我自己的原文哦~ https://blog.51cto.com/whaosoft/13960246
#语言模型是否会规划未来 token
Transformer本可以深谋远虑,但就是不做,语言模型是否会规划未来 token?这篇论文给你答案。
「别让 Yann LeCun 看见了。」
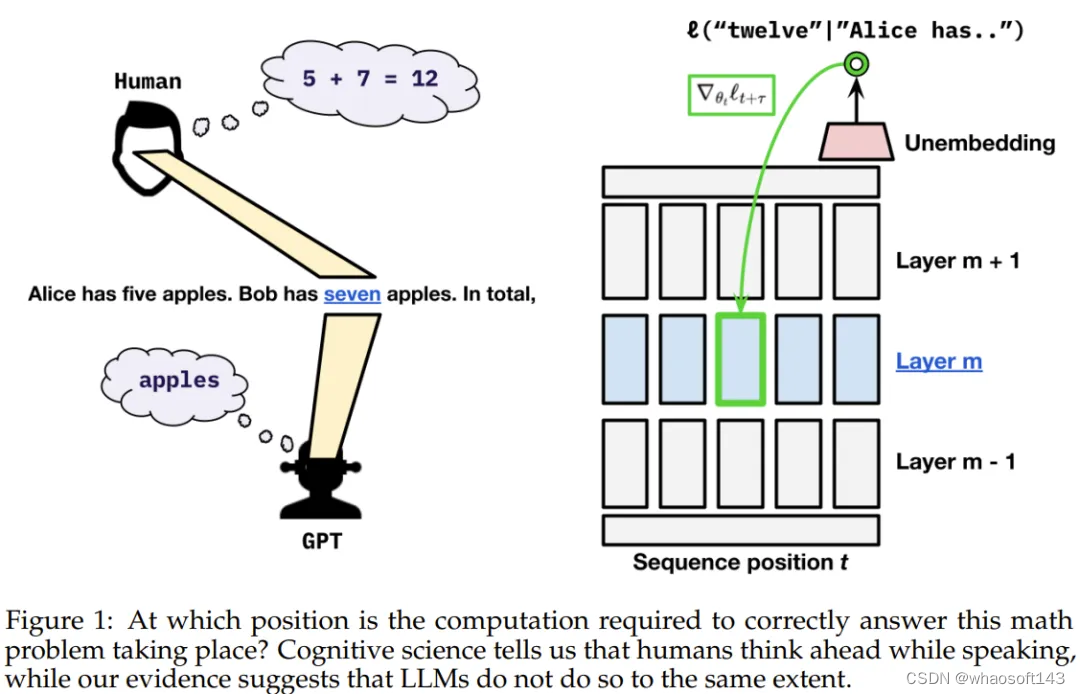
Yann LeCun 表示太迟了,他已经看到了。今天要介绍的这篇 「LeCun 非要看」的论文探讨的问题是:Transformer 是深谋远虑的语言模型吗?当它在某个位置执行推理时,它会预先考虑后面的位置吗?
这项研究得出的结论是:Transformer 有能力这样做,但在实践中不会这样做。
我们都知道,人类会思而后言。数十年的语言学研究表明:人类在使用语言时,内心会预测即将出现的语言输入、词或句子。
不同于人类,现在的语言模型在「说话」时会为每个 token 分配固定的计算量。那么我们不禁要问:语言模型会和人类一样预先性地思考吗?
近期的一些研究已经表明:可以通过探查语言模型的隐藏状态来预测下一 token 之后的更多 token。有趣的是,通过在模型隐藏状态上使用线性探针,可以在一定程度上预测模型在未来 token 上的输出,而干扰隐藏状态则可以对未来输出进行可预测的修改。
这些发现表明在给定时间步骤的模型激活至少在一定程度上可以预测未来输出。
但是,我们还不清楚其原因:这只是数据的偶然属性,还是因为模型会刻意为未来时间步骤准备信息(但这会影响模型在当前位置的性能)?
为了解答这一问题,近日科罗拉多大学博尔德分校和康奈尔大学的三位研究者发布了一篇题为《语言模型是否会规划未来 token?》的论文。
论文标题:Do Language Models Plan for Future Tokens?
论文地址:https://arxiv.org/pdf/2404.00859.pdf
研究概览
他们观察到,在训练期间的梯度既会为当前 token 位置的损失优化权重,也会为该序列后面的 token 进行优化。他们又进一步问:当前的 transformer 权重会以怎样的比例为当前 token 和未来 token 分配资源?
他们考虑了两种可能性:预缓存假设(pre-caching hypothesis)和面包屑假设(breadcrumbs hypothesis)。

预缓存假设是指 transformer 会在时间步骤 t 计算与当前时间步骤的推理任务无关但可能对未来时间步骤 t + τ 有用的特征,而面包屑假设是指与时间步骤 t 最相关的特征已经等同于将在时间步骤 t + τ 最有用的特征。
为了评估哪种假设是正确的,该团队提出了一种短视型训练方案(myopic training scheme),该方案不会将当前位置的损失的梯度传播给之前位置的隐藏状态。
对上述假设和方案的数学定义和理论描述请参阅原论文。
实验结果
为了了解语言模型是否可能直接实现预缓存,他们设计了一种合成场景,其中只能通过显式的预缓存完成任务。他们配置了一种任务,其中模型必须为下一 token 预先计算信息,否则就无法在一次单向通过中准确计算出正确答案。

该团队构建的合成数据集定义。
在这个合成场景中,该团队发现了明显的证据可以说明 transformer 可以学习预缓存。当基于 transformer 的序列模型必须预计算信息来最小化损失时,它们就会这样做。
之后,他们又探究了自然语言模型(预训练的 GPT-2 变体)是会展现出面包屑假设还是会展现出预缓存假设。他们的短视型训练方案实验表明在这种设置中,预缓存出现的情况少得多,因此结果更偏向于面包屑假设。
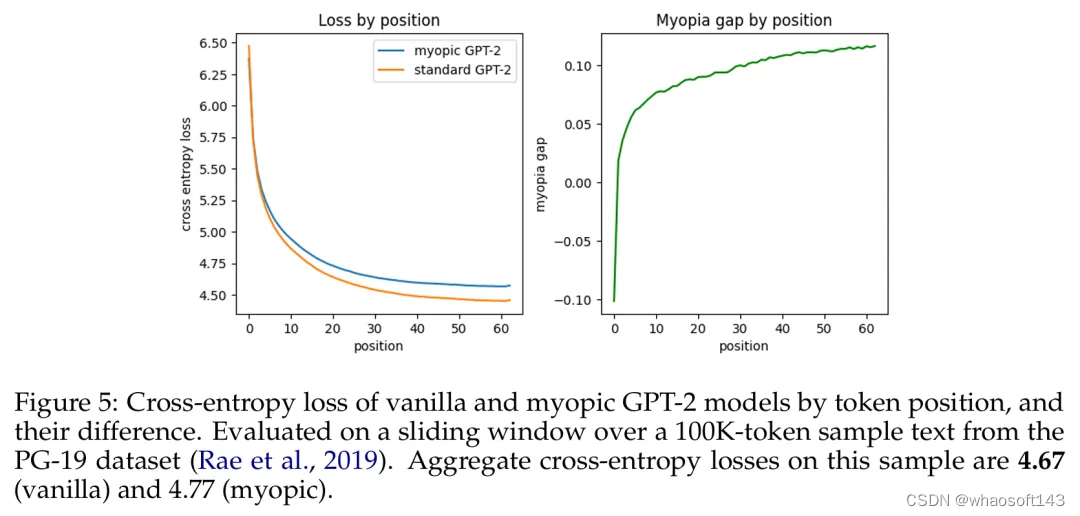
基于 token 位置的原始 GPT-2 模型与短视型 GPT-2 模型的交叉熵损失及其差异。
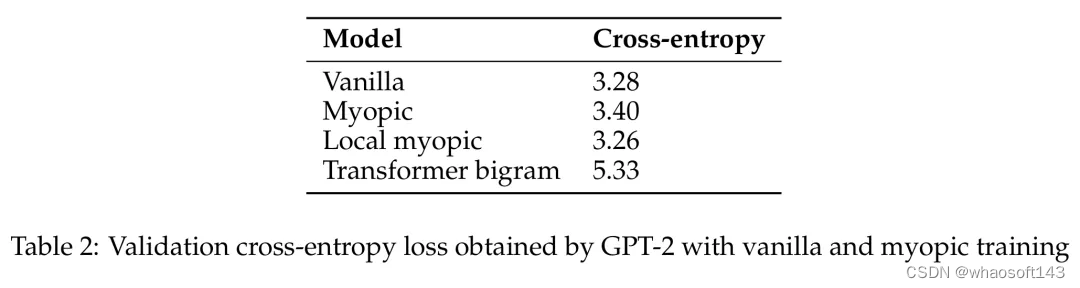
GPT-2 通过原始和短视型训练获得的验证交叉熵损失。
于是该团队声称:在真实语言数据上,语言模型并不会在显著程度上准备用于未来的信息。相反,它们是计算对预测下一个 token 有用的特征 —— 事实证明这对未来的步骤也很有用。
该团队表示:「在语言数据中,我们观察到贪婪地针对下一 token 损失进行优化与确保未来预测性能之间并不存在显著的权衡。」
因此我们大概可以看出来,Transformer 能否深谋远虑的问题似乎本质上是一个数据问题。
#Bigger is not Always Better
大模型一定就比小模型好?谷歌的这项研究说不一定, 在这个大模型不断创造新成就的时代,我们通常对机器学习模型有一个直观认知:越大越好。但事实果真如此吗?
近日,Google Research 一个团队基于隐扩散模型(LDM)进行了大量实验研究,得出了一个结论:更大并不总是更好(Bigger is not Always Better),尤其是在预算有限时。
- 论文标题:Bigger is not Always Better: Scaling Properties of Latent Diffusion Models
- 论文地址:https://arxiv.org/pdf/2404.01367.pdf
近段时间,隐扩散模型和广义上的扩散模型取得的成就不可谓不耀眼。这些模型在处理了大规模高质量数据之后,可以非常出色地完成多种不同任务,包括图像合成与编辑、视频创建、音频生成和 3D 合成。
尽管这些模型可以解决多种多样的问题,但要想在真实世界应用中大规模使用它们,还需要克服一大障碍:采样效率低。
这一难题的本质在于,为了生成高质量输出,LDM 需要依赖多步采样,而我们知道:采样总成本 = 采样步骤数 × 每一步的成本。
具体来说,目前人们首选的方法需要使用 50 步 DDIM 采样。这个过程虽能确保输出质量,但在具备后量化(post-quantization)功能的现代移动设备上却需要相当长的延迟才能完成。因此,为了促进 LDM 的实际应用,就需要优化其效率。
事实上,这一领域已经出现了一些优化技术,但对于更小型、冗余更少的模型的采样效率,研究社区还未给予适当关注。在这一领域,一个重大障碍是缺少可用的现代加速器集群,因为从头开始训练高质量文生图 LDM 的时间和资金成本都很高 —— 往往需要几周时间和数十万美元资金。
该团队通过实验研究了规模大小的变化对 LDM 的性能和效率的影响,其中关注重点是理解 LDM 的规模扩展性质对采样效率的影响。他们使用有限的预算从头开始训练了 12 个文生图 LDM,参数量从 39M 到 5B 不等。
图 1 给出了一些结果示例。所有模型都是在 TPUv5 上训练的,使用了他们的内部数据源,其中包含大约 6 亿对已过滤的文本 - 图像。

他们的研究发现,LDM 中确实存在一个随模型规模变化的趋势:在同等的采样预算下,较小模型可能有能力超越较大模型。
此外,他们还研究了预训练文生图 LDM 的大小会如何影响其在不同下游任务上的采样效率,比如真实世界超分辨率、主题驱动的文生图( 即 Dreambooth)。
对于隐扩散模型在文生图和其它多种下游任务上的规模扩展性质,该团队得到了以下重要发现:
- 预训练的性能会随训练计算量而扩展。通过将模型的参数量从 39M 扩展到 5B,该团队发现计算资源和 LDM 性能之间存在明显联系。这表明随着模型增大,还有潜力实现进一步提升。
- 下游性能会随预训练而扩展。该团队的实验表明:预训练性能与在下游任务上的成功之间存在很强的关联。较小模型即使使用额外的训练也无法完全赶上较大模型的预训练质量所带来的优势。
- 较小模型的采样效率更高。当给定了采样预算时,较小模型的图像质量一开始会优于较大模型,而当放松计算限制时,较大模型会在细节生成上胜过较小模型。
- 采样器并不会改变规模扩展效率。无论使用哪种扩散采样器,较小模型的采样效率总是会更好一点。这对确定性 DDIM、随机性 DDPM 和高阶 DPM-Solver++ 而言都成立。
- 在步数更少的下游任务上,较小模型的采样效率更高。当采样步数少于 20 步时,较小模型在采样效率上的优势会延伸到下游任务。
- 扩散蒸馏不会改变规模扩展趋势。即使使用扩散蒸馏,当采样预算有限时,较小模型的性能依然能与较大蒸馏模型竞争。这说明蒸馏并不会从根本上改变规模扩展趋势。
LDM 的规模扩展
该团队基于广被使用的 866M Stable Diffusion v1.5 标准,开发了一系列强大的隐扩散模型(LDM)。这些模型的去噪 UNet 具有不同的规模,参数数量从 39M 到 5B 不等。该团队通过逐渐增大残差模块中过滤器的数量,同时维持其它架构元素不变,实现了可预测的受控式规模扩展。表 1 展示了这些不同大小模型的架构差异。其中也提供了每个模型相较于基线模型的相对成本。
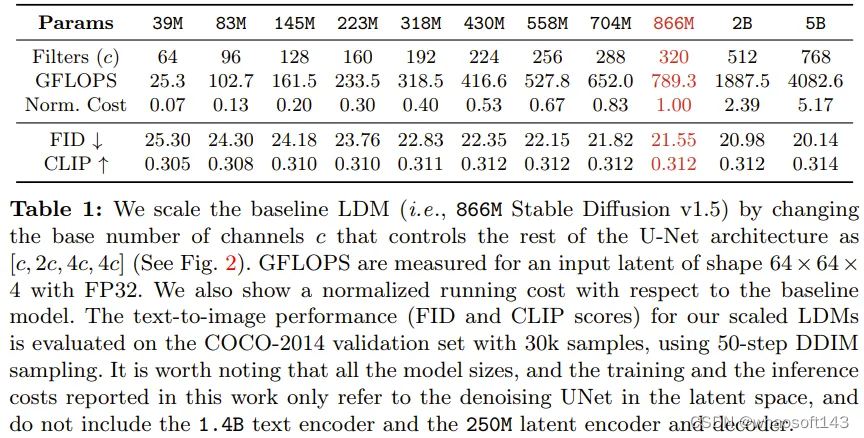
图 2 展示了规模扩展过程中的架构差异。这些模型的训练使用了他们的内部数据源,其中有 6 亿对经过过滤的文本 - 图像。所有模型都训练了 50 万步,批量大小为 2048,学习率为 1e-4。这让所有模型都能到达收益递减的程度。
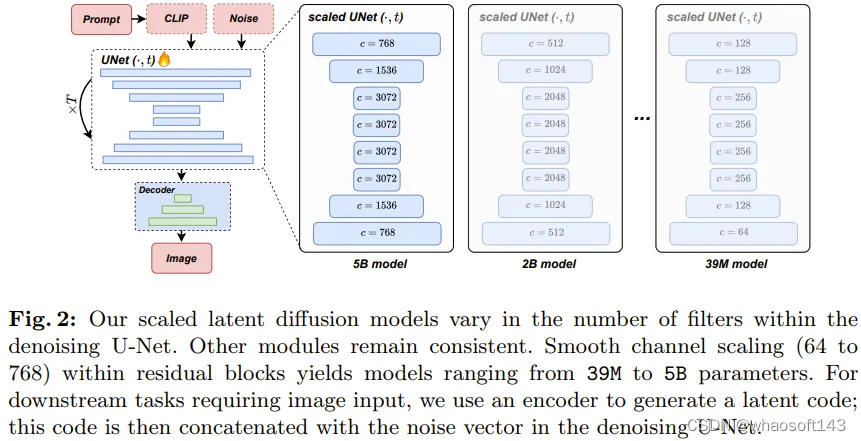
图 1 表明这些不同大小的模型都具有稳定一致的生成能力。
对于文生图任务,他们设置的采样步数为常用的 50 步,采样器为 DDIM,无分类器指导率为 7.5。可以看到,随着模型规模增大,所得结果的视觉质量明显提升。
文生图性能随训练计算量的扩展规律
实验中,各种大小的 LDM 的生成性能相对于训练计算成本都有类似的趋势,尤其是在训练稳定之后 —— 通常是在 20 万次迭代之后。这些趋势表明不同大小的模型的学习能力具备明显的扩展趋势。
具体来看,图 3 展示了参数量从 39M 到 5B 的不同模型的运行情况,其中的训练计算成本是表 1 中给出的相对成本和训练迭代次数的积。评估时,使用了相同的采样步数和采样参数。
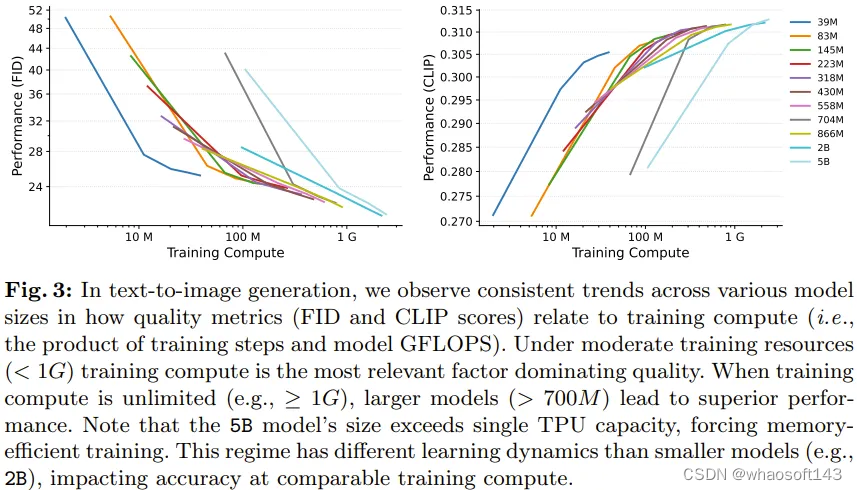
在训练计算量适中(即 < 1G,见图 3)的场景中,文生图模型的生成性能可在额外计算资源的帮助下很好地扩展。
预训练能扩展下游任务的性能
基于在文本 - 图像数据上预训练的模型,该团队又针对真实世界超分辨率和 DreamBooth 这两个下游任务进行了微调。表 1 给出了这些预训练模型的性能。
图 4 左图给出了在超分辨率(SR)任务上的生成性能 FID 与训练计算量的对应情况。
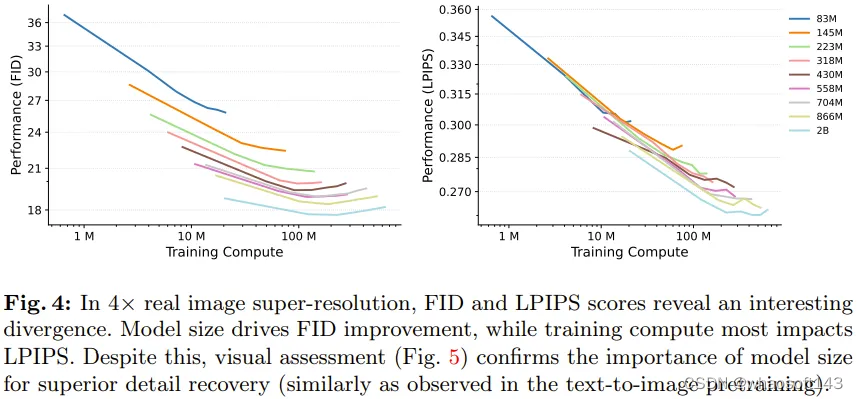
可以看出来,相比于训练计算量,超分辨率的性能更依赖模型大小。实验结果表明较小模型有一个明显的局限性:不管训练计算量如何,它们都无法达到与较大模型同等的性能。
图 4 右图给出了失真度指标 LPIPS 的情况,可以看到其与生成指标 FID 有一些不一致。虽如此,还是可以从图 5 明显看出:较大模型比较小模型更擅长恢复细粒度的细节。

基于图 4 能得到一个关键见解:相比于较小的超分辨率模型,较大模型即使微调时间更短,也能取得更好的结果。这说明预训练性能(由预训练模型大小主导)对超分辨率 FID 分数的影响比对微调的持续时间(即用于微调的计算量)的影响大。
此外,图 6 比较了不同模型上 DreamBooth 微调的视觉结果。可以看到视觉质量和模型大小之间也有相似的趋势。

扩展采样效率
分析 CFG 率的影响。文生图生成模型需要超过单一指标的细致评估。采样参数对定制化来说非常重要,而无分类器引导(CFG)率可以直接影响视觉保真度以及与文本 prompt 的语义对齐之间的平衡。
Rombach 等人的论文《High-resolution image synthesis with latent diffusion models》通过实验表明:不同的 CFG 率会得到不同的 CLIP 和 FID 分数。
而这项新研究发现 CFG 率(一个采样参数)会在不同的模型大小上得到不一致的结果。因此,使用 FID 或 CLIP 分数以定量方式确定每个模型大小和采样步骤的最佳 CFG 率是很有趣的。
该团队使用不同的 CFG 率(即 1.5、2.0、3.0、4.0、5.0、6.0、7.0、8.0)对不同规模的模型进行了采样,并以定量和定性方式比较了它们的结果。
图 7 便是两个模型在不同的 CFG 率下的视觉结果,从中可以看出其对视觉质量的影响。

该团队观察到,相比于 prompt 语义准确度,CFG 率的变化对视觉质量的影响更大,因此为了确定最佳 CFG 率,他们选取的评估指标是 FID 分数。
图 8 给出了不同的 CFG 率对文生图任务的 FID 分数的影响。
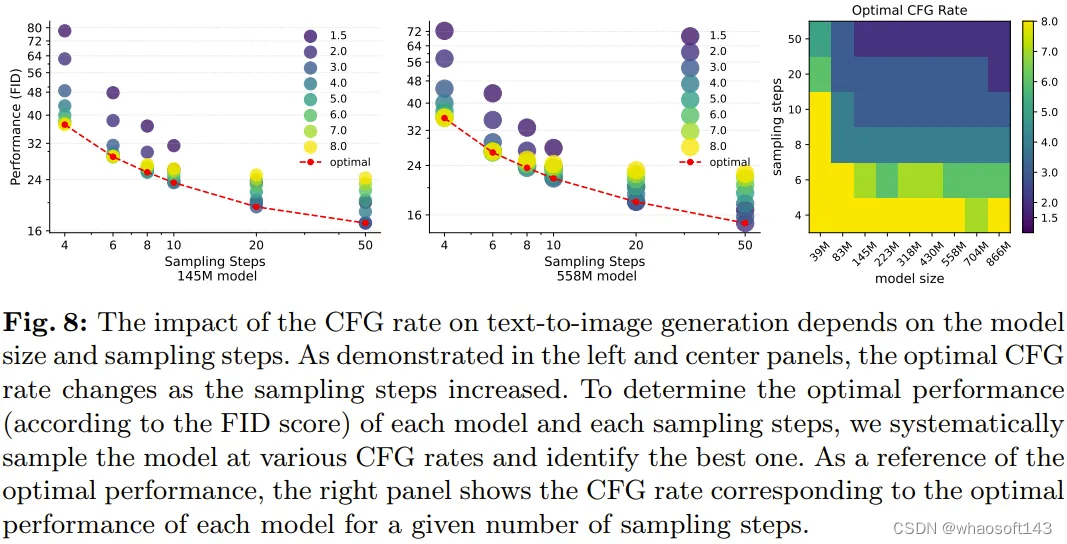
规模扩展效率趋势。使用每个模型在不同采样步骤下的最佳 CFG 率,该团队分析了最优性能表现,以理解不同 LDM 大小的采样效率。
具体来说,图 9 比较了不同采样成本下(归一化成本 × 采样步数)的不同模型及其最优性能。通过追踪不同采样成本下的最优性能点(竖虚线),可以看到一个趋势:在一个采样成本范围内,较小模型的 FID 分数通常优于较大模型。
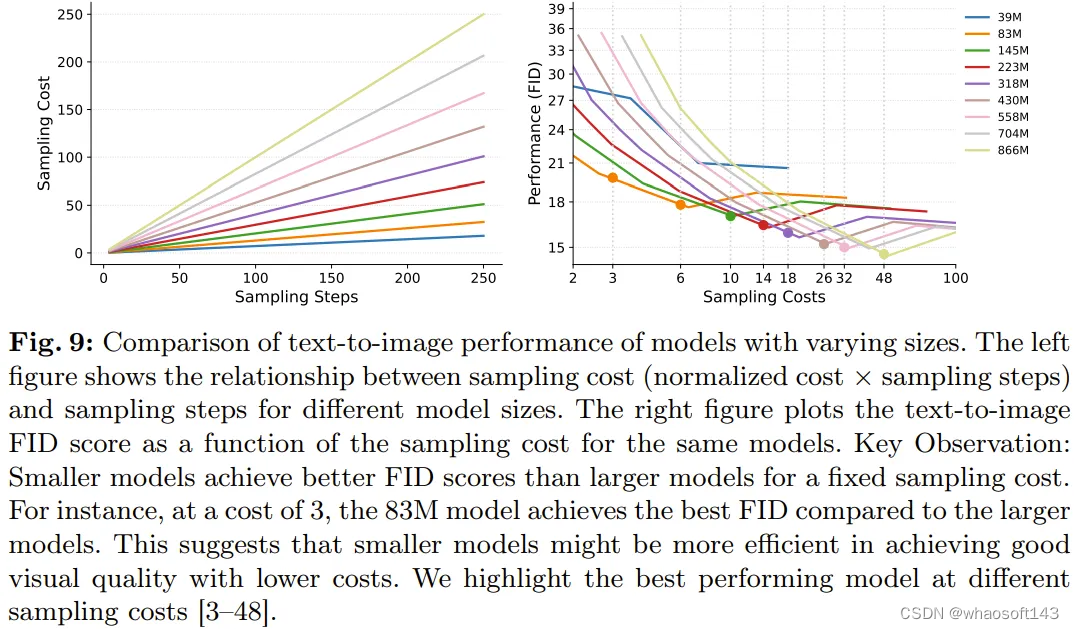
图 10 则给出了较小和较大模型结果的定性比较,从中可以看到在相似的采样成本条件下,较小模型是可以匹敌较大模型的。

不同大小的模型使用不同采样器的采样效率
为了评估采样效率趋势在不同模型规模下的普遍性,该团队评估了不同大小的 LDM 使用不同扩散采样器的性能。
他们使用的采样器有三种:DDIM、随机性 DDPM、高阶 DPM-Solver++。
图 11 给出了实验结果。
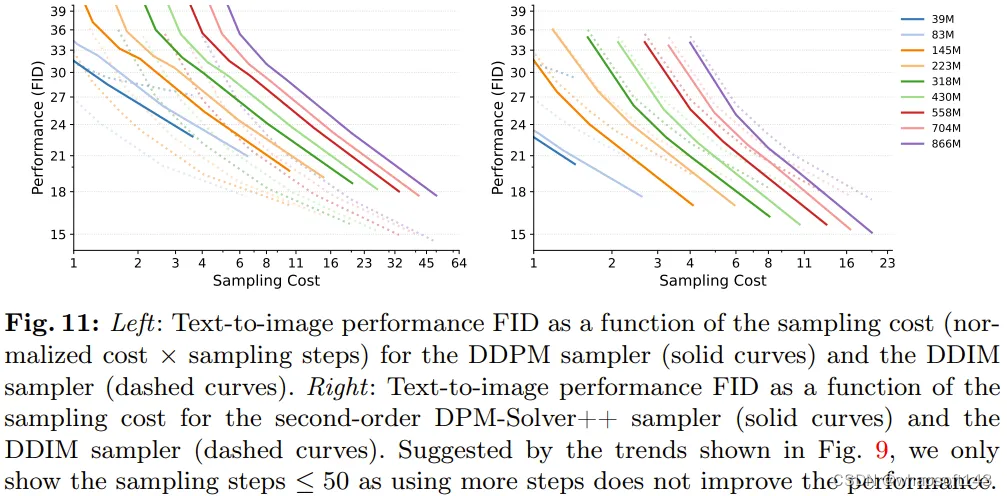
可以看出,当采样步数较少时,DDPM 采样器得到的质量通常低于 DDIM,而 DPM-Solver++ 则在图像质量上胜过 DDIM。
另一个发现也很重要,即三种采样器都有一致的采样效率趋势:采样成本一样时,较小模型的性能会优于较大模型。由于 DPM-Solver++ 采样器的设计并不适合用于超过 20 步的采样,因此这也是其采样范围。
结果表明:不管使用什么采样器,LDM 的规模扩展性质始终保持一致。
不同大小的模型在不同下游任务上的采样效率
这里关注的重点下游任务是超分辨率。这里是直接使用超分辨率采样结果,而不使用 CFG。受图 4 启发(在下游任务上,不同大小的 LDM 在采样 50 步时性能差距较大),该团队从两个方面调查了采样效率:较少采样步数和较多采样步数。
如图 12 左图所示,当采样步数不超过 20 步时,不同大小模型的采样效率趋势在超分辨率任务上依然成立。但图 12 右图又表明,一旦超过这个范围,较大模型的采样效率就会超过较小模型。
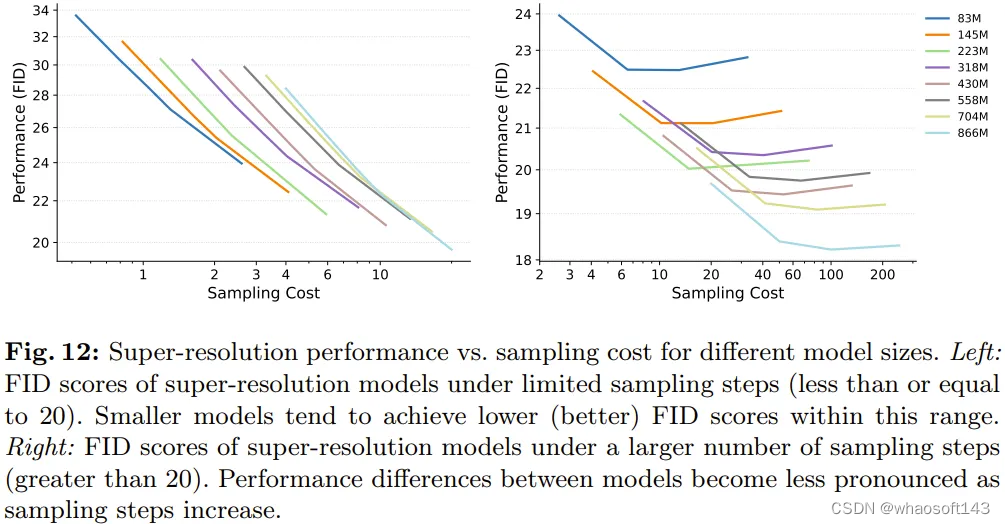
这一观察结果说明,在文生图和超分辨率等任务上,不同大小模型在采样步数较少时的采样效率趋势是一致的。
不同大小的已蒸馏 LDM 的采样效率
虽然之前的实验结果说明较小模型的采样效率往往更高,但需要指出,较小模型的建模能力也往往更差一些。对于近期那些严重依赖建模能力的扩散蒸馏方法来说,这就成了一大难题。人们可能会预测出一个矛盾的结论:经过蒸馏的大模型的采样速度快于经过蒸馏的小模型。
为了展示经过蒸馏的不同大小模型的采样效率,该团队使用条件一致性蒸馏方法在文生图数据上对之前的不同大小模型进行了蒸馏操作,然后比较了这些已蒸馏模型的最佳性能。
详细来说,该团队在采样步数 = 4(这已被证明可以实现最优的采样性能)的设定下测试了所有已蒸馏模型;然后在归一化的采样成本上比较了每个已蒸馏和未蒸馏模型。
图 13 左图表明,在采样步数 = 4 时,蒸馏可以提升所有模型的生成性能,并且 FID 全面提升。而在右图中,可以看到在同等的采样成本下,已蒸馏模型的表现优于未蒸馏模型。
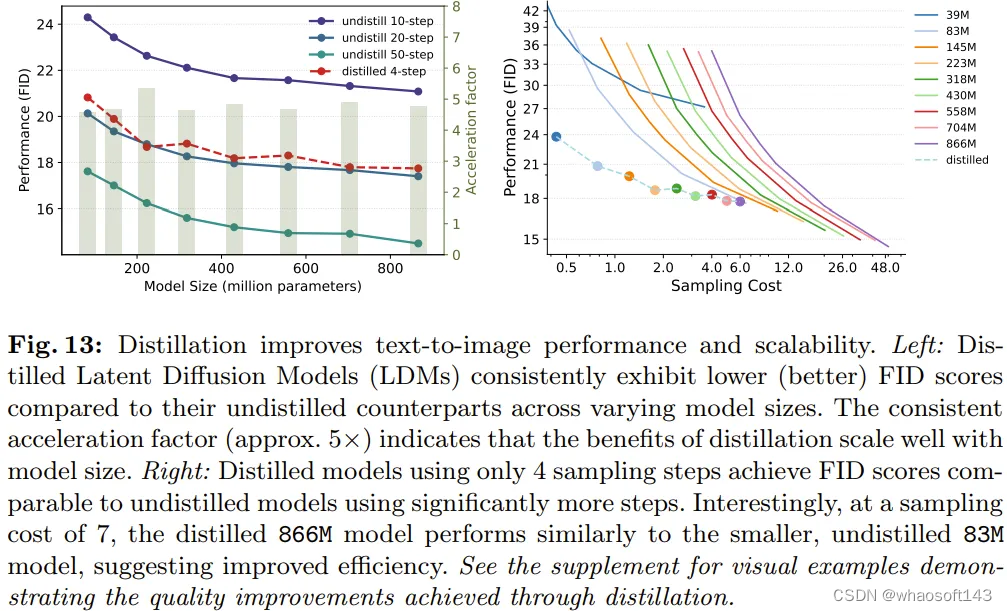
但是,在特定的采样成本下(即采样成本≈8),较小的未蒸馏 83M 模型依然能取得与较大已蒸馏 866M 模型相近的性能。这一观察进一步支持了该团队提出的不同大小 LDM 的采样效率趋势,其在使用蒸馏时也依然成立。
#AI重建粒子轨迹,发现新物理学
电子学在核物理领域从来都不是一帆风顺的。大型强子对撞机作为全球最强大的加速器,所产生的数据如此之多,使得全部记录这些数据从来都不是一个可行的选择。
因此,处理来自探测器的信号波的系统擅长于「遗忘」——它们在不到一秒的时间内重建次级粒子的轨迹,并评估刚刚观察到的碰撞是否可以被忽略,或者是否值得保存以供进一步分析。然而,当前重建粒子轨迹的方法很快将不再足够。
波兰科学院核物理研究所 (IFJ PAN) 的科学家通过研究表明,使用人工智能构建的工具可能是当前快速重建粒子轨迹方法的有效替代方法。它们的首次亮相可能会在未来两到三年内出现,或许是在支持寻找新物理的 MUonE 实验中。
该研究以《Machine Learning based Reconstruction for the MUonE Experiment》为题,于 2024 年 3 月 10 日发布在《Computer Science》上。
论文链接:https://doi.org/10.7494/csci.2024.25.1.5690
过去几十年来,包括计算技术在内的高能物理(HEP)实验领域取得了重大进展。对新物理现象的探索是对所谓的标准模型的扩展,即当前关于自然界基本成分的基本行为及其相互作用的不完整的理论知识,导致在不断增加的能量下进行实验研究。
两个粒子相互作用(碰撞事件)产生的粒子数量通常随着碰撞能量的增加而增加。因此,必须重建大量带电粒子(例如在质子-质子碰撞中),从而导致更复杂的事件模式。
图示:高能物理实验中的事件示例,显示多个粒子穿过探测器的轨迹。(来源:论文)
粒子在加速器中碰撞产生大量次级粒子级联(cascade)。然后,处理从探测器传来的信号的电子设备,有不到一秒的时间来评估某个事件是否值得保存以供以后分析。
在不久的将来,这项艰巨的任务可能会使用基于 AI 的算法来完成。
在现代高能物理实验中,从碰撞点发散的粒子穿过探测器的连续层,在每一层中沉积一点能量。实际上,这意味着如果探测器由十层组成,并且二次粒子穿过所有这些层,则必须基于十个点来重建其路径。任务看似简单。
「探测器内部通常有一个磁场。带电粒子在其中沿着曲线移动,这也是由它们激活的探测器元件(称之为撞击)相对于彼此定位的方式。」IFJ PAN 的 Marcin Kucharczyk 教授解释道。
「实际上,所谓的探测器占用率,即每个探测器元件的命中次数,可能非常高,这在尝试正确重建粒子轨迹时会导致许多问题。特别是,重建彼此靠近的轨道是一个很大的问题。」
旨在寻找新物理学的实验将以比以前更高的能量碰撞粒子,这意味着每次碰撞都会产生更多的次级粒子。光束的亮度也必须更高,这反过来又会增加单位时间的碰撞次数。在这种情况下,重建粒子轨迹的经典方法已经无法应对。AI 在需要快速识别某些普遍模式的领域表现出色,可以伸出援手。
用于轨迹重建的深度神经网络
「我们设计的 AI 是一个深度型神经网络,包括 20 个神经元组成的输入层、4 个各 1000 个神经元的隐藏层,以及 8 个神经元的输出层。每层的所有神经元都是相连的。该网络总共有 200 万个配置参数,这些参数的值是在学习过程中设置的。」IFJ PAN Milosz Zdybal 博士说道。
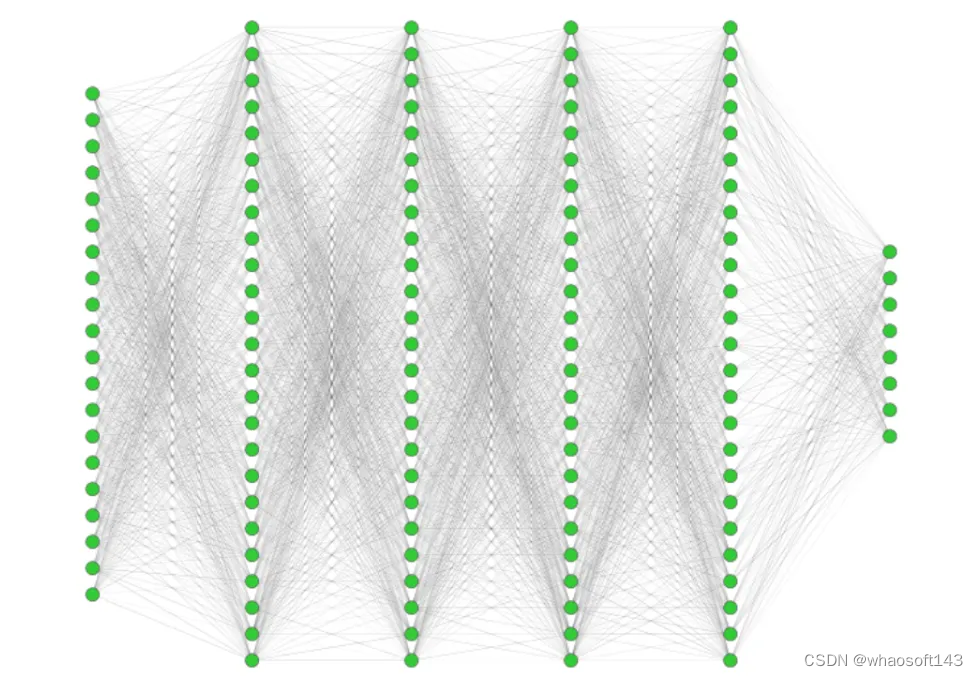
图示:用于轨迹重建的神经网络架构。(来源:论文)
由此制备的深度神经网络使用 40,000 次模拟粒子碰撞进行训练,并辅以人工生成的噪声。在测试阶段,只有命中信息被输入网络。由于这些来自计算机模拟,因此可以准确地了解负责粒子的原始轨迹,并且可以与 AI 提供的重建进行比较。在此基础上,AI 学会了正确重建粒子轨迹。
Kucharczyk 教授强调说:「在我们的论文中,我们表明,在适当准备的数据库上训练的深度神经网络能够像经典算法一样准确地重建二次粒子轨迹。这对于检测技术的发展非常重要。虽然训练一个深度神经网络是一个漫长且计算要求很高的过程,但训练后的网络会立即做出反应。由于它的精度也令人满意,因此我们可以乐观地考虑在实际碰撞的情况下使用它。」
MUonE 实验
基于机器学习技术的概念验证解决方案已在 MUonE(MUon ON Electron 弹性散射) 实验中实施和测试,该实验旨在寻找 μ 子反常磁矩领域的新物理。这检验了与 μ 子(质量大约是电子的 200 倍)有关的某个物理量的测量值与标准模型(即用于描述基本粒子世界的模型)的预测之间的有趣差异。
美国加速器中心费米实验室(American accelerator center Fermilab)进行的测量表明,所谓的 μ 子反常磁矩与标准模型的预测存在高达 4.2 个标准差(简称 sigma)的确定性差异。同时,物理学界普遍认为,高于 5 sigma 的显著性(对应于 99.99995% 的确定性)是宣布一项发现可接受的值。
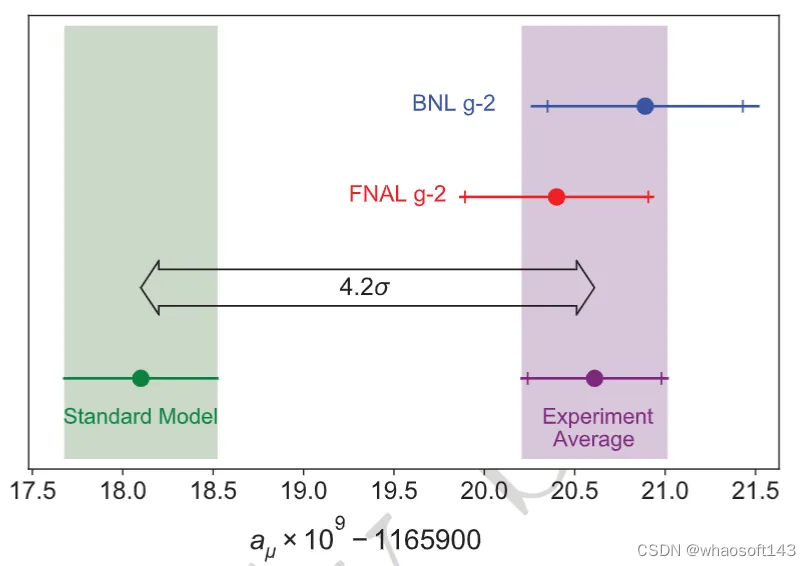
图示:反常 μ 子磁矩测量值与标准模型预测的比较。(来源:论文)
如果标准模型预测的精度能够提高,则表明新物理学的差异的重要性可能会显著增加。然而,为了更好地确定 μ 介子的反常磁矩,有必要知道一个更精确的参数值,即强子校正。不幸的是,无法对该参数进行数学计算。
至此,MUonE 实验的作用就变得清晰起来。其中,科学家们打算研究 μ 子在低原子序数原子(例如碳或铍)的电子上的散射。结果将允许更精确地确定直接取决于强子校正的某些物理参数。
如果一切按照物理学家的计划进行,以这种方式确定的强子校正将增加测量 μ 子反常磁矩的理论值和测量值之间高达 7 sigma 的差异的信心,迄今为止未知的物理学的存在可能会成为现实。
MUonE 实验最早将于明年在欧洲 CERN 核设施开始,但目标阶段已计划在 2027 年,届时克拉科夫物理学家可能有机会看到他们创造的人工智能是否能在重建粒子轨迹方面发挥作用。在真实实验条件下确认其有效性可能标志着粒子检测技术新时代的开始。
参考内容:https://phys.org/news/2024-03-team-ai-reconstruct-particle-paths.html
#Llama2~baby
OpenAI科学家Karpathy用了一个周末时间打造出明星项目llama2.c。他借助GPT-4辅助,仅用500行C语言代码实现对Llama 2 baby模型的推理。
你有没有想过仅用C语言去推理一个Llama 2的baby模型?
没有?现在就能做到了!
就在刚刚过去的这个周末,OpenAI科学家Andrej Karpathy做了一个非常有趣的项目——llama2.c。
项目灵感正是来自于之前的明星项目——llama.cpp
首先,在PyTorch中训练一个较小的Llama 2模型。
然后,用500行代码在纯C环境下进行推理,并且无需任何依赖项。
最后得到的预训练模型(基于TinyStories),可以在MacBook Air M1 CPU上用fp32以每秒18个token的速度生成故事样本。
llama2.c一经发布,就在GitHub上速揽1.6k星,并且还在快速攀升中。
项目地址:https://github.com/karpathy/llama2.c
顺便,Karpathy还表示:「感谢GPT-4对我生疏的C语言提供帮助!」
英伟达科学家Jim Fan称,GPT-4帮助Karpathy用C语言「养」了一只baby Llama!太了不起了!
网友也表示,使用GPT-4构建llama2.c,堪称是终极跨界。
纯C语言推理Llama 2
可能Karpathy没想到,这个llama2.c项目的潜力是如此巨大。
令人惊讶的是,你可以在单线程的CPU上以fp32的交互速率对这些较小(O(~10MB))的模型进行推理。
不过,我还没尝试过使用最小的Meta LLama2检查点(7B),预计速度会很慢。
Karpathy表示,在较窄的领域(比如,故事)中,人们可以使用更小的Transformer来做有趣的事情。
因此,这个简单的纯C语言实现还是很实用的,尤其是它还可以进行移植。
紧接着,他又使用-O3编译,将MacBook Air M1上的每秒处理token数tok/s从18增加到了98。
对于使用这样简单的方法,并能够以较高的交互速率运行相当大小的模型(几千万参数),Karpathy表示非常幸兴奋——
「看来,我现在必须训练一个更大的模型了。」
事实证明,我原来的检查点用编译-O3在MacBook Air M1上运行_way_(100 tok/s)的速度比我预期的要快,所以我现在正在训练一个更大的44M模型,它应该仍然以交互方式运行。也许7B Llama模型触手可及。
代码开源
目前,llama2.c的代码已经开源。
利用这段代码,你可以在PyTorch中从头开始训练Llama 2 LLM架构,然后将权重保存为原始二进制文件,并加载到一个约500行C文件(run. c)中。目前,该文件使用fp32对模型进行推理。
在云Linux开发环境中,Karpathy用一个维度为288、6层、6头的模型(约1500万参数)在fp32下以约100 tok/s的速度进行推理,而这也与M1 MacBook Air上的运行情况大致相同。
感受魔力
在C中运行一个baby Llama 2模型前,首先需要一个模型检查点。
对此,你可以下载在TinyStories数据集上训练的这个15M参数模型(约58MB),并将其放入默认检查点目录out:
wget https://karpathy.ai/llama2c/model.bin -P out然后,编译并运行C代码:
gcc -O3 -o run run.c -lm
./run out/model.bin可以看到,这只是对原始token进行了流式处理。想要读取的话,就需要将其转换为文本。
遗憾的是,现在只能通过一个简单的Python函数装饰器来实现翻译(30行代码):
pip install sentencepiece
python run_wrap.py在M1 MacBook Air上,它的运行速度约为每秒100个token,对于超级简单的fp32单线程C代码来说,效果还不错。
示例输出:
Once upon a time, there was a boy named Timmy. Timmy loved to play sports with his friends. He was very good at throwing and catching balls. One day, Timmy's mom gave him a new shirt to wear to a party. Timmy thought it was impressive and asked his mom to explain what a shirt could be for. "A shirt is like a special suit for a basketball game," his mom said. Timmy was happy to hear that and put on his new shirt. He felt like a soldier going to the army and shouting. From that day on, Timmy wore his new shirt every time he played sports with his friends at the party. Once upon a time, there was a little girl named Lily. She loved to play outside with her friends. One day, Lily and her friend Emma were playing with a ball. Emma threw the ball too hard and it hit Lily's face. Lily felt embarrassed and didn't want to play anymore. Emma asked Lily what was wrong, and Lily told her about her memory. Emma told Lily that she was embarrassed because she had thrown the ball too hard. Lily felt bad achieved tok/s: 98.746993347843922
从前,有一个叫Timmy的男孩。Timmy喜欢和他的朋友们一起运动。他非常擅长扔球和接球。一天,Timmy的妈妈给了他一件新衬衫,让他穿去参加一个聚会。Timmy觉得这件衬衫很棒,便问妈妈它有没有什么特别的用途。「衬衫就像篮球比赛时的特殊套装,」他妈妈说。Timmy听了很高兴,于是穿上了这件新衬衫。他感觉自己像个士兵要去参军一样,大声呐喊。从那天起,每次在聚会上和朋友们一起运动时,Timmy都会穿着这件新衬衫。从前,有一个叫Lily的小女孩。她喜欢和她的朋友在外面玩。一天,Lily和她的朋友Emma正在玩球。Emma把球扔得太用力了,结果打到了Lily的脸上。Lily觉得很尴尬,不想再玩了。Emma问Lily怎么了,Lily告诉她她的记忆。Emma告诉Lily,她很尴尬,因为她把球扔得太用力了。Lily觉得很糟糕。Tok/s:98.746993347843922
使用指南
理论上应该可以加载Meta发布的权重,但即使是最小的7B模型,使用这个简单的单线程C程序来进行推理,速度估计快不了。
所以在这个repo中,我们专注于更窄的应用领域,并从头开始训练相同的架构。
首先,下载并预分词一些源数据集,例如TinyStories:
python tinystories.py download
python tinystories.py pretokenize然后,训练模型:
python train.py更多特殊启动和超参数覆盖的信息,请查看train.py脚本。Karpathy预计简单的超参数探索应该可以得到更好的模型,因此并没有对其进行调整。
如果想跳过模型训练,只需下载Karpathy的预训练模型并将其保存到out目录中,就可以进行简单的演示了:
wget https://karpathy.ai/llama2c/model.bin -P out一旦有了model.bin文件,就可以在C中进行推理。
首先,编译C代码:
gcc -O3 -o run run.c -lm然后,运行:
./run out/model.bin注意,这里输出的只是SentencePiece token。要将token解码为文本,还需利用一个简单的装饰器来运行这个脚本:
python run_wrap.py此外,也可以运行PyTorch推理脚本进行比较(将model.ckpt添加到/out目录中):
python sample.py这将得到相同的结果。更详细的测试将在test_all.py中进行,运行方式如下:
$ pytest目前,你需要两个文件来进行测试或采样:model.bin文件和之前进行PyTorch训练的model.ckpt文件。
(论如何在不下载200MB数据的情况下运行测试。)
待办事项
- 为什么SentencePiece无法正确地迭代解码?
- 希望能够删除run_wrap.py文件,直接使用C代码转换为字符串
-是否支持多查询的功能?对于在CPU上运行的较小模型似乎用处不大?
- 计划支持超过max_seq_len步数的推理,必须考虑kv缓存的情况
- 为什么在我的A100 40GB GPU上进行训练时,MFU如此之低(只有约10%)?
- 使用DDP时出现了torch.compile和wandb的奇怪错误
- 增加更好的测试来减少yolo
网友热议
借着llama2.c热乎劲儿,网友将llama2编译成Emscripten,并在网页上运行。
他使用Emscripten进行了编译,并修改了代码,以在每次渲染时预测一个token。网页自动加载了50MB的模型数据。

