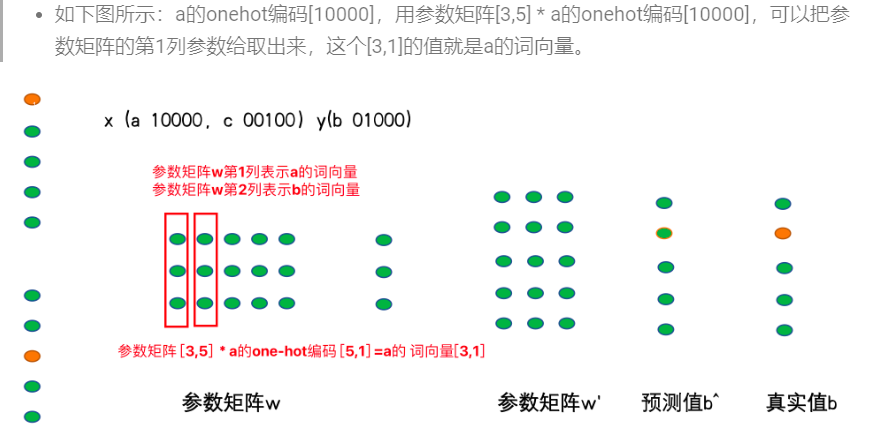
一. ElasticSearch简介
ElasticSearch 是一个基于 Lucene 构建的开源、分布式、RESTful 风格的搜索和分析引擎。

1. 核心功能
-
强大的搜索能力
- 它能够提供全文检索功能。例如,在海量的文档数据中,可以快速准确地查找到包含特定关键词的文档。这在处理诸如电商产品目录(可以按照产品名称等文本内容搜索)、新闻文章数据库(能依据标题或正文关键词检索新闻)等场景下非常有用。
- 支持多种搜索方式,如简单搜索、短语搜索、模糊搜索等。模糊搜索可以处理用户输入的拼写错误等情况,并且还能进行通配符搜索,像在搜索框中输入 “comput*” 就可以匹配到 “computer”“computing” 等词。
-
数据分析功能强大
- 可以执行聚合操作,对数据进行统计分析。比如在电商销售数据中,通过聚合操作可以计算出不同产品的销售额总和、平均销售额,或者按地域统计订单数量等。这些聚合操作可以帮助企业进行商业智能分析,了解业务发展趋势和用户行为模式。
-
高性能
- ElasticSearch 采用倒排索引的原理,这是一种非常高效的文本检索数据结构。并且它是分布式系统,能够将数据分散存储在多个节点上,这样在搜索和分析时可以充分利用多台服务器的资源,提高查询速度。例如,在一个大型的互联网公司中,面对海量的用户日志数据,ElasticSearch 可以快速响应查询请求,几乎不影响用户体验。
-
高扩展性和高可用性
- 它很容易进行横向扩展,可以通过添加新的节点来增加系统的处理能力和存储容量。同时,它具有副本机制,可以确保数据的安全性和高可用性。即使某个节点出现故障,数据也不会丢失,其他节点可以继续提供服务。这对于关键业务系统,如金融交易系统中的数据存储和查询来说至关重要,能够保证业务的连续性。
2. 应用场景
-
日志分析
- 在企业的 IT 基础设施中,服务器、应用程序等会产生大量的日志。ElasticSearch 可以收集、存储和分析这些日志数据,帮助运维人员快速定位系统故障。例如,通过分析 Web 服务器的日志,可以找出访问量高峰时段、响应时间过长的页面等信息,从而优化服务器性能。
-
企业搜索
- 可以将企业的内部文档(如员工手册、项目文档等)、知识库等数据整合到 ElasticSearch 中。员工可以通过简单易用的搜索界面快速找到所需信息,提高工作效率。比如,在大型律师事务所中,律师可以利用它快速检索相关的法律案例文件。
-
电商搜索和推荐系统
- 对于电商平台,ElasticSearch 可以提供强大的商品搜索功能。它能够根据用户的搜索词,快速返回匹配的商品列表,并且结合用户的行为数据(如浏览历史、购买记录等)进行个性化推荐。例如,当用户搜索 “运动鞋” 时,可以准确地展示各种品牌、型号的运动鞋,并且根据用户的偏好推荐相关的篮球鞋、跑步鞋等。
二. 常用操作命令
1. 创建索引
PUT http://<主机IP地址>:9200/<索引名称>
PUT http://10.0.1.2:9200/company{"settings": {// 将主分片数量"number_of_shards": 10,// 设置副本数量"number_of_replicas": 1}
}
2. 检索索引信息
GET http://<主机IP地址>:9200/<索引名称>
3. 删除索引信息
DELETE http://<主机IP地址>:9200/<索引名称>
4. 文档操作
4.1 新增文档,并指定ID
POST http://<主机IP地址>:9200/<索引名称>/_doc/<文档ID>
POST http://10.0.1.2:9200/company/_doc/123412341415{"company_name": "百胜中国有限公司","legal_name": "张三","tags": ["供应链管理", "餐饮服务"]
}
4.2 新增文档,不指定文档ID,系统采用随机文档ID
POST http://<主机IP地址>:9200/<索引名称>/_doc
POST http://10.0.1.2:9200/company/_doc{"company_name": "百胜中国有限公司","legal_name": "张三","tags": ["供应链管理", "餐饮服务"]
}
4.3 获取指定文档信息
GET http://<主机IP地址>:9200/<索引名称>/_doc/<文档ID>
GET http://10.0.1.2:9200/company/_doc/123412341415
4.4 更新文档
PUT http://<主机IP地址>:9200/<索引名称>/_doc/<文档ID>
PUT http://10.0.1.2:9200/company/_doc/123412341415{ "doc": {"legal_name": "李四","tags": ["供应链管理", "餐饮服务", "数字供应链"]}
}
4.5 删除文档
DELETE http://<主机IP地址>:9200/<索引名称>/_doc/<文档ID>
5. 查看所有的文档列表
GET http://<主机IP地址>:9200/_cat/indices?v
GET http://10.0.1.2:9200/_cat/indices?v
6. 查询
6.1 匹配查询
GET http://<主机IP地址>:9200/<索引名称>/_search
GET http://10.0.1.2:9200/company/_search?pretty{"query": {"match": {"legal_name": "李四"}}
}
match查询:
- 作用:用于在文本字段中执行全文检索,查找包含指定词语或短语的文档
- 使用场景:适用于执行基于文本内容的搜索,比如在公司名称、法人代表查找特定关键词。
6.2 范围查询
GET http://<主机IP地址>:9200/<索引名称>/_search
{"query": {"range": {"age": {"gte": 20,"lte": 35}}},// 设置查询返回数量size: <返回数据量>
}
- range: 指定进行范围查询
- age: 指定要进行查询的字段名称(属性名称)
- gte: 表示大于等于某个值
- lte: 表球小于等于某个值
6.3 布尔查询
GET http://<主机IP地址>:9200/<索引名称>/_search
