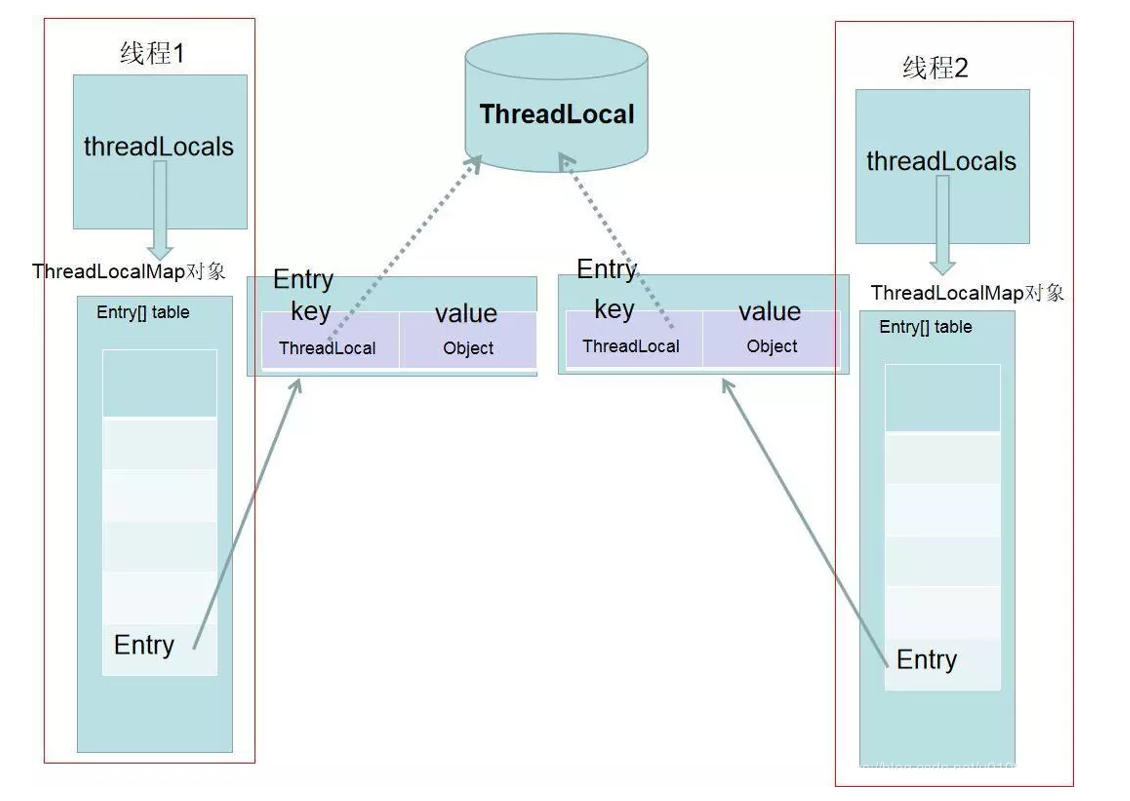
在自然语言处理(NLP)领域,词向量(Word Embedding)是基石般的存在。它将离散的符号——词语——转化为连续的、富含语义信息的向量表示,使得计算机能够“理解”语言。而在众多词向量模型中,FastText 凭借其独特的设计理念和卓越性能,尤其是在处理形态丰富的语言和罕见词方面,成为不可或缺的利器。本文将深入探讨词向量的核心概念、FastText的创新原理、技术优势、实现细节以及实际应用。
一、词向量:语言的数学化身
-
从离散到连续:One-Hot 的困境
-
传统方法(如 One-Hot Encoding)将每个词表示为一个巨大的稀疏向量(维度等于词汇表大小 V),其中只有对应词索引的位置为 1,其余为 0。
-
问题:
-
维度灾难 (Dimensionality Curse): V 可能极大(数万甚至数百万),计算和存储效率低下。
-
语义鸿沟 (Semantic Gap): 无法捕捉词之间的任何语义关系。例如,“king” 和 “queen” 的向量正交,与 “apple” 和 “king” 的距离相同,这显然不符合语言事实。
-
数据稀疏 (Data Sparsity): 大多数向量元素为 0,难以学习有效的模式。
-
-
-
词向量的曙光:分布式表示
-
核心思想:一个词的含义,可以由其上下文来定义。 出现在相似上下文中的词,往往具有相似的语义。
-
目标:将每个词映射到一个相对低维(d 维,d 通常为 50-300)的稠密实数向量空间中。
-
优势:
-
维度降低: 大幅减少计算和存储需求。
-
语义编码: 向量空间中的几何关系(如距离、方向)能反映词语的语义和语法关系。
-
相似性: 语义相似的词(如 “cat” 和 “dog”),其向量在空间中的距离较近。
-
类比关系: 经典的