此外,他还增添了去token化的支持。

还有网友表示,基于llama.cpp的成功,这个行业似乎正朝着为每个发布的模型提供单独源代码的方向发展,而不是像pytorch/tenorflow/onnxruntime这样的通用框架?
llama2.c的意义在何处?
网友举了一个生动的例子,创建一个关于一个有100人的小岛的电脑游戏,每个人都有意识,llama2. c是他们的大脑。然后你可以模拟一千年的历史,看看会发生什么。
参考资料:
https://github.com/karpathy/llama2.c
#CAME~
优化器在大语言模型的训练中占据了大量内存资源。现在有一种新的优化方式,在性能保持不变的情况下将内存消耗降低了一半。该成果由新加坡国立大学打造,在ACL会议上获得了杰出论文奖,并已经投入了实际应用。
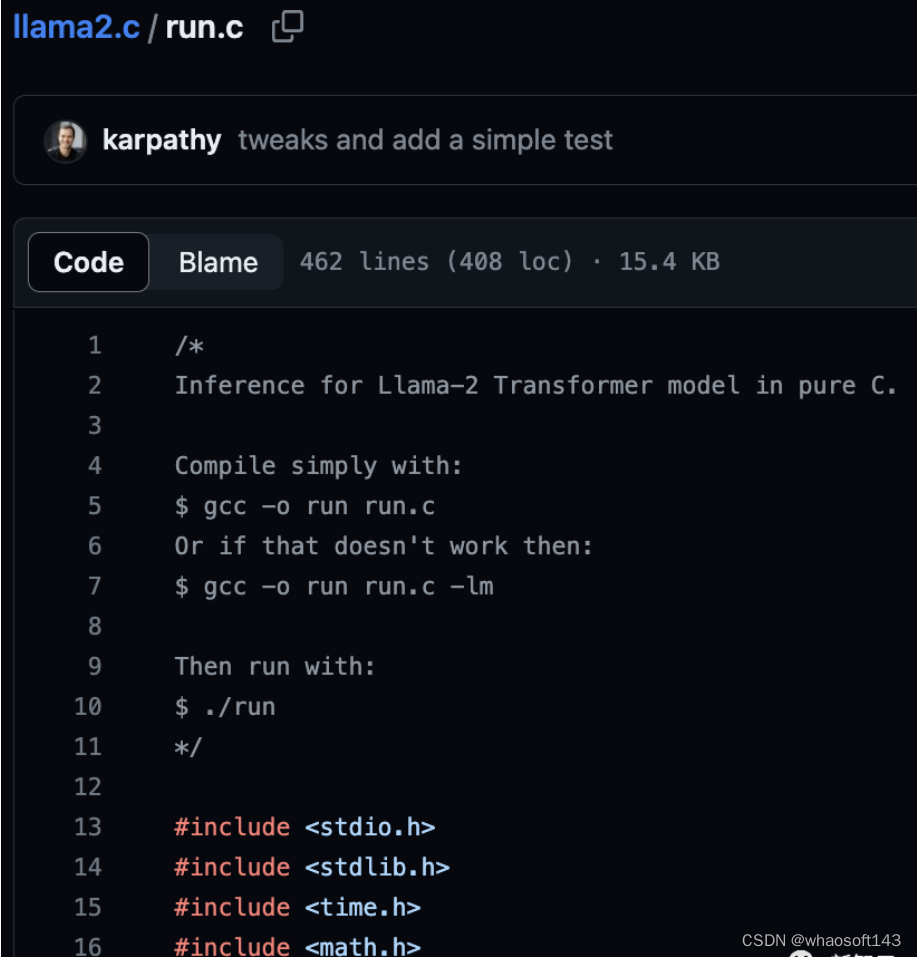
随着大语言模型不断增加的参数量,训练时的内存消耗问题更为严峻。研究团队提出了 CAME 优化器,在减少内存消耗的同时,拥有与Adam相同的性能。
CAME优化器在多个常用的大规模语言模型的预训练上取得了相同甚至超越Adam优化器的训练表现,并对大batch预训练场景显示出更强的鲁棒性。进一步地,通过CAME优化器训练大语言模型,能够大幅度降低大模型训练的成本。
实现方法
CAME 优化器基于 Adafactor 优化器改进而来,后者在大规模语言模型的预训练任务中往往带来训练性能的损失。Adafactor中的非负矩阵分解操作在深度神经网络的训练中不可避免地会产生错误,对这些错误的修正就是性能损失的来源。而通过对比发现,当起始数值mt和当前数值t相差较小时,mt的置信度更高。

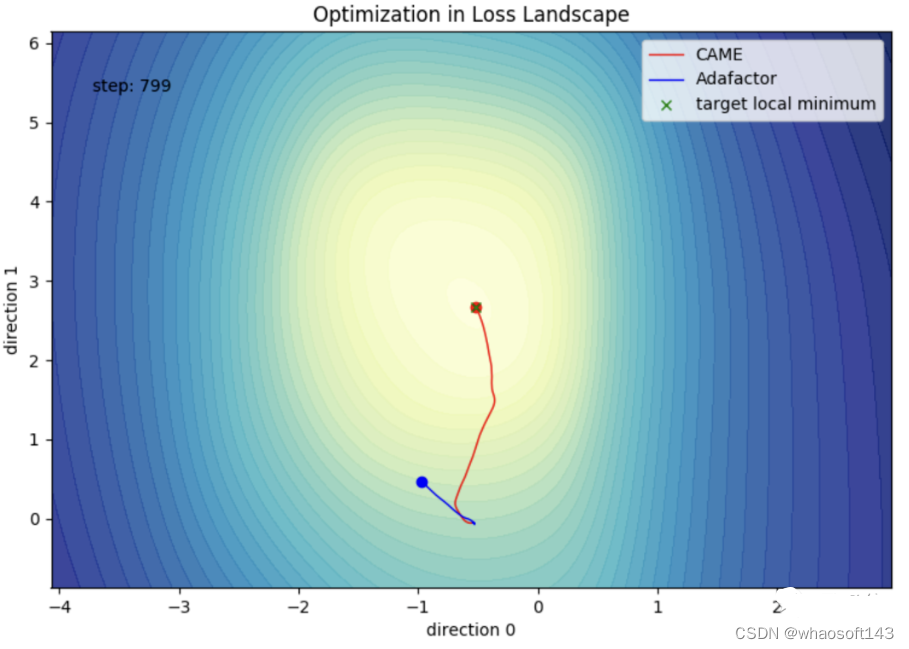
受这一点启发,团队提出了一种新的优化算法。下图中的蓝色部分就是CAME相比Adafactor增加的部分。

CAME 优化器基于模型更新的置信度进行更新量修正,同时对引入的置信度矩阵进行非负矩阵分解操作。最终,CAME成功以Adafactor的消耗得到了Adam的效果。
相同效果仅消耗一半资源
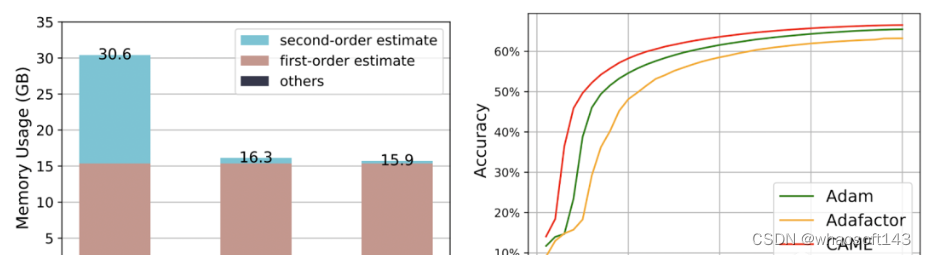
团队使用CAME分别训练了BERT、GPT-2和T5模型。此前常用的Adam(效果更优)和Adafactor(消耗更低)是衡量CAME表现的参照。其中,在训练BERT的过程中,CAME仅用一半的步数就达到了和Adafaactor相当的精度。
△左侧为8K规模,右侧为32K规模
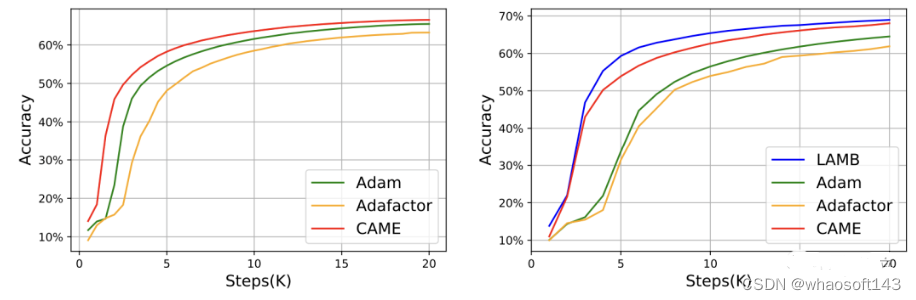
对于GPT-2,从损失和困惑度两个角度看,CAME的表现和Adam十分接近。
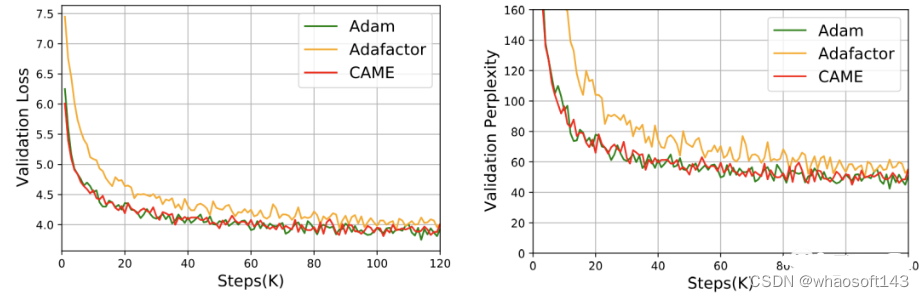
在T5模型的训练中,CAME也呈现出了相似的结果。
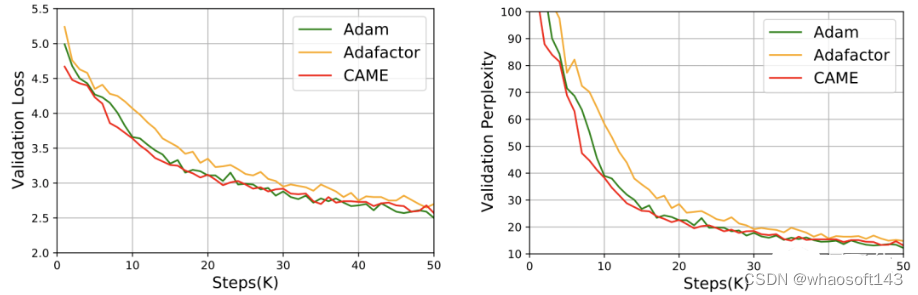
而对于模型的微调,CAME在精确度上的表现也不输于基准。

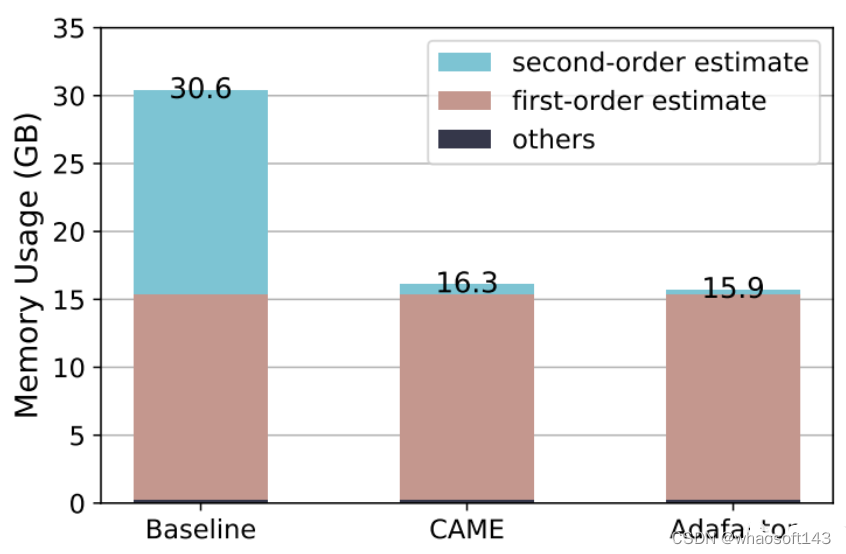
资源消耗方面,在使用PyTorch训练4B数据量的BERT时,CAME消耗的内存资源比基准减少了近一半。
新加坡国立大学HPC-AI 实验室是尤洋教授领导的高性能计算与人工智能实验室。实验室致力于高性能计算、机器学习系统和分布式并行计算的研究和创新,并推动在大规模语言模型等领域的应用。实验室负责人尤洋是新加坡国立大学计算机系的校长青年教授(Presidential Young Professor)。尤洋在2021年被选入福布斯30岁以下精英榜(亚洲)并获得IEEE-CS超算杰出新人奖,当前的研究重点是大规模深度学习训练算法的分布式优化。本文第一作者罗旸是该实验室的在读硕士生,他当前研究重点为大模型训练的稳定性以及高效训练。
- 论文地址:https://arxiv.org/abs/2307.02047GitHub
- 项目页:https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/CAME
#xTrimoPGLM
近日,百图生科与清华大学联合提出了一种名为 xTrimo Protein General Language Model (xTrimoPGLM) 的模型,参数量高达千亿(100B)。相关成果于 2023 年 7 月 7 日在 biorxiv 上发布。将蛋白质语言模型扩展到千亿参数,深度解读百图生科
论文链接:https://www.biorxiv.org/content/10.1101/2023.07.05.547496v3
自然语言处理(NLP)领域中的预训练模型相关进展已经被成功地用于学习蛋白质序列中隐藏的生物信息。现在大多数的蛋白质预训练模型都受限于自动编码或自回归预训练目标,这使得它们难以同时处理蛋白质理解(例如,蛋白质结构预测)和生成任务(例如,药物设计)。
这篇论文提出统一的蛋白质语言模型,xTrimoPGLM,通过一个创新的预训练框架来同时处理这两种类型的任务。xTrimoPGLM 主要技术贡献是探索了这两种类型目标之间的兼容性以及共同优化的可能性,并基于此训练了一个前所未有的 1000 亿参数规模的蛋白质语言模型,并消耗了 1 万亿 Tokens,模型 FLOPs 达到 6.2e+23,达到和 175B 参数的 GPT-3 一个量级。
在理解任务上,xTrimoPGLM 在多种蛋白质理解任务(15 项任务中的 13 项任务)中显著优于其他先进基线。在生成任务上,xTrimoPGLM 能够生成与自然蛋白质结构类似的新蛋白质序列。
此外,文章基于相同的框架额外训练了一个 12 亿参数的抗体模型(xTrimoPGLM-Ab),其在预测抗体自然性和结构方面取得了市面上最好的效果,并且显示出比 AlphaFold2 更快的推理速度(数十倍到数千倍)。综合来看,这些结果充分展示了 xTrimoPGLM 在理解和生成蛋白质序列方面的强大能力和广阔的应用前景。
蛋白质理解和生成的统一
不同类型的蛋白质相关任务需要蛋白质语言模型(Protein Language Model,PLM)提供各异的输出。具体的,蛋白质理解任务,如二级结构预测等,需要 PLM 提供精确的氨基酸和序列级别的表示;而蛋白质设计任务,如抗体或酶的设计,依赖于 PLM 的生成能力。然而,当前的 PLM 因为其单一的预训练框架的限制,大多只能处理一种类型的任务。
事实上,蛋白质的理解和生成都反映了蛋白质数据的分布信息,Meta 之前使用 ESM(基于 Masked Language Model 的蛋白质大模型)做生成的工作也证实了这一点,指出蛋白质理解预训练模型可以通过一些采样策略进行蛋白质设计。这进一步支撑了这两种看似不同的任务的统一性,如果能够使用同一个训练框架去处理这两种任务,将会进一步增强模型对蛋白质数据的拟合能力。
虽然 NLP 领域生成式模型(例如 UL2R, GPT) 已经成为主流范式,通过把数据标签映射到整个文本空间,结合指令微调来生成各式各样的任务的答案,但 PLM 还无法实现这一点。实际上,蛋白质的应用仍然依赖于将表示与下游任务特定标签(如结构预测的 3D 坐标)之间的桥接,这在很大程度上依赖于 BERT 样式的训练来处理蛋白质理解任务。因此,需要同时进行这两种训练目标。
本文介绍的 xTrimo 蛋白质通用语言模型(xTrimoPGLM)预训练框架,巧妙地统一了两种类型的预训练任务,使模型能同时处理多种与蛋白质相关的任务。研究团队通过全面的实验评估了 xTrimoPGLM 框架的有效性。在蛋白质理解任务的情况下,xTrimoPGLM-100B 在多种评估中表现出色,涵盖了蛋白质结构、功能、交互和可开发性等领域的 15 项任务。
"Scaling Law" 是衡量大型语言模型的重要原则,模型的性能应随着模型参数大小、数据量、计算量按比例指数增加而线性增长。实际上,研究团队在下游任务上的实验结果验证了这一定律,证明了大型模型在处理复杂任务时的必要性。
如下图所示,性能改善与预训练计算量增加之间的关系。以 Meta 的 ESM-2 为参考,随着蛋白质语言模型(PLM)的计算量呈指数增长,蛋白质的下游性能仍然会线性增长(每个大类有 3-4 个任务,数值表示这些任务的平均值)。
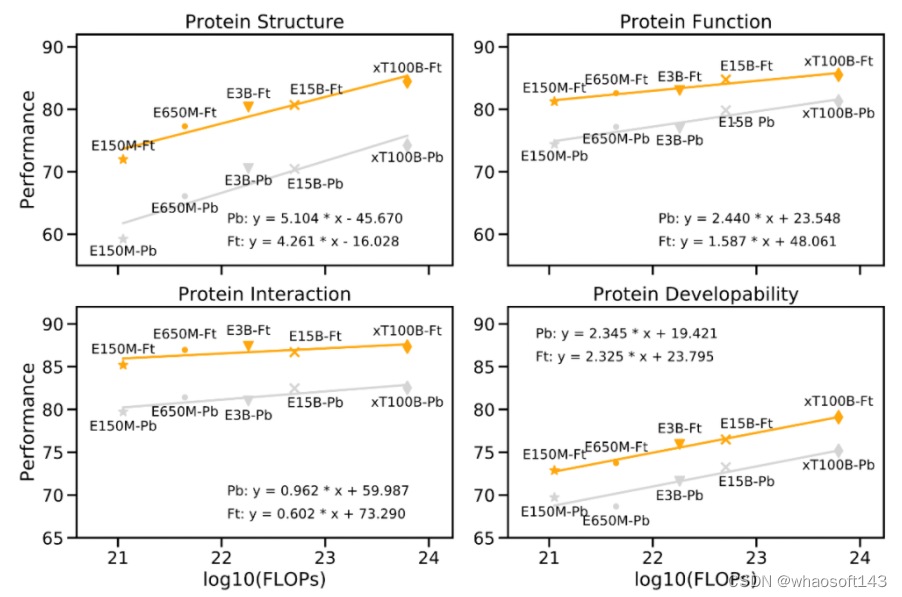
在蛋白质生成任务中,xTrimoPGLM-100B 展示了生成不同长度和序列的新蛋白质序列的能力,这是通过调整生成超参数实现的。值得注意的是,当与自然蛋白质进行比较时,xTrimoPGLM-100B 展示了生成结构相似但序列相异的新蛋白质序列的能力。这再次验证了大型模型对于复杂任务的重要性,进一步证实了遵循 "Scaling Law" 进行模型设计的决定是正确的。
同时,研究团队还开发了一种当前更具实用意义的具有 12 亿参数的抗体 PLM,即 xTrimoPGLM-Ab-1B。这种模型在 OAS 抗体数据库上进行 fine-tuning,处理了超过 1 万亿个 token。它在抗体的自然性和结构预测任务上达到了目前最优秀的性能。由于不依赖于外部库的检索和多序列对齐(Multiple Sequence Alignment),所以结构预测在速度上比 Alphafold2 模型提升成百上千倍,这对于基于抗体药物发现 AI 制药公司至关重要。
混合训练
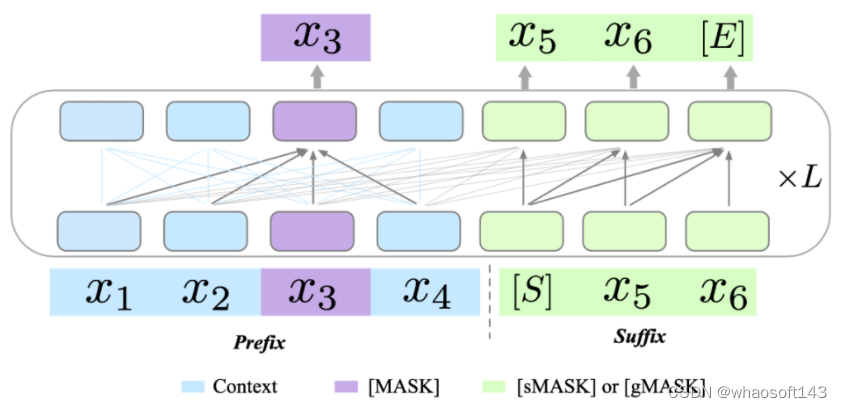
原始的 GLM 模型利用两种不同的预训练目标来提升其生成能力:1)跨度生成(Span Generation,简称 sMask),用于恢复句子中的短空白;2)长文本生成(Long-text Generation,简称 gMASK),用于在提供前缀上下文的基础上生成随机长度的序列。为了进一步提升 xTrimoPGLM 的理解能力,团队在 prefix 区域引入了被用作理解目标的 Masked Language Model(MLM,即 [MASK])。这样的设计确保了 xTrimoPGLM 能生成精确的残基级和序列级表示。
当使用 [MASK] 标识符时,xTrimoPGLM 的功能类似于 BERT。相反,当使用 [sMASK] 或 [gMASK] 时,xTrimoPGLM 的行为类似于 PrefixLM 或 GPT。总的来说,xTrimoPGLM-100B 的预训练阶段可以分为两个阶段。首先,利用 MLM 进行预训练以增强其表示能力,主要目标是快速减少损失水平。第二阶段,使用结合 MLM 和 GLM 损失的统一目标进行训练,以提升理解和生成能力。
NLP 领域大量探索了统一的预训练模式,但大多还是采样了同样的训练模式(自回归或自编码)。为了满足统一的蛋白质预训练模型的需求,需要将 BERT 样式的目标引入到预训练语言模型中,以增强模型的表示能力,同时也需要引入 GPT 样式的目标,以确保模型的生成能力。在最开始研究团队使用 Probing 策略探索 Contact Map Prediction 的任务时,发现仅仅依靠基于下一个词预测的生成式语言模型,效果会有大幅度的下降。
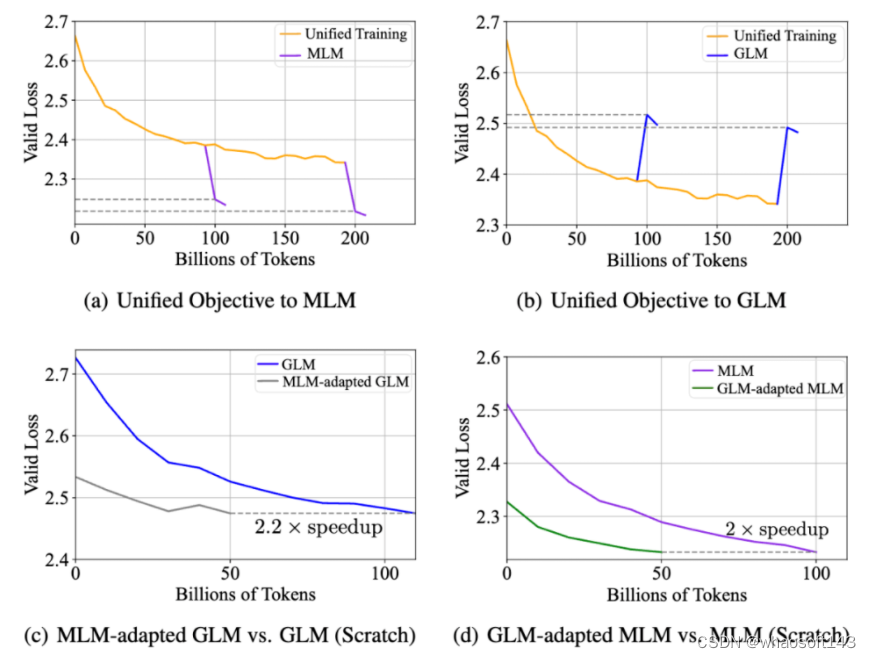
兼容性实验:在实证分析中,研究团队在 xTrimoPGLM-150m 模型上探究了同时优化两个不同目标的可行性。结果如下图 (a)(b) 所示,即使两种预训练目标看似冲突,MLM 损失和 GLM 损失也可以同时优化,反之亦然,即统一的训练可以很快的适配到 MLM 或者 GLM 上,并不会影响两者的收敛情况。
研究团队还探究了 MLM 与 GLM 两种目标是否能相互加速收敛,结果如图 (c)(d)。
- MLM-adapted GLM:接着 MLM 预训练后的模型,继续训练 GLM 目标函数;
- GLM-adapted MLM:接着 GLM 预训练后的模型,继续训练 MLM 目标函数;
总的说来,基于预训练后的模型中继续训练的模型,与从头开始训练的模型相比,其收敛速度明显加快。这些实验观察到:在蛋白质数据分布并不依赖于特定的训练模式,从而缩小了自编码 PLMs(如 ESM)和自回归 PLMs(如 ProGen2)之间的差距,为 100B 训练流程提供了支持。
训练稳定性
训练稳定性是成功训练 100B 规模大型语言模型的决定性因素。xTrimoPGLM 从 GLM-130B 的实现中借鉴了一些想法并解决了许多不稳定训练的问题。然而,xTrimoPGLM-100B 在从训练的第一阶段过渡到第二阶段时仍然会遇到灾难性的训练崩溃(小规模的模型(10B 规模)中并未观察到),即使一开始只将 1% 的 GLM 损失加入预训练也可能触发这些崩溃。
下图可以看到,如果直接给 GLM 分配一个比例 ,在训练初期,grad norm 都会出现 spike(橙,蓝,绿线)。
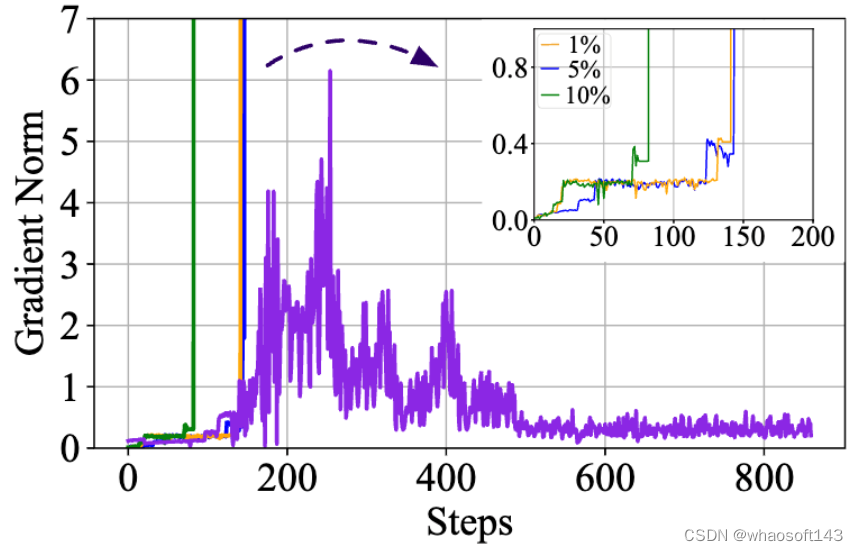
为了缓解这个问题,研究团队提出了一种平滑过渡策略。主要分为两个阶段。在第一阶段,主要目标是逐步提高 GLM 损失的比例,达到预期的数量。具体来说,给定一个期望的 GLM 损失比例 R,按照线性增长,以 K 步从 0 增加到 R。在这个阶段应该将学习率保持在极低的水平。完成过渡后,学习率可以按照预定义的脚本在几百个 steps 内逐渐回升至原来的水平 (紫线)。实际上,最后的 xTrimoPGLM-100B 训练运行只在过渡阶段经历了损失分歧情况,但是由于硬件故障多次失败,导致经常性的更换节点和重启。
训练数据
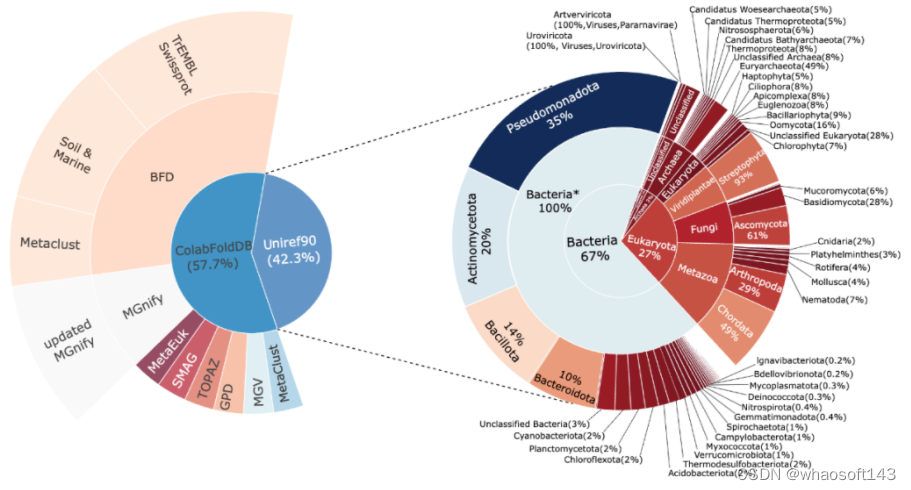
为了能够尽可能的映射整个蛋白世界, xTrimoPGLM-100B 的预训练模型的训练数据集整合自两个广泛的数据源:Uniref90 和 ColAbFoldDB。
结合这两个数据源,预训练模型数据集充分利用了这两个数据源的优势,既有广泛的生物分类覆盖,又有多样的环境生态位蛋白质序列,全面而详尽地映射了生物世界中的蛋白质资源。
超参数配置
xTrimoPGLM-100B 模型的训练过程复杂且耗费资源,团队耗费了 160 天的时间,开发团队使用了 96 台 DGX-A100 GPU 服务器(每台服务器拥有 8×40G 的 GPU)以混合精度(FP16)进行训练,消耗了 1 万亿的 tokens,由于大多数现有的大型语言模型在训练上存在严重不足,所以开发团队现在仍然在继续训练 xTrimoPGLM-100B 模型,以处理尽可能多的 tokens。
模型采用了 3D 并行策略,基于 DeepSpeed 进行了 4 路张量并行、8 路流水线并行,并且采用了 Zero Stage 1 进行训练。模型具有 72 个 Transformer 层,80 个 head,以及 10,240 维和 31,744 个 FNN 的维度。使用了 DeepNorm 初始化 Post-LN,并且采用了 Embedding Layer Gradient Shrink (EGS) 稳定训练,以及使用了 2D ROPE 位置编码技术。为了提升训练效率,每个样本由多个蛋白拼接再一起,使用 < eos > 区分开来,包含固定的 2,048 的序列长度。最终单卡的 TFLOPs 在 120-135 之间,68 examples/sec, 如果是 80G 的 A100,经过减少重算可到 92 examples/sec。下表展示了大部分超参数的配置。



