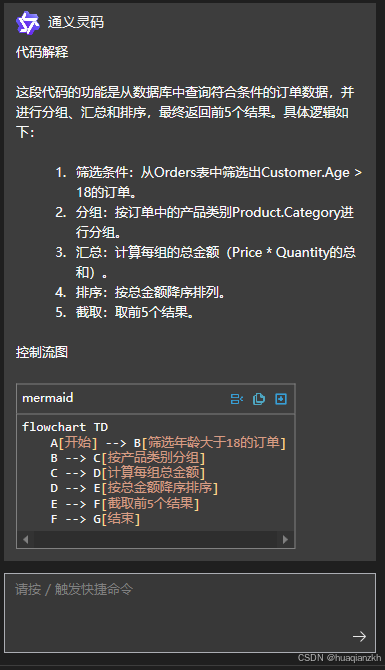
前言
本文一开始是此文的第一部分,后随着我司各大具身团队对各个动作策略的实践、深入,觉得可以挖掘且分享的细节越来越多,比如LeRobot ACT,其效果也不错
ALOHA ACT的复现与应用:双臂下的智能分拣场景
故把其中的「LeRobot ACT的源码解析与真机部署」单独抽取出来,独立成此文
第一部分 封装的ALOHA ACT策略
如本博客中的此文《一文通透动作分块算法ACT:斯坦福ALOHA团队推出的动作序列预测算法(Action Chunking with Transformers)》所述
下图左侧是CVAE编码器——包含一个transformer encoder,右侧是CVAE解码器——包含一个transformer encoder和一个transformer decoder)
- 上图左侧的CVAE 编码器(采用类似BERT的transformer编码器实现),其预测样式变量
的分布的均值和方差,该分布被参数化为对角高斯分布
其输入是来自当前关节位置,和来自示范数据集的长度为的目标动作序列,前面再加上一个习得的类似于BERT中的“[CLS]”token,从而形成了一个
长度的输入
通过编码器之后,使用“[CLS]”对应的特征用于预测“风格变量”- 上图右侧的CVAE解码器(即策略),通过
且他们使用ResNet图像编码器、transformer encoder,和transformer decoder来实现CVAE解码器
ACT模型的核心思想是同时预测一系列未来动作(称为"动作块"),而不是传统方法中单步预测动作。这种设计使机器人能够表现出更连贯、更具前瞻性的行为模式,特别适合需要精确协调的复杂任务
1.1 policies/act/modeling_act.py
`ACTPolicy`类继承自`PreTrainedPolicy`,作为用户接口层,负责输入/输出归一化、动作选择和训练过程管理
它包含两种关键的动作选择机制:
- 一种是简单地维护预测动作的队列
- 另一种是使用`ACTTemporalEnsembler`进行时序集成,通过加权平均多次预测结果来提高稳定性
时序集成器使用指数权重函数(`w_i = exp(-temporal_ensemble_coeff * i)`),可以调整对新旧预测的重视程度
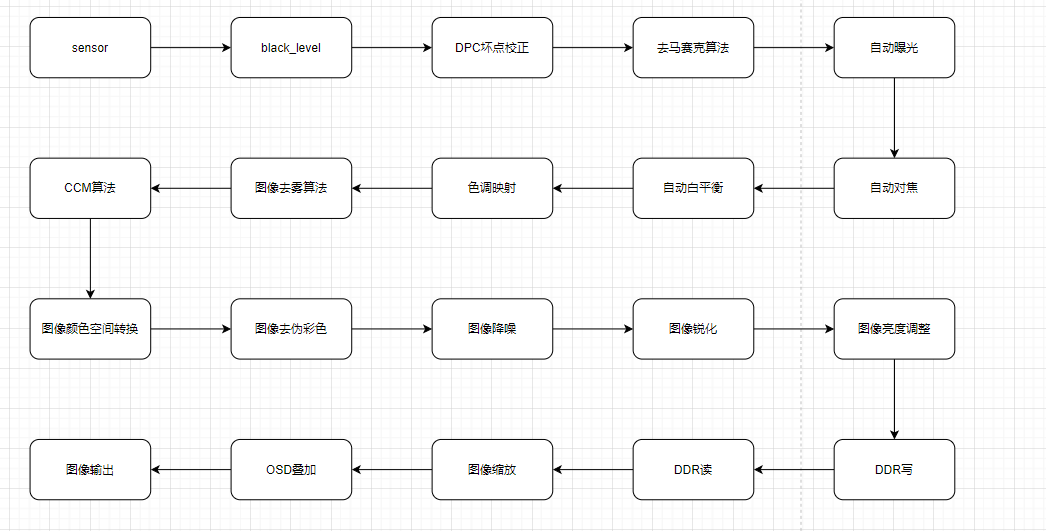
底层神经网络`ACT`类采用多模态Transformer架构,包括:
- 可选的变分自编码器(VAE)编码器,用于在训练时捕获动作空间的潜在分布
- 基于ResNet的视觉骨干网络,用于提取图像特征
- Transformer编码器,处理来自不同输入模态(潜变量、机器人状态、环境状态、图像特征)的标记
- Transformer解码器,通过交叉注意力机制整合编码器信息并生成动作序列
- 动作回归头,将解码器输出转换为具体的控制信号
- 位置编码在整个架构中起着关键作用,包括一维和二维的正弦位置编码,使模型能够处理序列和空间信息
模型支持两种训练方式:使用变分目标(带KL散度正则化)或直接使用L1损失
1.1.1 ACTPolicy类
1.1.2 ACTTemporalEnsembler类
1.1.3 ACT类
如代码中的ASCII图所示
TransformerUsed alone for inference(acts as VAE decoderduring training)┌───────────────────────┐│ Outputs ││ ▲ ││ ┌─────►┌───────┐ │┌──────┐ │ │ │Transf.│ ││ │ │ ├─────►│decoder│ │┌────┴────┐ │ │ │ │ │ ││ │ │ │ ┌───┴───┬─►│ │ ││ VAE │ │ │ │ │ └───────┘ ││ encoder │ │ │ │Transf.│ ││ │ │ │ │encoder│ │└───▲─────┘ │ │ │ │ ││ │ │ └▲──▲─▲─┘ ││ │ │ │ │ │ │inputs └─────┼──┘ │ image emb. ││ state emb. │└───────────────────────┘整体结构包含三个主要组件:
- 用于捕获动作分布的VAE编码器(训练时使用)
- 处理多模态观察的Transformer编码器
- 以及生成动作序列的Transformer解码器
1.3.1.1 __init__方法的实现
初始化方法构建了一个由多个精心设计的组件组成的网络:
- 首先是可选的变分自编码器(VAE)部分,它采用BERT风格的设计,以CLS标记、机器人状态和动作序列作为输入,通过编码过程捕获动作分布的潜在表示
