论文地址:https://arxiv.org/abs/2505.04588v2
摘要
有效的的信息搜索对于增强大型语言模型 (LLM) 的推理和生成能力至关重要。 最近的研究探索了使用强化学习 (RL) 通过与现实世界环境中的实时搜索引擎交互来提高 LLM 的搜索能力。 虽然这些方法显示出可喜的结果,但它们面临着两大挑战: (1) 不可控的文档质量:搜索引擎返回的文档质量往往不可预测,会在训练过程中引入噪声和不稳定性。 (2) 过高的 API 成本:RL 训练需要频繁的推出,可能涉及数十万次搜索请求,这会产生大量的 API 成本,并严重限制可扩展性。 为了应对这些挑战,我们引入了 ZeroSearch,这是一个强化学习框架,它无需与真实的搜索引擎交互即可激励 LLM 的搜索能力。 我们的方法首先进行轻量级的监督微调,将 LLM 转换为能够根据查询生成相关和噪声文档的检索模块。 在 RL 训练期间,我们采用基于课程推出策略,逐步降低生成的文档质量,通过将其暴露于越来越具有挑战性的检索场景中,逐步激发模型的推理能力。 大量的实验表明,ZeroSearch 使用 3B LLM 作为检索模块有效地激励了 LLM 的搜索能力。 值得注意的是,7B 的检索模块实现了与真实搜索引擎相当的性能,而 14B 的检索模块甚至超过了它。 此外,它在各种参数规模的基础模型和指令微调模型中都具有良好的泛化能力,并且与各种 RL 算法兼容。
1、引言
大型语言模型 (LLM) [36, 3, 45] 在广泛的下游任务中表现出卓越的性能,包括数学推理、问答和代码生成 [38, 39, 11, 22]。 然而,这些模型中编码的知识本质上是静态的,受到预训练期间遇到数据的范围的限制。 结果,LLM 仍然容易产生幻觉内容或过时信息 [13, 34, 44],这会影响其在实际应用中的可靠性。 因此,使大型语言模型 (LLM)能够访问外部信息来源以生成更准确、更可靠的响应至关重要。
解决这个问题的一种广泛采用的方法是检索增强生成 (RAG),它将外部知识整合到生成流程中 [29, 33, 30, 6, 2, 27]。 这方面早期的工作集中在基于提示的策略上,这些策略引导大型语言模型进行查询生成、查询分解和多轮信息检索 [43, 28, 42, 16, 33, 23]。 虽然有效,但这些策略通常需要细致的提示工程,并且对模型的推理能力提出了很高的要求。 为了提高效率,后续研究探索了监督微调 (SFT) 以提高小型大型语言模型的性能 [1, 24, 12]。 进一步的研究集中在测试时缩放技术 [25, 15, 46, 14] 上,例如蒙特卡洛树搜索 (MCTS),它在推理过程中动态扩展搜索空间。 虽然很有前景,但这些方法会产生大量的计算开销,这对实际部署提出了挑战。
最近,强化学习 (RL) 已成为一种很有前景的策略,可通过增强其推理和决策能力来进一步提高大型语言模型的性能 [7, 9]。 值得注意的是,基于强化学习的模型,例如 OpenAI-o1 和 DeepSeek-R1,在逻辑推理和迭代推理方面取得了显著进展——这是纯粹通过奖励驱动的学习实现的,无需依赖显式的逐步监督 [20]。 在这种范例中,一些研究探索了使用强化学习来训练策略模型,这些模型可以更有效地搜索相关信息。 代表性的例子包括 Search-R1 [17]、R1-Searcher [35] 和 ReSearch [19]。 值得注意的是,DeepResearcher [47] 引入了与 Google 等商业搜索引擎的实时交互,允许模型在一个与现实世界网络搜索非常相似的环境中进行训练。 尽管取得了这些进展,但将强化学习与现实世界的搜索场景相集成仍然面临着巨大的挑战: (1) 文档质量不受控制:从实时搜索引擎检索到的文档质量往往不可预测,这会在训练过程中引入噪声和不稳定性。 (2) 过高的 API 成本:强化学习训练需要频繁的展开,可能涉及数十万次 API 调用,这会产生大量的财务成本并严重限制可扩展性。