团队也对比了当前比较热门的预训练模型的 FLOPs,目前生物领域不同模型的结构也存在比较大的区别, 所以在 FLOPs 的计算上,团队考虑尽可能详细统计,包括 query、 key、value 的转换,Attention Matrix 的计算,注意力之后线性变换,MLP 中的变换,以及最后到 vocab 维度的映射,以及语言模型头(如果存在的话)中的线性转换等,可以看到,xTrimoPGLM-100B 高出其他模型一到两个量级。
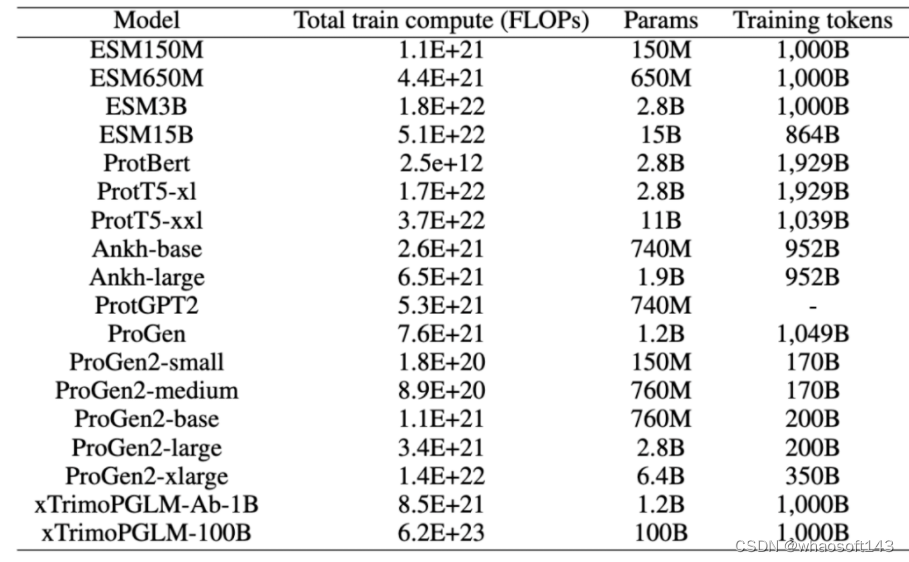
十五种蛋白质下游任务评估
为了全面评估 xTrimoPGLM-100B 模型,研究团队对 4 个领域内,15 个下游的蛋白质相关任务进行了基准测试。测试结果表明,xTrimoPGLM-100B 在蛋白质结构、蛋白质可开发能力、蛋白质相互作用和蛋白质功能等四个主要类别的任务中,都表现出了显著的优势。在这些任务中,xTrimoPGLM-100B 模型与微调技术的组合取得了优异的成绩,大部分超越了当前最先进的方法,从而推动这个领域的进步。
需要强调的是,下表对比主要从任务的角度进行,而不是一个完全公平的对比,因为 xTrimoPGLM-100B 在取得这些结果时,采用了这个领域大模型之前都不太关注微调技术。这些结果的大部分来自对论文直接引用,并使用相同的数据划分策略,有一些没有 benchmark 的任务,研究团队使用了 ESM-15B + finetuning 的策略作为 benchmark, 实际上,在所有任务中,研究团队也使用过这种策略,发现 ESM2-15B/3B + finetuning 在不少任务可以直接达到 SOTA,但是,目前大部分的蛋白质大语言模型很少关注微调技术,更多的是把 PLMs 作为特征提取器使用。
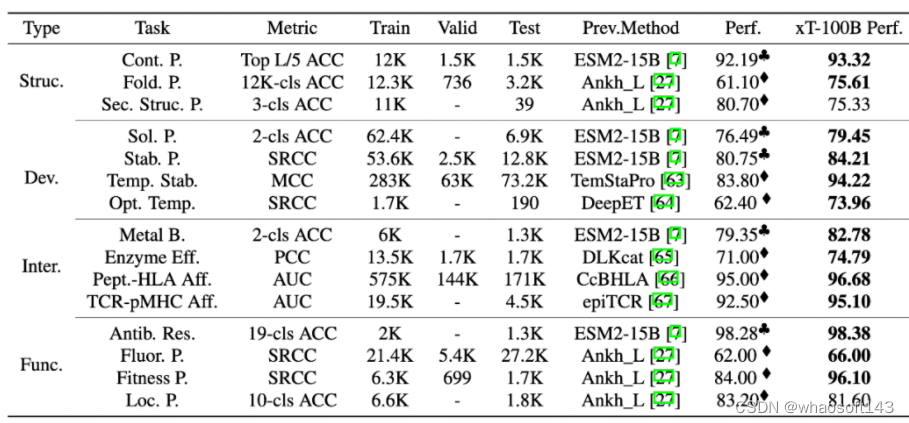
另一方面,为了表明 xTrimoPGLM 大模型的有效性,研究团队也给出来和 ESM2-15B 以及 150M 的在相同训练设置下的对比实验,使用相对较小的 ESM2-150M 模型作为指标,主要来理解各种下游蛋白质相关任务的难度程度。这些任务包括基于 feature-based 的 Probing 和 联合大模型参数的 Finetuning,xTrimoPGLM-100B 在大多数蛋白质相关任务中仍然展现出了优势。
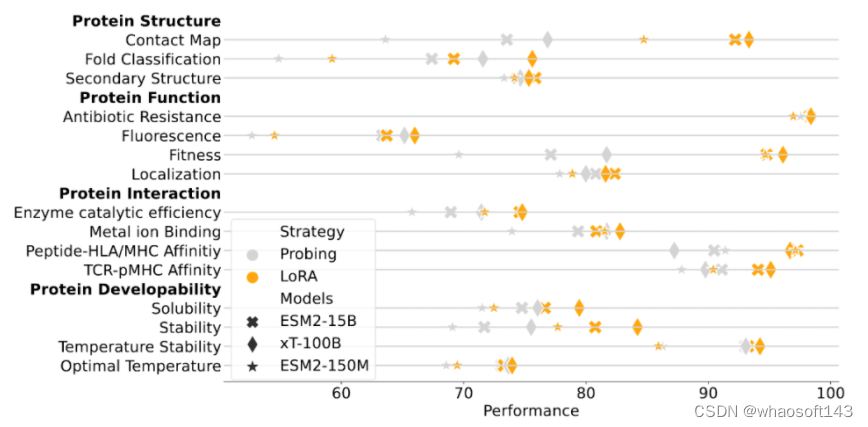
总的来说,xTrimoPGLM-100B 在 15 项任务中的 12 项上表现得比 ESM2-15B 更好。研究结果也揭示了一个规律:尽管其它的方法(比如 Ankh)在试图寻找一种途径,即在不依赖大规模语言模型的情况下,构建高效、低成本、有知识指导的蛋白质语言模型,但在模型的性能还是与模型规模密切相关,这表明,扩大模型规模可能是一个简单而有效的方法,能够在通用的蛋白质相关任务中提升模型的表现。这为未来对蛋白质预训练模型进一步的研究提供了指导。
抗体药物设计的两项任务
为了进一步确定 xTrimoPGLM 框架的通用性,团队把该框架应用在抗体蛋白预训练上。考虑到训练资源的限制和抗体数据的多样性不足(大部分长度相似且有相似的框架区域),团队没有直接在 xTrimoPGLM-100B 上进行精调,而是构建了一个 12 亿参数模型 xTrimoPGLM-Ab-1B,在包含 10 亿抗体序列的 OAS 数据集对模型进行训练。
考虑到 CDRs 是抗体最重要的部分,团队对 40% 的样本进行完整的 CDRs 掩码处理,另外 40% 的样本随机掩码处理,而剩下的 20% 则使用 MLM 目标。由于 [gMASK] 在抗体任务中的需求较少,所以没采用该 loss。xTrimoPGLM-Ab-1B 先在通用蛋白序列上训练 500B 的 token,随后在 OAS 的数据上接着训练 500B 的 token。一共使用 128 块 Nvidia A100 80G GPU 卡进行混合精度训练,大约需要 168 小时。
对于 antibody-based 的药物设计,有两项必不可少的任务就是序列自然度 (Naturalness) 以及抗体结构预测 (Antibody Structure Prediction), 下面分别介绍。
Zero-shot Naturalness
研究团队使用了百图生科湿实验室获得的蛋白质表达实验数据集来评估各种模型的性能。具体来说,任何产生的纯化蛋白质少于 10 mg/L 的样本都被归类为未表达,而产生超过 10 mg/L 的样本被认为是成功合成的。第一个数据集(数据集 1)包括 601 个抗体序列,来自在 CHO 和 HEK293 细胞上进行的湿实验。其中,成功表达的有 516 个。第二个数据集(数据集 2)包含了 98 个针对特定抗原的人类抗体序列,其中 90 个成功表达。评估采用 zero-shot 方式评估,不针对标签微调,仅通过计算序列困惑度(PPL)和伪困惑度(PPPL)给序列打分。
结果显示,在这两个数据集中,xTrimoPGLM-Ab-1B 均优于其他基准模型。而且,进一步对 xTrimoPGLM-Ab-1B 进行精调,分别得到了 xTrimoPGLM-Ab-1B-GLM 和 xTrimoPGLM-Ab-1B-MLM 两个模型。结果显示,这两个模型在数据集 2 上的 AUC 得分均有 0.02 的提升。
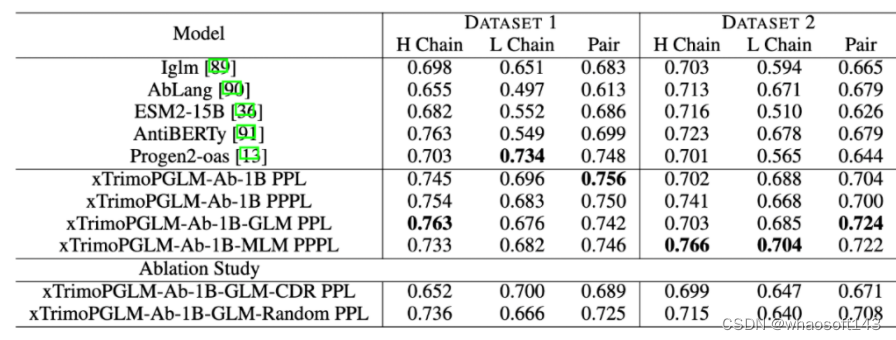
作者们还进行了消融研究,以证明随机区域掩码和 CDR 区域掩码的重要性。实验证明,同时使用这两种目标在数据集 1 和数据集 2 上的表现均优于仅使用其中一种任务的模型,这突显了组合使用这两类目标的重要性。
抗体结构预测
这个任务目标是根据抗体的序列来预测其结构,实验涵盖了单链结构预测和复杂结构预测,即 VH-VL 复合物。
单链结构预测的数据集源自 2022 年 4 月 13 日之前的 RCSB Protein Data Bank (PDB)。该数据集包含 19k 个抗体链(VL 或 VH)。通过过滤,最终获得了约 7.5k 个独特的序列。另一个数据集,VH-VL 复合物,包含了大约 4.7k 个来自 PDB 的抗体。评估标准为根均方偏差(RMSD)和 TM-score。复杂结构预测还包括 DockQ 评估。
相比当前流行的结构预测模型(如 ESMFold, AlphaFold2),xTrimoPGLM-AbFold 做了以下改变:1) 去除了 MSA 和模板搜索模块;2) 将下游 evoformer 模块的数量从 48 减少到 1。
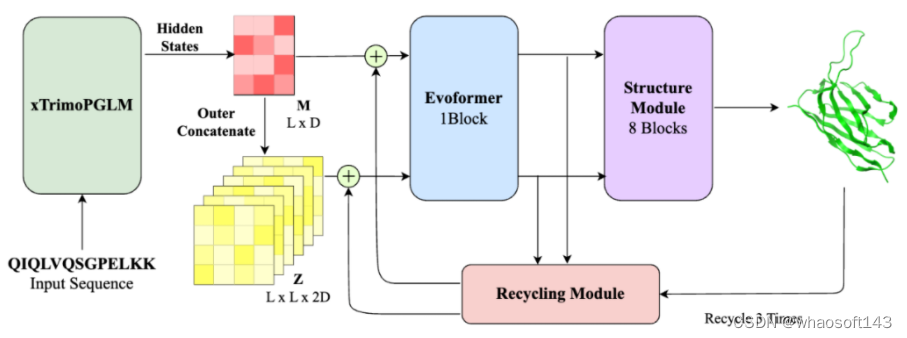
对于单链结构预测任务,研究团队对比了 Alphafold2 以及四个基于 PLM 的模型:OmegaFold、ESMFold、IgFold 和 xTrimoAbFold。
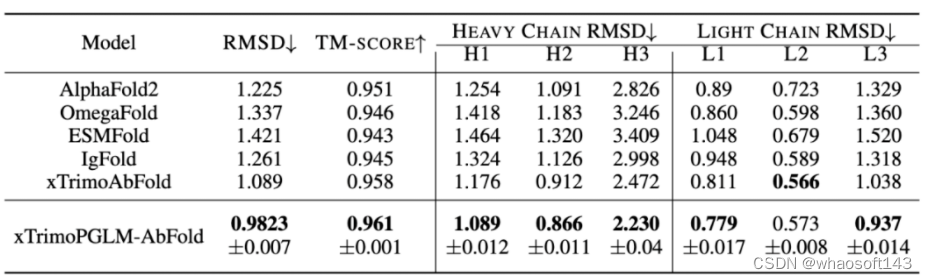
结果如表所示,xTrimoPGLM-AbFold 在所有抗体结构预测相关的指标上都显著优于其他模型,进一步说明,在预训练模型对数据分布拟合的足够好时,只需微调一个额外的 Evoformer 模块以及不依赖 MSA 和模板的情况下,就能成为领先的抗体结构预测模型。对于 VH-VL 复杂结构的预测,研究团队比较了 ZDock、ClusPro、EquiDock、HDOCK 以及 AlphaFold-Multimer。
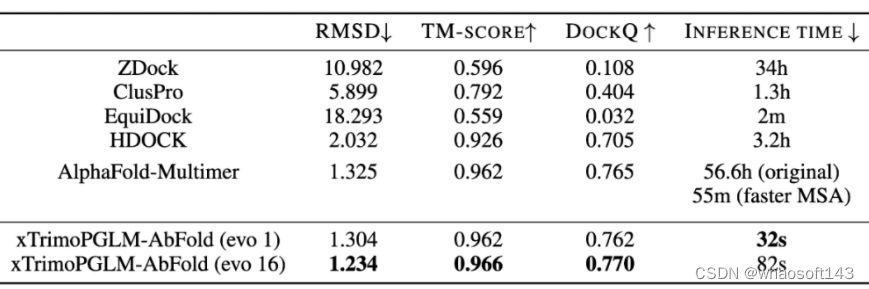
上表也展示了不同模型在 VH-VL 复合物性能上的表现。AlphaFold-Multimer 使用了 MSA 和模板信息,效果优于大多数结构预测算法。而 xTrimoPGLM-AbFold 不使用任何 MSA 或模板信息,与 AlphaFold-Multimer 的表现相当,这说明 xTrimoPGLM-Ab-1B 已经学习了足够丰富的抗体信息。更重要的是,其推理速度比 AlphaFold-Multimer 快了 6300 倍,而且比使用了 MSA 加速搜索策略的 AlphaFold-Multimer 快了 103 倍。在 AI 制药引擎中,往往需要对生成的候选序列快速进行结构预测,以便算出 reward,进行下一轮的迭代,速度的提升决定了引擎的效率。
此外,团队将 Evoformer 模块的数量增加到 16 个时,xTrimoPGLM-AbFold 在所有指标上都达到了最佳性能,同时速度还比原来的 AlphaFold-Multimer 快 2400 倍,比加速 MSA 搜索版的 AlphaFold-Multimer 快 40 倍。值得注意的是,当 Evoformer 模块的数量从 1 增加到 16 时,效果只有少量的提升,这表明预训练模型已经学习到了足够的序列信息,可以精确地预测原子位置。
普通蛋白生成
在探索 xTrimoPGLM 生成自然功能序列的能力上,研究团队生成了数千个序列并预测其对应的三维折叠结构。研究团队发现该模型能够生成重要的二级结构,包括 alpha 螺旋和 beta 折叠,这些都是更复杂三级结构的基础。此外,模型生成的序列与自然序列相似性低,这为之后的药物合成提供了更多的选择。
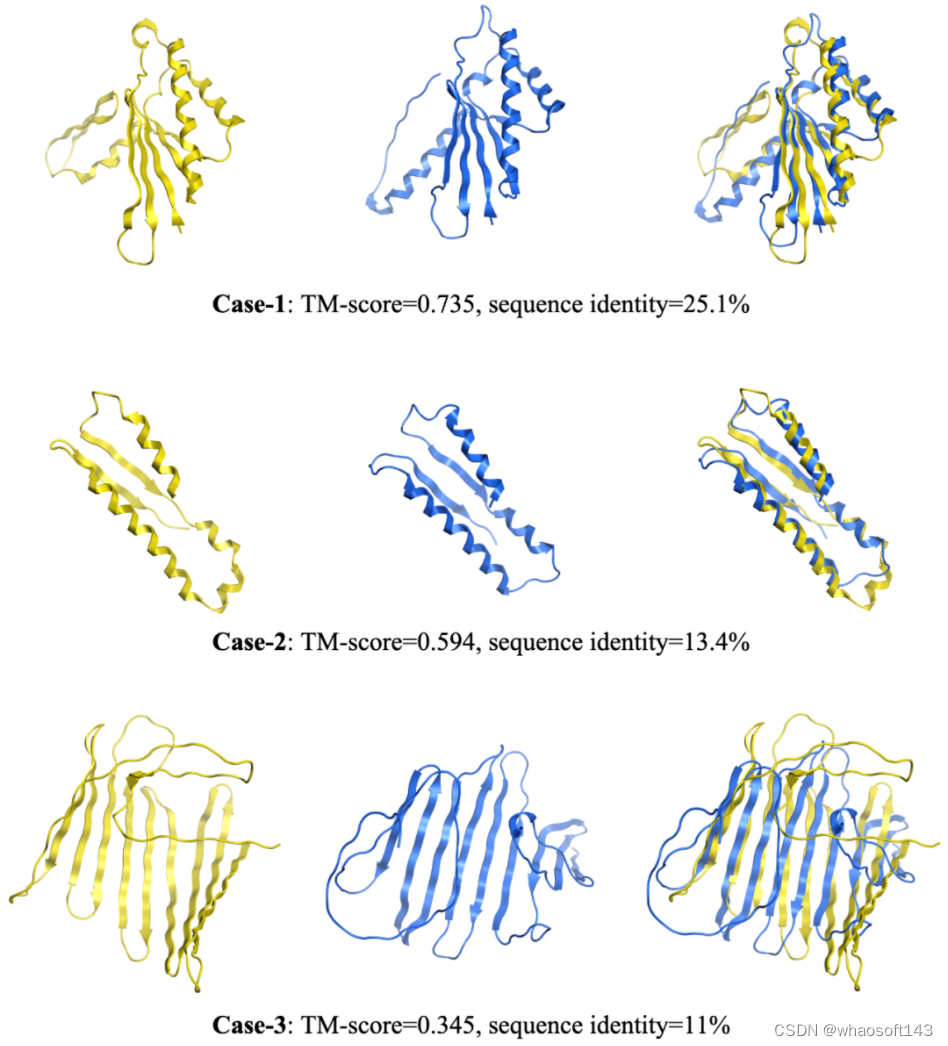
但是,如何生成高质量序列还有着巨大的挑战。首先,当处理超过 200 个氨基酸的序列时,模型往往生成大量的循环,而不是自然蛋白质般的结构。其次,模型在生成过程中经常会产生重复的问题,这可能源于模型倾向于选择在局部最大化输出概率的选项。对此团队尝试使用了 n-gram penalty 来减少生成重复序列的可能性,但研究团队发现许多示例都展示出低复杂度的序列(例如,局部重复),预测的结构中包含长循环无序区域,推测是 n-gram 惩罚可能阻碍了模型生成正确序列的能力(下图第一行)。在去除 n-gram penalty 后,模型能够生成正常的结构(下图第二行)。
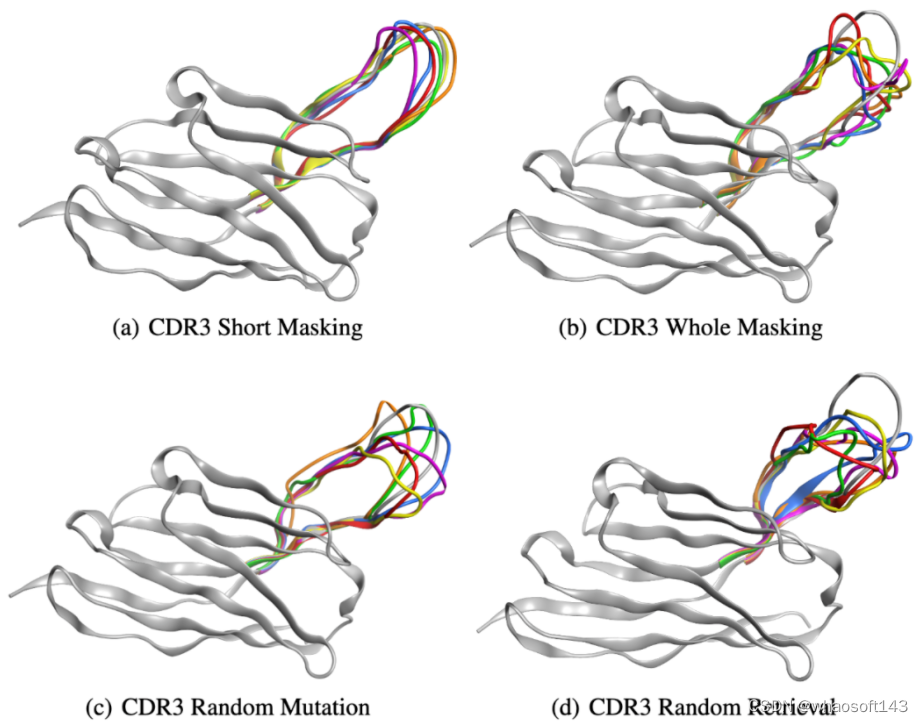
抗体蛋白生成
团队近一步展示了 xTrimoPGLM-Ab-1B 模型的生成能力,选择了一个能与 SARS-CoV-2-WT 链接的重链抗体序列,并采用四种不同的策略重新设计了该序列的 CDR3 区域。因为 CDR3 区域在抗体或 T 细胞受体的结构中起着关键作用,并且具有显著的变异性,对抗原识别的特异性起着重要的作用。以下是定义的四种策略:
- CDR3 短序列掩码(CSM):对 CDR3 部分区域进行掩码重设计。
- CDR3 全序列掩码(CWM):对 CDR3 全部区域进行掩码重设计。
- CDR3 随机突变(CRM):对 CDR3 区域内特定位点的随机 3-6 个位置进行突变。
- CDR3 随机检索(CRR):使用来自 SARS-CoV-2 野生型库中其他抗体的序列随机替换 CDR3 区域。
团队通过 xTrimoPGLM-Ab-1B 生成了一组 6,000 个抗体。研究团队随机选择了六种抗体,并使用 xTrimoPGLM-AbFold 作为结构预测模型。CSM 和 CWM 策略能够生成不同长度的序列,而不必进行突变或删除。相比之下,由两个并行基线 CRM 和 CRR 生成的序列显示出相当大的无序性,无论是否存在少量突变或完全替换整个 CDR3 片段。研究团队的分析进一步发现,编辑距离与生成抗体 CDR3 区域的结构之间存在关系。特别是,随着编辑距离的增加,CDR3 区域的结构倾向于退化,即使是大的生成模型目前也仍然面临限制。
结语
通过借鉴 NLP/CV 领域的想法,生物领域的预训练模型近两年雨后春笋般地冒出来,随着模型计算力的提升和生物数据增长,我们期待更多未知的、惊人的发现出现在这个领域中。
尽管仍然存在不少需要继续探索的地方,千亿模型的诞生不仅标志着最前沿的 AI 技术和生物学技术的融合,还意味着一个充满无限可能的未来已经开启。我们期待,这一重量级的模型引领制药领域步入一个新的黄金时代,为人类健康和科学事业开创更加光明的未来。
#lynx-llm
当前大语言模型 (Large Language Models, LLMs) 如 GPT4 在遵循给定图像的开放式指令方面表现出了出色的多模态能力。然而,这些模型的性能严重依赖于对网络结构、训练数据和训练策略等方案的选择,但这些选择并没有在先前的文献中被广泛讨论。此外,目前也缺乏合适的基准 (benchmarks) 来评估和比较这些模型,限制了多模态 LLMs 的 发展。
- 论文:https://arxiv.org/abs/2307.02469
- 网站:https://lynx-llm.github.io/
- 代码:https://github.com/bytedance/lynx-llm
字节团队从定量和定性两个方面对此类模型的训练进行了系统和全面的研究。设置了 20 多种变体,对于网络结构,比较了不同的 LLMs 主干和模型设计;对于训练数据,研究了数据和采样策略的影响;在指令方面,探讨了多样化提示对模型指令跟随能力的影响。对于 benchmarks ,文章首次提出包括图像和视频任务的开放式视觉问答评估集 Open-VQA。
基于实验结论,作者提出了 Lynx,与现有的开源 GPT4-style 模型相比,它在表现出最准确的多模态理解能力的同时,保持了最佳的多模态生成能力。
评估方案
不同于典型的视觉语言任务,评估 GPT4-style 模型的主要挑战在于平衡文本生成能力和多模态理解准确性两个方面的性能。为了解决这个问题,作者提出了一种包含视频和图像数据的新 benchmark Open-VQA,并对当前的开源模型进行了全面的评价。
具体来说,采用了两种量化评价方案:
- 收集开放式视觉问答 (Open-VQA) 测试集,其包含关于物体、OCR、计数、推理、动作识别、时间顺序等不同类别的问题。不同于有标准答案的 VQA 数据集,Open-VQA 的答案是开放式的。为了评估 Open-VQA 上的性能,使用 GPT4 作为判别器,其结果与人类评估有 95% 的一致性。
- 此外,作者采用了由 mPLUG-owl [1] 提供的 OwlEval 数据集来评估模型的文本生成能力,虽然只包含 50 张图片 82 个问题,但涵盖故事生成、广告生成、代码生成等多样问题,并招募人工标注员对不同模型的表现进行打分。
结论
为了深入研究多模态 LLMs 的训练策略,作者主要从网络结构(前缀微调 / 交叉注意力)、训练数据(数据选择及组合比例)、指示(单一指示 / 多样化指示)、LLMs 模型(LLaMA [5]/Vicuna [6])、图像像素(420/224)等多个方面设置了二十多种变体,通过实验得出了以下主要结论:
- 多模态 LLMs 的指示遵循能力不如 LLMs。例如,InstructBLIP [2] 倾向于不管输入指令如何都生成简短的回复,而其他模型倾向于生成长句子而不考虑指令,作者认为这是由于缺乏高质量和多样化的多模态指令数据所导致的。
- 训练数据的质量对模型的性能至关重要。基于在不同的数据上进行实验的结果,发现使用少量的高质量数据比使用大规模的噪声数据表现得更好。作者认为这是生成式训练和对比式训练的区别,因为生成式训练是直接学习词的条件分布而不是文本和图像的相似度。因此,为了更好的模型性能,在数据方面需要满足两点:1)包含高质量的流畅文本;2)文本和图像内容对齐得较好。
- 任务和提示对零样本 (zero-shot) 能力至关重要。使用多样化任务和指令可以提升模型在未知任务上的零样本生成能力,这与纯文本模型中的观察结果一致。
- 平衡正确性和语言生成能力是很重要的。如果模型在下游任务 (如 VQA) 上训练不足,更可能生成与视觉输入不符的编造的内容;而如果模型在下游任务中训练过多,它则倾向于生成短答案,将无法按照用户的指示生成较长的答案。
- 前缀微调 (prefix-finetuning, PT) 是目前对 LLMs 进行多模态适配的最佳方案。在实验中,prefix-finetuning 结构的模型能更快地提升对多样化指示的遵循能力,比交叉注意力 (cross-attention, CA) 的模型结构更易训练。(prefix-tuning 和 cross-attention 为两种模型结构,具体见 Lynx 模型介绍部分)
Lynx 模型
作者提出了 Lynx(猞猁)—— 进行了两阶段训练的 prefix-finetuning 的 GPT4-style 模型。在第一阶段,使用大约 120M 图像 - 文本对来对齐视觉和语言嵌入 (embeddings) ;在第二阶段,使用 20 个图像或视频的多模态任务以及自然语言处理 (NLP) 数据来调整模型的指令遵循能力。
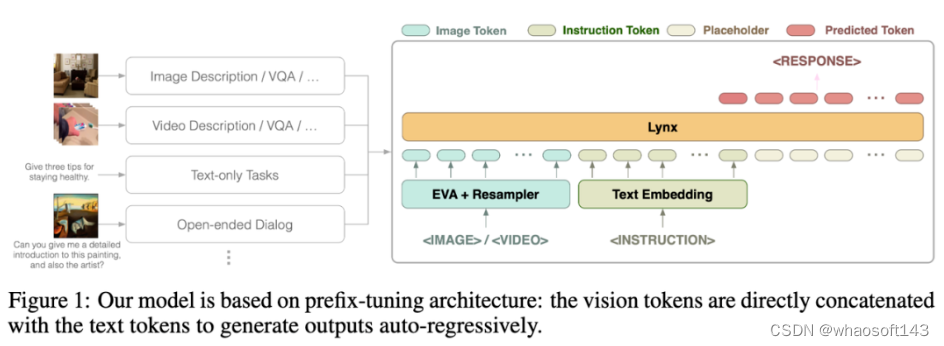
Lynx 模型的整体结构如上图 Figure 1 所示。
视觉输入经过视觉编码器处理后得到视觉令牌 (tokens) $$W_v$$,经过映射后与指令 tokens $$W_l$$ 拼接作为 LLMs 的输入,在本文中将这种结构称为「prefix-finetuning」以区别于如 Flamingo [3] 所使用的 cross-attention 结构。
此外,作者发现,通过在冻结 (frozen) 的 LLMs 某些层后添加适配器 (Adapter) 可以进一步降低训练成本。
模型效果
作者测评了现有的开源多模态 LLMs 模型在 Open-VQA、Mme [4] 及 OwlEval 人工测评上的表现(结果见后文图表,评估细节见论文)。可以看到 Lynx 模型在 Open-VQA 图像和视频理解任务、OwlEval 人工测评及 Mme Perception 类任务中都取得了最好的表现。其中,InstructBLIP 在多数任务中也实现了高性能,但其回复过于简短,相较而言,在大多数情况下 Lynx 模型在给出正确的答案的基础上提供了简明的理由来支撑回复,这使得它对用户更友好(部分 cases 见后文 Cases 展示部分)。
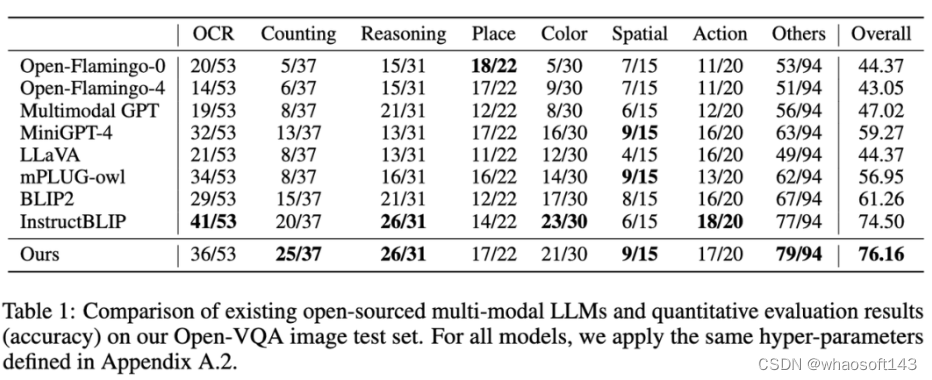
1. 在 Open-VQA 图像测试集上的指标结果如下图 Table 1 所示:
2. 在 Open-VQA 视频测试集上的指标结果如下图 Table 2 所示。
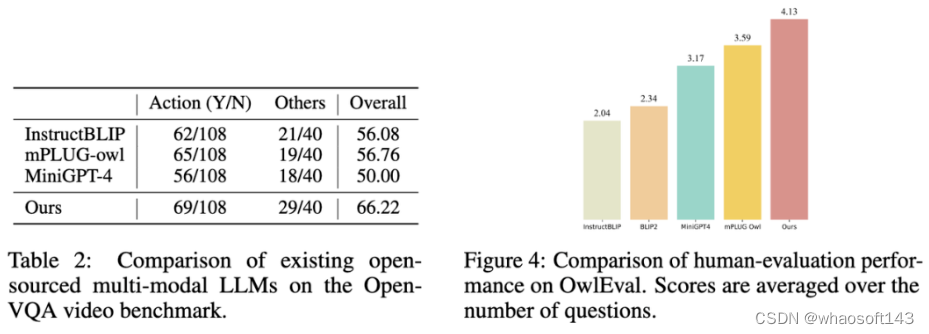
3. 选取 Open-VQA 中得分排名靠前的模型进行 OwlEval 测评集上的人工效果评估,其结果如上图 Figure 4 所示。从人工评价结果可以看出 Lynx 模型具有最佳的语言生成性能。
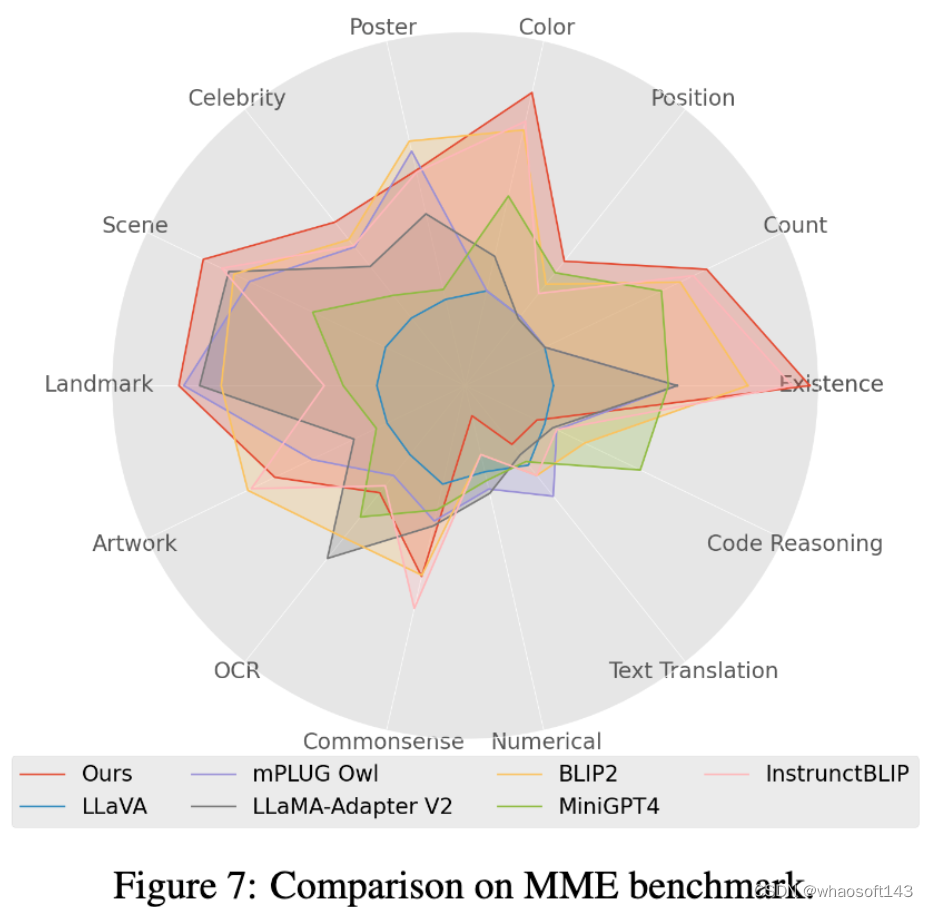
4. 在 Mme benchmark 测试中,Perception 类任务获得最好的表现,其中 14 类子任务中有 7 个表现最优。(详细结果见论文附录)
Cases 展示
Open-VQA 图片 cases

