6-2 MySQL 数据结构选择的合理性
文章目录
- 6-2 MySQL 数据结构选择的合理性
- 1. 全表查询
- 2. Hash 查询
- 3. 二叉搜索树
- 4. AVL 树
- 5. B-Tree
- 6.B + Tree
- 7. R树
- 8. 小结
- 附录:算法的时间复杂度
- 9. 最后:
这篇文章是我蹲在《尚硅谷》-康师傅博主家的 WiFi 上(不是),连夜 Ctrl+C / V 俩的镇站神文。
这篇转载只是为了,跟大家分享好内容,没有任何商业用途。如果你喜欢这篇文章,请一定要去原作者 B站《尚硅谷-MySQL从菜鸟到大牛》看看,说不定还能发现更多宝藏内容呢!
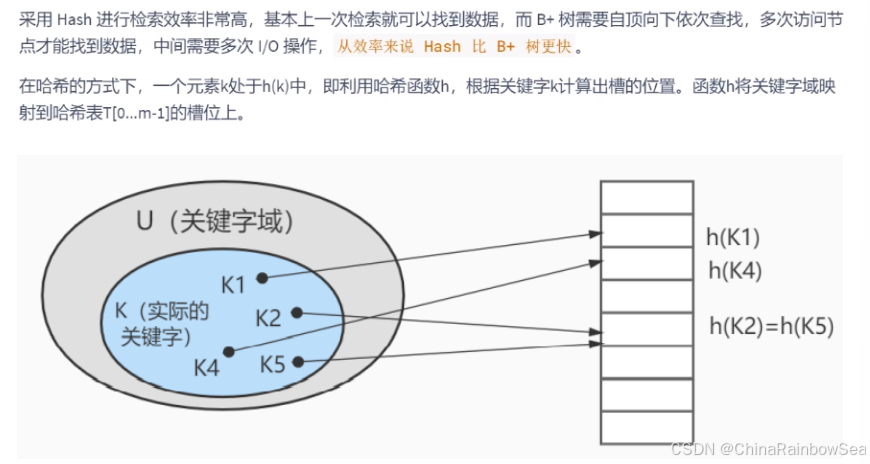
从 MySQL 的角度来说,不得不考虑一个现实问题就是磁盘IO 。如果我们能让索引的数据结构尽量减少硬盘的 I/) 操作,所消耗的时间也就越小。可以说,磁盘的 I/O 操作次数 对索引的使用效率至关重要。
查找都是索引操作,一般来说索引非常大,尤其是关系型数据库,当数据量比较大的时候,索引的大小有可能几个G甚至更多,为了减少索引在内存的占用,数据库索引是存储在外部磁盘上的 。当我们利用索引查询的时候,不可能把整个索引全部加载到内存,只能逐一加载 ,那么MySQL 衡量查询效率的标准就是磁盘的 IO 次数。
1. 全表查询
全表查询较为简单,这里就在过多赘述了。
2. Hash 查询