为了应对这些挑战,我们提出了 ZeroSearch——一个强化学习框架,它使大型语言模型能够学习搜索策略,而无需与真实的搜索引擎交互。 我们的关键见解是 大型语言模型在大型预训练过程中已经获得了广泛的世界知识,并且能够根据搜索查询生成相关的文档 [43]。 真实搜索引擎和模拟大语言模型 (LLM) 的主要区别在于返回内容的文本风格。 然而,通过轻量级的监督微调,即使是相对较小的LLM也能有效地模拟真实搜索引擎的行为。 除了消除API成本外,使用LLM生成文档的一个重要优势在于能够控制文档质量。 具体来说,在监督微调期间,通过提示设计区分导致正确或错误答案的文档,使模拟LLM能够仅仅通过调整提示中的几个词语来学习生成相关或噪声文档。 基于此,我们在训练过程中引入了一种课程展开机制,其中生成文档的质量会随着时间的推移逐渐下降,以模拟越来越具有挑战性的检索场景。 这使得策略模型能够首先学习基本的输出格式和任务要求,然后逐步适应更具挑战性和噪声的检索场景。 更重要的是,ZeroSearch表现出强大的可扩展性:增加GPU数量可以显著加快模拟LLM的生成吞吐量,从而实现高效的大规模展开。 实验结果表明,即使是作为模拟搜索引擎使用的3B LLM也能有效地激励策略模型的搜索能力。 一个7B的检索模块实现了与谷歌搜索相当的性能,而一个14B的检索模块甚至超过了它。 ZeroSearch兼容各种参数大小的基础模型和指令调优模型,无需单独的监督预热阶段。 此外,它与广泛使用的强化学习算法无缝集成,包括近端策略优化(PPO)[31]、组相对策略优化(GRPO)[32, 7]和Reinforce++[10]。
我们的贡献可以总结如下:
- 我们提出了ZeroSearch,这是一个新颖的强化学习框架,它能够在不与真实搜索引擎交互的情况下激励LLM的搜索能力。
- 通过监督微调,我们将LLM转换为一个检索模块,能够根据查询生成相关和噪声文档。 我们进一步引入了一种课程展开机制,通过将其暴露于越来越具有挑战性的检索场景中来逐步激发模型的推理能力。
- 我们在领域内和领域外数据集上进行了大量的实验。 结果表明,ZeroSearch 的性能优于基于真实搜索引擎的模型,同时无需任何 API 成本。 此外,它在各种参数规模的基础大型语言模型和指令微调大型语言模型上都具有良好的泛化能力,并支持不同的强化学习算法。
2、相关工作
2.1、检索增强生成
检索增强生成 (RAG) 通过将相关的外部知识集成到生成流程中来增强生成性能。 早期研究主要采用基于提示的方法,通过查询生成、查询分解和多轮信息检索等过程来指导大型语言模型[43, 28, 42, 16, 33, 23]。 尽管这些方法有效,但它们通常需要复杂的提示工程,并对模型的推理能力提出相当大的要求。 为了提高效率并减少对强大黑盒大型语言模型的依赖,后续工作提出了针对较小型语言模型的监督微调策略。 例如,Self-RAG [1] 采用了一种自我反思机制,通过预测的反思符元迭代地细化模型输出。 RetroLLM [24] 通过使模型能够通过约束解码直接从语料库生成细粒度的证据来集成检索和生成。 最近的进展还包括测试时缩放技术[25, 15, 46, 14],特别是蒙特卡洛树搜索 (MCTS),它在推理过程中动态扩展搜索空间。 例如,RAG-star [14] 将检索到的信息集成到基于树的推理过程中,而 AirRAG [5] 则采用 MCTS 来激活内在推理能力并扩展解决方案空间。 尽管结果令人鼓舞,但这些方法引入了大量的计算开销,限制了它们的实际应用。
2.2、通过强化学习学习搜索