OwlEval cases

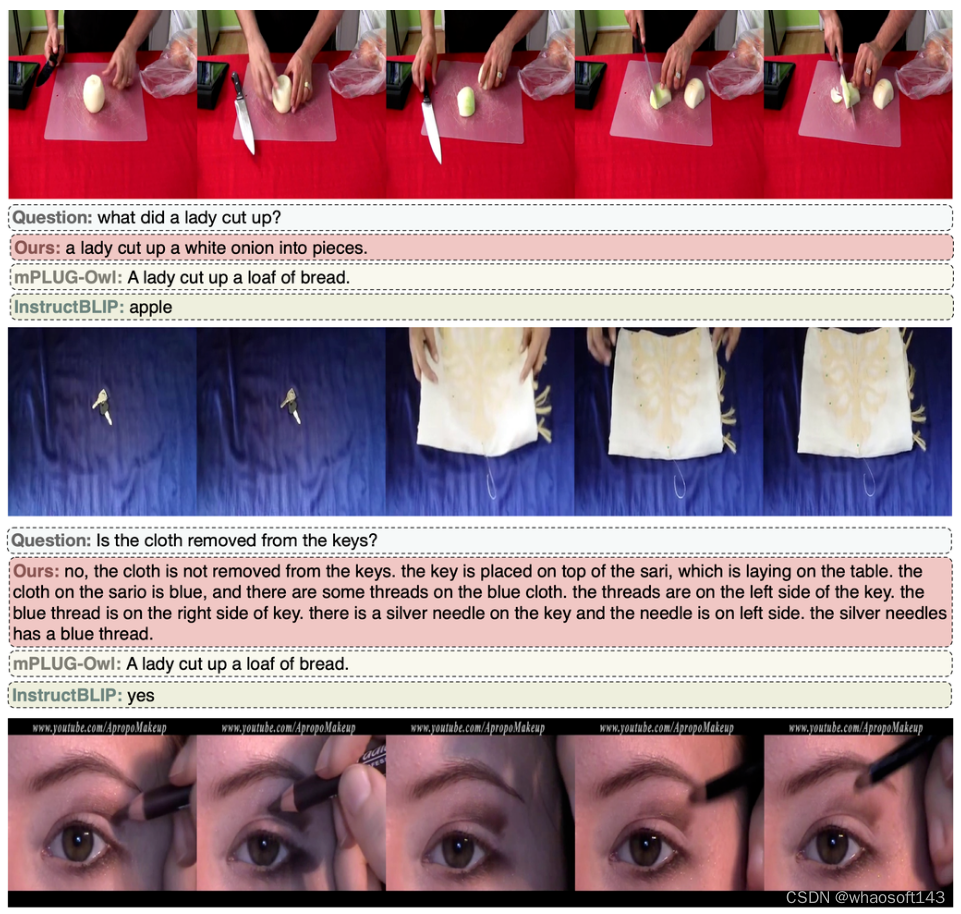
Open-VQA 视频 case

总结
在本文中,作者通过对二十多种多模态 LLMs 变种的实验,确定了以 prefix-finetuning 为主要结构的 Lynx 模型并给出开放式答案的 Open-VQA 测评方案。实验结果显示 Lynx 模型表现最准确的多模态理解准确度的同时,保持了最佳的多模态生成能力。
#lost-in-the-middle
大型语言模型大有用处,在设计 prompt 方面,人们通常建议为语言模型提供详尽的任务描述和背景信息。
近期的一些语言模型有能力输入较长的上下文,但它究竟能多好地利用更长的上下文?这一点却相对少有人知。
近日,斯坦福大学、加州大学伯克利分校和 Samaya AI 的研究者发布了一篇实证研究论文,探究了这个问题。
结论令人意外:如果上下文太长,语言模型会更关注其中的前后部分,中间部分却几乎被略过不看,导致模型难以找到放在输入上下文中部的相关信息。
论文链接:https://arxiv.org/pdf/2307.03172.pdf
他们对多种不同的开源(MPT-30B-Instruct、LongChat-13B (16K))和闭源(OpenAI 的 GPT-3.5-Turbo 和 Anthropic 的 Claude)的语言模型进行了对照实验 —— 实验中需要模型获取并使用输入上下文中的信息。
研究者首先实验了多文档问答,该任务需要模型基于多个文档进行推理,以找到相关信息并将其用于回答给定问题。这个任务模拟了检索增强式生成任务,其是许多商用生成式搜索和问答应用(如 Bing Chat)的基础。在实验中,他们的做法是改变输入上下文长度和输入上下文中相关信息的位置,然后对照比较输出结果的表现。
更详细地说,研究者通过向输入上下文添加更多文档来增大输入上下文的长度(类似于在检索增强式生成任务中检索更多文档);以及通过修改输入上下文中文档的顺序,将相关信息放置在上下文的开头、中间或结尾,从而修改上下文中相关信息的位置。
实验中,研究者观察到,随着相关信息位置的变化,模型性能呈现出明显的 U 型趋势,如图 1 所示。也就是说,当相关信息出现在输入上下文的开头或末尾时,语言模型的性能最高;而当模型必须获取和使用的信息位于输入上下文中部时,模型性能会显著下降。举个例子,当相关信息被放置在其输入上下文中间时,GPT3.5-Turbo 在多文档问题任务上的性能劣于没有任何文档时的情况(即闭卷设置;56.1%)。此外,研究者还发现,当上下文更长时,模型性能会稳步下降;而且配备有上下文扩展的模型并不一定就更善于使用自己的上下文。
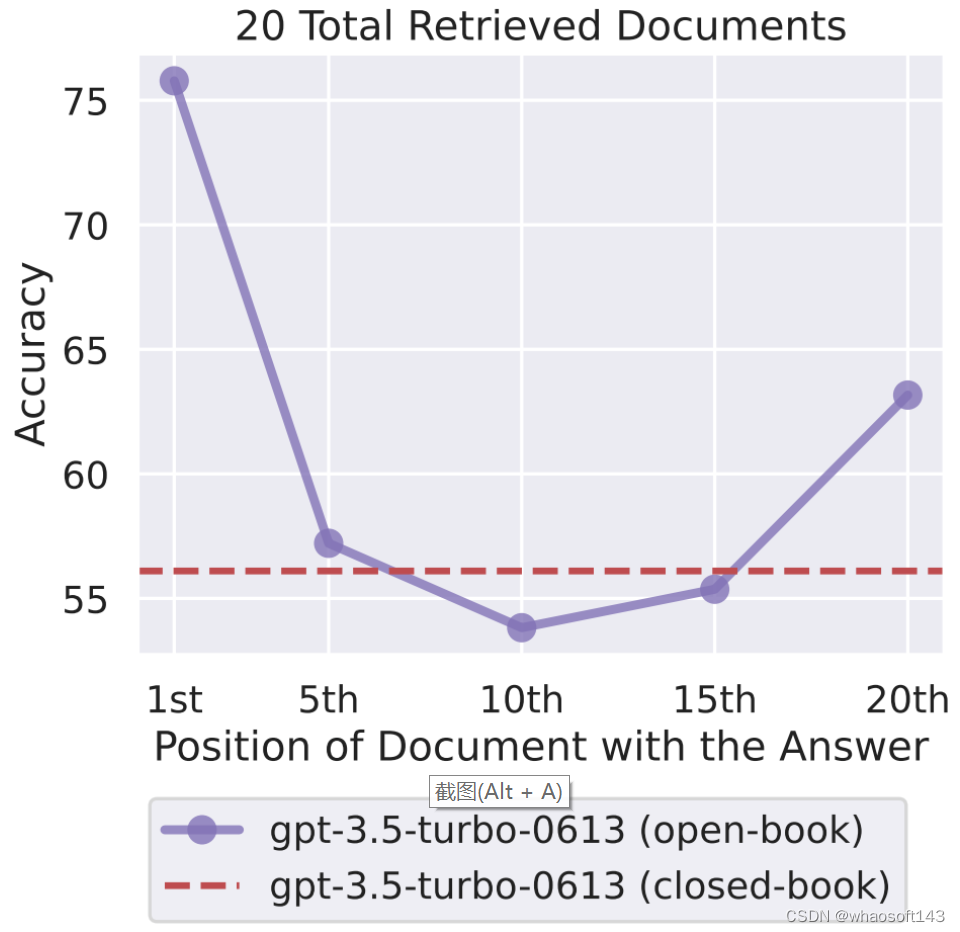
图 1
既然已经知道语言模型在多文档问答任务中难以检索和使用相关信息,那么我们不禁要问:语言模型究竟能在多大程度上从输入上下文中检索信息?
研究者通过一个合成的键 - 值检索任务研究了这一问题。该任务被设计成一个最小化的测试平台,用于检测从输入上下文中检索出相匹配的 token 的基本能力。
在此任务中,研究者会向模型提供一个 JSON 格式的「键 - 值」对集合,然后要求模型返回与特定键关联的值。与多文档问答任务相似,键 - 值检索任务也允许对输入上下文的长度(添加更多键 - 值对)和相关信息的位置进行进行对照更改。研究者在实验中观察到了类似的 U 型性能曲线,即当匹配的 token 出现在输入上下文中部时,许多模型就难以检测出它们。
为了理解语言模型难以获取和使用输入上下文中部位置的信息的原因,研究者分析了模型架构(仅解码器和编码器 - 解码器)、查询感知型上下文化(query-aware contextualization)和指令微调的作用。
他们发现,当评估时的序列长度在训练时所用的序列长度范围内时,对于输入上下文中相关信息位置的变化,编码器 - 解码器模型是相对稳健的;但如果评估时的序列长度长于训练时的,那么模型性能会呈现出 U 型特征。
此外,查询感知型上下文化(将查询放在文档或键 - 值对之前和之后)能让模型可以完美地执行该合成键 - 值任务,但基本不会改变多文档问答任务中呈现的趋势。还有,甚至是基础语言模型(即没有指令微调)也会随输入上下文中相关信息的位置变化而呈现出 U 型性能曲线。
最后,为了更好地理解「向输入上下文添加更多信息」与「增多模型推理所用的内容量」之间的权衡,研究者进行了一个案例研究。该研究基于检索器 - 阅读器模型在开放域问答任务上的表现。相较于对照式的多文档问答任务实验(上下文总是会包含刚好一个用于问答问题的文档),在开放域问答任务中,可能会有多个或零个文档包含答案。
研究者发现,当通过检索维基百科来回答 NaturalQuestions-Open 中的查询时,模型性能在检索器召回率趋于稳定之前很久就已经饱和,这表明模型无法有效地使用额外的检索文档 —— 使用超过 20 个检索文档仅能略微提高性能(对于 GPT-3.5-Turbo 是 ∼1.5%,对于 claude-1.3 为 ∼1%)。
整体来说,这份研究能帮助人们更好地理解语言模型是如何使用输入上下文的,并为未来的长上下文模型引入了新的评估协议。为了促进未来的相关研究,研究者放出了代码和评估数据,请访问:https://github.com/nelson-liu/lost-in-the-middle
为什么语言模型难以完整使用其输入上下文?
在多文档问答和键 - 值检索实验上的结果表明,当语言模型需要从长输入上下文的中部获取相关信息时,模型性能会显著下降。为了理解原因,研究者分析了模型架构(仅解码器和编码器 - 解码器)、查询感知型上下文化和指令微调的作用。
模型架构的影响
为了更好地理解模型架构的潜在影响,研究者比较了仅解码器模型和编码器 - 解码器语言模型。
实验中使用的具体模型为 Flan-T5-XXL 和 Flan-UL2。Flan-T5-XXL 的训练使用了序列长度为 512 token 的序列(编码器和解码器)。Flan-UL2 一开始使用 512 token 长度的序列训练(编码器和解码器),但之后又在 1024 token 长度的序列上预训练了额外 10 万步(编码器和解码器),然后进行了指令微调 —— 其编码器在 2048 token 长度的序列上微调,解码器的序列长度则为 512 token。但是,由于这些模型使用相对位置嵌入,因此它们的推断能力(原则上)可以超出这些最大上下文长度 ——Shaham et al. (2023) 发现当序列长度为 8000 token 时,这两个模型都能取得不错的表现。
图 11 并排展示了仅解码器模型和编码器 - 解码器模型的性能表现。当 Flan-UL2 评估时的序列长度在其训练时的 2048 token 上下文窗口范围内时,输入上下文中相关信息的位置变化能得到稳健的应对。而当评估时的序列长度超过 2048 token 时,如果相关信息位于输入上下文中部,那么 Flan-UL2 的性能会开始下降。Flan-T5-XXL 展现出的趋势类似 —— 如果相关信息在输入上下文中部,那么更长的输入上下文会导致性能下降更多。
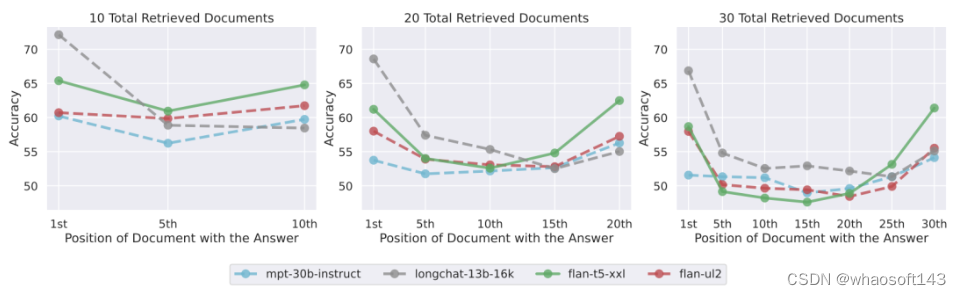
图 11
研究者推测编码器 - 解码器模型也许能更好地利用其上下文窗口,因为它们的双向编码器让它们可以在未来文档的上下文中处理每个文档,这或许能提升文档之间的相对重要性估计。
查询感知型上下文化的影响
实验中,研究者的做法是将查询(即要回答的问题或要检索的键)放在数据(即文档或键 - 值对)之后来处理。由此,当对文档或键 - 值对进行上下文化时,仅解码器模型无法顾及查询 token,因为查询只会出现在 prompt 末尾而仅解码器模型在每个时间步骤只能关注之前的 token。
另一方面,编码器 - 解码器模型使用了双向编码器来上下文化输入上下文,这似乎能更加稳健地应对相关信息的位置变化 —— 研究者猜想这一直观结论或许也能用于提升仅解码器模型的性能,做法是将查询同时放在数据的前面和后面,从而实现文档或键 - 值对的查询感知型上下文化。
研究者发现,查询感知型上下文化能极大提升模型在键 - 值检索任务上的表现。举个例子,当使用 300 个键 - 值对进行评估时,GPT-3.5-Turbo (16K)(使用了查询感知型上下文化)的表现堪称完美。对比之下,如果没有查询感知型上下文化,其在同样设置下的表现最低为 45.6%。
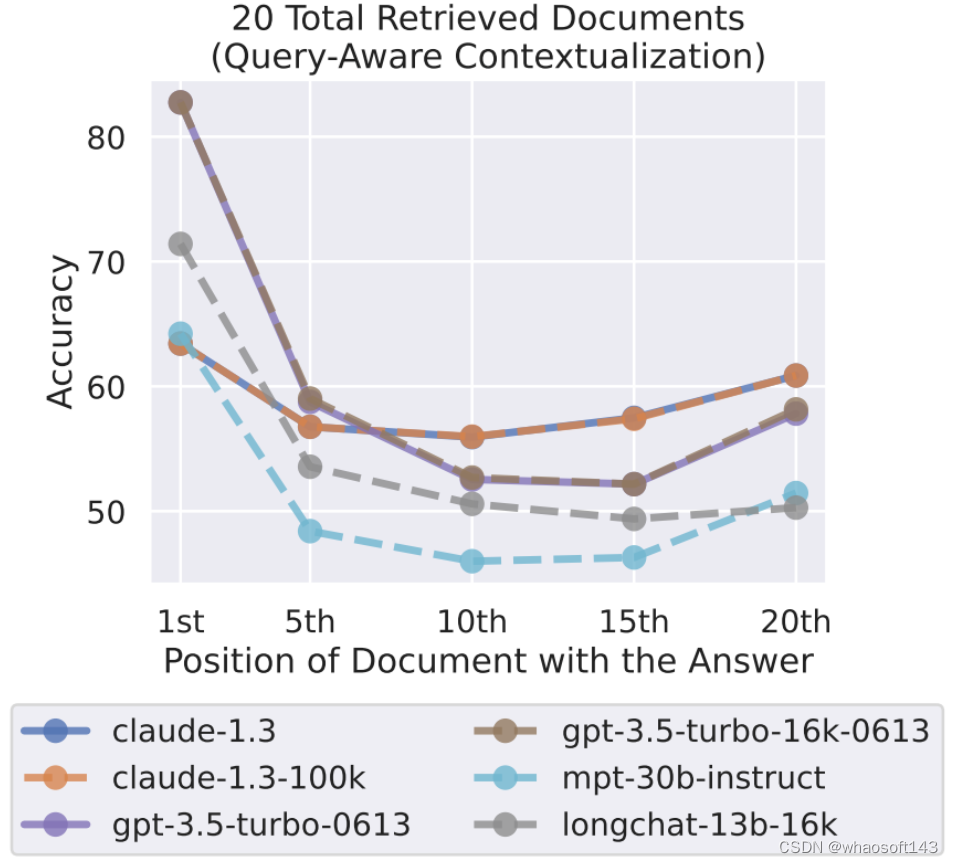
图 12
相比之下,在多文档问答任务上,查询感知型上下文化的影响很小。特别指出,当相关信息位于输入上下文的最开始时,它可以提高性能,但在其他设置中会稍微降低性能。
指令微调的影响
指令微调是指在初始的预训练之后,语言模型还会使用一个指令和响应数据集进行监督式微调。在这种监督式的指令微调数据中,任务规范和 / 或指令通常放置在输入上下文的开头,这可能会导致经过指令微调的语言模型为输入上下文的开头赋予更多权重。
为了更好地理解指令微调的潜在影响,研究者比较了 MPT-30B-Instruct 与其基础模型 MPT-30B(未经指令微调)在多文档问答任务上的性能表现。
图 13 展示了 MPT-30B-Instruct 和 MPT-30B 在多文档问答任务上的性能随输入上下文中相关信息的位置的变化。研究者惊讶地发现,MPT-30B-Instruct 和 MPT-30B 都展现出了 U 型趋势。尽管 MPT-30B-Instruct 的绝对表现优于 MPT-30B,但它们的整体性能趋势十分相似。
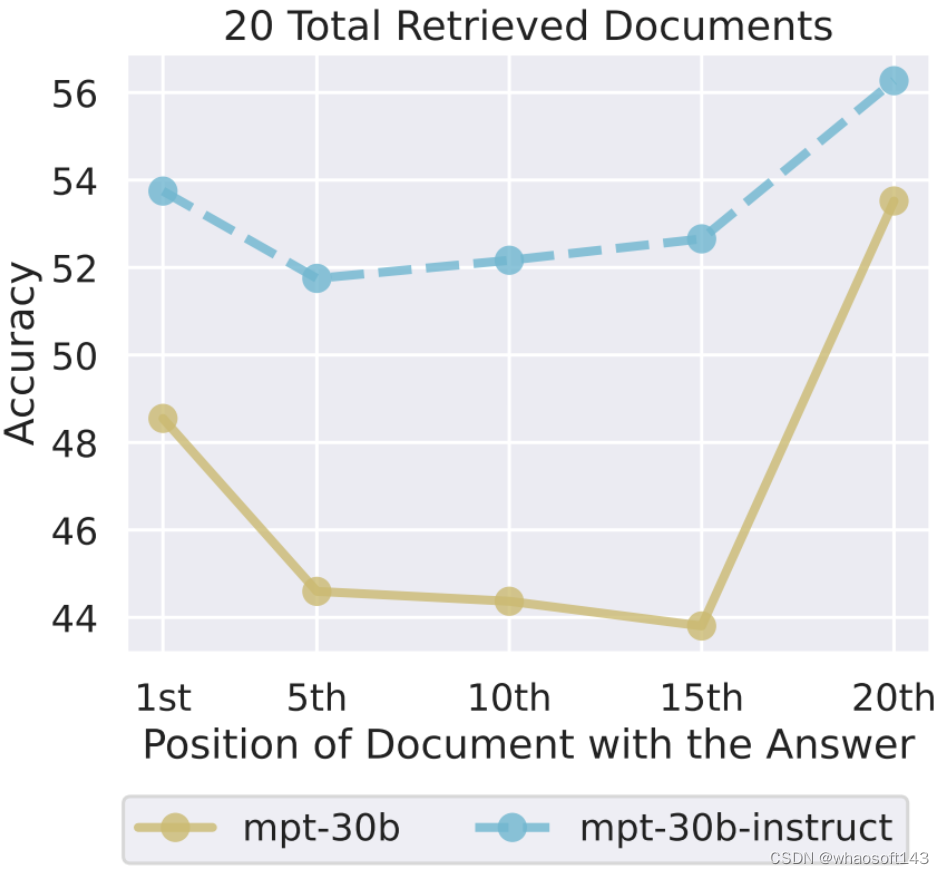
图 13
其实之前已有研究发现语言模型更偏向于近期的 token(即输入上下文的末端)。这种对近期 token 的偏好通常表现在预测连续文本的下一个词的语境中,此时语言模型只能从长程信息中获得极少的好处。相比之下,这里的实验结果表明,当 prompt 是指令格式的数据时,语言模型能够使用更长程的信息(即输入上下文的开头)。研究者猜想语言模型是从相似格式的数据中学习了这些上下文,而这些数据来自预训练时见过的网络文本。
上下文更多就总是更好吗?一个基于开放域问答的案例研究
在实践中,在输入上下文长度方面往往存在一个权衡 —— 如果给经过指令微调的语言模型输入更多信息,可能有助于其在下游任务上的性能,但也会增加模型需要处理的内容量。就算一个语言模型可以处理 1.6 万个 token,那么如果真的为其提供这么多 token,那会真的有用吗?这个问题的答案是:由下游任务决定。因为这取决于所添加上下文的边际价值以及模型有效使用长输入上下文的能力。为了更好地理解这一权衡,研究者在 NaturalQuestions-Open 上进行了开放域问答的案例研究。
他们使用的模型采用了标准的检索器 - 阅读器设置。一个检索系统(Contriever,基于 MS-MARCO 微调得到)从 NaturalQuestions-Open 取用一个输入查询,然后返回 k 个维基百科文档。为了在这些检索到的文档上调节经过指令微调的语言模型,研究者将它们包含到了 prompt 中。他们评估了检索器召回率和阅读器准确度(任何带注释的答案是否出现在预测输出中)随检索出的文档数 k 的变化情况。研究者使用了 NaturalQuestions-Open 的一个子集,其中长答案是一个段落(而不是表格或列表)。
图 14 给出了开放域问答的实验结果。可以看到,在检索器性能趋于稳定之前很久,阅读器模型的性能就早已饱和,这表明阅读器没有有效地使用额外的上下文。使用超过 20 个检索文档只能略微提升阅读器性能(对于 GPT-3.5-Turbo 是 ∼1.5%,对于 Claude 为 ∼1%),但却显著提升了输入上下文长度(由此延迟和成本都大幅提升)。
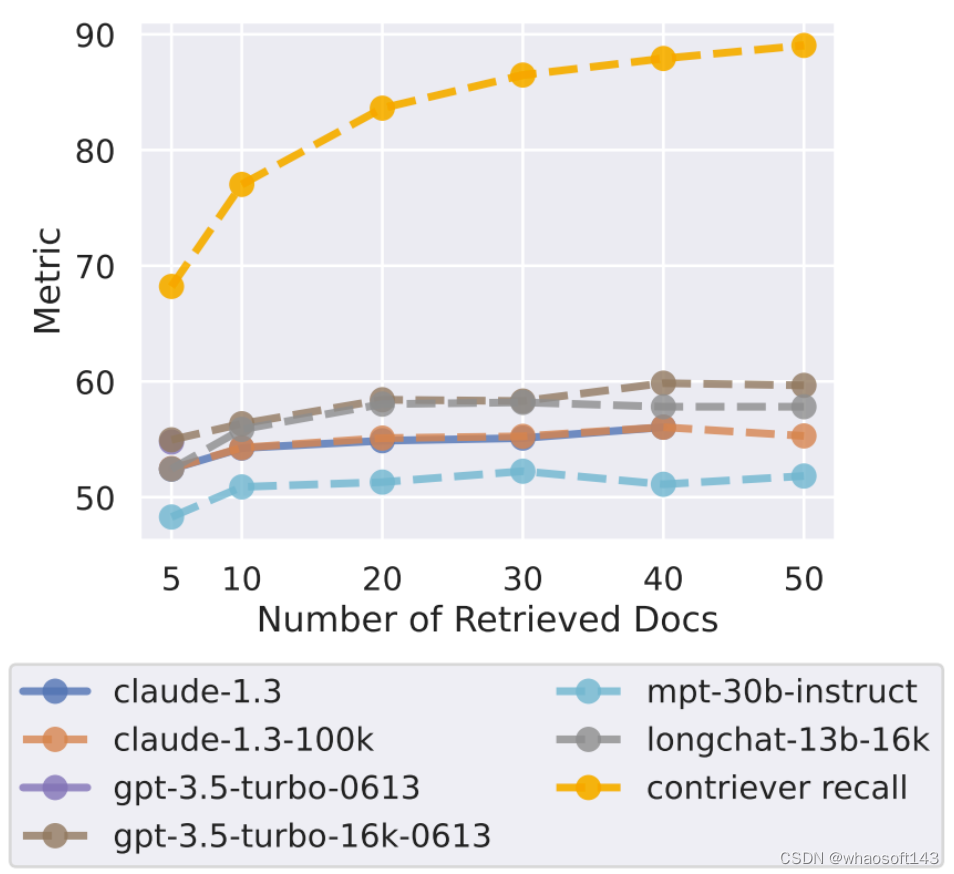
图 14
这些结果表明,如果能有效地对检索文档排序(让相关信息与输入上下文的起始处更近)或对已排序的列表进行截断处理(必要时返回更少的文档),那么也许可以提升基于语言模型的阅读器使用检索上下文的能力。
#FastLLM
本文首先梳理了一下FastLLM的调用链和关键的数据结构,然后解析了 FastLLM 的一些实现细节和CPU/GPU后端实现采用的优化技巧。
这篇文章首先梳理了一下FastLLM的调用链和关键的数据结构,然后解析了 FastLLM 的一些实现细节和CPU/GPU后端实现采用的优化技巧。
调用链和数据结构解析
以chatglm-6b的支持为例,函数入口在 https://github.com/ztxz16/fastllm/blob/master/src/models/chatglm.cpp#L626 ,这里的 input 就是输入的 context(string类型)。然后 https://github.com/ztxz16/fastllm/blob/master/src/models/chatglm.cpp#L633 这行代码对 input 进行 tokenizer encode并构造好inputIds,再构造好attentionMask之后就可以给Forward函数推理,拿到推理结果之后再使用tokenizer进行decode得到输出。
在这里,inputIds和attentionMask都是Data数据类型,类比于PyTorch的Tensor,来对输入数据以及device,shape等信息进行统一管理。下面的代码展示了Data数据结构的定义,源码在:https://github.com/ztxz16/fastllm/blob/master/include/fastllm.h#L201-L286
class Data { public: bool lockInCPU = false; // 如果lock在CPU上,那么不允许移动到其余设备 WeightType weightType = WeightType::NONE; // 权重类型,NONE代表非权重(或未知权重) DataType dataType = DataType::FLOAT32; // 数据类型 int unitSize, unitSizeDiv = 1; // 单个元素的字节数 = unitSIze / unitSizeDiv std::vector <int> dims; // 数据形状 std::vector <uint64_t> strides; // 跨度 uint64_t expansionSize = 0; // 扩容后的尺寸 uint64_t expansionBytes = 0; // 扩容后的字节数 std::vector <int> expansionDims; // 预扩容的形状 uint8_t *cpuData = nullptr; // 数据指针 void *cudaData = nullptr; std::vector <void*> extraCudaData; void *deviceData = nullptr; std::vector <void*> extraDeviceData; DataDevice dataDevice = DataDevice::CPU; // 这两个参数用于量化,对FLOAT数据不适用 int perChannelAxis = -1; // 沿哪个轴分通道量化,-1代表没有分通道 std::vector <LowBitConfig> perChannelsConfigs; // perChannelsConfigs[i]代表第i个通道的min, max; 如果没有分通道,perChannelsConfigs[0]代表全局min, max std::vector <float> scales, mins; std::vector <int> zeros; std::vector <int> weightSum; // 作为权重时,有时候需要存一些和加速计算 std::string fileName; long long filePos; std::shared_ptr<FileMmap> m_file; Data () {}; Data (DataType type); Data (DataType type, const std::vector <int> &dims); // 构造函数 // 构造函数,创建好之后从data复制数据 // data中是原始数据,如果type不是float那么需要量化 Data (DataType type, const std::vector <int> &dims, const std::vector <float> &data); ~Data(); // 析构函数 Data (const Data &ori); // 深拷贝 void CopyFrom(const Data &ori); // 复制 uint64_t GetBytes() const; // 获取总字节数 void Allocate(); // 分配内存 void Allocate(float v); // 分配内存并初始化 void Expansion(const std::vector <int> &dims); // 预扩容到相应尺寸 void MallocSpace(uint64_t size); // 在设备上分配 void FreeSpace(); // 回收设备上的内存 void UpdateUnitSize(); // 更新unitSize void Resize(const std::vector <int> &dims); // 更改尺寸 void Reshape(const std::vector <int> &dims); // 更改尺寸,但不修改数据 uint64_t Count(int i) const; // dims[i] * strides[i] void PrintShape() const; // 输出形状 void Print() const; // 输出 void CalcWeightSum(); // 计算WeightSum void ToDevice(DataDevice device); // 移动到指定device void ToDevice(void *device); void set_file(std::shared_ptr<FileMmap> file) { m_file = file; } };在Forward函数里面,以Data为核心载体,运行chatglm-6b模型的流程,具体包含如下的一些算子:https://github.com/ztxz16/fastllm/blob/master/include/fastllm.h#L346-L408 。以Permute为例我们浏览下它的实现:
void Permute(const Data &input, const std::vector<int> &axis, Data &output) { Data axisData = Data(DataType::INT32PARAM, {(int)axis.size()}); axisData.Allocate(); for (int i = 0; i < axisData.Count(0); i++) { ((int32_t*)axisData.cpuData)[i] = axis[i]; } curExecutor->Run("Permute", { {"input", (Data*)&input}, {"axis", &axisData}, {"output", (Data*)&output} }, {}, {}); }这里的curExecutor负责根据FastLLM编译开启的后端选项把算子Dispatch到不同的device进行执行,{"input", (Data*)&input}, {"axis", &axisData}, {"output", (Data*)&output}} 这行代码表示的是一个DataDict对象,也就是一个值为data的字典,原始定义为typedef std::map <std::string, Data*> DataDict;。接着我们看一下curExecutor的定义和实现:
namespace fastllm { class Executor { private: std::vector <BaseDevice*> devices; std::map <std::string, float> profiler; public: Executor (); // 创建默认的Executor ~Executor(); // 析构 void ClearDevices(); // 清空 devices void AddDevice(BaseDevice *device); // 增加一个device // 运行一个op void Run(const std::string &opType, const fastllm::DataDict &datas, const fastllm::FloatDict &floatParams, const fastllm::IntDict &intParams); void ClearProfiler(); void PrintProfiler(); };
}从Executor类的定义我们可以判断它负责了在设定的devices上根据opType和输入数据等执行Op的前向计算,也就是Run这个接口。由于Executor类是FastLLM的调度核心实现,所以我们来详细解析一下它的实现。
namespace fastllm { Executor::Executor() { this->devices.clear();
#ifdef USE_CUDA // 将一个指向 CudaDevice 类对象的指针插入到 devices 向量的末尾。 // 这里通过 new 运算符创建了一个 CudaDevice 对象,并将返回的指针进行类型转换为 BaseDevice* 类型。 this->devices.push_back((BaseDevice*) new CudaDevice());
#endif this->devices.push_back((BaseDevice*) new CpuDevice()); } Executor::~Executor() { // 释放 devices 向量中的每个指针元素所占用的内存。 for (int i = 0; i < devices.size(); i++) { delete devices[i]; } } void Executor::ClearDevices() { // this->devices 指的是当前对象的 devices 成员,即指向 BaseDevice 类对象的指针向量。 this->devices.clear(); } // 该函数用于向 devices 向量中添加一个指向 BaseDevice 类对象的指针。 void Executor::AddDevice(fastllm::BaseDevice *device) { this->devices.push_back(device); } void Executor::Run(const std::string &opType, const fastllm::DataDict &datas, const fastllm::FloatDict &floatParams, const fastllm::IntDict &intParams) { // 创建一个 st 变量,用于记录函数开始执行的时间。 auto st = std::chrono::system_clock::now(); // 创建一个布尔变量 lockInCPU,用于记录是否将数据锁定在 CPU 上。 bool lockInCPU = false; // 在第一个 for 循环中,遍历数据字典 datas,查找是否有 "___batch" 后缀的参数, // 并根据情况设置 lockInCPU 的值。it.first 是数据字典中的键(key),it.second // 是对应的值(value)。如果存在 "___batch" 后缀的参数,则将 lockInCPU 设置为 // 对应数据的 lockInCPU 属性(布尔值),否则设置为当前数据的 lockInCPU 属性。 for (auto &it: datas) { if (intParams.find(it.first + "___batch") != intParams.end()) { int batch = intParams.find(it.first + "___batch")->second; for (int i = 0; i < batch; i++) { lockInCPU |= ((Data**)it.second)[i]->lockInCPU; } } else { lockInCPU |= it.second->lockInCPU; } } // 第二个 for 循环遍历 devices 向量中的所有设备指针 device。 // 在循环中,首先检查 lockInCPU 是否为真,并且当前设备的类型不是 "cpu", // 如果是,则跳过当前设备(continue)。这个检查是为了保证数据锁定在 CPU 上时,只执行 CPU 设备上的操作。 for (auto device: devices) { if (lockInCPU && device->deviceType != "cpu") { continue; } // 然后,通过调用 device->CanRun(opType, datas, floatParams, intParams) // 检查当前设备是否可以运行指定的操作 opType。如果可以运行,则进行以下操作: if (device->CanRun(opType, datas, floatParams, intParams)) { // 第三个 for 循环遍历数据字典 datas,如果存在 "___batch" 后缀的参数, // 则将对应数据转移到当前设备上;否则,将当前数据转移到当前设备上。 for (auto &it: datas) { if (intParams.find(it.first + "___batch") != intParams.end()) { int batch = intParams.find(it.first + "___batch")->second; for (int i = 0; i < batch; i++) { ((Data**)it.second)[i]->ToDevice((void *) device); } } else { it.second->ToDevice((void *) device); } } // 调用 device->Reshape(opType, datas, floatParams, intParams) // 进行形状推导,device上的形状推导调用了opType对应的op的形状推导, // 并且被各个不同的op重写。 device->Reshape(opType, datas, floatParams, intParams); // 对opType对应的这个算子进行推理。 device->Run(opType, datas, floatParams, intParams); break; } } // 最后,计算操作运行时间,并将其加入 profiler 成员变量,用于性能分析。 float spend = GetSpan(st, std::chrono::system_clock::now()); profiler[opType] += spend; } // 清除profile的信息 void Executor::ClearProfiler() { profiler.clear(); } // 打印profile信息,也即输出每个层的运行时间和模型的总运行时间 void Executor::PrintProfiler() { float sum = 0.0; for (auto &it : profiler) { printf("%s spend %f\n", it.first.c_str(), it.second); sum += it.second; } printf("total spend %f\n", sum); }
}自此,前向计算就顺利完成了,再把推理结果给 tokenizer 解码就结束了,整体的调度执行流程是很简单明了的。
tokenizer 解析
接着,我们来解析一下tokenizer的实现。先看一下tokenizer的定义(https://github.com/ztxz16/fastllm/blob/master/include/fastllm.h#L287-L310):
struct Tokenizer { struct TrieNode { int tokenId; std::map <int, TrieNode*> next; TrieNode(); }; TrieNode *root; std::unordered_map <int, std::string> tokenToStringDict; Tokenizer (); ~Tokenizer(); void Clear(); // 清空分词器 void Insert(const std::string &s, int tokenId); // 插入一个token Data Encode(const std::string &s); // 编码 std::string Decode(const Data &data); // 解码 std::string DecodeTokens(const std::vector <int> &tokens); // 解码 };我们从实现来看tokenizer的细节:
// 这是 Tokenizer 类的嵌套结构 TrieNode 的构造函数的实现。 // 在构造函数中,将 tokenId 成员变量的值初始化为 -999999。 // 这个值在构造函数中被硬编码,它是作为一个特殊标记来使用的。 Tokenizer::TrieNode::TrieNode() { this->tokenId = -999999; } // Tokenizer 类的构造函数的实现。 // 在构造函数中,通过 new 运算符创建一个新的 TrieNode 对象, // 并将其指针赋值给 root 成员变量。这样,构造函数创建了一个空的字典树, // 并将其根节点指针存储在 root 中。 Tokenizer::Tokenizer() { root = new TrieNode(); } // Tokenizer 类的析构函数的实现。 // 在析构函数中,首先调用 Clear() 函数,用于释放动态分配的资源和清空数据。 // 然后,调用 delete 运算符释放通过 new 运算符创建的 root 对象的内存,从而释放整个字典树的内存。 Tokenizer::~Tokenizer() { Clear(); delete root; } // 这是 Tokenizer 类的成员函数 Clear() 的定义,用于清空分词器并释放动态分配的资源。 void Tokenizer::Clear() { // 创建一个指向 TrieNode 的指针向量 q,用于辅助遍历字典树。 std::vector <TrieNode*> q; // 将字典树的根节点 root 加入 q 向量,作为遍历的起始点。 q.push_back(root); // 开始遍历 q 向量中的节点,这是一个广度优先搜索(BFS)的过程。 for (int i = 0; i < q.size(); i++) { // 取出当前遍历到的节点 now。 TrieNode *now = q[i]; // 对当前节点 now 的所有子节点进行遍历。 for (auto it : now->next) { // 将当前节点 now 的子节点加入 q 向量中,以便继续遍历子节点的子节点。 q.push_back(it.second); } } // 当遍历完成后,q 向量中包含了字典树中的所有节点。 // 创建一个新的 TrieNode 对象,并将其指针赋值给 root 成员变量,表示创建了一个空的字典树。 root = new TrieNode(); // 清空 tokenToStringDict 映射表,以确保所有 token 的映射被清空。 tokenToStringDict.clear(); } // 这是 Tokenizer 类的成员函数 Insert 的定义,用于向分词器中插入一个 token。 void Tokenizer::Insert(const std::string &s, int tokenId) { // 创建一个指向 TrieNode 的指针 now,并将其初始化为指向字典树的根节点 root。 TrieNode *now = this->root; // 开始遍历输入的字符串 s 中的每个字符。 for (int i = 0; i < s.size(); i++) { // 检查当前字符 s[i] 是否已经存在于当前节点 now 的 next 映射表中。 // 如果当前字符 s[i] 不存在于当前节点 now 的子节点中, // 在 now->next 中添加新的子节点,该子节点的键为当前字符 s[i] 的编码值, // 值为指向新创建的 TrieNode 对象的指针。这表示在字典树中添加了一个新的字符节点。 if (now->next.find(s[i]) == now->next.end()) { now->next[s[i]] = new TrieNode(); } // 将 now 移动到下一个字符 s[i] 对应的节点,以便继续处理下一个字符。 now = now->next[s[i]]; } // 遍历完成后,now 将指向字典树中最后一个字符的节点。 // 设置当前节点的 tokenId 成员变量,表示当前节点代表一个 token, // 并使用传入的 tokenId 值来标识该 token。 now->tokenId = tokenId; // 将传入的 tokenId 和对应的字符串 s 添加到 tokenToStringDict // 映射表中,用于后续的解码过程。 tokenToStringDict[tokenId] = s; } // 这是 Tokenizer 类的成员函数 Encode 的定义,用于对输入的字符串 s 进行编码。 Data Tokenizer::Encode(const std::string &s) { // 创建一个浮点数向量 v,用于存储编码结果。该向量将存储找到的 token 对应的 tokenId 值。 std::vector <float> v; // 开始遍历输入的字符串 s 中的每个字符。 for (int i = 0; i < s.size(); i++) { // 创建两个整数变量 tokenId 和 pos, // 用于记录找到的 token 的 tokenId 值和 token 的结束位置。 int tokenId = -999999, pos = i - 1; // 创建一个指向 TrieNode 的指针 now,并将其初始化为指向字典树的根节点 root。 TrieNode *now = this->root; // 从当前字符 s[i] 开始继续遍历字符串 s。 for (int j = i; j < s.size(); j++) { // 检查当前字符 s[j] 是否存在于当前节点 now 的 next 映射表中。 // 如果存在,表示当前字符构成了一个 token 的一部分,继续遍历子节点。 if (now->next.find(s[j]) != now->next.end()) { // 将 now 移动到下一个字符 s[j] 对应的节点。 now = now->next[s[j]]; // 检查当前节点 now 是否代表一个 token,即它的 tokenId 是否有效。 if (now->tokenId != -999999) { // 如果当前节点代表一个 token,将 tokenId 和当前位置 j 存储到 // tokenId 和 pos 变量中,以便记录找到的 token 的信息。 tokenId = now->tokenId; pos = j; } } else { // 如果当前字符不再是 token 的一部分,退出内层循环,继续外层循环。 break; } } // 如果 pos 大于等于当前位置 i,表示找到了一个 token。 // 这里 pos 存储了找到的 token 的结束位置,i 移动到 pos 处,以便继续遍历下一个字符。 if (pos >= i) { i = pos; v.push_back(tokenId); //printf("%d ", tokenId); } } //printf("\n"); // 遍历完成后,v 向量中存储了输入字符串中所有找到的 token 对应的 tokenId 值。 // 创建一个 Data 对象并返回,表示编码的结果。这里 Data 是一个数据结构, // 用于存储数据及其相关信息。编码结果是一个一维浮点数数组, // 表示输入字符串中所有找到的 token 对应的 tokenId 值。 return Data (DataType::FLOAT32, {1, (int)v.size()}, v); } // 这是 Tokenizer 类的成员函数 DecodeTokens 的定义, // 用于对输入的 token 数组进行解码,将 token 转换回原始的字符串。 std::string Tokenizer::DecodeTokens(const std::vector<int> &tokens) { // 创建一个空字符串 ret,用于存储解码结果。 std::string ret = ""; // 开始遍历输入的 token 数组 tokens。 for (int i = 0; i < tokens.size(); i++) { // 获取当前 token 对应的原始字符串 s,通过查询 tokenToStringDict 映射表, // 将 tokens[i] 转换回字符串。 std::string s = tokenToStringDict[tokens[i]]; // 判断当前 token 是否需要特殊处理: // 如果 s 是类似 "<0xHH>" 格式的 token(其中 HH 表示十六进制数), // 则需要将其转换为对应的字符。首先,提取 HH,然后将其转换为对应的字符, // 并用空格代替原始的 token。 if (s.size() == 6 && s.substr(0, 3) == "<0x" && s.back() == '>') { int c = 0; for (int i = 3; i < 5; i++) { c *= 16; if (s[i] >= '0' && s[i] <= '9') { c += (s[i] - '0'); } else { c += (s[i] - 'A' + 10); } } s = " "; s[0] = c; } // 根据不同的 token 进行解码: if (s == "<n>") { ret += "\n"; } else if (s == "<|tab|>") { ret += "\t"; } else { ret += s; } } // 将特殊字符 "\xE2\x96\x81"(UTF-8 编码)替换为空格 " ",这是用于表示空格的特殊字符。 std::string blank = ""; blank += 226, blank += 150, blank += 129; while (true) { std::string::size_type pos(0); if ((pos = ret.find(blank)) != std::string::npos) ret.replace(pos, blank.length(), " "); else break; } // 检查是否有 "<|blank_数字>" 格式的特殊 token,如果有,将其解码成对应数量的空格字符。 int pos = ret.find("<|blank_"); if (pos != -1) { int space_num = atoi(ret.substr(8, ret.size() - 10).c_str()); return std::string(space_num, ' '); } return ret; } std::string Tokenizer::Decode(const Data &data) { std::vector <int> tokens; for (int i = 0; i < data.Count(0); i++) { tokens.push_back((int) ((float *) data.cpuData)[i]); } return DecodeTokens(tokens); }上面的:
if (pos != -1) { int space_num = atoi(ret.substr(8, ret.size() - 10).c_str()); return std::string(space_num, ' '); }这行代码应该是有bug,假设 ret 的值为 "Hello<|blank_4>world!",那么在解码时,pos 将是 8,而 space_num 将是 4。然后,函数将返回 " ",即包含四个空格字符的字符串。在这种情况下,特殊 token "<|blank_4>" 被成功解码成了四个空格字符,但是Hello和world!这部分被删掉了。所以最终的解码结果是不对的,需要修正一下。对tokenizer的解析可以发现,在c++中使用字典树数据结构来实现tokenizer是相对比较简单方便的。接下来,我们对CPU后端和GPU后端的算子实现进行解析。
CPU后端算子实现
主要就是对这个文件进行解析:https://github.com/ztxz16/fastllm/blob/master/src/devices/cpu/cpudevice.cpp 。
辅助函数
// 这是 CpuDevice 类的成员函数 Malloc 的定义,用于在 CPU 上分配一块内存空间。 bool CpuDevice::Malloc(void **ret, size_t size) { *ret = (void*)new uint8_t [size]; return true; } // 这是 CpuDevice 类的成员函数 Free 的定义,用于在 CPU 上释放之前分配的内存。 bool CpuDevice::Free(void *ret) { delete[] (uint8_t*)ret; return true; } // 这是 CpuDevice 类的成员函数 CopyDataFromCPU 的定义,用于将数据从 CPU 拷贝到指定的设备上。 // 这里什么都不做,直接返回true。 bool CpuDevice::CopyDataFromCPU(void *dst, void *src, size_t size) { return true; } // 这是 CpuDevice 类的成员函数 CopyDataToCPU 的定义,用于将数据从指定的设备拷贝到 CPU 上。 bool CpuDevice::CopyDataToCPU(void *dst, void *src, size_t size) { return true; } // 如果定义了 __AVX__ 和 __AVX2__,那么会启用第一个 DotU8U8 函数和 DotU4U8 函数。
// 如果只定义了 __AVX__,但没有定义 __AVX2__,那么会启用第二个 DotU8U8 函数和 DotU4U8 函数。 #ifdef __AVX__
#ifdef __AVX2__ // 这是一段使用了 Intel AVX2 指令集(Advanced Vector Extensions 2)的代码, // 用于计算两个8位无符号整数数组的点积。 // 定义了一个函数 DotU8U8,它接受两个指向 8 位无符号整数的指针 a 和 b, // 以及一个整数 n。这个函数的目的是计算数组 a 和 b 的点积,其中数组的长度为 n。 int DotU8U8(uint8_t *a, uint8_t *b, int n) { // 初始化一个 256 位的整数向量 acc,所有位都设置为零。这个向量用于存储点积的累加值。 __m256i acc = _mm256_setzero_si256(); // 初始化两个变量,i 用于循环计数,ans 用于存储最后的结果。 int i = 0; int ans = 0; // 等这几行代码初始化了一些常量向量 const __m256i lowMask = _mm256_set1_epi8(0xf); const __m256i ones = _mm256_set1_epi16(1); const __m256i ones8 = _mm256_set1_epi8(1); const __m256i xors = _mm256_set1_epi8(-128); // 这是一个循环,每次处理 32 个元素。这是因为 AVX2 可以同时处理 32 个 8 位整数。 for (; i + 31 < n; i += 32) { // 这两行代码从数组 a 和 b 中加载数据到 256 位的向量 bx 和 by。 __m256i bx = _mm256_loadu_si256((const __m256i *) (a + i)); __m256i by = _mm256_loadu_si256((const __m256i *) (b + i)); // 这行代码将 by 中的每个元素减去 128,这对应于上面表达式中的 ((int)b[i] - 128)。 by = _mm256_xor_si256(by, xors); // 这行代码对于那些原本是 0 的元素(在减去 128 后变为 -128 的元素)加 1, // 以避免后续乘法操作时的溢出。 by = _mm256_add_epi8(by, _mm256_and_si256(_mm256_cmpeq_epi8(by, xors), ones8)); // 这行代码将 bx 中的符号应用到 by 中,对应于上面表达式中的 ((int8_t*)a)[i]。 by = _mm256_sign_epi8(by, bx); // 这行代码将 bx 中的所有非零元素变为 1,这是为了在后续的乘法操作中保持 by 中元素的原值。 bx = _mm256_sign_epi8(bx, bx); // 这行代码先对 bx 和 by 进行乘法运算(这对应于上面表达式中的 * 操作), // 然后再与 acc 进行加法操作(这对应于上面表达式中的 += 操作)。 acc = _mm256_add_epi32(acc, _mm256_madd_epi16(_mm256_maddubs_epi16(bx, by), ones)); } // 这是另一个循环,用于处理数组中剩余的元素(数量小于 32)。 // 这些元素通过常规的方式计算点积,然后累加到 ans 中。 for (; i < n; i++) { ans += ((int8_t*)a)[i] * ((int)b[i] - 128); } // 最后,将 acc 中的所有元素相加,然后再加上 ans,返回最终的结果。 return ans + I32sum(acc); };
#else // 定义了一个函数 DotU8U8,它接受两个指向 8 位无符号整数的指针 a 和 b, // 以及一个整数 n。这个函数的目的是计算数组 a 和 b 的点积,其中数组的长度为 n。 int DotU8U8(uint8_t *a, uint8_t *b, int n) { // 初始化一个 256 位的整数向量 acc,所有位都设置为零。这个向量用于存储点积的累加值。 __m256i acc = _mm256_setzero_si256(); int i = 0; int ans = 0; // 这是一个循环,每次处理 32 个元素。这是因为 AVX 可以同时处理 32 个 8 位整数。 for (; i + 31 < n; i += 32) { // 这两行代码从数组 a 和 b 中加载数据到 256 位的向量 bx 和 by。 __m256i bx = _mm256_loadu_si256((const __m256i *) (a + i)); __m256i by = _mm256_loadu_si256((const __m256i *) (b + i)); // 接下来的四行代码将 bx 和 by 中的 8 位整数扩展为 16 位整数。 // 这是因为在后续的乘法和累加操作中,如果仍然使用 8 位整数,可能会发生溢出。 __m256i mx0 = _mm256_cvtepu8_epi16(_mm256_extractf128_si256(bx, 0)); __m256i mx1 = _mm256_cvtepu8_epi16(_mm256_extractf128_si256(bx, 1)); __m256i my0 = _mm256_cvtepu8_epi16(_mm256_extractf128_si256(by, 0)); __m256i my1 = _mm256_cvtepu8_epi16(_mm256_extractf128_si256(by, 1)); // 这两行代码首先对 mx0 和 my0,以及 mx1 和 my1 进行乘法累加操作, // 然后再与 acc 进行加法操作,结果存储在 acc 中。 acc = _mm256_add_epi32(acc, _mm256_madd_epi16(mx0, my0)); acc = _mm256_add_epi32(acc, _mm256_madd_epi16(mx1, my1)); } // 这是另一个循环,用于处理数组中剩余的元素(数量小于 32)。 // 这些元素通过常规的方式计算点积,然后累加到 ans 中。 for (; i < n; i++) { ans += a[i] * b[i]; } // 最后,将 acc 中的所有元素相加,然后再加上 ans,返回最终的结果。 return ans + I32sum(acc); };
#endif // 它接受两个指向 8 位无符号整数的指针 a 和 b,以及一个整数 n。 // 这个函数的目的是计算数组 a 和 b 的点积,其中数组的长度为 n。 int DotU4U8(uint8_t *a, uint8_t *b, int n) { // 初始化一个 256 位的整数向量 acc,所有位都设置为零。这个向量用于存储点积的累加值。 __m256i acc = _mm256_setzero_si256(); int i = 0; int ans = 0; // 初始化两个常量向量,lowMask 中的每个元素都是 0xf,ones 中的每个元素都是 1。 const __m256i lowMask = _mm256_set1_epi8(0xf); const __m256i ones = _mm256_set1_epi16(1); for (; i + 31 < n; i += 32) { // 从数组 a 中加载 16 个元素到 128 位的向量 orix 中。 // 这里 i / 2 的原因是每个元素实际上只有 4 位。 __m128i orix = _mm_loadu_si128((const __m128i *) (a + i / 2)); // 将 orix 中的元素分成高 4 位和低 4 位,然后将它们合并成一个 256 位的向量 bytex。 __m256i bytex = _mm256_set_m128i(_mm_srli_epi16(orix, 4), orix); // 使用按位与操作,取 bytex 中的每个元素的低 4 位,结果存储在 bx 中。 __m256i bx = _mm256_and_si256(lowMask, bytex); // 从数组 b 中加载数据到 256 位的向量 by。 __m256i by = _mm256_loadu_si256((const __m256i *) (b + i)); // 这行代码首先进行了两个向量的乘法累加操作,然后再与 acc 进行加法操作,结果存储在 acc 中。 acc = _mm256_add_epi32(acc, _mm256_madd_epi16(_mm256_maddubs_epi16(by, bx), ones)); } for (; i < n; i++) { ans += a[i] * b[i]; } return ans + I32sum(acc); };
#endif在启用AVX2进行点积计算时,有一个特殊的操作就是把b[i]转换为有符号的整数并减掉128。我没太懂这个操作的意义是什么,问了一下gpt4获得了如下的回答:

然后这里有个疑问是在DotU4U8的实现中调用的指令应该是AVX2的指令集,但确是在AVX2宏关闭时调用的,不清楚这里是否会有bug。
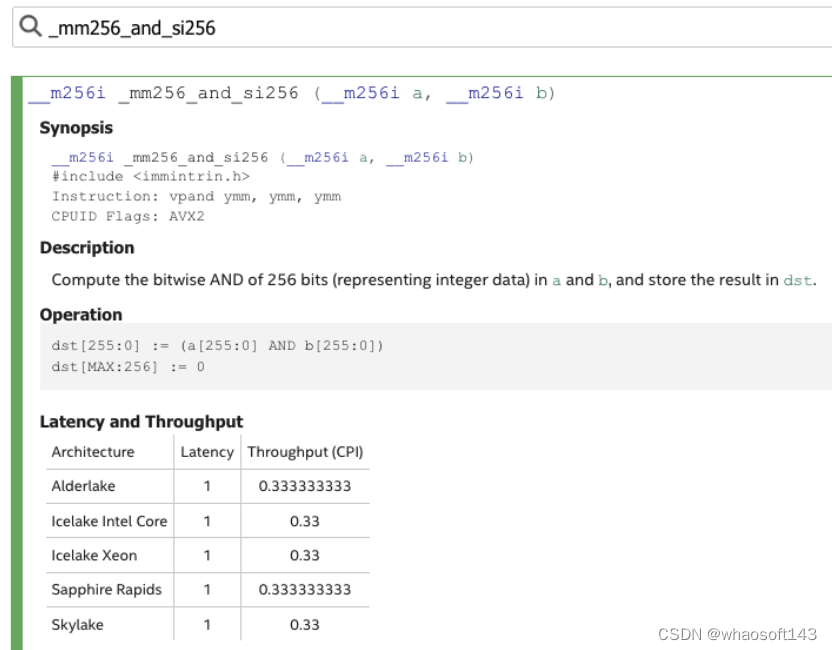
上述函数中涉及到大量的intel Intrinsics指令细节,读者想详细了解可以参考官方文档:https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html 。
CpuEmbedding 算子解析
// CpuEmbedding 算子的形状推导函数,这个函数接受四个参数:
// 一个 std::string 类型的 opType,两个字典类型的 datas 和 floatParams,以及一个 intParams。
void CpuEmbedding::Reshape(const std::string &opType, const fastllm::DataDict &datas, const fastllm::FloatDict &floatParams, const fastllm::IntDict &intParams) { // 这三行代码从 datas 字典中查找键为 "input"、"output" 和 "weight" 的元素, // 并将找到的元素的值赋给 input、output 和 weight。 // 这里的 "input"、"output" 和 "weight" 可以理解为嵌入层的输入、输出和权重。 Data &input = *(datas.find("input")->second); Data &output = *(datas.find("output")->second); Data &weight = *(datas.find("weight")->second); // 这行代码检查 weight 的维度数量是否为 2。如果不是,就会抛出一个错误。 AssertInFastLLM(weight.dims.size() == 2, "Embedding's weight's dim should be 2.\n"); // 这行代码检查 weight 的数据类型是否为 FLOAT32 或 BFLOAT16。如果不是,就会抛出一个错误。 AssertInFastLLM(weight.dataType == DataType::FLOAT32 || weight.dataType == DataType::BFLOAT16, "Embedding's weight's type should be float32 or bfloat16.\n"); // 这行代码检查 input 的数据类型是否为 FLOAT32。如果不是,就会抛出一个错误。 AssertInFastLLM(input.dataType == DataType::FLOAT32, "Embedding's input's type should be float32.\n"); // 这行代码将 weight 的 weightType 属性设置为 EMBEDDING。 weight.weightType = WeightType::EMBEDDING; // 这行代码从 weight 的维度中提取词汇大小(vocabSize)和嵌入大小(embSize)。 int vocabSize = weight.dims[0], embSize = weight.dims[1]; // 这两行代码将 embSize 添加到 input 的维度中,形成一个新的维度。 std::vector <int> dims = input.dims; dims.push_back(embSize); // 这两行代码将 output 的数据类型设置为 FLOAT32,并重新调整其维度。 output.dataType = DataType::FLOAT32; output.Resize(dims); } // 这是一个名为 CpuEmbedding::Run 的函数,它在某个名为 CpuEmbedding 的类中被定义。 // 这个函数接受四个参数:一个 std::string 类型的 opType, // 两个字典类型的 datas 和 floatParams,以及一个 intParams。 // 这个函数的主要任务是执行嵌入层(Embedding layer)的运算。 // 嵌入层通常用于将离散型特征(例如词汇)转换为连续的向量表示。 // 具体的实现方法是,对于每个输入的索引,从权重矩阵中查找对应的行, // 然后将其复制到输出矩阵的对应位置。 void CpuEmbedding::Run(const std::string &opType, const fastllm::DataDict &datas, const fastllm::FloatDict &floatParams, const fastllm::IntDict &intParams) { // 这三行代码从 datas 字典中查找键为 "input"、"output" 和 "weight" 的元素, // 并将找到的元素的值赋给 input、output 和 weight。 // 这里的 "input"、"output" 和 "weight" 可以理解为嵌入层的输入、输出和权重。 Data &input = *(datas.find("input")->second); Data &output = *(datas.find("output")->second); Data &weight = *(datas.find("weight")->second);; output.Allocate(); // 这行代码为 output 分配内存。 // 这行代码从 weight 的维度中提取词汇大小(vocabSize)和嵌入大小(embSize)。 int vocabSize = weight.dims[0], embSize = weight.dims[1]; // 这行代码计算 input 的长度。 uint64_t inputLen = input.Count(0); // 这行代码获取 input 的数据,并将其转换为浮点数的指针。 float *inputData = (float*)input.cpuData; // 接下来的代码根据内存模式和权重的数据类型的不同,分别处理了四种情况。 // 这四种情况可以归纳为两个大类:内存模式和权重的数据类型。 // 内存模式:如果 GetLowMemMode() 返回 true,则表示处于低内存模式。 // 在这种模式下,权重数据不会一次性全部加载到内存中,而是每次只加载需要的部分。 // 否则,权重数据会全部加载到内存中。 if (GetLowMemMode()) { FILE *fi = fopen(weight.fileName.c_str(), "rb"); // 权重的数据类型:如果权重的数据类型为 FLOAT32,则使用浮点数进行计算。 // 如果权重的数据类型为 BFLOAT16,则使用 16 位浮点数进行计算。 if (weight.dataType == DataType::FLOAT32) { float *outputData = (float *) output.cpuData; for (int i = 0; i < inputLen; i++) { // 这行代码从 inputData 中取出第 i 个元素,并将其四舍五入到最近的整数。 int token = (int) (inputData[i] + 1e-9); // 这两行代码将文件指针移动到第 token 行的开始位置。
#if defined(_WIN32) or defined(_WIN64) _fseeki64(fi, (long long)token * embSize * sizeof(float) + weight.filePos, 0);
#else fseek(fi, (long long)token * embSize * sizeof(float) + weight.filePos, 0);
#endif // 这行代码从文件中读取 embSize 个浮点数,并将它们存储在 outputData 的对应位置。 int ret = fread(outputData + i * embSize, sizeof(float), embSize, fi); } } else { // 如果权重的数据类型为 BFLOAT16,则使用 16 位浮点数进行计算。 // 这部分代码的逻辑与 FLOAT32 部分的逻辑类似,只是多了一个步骤: // 将 16 位的浮点数转换为 32 位的浮点数。 uint16_t *outputData = (uint16_t *) output.cpuData; uint16_t *weightData = new uint16_t[embSize]; for (int i = 0; i < inputLen; i++) { int token = (int) (inputData[i] + 1e-9);
#if defined(_WIN32) or defined(_WIN64) _fseeki64(fi, (long long)token * embSize * sizeof(uint16_t) + weight.filePos, 0);
#else fseek(fi, (long long)token * embSize * sizeof(uint16_t) + weight.filePos, 0);
#endif int ret = fread(weightData, sizeof(uint16_t), embSize, fi); for (int j = 0; j < embSize; j++) { outputData[i * embSize * 2 + j * 2] = 0; outputData[i * embSize * 2 + j * 2 + 1] = weightData[j]; } } delete[] weightData; } // 最后,fclose(fi); 这行代码关闭了文件。 fclose(fi); } else { if (weight.dataType == DataType::FLOAT32) { // 这两行代码获取 output 和 weight 的数据,并将它们转换为浮点数的指针。 float *outputData = (float *) output.cpuData; float *weightData = (float *) weight.cpuData; for (int i = 0; i < inputLen; i++) { int token = (int) (inputData[i] + 1e-9); // 这行代码从 weightData 中复制 embSize 个浮点数到 outputData 的对应位置。 // 这里的 token 是索引,embSize 是嵌入向量的长度。 memcpy(outputData + i * embSize, weightData + token * embSize, embSize * sizeof(float)); } } else { uint16_t *outputData = (uint16_t *) output.cpuData; uint16_t *weightData = (uint16_t *) weight.cpuData; for (int i = 0; i < inputLen; i++) { int token = (int) (inputData[i] + 1e-9); for (int j = 0; j < embSize; j++) { outputData[i * embSize * 2 + j * 2] = 0; outputData[i * embSize * 2 + j * 2 + 1] = weightData[token * embSize + j]; } } } } }CpuLayerNormOp 解析
void CpuLayerNormOp::Run(const std::string &opType, const fastllm::DataDict &datas, const fastllm::FloatDict &floatParams, const fastllm::IntDict &intParams) { // 这四行代码从 datas 字典中查找键为 "input"、"output"、"gamma" 和 "beta" 的元素, // 并将找到的元素的值赋给 input、output、gamma 和 beta。 // 这里的 "input" 是层归一化的输入,"output" 是输出, // "gamma" 和 "beta" 是用于对归一化后的结果进行缩放和移位的可学习参数。 Data &input = *(datas.find("input")->second); Data &output = *(datas.find("output")->second); Data &gamma = *(datas.find("gamma")->second); Data &beta = *(datas.find("beta")->second); // 这行代码为 output 分配内存。 output.Allocate(); // 这行代码从 intParams 字典中查找键为 "axis" 的元素。 // 如果找到,则使用找到的值作为归一化的轴;否则,使用默认值 -1。在层归一化中,轴通常是特征维度。 int axis = intParams.find("axis") != intParams.end() ? intParams.find("axis")->second : -1; // 这两行代码计算 input 的维度数,并将 axis 转换为非负数。 // 这是为了处理负数的轴值,因为在 Python 中,轴可以是负数,表示从后向前数的位置。 int dimsLen = input.dims.size(); axis = (axis % dimsLen + dimsLen) % dimsLen; // 这三行代码计算 outer、channels 和 inner。 // outer 是归一化操作的外部维度的元素总数,channels 是归一化操作的轴的大小, // inner 是归一化操作的内部维度的元素总数。 int outer = input.Count(0) / input.Count(axis); int channels = input.dims[axis]; int inner = input.strides[axis]; // 这行代码为 mean 和 var 分配内存,它们用于存储每个归一化组的均值和方差。 float *mean = new float[inner], *var = new float[inner]; float *inputData = (float *) input.cpuData; float *outputData = (float *) output.cpuData; float *gammaData = (float *) gamma.cpuData; float *betaData = (float *) beta.cpuData; // 在这个条件下,每个通道只有一个元素,所以可以并行地对每个通道进行层归一化。 if (inner == 1) { // 这是一个循环,对 input 中的每一个外部元素进行处理。 for (int i = 0; i < outer; i++) { // 这行代码定义了三个浮点数变量,分别用于存储均值、平方和和方差。 float mean = 0.f, s2 = 0.f, var = 0.f; int j = 0; // 这是一段条件编译的代码,只有在目标平台为 ARM 架构时才会编译和执行。 // 这段代码使用了 ARM 架构的 SIMD 指令来加速计算。
#ifdef __aarch64__ float32x4_t sums = vdupq_n_f32(0.0); float32x4_t sums2 = vdupq_n_f32(0.0); for (; j + 3 < channels; j += 4) { float32x4_t vi = vld1q_f32(inputData + j); sums = vaddq_f32(sums, vi); sums2 = vaddq_f32(sums2, vmulq_f32(vi, vi)); } mean = sums[0] + sums[1] + sums[2] + sums[3]; s2 = sums2[0] + sums2[1] + sums2[2] + sums2[3];
#endif
#ifdef __AVX2__ // 这是另一段条件编译的代码,只有在目标平台支持 AVX2 指令集时才会编译和执行。 // 这段代码使用了 AVX2 的 SIMD 指令来加速计算。 __m256 sum_vec = _mm256_setzero_ps(); __m256 squared_sum_vec = _mm256_setzero_ps(); for (; j < channels - 7; j += 8) { __m256 data_vec = _mm256_loadu_ps(inputData + j); sum_vec = _mm256_add_ps(sum_vec, data_vec); __m256 squared_data_vec = _mm256_mul_ps(data_vec, data_vec); squared_sum_vec = _mm256_add_ps(squared_sum_vec, squared_data_vec); } float sum_array[8]; _mm256_storeu_ps(sum_array, sum_vec); mean = sum_array[0] + sum_array[1] + sum_array[2] + sum_array[3] + sum_array[4] + sum_array[5] + sum_array[6] + sum_array[7]; float squared_sum_array[8]; _mm256_storeu_ps(squared_sum_array, squared_sum_vec); s2 = squared_sum_array[0] + squared_sum_array[1] + squared_sum_array[2] + squared_sum_array[3] + squared_sum_array[4] + squared_sum_array[5] + squared_sum_array[6] + squared_sum_array[7];
#endif // 这是一个循环,对 input 中剩余的每一个通道进行处理。 for (; j < channels; j++) { mean += inputData[j]; s2 += inputData[j] * inputData[j]; } // 这两行代码计算了均值和方差。 mean /= channels; var = sqrt(s2 / channels - mean*mean + 1e-10); // 接下来是对output的每一个通道进行并行处理 j = 0;
#ifdef __aarch64__ float32x4_t means = vdupq_n_f32(mean); float32x4_t vars = vdupq_n_f32(1.0 / var); for (; j + 3 < channels; j += 4) { float32x4_t va = vld1q_f32(gammaData + j), vb = vld1q_f32(betaData + j); float32x4_t vi = vld1q_f32(inputData + j); float32x4_t vo = vaddq_f32(vmulq_f32(vmulq_f32(vsubq_f32(vi, means), vars), va), vb); vst1q_f32(outputData + j, vo); }
#endif for (; j < channels; j++) { float a = gammaData[j], b = betaData[j]; outputData[j] = (inputData[j] - mean) / var * a + b; } // 这两行代码更新了 inputData 和 outputData 的指针位置, // 以便在下一轮循环中处理下一个外部元素。 inputData += channels; outputData += channels; } return; } else { // 这段代码同样是执行层归一化(Layer Normalization)操作,但这次的操作更为通用, // 能处理 inner 不等于 1 的情况,即每个通道有多个元素的情况。 // 这是一个循环,对 input 中的每一个外部元素进行处理。 for (int i = 0; i < outer; i++) { // 这两行代码将 mean 和 var 数组的所有元素初始化为 0。 std::fill(mean, mean + inner, 0.f); std::fill(var, var + inner, 0.f); // 这行代码定义了一个指针 inputWalk,指向 inputData。 float *inputWalk = inputData; // 这是一个循环,对每个通道进行处理。 for (int j = 0; j < channels; j++) { // 这是一个嵌套循环,对每个通道内的每个元素进行处理。 for (int k = 0; k < inner; k++) { // 这行代码将当前元素的值加到对应的 mean 中,然后 inputWalk 指针向后移动。 mean[k] += *inputWalk++; } } // 这是另一个循环,计算每个通道的均值。 for (int k = 0; k < inner; k++) { mean[k] /= channels; } // 方差类似 inputWalk = inputData; for (int j = 0; j < channels; j++) { for (int k = 0; k < inner; k++) { float x = (*inputWalk++) - mean[k]; var[k] += x * x; } } for (int k = 0; k < inner; k++) { var[k] = sqrt(var[k] / channels + 1e-5); } // 计算输出也是类似 inputWalk = inputData; float *outputWalk = outputData; for (int j = 0; j < channels; j++) { float a = gammaData[j], b = betaData[j]; for (int k = 0; k < inner; k++) { *outputWalk++ = ((*inputWalk++) - mean[k]) / var[k] * a + b; } } inputData += channels * inner; outputData += channels * inner; } delete[] mean; delete[] var; } }CPULinearOp 解析
最后简单读一下CPULinearOp这个算子。
void CpuLinearOp::Run(const std::string &opType, const fastllm::DataDict &datas, const fastllm::FloatDict &floatParams, const fastllm::IntDict &intParams) {
//auto st = std::chrono::system_clock::now(); Data &input = *(datas.find("input")->second); Data &output = *(datas.find("output")->second); Data &weight = *(datas.find("weight")->second); Data &bias = *(datas.find("bias")->second); output.Allocate(0.0f); int n = input.Count(0) / input.dims.back(); int m = input.dims.back(); int k = output.dims.back(); // 这段代码处理权重数据类型为FLOAT32的情况。首先,它将输入、权重、输出和 // 偏置数据的指针分别转换为 float* 类型的指针。对于偏置数据,如果其维度长度大于0, // 则获取其数据指针,否则设为nullptr。 if (weight.dataType == DataType::FLOAT32) { float *inputData = (float *) input.cpuData; float *weightData = (float *) weight.cpuData; float *outputData = (float *) output.cpuData; float *biasData = bias.dims.size() > 0 ? (float *) bias.cpuData : nullptr; // 接下来,计算需要的线程数(threadNum)。这里用的是用户设定的线程数 //(通过 GetThreads() 获得)。然后,每个线程负责的任务数(per) // 为 k(输出数据的最后一个维度)除以线程数。cur 用来表示当前任务的起始位置。 int threadNum = GetThreads(); int per = k / threadNum; int cur = 0; // 接着,创建线程池(通过 GetPool() 获取)和用于保存线程任务的std::future数组。 // 对于每个线程,确定其需要处理的任务范围(从 cur 到 end),然后提交线程任务。 // 线程任务是通过调用 FloatLinearPart 函数来执行的,该函数需要输入数据、 // 权重数据、偏置数据、输出数据、输入维度(n)、权重维度(m)、输出维度(k) // 以及任务范围(从 cur 到 end)作为参数。 auto pool = GetPool(); std::vector <std::future <void> > futures; for (int i = 0; i < threadNum - 1; i++) { int end = cur + per + (cur + per * (threadNum - i) < k); futures.push_back(pool->Submit(FloatLinearPart, inputData, weightData, biasData, outputData, n, m, k, cur, end)); cur = end; } // 然后,主线程也执行一部分任务,处理范围为从 cur 到 k。 FloatLinearPart(inputData, weightData, biasData, outputData, n, m, k, cur, k); // 最后,主线程等待所有子线程完成工作。通过调用 std::future::get() // 方法来阻塞主线程,直到对应的子线程完成任务。 // 这样,可以保证所有的线程任务都完成后,主线程才继续执行。 for (int i = 0; i < futures.size(); i++) { futures[i].get(); } } else if (weight.dataType == DataType::FLOAT16) { float *inputData = (float *) input.cpuData; uint16_t *weightData = (uint16_t *) weight.cpuData; float *outputData = (float *) output.cpuData; float *biasData = bias.dims.size() > 0 ? (float *) bias.cpuData : nullptr;
#ifdef __ARM_FEATURE_FP16_VECTOR_ARITHMETIC uint16_t *temp = new uint16_t[n * m]; for (int i = 0; i < n * m; i++) { temp[i] = float_to_half(inputData[i]); } inputData = (float*)temp;
#endif int threadNum = GetThreads(); int per = k / threadNum; int cur = 0; auto pool = GetPool(); std::vector <std::future <void> > futures; for (int i = 0; i < threadNum - 1; i++) { int end = cur + per + (cur + per * (threadNum - i) < k); futures.push_back(pool->Submit(Float16LinearPart, inputData, weightData, biasData, outputData, n, m, k, cur, end)); cur = end; } Float16LinearPart(inputData, weightData, biasData, outputData, n, m, k, cur, k); for (int i = 0; i < futures.size(); i++) { futures[i].get(); }
#ifdef __ARM_FEATURE_FP16_VECTOR_ARITHMETIC delete[] temp;
#endif } else if (weight.dataType == DataType::INT8) { // 这段代码处理权重数据类型为 INT8 的情况。 // 这段代码首先对输入、权重、输出和偏置数据的指针进行类型转换, // 并根据偏置数据的维度是否大于0来决定是否获取偏置数据的指针。然后,它计算了权重数据的总和。 float *inputData = (float *) input.cpuData; uint8_t *weightData = (uint8_t *) weight.cpuData; float *outputData = (float *) output.cpuData; float *biasData = bias.dims.size() > 0 ? (float *) bias.cpuData : nullptr; weight.CalcWeightSum(); // 之后,代码创建一个std::vector<LowBitConfig>对象, // LowBitConfig是一个用于存储数据量化信息的类,包括最小值、最大值、位宽和零点。 // 这些信息是通过遍历输入数据获得的。 std::vector <LowBitConfig> inputConfigs; for (int i = 0; i < n; i++) { float minValue = 1e9, maxValue = -1e9; for (int j = 0; j < m; j++) { minValue = std::min(minValue, inputData[i * m + j]); maxValue = std::max(maxValue, inputData[i * m + j]); } inputConfigs.push_back(LowBitConfig(minValue, maxValue, 8, 0)); } // 接着,创建一个std::vector<uint8_t>对象uinput,并将其大小设置为输入数据的大小(n * m)。 // uinput中的每个元素都是输入数据元素经过inputConfigs中对应配置信息量化后的结果。 // 注意这里的量化过程可能会根据是否定义了__AVX2__进行不同的处理。 std::vector <uint8_t> uinput; uinput.resize(n * m); for (int i = 0; i < n * m; i++) {
#ifdef __AVX2__ uinput[i] = inputConfigs[i / m].quantization(inputData[i]); uinput[i] = (uinput[i] + !uinput[i]) ^ 128;
#else uinput[i] = inputConfigs[i / m].quantization(inputData[i]);
#endif } // 随后,调用MultiplyMultiThread函数,使用多线程并行计算uinput和weightData的乘积, // 并将结果存储在outputData中。 MultiplyMultiThread(uinput.data(), weightData, (int32_t*)outputData, n, m, k, GetThreads()); // 这段代码的目的是把在使用INT8进行量化计算时由于量化造成的误差进行修正, // 使得结果更接近于使用浮点数进行计算的结果。也就是反量化过程。 for (int i = 0; i < n; i++) { // 这一步中,对于每一个输入向量(i从0到n),代码首先初始化inputSum为0, // 然后遍历输入向量的每个元素(j从0到m),将元素值加到inputSum上。 // 如果定义了__AVX2__,则在加到inputSum之前,元素值会先与128进行异或操作。 uint32_t inputSum = 0; for (int j = 0; j < m; j++) {
#ifdef __AVX2__ inputSum += uinput[i * m + j] ^ 128;
#else inputSum += uinput[i * m + j];
#endif } // 接下来,代码遍历每个输出元素(j从0到k),并按照以下步骤进行调整和缩放: for (int j = 0; j < k; j++) { // 首先,获取输出元素的原始值value。 int value = ((int32_t*)outputData)[i * k + j];
#ifdef __AVX2__ // 如果定义了__AVX2__,则value会增加128 * weight.weightSum[j]、 // 128 * inputSum,并减去m * 128 * 128。 value += (128 * weight.weightSum[j]); value += (128 * inputSum); value -= m * 128 * 128;
#endif value -= weight.weightSum[j] * inputConfigs[i].zeroPoint; value -= inputSum * weight.perChannelsConfigs[j].zeroPoint; value += (int)inputConfigs[i].zeroPoint * weight.perChannelsConfigs[j].zeroPoint * m; outputData[i * k + j] = weight.perChannelsConfigs[j].scale * inputConfigs[i].scale * value + (biasData == nullptr ? 0.0 : biasData[j]); } } } else if (weight.dataType == DataType::INT4 || weight.dataType == DataType::INT4_NOZERO) { float *inputData = (float *) input.cpuData; uint8_t *weightData = (uint8_t *) weight.cpuData; float *outputData = (float *) output.cpuData; float *biasData = bias.dims.size() > 0 ? (float *) bias.cpuData : nullptr; weight.CalcWeightSum(); std::vector <LowBitConfig> inputConfigs; for (int i = 0; i < n; i++) { float minValue = 1e9, maxValue = -1e9; for (int j = 0; j < m; j++) { minValue = std::min(minValue, inputData[i * m + j]); maxValue = std::max(maxValue, inputData[i * m + j]); } inputConfigs.push_back(LowBitConfig(minValue, maxValue, 8, 0)); } std::vector <uint8_t> uinput; uinput.resize(n * m); for (int i = 0; i < n * m; i++) { uinput[i] = inputConfigs[i / m].quantization(inputData[i]); }
#ifdef __AVX__ uint8_t *temp = new uint8_t[32]; for (int i = 0; i < n; i++) { for (int j = 0; j + 31 < m; j += 32) { memcpy(temp, uinput.data() + i * m + j, 32); for (int k = 0; k < 16; k++) { uinput[i * m + j + k] = temp[k * 2 + 1]; uinput[i * m + j + k + 16] = temp[k * 2]; } } } delete[] temp;
#endif if (weight.dataType == DataType::INT4) { MultiplyInt4MultiThread(uinput.data(), weightData, (int32_t *) outputData, n, m, k, weight.weightSum.data(), weight.zeros.data(), weight.scales.data(), biasData, inputConfigs, GetThreads()); } else { MultiplyInt4NoZeroMultiThread(uinput.data(), weightData, (int32_t *) outputData, n, m, k, weight.weightSum.data(), weight.mins.data(), weight.scales.data(), biasData, inputConfigs, GetThreads()); } } else { ErrorInFastLLM("Linear error: unsupport weight's dataType.\n"); }
//float spend = GetSpan(st, std::chrono::system_clock::now());
//float gops = (float)n * m * k / spend / 1e9;
// printf("n = %d, m = %d, k = %d, spend %f s, gops = %f\n", n, m, k, spend, gops); }在上面的实现中,MultiplyMultiThread完成了对量化输入的计算,我们看一下它的实现细节:
//a = [n, m], b = [k, m], c = aT(b') = [n, k] void MultiplyMultiThread(uint8_t *a, uint8_t *b, int32_t *c, int n, int m, int k, int threadNum) { int per = k / threadNum; int cur = 0; if (threadNum == 1) { Multiply(a, b + cur * m, c + cur, n, m, k - cur, k); } else { auto pool = GetPool(); std::vector<std::future<void> > futures; for (int i = 0; i < threadNum; i++) { int end = cur + per + (cur + per * (threadNum - i) < k); if (i == threadNum - 1) { end = k; } futures.push_back(pool->Submit(Multiply, a, b + cur * m, c + cur, n, m, end - cur, k)); cur = end; } for (int i = 0; i < futures.size(); i++) { futures[i].get(); } } }可以看到这段代码仍然是在用线程池来启动多个线程完成计算,核心部分是Multiply函数,这个函数的实现细节:
//a = [n, m], b = [k, m], c = aT(b') = [n, k] void Multiply(uint8_t *a, uint8_t *b, int32_t *c, int n, int m, int k, int kstride) {
#ifdef __ARM_FEATURE_DOTPROD int block = 0; for (; block < n; block++) { uint8_t *weightWalk = b; uint8_t *inputStart = a + block * m; for (int i = 0; i < k; i++) { int value = 0; uint8_t *inputWalk = inputStart; int j = 0; uint32x4_t sum0 = {0, 0, 0, 0}; for (; j + 31 < m; j += 32) { uint8x16_t vi = vld1q_u8(inputWalk); uint8x16_t vi0 = vld1q_u8(inputWalk + 16); uint8x16_t vw = vld1q_u8(weightWalk); uint8x16_t vw0 = vld1q_u8(weightWalk + 16); sum0 = vdotq_u32(sum0, vi, vw); sum0 = vdotq_u32(sum0, vi0, vw0); inputWalk += 32; weightWalk += 32; } value += sum0[0] + sum0[1] + sum0[2] + sum0[3]; for (; j < m; j++) { value += (int)(*(weightWalk++)) * (*(inputWalk++)); } c[block * kstride + i] = value; } }
#elif defined(__aarch64__) int block = 0; for (; block < n; block++) { uint8_t *weightWalk = b; uint8_t *inputStart = a + block * m; for (int i = 0; i < k; i++) { int value = 0; uint8_t *inputWalk = inputStart; int per = 64; int cnt = m / per; int sur = m % per; uint32x4_t sum = {0}; uint16x8_t temp = {0}; uint16x8_t temp1 = {0}; uint16x8_t temp2 = {0}; uint16x8_t temp3 = {0}; uint16x8_t temp4 = {0}; uint16x8_t temp5 = {0}; uint16x8_t temp6 = {0}; uint16x8_t temp7 = {0}; while (cnt--) { temp = vmull_u8(vld1_u8(inputWalk), vld1_u8(weightWalk)); temp1 = vmull_u8(vld1_u8(inputWalk + 8), vld1_u8(weightWalk + 8)); temp2 = vmull_u8(vld1_u8(inputWalk + 16), vld1_u8(weightWalk + 16)); temp3 = vmull_u8(vld1_u8(inputWalk + 24), vld1_u8(weightWalk + 24)); temp4 = vmull_u8(vld1_u8(inputWalk + 32), vld1_u8(weightWalk + 32)); temp5 = vmull_u8(vld1_u8(inputWalk + 40), vld1_u8(weightWalk + 40)); temp6 = vmull_u8(vld1_u8(inputWalk + 48), vld1_u8(weightWalk + 48)); temp7 = vmull_u8(vld1_u8(inputWalk + 56), vld1_u8(weightWalk + 56)); sum = vpadalq_u16(sum, temp); sum = vpadalq_u16(sum, temp1); sum = vpadalq_u16(sum, temp2); sum = vpadalq_u16(sum, temp3); sum = vpadalq_u16(sum, temp4); sum = vpadalq_u16(sum, temp5); sum = vpadalq_u16(sum, temp6); sum = vpadalq_u16(sum, temp7); inputWalk += per; weightWalk += per; } value += (sum[0] + sum[1] + sum[2] + sum[3]); while (sur--) { value += (int)(*(weightWalk++)) * (*(inputWalk++)); } c[block * kstride + i] = value; } }
#elif defined(__AVX__) int block = 0; for (; block < n; block++) { uint8_t *weightWalk = b; uint8_t *inputStart = a + block * m; for (int i = 0; i < k; i++) { uint8_t *inputWalk = inputStart; c[block * kstride + i] = DotU8U8(inputWalk, weightWalk, m); weightWalk += m; } }
#else int block = 0; for (; block < n; block++) { uint8_t *weightWalk = b; uint8_t *inputStart = a + block * m; for (int i = 0; i < k; i++) { int value = 0; uint8_t *inputWalk = inputStart; for (int j = 0; j < m; j++) { value += (int)(*(weightWalk++)) * (*(inputWalk++)); } c[block * kstride + i] = value; } }
#endif }这段代码实现了两个矩阵的乘法。输入的两个矩阵是 (a) 和 (b),结果矩阵是 (c)。矩阵 (a) 的形状是 ([n, m]),矩阵 (b) 的形状是 ([k, m]),所以矩阵 (c = a^T b) 的形状是 ([n, k])。
在这段代码中,使用了不同的方法进行矩阵乘法,取决于系统是否支持特定的优化硬件指令。
- 如果系统支持 ARMv8.2 的点积指令(
__ARM_FEATURE_DOTPROD),那么会使用这个指令进行矩阵乘法。在这种情况下,每次会同时处理32个元素,这样可以加速计算。 - 如果系统支持 ARMv8(
__aarch64__),但不支持 ARMv8.2 的点积指令,那么会使用 NEON SIMD 指令进行矩阵乘法。在这种情况下,每次会同时处理64个元素。 - 如果系统支持 AVX(
__AVX__),那么会使用 AVX 指令进行矩阵乘法。在这种情况下,会使用 DotU8U8 函数来计算向量的点积。 - 如果系统不支持上述任何一种优化指令,那么会使用基础的方法进行矩阵乘法。在这种情况下,每次只处理一个元素。
这段代码的优化部分主要利用了 SIMD(单指令多数据)的并行化特性,通过同时处理多个元素来加速计算。而选择使用哪种优化方法,取决于系统支持哪种硬件指令。
CPU后端的算子解析就暂时讲到这里,我们发现CPU的算子实现不仅考虑了Intel CPU也考虑了Arm端的优化,这也是FastLLM可以在Arm边缘端部署大模型的原因。
GPU后端算子实现
GPU后端算子实现在 https://github.com/ztxz16/fastllm/blob/master/src/devices/cuda/cudadevice.cpp 和 https://github.com/ztxz16/fastllm/blob/master/src/devices/cuda/fastllm-cuda.cu 。我们还是挑几个算子来讲解。
CudaLlamaRotatePosition2DOp
LLama的ROPE实现在:https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py#L92-L126 。
# 这个类是用来创建旋转位置编码(Rotary Position Embedding)的。
# Llama模型引入了旋转位置编码,以改进长序列处理的性能。
class LlamaRotaryEmbedding(torch.nn.Module): # 这是类的初始化方法,接收四个参数:dim(嵌入的维度),max_position_embeddings # (最大的位置嵌入长度,默认为2048),base(基数,默认为10000)和device(设备类型,例如CPU或GPU)。 def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None): super().__init__() self.dim = dim # 将输入的dim参数保存到self.dim属性中。 # # 将输入的max_position_embeddings参数保存到self.max_position_embeddings属性中。 self.max_position_embeddings = max_position_embeddings # 将输入的base参数保存到self.base属性中。 self.base = base # 计算逆频率并保存到变量inv_freq中。逆频率是一种用于位置编码的技巧, # 它可以帮助模型更好地捕捉位置信息。 inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim)) # 将inv_freq保存到模型的缓存中。register_buffer是PyTorch nn.Module的一个方法, # 它用于保存一些不需要计算梯度的变量。 self.register_buffer("inv_freq", inv_freq, persistent=False) # Build here to make `torch.jit.trace` work. # 调用_set_cos_sin_cache方法,预先计算并保存正弦和余弦的缓存值。 self._set_cos_sin_cache( seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype() ) # 这是一个私有方法,接收三个参数:seq_len(序列长度),device(设备类型)和dtype(数据类型) def _set_cos_sin_cache(self, seq_len, device, dtype): # 将输入的seq_len参数保存到self.max_seq_len_cached属性中。 self.max_seq_len_cached = seq_len # 生成一个长度为max_seq_len_cached的序列,并保存到变量t中。 t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype) # 使用外积计算频率和t的乘积,结果保存到变量freqs中。 freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation in order to obtain the same calculation # 将频率的两份副本拼接在一起,结果保存到变量emb中。 emb = torch.cat((freqs, freqs), dim=-1) # 计算emb的余弦值,然后将结果保存到模型的缓存中。 self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False) # 计算emb的正弦值,然后将结果保存到模型的缓存中。 self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False) # 这是模型的前向传播方法,接收两个参数:x(输入数据)和seq_len(序列长度)。 def forward(self, x, seq_len=None): # x: [bs, num_attention_heads, seq_len, head_size] # 如果输入的序列长度大于缓存的最大序列长度,那么调用_set_cos_sin_cache方法,更新缓存。 if seq_len > self.max_seq_len_cached: self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype) # 返回对应输入位置的正弦和余弦值。这些值将用于旋转位置编码。 return ( self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype), self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype), ) def apply_rotary_pos_emb(q, k, cos, sin, position_ids): # The first two dimensions of cos and sin are always 1, so we can `squeeze` them. cos = cos.squeeze(1).squeeze(0) # [seq_len, dim] sin = sin.squeeze(1).squeeze(0) # [seq_len, dim] cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim] sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim] q_embed = (q * cos) + (rotate_half(q) * sin) k_embed = (k * cos) + (rotate_half(k) * sin) return q_embed, k_embedCudaLlamaRotatePosition2DOp对应的就是上面的Python代码。
void CudaLlamaRotatePosition2DOp::Run(const std::string &opType, const fastllm::DataDict &datas, const fastllm::FloatDict &floatParams, const fastllm::IntDict &intParams) { Data &data = *(datas.find("input")->second); Data &positionIds = *(datas.find("positionIds")->second); Data &sinData = *(datas.find("sin")->second); Data &cosData = *(datas.find("cos")->second); int rotaryDim = intParams.find("rotaryDim") != intParams.end() ? intParams.find("rotaryDim")->second : 128; FastllmCudaLlamaRotatePosition2D(data, positionIds, sinData, cosData, rotaryDim); }这里调用的是FastllmCudaLlamaRotatePosition2D这个函数,它的实现和解析如下:
// 这是一个在 GPU 上运行的 CUDA 函数,用于执行 Llama 模型的位置编码旋转操作。
// data:输入的数据,这个数据将会被旋转。
// positionIds:位置编码的数据。
// sinData,cosData:用于旋转的 sin 和 cos 值。
// rotaryDim:旋转的维度。
bool FastllmCudaLlamaRotatePosition2D(fastllm::Data &data, const fastllm::Data &positionIds, const fastllm::Data &sinData, const fastllm::Data &cosData, int rotaryDim) { // 使用 FastllmCudaPrepareInput 函数将输入的数据从 CPU 复制到 GPU。 // 这个函数会返回一个指向 GPU 内存的指针。 float *cudaData = (float *) FastllmCudaPrepareInput(data); float *cudaPositionIds = (float *) FastllmCudaPrepareInput(positionIds); float *cudaSin = (float *) FastllmCudaPrepareInput(sinData); float *cudaCos = (float *) FastllmCudaPrepareInput(cosData); // 计算旋转操作需要的一些参数,包括 outer,spatial,bs,len,n 和 m。 // 这些参数是用于确定 CUDA 核函数的执行配置和一些数据操作的。 int outer = data.dims[0] * data.dims[1]; int spatial = data.Count(2); int bs = data.dims[0], len = data.dims[1]; int n = data.dims[2], m = data.dims[3]; // 调用 CUDA 核函数 FastllmLlamaRotatePosition2DKernel 来在 GPU 上执行位置编码的旋转操作。 // <<<outer * n, min(rotaryDim, m / 2)>>> 是 CUDA 中定义并行线程块和线程的语法, // outer * n 是线程块的数量,min(rotaryDim, m / 2) 是每个线程块中的线程数量。 // 核函数的参数包括之前准备的数据和一些计算参数。 FastllmLlamaRotatePosition2DKernel <<< outer * n, min(rotaryDim, m / 2) >>> (cudaData, cudaPositionIds, cudaSin, cudaCos, len, bs, spatial, n, m, (int)positionIds.dims.back(), (int)sinData.dims[1], rotaryDim); // 使用 FastllmCudaFinishInput 函数释放 positionIds,sinData 和 cosData 在 GPU 上的内存。 // 这些数据在这个函数中不再需要。 FastllmCudaFinishInput(positionIds, cudaPositionIds); FastllmCudaFinishInput(sinData, cudaSin); FastllmCudaFinishInput(cosData, cudaCos); // 使用 FastllmCudaFinishOutput 函数将旋转后的数据从 GPU 复制回 CPU。 // 这个函数也会释放 data 在 GPU 上的内存。 FastllmCudaFinishOutput(data, cudaData); return true;
}最后再解析下这个cuda kernel。
// float *data:输入数据,大小为 [bs, len, n, m],其中 bs 是批量大小,
// len 是序列长度,n 是头的数量,m 是每个头的维度。
// float *positionIds:位置编码的索引,大小为 [bs, len]。
// float *sin 和 float *cos:预先计算的正弦和余弦值,用于旋转编码。
// int len, int bs, int spatial, int n, int m:输入数据的各个维度大小。
// int partStride 和 int sinCosStride:用于索引 positionIds 和 sin/cos 的步长。
// int rotateDim:旋转维度。
__global__ void FastllmLlamaRotatePosition2DKernel(float *data, float *positionIds, float *sin, float *cos, int len, int bs, int spatial, int n, int m, int partStride, int sinCosStride, int rotateDim) { // 首先,计算出当前线程应处理的位置 o,长度 l 和批次 b。 int o = (blockIdx.x / n); int l = o % len; int b = o / len; int j = threadIdx.x; // 然后,根据 positionIds 获取对应的旋转角度的正弦值 curSin 和余弦值 curCos。 int index = (int) (positionIds[b * partStride + l]); float curSin = sin[index * sinCosStride + j]; float curCos = cos[index * sinCosStride + j]; float *d = (float *) data + o * spatial + j; int i = blockIdx.x % n; // 接着,获取输入数据对应位置的值 va 和 vb。 float va = d[i * m], vb = d[i * m + m / 2]; // 最后,根据旋转矩阵的公式,计算旋转后的值,并将结果写回输入数据中。 d[i * m] = va * curCos - vb * curSin; d[i * m + m / 2] = va * curSin + vb * curCos;
}直接看这个cuda kernel可能比较难理解,可以结合https://github.com/ztxz16/fastllm/blob/master/src/devices/cpu/cpudevice.cpp#L2204-L2233 这里的cpu实现来看,这样来看设置batch * seq_length * n个block,每个block处理m个元素就是比较合理直观的。
void CpuLlamaRotatePosition2DOp::Run(const std::string &opType, const fastllm::DataDict &datas, const fastllm::FloatDict &floatParams, const fastllm::IntDict &intParams) { Data &data = *(datas.find("input")->second); Data &positionIds = *(datas.find("positionIds")->second); Data &sinData = *(datas.find("sin")->second); Data &cosData = *(datas.find("cos")->second); int rotaryDim = intParams.find("rotaryDim") != intParams.end() ? intParams.find("rotaryDim")->second : 128; int bs = data.dims[0], len = data.dims[1]; int spatial = data.Count(2); int n = data.dims[2], m = data.dims[3]; int stride = (int)sinData.dims[1]; for (int b = 0; b < bs; b++) { for (int l = 0; l < len; l++) { int index = (int) ((float *) positionIds.cpuData)[b * positionIds.dims.back() + l]; float *sin = ((float *) sinData.cpuData) + stride * index; float *cos = ((float *) cosData.cpuData) + stride * index; float *d = (float *) data.cpuData + (b * len + l) * spatial; for (int i = 0; i < n; i++) { for (int j = 0; j < rotaryDim && j < m / 2; j++) { float a = d[j], b = d[j + m / 2]; d[j] = a * cos[j] - b * sin[j]; d[j + m / 2] = a * sin[j] + b * cos[j]; } d += m; } } } }FastLLM在cuda上的实现不算高校,不过优点在于它支持了完整的int8和int4量化的计算,有兴趣的读者可以自行研究这部分kernel实现。
LLMSamping解析
在 chatglm-6b 的实现中,在前向推理完成后以及tokenizer解码之前有一个根据logits取label的过程:https://github.com/ztxz16/fastllm/blob/master/src/models/chatglm.cpp#L267-L279 。
if (generationConfig.IsSimpleGreedy()) { // 对 logits 进行 TopK 操作,将结果存储在 topk 中。 // 这里的 TopK 操作是找到 logits 中最大的 K 个值,这里 K=1,所以是找到最大值。 TopK(logits, topk, 1); topk.ToDevice(DataDevice::CPU); for (int b = 0; b < batch; b++) { int base = (maxLen - 1) * batch + b; // 计算基础索引值 base。 // 将 topk 中对应索引的值取整并添加到 lastRet 中。 lastRet.push_back((int) (((float *) topk.cpuData)[base * 2] + 1e-3)); } } else { for (int b = 0; b < batch; b++) { int base = (maxLen - 1) * batch + b; // 计算基础索引值 base。 // 使用 LLMSampling 方法进行抽样,将结果添加到 lastRet 中。 lastRet.push_back(LLMSampling(logits, base, generationConfig, lastTokens.units[b])); } }LLMSampling是一种常见的在序列生成任务中,根据不同的需求,使用不同的策略生成序列的方法。我们这里来研究一下它的实现。它的实现在:https://github.com/ztxz16/fastllm/blob/master/src/fastllm.cpp#L874-L916 。
// 这段代码是一个用于从给定的 logits(通常表示预测的概率分布)进行采样的函数,
// 采样策略主要受 GenerationConfig 和 LastTokensUnit 参数的影响。
int LLMSampling(Data &logits, int outerOffset, const GenerationConfig &config, const LastTokensUnit &tokens) { // 将 logits 数据从当前设备转移到 CPU。 logits.ToDevice(DataDevice::CPU); // 从 logits 的维度中获取词汇量 vocabSize。 int vocabSize = logits.dims.back(); // 计算 base 指针,指向要处理的 logits 的开始位置。 float *base = ((float*)logits.cpuData) + outerOffset * vocabSize; // 判断 config.repeat_penalty 是否不等于1,如果不等于1, // 则对 tokens.tokenSet 中每个 id 对应的 base[id] 值进行修改。 if (fabs(config.repeat_penalty - 1.0) > 1e-6) { for (int id : tokens.tokenSet) { base[id] = (base[id] < 0 ? base[id] * config.repeat_penalty : base[id] / config.repeat_penalty); } } // 计算温度的倒数 invTemp。 float invTemp = 1.0f / config.temperature; // 定义一个向量 v,用于存储 <logit值,索引>。 std::vector <std::pair <float, int> > v; // 遍历每个 logit,将其值乘以 invTemp,并存入 v 中。 for (int i = 0; i < vocabSize; i++) { v.push_back(std::make_pair(-base[i] * invTemp, i)); } // 计算 topk,它是词汇量 vocabSize 和 config.top_k 中的较小值。 int topk = std::min(vocabSize, config.top_k); // 对 v 中的前 topk 个元素进行排序。 std::partial_sort(v.begin(), v.begin() + topk, v.end()); // 初始化 psum 和 maxValue,maxValue 是 v 中最大的元素。 float psum = 0.0, maxValue = -v.begin()->first; // 定义一个向量 ps,用于存储处理后的概率。 std::vector <float> ps; // 遍历 v 中的前 topk 个元素,将其值取 exp 并减去 maxValue,存入 ps,同时更新 psum。 for (int i = 0; i < topk; i++) { ps.push_back(expf(-v[i].first - maxValue)); psum += ps.back(); } float curSum = 0.0; // 遍历 ps,将其每个元素除以 psum 并更新 curSum, // 当 curSum 大于 config.top_p 时,更新 topk 并退出循环。 for (int i = 0; i < topk; i++) { ps[i] /= psum; curSum += ps[i]; if (curSum > config.top_p) { topk = i + 1; break; } } // 生成一个随机数 rnd。 float rnd = fastllmRandom.randP(); curSum = 0.0; // 遍历 ps 中的前 topk 个元素,将其累加到 curSum, // 当 curSum 大于 rnd 或者达到最后一个元素时, // 返回对应 v[i].second,也就是返回采样得到的 id。 for (int i = 0; i < topk; i++) { curSum += ps[i]; if (curSum > rnd || i == topk - 1) { return v[i].second; } } // 如果以上步骤都没有返回,那么返回 -1。 return -1; }LLMSampling实现了一种基于温度和惩罚的采样策略,用于从给定的 logits 中选择一个 id。这种采样的方法可以控制输出文本的多样性。
#ChartLlama
在图像理解领域,多模态大模型已经充分展示了其卓越的性能。然而,对于工作中经常需要处理的图表理解与生成任务,现有的多模态模型仍有进步的空间。
尽管当前图表理解领域中的最先进模型在简单测试集上表现出色,但由于缺乏语言理解和输出能力,它们无法胜任更为复杂的问答任务。另一方面,基于大语言模型训练的多模态大模型的表现也不尽如人意,主要是由于它们缺乏针对图表的训练样本。这些问题严重制约了多模态模型在图表理解与生成任务上持续进步。
近期,腾讯联合南洋理工大学、东南大学提出了 ChartLlama。研究团队创建了一个高质量图表数据集,并训练了一个专注于图表理解和生成任务的多模态大型语言模型。ChartLlama 结合了语言处理与图表生成等多重性能,为科研工作者和相关专业人员提供了一个强大的研究工具。
论文地址:https://arxiv.org/abs/2311.16483
主页地址:https://tingxueronghua.github.io/ChartLlama/
ChartLlama 的团队构思出了一种巧妙的多元化数据收集策略,通过 GPT-4 生成特定主题、分布和趋势的数据,来确保数据集的多样性。研究团队综合开源的绘图库与 GPT-4 的编程能力,来编写图表代码,生成精确的图形化数据表示。此外,研究团队还运用 GPT-4 描述图表内容和生成问答对,为每个图表生成了丰富多样的训练样本,以确保经过训练的模型能够充分的理解图表。
图表理解领域中,传统模型仅能实现诸如读取图表中的数字这种简单的 QA 任务,无法对较复杂的问题进行回答。具体来说,它们难以跟随较长的指令,在涉及数学运算的问答中,也经常出现运算错误,而 ChartLlama 可以有效的避免此类问题,具体对比如下所示:

在传统任务之外,研究团队也定义了若干新任务,其中有三个任务涉及到了图表生成,论文中给出了相关示例:
给定图表和指令,进行图表重建与图表编辑的示例
根据指令和原始数据,生成图表的示例
在各种基准数据集上,ChartLlama 都达到了 SOTA 水平,需要的训练数据量也更少。其灵活的数据生成与收集方法,极大地拓宽了图表理解与生成任务中图表和任务的种类,推动了该领域的发展。
方法概述
ChartLlama 设计了一种灵活的数据收集方法,利用 GPT-4 的强大语言能力和编程能力,创建了丰富的多模态图表数据集。

ChartLlama 的数据收集包括三个主要阶段:
- 图表数据生成:ChartLlama 不仅从传统数据源收集数据,还利用 GPT-4 的能力产生合成数据。通过提供特定的特征,如主题、分布和趋势,从而引导 GPT-4 产生多样化和平衡的图表数据。由于生成的数据包含了已知的数据分布特性,这使得指令数据的构建更加灵活和多样。
- 图表生成:接着,利用 GPT-4 强大的编程能力,使用开源库(如 Matplotlib)根据已生成的数据和函数文档来编写图表绘制脚本,生成了一系列精心渲染的图表。由于图表的绘制完全是基于开源工具,这种算法可以生成更多类型的图表用于训练。对比已有数据集,例如 ChatQA,只支持三种图表类型, ChartLlama 所构建的数据集支持多达 10 种图表类型,而且可以任意扩展。
- 指令数据生成:除了图表渲染外,ChartLlama 还进一步利用 GPT-4 来描述图表内容,构造多种多样的问答数据,以确保训练过的模型能全面理解图表。这个全面的指令调整语料库,融合了叙述文本、问题 - 答案对以及图表的源代码或修改后的代码。过往的数据集只支持 1-3 种图表理解任务,而 ChartLlama 支持多达 10 种图表理解与生成任务,能够更好的帮助训练图文大模型理解图标中的信息。
经过以上步骤,ChartLlama 创建了包含多种任务和多种图表类型的数据集。其中不同类型的任务、图表在总数据集中的占比如下所示:
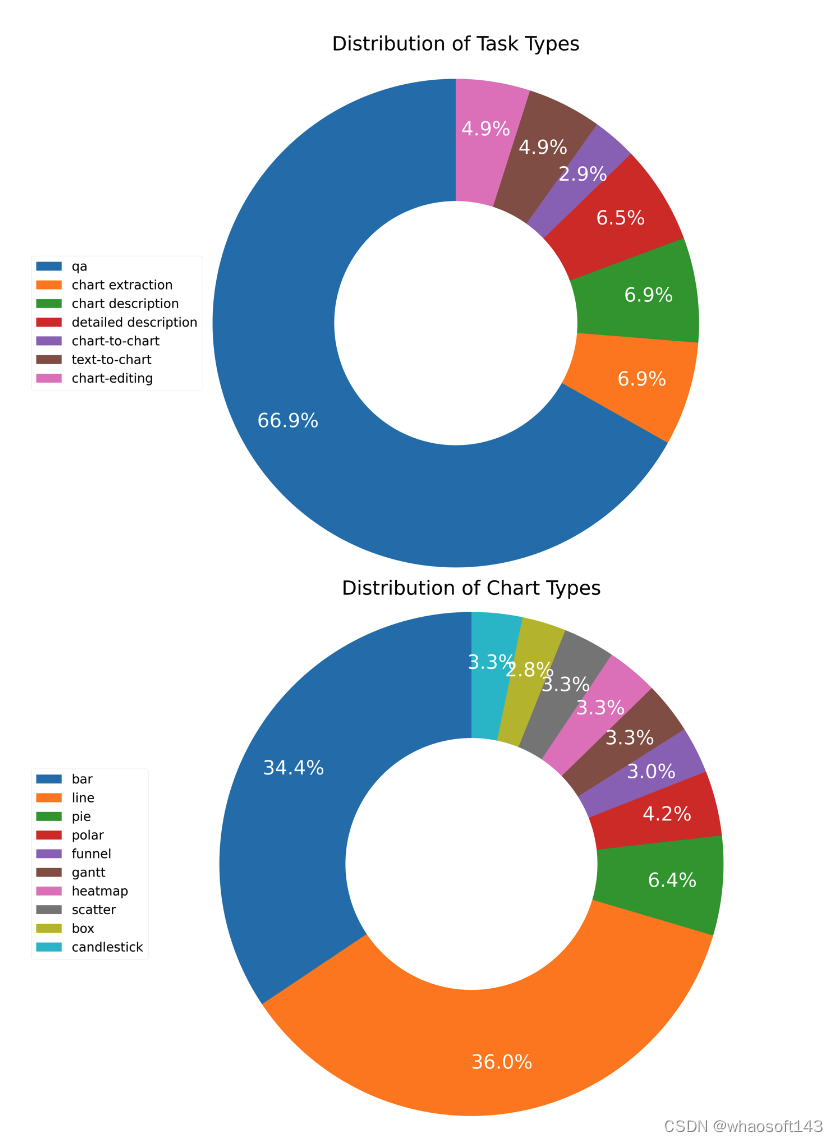
更详细的指令及其说明请参考论文原文。
实验结果
无论是传统任务还是新的任务,ChartLlama 都展现了最优越的性能。传统任务包括图表问答、图表总结,以及图表的结构化数据提取。对比 ChartLlama 和此前最先进的模型,结果如下图所示:

研究人员也评估了 ChartLlama 所独有的任务能力,包括图表代码生成,图表总结和图表编辑,同时也构造了对应任务的测试集,并与当前最强的开源图文大模型 LLaVA-1.5 进行了对比,结果如下所示:

研究团队还在类型各异的图表中测试了 ChartLlama 的问答准确率,和之前的 SOTA 模型 Unichart 以及提出的基线模型进行了对比,结果如下:
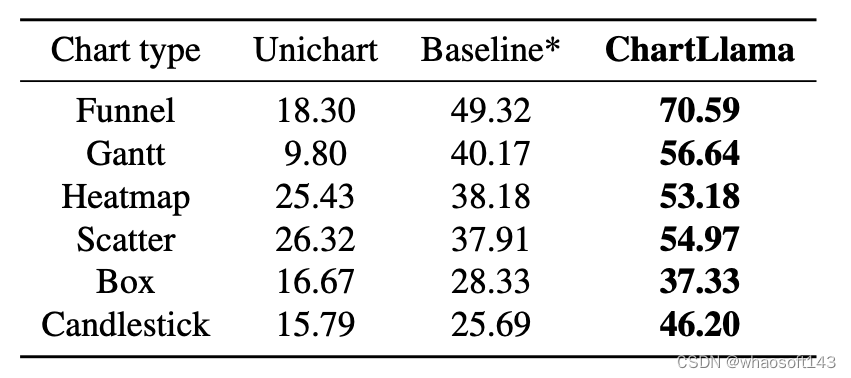
总的来说,ChartLlama 不仅推动了多模态学习的边界,也为图表的理解和生成提供了更精确和高效的工具。无论是在学术写作还是在企业演示中,ChartLlama 都将使图表的理解和创造变得更加直观和高效,在生成和解读复杂视觉数据方面迈出了重要的一步。
#ShareGPT4V
ShareGPT4V数据集包含120万条“图像-高度详细的文本描述”数据。这些数据囊括了了世界知识,对象属性,空间关系,艺术评价等众多方面,在多样性和信息涵盖度等方面超越了现有的数据。
Paper:https://arxiv.org/abs/2311.12793
Project Page:https://sharegpt4v.github.io/
Web Demo:https://huggingface.co/spaces/Lin-Chen/ShareGPT4V-7B
Code and Dataset:https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V
OpenAI在九月份为ChatGPT添加了图像输入功能,允许用户使用上传一张或多张图像配合进行对话。这一新兴功能的背后是一个被OpenAI称为GPT4-Vision的多模态(vision-language)大模型。鉴于OpenAI对“闭源”的坚持,多模态开源社区如雨后春笋般涌出了众多优秀的多模态大模型研究成果。例如两大代表作[MiniGPT4]和[LLaVA],像用户们展示了多模态对话和推理的无限可能性。
在多模态大模型(Large Multi-modal Models)领域,高效的模态对齐(modality alignment)是至关重要的,但现有工作中模态对齐的效果却往往受制于缺少大规模的高质量的“图像-文本”数据。为了解决这一瓶颈,近日,中科大和上海AI Lab的研究者们最近推出了具有开创性意义的大型图文数据集--ShareGPT4V数据集。ShareGPT4V数据集包含120万条“图像-高度详细的文本描述”数据。这些数据囊括了了世界知识,对象属性,空间关系,艺术评价等众多方面,在多样性和信息涵盖度等方面超越了现有的数据。

表 1 ShareGPT4V和主流标注数据集的比较。其中“LCS”指LAION, CC和SBU数据集,“Visible”指明了图片在被标注时是否可见,“Avg.”展示了文本描述的平均英文字符数。
数据
ShareGPT4V来源于从先进的GPT4-Vision模型获得的10万条“图像-高度详细的文本描述”数据。研究者们从多种图片数据源(如COCO,LAION,CC,SAM等)搜集图片数据,接着使用各自数据源特定的prompt来控制GPT4-Vision产生高质量的初始数据。如下图所示,给GPT4-Vision模型一张《超人》剧照,其不仅可以准确地识别出《超人》剧照中的超人角色以及其扮演者Henry Cavill,还可以充分分析出图像内物体间的位置关系以及物体的颜色属性等。如果给GPT4-Vision模型一个梵高的画作《播种者》,其不仅可以准确地识别出画作的名称,创作者,还可以分析出画作所属的艺术流派,画作内容,以及画作本身表达出的情感与想法等信息。

图 1 利用GPT4-Vision 收集ShareGPT4V原始数据流程图
为了更充分地与现有的图像描述数据集进行对比。我们在下图中将ShareGPT4V数据集中的高质量文本描述与当前多模态大模型所使用的数据集中的文本描述一起罗列出来:

图 2 “图片-文本描述“数据质量对比图
从图中可以看出,使用人工标注的COCO数据集虽然正确但通常十分的短,提供的信息极其有限。LLaVA数据集使用语言模型GPT4想象出的场景描述通常过度依赖bounding box而不可避免地带来幻觉问题。比如bounding box确实会提供8个人的标注,但其中两个人在火车上而不是在等车。其次,LLaVA数据集还只能局限于COCO的标注信息,通常会遗漏人工标注中没提及的内容(比如树木)。在比较之下,我们收集的图像描述不仅可以给出综合性的描述,还不容易遗漏图像中的重要信息(比如站台信息和告示牌文字等)。
通过在该初始数据上进行深入训练后,研究者们开发出了一个强大的图像描述模型Share-Captioner。利用这一模型,他们进一步生成了120万高质量的“图片-文本描述”数据ShareGPT4V-PT以用于预训练阶段。

图 3 图像描述模型扩大数据集规模流程图
Share-Captioner在图像描述能力上有着媲美GPT4-Vision的水平,下面是对于同一张图片的不同来源的文本描述:

图 4 不同来源图像描述对比图
从上图可以看出Share-Captioner缩小了与GPT4-Vision模型在图像描述任务上的能力。可以作为收集大规模高质量图文数据对的“平替”。
实验
研究者们首先通过等量替换实验,在有监督微调(SFT)阶段充分展示了ShareGPT4V数据集的有效性。从图中可以看出,ShareGPT4V数据集可以无缝地使得多种架构、多种参数规模的多模态模型的性能得到大幅提升!
图 5 使用ShareGPT4V数据集等量替换SFT中图像描述数据后模型效果对比图
接下来,研究者们将ShareGPT4V数据集同时在预训练和有监督微调阶段使用,得到了ShareGPT4V-7B模型。ShareGPT4V-7B在绝大多数多模态基准测试中都取得了非常优异的成果,在7B的模型规模全部取得了最优的性能!
图 6 ShareGPT4V-7B在各个多模态基准测试上的表现
总体而言,ShareGPT4V数据集的推出为未来的多模态研究与应用奠定了新的基石。多模态开源社区有望着眼于高质量图像描述开发出更强大、智能的多模态模型。
#GPT4Motion
扩散模型的出现推动了文本生成视频技术的发展,但这类方法的计算成本通常不菲,并且往往难以制作连贯的物体运动视频。
为了解决这些问题,来自中国科学院深圳先进技术研究院、中国科学院大学和 VIVO AI Lab 的研究者联合提出了一个无需训练的文本生成视频新框架 ——GPT4Motion。GPT4Motion 结合了 GPT 等大型语言模型的规划能力、Blender 软件提供的物理模拟能力,以及扩散模型的文生图能力,旨在大幅提升视频合成的质量。GPT-4+物理引擎加持扩散模型,生成视频逼真、连贯、合理
- 项目链接:https://gpt4motion.github.io/
- 论文链接:https://arxiv.org/pdf/2311.12631.pdf
- 代码链接:https://github.com/jiaxilv/GPT4Motion
具体来说,GPT4Motion 使用 GPT-4 基于用户输入的文本 prompt 生成 Blender 脚本,利用 Blender 内置的物理引擎来制作基本的场景组件,并封装成跨帧的连续运动,然后再将这些组件输入到扩散模型中,生成与文本 prompt 对齐的视频。
实验结果表明,GPT4Motion 可以在保持运动一致性和实体一致性的前提下高效生成高质量视频。值得注意的是,GPT4Motion 使用了物理引擎,这让其生成的视频更具真实性。GPT4Motion 为文本生成视频提供了新的见解。
我们先来看一下 GPT4Motion 的生成效果,例如输入文本 prompt:「一件白 T 恤在微风中飘动」、「一件白 T 恤在风中飘动」、「一件白 T 恤在大风中飘动」,风的强度不同,GPT4Motion 生成的视频中白 T 恤的飘动幅度就不同:

在液体流动形态方面,GPT4Motion 生成的视频也能够很好地表现出来:

方法介绍
该研究的目标是根据使用者对一些基本物理运动场景的 prompt,生成一个符合物理特性的视频。物理特性通常与物体的材料有关。研究者的重点在于模拟日常生活中常见的三种物体材料:1)刚性物体,在受力时能保持形状不发生变化;2)布料,其特点是柔软且易飘动;3)液体,表现出连续和可变形的运动。
此外,研究者还特别关注这些材料的几种典型运动模式,包括碰撞(物体之间的直接撞击)、风效应(气流引起的运动)和流动(连续且朝着一个方向移动)。模拟这些物理场景通常需要经典力学、流体力学和其他物理知识。目前专注于文本生成视频的扩散模型很难通过训练获取这些复杂的物理知识,因此无法制作出符合物理特性的视频。
GPT4Motion 的优势在于:确保生成的视频不仅与用户输入的 prompt 一致,而且在物理上也是正确的。GPT-4 的语义理解和代码生成能力可将用户 prompt 转化为 Blender 的 Python 脚本,该脚本可以驱动 Blender 的内置物理引擎来模拟相应的物理场景。并且,该研究还采用 ControlNet,将 Blender 模拟的动态结果作为输入,指导扩散模型逐帧生成视频。
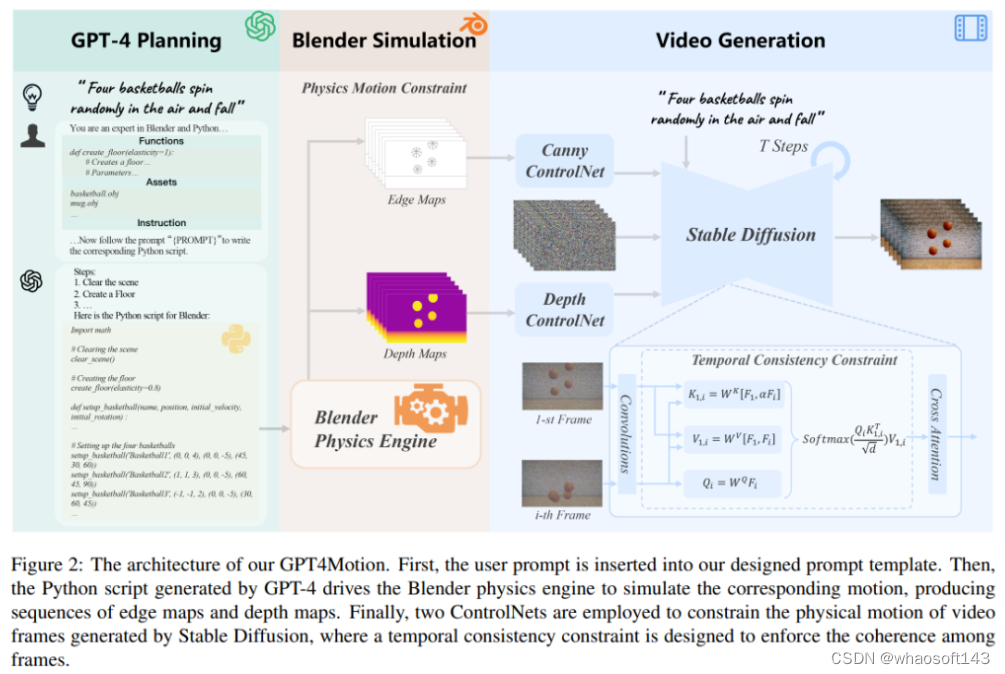
通过 GPT-4 触发 Blender 完成模拟
研究者观察到,虽然 GPT-4 对 Blender 的 Python API 有一定的了解,但它根据用户 prompt 生成 Blender 的 Python 脚本的能力仍然有所欠缺。一方面,要求 GPT-4 直接在 Blender 中创建哪怕是一个简单的 3D 模型(如篮球)似乎都是一项艰巨的任务。另一方面,由于 Blender 的 Python API 资源较少且 API 版本更新较快,GPT-4 很容易误用某些功能或因版本差异而出错。为了解决这些问题,该研究提出了以下方案:
- 使用外部 3D 模型
- 封装 Blender 函数
- 将用户 prompt 转化为物理特性
图 3 显示了该研究为 GPT-4 设计的通用 prompt 模板。它包括封装的 Blender 函数、外部工具和用户指令。研究者在模板中定义了虚拟世界的尺寸标准,并提供了有关摄像机位置和视角的信息。这些信息有助于 GPT-4 更好地理解三维空间的布局。之后基于用户输入的 prompt 生成相应的指令,引导 GPT-4 生成相应的 Blender Python 脚本。最后,通过该脚本,Blender 渲染出物体的边缘和深度,并以图像序列的形式输出。

生成符合物理规律的视频
该研究的目标是根据用户 prompt 和 Blender 提供的相应物理运动条件生成文字和视频内容一致,并且视觉效果逼真的视频。该研究采用扩散模型 XL(SDXL),一个扩散模型的升级版本,来完成生成任务,并且对 SDXL 做了以下修改:
- 物理运动约束
- 时间一致性约束
实验结果
控制物理特性
篮球的下落和碰撞。图 4 展示了 GPT4Motion 在三种 prompt 下生成的篮球运动视频。在图 4(左)中,篮球在旋转时保持了高度逼真的纹理,并准确复制了与地面碰撞后的弹跳行为。图 4(中)表明,此方法可以精确控制篮球的数量,并有效生成多个篮球落地时发生的碰撞和弹跳。令人惊喜的是,如图 4(右图)所示,当用户要求将篮球抛向摄像机时,GPT-4 会根据生成脚本中篮球的下落时间计算出必要的初速度,从而实现逼真的视觉效果。这表明,GPT4Motion 可以与 GPT-4 所掌握的物理知识相结合,从而控制生成的视频内容。

在风中飘动的布料。图 5 和图 6 验证了 GPT4Motion 在生成在风力影响下运动的布匹的能力。利用现有的物理引擎进行模拟,GPT4Motion 可生成不同风力下布的波动和波浪。在图 5 展示了一面飘动旗帜的生成结果。在不同风力下,旗帜呈现出复杂的波纹和波浪图案。图 6 显示了不规则布料物体 —— T 恤,在不同风力下的运动情况。受织物弹性和重量等物理特性的影响,T 恤发生了抖动和扭曲,并出现了明显的褶皱变化。


水倒入马克杯。图 7 展示了三段将不同粘度的水倒入马克杯的视频。当粘度较低时,流动的水与杯子中的水碰撞融合,在表面形成复杂的湍流。随着粘度的增加,水流变得缓慢,液体开始粘在一起。

与基线方法对比
图 1 展示了 GPT4Motion 与其他基线方法的直观对比。很明显,基线的结果与用户的 prompt 不符。DirecT2V 和 Text2Video-Zero 在纹理逼真度和动作一致性方面存在缺陷,而 AnimateDiff 和 ModelScope 虽然提高了视频的流畅度,但在纹理一致性和动作逼真度方面还有提升空间。与这些方法相比,GPT4Motion 可以在篮球下落和与地板碰撞后的弹跳过程中生成平滑的纹理变化,看起来更加逼真。

如图 8(第一行)所示,AnimateDiff 和 Text2Video-Zero 生成的视频在旗帜上出现了伪影 / 扭曲,而 ModelScope 和 DirecT2V 则无法平滑地生成旗帜在风中飘动的渐变。但是,如图 5 中间所示,GPT4Motion 生成的视频可以显示出旗帜在重力和风力作用下皱纹和波纹的连续变化。

如图 8(第 2 行)所示,所有基线的结果都与用户提示不符。虽然 AnimateDiff 和 ModelScope 的视频反映了水流的变化,但它们无法捕捉到水倒入杯子的物理效果。而由 Text2VideoZero 和 DirecT2V 生成的视频则创造了一个不断抖动的杯子。相比之下,如图 7(左)所示,GPT4Motion 生成的视频准确地描述了水流与马克杯碰撞时的激荡,效果更加逼真。
#GPT-4 Turbo
真如 Sam Altman 此前所言,OpenAI 首届开发者大会为人们带来了一些非常棒的新东西。OpenAI首个开发者日:自定义GPT、GPT商店太炸,还有模型更强更便宜了
继今年春天发布 GPT-4 之后,OpenAI 又创造了一个不眠夜。
过去一年,ChatGPT 绝对是整个科技领域最热的词汇。OpenAI 也依靠 ChatGPT 取得了惊人的成绩:总结来说,OpenAI 证实 ChatGPT 目前每周有超过 1 亿活跃用户,超过 200 万开者使用 API 等进行开发,与超过 92% 的财富 500 强公司合作。

作为备受期待的首届开发者大会,Sam Altman 在昨晚带来了一系列全新的 AI 模型和工具,包括如下:
- 全新的 GPT-4 Turbo 模型
- 更可控的输出:函数调用增强、JSON 模式
- 开放新的 API:DALLE-3、GPT-4 Turbo with vision、TTS 和 Whisper V3
- GPT-4 微调、自定义模型
- GPTs:创建自定义版本的 ChatGPT
- GPT Store 即将上线
- Assistants API:更接近 AI 智能体的体验
从这些更新的展示中可以明显感觉到,OpenAI 正在努力把 ChatGPT 构建成一个自动化程度更高的 AI 智能体,这个智能体不再是「纸上谈兵」,而是越来越多地通过操纵现有应用对物理世界产生影响。比如,在活动现场,一位 OpenAI 的工作人员通过语音与 ChatGPT 对话,给在场的每一位观众发放了 500 美元 OpenAI 代金券。
GPT-4 Turbo:128k 上下文、价格更便宜
会上首先亮相的是 GPT-4 的全新版本 GPT-4 Turbo。我们知道,OpenAI 在今年 3 月发布了 GPT-4 初始版本,并在 7 月广泛提供给了所有开发者。Sam Altman 在现场一一解析了 GPT-4 Turbo 的几大亮点。
首先,GPT-4 Turbo 比 GPT-4 更强大,支持 128k 上下文窗口,可以在单个 prompt 中处理超过 300 页的文本。更长的上下文意味着模型输出结果更加准确。
其次,GPT-4 Turbo 能够了解更近、更丰富的世界知识,外部文档和数据库的截止日期更新到了 2023 年 4 月。与之相比,GPT-4 的知识库截止日期为 2021 年 9 月。
接下来是函数调用更新。函数调用允许将应用程序函数或外部 API 描绘给模型,并让模型智能选择「包含调用这些函数的参数」的 JSON 对象。
今天,GPT-4 Turbo 在这方面做了几项改进,比如在一条消息中能够调用多个函数。用户可以在发送一条消息时请求多个操作,如「打开车窗并关闭空调」。此外函数调用的准确性也得到提升,GPT-4 Turbo 更有可能返回正确的函数参数。

与此同时,指令遵循性能得到提升并支持了 JSON 模式。其中在需要严格指令遵循的任务上,GPT-4 Turbo 的表现比以往的模型更好,比如生成特定格式(始终以 XML 来响应)。
GPT-4 Turbo 支持了新的 JSON 模式,确保模型使用有效的 JSON 进行响应。新的 API 参数 response_format 限制模型输出以生成语法正确的 JSON 对象。该模式对开发者在聊天完成(Chat Completions)API 中生成 JSON 非常有用。

多模态能力也是大会的重点内容,为此 OpenAI 开放了全新的 API。
GPT-4 Turbo 集成了 DALL·E 3,能够接受并处理图像输入(即 GPT-4 Turbo with vision),生成标题、分析现实世界的图像、阅读带图表的文档等。
对于 GPT-4 Turbo with vision,开发者可以通过 API 中的 gpt-4-vision-preview 来访问。OpenAI 计划为主要的 GPT-4 Turbo 模型提供视觉支持,价格取决于输入图像的大小,例如像素 1080×1080 的图像需要的成本为 0.00765 美元。
已经有开发者上手试用,效果不错。图源:https://x.com/_nateraw/status/1721661738956058925?s=20
同样地,开发者可以通过图像 API 将 DALL・E 3 直接集成到他们的应用程序和产品中。与之前版本的 DALL・E 类似,该 API 内置审核功能,可以帮助开发者保护自己的应用程序免遭滥用。OpenAI 提供了不同的格式和质量选项,生成一张图像的起价为 0.04 美元。
在文本转换语音领域,开发者现在可通过文本到语音(text-to-speech)API,将文本转化为人类质量的语音。全新 TTS 模型提供了 6 种预设声音和两种模型变体即 tts-1 和 tts-1-hd,其中 tts 针对实时用例进行优化,tts-1-hd 针对质量进行优化。每输入 1000 字符的起价为 0.015 美元。
有了新版本 GPT-4 Turbo,OpenAI 也没有「忘了」GPT-4。
现在,GPT-4 微调正在实验访问阶段。OpenAI 正在创建一个用于 GPT-4 微调的实验性访问程序。不过与 GPT-3.5 微调获得的实质收益相比,GPT-4 微调需要更多工作才能对基础模型实现有意义的改进。
未来,随着 GPT-4 微调在质量和安全性方面得到提升,GPT-3.5 微调的活跃使用者可以选择在他们的微调控制中心应用 GPT-4 程序。
在微调之外,对于那些需要更多定制化功能的组织机构,OpenAI 启动了自定义模型(Custom Models)计划,允许组织机构与 OpenAI 研究人员一起针对特定领域来训练定制化 GPT-4。这包括修改模型训练过程的每一步,从额外的领域特定预训练到运行针对特定领域的定制化 RL 训练后(post-training)过程。
组织机构对其定制化模型拥有独家访问权。OpenAI 不会提供给其他客户或与其他客户共享,也不会用于训练其他模型。此外提供给 OpenAI 以训练定制化模型的专有数据不会在其他上下文中重复使用。不过,OpenAI 表示,目前自定义模型的功能有限且成本高昂。
最后是价格。如你我所见,GPT-4 Turbo 性能更强了,但价格却被打下来了。对比 GPT-4,GPT-4 Turbo 的输入 token 价格是其 1/3,为 0.01 美元 / 1000token;输出 token 价格是其 1/2,为 0.03 美元 / 1000token。
同样地,GPT-3.5 Turbo 16K 以及 GPT-3.5 Turbo 4K、16K 微调的价格也都有一定程度的下降,具体参见下图。

