fmt.Println(slice) //[1 2 3]fmt.Println(len(slice)) //3fmt.Println(cap(slice)) //5
3. 直接追加一个切片(不可以追加数组)
slice2 := []int{100, 200, 300}slice := make([]int, 0, 5)slice = append(slice, slice2...)fmt.Println(slice) //[100 200 300]fmt.Println(len(slice)) //3fmt.Println(cap(slice)) //5
追加切片时,切片后必须加"..."来解包切片,意思就是将一个切片的所有元素展开,这是因为切片是 [ ]int 类型,而 append 要求接收的参数是 int 类型,如果直接传入 slice2 会报错:
cannot use slice2 (variable of type []int) as int value in argument to append
4. 追加它自己
var slice []intslice = append(slice, 1, 2)slice = append(slice, 3, 4, 5)slice = append(slice, slice...)fmt.Println(slice) //[1 2 3 4 5 1 2 3 4 5]
4.2 是否扩容
在 go 中,append 函数在向切片(slice)追加元素时,只有在当前容量(cap)不足时才会触发扩容
4.2.1 不扩容
当切片的容量足够:len(slice) + 新增元素数 <= cap(slice) 时,不会扩容
eg1:容量足够时不扩容
slice := make([]int, 2, 5) //len=2, cap=5slice = append(slice, 3) //len=3, cap=5
eg2:容量不足时扩容
slice := []int{1, 2, 3} //len=3, cap=3slice = append(slice, 5) //len=4, cap=6
不扩容的底层机制
每次调用 append 函数,必须先检测slice底层数组是否有足够的容量来保存新添加的元素。如果有足够空间的话,直接扩展slice(依然在原有的底层数组之上),将新添加的元素复制到新扩展的空间,并返回slice
底层实现(伪代码)
func appendNoGrow(slice []T, elements ...T) []T {newLen := len(slice) + len(elements)if newLen <= cap(slice) { // 容量足够newSlice := slice[:newLen] // 扩展 lencopy(newSlice[len(slice):], elements) // 追加数据return newSlice}// 否则触发扩容...
}
首先计算新的长度 newLen ,通过slice创建一个新的扩展的切片,再使用copy 函数将新的元素复制
4.2.2 扩容
当切片的容量不足:len(slice) + 新增元素数 > cap(slice) 时,就会扩容
扩容的底层机制
如果没有足够的增长空间的话,append 函数则会先分配一个足够大的slice用于保存新的结果,先将原切片复制到新的空间,然后添加元素,最后新的切片和原切片引用不同的底层数组
基本扩容规则:
新容量(newCap)的计算- 若当前容量(oldCap)<1024,则二倍扩容,newCap = 2 * oldCap
- 若当前容量 >= 1024, 则 newCap = 1.25 * oldCap
- 内存对齐:最终容量会根据切片类型的大小(如 int、struct 等)向上取整到最近的内存对齐值(避免内存碎片)
append 语句示例:
slice := []int{1, 2, 3} //len=3, cap=3slice = append(slice, 5) //len=4, cap=6
扩容的具体步骤
-
计算新容量
- 假设 oldCap = 3(当前容量),追加一个元素
- 新容量 newCap = 3 * 2 = 6 (oldCap < 1024,二倍扩容)
-
分配新数组
- 创建一个长度为newCap 的新底层数组
-
数据迁移
- 将旧数组的元素复制到新数组
-
追加新元素
- 在新数组的末尾添加新元素
-
更新切片
- 新切片的 len 为 oldLen + 新增元素数,cap 为newCap
特殊案例
追加多个元素:一次性追加多个元素时,扩容会直接 计算总需求
slice := []int{1, 2} //len=2, cap=2slice = append(slice, 3, 4, 5) //len=5, cap=6
新容量计算:
- 需求容量:needCap = 2 + 3 = 5
- 按规则,newCap = 2 * 2 = 4(但4 < 5),所以会继续扩容直到 newCap >=5。这里依据二倍扩容我们预期 newCap = 8,但实际上go 的扩容策略比二倍扩容更复杂,并且有着优化,所以最终 newCap 实际上是6
为什么对 slice 扩容不直接使用 append(slice, 1)
而是要 slice = append(slice, 1)
这是因为
通常我们并不知道append调用是否导致了内存的重新分配,因此我们也不能确认新的slice和原始的slice是否引用的是相同的底层数组空间。同样,我们不能确认在原先的slice上的操作是否会影响到新的slice。因此,通常是将append返回的结果直接赋值给输入的slice变量
总结
总的来说 slice 的底层还是比较重要,对于后续的学习和面试都必不可少









![[JS逆向] 福建电子交易平台](https://i-blog.csdnimg.cn/direct/93935d89775c424a99192f1508f60ec2.png)