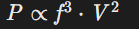引言
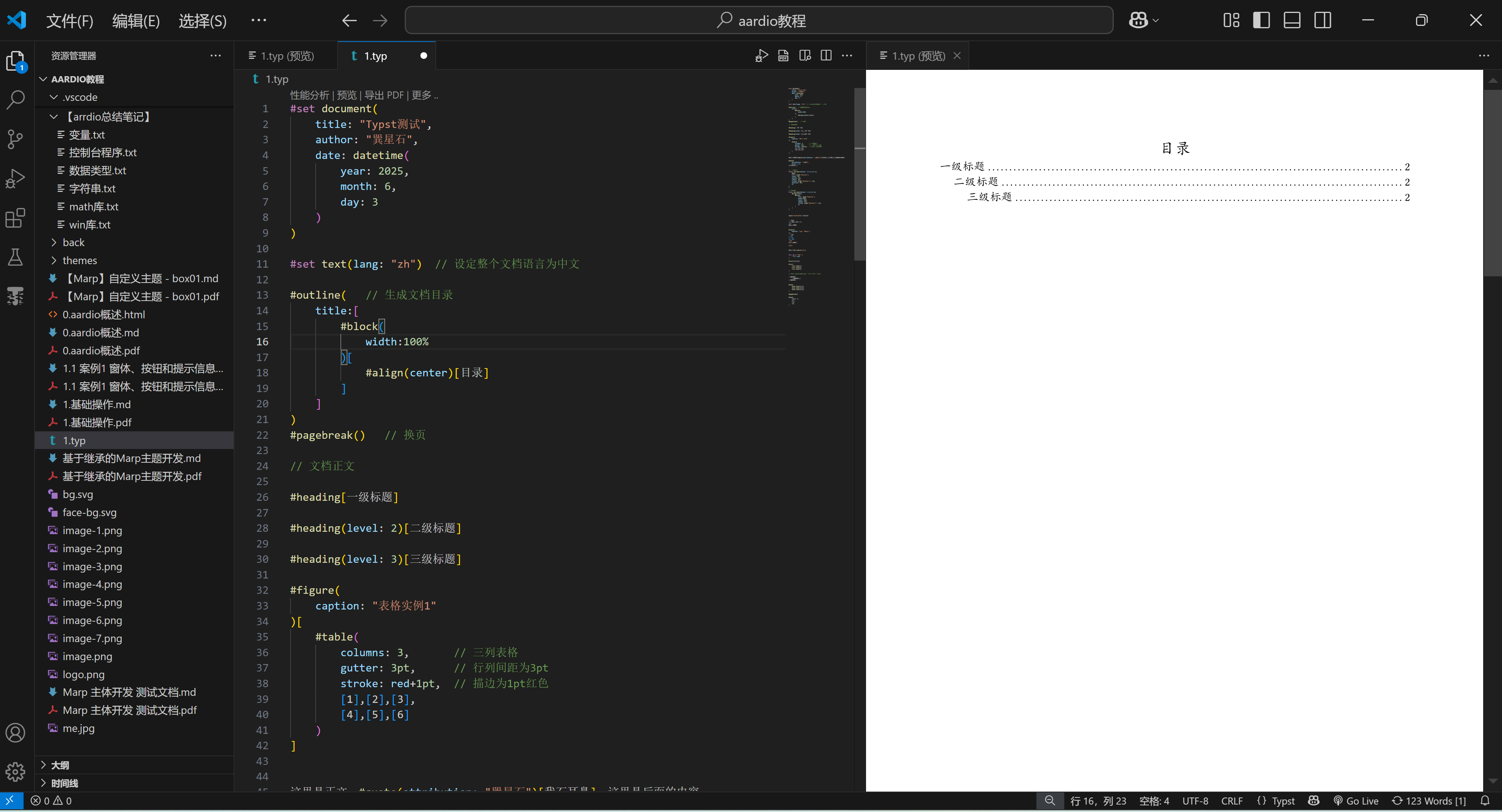
RagflowPlus v0.3.0 版本中,增加了对excel文件的解析支持,但收到反馈,说效果并不佳。
以下测试文件内容来自群友反馈提供,数据已脱敏处理。
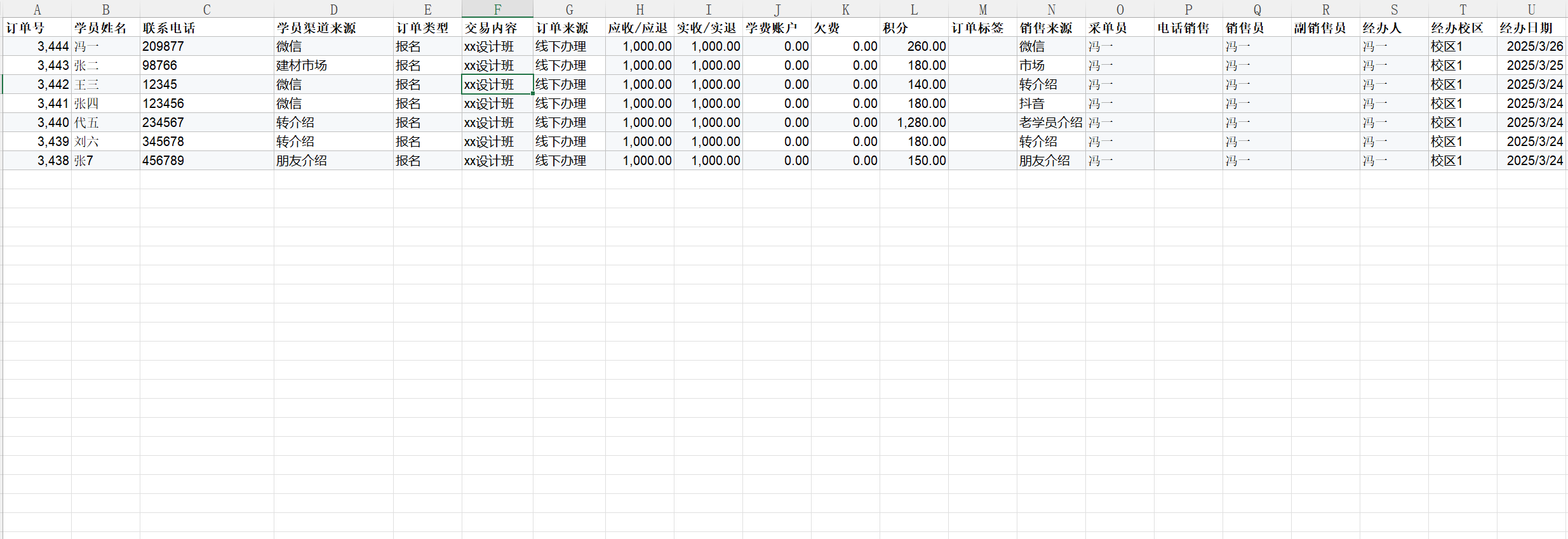
经系统解析后,分块效果如下:
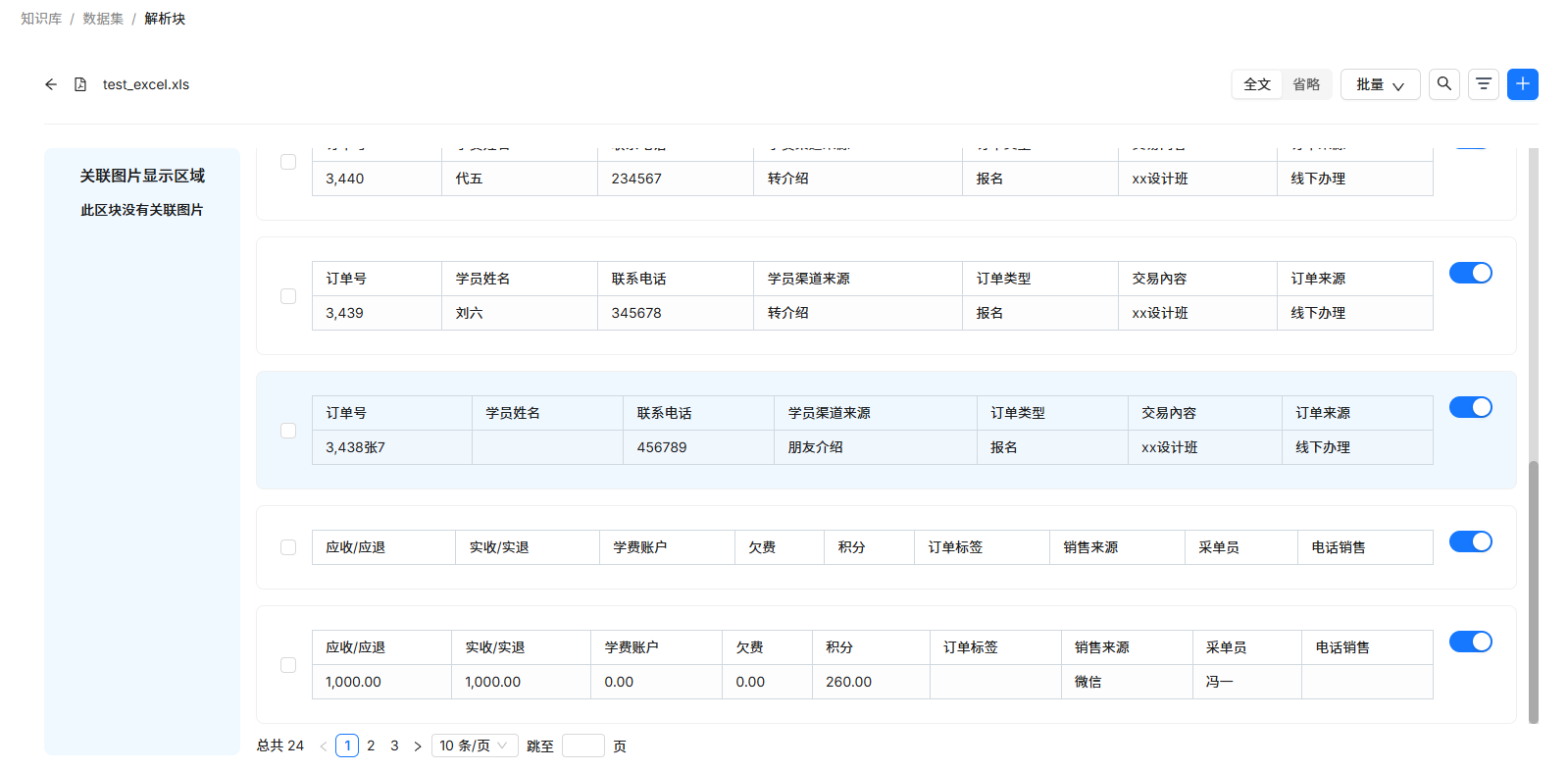