最近,强化学习 (RL) 已成为增强大型语言模型推理能力的一种很有前景的范例[7, 9]。 诸如 OpenAI-o1 和 DeepSeek-R1 等值得注意的基于强化学习的模型已在逻辑推理和迭代推理方面展现出卓越的能力,完全由奖励信号驱动,无需明确的逐步监督[20]。 一些研究也探索了专门设计用于训练模型以实现有效信息检索的强化学习技术。 例如,Search-R1 [17]利用强化学习在逐步推理过程中自主生成多个搜索查询。 类似地,R1-Searcher [35]提出了一种旨在增强搜索能力的两阶段、基于结果的强化学习方法。 ReSearch [19]利用强化学习来训练模型进行搜索推理,完全无需对中间推理步骤进行监督。 然而,这些方法通常使用静态的、局部的文本语料库,例如维基百科,并且无法捕捉现实世界交互的复杂性。 为了弥合这一差距,DeepResearcher [47]引入了与商业搜索引擎(例如谷歌)的直接交互,从而允许创建与现实世界搜索场景非常接近的训练环境。 虽然这些实时检索方法取得了优越的性能,但它们也面临着巨大的挑战,包括不可预测的文档质量、过高的API成本对系统可扩展性造成不利影响。 为了解决这些限制,我们提出了ZeroSearch,这是一种利用大语言模型 (LLM) 模拟实时搜索的方法,有效地消除了对昂贵且速率受限的真实搜索API的依赖。 通过轻量级的监督微调,ZeroSearch允许对文档质量进行显式控制,并实现了一种课程推出机制,从而增强了训练的稳定性和鲁棒性。
3、ZeroSearch
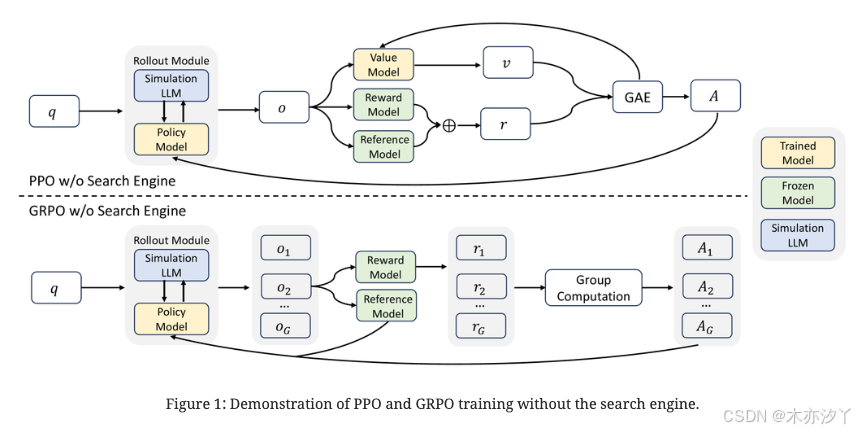
在本节中,我们首先在没有搜索引擎的情况下正式定义强化学习目标。 然后,我们详细介绍ZeroSearch的设计,包括训练模板、搜索模拟调优、基于课程的展开策略、奖励设计和训练算法。
3.1、无需搜索引擎的强化学习
我们提出了一种强化学习框架,通过利用大语言模型 (LLM) 模拟搜索引擎来消除对真实搜索引擎的需求。 优化目标被表述为:
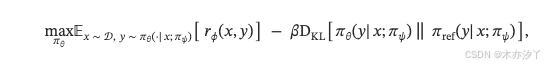
其中 是待优化的策略模型,
是参考模型,并且
表示奖励函数。
代表模拟大语言模型 (LLM),其参数在整个训练过程中保持不变。
3.2、训练模板

在ZeroSearch中,我们并没有依赖于监督微调进行生成,而是遵循[17]并应用一个多轮交互模板,该模板通过迭代推理和信息检索引导策略模型,直到得到最终答案。
如表1所示,交互过程分为三个不同的阶段:首先,模型在<think>...</think>标签内阐述其内部推理过程。 其次,如果需要更多证据,它会在<search>...</search>标签内发出搜索查询。 最后,一旦检索到足够的信息,模型就会在<answer>...</answer>标签内提供其答案。 推理、搜索和回答的这种明确分离强制执行了一个结构化的决策过程,增强了模型的透明度和可靠性。
3.3、搜索模拟调优
在部署过程中,我们使用大语言模型 (LLM) 通过生成响应查询的文档来模拟真实的搜索引擎。 一个直接的方法是直接提示 LLM 生成文档。 然而,这通常会导致与真实搜索引擎输出相比明显的风格差异。
为弥合这一差距,我们提出了一种轻量级的监督微调 (SFT) 程序。 具体来说,我们首先通过提示 LLM 以多轮方式与真实的搜索引擎交互,直到获得最终答案,从而收集交互轨迹。 产生正确答案的轨迹被标记为正样本,表明检索到的文档是有用的;而导致错误答案的轨迹则被标记为负样本,表明检索结果存在噪声。
然后,我们从正样本和负样本轨迹中提取查询-文档对,并执行轻量级 SFT 以提高 LLM 模拟真实搜索引擎的能力。 如表2所示,通过调整提示中的几个词语即可实现对有用和噪声检索结果的区分。 此外,我们还将输入问题及其对应的答案纳入提示中,以拓宽 LLMs 的知识边界。 微调后,LLM 能够生成有用和噪声文档,从而在部署过程中实现动态的文档质量控制。
3.4、基于课程搜索模拟的部署

输入问题和其真实答案也包含在提示中,以帮助扩展模拟LLM的知识覆盖范围。
在部署过程中,策略模型执行交互式推理并生成搜索查询,这些查询被输入到模拟 LLM 中以生成相应的文档。 为了逐步提高训练难度,我们引入了一种基于课程学习的展开机制,其中生成的文档质量会随着时间的推移逐渐下降。 这由一个概率函数控制 该函数控制在步骤中生成噪声文档的可能性 i:
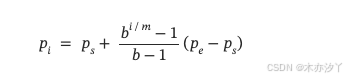
