本文还有配套的精品资源,点击获取 
简介:VGG16,作为深度学习领域的里程碑,以其独特的16层深度网络架构在2014年ILSVRC中取得突破。该模型主要采用3x3的小型卷积核,通过深层次的卷积层堆叠来提升模型复杂度。VGG16通常作为预训练模型,用于图像分类、物体检测等计算机视觉任务的特征提取或微调。在Python中,Keras库简化了VGG16模型的加载与应用,并允许开发者通过移除顶层全连接层、添加自定义层来适配新的分类任务。本项目通过Jupyter Notebook展示了VGG16模型在图像处理中的应用,以及如何进行模型训练与评估。项目文件包括数据处理、模型构建、训练和评估的完整流程。 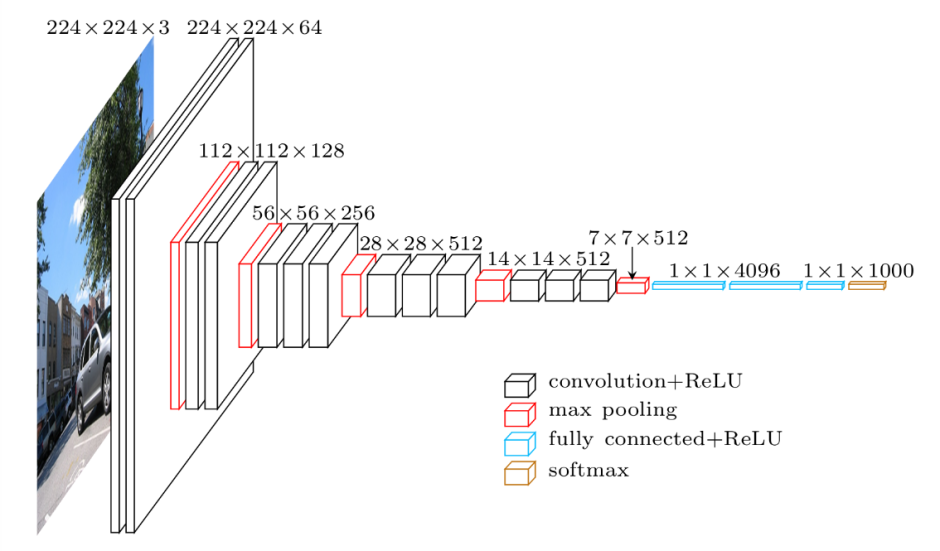
1. VGG16模型简介与架构特点
在深度学习的众多模型中,VGG16模型因其简单而强大的网络结构在图像处理领域赢得了广泛的关注。自2014年由Karen Simonyan和Andrew Zisserman提出以来,VGG16模型成为了学术界和工业界的基准,并在多个视觉识别挑战赛中取得了领先地位。VGG16模型的显著特点在于其序列化的重复使用卷积核大小为3x3的卷积层和2x2的池化层,从而构建了一个深层的网络结构。
VGG16模型的诞生背景及其在深度学习领域的重要性
VGG16是在图像识别竞赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge)的背景下诞生的。它的出现标志着深度学习技术开始在图像分类任务中占据统治地位。VGG16的成功之处不仅在于其模型架构,也在于它通过大量的实验验证了更深网络结构的必要性和有效性。
深入探讨VGG16的网络架构
VGG16模型由16个权重层构成,其中包括13个卷积层和3个全连接层。每个卷积层后面通常跟随一个ReLU激活函数以及一个2x2池化层,以此逐步降低特征图的空间尺寸。这一系列卷积层与池化层之后,接着是三个全连接层,其中最后一层采用softmax激活函数来进行多类别分类。
在VGG16中,网络的宽度(卷积核的数量)是固定的,通常为64、128或者256,而深度则通过堆叠多个卷积层来加深。这种设计使得网络可以学习到复杂的空间层次特征,对于视觉任务非常关键。此外,VGG16还采用了小卷积核(3x3)来增加网络深度,相较于使用更大型卷积核,这种方法可以更好地保留图像的边缘信息,并且参数数量也相对较少。
接下来的章节将介绍VGG16模型在图像处理中的应用、预训练模型的特征提取与微调、以及在Keras中的自定义与应用实践等,进一步揭示其在深度学习领域的广泛应用和实践操作。
2. VGG16在图像处理中的应用
2.1 VGG16模型的图像识别能力
2.1.1 图像分类的基本原理
图像分类是将图片分配到不同类别中的过程,它是计算机视觉领域中的一项基础任务。基本原理可以概括为以下几点:
- 图像特征提取 :计算机视觉系统首先需要提取图像中的关键特征。这些特征可以是边缘、角点、纹理等低级特征,也可以是物体部件、形状等高级特征。
-
特征表示 :提取的特征需要被转换成模型能够理解和处理的形式,通常是向量或矩阵。
-
分类器设计 :分类器负责根据提取的特征将图像分配到预定义的类别。深度学习模型,特别是卷积神经网络(CNN),在这个过程中已经取得了显著的成果。
-
训练与优化 :使用大量带标签的图像数据来训练分类器,通过不断迭代来优化模型参数,使其在未见数据上表现出良好的分类性能。
2.1.2 VGG16在图像分类中的优势
VGG16模型由牛津大学的研究者提出,它在2014年的ImageNet大规模视觉识别挑战赛(ILSVRC)中获得了突破性的成绩。VGG16的优势可以从以下几个方面来分析:
-
深层网络结构 :VGG16拥有16个权重层(其中13个为卷积层,3个为全连接层),这种深层结构使得它能够捕捉图像中的复杂模式。
-
小卷积核设计 :VGG16全部使用了3x3大小的卷积核,这种设计虽然增加了模型的深度,但减少了参数数量,并且可以构建更深的网络。
-
通用特征提取器 :在多个不同数据集上的广泛测试显示,VGG16预训练模型可以作为一个强大的特征提取器,即使是在与训练数据集不同的任务中也能表现出色。
2.2 VGG16模型的迁移学习
2.2.1 迁移学习概念及其重要性
迁移学习是机器学习领域的一种方法,它将一个问题的知识应用到另一个问题中。在深度学习中,迁移学习允许我们利用在大型数据集(如ImageNet)上预训练的模型来解决特定任务,显著降低了对大量标注数据的需求。
迁移学习的重要性体现在以下几点:
-
减少训练数据需求 :在许多专业领域,获取大量标注数据是不现实的。迁移学习允许我们在较小的数据集上实现良好的性能。
-
加速训练过程 :预训练模型已经学习了大量的通用特征,这减少了训练新模型所需的时间和计算资源。
-
提高模型泛化能力 :预训练模型通常在广泛的数据集上训练,因此它们学习到的特征更加泛化,有助于提高新任务的性能。
2.2.2 VGG16迁移学习在图像处理中的实际应用案例
VGG16模型的迁移学习在多个图像处理任务中被广泛应用。以下是几个典型的应用案例:
-
医学影像分析 :在医学影像领域,使用VGG16可以进行癌症细胞的检测和分类,从而辅助医生诊断。
-
自动驾驶 :自动驾驶车辆需要识别道路上的各种物体,如行人、交通标志等。通过迁移学习,可以快速训练出一个可靠的物体识别系统。
-
面部识别 :VGG16可以用于提取人脸图像的特征,助力于安全验证和用户认证系统。
为了更深入地理解迁移学习,下面给出使用VGG16进行迁移学习的基本步骤和代码示例。
3. 使用预训练的VGG16进行特征提取和微调
3.1 特征提取的原理与方法
3.1.1 特征提取技术概述
特征提取是机器学习中一个核心步骤,它涉及到从原始数据中提取有助于任务执行的有用信息。在图像处理领域,特征通常指图像的边缘、角点、纹理等属性。传统手工特征提取方法依赖于图像处理专家的先验知识,例如使用SIFT(Scale-Invariant Feature Transform)和HOG(Histogram of Oriented Gradients)等算法。然而,这些方法往往计算复杂且对环境变化敏感。
近年来,随着深度学习的发展,卷积神经网络(CNNs)已成为自动提取图像特征的首选方法。深度学习模型,尤其是像VGG16这样的预训练网络,能够自动学习丰富的层次特征,这些特征不仅能够捕捉低级的边缘和纹理信息,还能捕捉高级的抽象特征。
3.1.2 利用VGG16进行高效特征提取
VGG16模型在ImageNet大规模视觉识别挑战赛(ILSVRC)上取得了卓越的成绩,其深层的网络结构能够提取有效的图像特征。在进行特征提取时,我们通常会使用预训练的VGG16模型,其参数已经通过大量图像数据的训练而得到优化。接下来,我们将网络作为特征提取器,固定模型中的权重,只使用模型的输出作为图像的特征表示。
下面是使用Keras库中的预训练VGG16模型进行特征提取的示例代码:
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np# 加载预训练的VGG16模型
model = VGG16(weights='imagenet', include_top=False)# 加载图像数据并进行预处理
img_path = 'path_to_your_image.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)# 提取特征
features = model.predict(x)# 输出特征的形状
print(features.shape)
在上述代码中,我们首先导入了 VGG16 模型和图像处理模块,然后加载了预训练的模型权重。通过 image.load_img 函数加载并调整了图像尺寸到224x224像素以符合VGG16的输入要求。图像被转换成数组并扩展了一个维度以适配模型输入的批量维度。接着,图像数据经过预处理函数 preprocess_input 转换,确保数据符合在训练模型时使用的相同格式。最后,我们使用 model.predict 方法提取特征。此操作会返回一个四维数组,其形状通常为 (1, 7, 7, 512) ,表示单张图像的特征。在实际应用中,我们通常会忽略批次维度(第一个维度)。
3.2 VGG16模型的微调技巧
3.2.1 微调的基本步骤
微调是深度学习中一种常见的技术,它允许我们修改预训练模型的权重以适应新的数据集。通过微调,我们可以利用预训练模型在大规模数据集上学习到的有用特征,并对它们进行优化以适应特定的任务。
微调的步骤大致如下:
- 初始化:使用预训练的权重初始化模型。
- 冻结:将模型的一部分权重冻结(即设置为不可训练),通常情况下我们会冻结早期层的权重。
- 替换:替换最后的全连接层以适应新的数据集的类别数量。
- 训练:只训练未冻结层和新替换的层,使用新的数据集进行训练。
- 评估与微调:评估模型性能,根据需要调整学习率和训练参数,进行进一步微调。
下面是一个简化的代码示例,演示如何对VGG16模型进行微调:
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D# 加载预训练模型
base_model = VGG16(weights='imagenet', include_top=False)# 冻结模型的所有层
for layer in base_model.layers:layer.trainable = False# 添加新层
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(num_classes, activation='softmax')(x)# 构建微调模型
model = Model(inputs=base_model.input, outputs=predictions)# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 训练模型(只训练顶层)
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))# 解冻部分层
for layer in model.layers[:10]: # 只解冻前10层layer.trainable = True# 重新编译模型,以应用修改
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 再次训练模型(训练解冻层)
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
在这段代码中,我们首先创建了一个新的模型,并使用预训练的VGG16作为基础。我们冻结了所有层,然后添加了两个新的全连接层,最终输出层的神经元数量与我们数据集中的类别数量相对应。之后,我们编译并训练了模型。在此之后,我们选择性地解冻了模型的一部分层,并重新编译以应用这些修改,随后再次训练模型。
3.2.2 VGG16微调的参数调整和性能优化
性能优化是微调过程中的关键一环。模型的性能很大程度上依赖于超参数的选择,如学习率、批次大小、优化器等。正确调整这些参数可以显著提升模型的收敛速度和最终性能。
-
学习率:是控制模型权重更新步长的超参数。学习率太高可能会导致模型震荡,太低则会导致学习过程过慢。通常可以使用学习率调度(如学习率衰减)或自适应学习率优化器(如Adam)来自动调整学习率。
-
批次大小:决定了在一次参数更新中使用多少训练样本。太大的批次大小可能导致内存不足,而太小的批次大小可能使训练不够稳定。一些研究表明,小批量训练可以有助于模型泛化。
-
优化器:选择合适的优化器至关重要。常见的优化器有SGD、RMSprop、Adagrad和Adam。Adam优化器因其自适应学习率调整而广受欢迎,它结合了RMSprop和Momentum两种优化算法的优点。
性能优化通常涉及多次迭代和实验,选择最佳超参数组合是一个需要不断试验和验证的过程。为了系统地选择最优参数,可以使用网格搜索、随机搜索或贝叶斯优化等超参数优化技术。这些技术可以帮助我们更有效地探索参数空间,找到最优的超参数组合。
此外,使用验证集监控模型的性能,结合早停法(early stopping)和模型检查点(model checkpointing)可以防止过拟合,并且可以保存性能最好的模型。早停法会在验证集的性能不再提升时停止训练,而模型检查点会定期保存训练过程中的模型状态。
4. Keras库中VGG16模型的加载与自定义
4.1 Keras框架的特点及优势
4.1.1 Keras框架概述
Keras 是一个开源的神经网络库,最初由 Francois Chollet 设计和开发,旨在实现快速实验。Keras 最大的特点之一是其模块化和易扩展性,它允许研究人员和开发者轻松地设计和测试新的架构。作为 TensorFlow 的高级API,Keras 简化了模型的构建过程,提供了一套简洁而直观的接口,使得深度学习模型的创建、训练和部署变得更加容易和直观。
Keras 设计哲学强调最小化用户的工作量,这意味着它专注于快速实验。在 Keras 中,用户可以迅速构建原型,而不需要编写大量的代码。这种特性使得 Keras 在教学和学术研究中尤其受到欢迎。同时,Keras 支持多种后端引擎,如 TensorFlow、Microsoft Cognitive Toolkit (CNTK) 和 Theano,为研究人员提供了灵活的选择。
4.1.2 Keras与VGG16模型的结合使用