king - man + woman ≈ queen或Paris - France + Germany ≈ Berlin等式成立,意味着向量运算能捕捉语义关系。
-
-
泛化能力: 即使是训练时未见过的新词组合或语境,模型也能基于向量表示进行一定程度的推理。
-
-
-
里程碑模型:Word2Vec
-
Mikolov 等人提出的 Word2Vec 是词向量发展史上的里程碑,极大地推动了应用。它包含两种高效算法:
-
Continuous Bag-of-Words (CBOW): 用周围上下文词预测中心目标词。适合较小数据集,对高频词效果更好。
-
Skip-Gram: 用中心目标词预测周围上下文词。在大型数据集上表现优异,尤其擅长处理低频词。
-
-
核心训练机制:基于神经网络(浅层结构),通过最大似然估计或负采样 (Negative Sampling) / 层次 Softmax (Hierarchical Softmax) 优化目标函数,学习词向量矩阵。
-
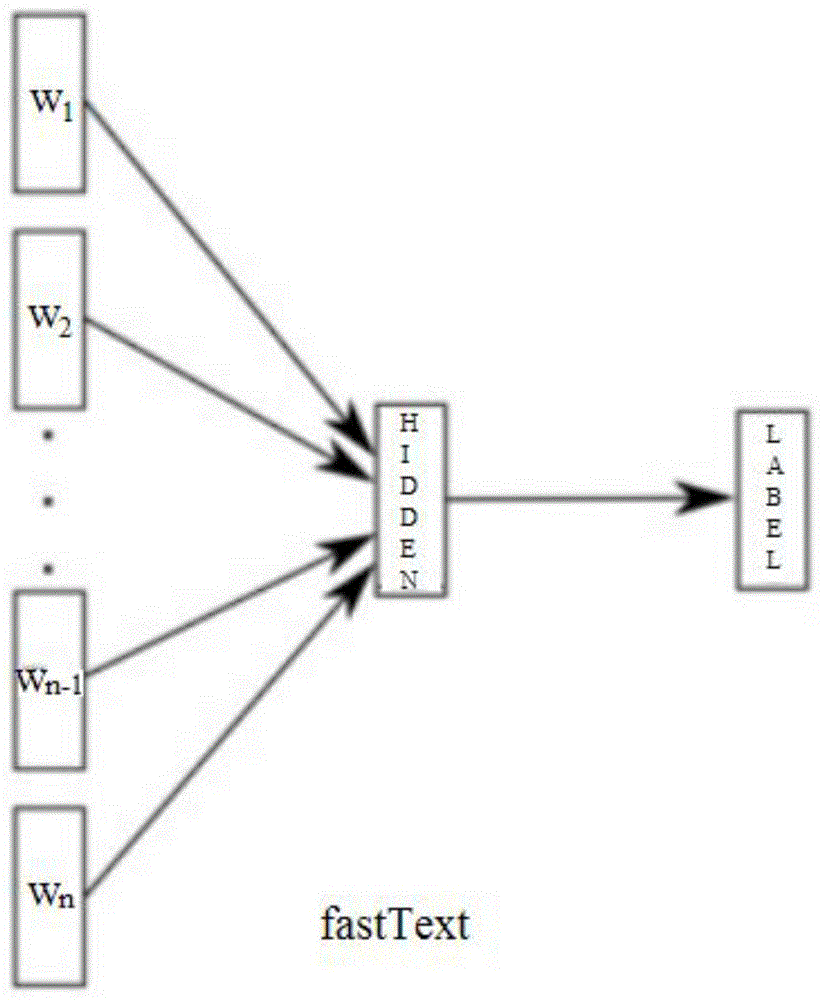
二、FastText:突破词边界的智慧
FastText 由 Facebook AI Research (FAIR) 团队于 2016 年提出。它在 Word2Vec 的 Skip-Gram 模型基础上,引入了革命性的创新:子词信息 (Subword Information)。
-
Word2Vec 的瓶颈:形态学与罕见词
-
Word2Vec 将每个词视为一个独立的原子单元,学习一个固定的向量。
-
问题:
-
形态丰富语言 (Morphologically Rich Languages): 如德语、土耳其语、俄语、芬兰语、阿拉伯语等,存在大量通过词缀(前缀、后缀、中缀)派生的词。Word2Vec 难以有效共享不同形态变体(如 “walk”, “walked”, “walker”, “walking”)之间的语义信息。
-
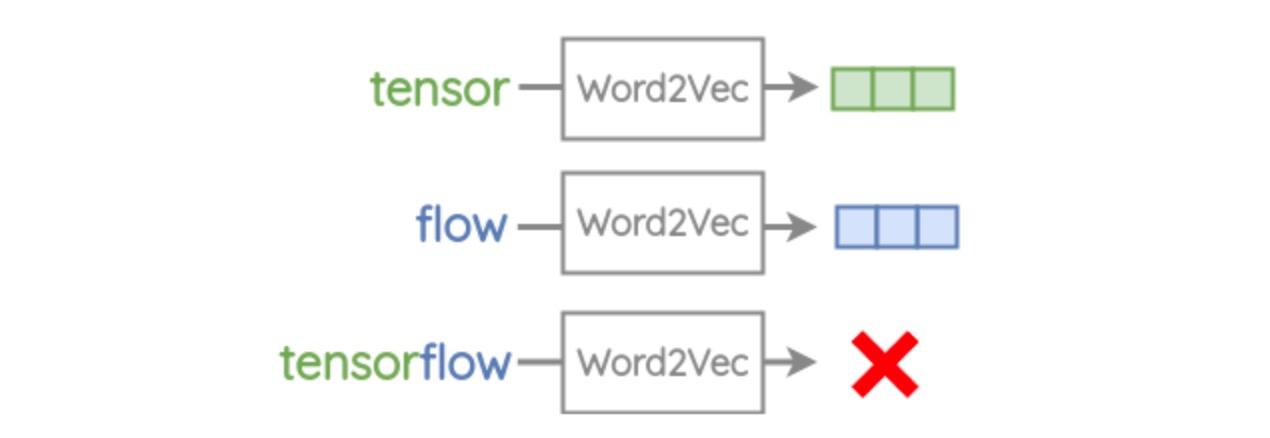
