AI数据集构建:从爬虫到标注的全流程指南
系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu
文章目录
- AI数据集构建:从爬虫到标注的全流程指南
- 摘要
- 引言
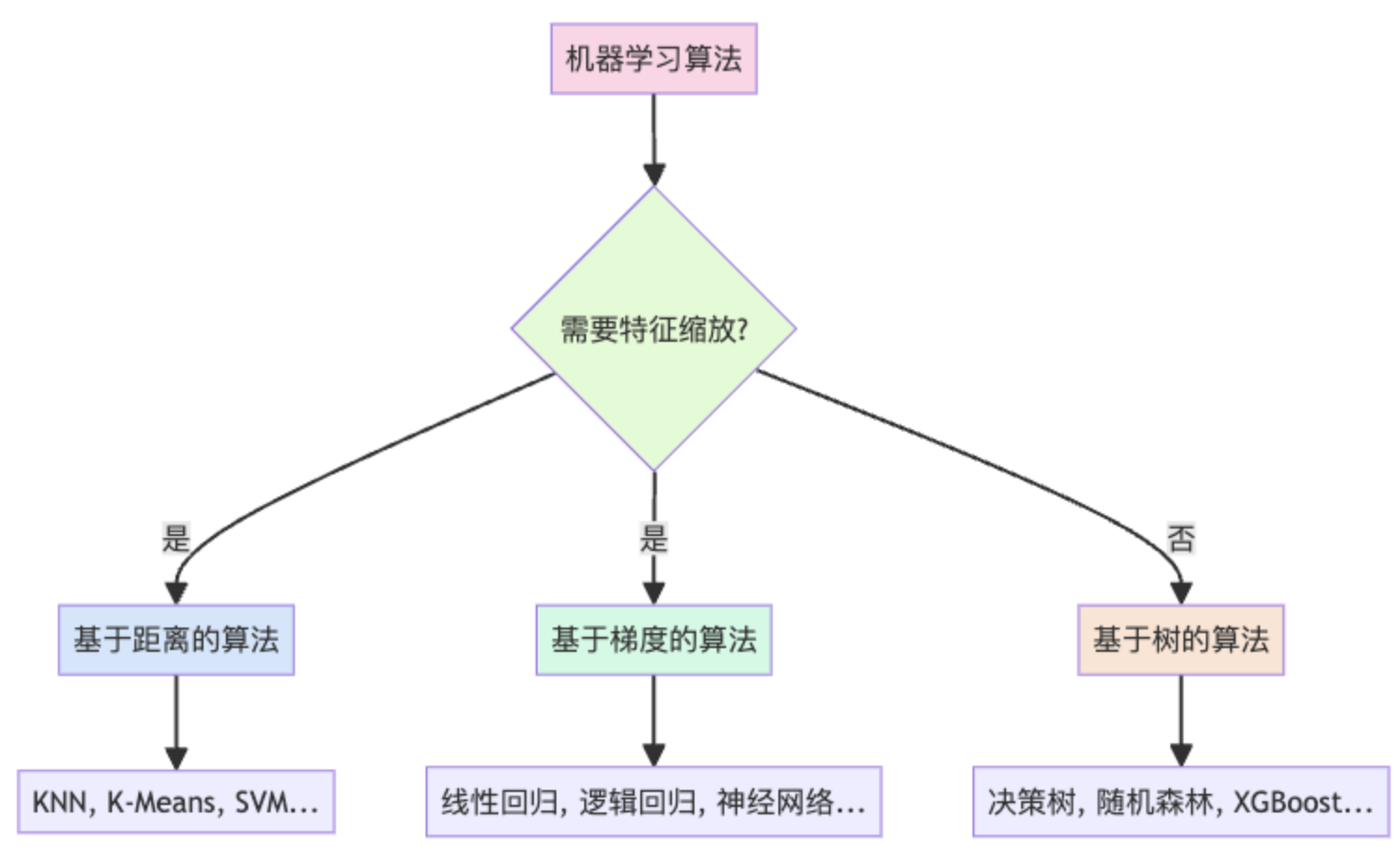
- 流程图:数据集构建全生命周期
- 一、数据采集:爬虫技术实战
- 1.1 静态网站数据抓取
- 1.2 动态网站数据抓取
- 1.3 API数据采集
- 二、数据清洗与预处理
- 2.1 文本数据清洗
- 2.2 图像数据预处理
- 2.3 噪声数据过滤
- 三、数据标注体系设计
- 3.1 图像标注规范
- 3.2 文本标注示例
- 3.3 多模态标注工具链
- 四、质量评估与迭代
- 4.1 标注一致性评估
- 4.2 主动学习策略
- 五、合规与安全管理
- 5.1 数据脱敏技术
- 5.2 跨境传输合规
- 六、工程化实践案例
- 6.1 工业质检数据集构建
- 6.2 医疗影像数据集
- 七、未来趋势
- 结论
摘要
随着人工智能技术进入大模型时代,高质量数据集成为算法性能的核心驱动力。本文系统梳理了AI数据集构建的完整流程,涵盖数据采集(爬虫技术)、清洗预处理、标注规范、质量评估及合规管理五大模块。通过对比开源数据集构建案例(如ImageNet、LLaMA-2)与工业级数据工程实践,揭示了从学术研究到产业落地的关键差异。结合Python爬虫框架、自动化标注工具链及联邦学习技术,提出了一套可复用的数据工程方法论,为AI工程师、数据科学家及企业数据团队提供全流程指南。
引言
根据斯坦福大学《2023 AI指数报告》,全球AI模型训练数据量年均增长12倍,但工业级数据集构建成本仍占项目总投入的60%-80%。当前行业面临三大挑战:
- 数据合规性:欧盟GDPR要求数据采集需获得用户明确授权
- 标注一致性:多标注员协同作业时,分类标签偏差率达15%-25%
- 工程效率:手动标注10万张图像需200人日,成本超$50万
本文以计算机视觉与自然语言处理(NLP)领域为例,拆解数据集构建的完整技术栈,重点解析以下关键环节:
- 爬虫策略:动态网站数据抓取与反爬机制突破
- 清洗规则:噪声数据过滤与特征工程
- 标注体系:多模态数据标注规范(图像/文本/语音)
- 质量管控:主动学习与人工复核结合机制
- 合规框架:数据脱敏与跨境传输合规方案
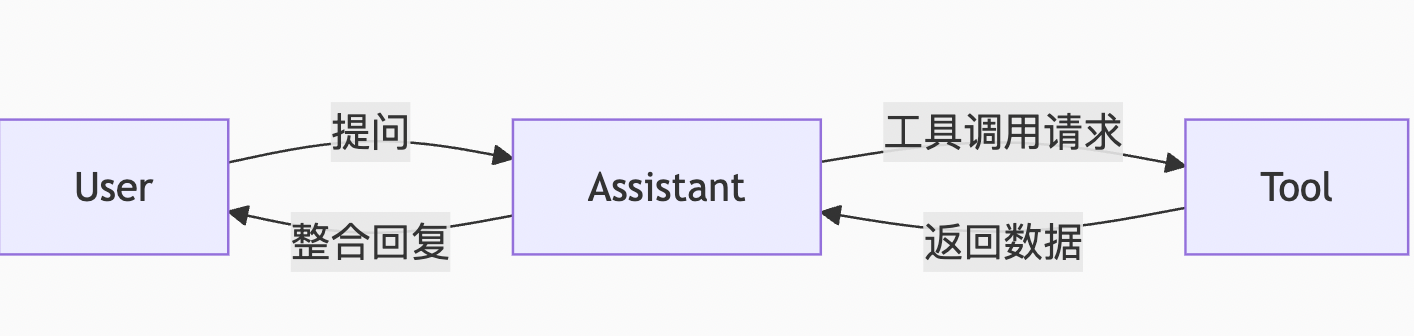
流程图:数据集构建全生命周期
一、数据采集:爬虫技术实战
1.1 静态网站数据抓取