其中, 和
代表初始和最终噪声概率, i 和 m 表示当前和总训练步骤数,而 b 是指数基数,其默认值为 4。 随着训练的进行,比率 i/m 会增加,导致更高的
值——即产生噪声文档的可能性更大。 这使得策略模型能够首先学习基本的输出结构和任务要求,然后再逐步适应更具挑战性和噪声的检索场景。
3.5、奖励设计
奖励信号是强化学习过程中主要的监督信号。 在这项工作中,我们采用了一个基于规则的奖励函数,该函数仅关注答案的准确性。 在预备实验中,我们观察到使用精确匹配 (EM) 作为奖励指标经常会导致奖励作弊:策略模型倾向于生成过长的答案以增加包含正确答案的机会。 为了减轻这个问题,我们采用基于 F1 分数的奖励,它平衡了精确率和召回率,计算公式如下:
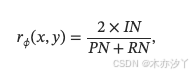
其中 IN 表示预测结果和真实结果之间重叠的单词数量,PN 是预测结果中的单词数量,RN 是真实结果中的单词数量。 我们没有加入关于输出格式的额外奖励,因为我们观察到模型在没有明确监督的情况下始终生成格式良好的响应。
3.6、训练算法
我们的方法与各种强化学习算法兼容,包括近端策略优化 (PPO) [31]、组相对策略优化 (GRPO) [32, 7] 和 Reinforce++ [10],每种算法都为优化检索增强推理提供了独特的优势。
在 ZeroSearch 中,展开序列包含策略模型生成的符元和模拟大语言模型 (LLM) 返回的文档符元。 对这两种类型的符元应用相同的优化过程可能会导致训练不稳定,因为检索到的内容是外部生成的,并且策略模型无法直接控制。
为了减轻这个问题,我们引入了一种针对检索到的符元的损失掩码机制,确保仅针对模型自身的输出计算梯度。 此策略稳定了强化学习训练过程,同时保持了检索增强生成的有效性。
4、主要结果
4.1、数据集和评估指标
我们在各种问答基准上评估了 ZeroSearch: (1) 单跳问答,包括 NQ [21]、TriviaQA [18] 和 PopQA [26]。 (2) 多跳问答,包括 HotpotQA [41]、2WikiMultiHopQA [8]、Musique [37] 和 Bamboogle [28]。
我们遵循 [17] 并采用精确匹配 (EM) 作为我们的评估指标。 如果预测的标准化形式与任何标准化后的真实答案完全匹配,则认为该预测是正确的。
4.2、基线方法
为了评估ZeroSearch的有效性,我们将我们的方法与以下基线方法进行了比较。 (1) 基础提示方法:此类别包括直接提示、思维链 (CoT) 和标准的检索增强生成 (RAG)。 (2) 高级RAG方法:我们考虑了RAgent [23] 和Search-o1 [23],它们迭代地搜索相关信息。 (3) 强化学习调优方法:此类别包括R1和Search-R1 [17]。 在R1中,策略模型被训练成仅基于其内部知识进行深入推理。 相反,Search-R1使策略模型能够在推理过程中多次与真实的搜索引擎交互。
为了确保公平比较,我们采用F1分数作为所有强化学习方法的奖励指标。 值得注意的是,在基于强化学习的搜索基线中, 我们只与Search-R1进行比较,因为它避免了复杂的奖励设计、数据选择或复杂的训练流程。 此设置允许在真实的搜索引擎和我们模拟的搜索引擎之间进行直接和公平的比较。
4.3、实验设置
我们使用三个模型系列进行实验:Qwen-2.5-7B (Base/Instruct) 和 Qwen-2.5-3B (Base/Instruct) [40],以及LLaMA-3.2-3B (Base/Instruct) [4]。 为了模拟现实世界的检索场景,我们通过SerpAPI(1)使用谷歌网页搜索作为外部搜索引擎。 为了确保公平比较,所有方法检索到的文档数量均固定为五个。