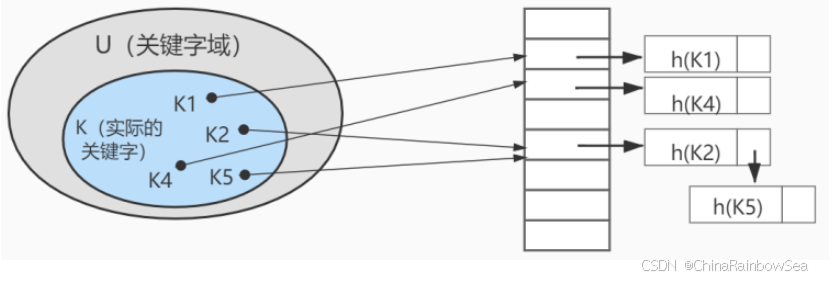
加快查找速度的数据结构,常见的有两类:
- 树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是
O(log2N); - 哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是
O(1); (key, value)
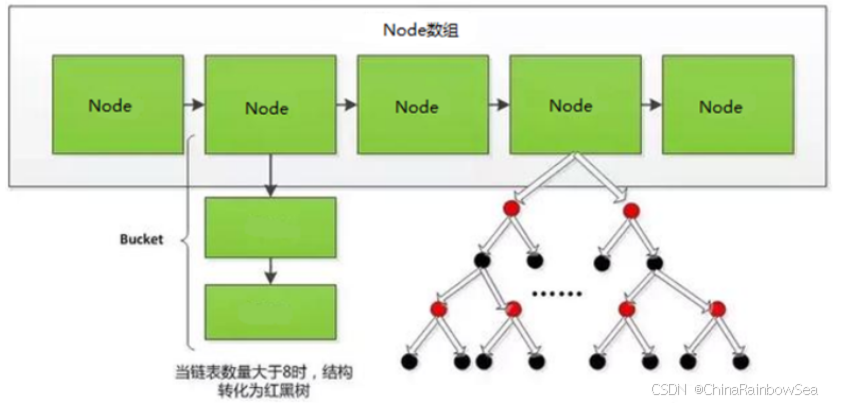
上图中哈希函数h有可能将两个不同的关键字映射到相同的位置,这叫做 碰撞 ,在数据库中一般采用 链 接法 来解决。在链接法中,将散列到同一槽位的元素放在一个链表中,如下图所示:
实验:体会数组和hash表的查找方面的效率区别
// 算法复杂度为 O(n)
@Test
public void test1(){int[] arr = new int[100000];for(int i = 0;i < arr.length;i++){arr[i] = i + 1;}long start = System.currentTimeMillis();for(int j = 1; j<=100000;j++){int temp = j;for(int i = 0;i < arr.length;i++){if(temp == arr[i]){break;}}}long end = System.currentTimeMillis();System.out.println("time: " + (end - start)); //time: 823
}
// 算法复杂度为 O(1)
@Test
public void test2(){HashSet<Integer> set = new HashSet<>(100000);for(int i = 0;i < 100000;i++){set.add(i + 1);}long start = System.currentTimeMillis();for(int j = 1; j<=100000;j++) {int temp = j;boolean contains = set.contains(temp);}long end = System.currentTimeMillis();System.out.println("time: " + (end - start)); //time: 5
}
Hash结构效率高,那为什么索引结构要设计成树型呢?

Hash索引适用存储引擎如表所示:
| 索引 / 存储引擎 | MyISAM | InnoDB | Memory |
|---|---|---|---|
| HASH索引 | 不支持 | 不支持 | 支持 |
Hash索引的适用性:

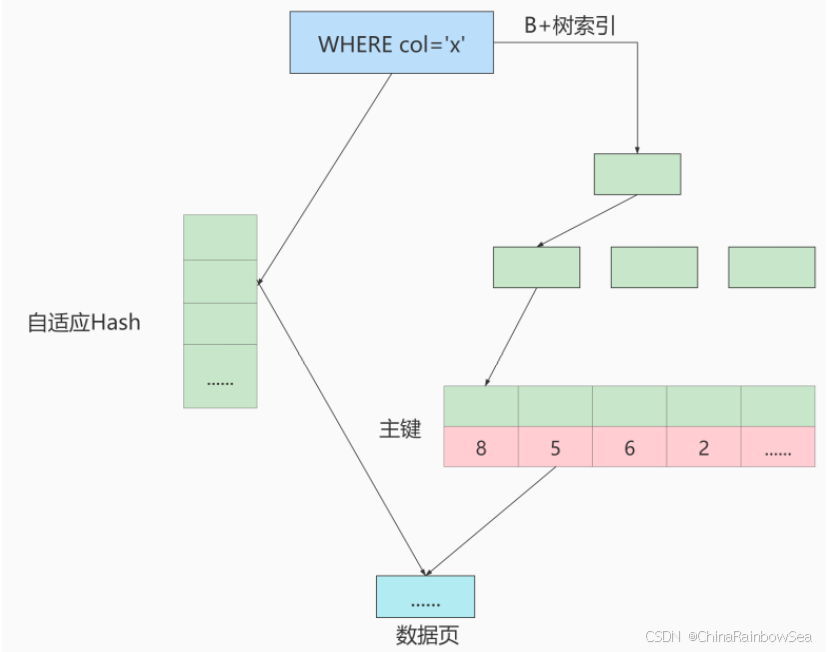
采用自适应 Hash 索引目的是方便根据 SQL 的查询条件加速定位到叶子节点,特别是当 B+ 树比较深的时 候,通过自适应 Hash 索引可以明显提高数据的检索效率。
我们可以通过 innodb_adaptive_hash_index 变量来查看是否开启了自适应 Hash,比如:
mysql> show variables like '%adaptive_hash_index';
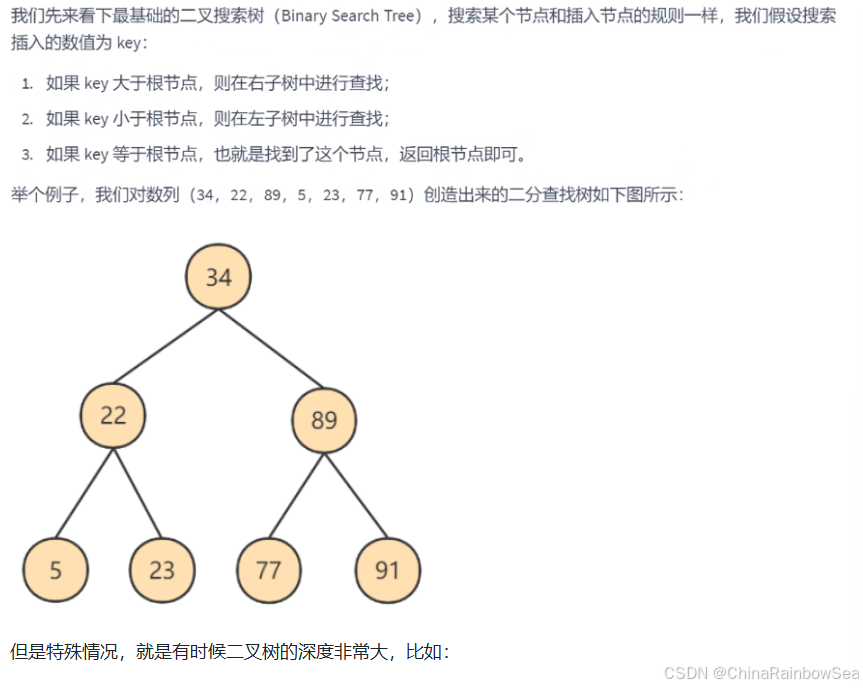
3. 二叉搜索树
如果我们利用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。
1. 二叉搜索树的特点
- 一个节点只能有两个子节点,也就是一个节点度不能超过2
- 左子节点 < 本节点; 右子节点 >= 本节点,比我大的向右,比我小的向左
2. 查找规则

为了提高查询效率,就需要 减少磁盘IO数 。为了减少磁盘IO的次数,就需要尽量 降低树的高度 ,需要把 原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。
4. AVL 树