罕见词 (Rare Words) 与未登录词 (Out-of-Vocabulary, OOV): 对于训练语料中出现频率极低或从未出现的词,Word2Vec 要么学不到好的表示(稀疏),要么直接无法处理(OOV)。在专业领域、社交媒体或包含拼写错误的文本中,OOV 问题尤为突出。
-
-
-
FastText 的核心思想:词即字符 n-gram 的集合
-
核心洞见:一个词的语义不仅由其整体决定,也由其构成部分(字符序列)决定。
-
模型创新:不再只为整个词学习一个向量,而是为词的所有字符 n-gram 学习向量,并将词的向量表示为其所有字符 n-gram 向量之和(或平均)。
-
什么是 n-gram? 指连续的 n 个字符序列。例如,对于词
"apple"(假设加上边界符<apple>):-
3-gram:
<ap,app,ppl,ple,le> -
4-gram:
<app,appl,pple,ple> -
5-gram:
<appl,apple,pple>
-
-
通常 n 取 3 到 6,并同时考虑不同长度的 n-gram (如 minn=3, maxn=6)。
-
-
-
模型架构:基于 Skip-Gram 的扩展
-
FastText 主要建立在 Skip-Gram 模型之上。
-
关键修改:输入不再是中心词 w 的 one-hot 编码,而是其所有字符 n-gram 的向量表示的和(或平均)。
-
目标函数: 最大化给定中心词 w 时,其上下文词 c 出现的概率 (对数似然)。其核心公式可表示为:
J(θ) = Σ Σ log p(c | w; θ)
其中,w的向量表示v_w是其所有 n-gram g ∈ G_w 的向量z_g之和:v_w = Σ z_g。 -
预测上下文词 c 的概率通常使用 softmax 或其近似(负采样、分层 softmax)。
-
-
FastText 如何解决 Word2Vec 的痛点?