对于数据集,遵循[17]中的设置,我们将NQ和HotpotQA的训练集合并,为所有基于微调的方法创建一个统一的数据集。 在七个数据集上进行评估,以评估领域内和领域外的性能。 对于基于提示的基线,我们使用 Instruct 模型,因为基础模型通常难以遵循任务指令。 对于基于强化学习的方法,我们评估基础模型和 Instruct 模型的变体,以评估不同模型类型的泛化能力。
为了训练模拟大语言模型,我们使用 Qwen-2.5-3B、Qwen-2.5-7B 和 Qwen-2.5-14B 作为主干进行轻量级监督微调 (SFT)。 学习率设置为 1e-6。 为了训练ZeroSearch,我们采用了两种强化学习算法:GRPO 和 PPO。 在 GRPO 设置中,策略大语言模型的学习率为 1e-6,每个提示采样五个响应。 在 PPO 设置中,策略大语言模型的学习率为 1e-6,而价值模型的学习率为 1e-5。 我们应用广义优势估计 (GAE),超参数为 λ=1 和 γ=1. 除非另有说明,否则使用 GRPO 作为默认的强化学习算法,并在所有实验中使用 Qwen-2.5-14B 作为默认的模拟大语言模型。
4.4、性能
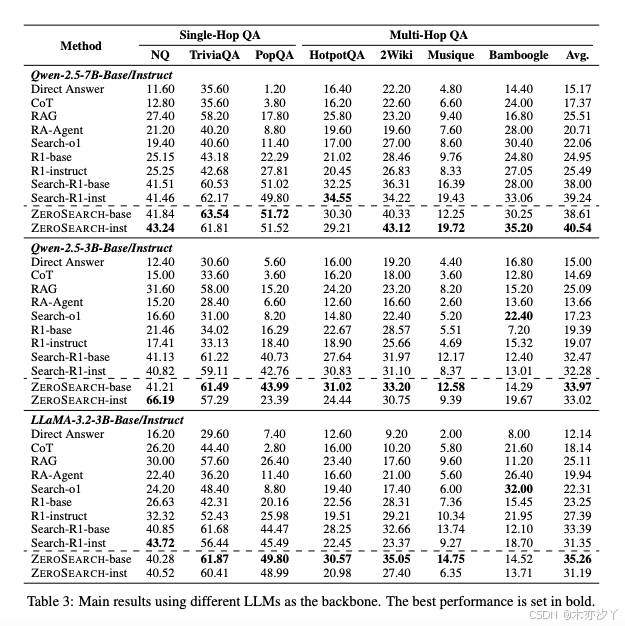
表3 展示了ZeroSearch与七个数据集上的几种基线方法之间的比较。 基于结果,可以得出几个关键观察结果:
ZeroSearch 一直优于所有基线方法。 这种性能优势在领域内数据集(即NQ 和 HotpotQA)和领域外数据集(即TriviaQA、PopQA、2WikiMultiHopQA、Musique 和 Bamboogle)中都适用,证明了我们方法的稳健性。
ZeroSearch 优于依赖真实搜索引擎的方法。 与使用真实搜索引擎的 Search-R1 相比,ZeroSearch 实现了更好的性能,突出了其作为大规模强化学习中真实搜索引擎有效替代方案的潜力。
ZeroSearch 表现出强大的泛化能力。 在不同的模型系列、参数大小和类型(即基础模型或指令调优模型)中,ZeroSearch 一直优于基线。 此外,其性能随着模型规模的增大而进一步提高,突显了其可扩展性。
5、进一步分析
5.1、比较 ZeroSearch 与真实搜索引擎
我们比较了基于Qwen-2.5-3B的Search-R1(使用真实搜索引擎) 和 ZeroSearch奖励曲线,如所示。可以得出几个关键的观察结果:
两种方法的整体奖励趋势相似。 随着训练的进行,ZeroSearch和Search-R1的奖励分数稳步提高,表明两种设置下的策略模型都能有效地学习与搜索引擎交互并产生正确的答案。
ZeroSearch 实现了更稳定、更平滑的学习曲线。 如图2(b)所示,ZeroSearch最初落后于Search-R1,但最终由于课程机制帮助模型逐渐掌握搜索工具的使用,它以更小的波动超越了Search-R1。
ZeroSearch 在基础模型和指令微调模型上都具有良好的泛化能力。 在两种模型类型下,ZeroSearch 的奖励性能稳步提高,突显了其泛化能力。
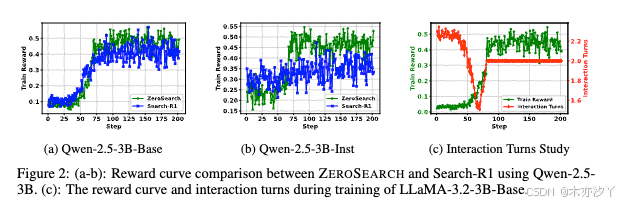
图2: (a-b):使用Qwen-2.5-3B的ZeroSearch和Search-R1的奖励曲线比较。 (c):LLaMA-3.2-3B-base训练期间的交互轮次和奖励进展。
5.2、模拟大语言模型的选择
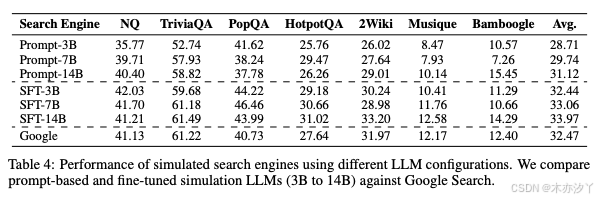
我们将基于提示的方法和经过微调的模拟大语言模型(参数量从 30 亿到 140 亿)与 Google 搜索进行了比较。
在本节中,我们研究了不同的模拟引擎配置如何影响性能,包括参数量从 30 亿到 140 亿不等的基于提示的方法和经过微调的大语言模型。 基于表4中的结果,我们得出以下结论:
首先,经过微调的 70 亿参数模拟引擎 (SFT-7B) 达到了与 Google 搜索相当的性能,而 140 亿参数版本 (SFT-14B) 甚至超越了它。 这证明了在强化学习环境中使用经过良好训练的大语言模型替代真实搜索引擎的可行性。