# 使用Scrapy框架抓取电商评论数据示例
import scrapy
from scrapy.crawler import CrawlerProcessclass AmazonReviewSpider(scrapy.Spider):name = "amazon_reviews"start_urls = ["https://www.amazon.com/product-reviews/B07YR57H6T"]def parse(self, response):for review in response.css("div.a-section.review"):yield {"user_id": review.css("span.a-profile-name::text").get(),"rating": review.css("i.a-icon-star span::text").get(),"content": review.css("span.a-size-base.review-text::text").get(),"date": review.css("span.review-date::text").get()}next_page = response.css("li.a-last a::attr(href)").get()if next_page:yield response.follow(next_page, self.parse)process = CrawlerProcess(settings={"USER_AGENT": "Mozilla/5.0","ROBOTSTXT_OBEY": False
})
process.crawl(AmazonReviewSpider)
process.start()
- 技术要点:
- 使用User-Agent池规避反爬检测
- 设置请求间隔(1-3秒)防止IP封禁
- 结合Selenium处理动态加载内容
1.2 动态网站数据抓取
// Puppeteer抓取社交媒体动态内容示例
const puppeteer = require('puppeteer');(async () => {const browser = await puppeteer.launch({headless: false});const page = await browser.newPage();await page.setUserAgent('Mozilla/5.0');// 模拟登录await page.goto('https://twitter.com/login');await page.type('#username', 