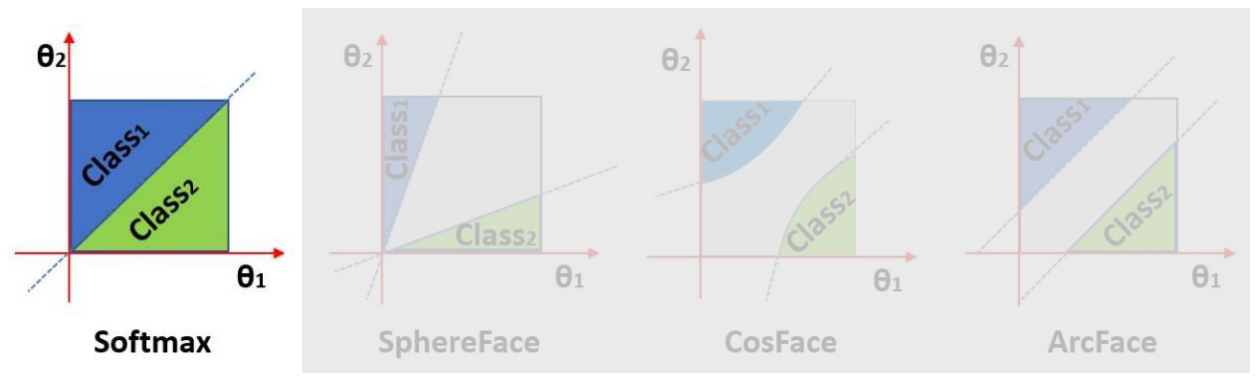
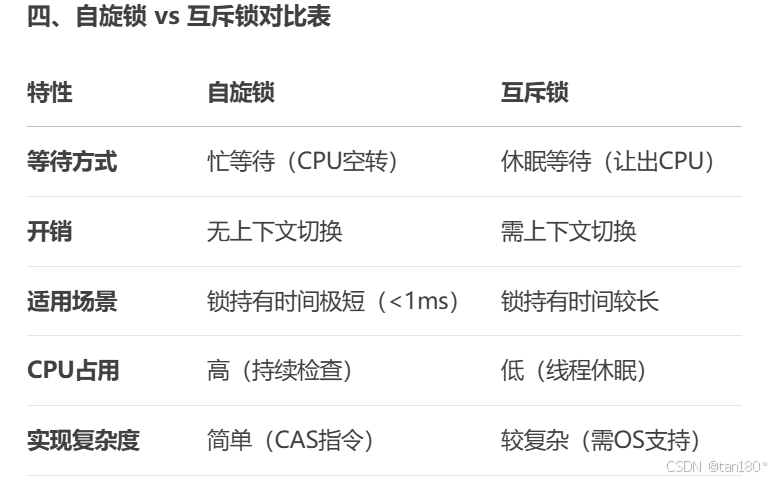
Java 大数据处理:使用 Hadoop 和 Spark 进行大规模数据处理
在当今数字化时代,数据呈现出爆炸式增长,如何高效地处理大规模数据成为企业面临的重要挑战。Java 作为一门广泛使用的编程语言,在大数据处理领域同样发挥着关键作用。本文将深入探讨如何利用 Hadoop 和 Spark 这两大主流框架,基于 Java 进行大规模数据处理,帮助读者掌握相关技术要点。
一、Java 在大数据处理中的角色
Java 语言以其良好的跨平台性、稳定性和丰富的类库,在大数据生态系统中占据重要地位。众多大数据框架如 Hadoop、Spark 等都基于 Java 或者与 Java 深度集成,这使得 Java 开发者能够充分利用这些强大的工具来处理海量数据。Java 提供了丰富的 API 用于文件操作、网络通信等,为大数据处理中的数据读取、传输和存储等环节奠定了基础。
二、Hadoop:分布式存储与计算的基础
(一)Hadoop 简介
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构,它主要包括 Hadoop 分布式文件系统(HDFS)和 MapReduce 计算模型。HDFS 能够在集群中可靠地存储大量数据,将数据分散存储到多个节点上,并通过冗余存储保证数据的可靠性。MapReduce 则是一种编程模型,用于大规模数据集的并行处理,将复杂的计算任务分解为多个独立的子任务,在集群节点上并行执行,最后汇总结果。
(二)Hadoop 环境搭建
在开始使用 Hadoop 进行数据处理之前,需要搭建 Hadoop 集群环境。以下是搭建 Hadoop 单节点集群的基本步骤:
- 安装 Java 开发环境:确保系统已安装 Java JDK,并设置好 JAVA_HOME 环境变量,因为 Hadoop 是基于 Java 开发的,需要 Java 运行环境支持。
- 下载并解压 Hadoop:从 Apache Hadoop 官方网站下载合适版本的 Hadoop,然后解压到指定目录。
- 配置 Hadoop 环境变量:编辑 hadoop-env.sh 文件,设置 Hadoop 所需的 Java 路径等环境变量。
- 配置 HDFS:修改 core-site.xml 和 hdfs-site.xml 文件,设置 HDFS 的相关参数,如文件系统 URI、存储目录等。
- 格式化 HDFS:使用命令
hdfs namenode -format对 HDFS 进行格式化,初始化文件系统。 - 启动 HDFS:通过命令
start-dfs.sh启动 HDFS 服务,此时可以通过浏览器访问 Hadoop 的 Web 界面查看 HDFS 的状态。
(三)MapReduce 示例:单词统计
// Mapper 类
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {word.set(tokenizer.nextToken());context.write(word, one);}}
}// Reducer 类
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}context.write(key, new IntWritable(sum));}
}// 主类
public class WordCount {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
(四)运行 MapReduce 程序
- 将编写好的 MapReduce 程序打包成 JAR 文件。
- 将输入数据上传到 HDFS 上,使用命令
hdfs dfs -put local_input_path hdfs_input_path。 - 提交 MapReduce 作业,通过命令
hadoop jar jar_file_name.jar WordCount hdfs_input_path hdfs_output_path运行程序,其中WordCount是主类所在的类名,hdfs_input_path和hdfs_output_path分别表示输入和输出在 HDFS 上的路径。 - 查看输出结果,使用命令
hdfs dfs -cat hdfs_output_path/*查看统计结果。
三、Spark:快速的分布式数据处理引擎
(一)Spark 简介