可以看到,由于该文件包含很多列信息,导致表格被截断,同一行信息完全错位,分散到了不同的chunk中。
表格解析新思路
其实问题就出在对表格文件的处理上,直接套用MinerU的文件处理管线,会先通过LibreOffice将文件转成pdf的形式,再进行表格区域识别。
其实,excel本身就是格式化的表格,这样的处理方式,就像是拿尼康八百定去拍人物写真,上重装备,还拍不好。

既然excel已经是格式化的文件,只需要用pandas去逐行读取就行了。
考虑一般表格都会有表头,每一行内容需要和表头关联,因此,每个chunk根据表头+当前行的形式划分即可,示例代码如下:
import pandas as pddef parse_excel(file_path):# 读取Excel文件df = pd.read_excel(file_path)# 获取表头headers = df.columns.tolist()blocks = []for _, row in df.iterrows():# 构建HTML表格html_table = "<html><body><table><tr>{}</tr><tr>{}</tr></table></body></html>".format("".join(f"<td>{col}</td>" for col in headers), "".join(f"<td>{row[col]}</td>" for col in headers))block = {"type": "table", "img_path": "", "table_caption": [], "table_footnote": [], "table_body": f"{html_table}", "page_idx": 0}blocks.append(block)return blocksif __name__ == "__main__":file_path = "test_excel.xls"parse_excel_result = parse_excel(file_path)print(parse_excel_result)
将这个解析逻辑融合进解析模块,再次解析,效果如下:
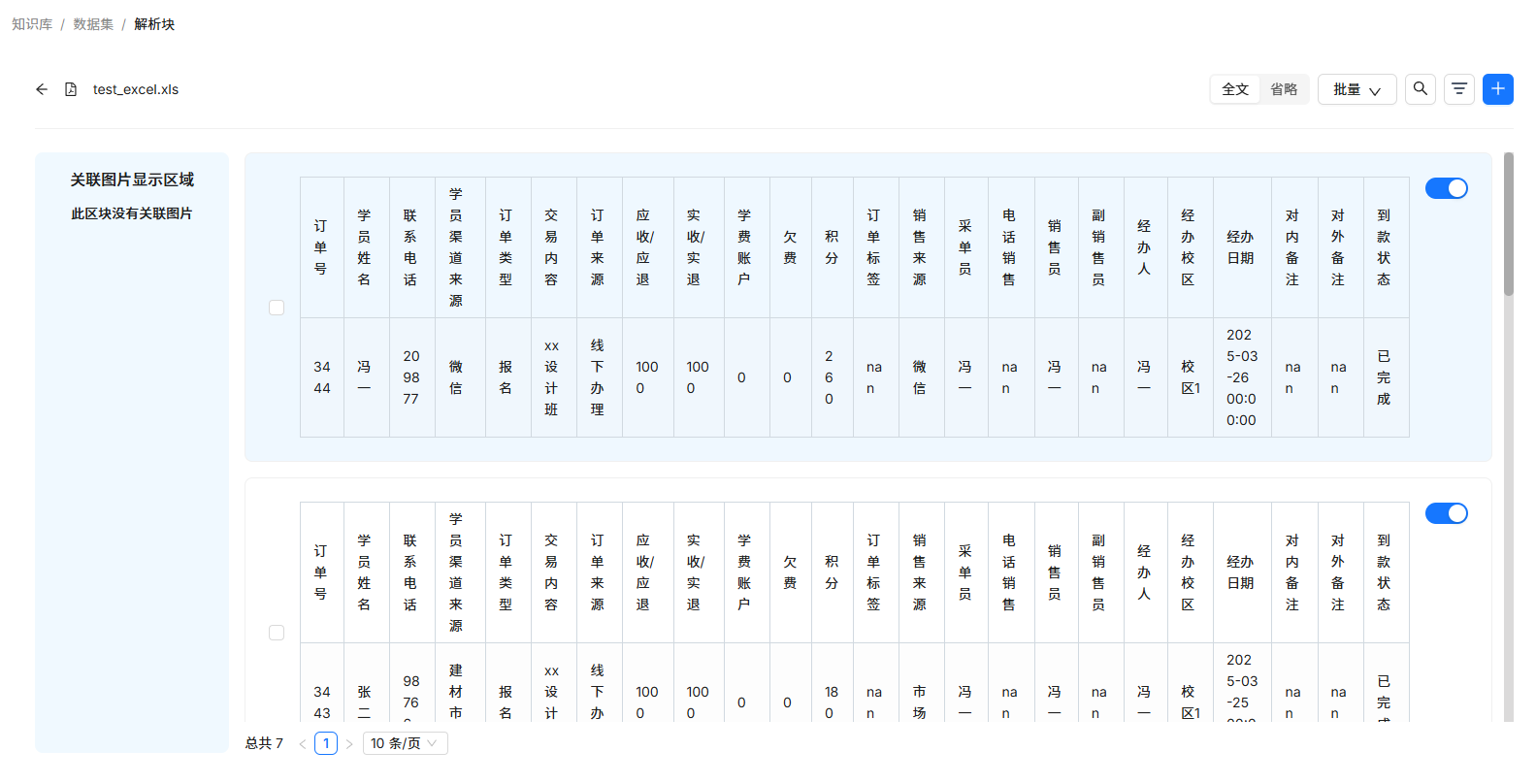
关键词编辑技巧
虽然已经把表格格式处理好了,但进行检索测试,发现效果不好,关键词相似度为0。
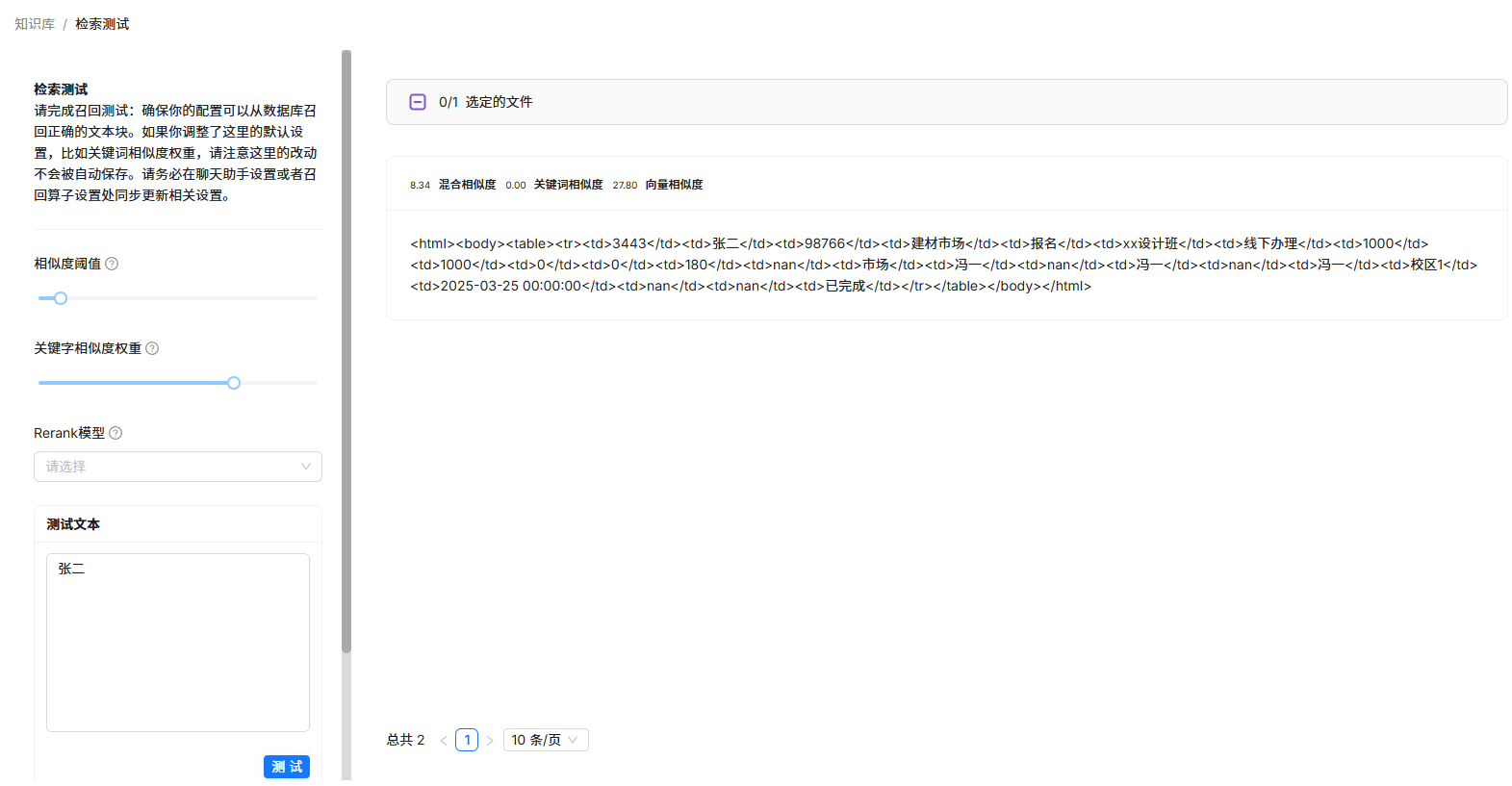
上篇文章,已经详细分析过关键词相似度的计算方式。由于表格实际上是html格式的数据,这会间接导致原始关键词的提取存在问题。