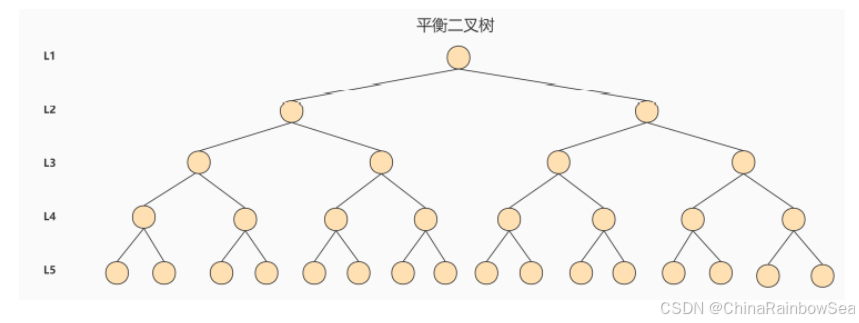
`每访问一次节点就需要进行一次磁盘 I/O 操作,对于上面的树来说,我们需要进行 5次 I/O 操作。虽然平衡二叉树的效率高,但是树的深度也同样高,这就意味着磁盘 I/O 操作次数多,会影响整体数据查询的效率。
针对同样的数据,如果我们把二叉树改成 M 叉树 (M>2)呢?当 M=3 时,同样的 31 个节点可以由下面 的三叉树来进行存储:
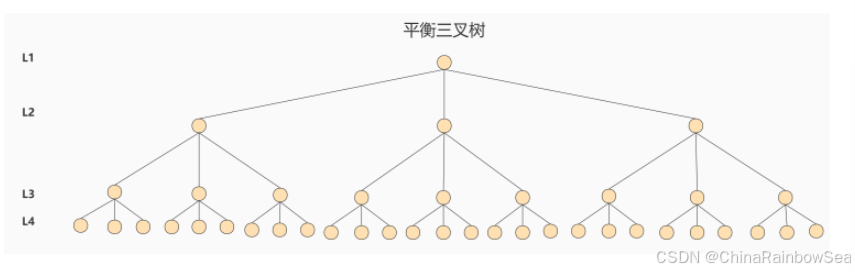
你能看到此时树的高度降低了,当数据量 N 大的时候,以及树的分叉树 M 大的时候,M叉树的高度会远小于二叉树的高度 (M > 2)。所以,我们需要把 `树从“瘦高” 变 “矮胖”。
5. B-Tree
B 树的英文是 Balance Tree,也就是 多路平衡查找树。简写为 B-Tree。它的高度远小于平衡二叉树的高度。
B 树的结构如下图所示:
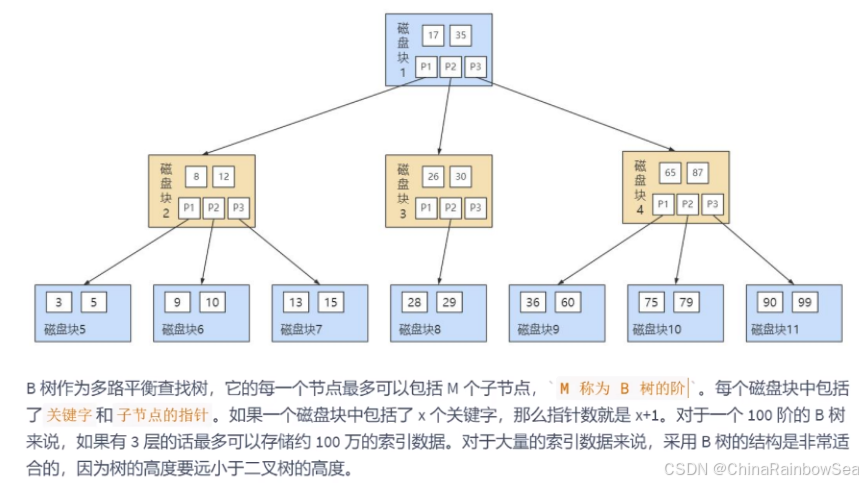
一个 M 阶的 B 树(M>2)有以下的特性:
- 根节点的儿子数的范围是 [2,M]。
- 每个中间节点包含 k-1 个关键字和 k 个孩子,孩子的数量 = 关键字的数量 +1,k 的取值范围为 [ceil(M/2), M]。
- 叶子节点包括 k-1 个关键字(叶子节点没有孩子),k 的取值范围为 [ceil(M/2), M]。
- 假设中间节点节点的关键字为:Key[1], Key[2], …, Key[k-1],且关键字按照升序排序,即 Key[i]<Key[i+1]。此时 k-1 个关键字相当于划分了 k 个范围,也就是对应着 k 个指针,即为:P[1], P[2], …, P[k],其中 P[1] 指向关键字小于 Key[1] 的子树,P[i] 指向关键字属于 (Key[i-1], Key[i]) 的子树,P[k] 指向关键字大于 Key[k-1] 的子树。
- 所有叶子节点位于同一层。
上面那张图所表示的 B 树就是一棵 3 阶的 B 树。我们可以看下磁盘块 2,里面的关键字为(8,12),它 有 3 个孩子 (3,5),(9,10) 和 (13,15),你能看到 (3,5) 小于 8,(9,10) 在 8 和 12 之间,而 (13,15) 大于 12,刚好符合刚才我们给出的特征。
然后我们来看下如何用 B 树进行查找。假设我们想要 查找的关键字是 9 ,那么步骤可以分为以下几步:
- 我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;
- 按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;
- 按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
你能看出来在 B 树的搜索过程中,我们比较的次数并不少,但如果把数据读取出来然后在内存中进行比 较,这个时间就是可以忽略不计的。而读取磁盘块本身需要进行 I/O 操作,消耗的时间比在内存中进行 比较所需要的时间要多,是数据查找用时的重要因素。 B 树相比于平衡二叉树来说磁盘 I/O 操作要少 , 在数据查询中比平衡二叉树效率要高。所以 只要树的高度足够低,IO次数足够少,就可以提高查询性能 。