目前如何使用 GPT-4 Turbo 呢?
所有付费开发者都可以通过 API 中的 gpt-4-1106-preview 来试用 GPT-4 Turbo。未来几周,OpenAI 将发布稳定的生产就绪(production-ready)模型。
GPTs 与 GPT 商店
新模型的发布令人激动。但接下来这一发布,可能会令你联想到十几年前苹果的发布会,这也是众多网友认为的最大亮点。
Sam Atlman 发布了 GPTs,让用户们无需代码,结合自己的指令、外部知识和能力创建自定义版本的 ChatGPT。
自从推出 ChatGPT 以来,用户们一直期待能够定制 ChatGPT。OpenAI 在 7 月推出了自定义指令,可让用户设置一些首选项,但这无法完全满足用户。许多高级用户会维护一份提示和指令集列表,并将它们手动复制到 ChatGPT 中。GPTs 的发布能够自动帮用户们完成这项工作了。

从现场展示来看,为了创建一个 GPT,OpenAI 允许用户使用一个名为 GPT Builder 的对话式 AI 模型,让用户使用自然语言就能构建自定义的 GPT。
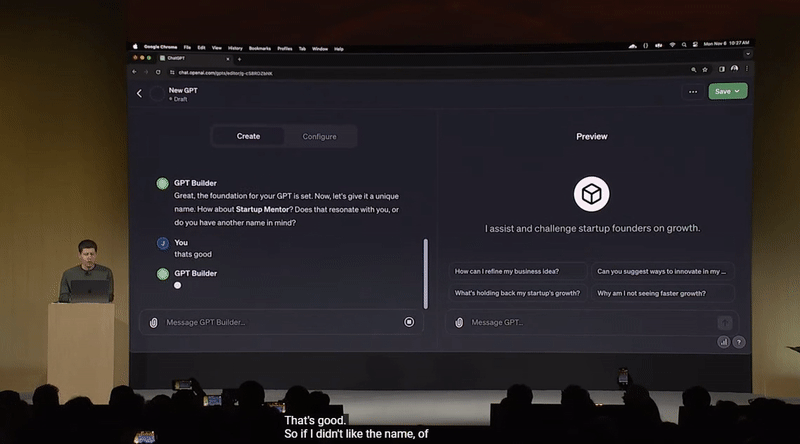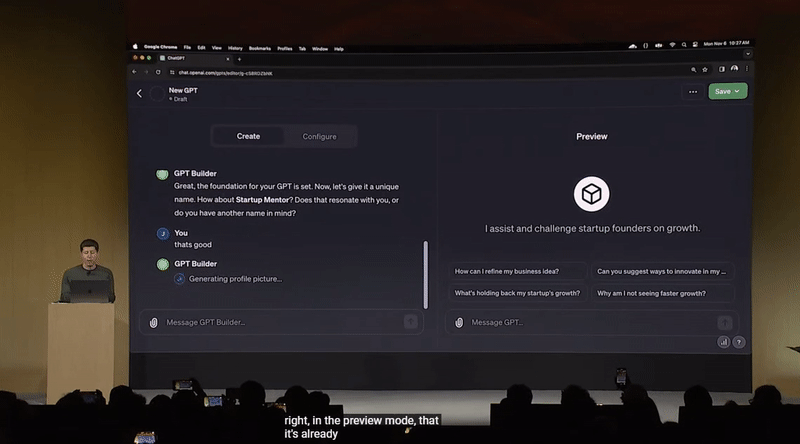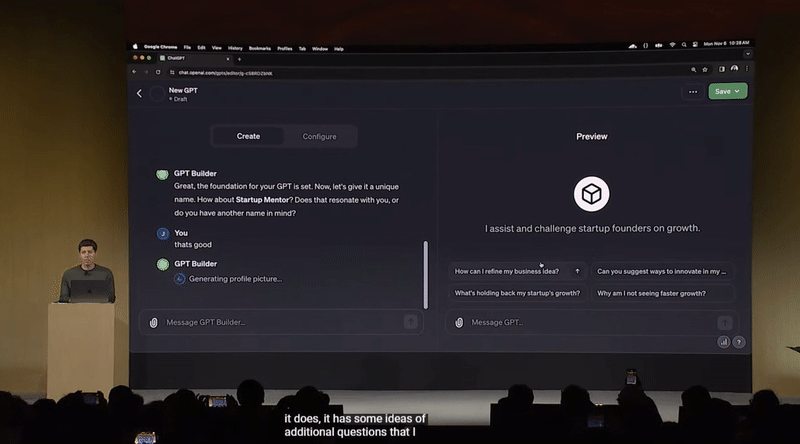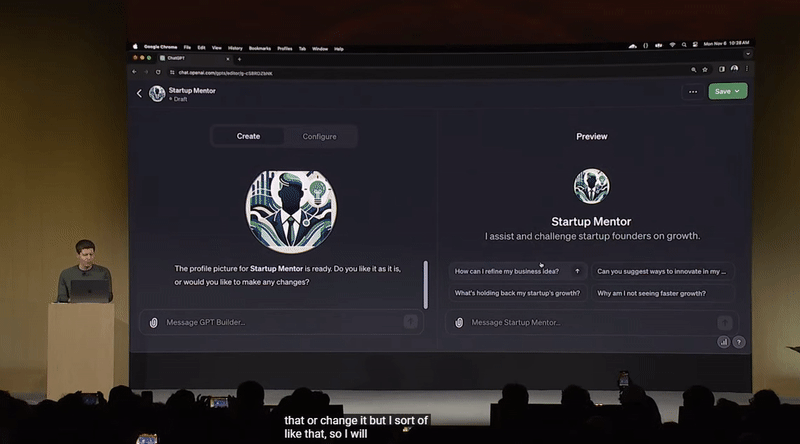
Sam Altman 现场展示如何通过自然语言构建自定义 GPT。在这个例子中,Altman 要求 ChatGPT 创建一个可以给创业者提供建议的 GPT。在接收到指令后,ChatGPT 不仅构建了这个 GPT,还提供了头像、命名建议。
除了使用内置功能之外,用户还可以通过向 GPT 提供一个或多个 API 来定义定制化 action。与插件一样,定制 action 允许 GPTs 集成外部数据或与现实世界交互。
此举目的非常简单,OpenAI 要充分挖掘社区开发者的力量,「我们相信最惊人的 GPT 产品将来自社区。无论您是教育家、教练,还是只是喜欢构建有用工具的人,您都不需要了解编码来制作工具并分享您的专业知识。」
同时,OpenAI 也会在本月底上线 GPT Store,让开发者们分享、发布自己创建的 GPTs。这是继这家公司宣布打造 ChatGPT 插件生态系统之后的又一次尝试。
没错,你是不是想到了苹果商店?OpenAI 明确表示 GPT Store 上会有 GPT 的排行榜。活动上,Altman 表示 OpenAI 将向最常用、最有用的 GPT 支付收入的一部分,但是否会向发布 GPT 的创建者们收费还未知。
目前,GPTs 可供 ChatGPT Plus 和企业用户试用。
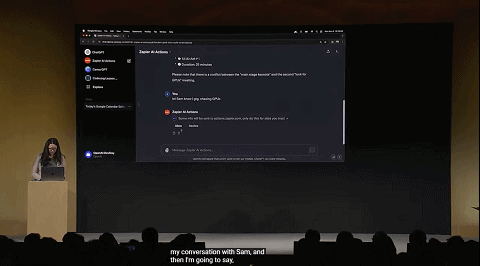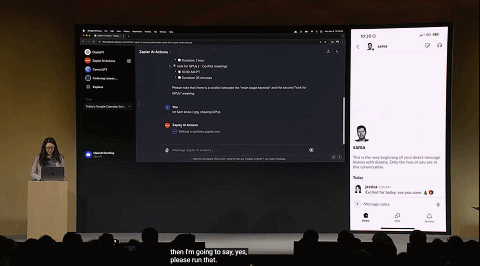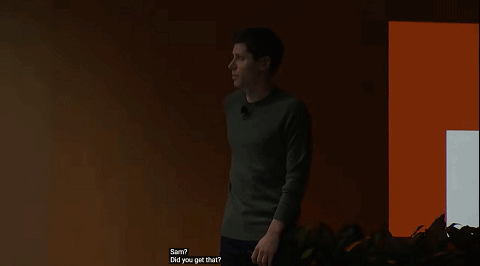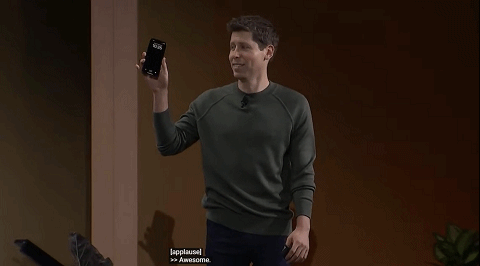
OpenAI 工作人员现场演示 GPTs。她构建了一个能与个人行程表联通的 GPT,然后以对话的形式命令 GPT 给 Altman 发信息,结果 Altman 真的收到了。
Altman表示:「最终,你只需向计算机询问你需要什么,它就会为你完成所有这些任务。」
Assistants API
在 keynote 环节,Sam Altman 还发布了「Assistants API」,这是他们帮助开发人员在自己的应用中构建类似「AI 智能体(agent)」体验的第一步。
通俗点来说,「assistant」可以理解为一种为某个专门用途构建的 AI,它有特定的指令,利用额外的知识,并能调用模型和工具来执行任务。新的 Assistants API 提供了代码解释器(Code Interpreter)、检索(Retrieval)以及函数调用(function calling)等新功能,可以处理大量以前你需要自己完成的繁重工作,使你能够构建高质量的 AI 应用。
这个 API 设计灵活,用例包括基于自然语言的数据分析应用、编码助手、AI 驱动的度假计划器、声控 DJ、智能可视画布等等。Assistants API 基于支持新 GPTs 产品的相同功能而构建:自定义指令和工具,如代码解释器、检索和函数调用。
这个 API 引入的一个关键变化是持久和无限长的线程,它允许开发人员将线程状态管理移交给 OpenAI,并绕过上下文窗口限制。使用 Assistants API,你只需将每条新消息添加到现有线程中即可。
Assistants 还可根据需要调用新工具,包括
- 代码解释器(Code Interpreter):在沙盒执行环境中编写和运行 Python 代码,并生成图形和图表,处理包含各种数据和格式的文件。它允许你的 assistants 反复运行代码,以解决具有挑战性的代码和数学问题等。
- 检索(Retrieval):利用模型之外的知识(如专有领域数据、产品信息或用户提供的文档)增强 assistants。这意味着,你不需要计算和存储文档的嵌入,也不需要实现分块和搜索算法。Assistants API 会根据 OpenAI 在 ChatGPT 中构建知识检索的经验,优化要使用的检索技术。
- 函数调用(Function calling):使助理能够调用你定义的函数,并将函数响应纳入其信息中。
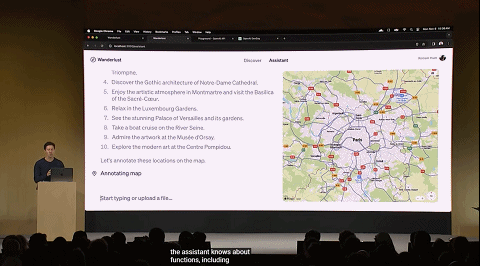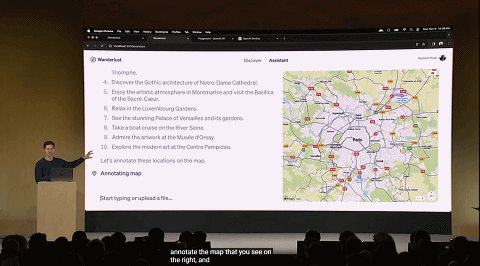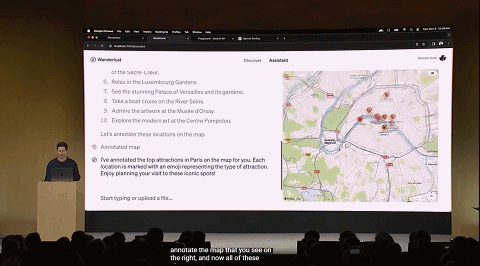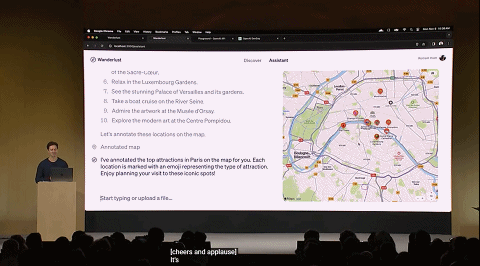
OpenAI 的工作人员现场演示 Assistants API 的用法:它不仅能列出巴黎旅游建议,还能在地图上将计划中提到的地点按类别标记出来。

Assistants API 自动阅读文档、调用代码解释器来计算旅行开销。
OpenAI 表示,与平台的其他部分一样,传给 OpenAI API 的数据和文件绝不会用于训练他们的模型,开发人员可以在他们认为合适的时候删除数据。
开发者可以前往 Assistants playground 试用 Assistants API 测试版,无需编写任何代码:https://platform.openai.com/playground?mode=assistant
从今天起,所有开发者都可以使用 Assistants API 测试版。定价参见:https://openai.com/pricing
还要钱比较烦~~
博客链接:https://openai.com/blog/new-models-and-developer-products-announced-at-devday
#NExT-GPT
继各类输入端多模态大语言模型之后,新加坡国立大学华人团队近期开源一种支持任意模态输入和任意模态输出的真正「大一统」多模态大模型,火爆 AI 社区。
ChatGPT 的诞生,引爆了 2023 年的基于大语言模型的 AI 浪潮,此后各类开源大语言模型陆续问世,包括 Flan-T5、Vicuna、 LLaMA、Alpaca 等。随后,社区继续发力,为模拟这个多模态的世界,研究者们将纯语言的大模型扩展到了处理语言之外的多模态大语言模型,诸如支持图像类的 MiniGPT-4、BLIP-2、Flamingo、InstructBLIP 等,支持视频类的 Video-LLaMA、PandaGPT 等,以及支持声音类的 SpeechGPT 等等。
但目前的多模态大语言模型,距离真正人类级别的 AGI,总感觉少了点「内味」。没错,人类的认知和沟通必须无缝地在任何信息模态之间进行转换。作为人类,我们不仅仅可以理解多模态内容,还能够以多模态的方式灵活输出信息。
对于现有的大语言模型,一方面,其大多局限于关注于某种单一模态信息的处理,而缺乏真正「任意模态」的理解;另一方面,其都关注于多模态内容在输入端的理解,而不能以任意多种模态的灵活形式输出内容。
正当大家都在期待 OpenAI 未来要发布的 GPT-5 是否能实现任意模态大一统功能时,几天前,来自于新加坡国立大学的 NExT++ 实验室的华人团队率先开源了一款「大一统」通用多模态大模型「NExT-GPT」,支持任意模态输入到任意模态输出。目前 NExT-GPT 的代码已经开源,并且上线了 Demo 系统。
- 项目地址:https://next-gpt.github.io
- 代码地址:https://github.com/NExT-GPT/NExT-GPT
- 论文地址:https://arxiv.org/abs/2309.05519
该实验室在多模态学习方向的研究有着多年的耕耘,具有深厚的积累,而 NExT-GPT 的取名也双关了实验室的名字以及 GPT of Next generation 的寓意。
NExT-GPT 一经发布便受到了 AI 社区的大量关注。有网友表示,NExT-GPT 标识着全能型 LLM 的到来:
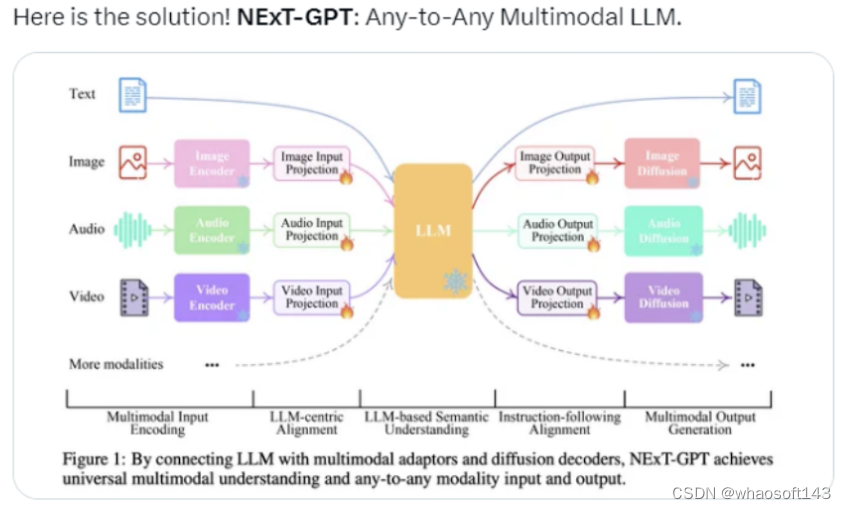
也有网友赞叹,这才是未来的 LLM 大趋势(大一统任意模态输入输出的 LLM):
接下来,我们来看看 NExT-GPT 可以实现哪些功能:
- Text → Text + Image + Audio
视频发不了音频发不了
- Text + Image → Text + Image + Video + Image
- Text + Video → Text + Image
- Text + Video → Text + Audio
- Text + Audio → Text + Image + Video
- Text → Text + Image + Audio + Video
- Text → Text + Image
- Text + Video → Text + Image + Audio
- Text → Text + Image + Audio + Video
- Text → Text + Image
可看到,NExT-GPT 能够准确理解用户所输入的各类组合模态下的内容,并准确灵活地返回用户所要求的甚至隐含的多模态内容,常见的图生文、图生视频、看图像 / 声音 / 视频说话、图像 / 声音 / 视频问答等问题统统不在话下,统一了跨模态领域的大部分常见任务,做到了真正意义上的任意到任意模态的通用理解能力。
作者在论文中还给出一些定量的实验结果验证,感兴趣的读者可以阅读论文内容。
技术细节
那 NExT-GPT 是如何实现任意模态输入到任意模态输出的?原理非常简单,作者甚至表示在技术层面上「没有显著的创新点」:通过有机地连接现有的开源 1) LLM, 2) 多模态编码器和 3) 各种模态扩散解码器,便构成了 NExT-GPT 的整体框架,实现任意模态的输入和输出,可谓大道至简。
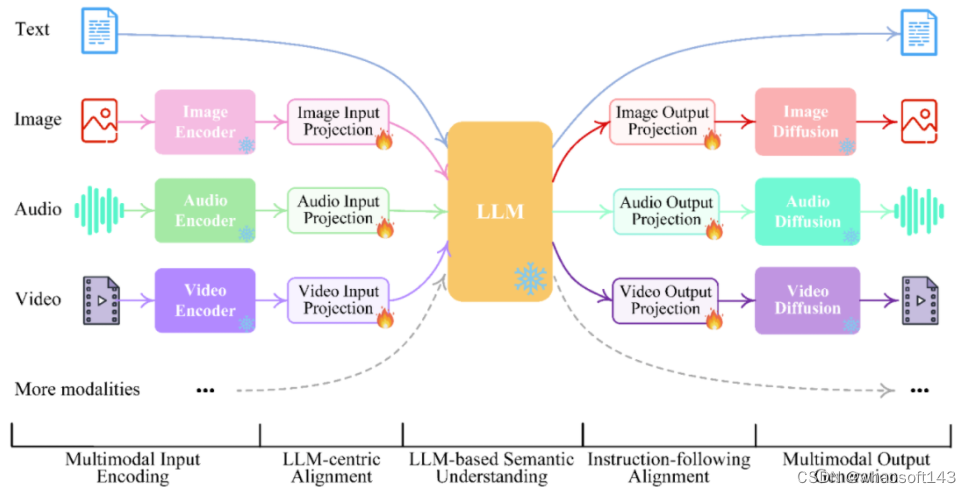
NExT-GPT 整体呈现为一个「编码端 - 推理中枢 - 解码器」三层架构:
- 多模编码阶段:利用已开源的编码器对各种输入模态进行编码,然后通过一个投影层将这些特征投影为 LLM 所能够理解的「类似语言的」表征。作者采用了 MetaAI 的 ImageBind 统一多模态编码器。
- 推理中枢阶段:利用开源 LLM 作为核心大脑来处理输入信息,进行语义理解和推理。LLM 可以直接输出文本,同时其还将输出一种「模态信号」token,作为传递给后层解码端的指令,通知他们是否输出相应的模态信息,以及输出什么内容。作者目前采用了 Vicuna 作为其 LLM。
- 多模生成阶段:利用各类开源的图像扩散模型、声音扩散模型以及视频扩散模型,接收来自 LLM 的特定指令信号,并输出所对应的模型内容(如果需要生成的指令)。
模型在推理时,给定任意组合模态的用户输入,通过模态编码器编码后,投影器将其转换为特征传递给 LLM(文本部分的输入将会直接出入到 LLM)。然后 LLM 将决定所生成内容,一方面直接输出文本,另一方面输出模态信号 token。如果 LLM 确定要生成某种模态内容(除语言外),则会输出对应的模态信号 token,表示该模态被激活。技术示意图如下:
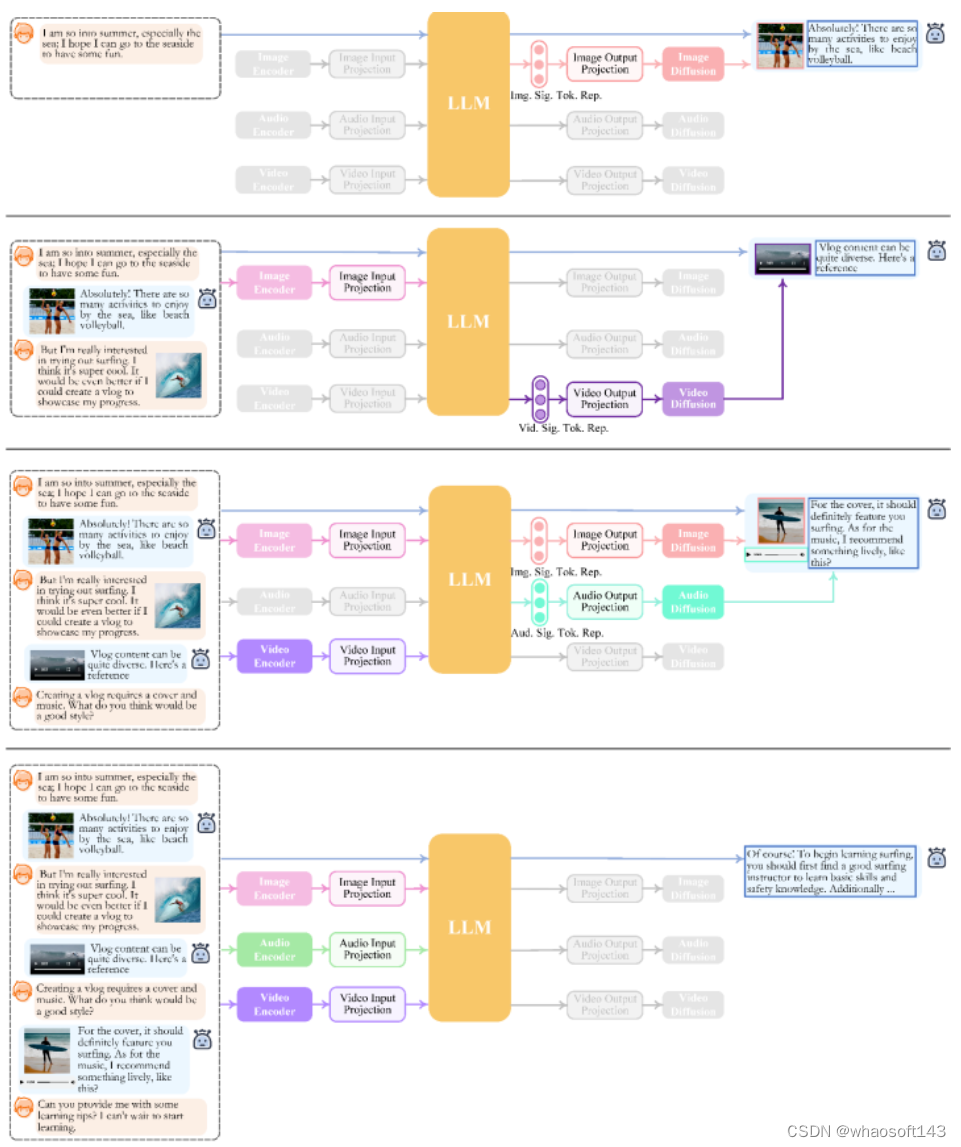
文中作者指出,NExT-GPT 可能并不是实现任意模态输入到任意模态输出功能的首个工作。目前有两类前驱工作:
- 一类是不久前所发布的 CoDi 模型,其整合了各种模态的 diffusion 模型,可以同时处理和生成各种组合的模态内容。然而作者指出,CoDi 由于缺乏 LLMs 作为其核心部件,其仅限于成对(Parallel)内容的输入和生成,而无法实现复杂的内容推理和决策,根据用户输入的指令灵活响应。
- 另一类工作则试图将 LLMs 与现有的外部工具结合,以实现近似的「任意多模态」理解和生成,代表性的系统如 Visual-ChatGPT 和 HuggingGPT。但作者指出,由于这类系统在不同模块之间的信息传递完全依赖于 LLM 所生成的文本,其割裂、级联的架构容易不可避免地引入了噪音,降低不同模块之间的特征信息传递效用。并且其仅利用现有外部工作进行预测,缺乏一种整体的端到端训练,这对于充分理解用户的输入内容和指令是不利的。
而 NExT-GPT 可以良好地解决如上所述的现有工作问题。那么 NExT-GPT 有哪些关键点呢?
- 关键点-1:低成本实现复杂推理 + 多模态 in 和多模态 out
如前文所述,不仅要继承 LLM 所具备的复杂内容理解和推理能力,还需要实现任意模态的输入和输出。若考虑从零开始构建整个系统,代价将会巨大(除非是大厂才能承担成本),也不利于开源和传播。考虑到现有的大模型已经基本实现了多模态的输入,为实现全能的大一统多模态能力,因此最关键的一点在于高性能的多模态输出。为此,NExT-GPT 完全基于现有开源的高性能模块(比如目前性能最强的扩散模型),充分站在巨人的肩膀上,以最低的成本实现大一统多模态大模型的构建目标(实验室可承担级别的成本)。
- 关键点-2:高效率端到端训练和模态对齐学习
妥当的、端到端的系统训练是 NExT-GPT 区别于现有其他组合型统一大模型系统最重要的一点,也是保证 NExT-GPT 具有优秀性能的前提。另一方面,还需要充分对齐系统中的所有模态的特征表征。为了既保证具有较好的学习成效,又全面降低、控制学习成本,本工作包含了以下的亮点。
首先,NExT-GPT 考虑分别在编码层 - LLM 之间以及 LLM - 解码层之间插入投影层(Projection Layers)。在冻结大规模参数的基座「编码层 - LLM - 解码层」情况下,仅去训练参数量极低的投影层部分(以及在指令微调时基于 LoRA 的 LLM 低代价更新),作者实现了仅仅 1% 参数量的训练代价。
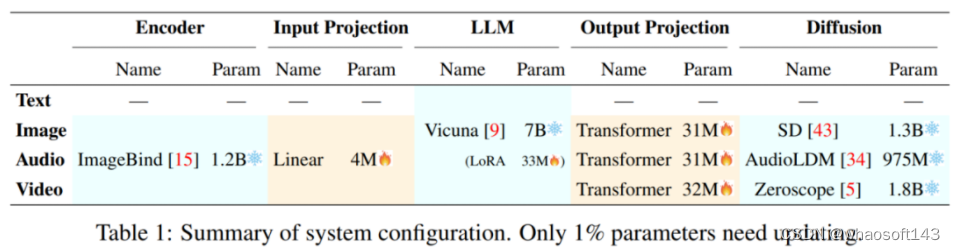
具体通过 1)以 LLM 为中心的编码端多模态对齐学习,和 2)局部微调的解码端指令跟随增强学习实现。
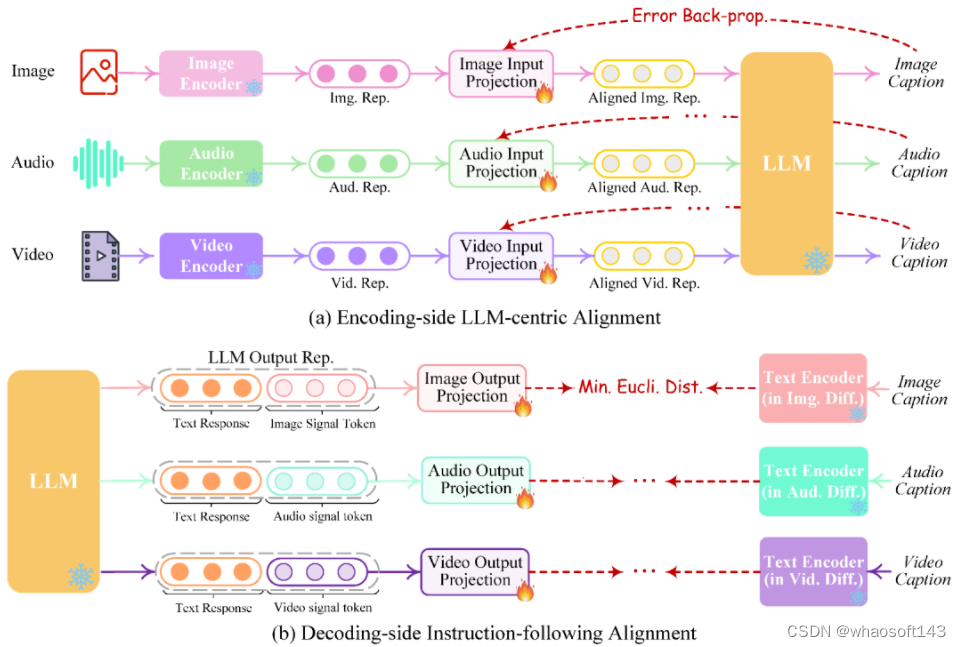
另外,对于多模态大模型,为确保其能够充分忠于用户指令而响应,进一步的指令调整(IT)是非常有必要的。不同于现有的多模态大模型其输出端仅涉及到文本,我们的 NExT-GPT 系统,其输入和输出端同时覆盖了各类模态信息。 为此,作者提出了一种模态切换指令微调学习(Modality-switching Instruction Tuning,MosIT),技术内涵如下图所示。同时,由于现存的多模态指令微调数据集都无法满足任意多模态 LLM 场景(即 MosIT)的要求,我们因此构建了一套 MosIT 数据集。该数据涵盖了各种多模态输入和输出,提供了必要的复杂性和变异性,帮助提升 NExT-GPT 获得优越的多模态指令跟随和相应能力。
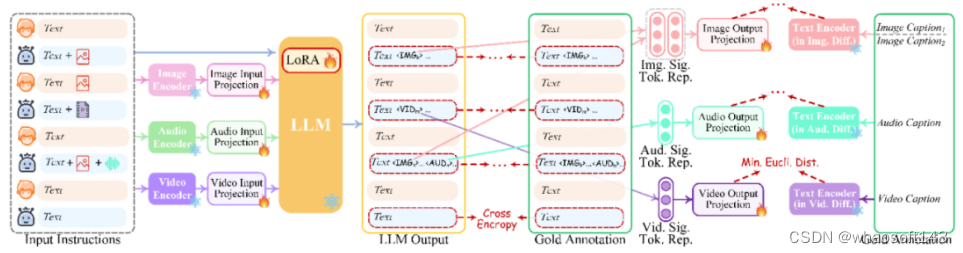
结论和未来展望
总体上,NExT-GPT 系统展示了构建一个通用大一统多模态的 AI 模型的美好景愿和喜人的可能性,这将为 AI 社区中后续的更「人类水平」的人工智能研究提供宝贵的借鉴。
基于 NExT-GPT,后续的研究工作可以考虑以下几个方面:
1. 模态与任务扩展:受限于现有资源,目前作者所开源的 NExT-GPT 系统仅支持四种模态:语言、图像、视频和音频。作者表示,后续会逐步扩展到更多的模态(例如,网页、3D 视觉、热图、表格和图表)和任务(例如,对象检测、分割、定位和跟踪),以扩大系统的普遍适用性。
2. 考虑更多基座 LLM:目前作者实现了基于 7B 版本的 Vicuna LLM,其表示下一步将整合不同大小的 LLM,以及其他 LLM 类型。
3. 多模态生成策略:目前版本的 NExT-GPT 系统仅考虑了基于扩散模型的纯输出方式的多模态输出。然而生成模式容易输出错误幻想内容(Hallucination),并且输出内容的质量往往容易受到扩散模型能力的限制。因此,进一步提升扩散模型的性能很关键,这能直接帮助提高多模态内容的输出质量。另外,实际上可以整合基于检索的方法来补充基于生成的过程的弊端,从而提升整体系统的输出可靠性。
4. 降低多模态支持成本:可以考虑进一步降低对更多模态的支持的成本。NExT-GPT 考虑了 ImageBind 来统一多种模态的编码,从而节省了在编码端的代价。而对于多模态输出端,作者简单地集成了多个不同模态的扩散模型。如何防止随着模态的增加而动态增加解码器是后续的重要研究方面。比如可以考虑将一些支持不同模态生成(但具有模态共性)的扩散模型进行复用。
5. MosIT 数据集扩展:目前 NExT-GPT 所使用的 MosIT 数据集规模受限,这也会限制其与用户的交互表现。后续研究可以进一步提升模态切换指令微调学习策略以及数据集。
#DeepMind4
DeepMind让大模型学会归纳和演绎,GPT-4准确率提升13.7%
当前,大型语言模型(LLM)在推理任务上表现出令人惊艳的能力,特别是在给出一些样例和中间步骤时。然而,prompt 方法往往依赖于 LLM 中的隐性知识,当隐性知识存在错误或者与任务不一致时,LLM 就会给出错误的回答。
现在,来自谷歌、Mila 研究所等研究机构的研究者联合探索了一种新方法 —— 让 LLM 学习推理规则,并提出一种名为假设到理论(Hypotheses-to-Theories,HtT)的新框架。这种新方法不仅改进了多步推理,还具有可解释、可迁移等优势。
论文地址:https://arxiv.org/abs/2310.07064
对数值推理和关系推理问题的实验表明,HtT 改进了现有的 prompt 方法,准确率提升了 11-27%。学到的规则也可以迁移到不同的模型或同一问题的不同形式。
方法简介
总的来说,HtT 框架包含两个阶段 —— 归纳阶段和演绎阶段,类似于传统机器学习中的训练和测试。
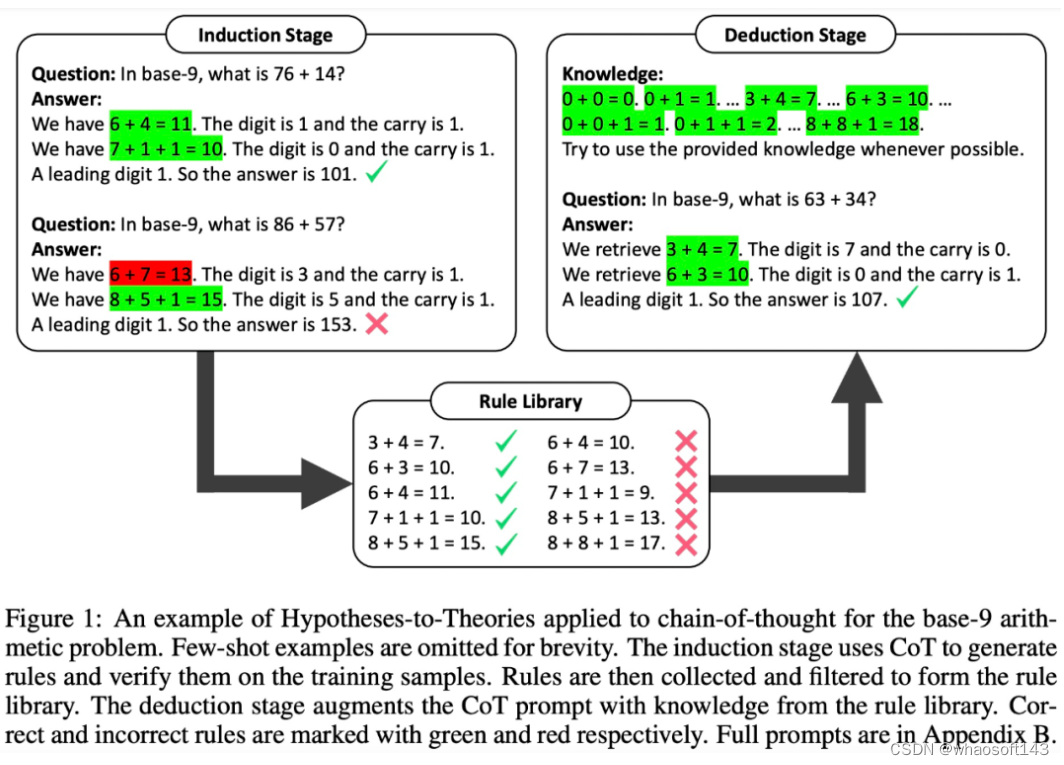
在归纳阶段,LLM 首先被要求生成并验证一组训练样例的规则。该研究使用 CoT 来声明规则并推导答案,判断规则的出现频率和准确性,收集经常出现并导致正确答案的规则来形成规则库。
有了良好的规则库,下一步该研究如何应用这些规则来解决问题。为此,在演绎阶段,该研究在 prompt 中添加规则库,并要求 LLM 从规则库中检索规则来进行演绎,将隐式推理转换为显式推理。
然而,该研究发现,即使是非常强大的 LLM(例如 GPT-4)也很难在每一步都检索到正确的规则。为此,该研究开发了 XML tagging trick,来增强 LLM 的上下文检索能力。
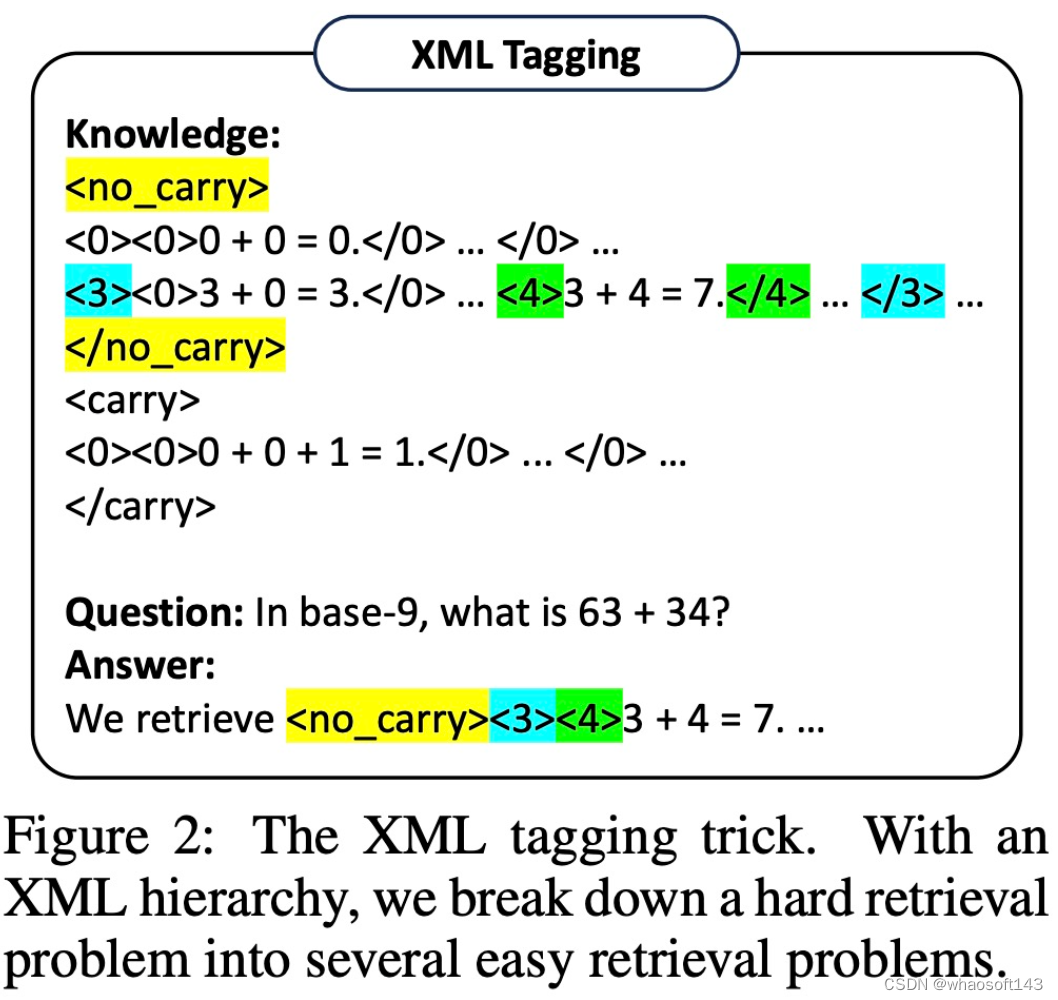
实验结果
为了评估 HtT,该研究针对两个多步骤推理问题进行了基准测试。实验结果表明,HtT 改进了少样本 prompt 方法。作者还进行了广泛的消融研究,以提供对 HtT 更全面的了解。
他们在数值推理和关系推理问题上评估新方法。在数值推理中,他们观察到 GPT-4 的准确率提高了 21.0%。在关系推理中,GPT-4 的准确性提高了 13.7%,GPT-3.5 则获益更多,性能提高了一倍。性能增益主要来自于规则幻觉的减少。
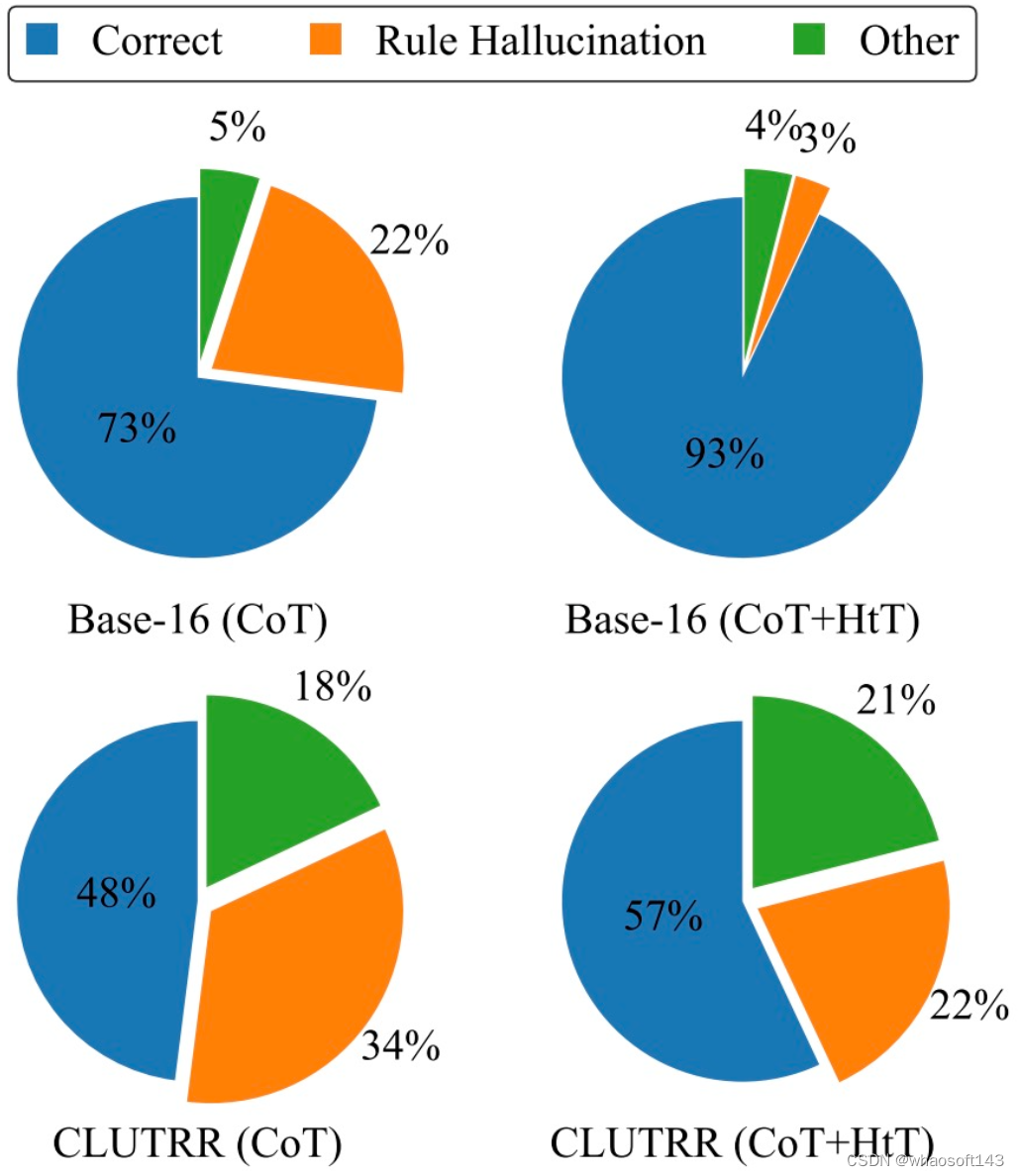
具体来说,下表 1 显示了在算术的 base-16、base-11 和 base-9 数据集上的结果。在所有 base 系统中,0-shot CoT 在两个 LLM 中的性能都最差。
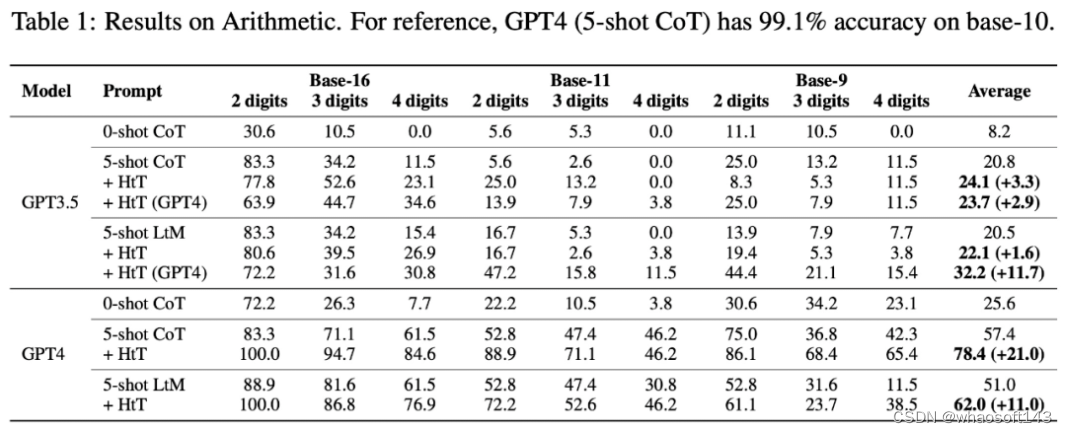
表 2 呈现了在 CLUTRR 上比较不同方法的结果。可以观察到,在 GPT3.5 和 GPT4 中,0-shot CoT 的性能最差。对于 few-shot 提示方法,CoT 和 LtM 的性能相似。在平均准确率方面,HtT 始终比两种模型的提示方法高出 11.1-27.2%。值得注意的是,GPT3.5 在检索 CLUTRR 规则方面并不差,而且比 GPT4 从 HtT 中获益更多,这可能是因为 CLUTRR 中的规则比算术中的规则少。
值得一提的是,使用 GPT4 的规则,GPT3.5 上的 CoT 性能提高了 27.2%,是 CoT 性能的两倍多,接近 GPT4 上的 CoT 性能。因此,作者认为 HtT 可以作为从强 LLM 到弱 LLM 的一种新的知识蒸馏形式。
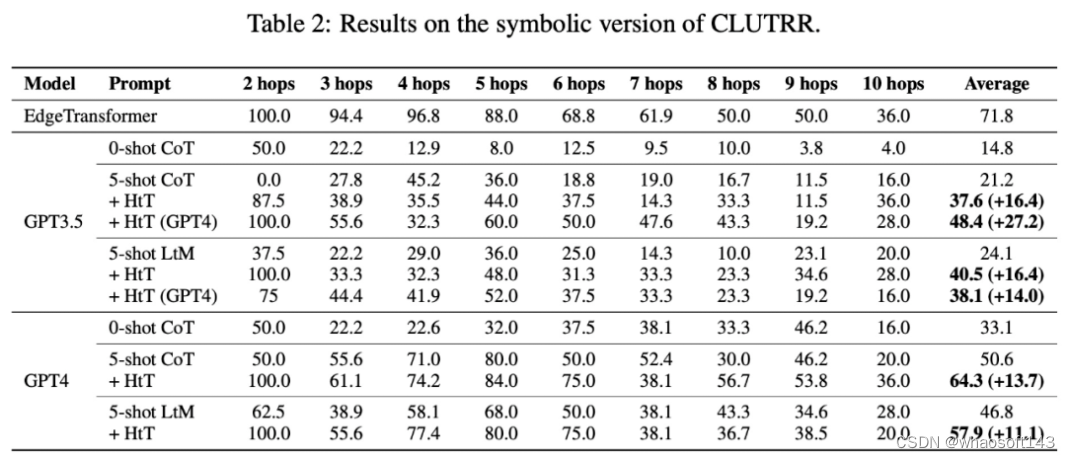
表 3 显示,HtT 显著提高了 GPT-4(文本版)的性能。对于 GPT3.5 来说,这种改进并不显著,因为在处理文本输入时,它经常产生除规则幻觉以外的错误。
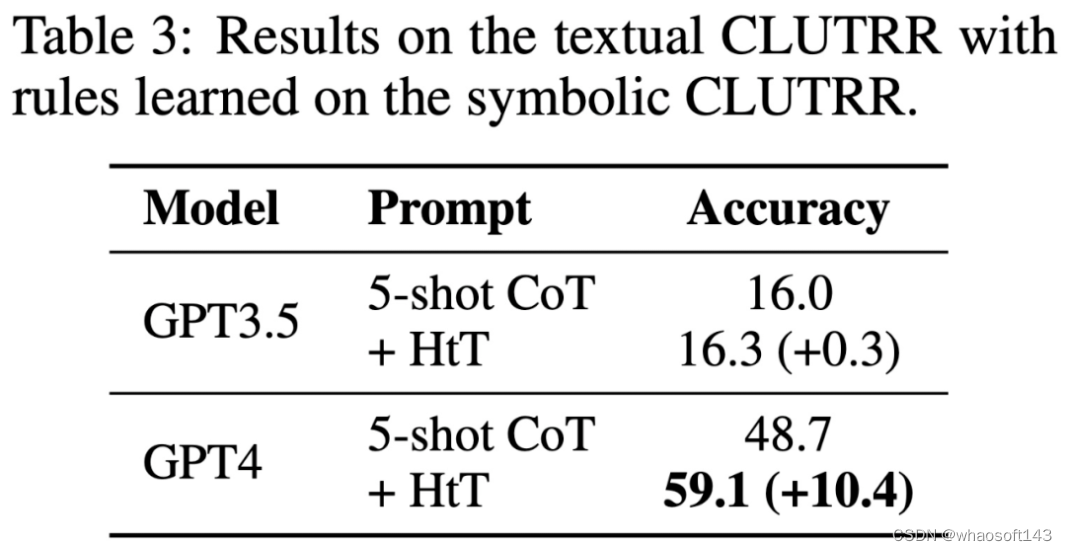
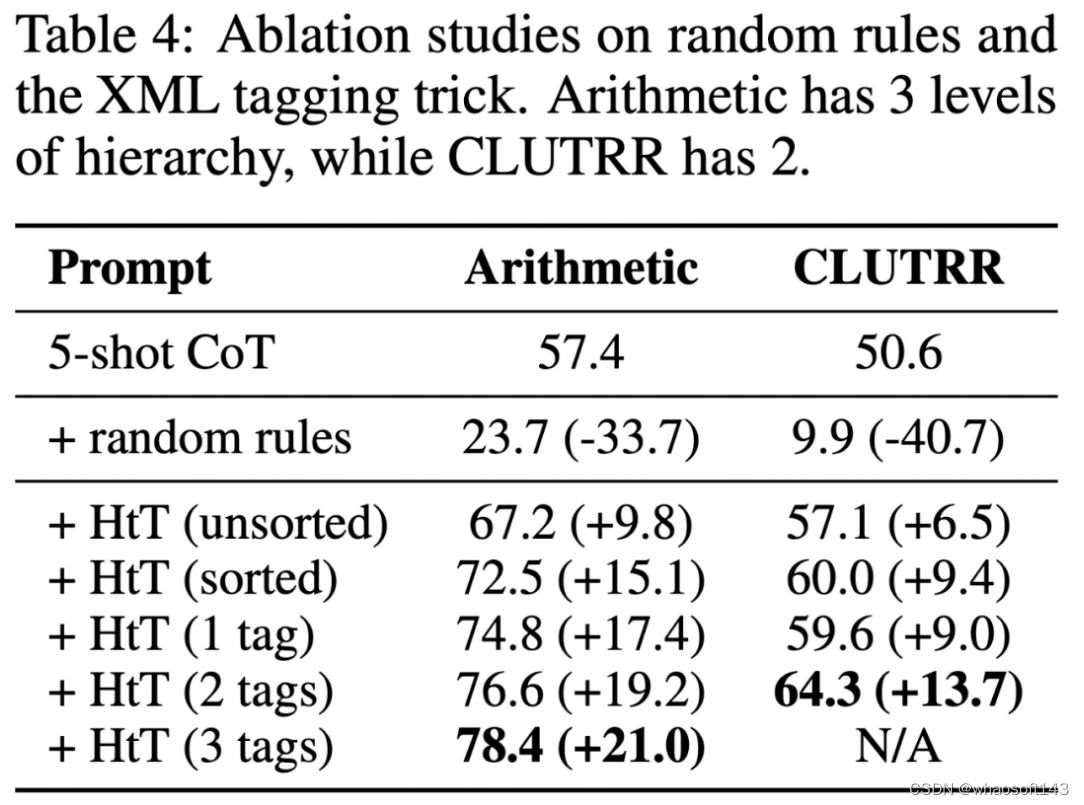
#DeepMind3
对于谷歌 DeepMind 的 Soft MoE,有人表示:「即使它不是万能药,仍可以算得上一个突破」。
随着大模型涌现出令人惊艳的性能,模型大小已经成为影响模型性能的关键因素之一。通常,对 Transformer 模型来说,模型越大,性能就会越好,但计算成本也会增加。近期有研究表明,模型大小和训练数据必须一起扩展,才能最佳地使用给定的训练计算预算。
稀疏混合专家模型(MoE)是一种很有前途的替代方案,可以在计算成本较少的情况下,扩展模型的大小。稀疏 MoE Transformer 有一个关键的离散优化问题:决定每个输入 token 应该使用哪些模块。这些模块通常是称为专家的 MLP。
为了让 token 与专家良好匹配,人们设计了许多方法,包括线性规划、强化学习、最优传输(optimal transport)等。在许多情况下,需要启发式辅助损失(auxiliary loss)来平衡专家的利用率并最大限度地减少未分配的 token。这些挑战在分布外场景中可能会加剧。
现在,来自 Google DeepMind 的研究团队提出了一种称为「Soft MoE」的新方法 ,解决了许多问题。
论文地址:https://arxiv.org/pdf/2308.00951.pdf
Soft MoE 不采用稀疏且离散的路由器在 token 和专家之间进行硬分配(hard assignment),而是通过混合 token 来执行软分配(soft assignment)。值得注意的是,这种方法会计算所有 token 的多个加权平均值(weighted average),其中权重取决于 token 和专家,然后由相应的专家处理每个加权平均值。
常见的稀疏 MoE 算法通常会学习一些路由器参数,但这些算法的效果有时甚至不如随机固定路由。在 Soft MoE 中,由于每个路由(或混合)参数都是根据单个输入 token 直接更新的,因此可以在训练路由器期间提供稳定性。研究团队还观察到,在训练期间,大部分输入 token 可以同时改变网络中的离散路由。
此外,硬路由(hard routing)在专家模块数量较多时可能具有挑战性,因此大多数研究的训练只有几十个专家模块。相比之下,Soft MoE 可扩展至数千个专家模块,并且可以通过构建实现平衡。最后,Soft MoE 在推理时不存在批次效应(batch-effect)。
该研究进行了一系列实验来探究 Soft MoE 方法的实际效果。实验结果表明,Soft MoE L/16 在上游任务、少样本任务和微调方面击败了 ViT H/14,并且 Soft MoE L/16 仅需要一半的训练时间,推理速度还是 ViT H/14 的 2 倍。值得注意的是,尽管 Soft MoE B/16 的参数量是 ViT H/14 的 5.5 倍,但 Soft MoE B/16 的推理速度却是 ViT H/14 的 5.7 倍。
此外,该研究用实验表明通过软路由学习的表征保留了图像 - 文本对齐的优势。
Soft MoE 模型
算法描述
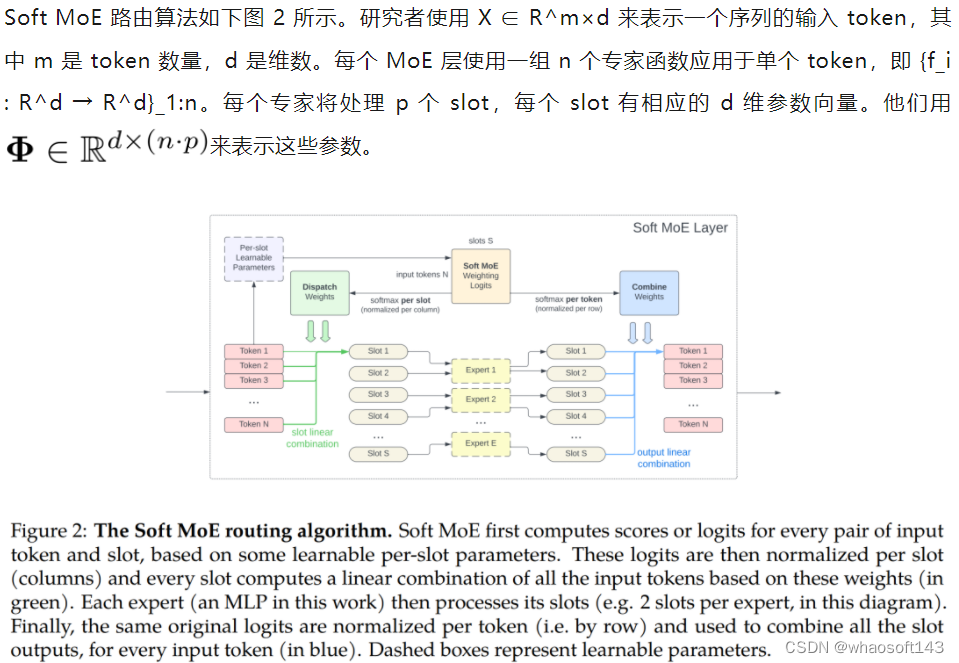
研究者遵循稀疏 MoE 的常规设计,利用 Soft MoE 块替换掉了 Transformer MLP 块的一个子集。这里通常会替换掉 MLP 块的后半部分。slot 的总数量是 Soft MoE 层的关键超参数,这是因为时间复杂度依赖于 slot 数量而不是专家数量。比如可以将 slot 数设置为与输入序列长度相等,以匹配等效密集 Transformer 的 FLOP。