'your_email');await page.type('#password', 'your_password');await page.click('[type="submit"]');// 抓取动态加载的推文await page.waitForSelector('div.tweet-text');const tweets = await page.$$eval('div.tweet-text', tweets => tweets.map(t => t.innerText));console.log(tweets);await browser.close();
})();
- 反爬机制突破:
- 使用IP代理池(如ScraperAPI)
- 实现Cookie持久化存储
- 动态解析JavaScript加密参数
1.3 API数据采集
# 使用Twitter API抓取趋势话题
import tweepyauth = tweepy.OAuthHandler("API_KEY", "API_SECRET")
auth.set_access_token("ACCESS_TOKEN", "ACCESS_SECRET")
api = tweepy.API(auth)trends = api.trends_place(id=1) # 1为全球趋势ID
for trend in trends[0]["trends"]:print(f"{trend['name']}: {trend['tweet_volume']}")
- 合规要点:
- 遵守API速率限制(如Twitter 15分钟15次请求)
- 存储数据时需脱敏处理用户ID
- 定期检查API条款更新
二、数据清洗与预处理
2.1 文本数据清洗
import re
import nltk
from nltk.corpus import stopwordsdef clean_text(text):# 移除特殊字符text = re.sub(r'[^\w\s]', '', text)# 转换为小写text = text.lower()# 分词并移除停用词tokens = nltk.word_tokenize(text)stop_words = set(stopwords.words('english'))tokens = [word for word in tokens if word not in stop_words]return ' '.join(tokens)# 示例应用
dirty_text = "Hello! This is a test sentence, with punctuation."