实际上,ragflow原本就提供了一种为chunk块编辑关键词的方式。
双击chunk,可以对关键词进行自定义设置。
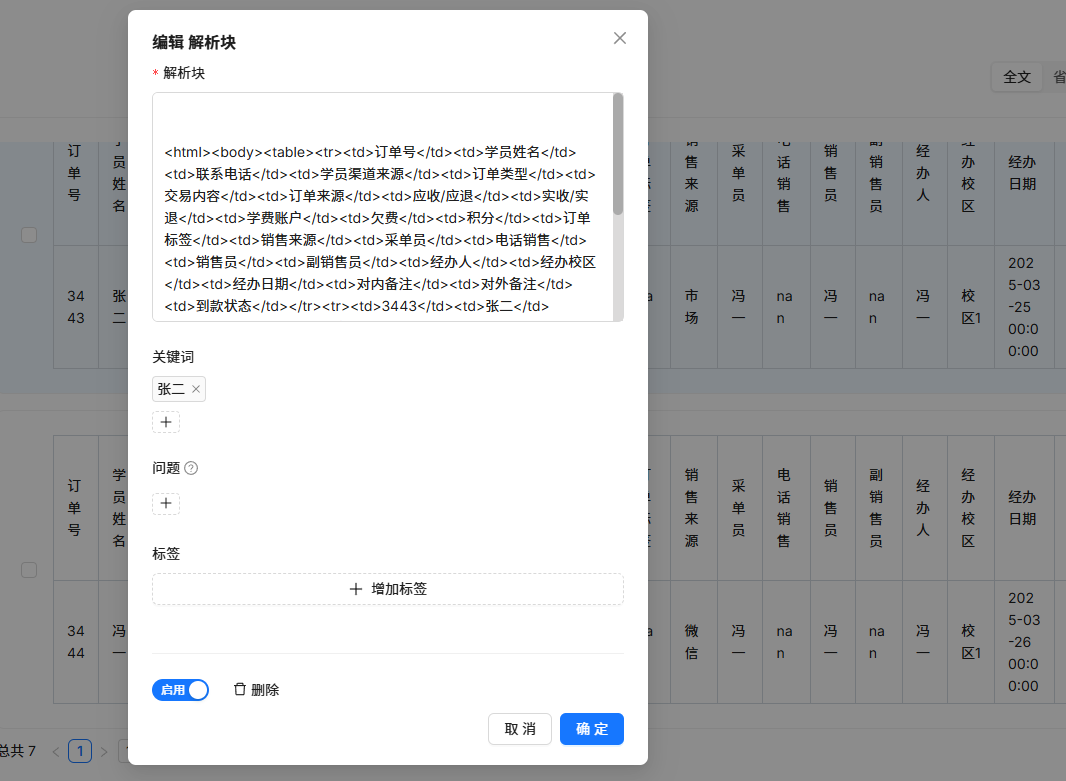
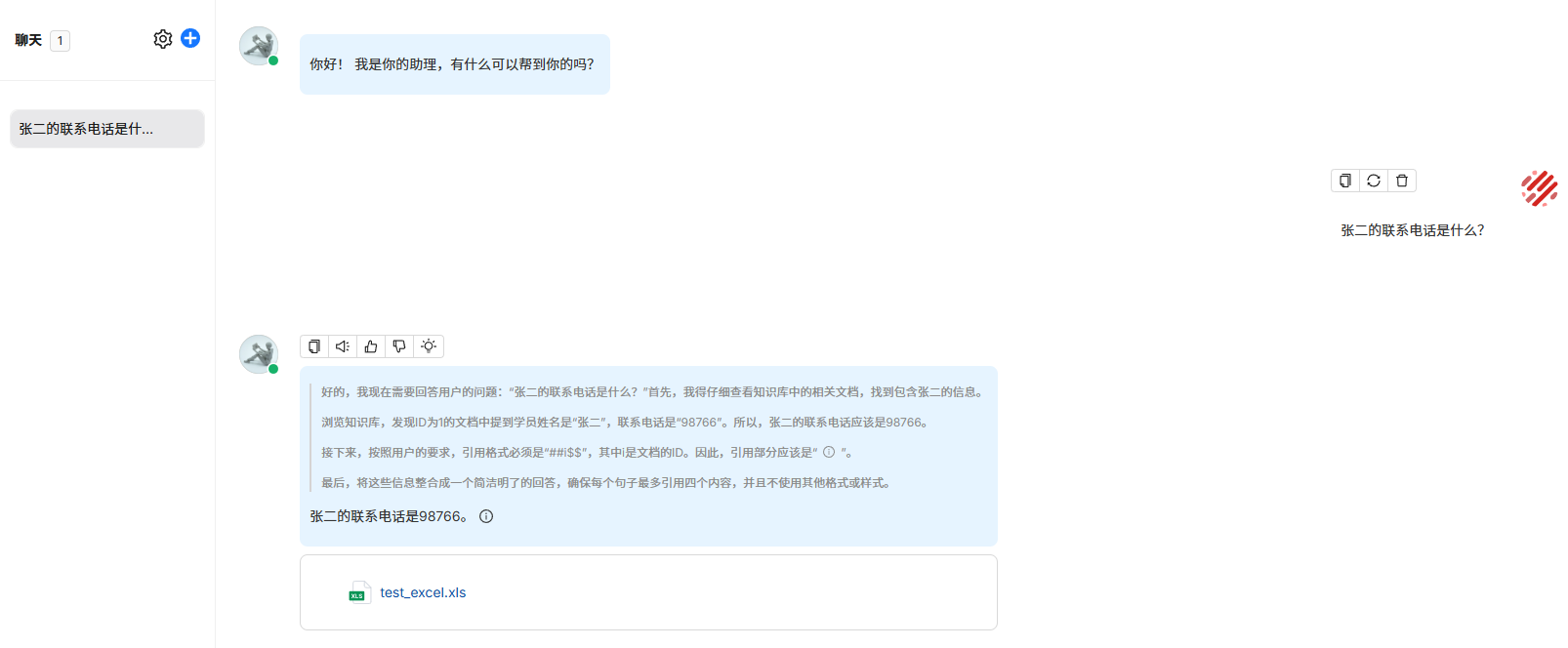
比如,我设定该chunk的关键词为某学员姓名,再次检索此关键词,关键词相似度就变成了100。
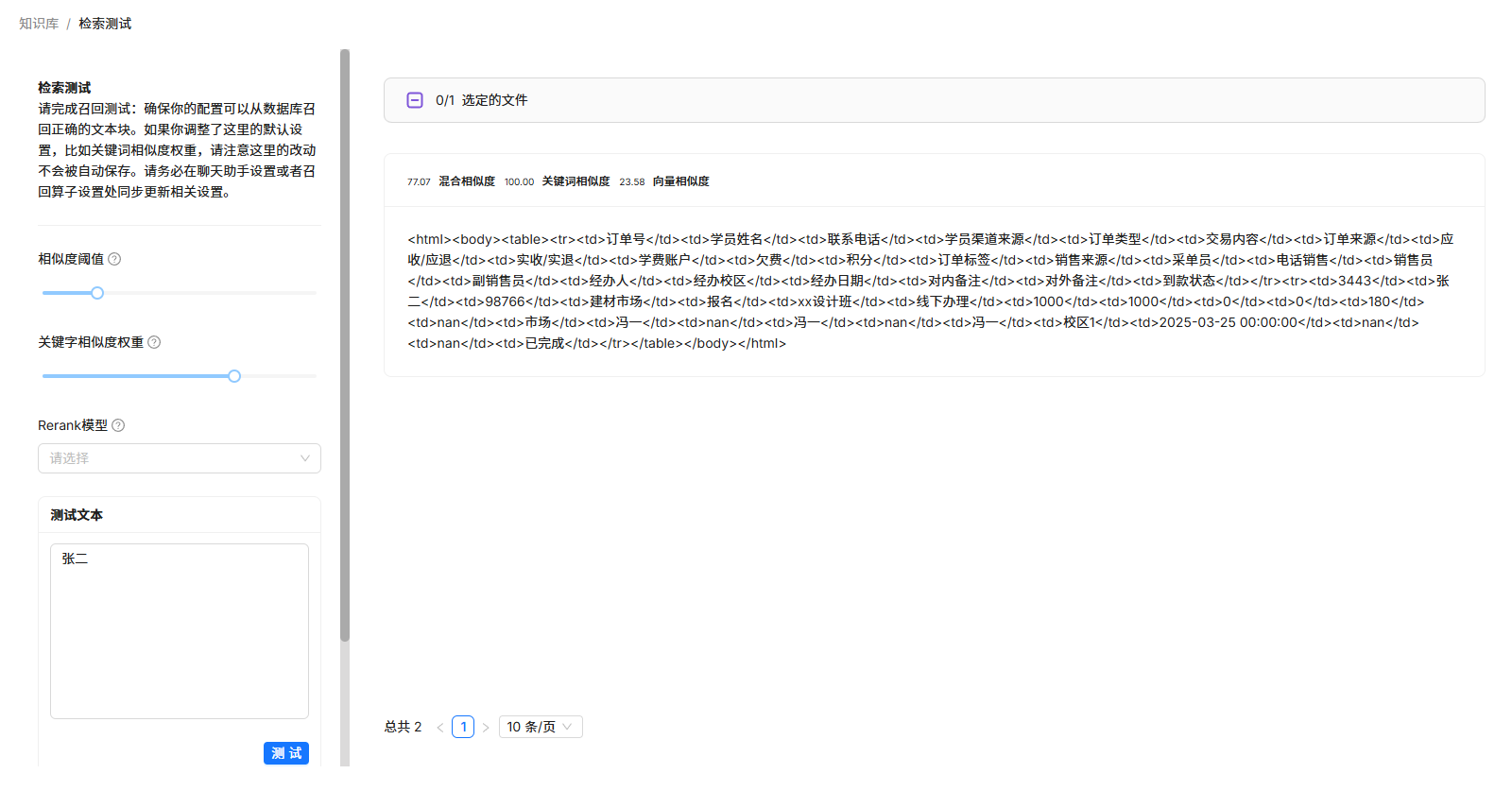
用对话模型进行测试,模型能正确检索回答。
公式解析适配
之前有群友问过:为什么解析文件时,会过滤公式的chunk。