-
形态丰富语言:
-
共享的 n-gram 向量使得具有相同词根或词缀的词(如 “quickly”, “quickness”, “quicker”)能自动共享部分语义信息。因为它们包含大量重叠的 n-gram (如
qu,ick,ckl,ly等)。 -
模型能更好地理解词形变化和派生关系。
-
-
罕见词与 OOV 词:
-
罕见词: 即使一个词本身出现次数少,只要其构成字符 n-gram 在其他常见词中出现过,FastText 也能利用这些 n-gram 的信息为该罕见词生成一个相对合理的向量表示。
-
OOV 词: 这是 FastText 最强大的优势!对于训练时完全没见过的词:
-
将其分解为训练时见过的字符 n-gram。
-
将这些 n-gram 的向量(在训练过程中已学习到)求和(或平均)。
-
得到该 OOV 词的向量表示。
-
-
例如,训练语料中有 “playing”, “player”, “played”,但没有 “playable”。FastText 可以基于共享的 n-gram (如
<pl,pla,lay,ay>,able>) 生成 “playable” 的向量,其效果通常远好于随机初始化或零向量。
-
-
-
FastText 的额外优势
-
训练速度: 虽然引入了 n-gram,但通过高效的实现(如哈希技巧存储 n-gram 向量),训练速度通常与 Word2Vec 相当甚至更快,尤其在处理大型语料时。
-
内存效率: 不需要存储庞大的词汇表向量,只需存储固定数量的 n-gram 向量(数量可控)和词向量(词向量由 n-gram 向量动态计算)。词向量本身可以丢弃,只保留 n-gram 向量即可推断任意词(包括 OOV)。
-
适用于小语种和特定领域: 对数据量要求相对 Word2Vec 更低,能更好地处理形态复杂或词汇更新快的场景(如社交媒体)。
-
-
FastText vs. Word2Vec:关键对比
| 特性 | Word2Vec (Skip-Gram/CBOW) | FastText (基于 Skip-Gram) |
|---|---|---|
| 基本单元 | 词 (Word) | 字符 n-gram (Subword) |
| 词向量构成 | 每个词有独立向量 | 词向量 = 其所有字符 n-gram 向量之和 |
| 处理 OOV | ❌ 无法处理,需特殊策略 | ✅ 可通过 n-gram 向量求和生成 |
| 罕见词表示 | 通常较差 (数据稀疏) | ✅ 较好 (利用共享 n-gram) |
| 形态丰富语言 | 效果一般 | ✅ 效果显著提升 |
| 训练速度 | 快 | 相当或略快 (高效实现) |
| 内存占用 | 存储所有词向量 (O(V*d)) | 存储 n-gram 向量 (O(N*d), N 可控) |
| 模型文件 | 包含所有词向量 | 只需包含 n-gram 向量 (更小/灵活) |
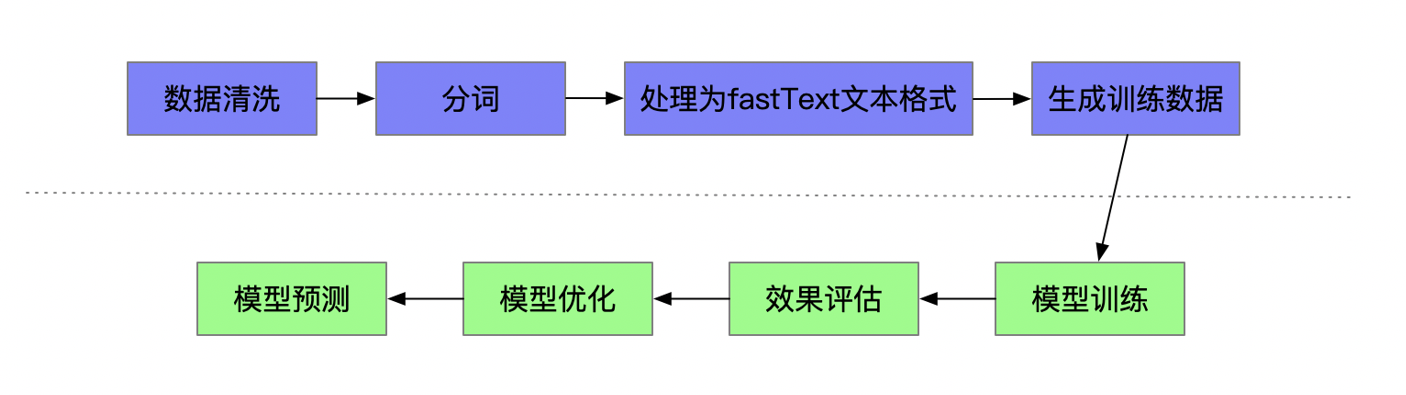
三、FastText 实战:训练与应用
-
训练 FastText 模型
-
工具: Facebook 官方提供了高效的 C++ 实现和 Python 封装 (
fasttext包)。 -
数据准备: 大规模、干净(或经过预处理)的纯文本语料库。格式通常是一行一个句子,词语用空格分隔。
-
关键参数:
-
-model:训练模式 (skipgram或cbow,推荐skipgram)。-input:输入文件路径。-output:输出模型文件前缀。-dim:词向量的维度 (如 100, 200, 300)。-minCount:词的最小出现次数阈值,低于此阈值的词被忽略。-minn/-maxn:最小/最大字符 n-gram 长度 (如minn=3,maxn=6)。-epoch:迭代次数。-lr:学习率。-ws:上下文窗口大小。-neg:负采样数量 (如果使用负采样)。-loss:损失函数 (ns负采样,hs分层 softmax,softmax)。-