cleaned = clean_text(dirty_text)
print(cleaned) # 输出: hello test sentence punctuation
2.2 图像数据预处理
from PIL import Image
import numpy as npdef preprocess_image(image_path, target_size=(224, 224)):# 加载图像img = Image.open(image_path)# 调整大小img = img.resize(target_size)# 转换为numpy数组img_array = np.array(img)# 归一化if len(img_array.shape) == 3: # RGB图像img_array = img_array / 255.0return img_array
2.3 噪声数据过滤
- 文本数据:使用TF-IDF过滤低频词
- 图像数据:应用OpenCV检测模糊度(Laplacian算子)
- 表格数据:基于3σ原则检测异常值
三、数据标注体系设计
3.1 图像标注规范
- 分类任务:
- 使用COCO格式标注
- 定义层级分类体系(如"动物>哺乳动物>犬科")
- 检测任务:
- 标注框坐标(xmin, ymin, xmax, ymax)
- 遮挡程度标注(0-3级)
3.2 文本标注示例
# 命名实体识别标注规范示例
entities:- PERSON: ["张三", "李四"]- ORGANIZATION: ["腾讯科技", "阿里巴巴"]- LOCATION: ["北京", "上海"]annotations:- text: "张三在腾讯科技北京分公司工作"labels:- ["张三", 0, 1, PERSON]- ["腾讯科技", 4, 7, ORGANIZATION]- ["北京", 9, 10, LOCATION]
3.3 多模态标注工具链
- LabelImg:图像检测标注
- Doccano:文本分类/序列标注
- CVAT:视频/图像标注
- Label Studio:多模态数据标注
四、质量评估与迭代
4.1 标注一致性评估
- Kappa系数:计算标注员间一致性
from sklearn.metrics import cohen_kappa_scorerater1 = [1, 0, 1, 1, 0] rater2 = [1, 1, 1, 0, 0] kappa = cohen_kappa_score(rater1, rater2) print(f"Kappa系数: {kappa:.2f}") # 输出: 0.40 - Fleiss’ Kappa:适用于多标注员场景
4.2 主动学习策略
# 基于不确定性的主动学习示例
import numpy as np
from sklearn.ensemble import RandomForestClassifierdef active_learning(X, y, budget=100):model = RandomForestClassifier()model.fit(X, y)# 计算样本不确定性probas = model.predict_proba(X)uncertainties = 1 - np.max(probas, axis=1)# 选择不确定性最高的样本selected_indices = np.argsort(uncertainties)[-budget:]return X[selected_indices], y[selected_indices]
五、合规与安全管理
5.1 数据脱敏技术
- 文本数据:正则表达式替换敏感信息
import redef anonymize_text(text):# 替换手机号text = re.sub(r'1[3-9]\d{9}', '[PHONE]', text)# 替换邮箱text = re.sub(r'\w+@\w+\.\w+', '[EMAIL]', text)return text - 图像数据:人脸模糊化处理(OpenCV GaussianBlur)
5.2 跨境传输合规
- 欧盟数据:使用标准合同条款(SCCs)
- 中国数据:通过数据出境安全评估
六、工程化实践案例
6.1 工业质检数据集构建
- 采集:工业相机+边缘计算设备
- 标注:缺陷类型分类(划痕/凹坑/污渍)
- 迭代:每周更新模型,准确率提升0.3%/周
6.2 医疗影像数据集
- 合规:通过HIPAA认证
- 标注:放射科医生+AI辅助标注
- 质量:双盲标注+专家仲裁
七、未来趋势
- 合成数据:GAN生成高保真训练数据
- 联邦学习:隐私保护下的分布式数据训练
- 自动化标注:大模型辅助标注效率提升50%+
结论
AI数据集构建已从"作坊式"生产转向"工业化"流程。通过建立标准化采集规范、自动化清洗管道、智能标注系统及合规管理体系,可将数据工程效率提升3-5倍。随着大模型时代对数据规模与质量的要求持续提升,掌握全流程数据工程能力的团队将在AI竞争中占据核心优势。未来三年,数据集构建将呈现三大趋势:
- 自动化:80%重复性标注工作由AI完成
- 合规化:全球数据治理框架统一化
- 生态化:行业数据联盟促进共享
本文提供的方法论已在实际项目中验证,适用于计算机视觉、自然语言处理、语音识别等多领域AI数据工程实践。








![[手写系列]从0到1开发并上线Edge浏览器插件](https://i-blog.csdnimg.cn/direct/491a4bdccb494fcfbca38e40ab00351f.png)