再举例1:
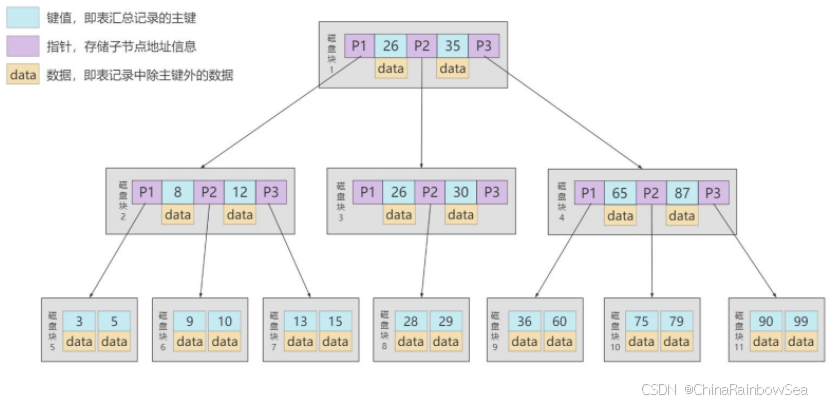
6.B + Tree
B + 树也是一种多路搜索树,基于 B 树做出了改进 ,主流的 DBMS 都支持 B+ 树的索引方式,比如 MySQL,相比于 B-Tree ,B+Tree适合文件索引系统 。
- MySQL官网说明:

B+ 树和 B 树的差异在于以下几点:
- 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数 +1。
- 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最 小)。
- 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中, 非 叶子节点既保存索引,也保存数据记录 。
- 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大 小从小到大顺序链接。
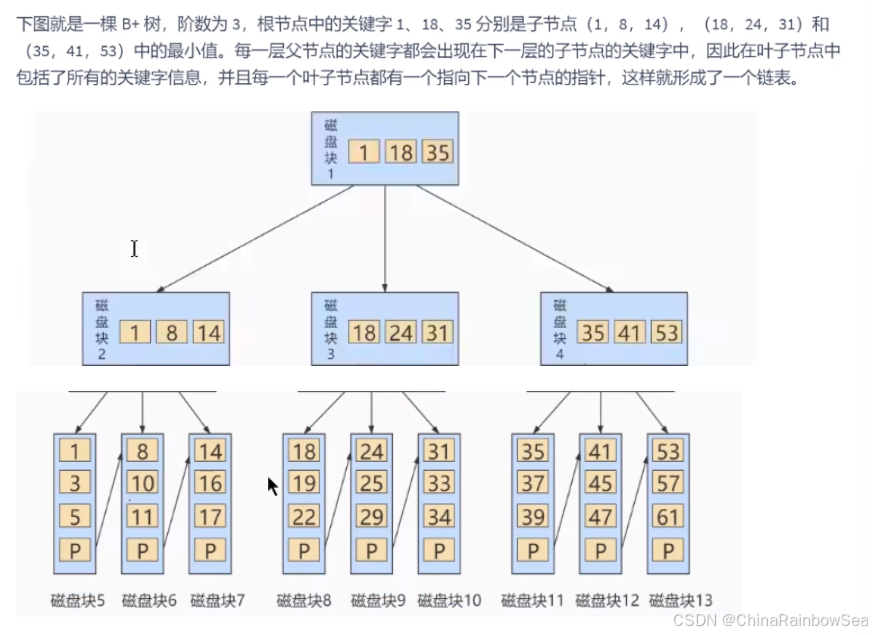