VAE编码器使用固定的正弦位置编码和多层投影来处理不同类型的输入def __init__(self, config: ACTConfig):# 初始化父类nn.Modulesuper().__init__() # 存储配置参数 self.config = config # 如果启用VAE模式if self.config.use_vae: # 创建VAE编码器self.vae_encoder = ACTEncoder(config, is_vae_encoder=True) # 创建分类标记嵌入层,只有1个标记self.vae_encoder_cls_embed = nn.Embedding(1, config.dim_model) # 为机器人关节状态创建投影层,将其映射到隐藏维度# 如果提供了机器人状态特征if self.config.robot_state_feature: # 从原始维度映射到模型维度self.vae_encoder_robot_state_input_proj = nn.Linear(self.config.robot_state_feature.shape[0], config.dim_model )# 为动作(关节空间目标)创建投影层,将其映射到隐藏维度self.vae_encoder_action_input_proj = nn.Linear(# 动作特征的原始维度self.config.action_feature.shape[0], # 映射到模型维度config.dim_model, )
当`use_vae`设为False时,这部分会被完全跳过,模型将使用全零向量作为潜变量# 从VAE编码器的输出创建到潜在分布参数空间的投影层(输出均值和方差)# *2是因为需要输出均值和方差self.vae_encoder_latent_output_proj = nn.Linear(config.dim_model, config.latent_dim * 2) # 为VAE编码器的输入创建固定的正弦位置嵌入,为批次维度添加一个维度# *2是因为需要输出均值和方差num_input_token_encoder = 1 + config.chunk_size Ç# 如果有机器人状态,则增加一个标记if self.config.robot_state_feature: num_input_token_encoder += 1# 注册一个不需要梯度的缓冲区self.register_buffer( # 缓冲区名称"vae_encoder_pos_enc", # 创建正弦位置编码并扩展批次维度create_sinusoidal_pos_embedding(num_input_token_encoder, config.dim_model).unsqueeze(0), ) - 视觉处理采用配置化的预训练骨干网络(通常是ResNet),通过`IntermediateLayerGetter`提取深层特征
这种设计使模型能够处理原始相机输入,而不需要手工设计的特征提取器# 用于图像特征提取的骨干网络# 如果使用图像特征if self.config.image_features: # 从torchvision.models获取指定的骨干网络backbone_model = getattr(torchvision.models, config.vision_backbone)( # 控制是否使用空洞卷积replace_stride_with_dilation=[False, False, config.replace_final_stride_with_dilation], # 使用预训练权重weights=config.pretrained_backbone_weights, # 使用冻结的批量归一化层(不更新统计信息)norm_layer=FrozenBatchNorm2d, )# 注意:这里假设我们使用的是ResNet模型(因此layer4是最终特征图)# 注意:这个forward方法返回一个字典:{"feature_map": output}self.backbone = IntermediateLayerGetter(backbone_model, return_layers={"layer4": "feature_map"}) # 创建一个获取中间层输出的包装器 - 核心Transformer结构包含编码器和解码器
# Transformer(在使用变分目标训练时充当VAE解码器)self.encoder = ACTEncoder(config) # 创建Transformer编码器self.decoder = ACTDecoder(config) # 创建Transformer解码器
前者处理包括潜变量、机器人状态(即机器人的关节角度joints等状态信息)、环境状态和图像特征在内的多模态输入
