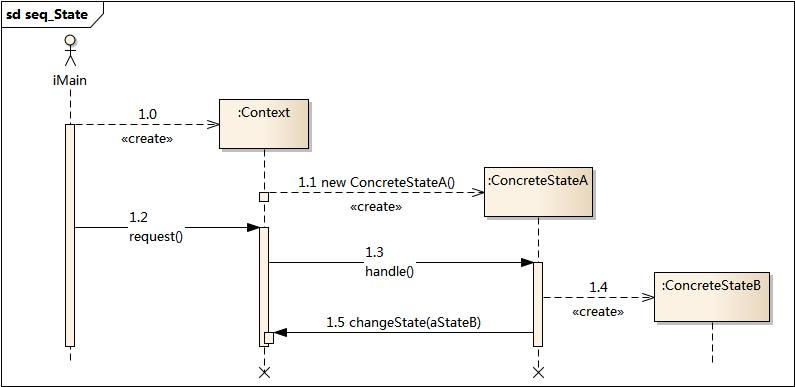
博客配套代码发布于github:福建电子交易平台
相关知识点:[爬虫知识] 密码学:通往JS逆向路上必会的一环
相关爬虫专栏:JS逆向爬虫实战 爬虫知识点合集 爬虫实战案例
此案例目标为对福建省电子公共服务平台逆向,并爬取前20页。
(如不熟悉加密算法,强烈建议先在相关知识点的密码学中完整学习,不然很多地方是看不懂的)
一、目标网站分析
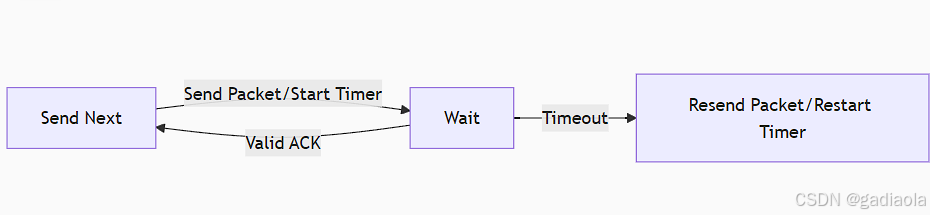
打开开发者工具,清空其他包后,能看到这里大概是个ajax请求,我们点击其他页数: ,能看到对应的数据包刷新:
,能看到对应的数据包刷新:
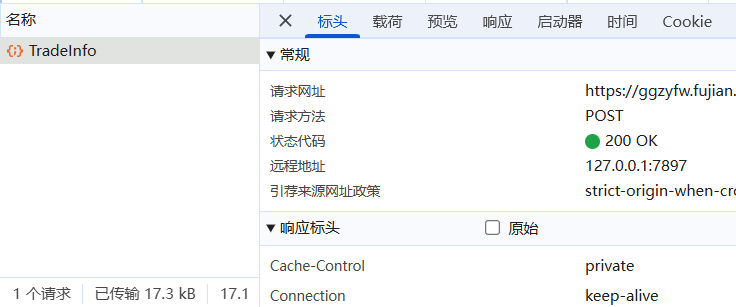 直接将其copy到Convert curl commands to Python,并复制粘贴到py,再加上下面俩行测试下:
直接将其copy到Convert curl commands to Python,并复制粘贴到py,再加上下面俩行测试下:
data = response.json()
print(response.text)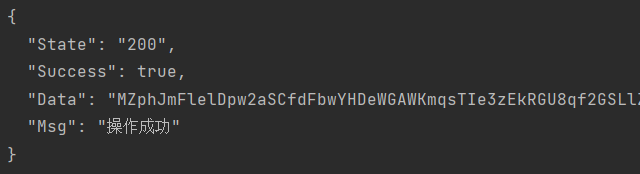 很明显返回的data数据被加密了。首先我们观察下这个Data:
很明显返回的data数据被加密了。首先我们观察下这个Data:![]()
大概猜测它是base64编码(里面有+和/这俩特殊符号),对它进行b64解密逻辑复现:
# base64编码
encrypt_data_bytes = base64.b64decode(data['Data'].encode())
print(encrypt_data_bytes)![]()
发现还是密文,这时我们基本可以确定:这是AES/DES加密算法。心里大概有底后,开始寻找key/iv(AES加解密必需的俩参数)。
二、解密逻辑
先来完成这个解密逻辑,逆向掉这个加密参数。
1.网站JS分析
既然都猜到这是AES算法了,咱也别客气,直接搜一下:
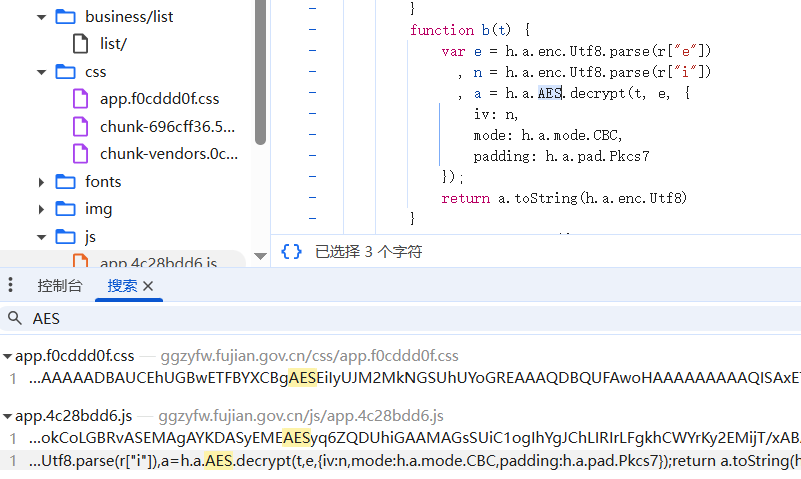 哎,这不正好搜到了一个好地儿:旁边还有iv,mode,而且还有个大大的decrypt,不是这还能是哪?开始断点并按其他页刷新:
哎,这不正好搜到了一个好地儿:旁边还有iv,mode,而且还有个大大的decrypt,不是这还能是哪?开始断点并按其他页刷新: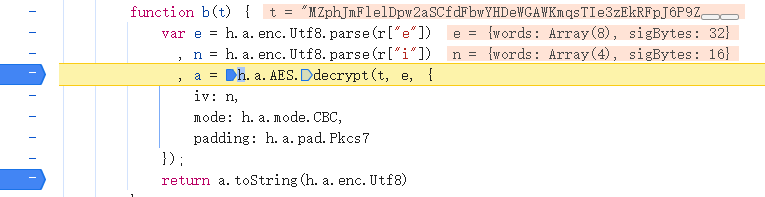
很明显被传入的t就是那个加密密文,其中r["e"]是key,r["i"]是iv,![]()