示例代码 (Python):
import fasttext # 训练 Skip-Gram 模型 model = fasttext.train_unsupervised(input='your_corpus.txt', # 语料文件路径model='skipgram', # 模型类型dim=300, # 向量维度minCount=5, # 最小词频minn=3, # 最小 n-grammaxn=6, # 最大 n-gramepoch=10, # 迭代次数lr=0.05, # 学习率ws=5, # 窗口大小neg=5, # 负采样数loss='ns' # 损失函数:负采样 ) # 保存模型 model.save_model('fasttext_model.bin')
加载与使用模型
# 加载模型
model = fasttext.load_model('fasttext_model.bin')
# 1. 获取词向量 (已知词)
word = "king"
vector = model.get_word_vector(word) # 返回 numpy 数组
# 2. 获取词向量 (OOV 词) - FastText 核心优势!
oov_word = "supercalifragilisticexpialidocious"
oov_vector = model.get_word_vector(oov_word) # 通过 n-gram 合成
# 3. 寻找最近邻 (已知词)
neighbors = model.get_nearest_neighbors(word, k=5) # 返回 (相似度, 词) 元组列表
# 4. 词类比 (已知词)
analogy = model.get_analogies("king", "man", "woman", k=1) # 期望得到 'queen'
# 5. 计算词相似度
similarity = model.get_similarity(word1, word2)-
应用场景
-
文本分类: FastText 同样提供了高效的文本分类工具(
-model supervised),特别擅长处理带有大量 OOV 词或形态变化的短文本(如新闻标题、社交媒体评论、产品描述)。其原理是将文本中所有词的向量平均(或求和)作为整个文本的表示,再用于分类。 -
信息检索: 计算查询词与文档词的语义相似度,提升召回率和相关性排序。
-
命名实体识别 (NER) / 词性标注 (POS): 作为深度学习模型(如 BiLSTM-CRF)的输入特征,提供词汇的语义和形态信息。
-
机器翻译: 作为源语言和目标语言端词表示的基础,尤其受益于对形态丰富语言和罕见词的处理能力。
-
聊天机器人/问答系统: 理解用户查询和知识库内容的语义。
-
词义消歧: 结合上下文信息进行词义表示。
-
四、超越基础:FastText 的深入思考
-
与 BPE/WordPiece 的区别
-
FastText 的子词是字符级别的 n-gram,基于词的表面形式,没有显式的“合并”操作。
-
BPE (Byte Pair Encoding) / WordPiece:这些是数据驱动的子词分割算法。它们从训练语料中统计高频的字符/子词对,逐步合并形成更大的子词单元(如
"un", "aff", "able")。这些子词单元通常是有语义或形态意义的部分。像 BERT 等现代 Transformer 模型广泛使用 BPE/WordPiece。 -