后者通过交叉注意力机制生成动作序列# Transformer编码器输入投影。标记将被结构化为# [latent, (robot_state), (env_state), (image_feature_map_pixels)]# 从骨干网络最后一层特征数到模型维度if self.config.robot_state_feature: # 为机器人状态创建投影层self.encoder_robot_state_input_proj = nn.Linear( # 从原始维度映射到模型维度self.config.robot_state_feature.shape[0], config.dim_model )# 如果使用环境状态特征if self.config.env_state_feature: # 为环境状态创建投影层self.encoder_env_state_input_proj = nn.Linear( # 从原始维度映射到模型维度self.config.env_state_feature.shape[0], config.dim_model )# 为潜在向量创建投影层self.encoder_latent_input_proj = nn.Linear(config.latent_dim, config.dim_model) # 如果使用图像特征if self.config.image_features: # 为图像特征创建1x1卷积投影层self.encoder_img_feat_input_proj = nn.Conv2d( # 从骨干网络最后一层特征数到模型维度backbone_model.fc.in_features, config.dim_model, kernel_size=1 )
特别值得注意的是位置编码的处理:一维特征使用简单的嵌入层,而图像特征使用复杂的二维正弦位置编码(通过`ACTSinusoidalPositionEmbedding2d`实现),确保模型能够理解空间关系# Transformer解码器# 为transformer的解码器创建可学习的位置嵌入(类似于DETR的对象查询)# 为每个动作块位置创建嵌入self.decoder_pos_embed = nn.Embedding(config.chunk_size, config.dim_model) # 在transformer解码器输出上的最终动作回归头# 从模型维度映射到动作维度self.action_head = nn.Linear(config.dim_model, self.config.action_feature.shape[0]) # 重置模型参数self._reset_parameters()# Transformer编码器位置嵌入# 为潜在向量预留1个标记n_1d_tokens = 1 # 如果有机器人状态,则增加一个标记if self.config.robot_state_feature: n_1d_tokens += 1# 如果有环境状态,则增加一个标记if self.config.env_state_feature: n_1d_tokens += 1# 为一维特征创建位置嵌入self.encoder_1d_feature_pos_embed = nn.Embedding(n_1d_tokens, config.dim_model) # 如果使用图像特征if self.config.image_features: # 创建二维正弦位置嵌入self.encoder_cam_feat_pos_embed = ACTSinusoidalPositionEmbedding2d(config.dim_model // 2)
该架构的模块化设计使其能够适应不同的任务需求:它可以处理多摄像头输入、不同的状态表示,并且可以通过配置参数调整如块大小、层数、头数等性能关键因素。最终,通过动作回归头,模型将解码器的输出映射为具体的控制信号,形成一个完整的感知-决策-控制流程,使机器人能够执行连贯、前瞻性的动作序列
1.3.1.2 _reset_parameters的实现
对于视觉处理,模型使用预训练的ResNet骨干网络(可配置)提取特征,并支持多摄像头输入
def _reset_parameters(self):"""Xavier-uniform initialization of the transformer parameters as in the original code."""# 遍历编码器和解码器的所有参数for p in chain(self.encoder.parameters(), self.decoder.parameters()): # 如果参数维度大于1(通常是权重矩阵if p.dim() > 1: )# 使用Xavier均匀初始化nn.init.xavier_uniform_(p) 1.3.1.3 forward方法的实现
前向传播流程清晰分明:可选的VAE编码阶段(仅用于训练)、输入准备阶段、Transformer编码-解码阶段和输出阶段
- Transformer部分的设计特别注重处理多模态输入和位置编码
编码器处理包括潜在向量、机器人状态、环境状态和图像特征的标记序列,每种输入都有相应的投影层将其映射到共同的嵌入维度
位置编码同样精心设计,包括一维序列的正弦位置编码和图像特征的二维正弦位置编码 - 解码器则使用可学习的位置嵌入(类似DETR的对象查询)和交叉注意力机制从编码器输出生成动作序列
具体而言,方法首先处理批次大小确定,并根据配置和运行模式决定如何准备潜在向量
- 当启用VAE且处于训练模式时,它构建一个BERT风格的输入序列——如下图左下角所示,以CLS标记开始,后跟机器人状态(如果配置),最后是动作序列