其次,经过微调的模拟引擎显著优于基于提示的方法。 尽管基于提示的方法明确地引导模拟真实搜索引擎的响应风格,但仍然存在显著的分布差异,导致性能较差。
第三,性能随着模型规模的增大而持续提高。 更大型的模拟大语言模型不仅表现出更强的模拟能力,而且能够更准确地区分相关和不相关的文档,从而在训练过程中实现更有效的课程学习。
5.3、交互轮次研究
在本节中,我们使用 LLaMA3.2-3B-Base 模型,通过检查奖励进程和整个训练过程中的交互轮次数量来分析ZeroSearch的训练动态。 结果如图2(c)所示。
在训练的早期阶段,交互轮次数量急剧下降,而奖励增长缓慢。 这主要是因为策略模型最初缺乏如何正确调用搜索引擎的知识,导致冗余交互。 但是,它很快学习了正确的格式,并开始有效地消除不必要的步骤。
随着训练的进行,交互轮次的数量和奖励曲线都急剧上升,然后趋于稳定。 这主要是因为策略模型能够有效地检索相关文档并最终获得正确答案,从而获得更高的奖励。 值得注意的是,尽管奖励在训练后期看起来很稳定,但由于课程机制,底层任务难度持续上升。 因此,策略必须不断改进其策略并提高其推理能力以保持一致的性能。
5.4、不同的强化学习算法:PPO 与 GRPO
我们使用 Qwen2.5-3B-Base 和 LLaMA-3.2-3B-Base 模型比较了 PPO 和 GRPO。
在本节中,我们使用 Qwen2.5-3B-Base 和 LLaMA-3.2-3B-Base 模型,在ZeroSearch框架内评估了两种广泛采用的强化学习训练算法 PPO 和 GRPO 的性能。 此比较的结果在第5.4节中给出。
如观察到的那样,GRPO 和 PPO 都成功地激励了我们框架内的搜索能力,证明了我们方法的多功能性。 其中,GRPO 在两种模型上都表现出更稳定的性能,突出了其在训练稳定性方面的优势。 还值得注意的是,GRPO 中的重复展开机制在与真实的搜索引擎交互时会产生更高的 API 成本,进一步突出了我们模拟搜索设置的实用性。
5.5、反向课程学习
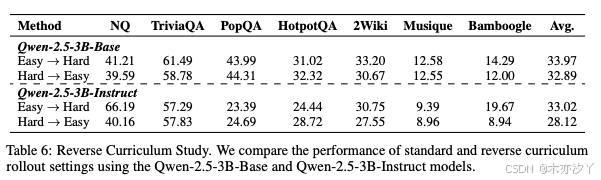
我们使用 Qwen-2.5-3B-Base 和 Qwen-2.5-3B-Instruct 模型比较了标准和反向课程展开设置的性能。
本节通过与反向课程设置进行比较,分析了课程展开策略的有效性,在反向课程设置中,训练难度随着检索文档质量的逐步提高而降低。 结果在第5.5节中给出。
结果清楚地表明,标准的易到难课程在两种模型中始终优于反向的难到易变体,这支持了课程学习在我们框架中的有效性。 从更好的搜索结果开始,允许策略模型首先学习如何调用搜索引擎并理解基本的输出格式。 随着训练的进行,模型会接触到越来越具有挑战性的场景,从而培养更强的推理能力。
6、结论
在本文中,我们提出了ZeroSearch,这是一种新颖的强化学习框架,它能够增强大型语言模型的搜索能力,而无需与真实的搜索引擎交互。 通过监督微调,大型语言模型被转化为一个检索模块,能够生成相关和噪声文档。 采用课程展开机制,通过将模型暴露于越来越具有挑战性的检索场景中来逐步改进推理能力。 实验结果表明,ZeroSearch优于基于真实搜索的模型,在不同大小的基础模型和指令微调大型语言模型上都具有良好的泛化能力,并支持各种强化学习算法。
然而,我们的方法也有一定的局限性。 部署模拟搜索大型语言模型需要访问GPU服务器。 虽然比商业API的使用更经济有效,但这会带来额外的基础设施成本。 我们在附录中详细讨论了这些成本。
参考文献
-
[1]A. Asai, Z. Wu, Y. Wang, A. Sil, and H. Hajishirzi.Self-rag: Learning to retrieve, generate, and critique through self-reflection.In The Twelfth International Conference on Learning Representations, 2023.