在 Keras 中,VGG16 模型已经被预构建并可以很容易地加载和使用。这种预构建模型可以显著减少开发时间,因为它允许研究人员跳过构建和训练模型的初期阶段。Keras 提供了一个名为 applications 的模块,其中包括了多种预训练模型,如 VGG16、VGG19、ResNet 和 Inception 等。这些预训练模型可以被用于图像分类、特征提取、迁移学习等任务。
通过 Keras 加载 VGG16 模型,用户可以利用在 ImageNet 等大规模数据集上预训练的权重。这为用户提供了两个主要优势:一是可以使用一个已经具备复杂特征提取能力的模型,二是能够通过微调模型来适应特定的图像处理任务。
4.2 自定义VGG16模型的流程
4.2.1 修改VGG16模型的层结构
在某些情况下,可能需要修改预训练的 VGG16 模型以适应特定任务的需求。这可能涉及到替换最后一层的全连接层以匹配新的分类数,或者移除顶部的几层并添加新的层以适应不同的任务。
from keras.applications import VGG16
from keras.layers import Dense, Flatten
from keras.models import Model# 加载预训练的 VGG16 模型
base_model = VGG16(weights='imagenet', include_top=False)# 添加新的顶层
x = base_model.output
x = Flatten()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x) # 假设我们有10个类别# 构建最终的模型
model = Model(inputs=base_model.input, outputs=predictions)# 冻结 VGG16 的所有层
for layer in base_model.layers:layer.trainable = False# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
在上述代码中,我们首先加载了 VGG16 模型,但是不包括顶层。接着,我们添加了两个全连接层来完成分类任务。然后,我们构建了一个新的模型,这个模型以原始 VGG16 模型的输入为基础,以新的顶层输出为终点。在编译模型之前,我们还需要冻结 VGG16 层,这意味着在训练过程中这些层的权重将保持不变。
4.2.2 实现特定任务的自定义VGG16模型
在根据特定任务对模型进行修改之后,下一步就是训练和评估这个模型。如果是为了适应一个新的数据集,通常需要对模型进行微调。微调是指对模型进行少量训练,使模型适应新的数据分布。在微调过程中,可以选择性地解冻部分层,并在较小的学习率下重新训练这些层。
from keras.preprocessing.image import ImageDataGenerator# 创建图像数据生成器
train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)# 假设我们的训练和测试数据分别在 train_dir 和 test_dir 文件夹中
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(224, 224), batch_size=32, class_mode='categorical')
test_generator = test_datagen.flow_from_directory(test_dir, target_size=(224, 224), batch_size=32, class_mode='categorical')# 训练模型
model.fit_generator(train_generator, steps_per_epoch=100, epochs=10, validation_data=test_generator, validation_steps=50)
在上述代码中,我们使用了 Keras 的 ImageDataGenerator 类来实时地对图像数据进行增强。数据增强是提高模型泛化能力的有效手段,它可以通过对图像进行随机变换来生成新的训练样本。接着,我们使用 fit_generator 方法来训练模型。由于我们是在微调模型,因此可以设置较小的 epochs 值,并选择性地解冻顶部的一些层进行训练。
通过上述步骤,我们可以实现一个针对特定任务的自定义 VGG16 模型,同时保证模型在面对新任务时依然具有较高的准确性和泛化能力。
5. Jupyter Notebook在图像处理项目中的应用