B 树和 B+ 树都可以作为索引的数据结构,在 MySQL 中采用的是 B+ 树。 但B树和B+树各有自己的应用场景,不能说B+树完全比B树好,反之亦然。
思考题:为了减少IO,索引树会一次性加载吗?

思考题:B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO

思考题:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?

思考题:Hash 索引与 B+ 树索引的区别

思考题:Hash 索引与 B+ 树索引是在建索引的时候手动指定的吗?

7. R树
R-Tree在MySQL很少使用,仅支持 geometry数据类型 ,支持该类型的存储引擎只有myisam、bdb、 innodb、ndb、archive几种。举个R树在现实领域中能够解决的例子:查找20英里以内所有的餐厅。如果 没有R树你会怎么解决?一般情况下我们会把餐厅的坐标(x,y)分为两个字段存放在数据库中,一个字段记 录经度,另一个字段记录纬度。这样的话我们就需要遍历所有的餐厅获取其位置信息,然后计算是否满 足要求。如果一个地区有100家餐厅的话,我们就要进行100次位置计算操作了,如果应用到谷歌、百度 地图这种超大数据库中,这种方法便必定不可行了。R树就很好的 解决了这种高维空间搜索问题 。它把B 树的思想很好的扩展到了多维空间,采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解 结点的方法,保证树的平衡性。因此,R树就是一棵用来 存储高维数据的平衡树 。相对于B-Tree,R-Tree 的优势在于范围查找。
| 索引 / 存储引擎 | MyISAM | InnoDB | Memory |
|---|---|---|---|
| R-Tree索引 | 支持 | 支持 | 不支持 |
8. 小结
使用索引可以帮助我们从海量的数据中快速定位想要查找的数据,不过索引也存在一些不足,比如占用存储空间,降低数据库写操作的性能等,如果多个索引还会增加索引选择的时间。当我们使用索引时,需要平衡索引的利(提升查询效率) 和弊(维护索引所需的代价)。
我们在实际工作中,我们还需要基于实际的需求 和 数据 本身的分布情况从而来确定是否使用索引,尽管索引不是万能的 ,但是数据最大的时候不适用索引是不可想象的 。毕竟我们的索引的本质:就是为了帮助我们提升数据检索的效率 。
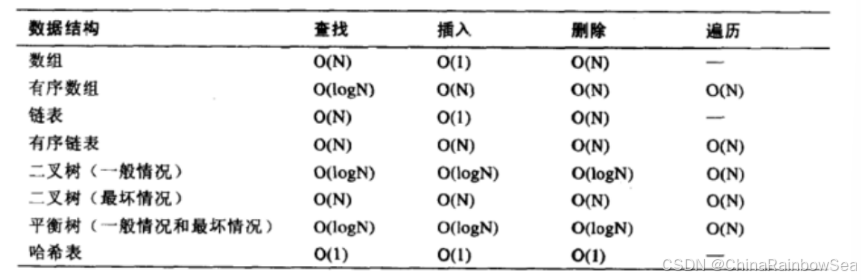
附录:算法的时间复杂度
同一问题可用不同算法解决,而一个算法的质量优劣将影响到算法乃至程序的效率。算法分析的目的在 于选择合适算法和改进算法。
9. 最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”