-
[2]B. Bohnet, V. Q. Tran, P. Verga, R. Aharoni, D. Andor, L. B. Soares, J. Eisenstein, K. Ganchev, J. Herzig, K. Hui, et al.Attributed question answering: Evaluation and modeling for attributed large language models.arXiv preprint arXiv:2212.08037, 2022.
-
[3]A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, et al.Palm: Scaling language modeling with pathways.arXiv preprint arXiv:2204.02311, 2022.
-
[4]A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al.The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024.
-
[5]W. Feng, C. Hao, Y. Zhang, J. Song, and H. Wang.Airrag: Activating intrinsic reasoning for retrieval augmented generation via tree-based search.arXiv preprint arXiv:2501.10053, 2025.
-
[6]L. Gao, Z. Dai, P. Pasupat, A. Chen, A. T. Chaganty, Y. Fan, V. Y. Zhao, N. Lao, H. Lee, D.-C. Juan, et al.Rarr: Researching and revising what language models say, using language models.arXiv preprint arXiv:2210.08726, 2022.
-
[7]Y. Guo, L. Hou, R. Shao, P. G. Jin, V. Kumar, W. Weng, Y. Xie, and T.-Y. Liu.Deepseek-r1: Reinforcement learning for retrieval-augmented generation in large language models.arXiv preprint arXiv:2503.01234, 2025.
-
[8]X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa.Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps.arXiv preprint arXiv:2011.01060, 2020.
-
[9]Y. Hou and et al.Rl-based learning for reasoning and decision-making in large language models.In ACL, 2025.
-
[10]J. Hu.Reinforce++: A simple and efficient approach for aligning large language models.arXiv preprint arXiv:2501.03262, 2025.
-
[11]S. Imani, L. Du, and H. Shrivastava.Mathprompter: Mathematical reasoning using large language models.arXiv preprint arXiv:2303.05398, 2023.
-
[12]S. Jeong, J. Baek, S. Cho, S. J. Hwang, and J. C. Park.Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity.arXiv preprint arXiv:2403.14403, 2024.
-
[13]Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. J. Bang, A. Madotto, and P. Fung.Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023.
-
[14]J. Jiang, J. Chen, J. Li, R. Ren, S. Wang, W. X. Zhao, Y. Song, and T. Zhang.Rag-star: Enhancing deliberative reasoning with retrieval augmented verification and refinement.arXiv preprint arXiv:2412.12881, 2024.
-
[15]J. Jiang, Z. Chen, Y. Min, J. Chen, X. Cheng, J. Wang, Y. Tang, H. Sun, J. Deng, W. X. Zhao, et al.Technical report: Enhancing llm reasoning with reward-guided tree search.arXiv preprint arXiv:2411.11694, 2024.
-
[16]Z. Jiang, F. F. Xu, L. Gao, Z. Sun, Q. Liu, J. Dwivedi-Yu, Y. Yang, J. Callan, and G. Neubig.Active retrieval augmented generation.In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969–7992, 2023.
-
[17]B. Jin, H. Zeng, Z. Yue, D. Wang, H. Zamani, and J. Han.Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025.
-
[18]M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer.Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension.arXiv preprint arXiv:1705.03551, 2017.
-
[19]R. Kumar and et al.Research: Autonomous retrieval decision-making in llms using reinforcement learning.In ICLR, 2025.
-
[20]V. Kumar, L. Hou, Y. Guo, R. Shao, P. G. Jin, W. Weng, Y. Xie, and T.-Y. Liu.Self-correcting language models with reinforcement learning.arXiv preprint arXiv:2409.06543, 2024.
-
[21]T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee, et al.Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019.
-
[22]A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V. Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo, et al.Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35:3843–3857, 2022.
-
[23]X. Li, G. Dong, J. Jin, Y. Zhang, Y. Zhou, Y. Zhu, P. Zhang, and Z. Dou.Search-o1: Agentic search-enhanced large reasoning models.arXiv preprint arXiv:2501.05366, 2025.