Soft MoE 的特性
首先 Soft MoE 完全可微。Soft MoE 中的所有操作都是连续且完全可微的。我们可以将带有 softmax 分数的加权平均值解释为软分类,这也是 Soft MoE 算法名称的由来。作为对比,稀疏 MoE 方法通常采用的是硬分类。
其次 Soft MoE 没有 token dropping 和专家不平衡。Soft MoE 基本上不受这两点的影响,这得益于每个 slot 都填充了所有 token 的加权平均值。并且由于 softmax,所有权重都是严格正的。
再次 Soft MoE 速度快。它的主要优势是完全避免了排序或 top-k 操作,这些操作速度慢并且通常不太适合硬件加速器。因此,Soft MoE 的速度明显要快于大多数稀疏 MoE,具体如下图 6 所示。
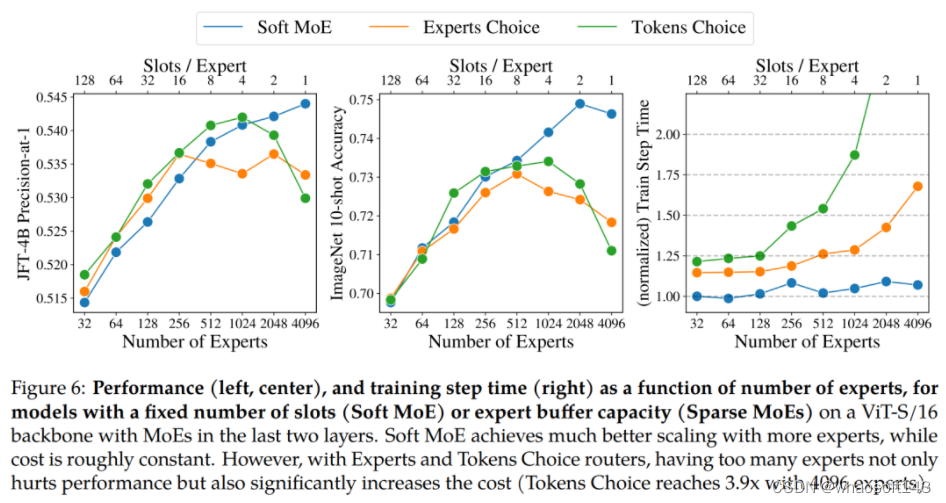
Soft MoE 还兼具稀疏和密集的特点。稀疏 MoE 的稀疏性来自于专家参数仅应用于输入 token 的子集。然而,Soft MoE 在技术上不稀疏,这是因为每个 slot 是所有输入 token 的加权平均值。并且每个输入 token 会极少部分激活所有模型参数。同样所有输出 token 也极少部分依赖所有 slot(和专家)。还要注意一点,Soft MoE 不是密集 MoE(其中每个专家处理所有输入 token),它的每个专家仅处理 slot 的子集。
最后 Soft MoE 具有序列性。由于它组合了每个输入序列中的所有 token,因此只需将组大小设置为一个大序列。每个专家会处理每个输入的 token,这可能会在一定程度上限制高级 specialization 的数量。这也意味着 Soft MoE 呈现逐实例确定性和速度快,而稀疏 MoE 的典型实例不是这样。
实现
时间复杂度。假设单个专家函数的逐 token 成本是 O (k),则一个 Soft MoE 层的时间复杂度为 O (mnpd + npk)。通过为每个专家选择 p = O (m/n) 个 slot,也就是 token 数量除以专家数量,成本可以降低至 O (m^2d + mk)。
归一化。在 Transformer 中,MoE 层通常用来替换掉每个编码器块中的前馈层。因此当使用预归一化作为大多数现代 Transformer 架构时,MoE 层的输入是「层归一化的」。

分布式模型。研究者采用标准技术将模型分布在很多设备上。分布式模型通常会增加模型的成本开销,不过他们上文推导的基于 FLOP 的时间复杂度分析并没有捕获这一点。因此在所有实验中,研究者不仅测量了 FLOP,还测量了以 TPUv3-chip-hour 为单位的挂钟时间。
图像分类实验结果
研究者展示了图像分类的三种类型的实验:
- 训练帕累托边界
- 推理时优化模型
- 模型消融
研究者在 JFT-4B 数据集上对模型进行预训练,这是一个专有数据集,最新版本包含了超过 4B 张图像、29k 个类别。
在预训练期间,他们提供了两个指标的评估结果,即 JFT-4B 的上游验证 precision-at-1 和 ImageNet 10-shot 准确率。此外还提供了在 ImageNet-1k(1.3M 张图像)上进行微调后,ImageNet-1k 验证集上的准确率。
研究者对比了两个流行 MoE 路由算法,分别是 Tokens Choice 和 Experts Choice。
训练帕累托 - 优化模型
研究者训练了 VIT-S/8、VIT-S/16、VIT-S/32、VIT-B/16、VIT-B/32、VIT-L/16、VIT-L/32 和 VIT-H/14 模型,以及它们的稀疏对应模型。
下图 3a 和 3b 显示了每个类别中模型的结果,这些模型位于各自的训练成本 / 性能帕累托边界上。在上述两个评估指标上,对于任何给定的 FLOP 或时间预算,Soft MoE 显著优于密集和其他稀疏方法。
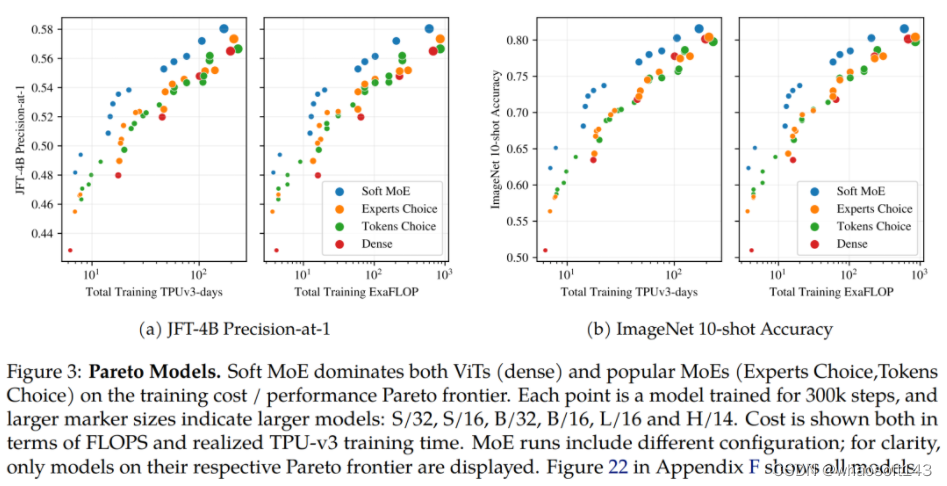
长训练运行
除了较短的运行和消融实验之外,研究者还训练了运行更长(几百万 step)的模型,从而在更大的计算规模上测试 Soft MoE 的性能。
首先研究者训练了从 Small 到 Huge 的不同大小的 ViT 和 Soft MoE 模型,它们运行了 4 百万 step。下图 4 和表 2 展示了结果。
其中图 4 展示了 Soft MoE 与 ViT 的 JFT-4B 精度、ImageNet 10-shot 准确率和 ImageNet 微调准确率,以及 ExaFLOPS 的训练成本。表 2 提供了所有结果。对于给定的计算预算,Soft MoE 模型的性能远优于 ViT 模型。
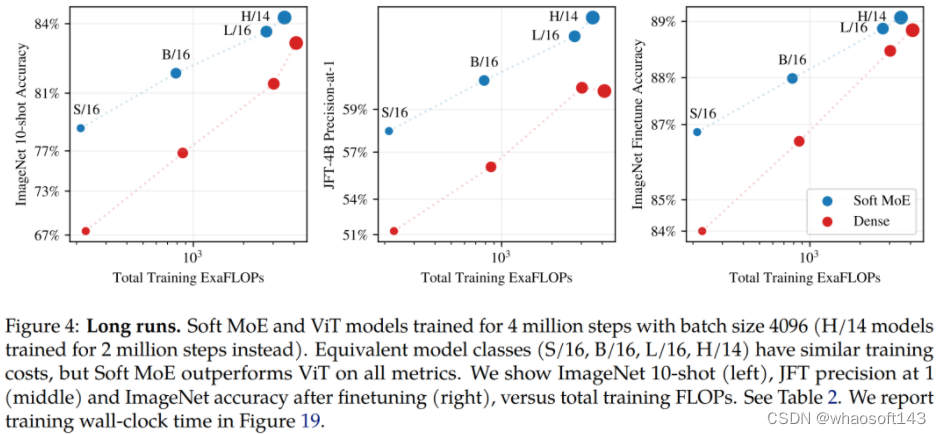
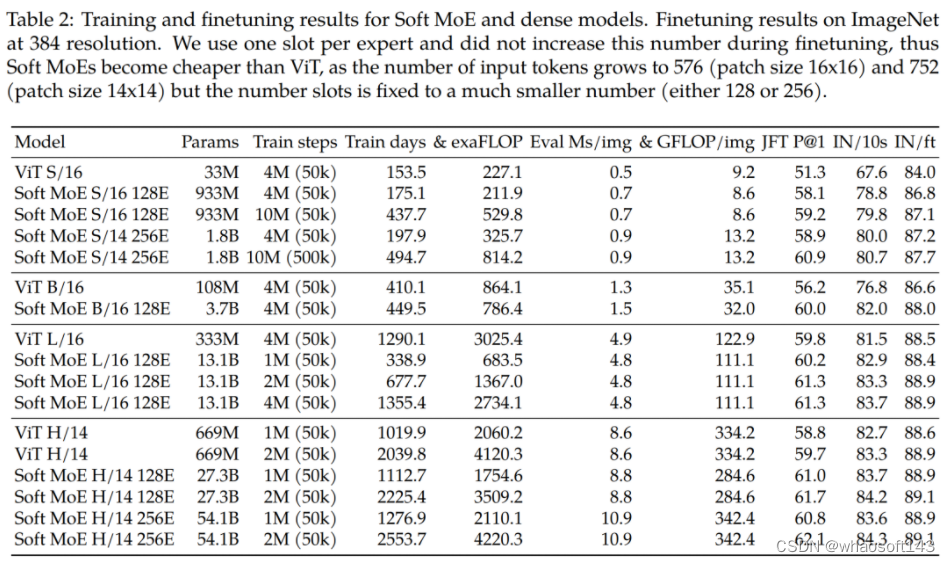
再来看针对推理进行优化的 Soft MoE。对于具有较小主干的 Soft MoE 可以与较大 ViT 模型一较高下这一事实,研究者受到了鼓舞,继续训练小的主干,以在非常低的推理成本下获得更高质量的模型对于更长时间的运行,研究者观察到冷却时间(学习率线性降低到 0)越长,Soft MoE 的效果很好。因此,他们将冷却时长从 50k step 增加到最多 500k。下图 5 展示了这些模型。
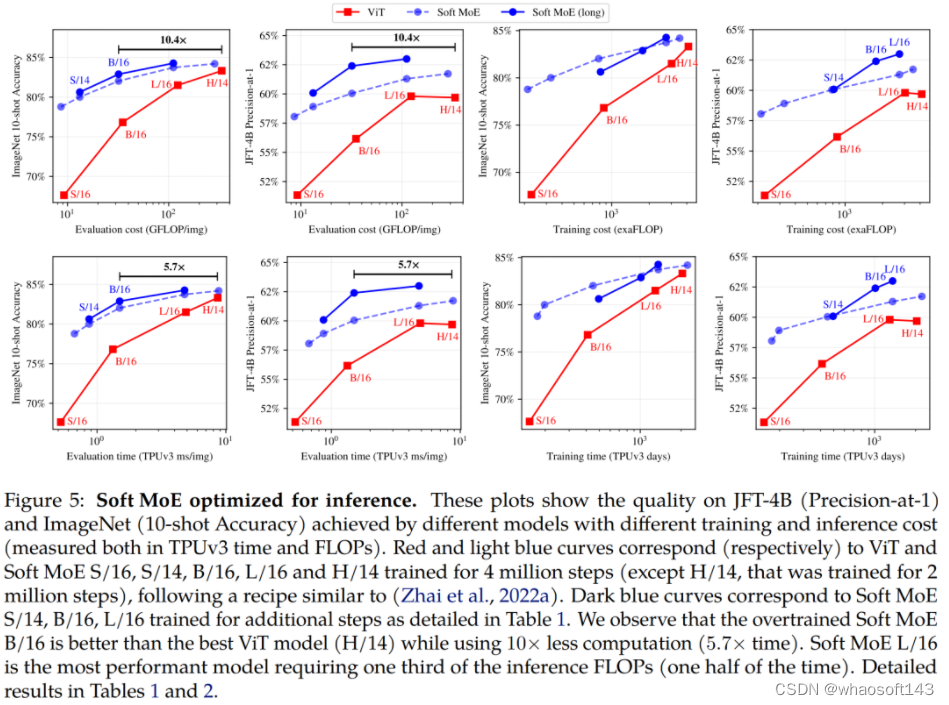
从结果来看,经过 1k TPUv3 days 训练的 Soft MoE B/16 优于在类似时间预算下训练的 ViT H/14,同时在 FLOP 推理上成本 10 倍降低,在挂钟时间上 5.7 倍减少。
即使将 ViT-H/14 的训练预算加倍(2M step 和 2039.8 train days),Soft MoE B/16(1011.4 days)也几乎与它性能相近。
此外,Soft MoE L/16 大幅地击败所有模型,同时推理速度是 ViT H/14 的近 2 倍。
#DeepMind2
也是第二 之前说过一次
给机器人发命令,从没这么简单过。
我们知道,在掌握了网络中的语言和图像之后,大模型终究要走进现实世界,「具身智能」应该是下一步发展的方向。
把大模型接入机器人,用简单的自然语言代替复杂指令形成具体行动规划,且无需额外数据和训练,这个愿景看起来很美好,但似乎也有些遥远。毕竟机器人领域,难是出了名的。
然而 AI 的进化速度比我们想象得还要快。
本周五,谷歌 DeepMind 宣布推出 RT-2:全球第一个控制机器人的视觉 - 语言 - 动作(VLA)模型。
现在不再用复杂指令,机器人也能直接像 ChatGPT 一样操纵了。

RT-2 到达了怎样的智能化程度?DeepMind 研究人员用机械臂展示了一下,跟 AI 说选择「已灭绝的动物」,手臂伸出,爪子张开落下,它抓住了恐龙玩偶。

在此之前,机器人无法可靠地理解它们从未见过的物体,更无法做把「灭绝动物」到「塑料恐龙玩偶」联系起来这种有关推理的事。
跟机器人说,把可乐罐给泰勒・斯威夫特:

看得出来这个机器人是真粉丝,对人类来说是个好消息。
ChatGPT 等大语言模型的发展,正在为机器人领域掀起一场革命,谷歌把最先进的语言模型安在机器人身上,让它们终于拥有了一颗人工大脑。
在 DeepMind 在最新提交的一篇论文中研究人员表示,RT-2 模型基于网络和机器人数据进行训练,利用了 Bard 等大型语言模型的研究进展,并将其与机器人数据相结合,新模型还可以理解英语以外的指令。
谷歌高管称,RT-2 是机器人制造和编程方式的重大飞跃。「由于这一变化,我们不得不重新考虑我们的整个研究规划了,」谷歌 DeepMind 机器人技术主管 Vincent Vanhoucke 表示。「之前所做的很多事情都完全变成无用功了。」
RT-2 是如何实现的?
DeepMind 这个 RT-2 拆开了读就是 Robotic Transformer —— 机器人的 transformer 模型。
想要让机器人能像科幻电影里一样听懂人话,展现生存能力,并不是件容易的事。相对于虚拟环境,真实的物理世界复杂而无序,机器人通常需要复杂的指令才能为人类做一些简单的事情。相反,人类本能地知道该怎么做。
此前,训练机器人需要很长时间,研究人员必须为不同任务单独建立解决方案,而借助 RT-2 的强大功能,机器人可以自己分析更多信息,自行推断下一步该做什么。
RT-2 建立在视觉 - 语言模型(VLM)的基础上,又创造了一种新的概念:视觉 - 语言 - 动作(VLA)模型,它可以从网络和机器人数据中进行学习,并将这些知识转化为机器人可以控制的通用指令。该模型甚至能够使用思维链提示,比如哪种饮料最适合疲惫的人 (能量饮料)。
RT-2 架构及训练过程
其实早在去年,谷歌就曾推出过 RT-1 版本的机器人,只需要一个单一的预训练模型,RT-1 就能从不同的感官输入(如视觉、文本等)中生成指令,从而执行多种任务。
作为预训练模型,要想构建得好自然需要大量用于自监督学习的数据。RT-2 建立在 RT-1 的基础上,并且使用了 RT-1 的演示数据,这些数据是由 13 个机器人在办公室、厨房环境中收集的,历时 17 个月。
DeepMind 造出了 VLA 模型
前面我们已经提到 RT-2 建立在 VLM 基础之上,其中 VLMs 模型已经在 Web 规模的数据上训练完成,可用来执行诸如视觉问答、图像字幕生成或物体识别等任务。此外,研究人员还对先前提出的两个 VLM 模型 PaLI-X(Pathways Language and Image model)和 PaLM-E(Pathways Language model Embodied)进行了适应性调整,当做 RT-2 的主干,并将这些模型的视觉 - 语言 - 动作版本称为 RT-2-PaLI-X 以及 RT-2-PaLM-E 。
为了使视觉 - 语言模型能够控制机器人,还差对动作控制这一步。该研究采用了非常简单的方法:他们将机器人动作表示为另一种语言,即文本 token,并与 Web 规模的视觉 - 语言数据集一起进行训练。
对机器人的动作编码基于 Brohan 等人为 RT-1 模型提出的离散化方法。
如下图所示,该研究将机器人动作表示为文本字符串,这种字符串可以是机器人动作 token 编号的序列,例如「1 128 91 241 5 101 127 217」。

该字符串以一个标志开始,该标志指示机器人是继续还是终止当前情节,然后机器人根据指示改变末端执行器的位置和旋转以及机器人抓手等命令。
由于动作被表示为文本字符串,因此机器人执行动作命令就像执行字符串命令一样简单。有了这种表示,我们可以直接对现有的视觉 - 语言模型进行微调,并将其转换为视觉 - 语言 - 动作模型。
在推理过程中,文本 token 被分解为机器人动作,从而实现闭环控制。
实验
研究人员对 RT-2 模型进行了一系列定性和定量实验。
下图展示了 RT-2 在语义理解和基本推理方面的性能。例如,对于「把草莓放进正确的碗里」这一项任务,RT-2 不仅需要对草莓和碗进行表征理解,还需要在场景上下文中进行推理,以知道草莓应该与相似的水果放在一起。而对于「拾起即将从桌子上掉下来的袋子」这一任务,RT-2 需要理解袋子的物理属性,以消除两个袋子之间的歧义并识别处于不稳定位置的物体。
需要说明的是,所有这些场景中测试的交互过程在机器人数据中从未见过。

下图表明在四个基准测试上,RT-2 模型优于之前的 RT-1 和视觉预训练 (VC-1) 基线。
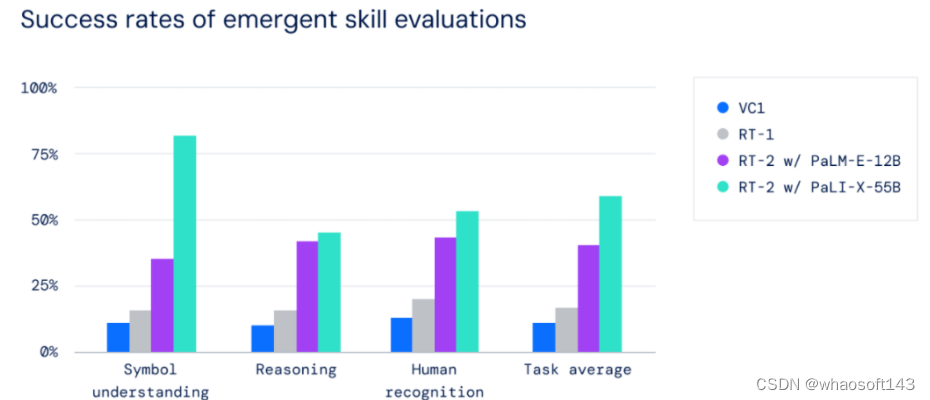
RT-2 保留了机器人在原始任务上的性能,并提高了机器人在以前未见过场景中的性能,从 RT-1 的 32% 提高到 62%。
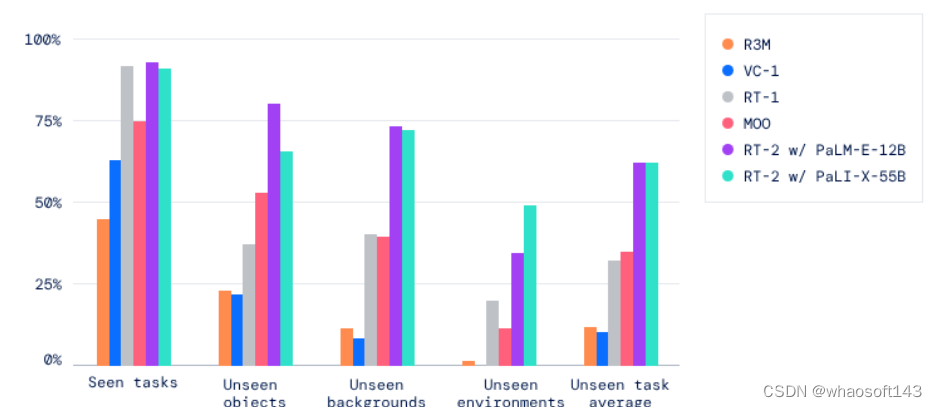
一系列结果表明,视觉 - 语言模型(VLM)是可以转化为强大的视觉 - 语言 - 动作(VLA)模型的,通过将 VLM 预训练与机器人数据相结合,可以直接控制机器人。
和 ChatGPT 类似,这样的能力如果大规模应用起来,世界估计会发生不小的变化。不过谷歌没有立即应用 RT-2 机器人的计划,只表示研究人员相信这些能理解人话的机器人绝不只会停留在展示能力的层面上。
简单想象一下,具有内置语言模型的机器人可以放入仓库、帮你抓药,甚至可以用作家庭助理 —— 折叠衣物、从洗碗机中取出物品、在房子周围收拾东西。

它可能真正开启了在有人环境下使用机器人的大门,所有需要体力劳动的方向都可以接手 ,大模型影响不到的那部分,现在也能被覆盖。
具身智能,离我们不远了?
最近一段时间,具身智能是大量研究者正在探索的方向。本月斯坦福大学李飞飞团队就展示了一些新成果,通过大语言模型加视觉语言模型,AI 能在 3D 空间分析规划,指导机器人行动。
稚晖君的通用人形机器人创业公司「智元机器人(Agibot)」昨天晚上放出的视频,也展示了基于大语言模型的机器人行为自动编排和任务执行能力。

预计在 8 月,稚晖君的公司即将对外展示最近取得的一些成果。
可见在大模型领域里,还有大事即将发生。
参考内容:
https://www.deepmind.com/blog/rt-2-new-model-translates-vision-and-language-into-action
https://www.blog.google/technology/ai/google-deepmind-rt2-robotics-vla-model/
https://www.theverge.com/2023/7/28/23811109/google-smart-robot-generative-ai
https://www.nytimes.com/2023/07/28/technology/google-robots-ai.html
https://www.bilibili.com/video/BV1Uu4y1274k/






![[Python] Python自动化:PyAutoGUI的基本操作](https://i-blog.csdnimg.cn/direct/8d4db10265134fa487cfb7052ee2c1b4.png)