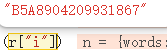 我们分别将这两个取出
我们分别将这两个取出
(key与iv可能有动态算法,此处是经动态调试后发现二者均为静态所以能直接用),
之后开始进入py算法
2.py算法复现
# 浏览器代码复现
key = b'EB444973714E4A40876CE66BE45D5930'
iv = b'B5A8904209931867'
aes = AES.new(key, AES.MODE_CBC, iv)
contents = json.loads(unpad(aes.decrypt(encrypt_data_bytes), 16).decode())# json.loads是将json格式的字符串转化为py对象的字典
print(contents)![]()
看到没问题,顺便将我们想要的内容取出下:
for i in contents['Table']:print(i['NAME'])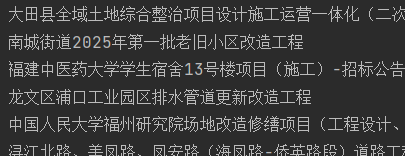
搞定。
但咱能开心了吗?并不行。
我们的确完成了解密逻辑的破解,但这个加密算法并没有解决。这一页的数据是取到了,那其他页的数据呢?想要批量爬取每一页的数据,还是得干掉这个加密参数。收拾收拾,我们开始搞加密。
三、加密逻辑
一般处理网页算法逻辑有两种做法:扣JS/PY算法复现。
通常来讲扣JS会简单点,不需要理解所有的js代码逻辑。而PY算法逻辑复现需要对大部分关键点js代码逻辑做具体分析。
这里我们选择py算法复现。
1.网站JS分析
回到网站处,我们再分析下网站请求参数里哪些是比较特殊的:
![]() json_data里这个一眼时间戳,好处理,暂时不用管。
json_data里这个一眼时间戳,好处理,暂时不用管。
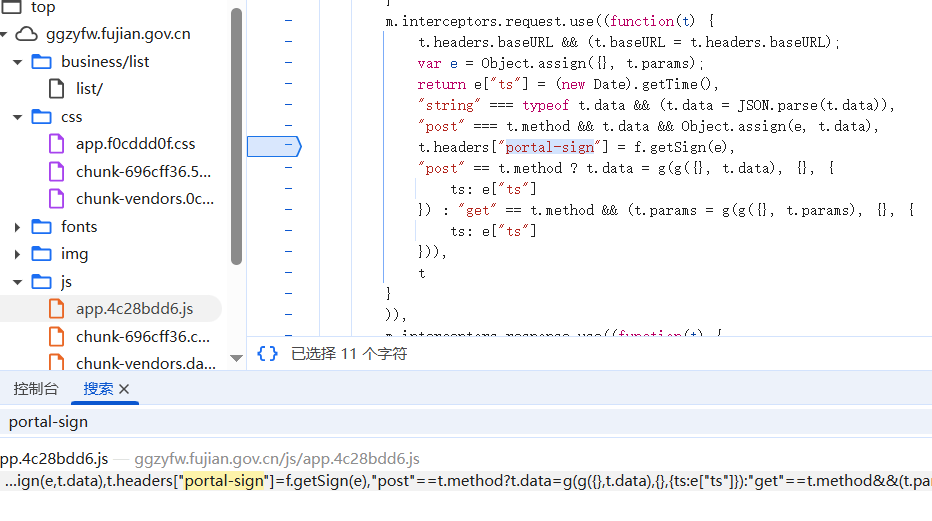
![]() 哎,你看headers里这个portal-sign,又有sign长的还像个加密参数(一眼md5),不搞它还能搞谁?开搜:
哎,你看headers里这个portal-sign,又有sign长的还像个加密参数(一眼md5),不搞它还能搞谁?开搜:
 正好就这一处位置也省的再找了。
正好就这一处位置也省的再找了。
断住这行(它都写赋值headers并且这么大个getSign了,百分之八百是这)
看看getSign的上层栈点:

看到后先把这个return断了
大概看下这段代码的逻辑:
for一行用于遍历t(t就是传入的载荷参数),并且判断,如果某个t的值为false,那么去除
所以之后的t中的空值都被去除了。