Spark 是一个快速、通用的集群计算系统,它提供了内存计算能力,能够高效地处理大规模数据。与 Hadoop 的 MapReduce 相比,Spark 在某些场景下具有更快的速度,因为它可以在内存中存储中间结果,减少磁盘 I/O 操作。Spark 采用了弹性分布式数据集(RDD)作为其基本数据抽象,提供了丰富的操作接口,方便用户进行数据处理。
(二)Spark 环境搭建
- 安装 Java 开发环境:同 Hadoop 环境搭建中的 Java 环境配置。
- 下载并解压 Spark:从 Apache Spark 官方网站下载合适版本的 Spark,解压到指定目录。
- 配置 Spark 环境变量:编辑 spark-env.sh 文件,设置 Spark 的相关环境变量,如 SPARK_MASTER_HOST、SPARK_MASTER_PORT 等。
- 启动 Spark 集群:运行 Spark 的启动脚本,启动 Spark 集群,包括主节点和工作节点。
(三)Spark 示例:使用 RDD 进行数据处理
// 创建 Spark 配置
SparkConf conf = new SparkConf().setAppName("SparkExample").setMaster("local");
// 创建 JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);// 读取文本文件创建 RDD
JavaRDD<String> textFile = sc.textFile("hdfs://path/to/input/file.txt");// 对 RDD 进行 WordCount 操作
JavaRDD<String> words = textFile.flatMap(s -> Arrays.asList(s.split(" ")).iterator());
JavaPairRDD<String, Integer> wordCounts = words.mapToPair(word -> new Tuple2<>(word, 1)).reduceByKey((a, b) -> a + b);// 保存结果到 HDFS
wordCounts.saveAsTextFile("hdfs://path/to/output/directory");// 停止 SparkContext
sc.close();
(四)Spark 的优势与优化
- 优势 :Spark 的内存计算使得它在迭代式算法(如机器学习算法)和交互式数据挖掘中表现出色,能够快速处理数据。同时,Spark 提供了多种高级库,如 Spark SQL、Spark Streaming、MLlib 等,方便用户进行不同类型的数据处理任务。
- 优化 :为了充分利用 Spark 的性能,在实际应用中可以对 Spark 进行一些优化。例如,合理调整 Spark 的内存分配参数,根据数据规模和集群资源设置合适的分区数,使用数据本地性优化等。对于 RDD 操作,尽量避免频繁的 shuffle 操作,因为 shuffle 会带来较大的性能开销,可以通过合理使用广播变量、累加器等方式来优化数据传输和处理过程。
四、Hadoop 与 Spark 的比较与选择
(一)性能方面
Spark 的内存计算在处理速度上通常优于 Hadoop 的 MapReduce,尤其是在需要进行多轮迭代计算的场景下。但 Hadoop 也有其优势,对于一些对实时性要求不高、数据规模极大且计算逻辑相对简单的任务,Hadoop 的 MapReduce 模型可能具备更好的稳定性和成本效益。
(二)适用场景方面
Hadoop 适用于大规模数据的批处理任务,能够有效地存储和处理海量的静态数据。而 Spark 更适合于需要快速处理、迭代计算和交互式查询的场景,如实时数据流处理、机器学习训练等。在实际项目中,可以根据具体的数据处理需求和业务特点,选择合适的框架或者将两者结合使用,发挥各自的优势。
(三)资源消耗方面
Spark 由于需要将数据存储在内存中,对内存资源的消耗较大,需要一定的硬件资源支持。Hadoop 则主要依赖磁盘存储和计算,在硬件资源要求上相对较为灵活。因此,在资源有限的情况下,也需要综合考虑选择合适的框架。
五、总结
Java 在大数据处理领域具有重要地位,通过使用 Hadoop 和 Spark 这两大框架,能够高效地处理大规模数据。Hadoop 提供了可靠的分布式存储和基本的分布式计算能力,适合于大规模数据的批处理任务;Spark 则以其快速的内存计算和丰富的高级库,适用于更复杂的、需要快速迭代处理的数据场景。理解两者的原理、掌握其使用方法和优化技巧,对于 Java 开发者在大数据时代应对各种数据挑战具有重要意义。随着技术的不断发展,相信在 Java 大数据处理领域还会有更多的创新和突破,为数据驱动的业务决策提供更强大的支持。