我当时给出的回答是这样:公式都是由数学符号组成,本身和问题不会具备相似性。比如,正常问题通常会问xx公式,但不会把公式原本的形式当成问题去问。这就会导致将公式变成解析块会毫无意义,因为压根不会被检索出来。
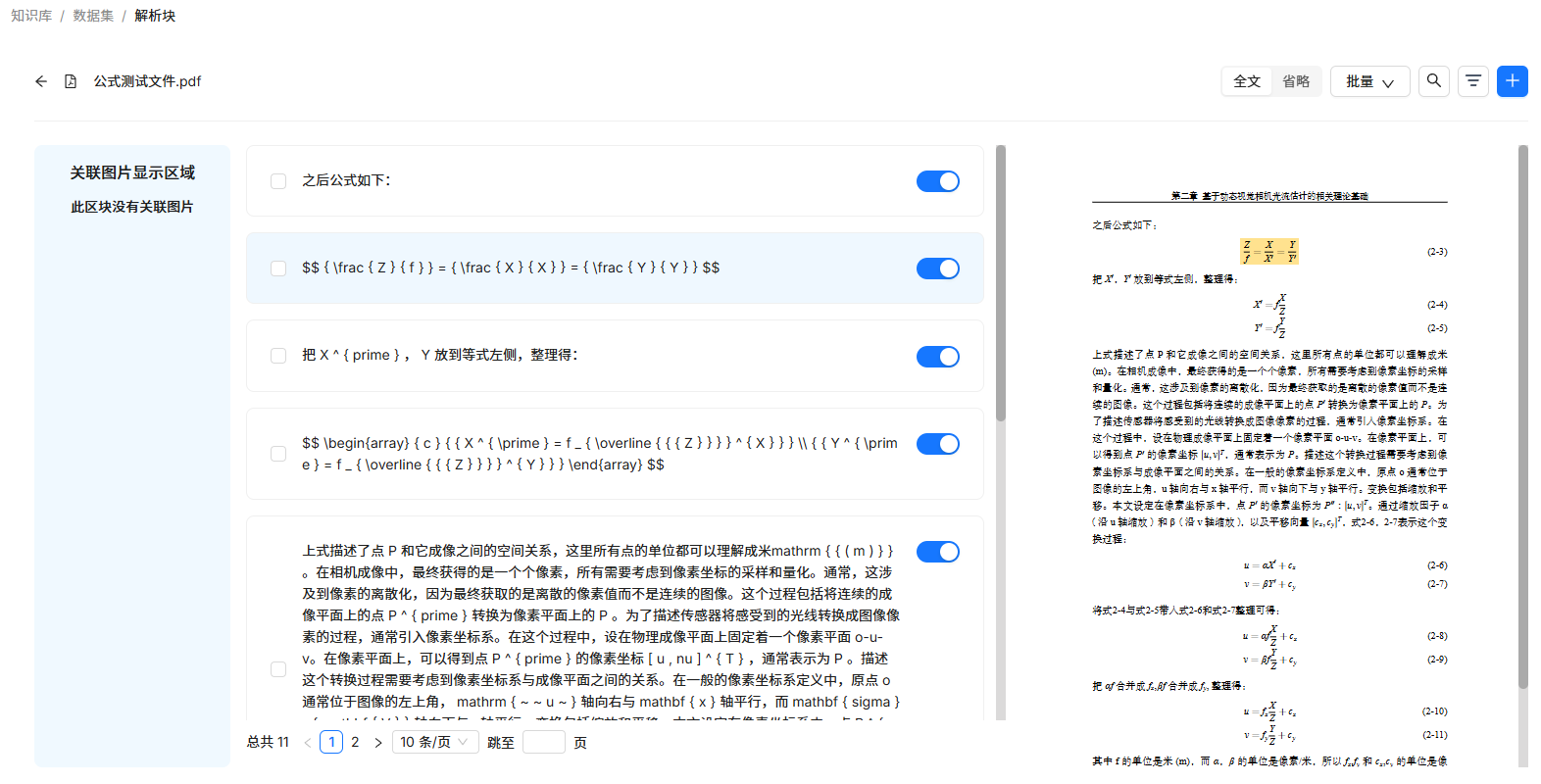
但是利用关键词编辑,就可以让公式chunk具备实际意义,因此将公式chunk添加进解析结果。
以下是一个包含公式的文件解析结果:
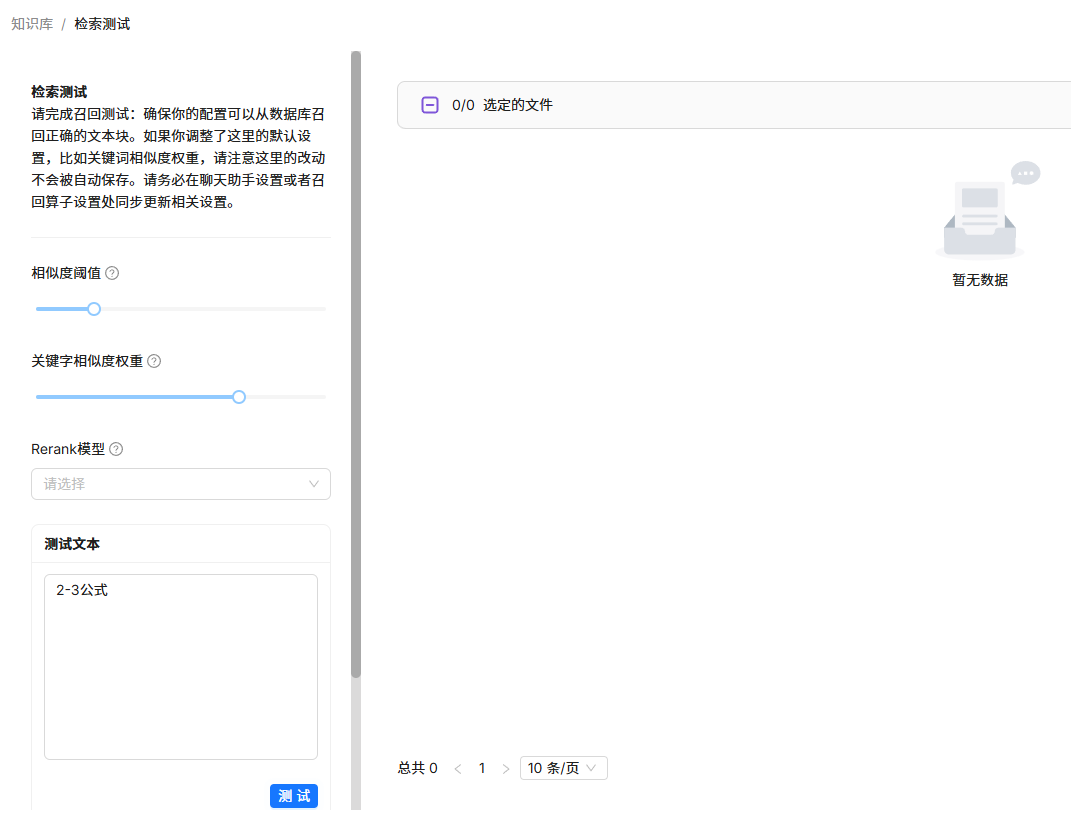
以2-3公式(假设作为一个公式的具体名字)为测试文本进行检索,是得不到任何结果的。