{"query": {"bool": {"must": [{"match": {"company_name": "生物科技" },}, {"range": {"establish_year": {"gte": 3}}}],"must_not": [{"match": {"status": "注销"}}],"should": [{"match": {"province": "广东省"}}], "minimum_should_match": 1}},// 设置查询返回数量size: <返回数据量>
}
上述内容用于构建复杂“Elastic”查询逻辑, 包括以下几个部分:
- must: 指定了所有这些条件必须满足的查询子句;
- must_not: 指定了文档不能匹配的条件;
- should: 指定了一个可选条件,如果满足则增加文档的匹配分数;
- minimum_should_match: 指定了至少满足几个“should”查询条件,默认是0。
6.4 分页查询
GET http://<主机IP地址>:9200/<索引名称>/_search
{"query": {// 查询条件"range": {"age": {"gte": 20,"lte": 35}}},// 从第一个文档开始,类似于MySQL的offsetfrom: 0,// 设置查询返回数量size: <返回数据量>
}
使用from和size参数来实现分页:
- from: 指定了查询结果中的偏移量,类似于MySQL的offset;
- size: 指定了每页返回的文档数
6.5 多字段匹配查询
多字段查询可使用的匹配类型为multi_match,multi_match与match类似,不同的是它可以在多个字段中进行查询。
GET http://<主机IP地址>:9200/<索引名称>/_search
{"query": {// 查询条件"multi_search": {"query": "医疗器械","fields": ["company_name","business_scope"]}},// 从第一个文档开始,类似于MySQL的offsetfrom: 0,// 设置查询返回数量size: <返回数据量>
}
6.6 关键字精准查询
使用term(单关键字)/terms(多关键字)查询,精确的关键词匹配查询,不对查询条件进行分词。
GET http://<主机IP地址>:9200/<索引名称>/_search
1. 单关键词查询{"query": {"term": {"legal_name": "张三"}}
}2. 多关键词查询{"query": {"terms": {"legal_name": ["张三", "李四"]}}
}
6.7 指定字段查询
默认情况下,Elasticsearch在搜索的结果中,会将文档中保存到在source的所有字段都返回,如果只想返回某些字段,可以添加source进行过滤。
GET http://<主机IP地址>:9200/<索引名称>/_search
{"_source": ["company_name", "legal_name", "credit_code", "business_scope"],"query": {"term": {"legal_name": "张三"}}
}
6.8 过滤字段查询
使用includes和excludes两个字段
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
GET http://<主机IP地址>:9200/<索引名称>/_search
{"_source": {"includes": ["company_name", "legal_name", "credit_code", "business_scope"],"excludes": ["create_time", "update_time"]},"query": {"term": {"legal_name": "张三"}}
}
6.9 模糊查询
返回包含与搜索字词相似的字词的文档可以使用“fuzzy”字段。为了找到相似的术语,fuzzy查询会在指定的编辑距离内创建一组搜索词的所有可能的变体或扩展,然后查询返回每个扩展的完全匹配。
GET http://<主机IP地址>:9200/<索引名称>/_search
{"_source": {"includes": ["company_name", "legal_name", "credit_code", "business_scope"],"excludes": ["create_time", "update_time"]},"query": {"fuzzy": {// 匹配字段名称"legal_name": {"value": "张三",// 编辑距离"fuzziness": 2}}}
}
6.9 查询并排序输出
使用sort字段对返回的结果进行排序,通过order指定排序方式,desc是降序,asc是升序。
GET http://<主机IP地址>:9200/<索引名称>/_search
{"_source": {"includes": ["company_name", "legal_name", "credit_code", "business_scope"],"excludes": ["create_time", "update_time"]},"query": {"term": {"legal_name": "张三"}},"sort": [{"company_name": {"order": "desc"}}, {"province": {"order": "asc"}}]
}
三. ElasticSearch索引内容
查看所有索引
向Elasticsearch服务器发送GET请求 http://127.0.0.1:9200/_cat/indices?v 这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES服务器中的所有索引,就像 MySQL 中的 show tables。返回数据表的含义如下表:
| 表头 | 含义 |
|---|---|
| health | 当前服务器的健康状态 |
| status | 索引打开、关闭状态 |
| index | 索引名称 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量(总记录数) |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占用空间大小 |