- 这些输入经过嵌入层投影到统一维度空间,并添加正弦位置编码以保留序列顺序信息
经过VAE编码器处理后,如上图右上角所示,CLS标记的输出被用来生成潜在空间分布参数(均值和对数方差),最后通过重参数化技巧(mu + exp(log_sigma/2) * 随机噪声)采样得到潜在向量
这是VAE训练的关键步骤,确保梯度可以通过随机采样过程反向传播# 将cls标记输出投影为潜在分布参数latent_pdf_params = self.vae_encoder_latent_output_proj(cls_token_out) # 前半部分为均值参数mu = latent_pdf_params[:, : self.config.latent_dim] # 后半部分为对数方差参数,这是2*log(sigma),这样做是为了匹配原始实现log_sigma_x2 = latent_pdf_params[:, self.config.latent_dim :] # 使用重参数化技巧采样潜在变量,mu + exp(log_sigma/2)*噪声latent_sample = mu + log_sigma_x2.div(2).exp() * torch.randn_like(mu)
若不使用VAE,则简单地使用全零向量作为潜在表示
接下来的多模态融合阶段展示了处理异构数据的精妙设计
- 方法首先准备Transformer编码器的输入「接收包含多模态输入(机器人状态、环境状态和/或摄像头图像)的批次数据」:
从投影后的潜在向量开始
根据配置添加机器人状态和环境状态标记# 准备transformer编码器的输入,首先添加投影后的潜在变量encoder_in_tokens = [self.encoder_latent_input_proj(latent_sample)] # 准备一维特征的位置嵌入encoder_in_pos_embed = list(self.encoder_1d_feature_pos_embed.weight.unsqueeze(1))
对于图像处理,它遍历每个摄像头视角,通过ResNet骨干网络提取特征# 机器人状态标记,如果配置包含机器人状态特征if self.config.robot_state_feature: # 添加投影后的机器人状态 encoder_in_tokens.append(self.encoder_robot_state_input_proj(batch["observation.state"])) # 环境状态标记,如果配置包含环境状态特征if self.config.env_state_feature: # 添加投影后的环境状态encoder_in_tokens.append( self.encoder_env_state_input_proj(batch["observation.environment_state"]))
添加二维位置编码,然后将所有特征拼接并重排为序列形式。这种设计允许模型无缝地整合来自不同来源的信息# 相机观察特征和位置嵌入,如果配置包含图像特征if self.config.image_features: # 用于存储所有相机的特征all_cam_features = [] # 用于存储所有相机特征的位置嵌入all_cam_pos_embeds = [] # 遍历每个相机for cam_index in range(batch["observation.images"].shape[-4]): # 通过骨干网络提取特征cam_features = self.backbone(batch["observation.images"][:, cam_index])["feature_map"] # 生成2D位置嵌入并转换为与特征相同的数据类型,(B, C, h, w) , 将特征投影到模型维度cam_features = self.encoder_img_feat_input_proj(cam_features) # 添加到所有相机特征列表 all_cam_features.append(cam_features) # 添加到所有相机位置嵌入列表all_cam_pos_embeds.append(cam_pos_embed) - 最后的Transformer处理阶段将所有准备好的标记和位置编码输入编码器,产生上下文化的表示
解码器以全零输入开始,通过交叉注意力机制关注编码器输出的相关部分,生成动作表示序列
最终通过线性层将这些表示映射为具体的动作向量
1.1.4 ACTEncoder类和ACTEncoderLayer类
1.1.5 ACTDecoder类和ACTDecoderLayer类
1.1.6 ACTSinusoidalPositionEmbedding2d类
1.2 policies/act/configuration_act.py
// 待更


![[AD] CrownJewel-1 Logon 4799+vss-ShadowCopy+NTDS.dit/SYSTEM+$MFT](https://i-blog.csdnimg.cn/img_convert/367fde968365cb24a6207e6f2dfa0292.jpeg)