利用关键词编辑,为其添加关键词:
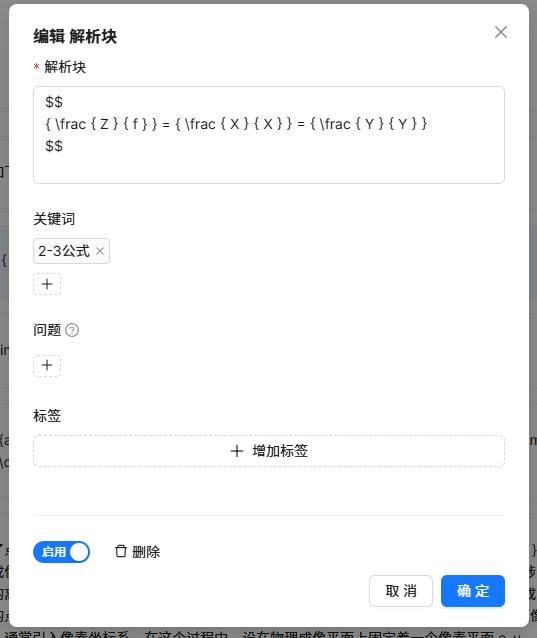
再次检索,就可以顺利检索出来。
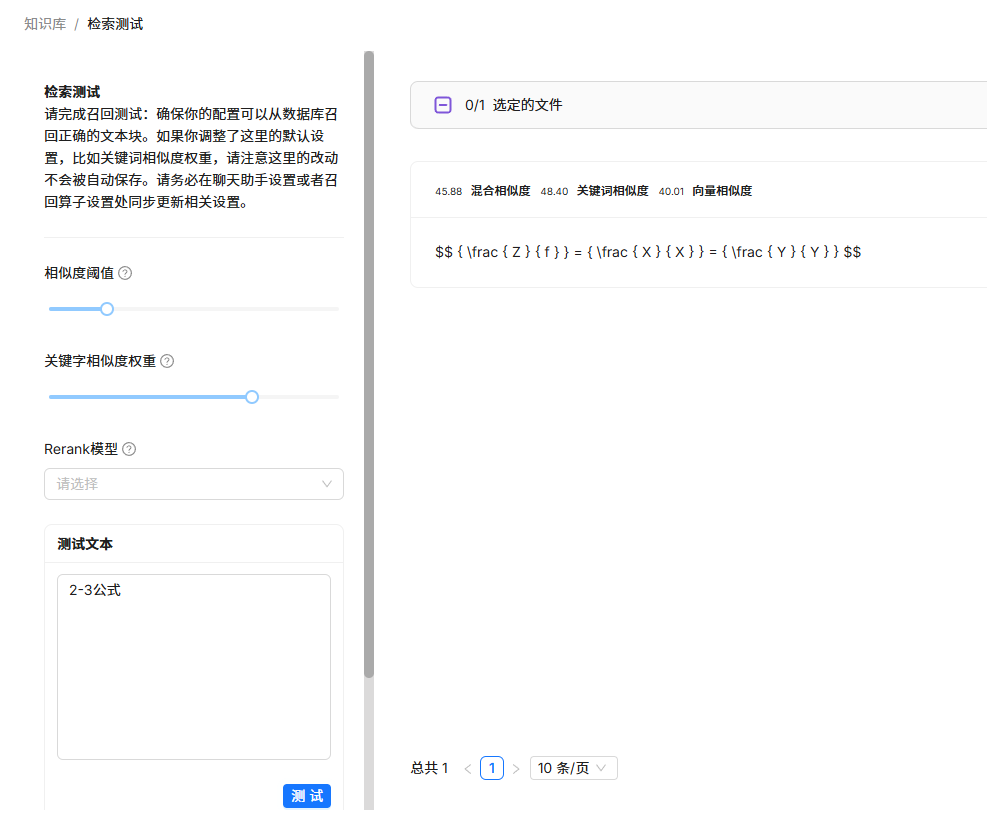
用问答模块测试,也可以正常显示。

总结
本文对表格和公式两类元素进行调优测试,不难发现,对于rag系统来说,检索是至关重要的环节。
想要效果好,就需要对每一个块进行精调。
因此,在进行对话测试前,检索测试是必要环节:如果检索不出来,那就要排查chunk块的类型和关键词设定;如果能检索到,模型回答不出来,那就是模型本身的性能问题。