核心区别: FastText 在训练词向量时隐式地利用所有可能的字符 n-gram;而 BPE/WordPiece 是预处理步骤,先确定一个固定的子词词汇表,然后在这个词汇表上进行训练。FastText 处理 OOV 更灵活(任意组合 n-gram),BPE/WordPiece 的 OOV 处理依赖于其学到的子词组合规则。
-
-
n-gram 大小选择
-
minn和maxn的选择是经验和任务相关的:-
较小的 n (如 3-4) 能捕捉更短的词缀和常见组合。
-
较大的 n (如 5-6) 能捕捉更长的词根或整个短词。
-
对于长词较多的语言或领域,可能需要更大的
maxn。 -
过大的 n 会增加计算量和内存,可能引入噪音;过小的 n 可能丢失重要信息。通常
minn=3, maxn=6是一个不错的起点。
-
-
-
模型文件与效率
-
.bin文件:包含完整的 FastText 模型(包括输入矩阵即 n-gram 向量、输出矩阵、词汇信息等),可用于继续训练、推理(找邻居、类比、计算 OOV 向量)。 -
.vec文件:通常只包含预先计算好的已知词汇表中每个词的最终向量表示(即 n-gram 向量之和)。文件更小,加载更快。 -
关键取舍:
-
使用
.bin文件:功能完整(可处理 OOV、继续训练),但文件较大,加载稍慢。 -
使用
.vec文件:文件小巧,加载极快,但丧失了 FastText 的核心优势——处理 OOV 词的能力! 它表现得就像一个普通的 Word2Vec 模型。仅在你确定应用中不会遇到 OOV 词,且只需要已知词的向量表示时使用.vec。
-
-
-
FastText 在预训练时代的定位
-
随着 BERT、GPT 等基于 Transformer 的上下文预训练模型 (Contextual Pretrained Models) 的崛起,传统的静态词向量(包括 Word2Vec 和 FastText)似乎不再是 SOTA 选择。这些新模型能为同一个词在不同上下文中生成不同的向量表示,极大地提升了语言理解的深度。
-
FastText 的价值依然存在:
-
轻量级与高效: FastText 模型小、训练和推理速度快、资源消耗低,在嵌入式设备、实时系统或资源受限场景下优势明显。
-
OOV 处理的标杆: 对于需要处理大量未知词、拼写错误或新造词的任务(如社交媒体分析、特定领域文本挖掘),FastText 的 OOV 处理能力仍然是简单有效且难以被完全替代的方案。
-
特定任务的优异表现: 在文本分类(尤其是短文本、带噪音文本)等任务上,FastText 分类器因其速度和鲁棒性,常作为强基线或生产部署的选择。
-
多语言支持: FastText 官方提供了涵盖 157 种语言的预训练词向量,对研究和快速原型开发非常有用,特别是在资源匮乏的小语种上。
-
作为基础特征: 即使在使用大型预训练模型时,FastText 向量有时仍可作为附加的静态词特征输入,提供互补信息。
-
-
总结: FastText 不是万能的,但在其擅长的领域(高效、轻量、OOV 处理、形态丰富语言、文本分类基线)依然是极其有价值的工具,是 NLP 工程师工具箱中的重要组成部分。
-
五、总结:FastText 的意义与启示
FastText 通过引入字符 n-gram 的子词信息,巧妙地解决了传统词向量模型(如 Word2Vec)在形态丰富语言、罕见词和未登录词(OOV)处理上的痛点。它将词视为字符序列的组合,利用共享的 n-gram 向量实现了词义的分解与组合,显著提升了词向量表示的鲁棒性和泛化能力。其高效的实现、对 OOV 词的处理能力以及优秀的文本分类性能,使其在工业界和学术界得到广泛应用。