Jupyter Notebook 是一款广泛用于数据清洗、转换、可视化以及机器学习的开源Web应用程序,特别适合于数据分析和科学计算。由于其支持多种编程语言,交互式和可复现的笔记记录等特点,在图像处理项目中尤为受欢迎。
5.1 Jupyter Notebook的介绍和安装
5.1.1 Jupyter Notebook的基本功能
Jupyter Notebook 提供了一个在浏览器中运行的交互式编程环境,让用户可以将代码、文本、公式、图像、视频等多种内容元素集成在一个文档中。其核心功能包括:
- 代码执行与结果展示:用户可以输入代码并立即执行,查看输出结果。
- 多种内核支持:Jupyter支持Python、R、Julia等多种编程语言的内核。
- 富文本编辑:用户可以插入Markdown、HTML等格式的富文本内容。
- 交互式小部件:集成的滑动条、按钮等小部件使文档变为可交互式文档。
- 文件管理:能够方便地管理用户的工作目录中的文件和文件夹。
5.1.2 如何在图像处理项目中安装和配置Jupyter Notebook
为了在图像处理项目中使用 Jupyter Notebook,你需要按照以下步骤进行安装和配置:
- 安装 Jupyter Notebook:
bash pip install notebook - 启动 Jupyter Notebook 服务:
bash jupyter notebook - 确保你的环境(如Python、TensorFlow等)已经安装并配置好,以便在 Notebook 中使用。
安装完成后,你可以通过浏览器访问显示的URL(通常为 http://localhost:8888 ),开始创建你的图像处理项目Notebook。
5.2 Jupyter Notebook在VGG16项目中的应用实践
5.2.1 使用Jupyter Notebook进行模型训练和调试
在 Jupyter Notebook 中进行 VGG16 模型训练和调试是一个直观的过程。你可以按照以下步骤操作:
-
导入必要的库:
python import numpy as np from keras.applications.vgg16 import VGG16 from keras.preprocessing.image import ImageDataGenerator -
加载预训练的 VGG16 模型并进行微调:
python model = VGG16(weights='imagenet', include_top=False) # 添加自定义层进行微调 x = model.output x = Flatten()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(num_classes, activation='softmax')(x) # 构建新的模型 from keras.models import Model new_model = Model(inputs=model.input, outputs=predictions) -
使用 ImageDataGenerator 进行数据增强:
python train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1./255) # 以小批量加载数据 train_generator = train_datagen.flow_from_directory(train_dir, target_size=(img_height, img_width), batch_size=batch_size, class_mode='categorical') validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(img_height, img_width), batch_size=batch_size, class_mode='categorical') -
训练模型并进行可视化监控:
python new_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) history = new_model.fit_generator(train_generator, steps_per_epoch=nb_train_samples/batch_size, epochs=epochs, validation_data=validation_generator, validation_steps=nb_validation_samples/batch_size)