这样的t再被传入u(),正常来讲我们要接着分析u(),但别急,我们看下u(t):
![]()
发现这里u(t)就是把所有t的键值拼接到一块,那就正好不用慢慢分析u()了。
接着再看r['a']: 发现这就是个固定字符串,
发现这就是个固定字符串,
由上得到了n,再看这个s(),调栈点到其上层:
就是很正常的md5算法,把之前这个n放进来了而已。
算法已经理解完成,接下来进py复现js逻辑即可。
2.py算法实现
t = int(time.time() * 1000) # 时间戳def get_sign():# 排序sorted_items = dict(sorted(json_data.items()))a = ''for key_, value_ in sorted_items.items():if not value_:continuea += key_ + str(value_)# 合并b = 'B3978D054A72A7002063637CCDF6B2E5'c = b + a# 加入MD5obj = md5()obj.update(c.encode('utf8'))data_ = obj.hexdigest()return data_my_sign = get_sign()再把my_sign与时间戳放到对应位置,运行:
 如图,加密算法逆向完成。
如图,加密算法逆向完成。
这里讲解一下排序的逻辑:
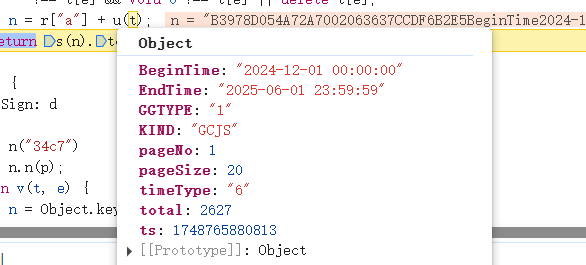
观察之前js代码中我们提到的t(json_data),发现它的排序是按照ASCII,也就是从a-z,而原本的json_data并非这种排序:![]()
这是因为字典本身就是无序的,所以我们才需要上面的排序逻辑,把字典排好位置才能进行之后的拼接。
四、完整逻辑构建与数据抓取
加解密逻辑都完成,剩下的逻辑就很简单了:
写一个for循环,并依次改变打印的每个载荷(pageNo)作为变动的页码即可。同时别忘加个time.sleep降低点请求频率,咱要做个礼貌爬虫!
for i_ in range(1, 21):# 之前代码放于此处print(f'正在打印第{i_}页...')for i in contents['Table']:print(i['NAME'])time.sleep(random.uniform(0.4, 0.7))
print(f'打印完成!一共打印20页!')
 至此,逆向完成。
至此,逆向完成。
五、小结
这个案例难度尚可,非常适合刚接触js逆向的新人练手。推荐看完本文后立刻上手自己复刻一遍操作。本案例代码已经放到github上了,欢迎点赞收藏本文并star我的仓库!后续js案例仍会继续更新,想持续学习其他案例的不妨给我个关注吧。