-
[24]X. Li, J. Jin, Y. Zhou, Y. Wu, Z. Li, Q. Ye, and Z. Dou.Retrollm: Empowering large language models to retrieve fine-grained evidence within generation.arXiv preprint arXiv:2412.11919, 2024.
-
[25]X. Li, W. Xu, R. Zhao, F. Jiao, S. Joty, and L. Bing.Can we further elicit reasoning in llms? critic-guided planning with retrieval-augmentation for solving challenging tasks.arXiv preprint arXiv:2410.01428, 2024.
-
[26]A. Mallen, A. Asai, V. Zhong, R. Das, H. Hajishirzi, and D. Khashabi.When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories.arXiv preprint arXiv:2212.10511, 7, 2022.
-
[27]J. Menick, M. Trebacz, V. Mikulik, J. Aslanides, F. Song, M. Chadwick, M. Glaese, S. Young, L. Campbell-Gillingham, G. Irving, et al.Teaching language models to support answers with verified quotes.arXiv preprint arXiv:2203.11147, 2022.
-
[28]O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis.Measuring and narrowing the compositionality gap in language models.arXiv preprint arXiv:2210.03350, 2022.
-
[29]O. Ram, Y. Levine, I. Dalmedigos, D. Muhlgay, A. Shashua, K. Leyton-Brown, and Y. Shoham.In-context retrieval-augmented language models.arXiv preprint arXiv:2302.00083, 2023.
-
[30]H. Rashkin, V. Nikolaev, M. Lamm, L. Aroyo, M. Collins, D. Das, S. Petrov, G. S. Tomar, I. Turc, and D. Reitter.Measuring attribution in natural language generation models.arXiv preprint arXiv:2112.12870, 2021.
-
[31]J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov.Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017.
-
[32]Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al.Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024.
-
[33]W. Shi, S. Min, M. Yasunaga, M. Seo, R. James, M. Lewis, L. Zettlemoyer, and W.-t. Yih.Replug: Retrieval-augmented black-box language models.arXiv preprint arXiv:2301.12652, 2023.
-
[34]K. Shuster, S. Poff, M. Chen, D. Kiela, and J. Weston.Retrieval augmentation reduces hallucination in conversation.arXiv preprint arXiv:2104.07567, 2021.
-
[35]H. Song, J. Jiang, Y. Min, J. Chen, Z. Chen, W. X. Zhao, L. Fang, and J.-R. Wen.R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592, 2025.
-
[36]R. Taylor, M. Kardas, G. Cucurull, T. Scialom, A. Hartshorn, E. Saravia, A. Poulton, V. Kerkez, and R. Stojnic.Galactica: A large language model for science.CoRR, abs/2211.09085, 2022.
-
[37]H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal.Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022.
-
[38]S. Xia, X. Li, Y. Liu, T. Wu, and P. Liu.Evaluating mathematical reasoning beyond accuracy.arXiv preprint arXiv:2404.05692, 2024.
-
[39]R. Yamauchi, S. Sonoda, A. Sannai, and W. Kumagai.Lpml: llm-prompting markup language for mathematical reasoning.arXiv preprint arXiv:2309.13078, 2023.
-
[40]A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, et al.Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024.
-
[41]Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning.Hotpotqa: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600, 2018.
-
[42]O. Yoran, T. Wolfson, B. Bogin, U. Katz, D. Deutch, and J. Berant.Answering questions by meta-reasoning over multiple chains of thought.arXiv preprint arXiv:2304.13007, 2023.
-
[43]W. Yu, D. Iter, S. Wang, Y. Xu, M. Ju, S. Sanyal, C. Zhu, M. Zeng, and M. Jiang.Generate rather than retrieve: Large language models are strong context generators.arXiv preprint arXiv:2209.10063, 2022.
-
[44]J. Zhang, Z. Li, K. Das, B. Malin, and S. Kumar.Sac3: Reliable hallucination detection in black-box language models via semantic-aware cross-check consistency: Reliable hallucination detection in black-box language models via semantic-aware cross-check consistency.In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 15445–15458, 2023.
-
[45]W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, et al.A survey of large language models.arXiv preprint arXiv:2303.18223, 2023.
-
[46]Y. Zhao, H. Yin, B. Zeng, H. Wang, T. Shi, C. Lyu, L. Wang, W. Luo, and K. Zhang.Marco-o1: Towards open reasoning models for open-ended solutions.arXiv preprint arXiv:2411.14405, 2024.
-
[47]Y. Zheng, D. Fu, X. Hu, X. Cai, L. Ye, P. Lu, and P. Liu.Deepresearcher: Scaling deep research via reinforcement learning in real-world environments.arXiv preprint arXiv:2504.03160, 2025.