5.2.2 Jupyter Notebook在数据可视化中的应用
Jupyter Notebook 通过内嵌的matplotlib库或seaborn库,提供数据可视化的强大支持,这对于在图像处理项目中的调试和结果展示非常有帮助。以下是一个简单的可视化例子:
- 使用 matplotlib 绘制训练过程中的准确率和损失值: ```python import matplotlib.pyplot as plt
# 绘制训练 & 验证的准确率值 plt.plot(history.history['accuracy']) plt.plot(history.history['val_accuracy']) plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train', 'Test'], loc='upper left') plt.show()
# 绘制训练 & 验证的损失值 plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.title('Model loss') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(['Train', 'Test'], loc='upper left') plt.show() ```
5.3 VGG16模型在实际项目中的训练与评估流程
5.3.1 训练数据的准备和预处理
在开始训练之前,需要对数据进行清洗、标注、格式转换等预处理操作。通常这些数据会被组织成结构化的文件夹,每个类别作为子文件夹存储图片。
train_data_dir = 'data/train'
validation_data_dir = 'data/validation'# 图像大小和批大小设置
img_width, img_height = 150, 150
batch_size = 32
epochs = 50
5.3.2 模型训练的参数设置和训练过程监控
在模型训练之前,需要对模型进行适当的参数设置。这些参数包括优化器类型、损失函数、评估指标等。
from keras.optimizers import RMSpropmodel.compile(loss='categorical_crossentropy', optimizer=RMSprop(lr=1e-4), metrics=['accuracy'])history = model.fit_generator(... # 与上一节相同
监控训练过程可以通过查看训练日志,或者使用TensorBoard等可视化工具。
5.3.3 模型评估的标准和方法
模型评估是模型训练后的一个重要步骤。一般使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)等指标来评估模型性能。
from keras.metrics import top_k_categorical_accuracy
from sklearn.metrics import classification_reportdef top_3_accuracy(y_true, y_pred):return top_k_categorical_accuracy(y_true, y_pred, k=3)# 在测试集上进行评估
scores = model.evaluate(validation_generator, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
通过以上方法,你可以对你的VGG16模型进行有效的训练和评估,进一步优化你的图像处理项目。
本文还有配套的精品资源,点击获取
简介:VGG16,作为深度学习领域的里程碑,以其独特的16层深度网络架构在2014年ILSVRC中取得突破。该模型主要采用3x3的小型卷积核,通过深层次的卷积层堆叠来提升模型复杂度。VGG16通常作为预训练模型,用于图像分类、物体检测等计算机视觉任务的特征提取或微调。在Python中,Keras库简化了VGG16模型的加载与应用,并允许开发者通过移除顶层全连接层、添加自定义层来适配新的分类任务。本项目通过Jupyter Notebook展示了VGG16模型在图像处理中的应用,以及如何进行模型训练与评估。项目文件包括数据处理、模型构建、训练和评估的完整流程。
本文还有配套的精品资源,点击获取