本文目录:
- 一、集成学习概念
- **核心思想:**
- 二、集成学习分类
- (一)Bagging集成
- (二)Boosting集成
- (三)两种集成方法对比
- 三、随机森林
一、集成学习概念
集成学习是一种通过结合多个基学习器(弱学习器)的预测结果来提升模型整体性能的机器学习方法。其核心思想是“集思广益”,通过多样性(Diversity)和集体决策降低方差(Variance)或偏差(Bias),从而提高泛化能力。
核心思想:
弱学习器:指性能略优于随机猜测的简单模型(如决策树桩、线性模型);
强学习器:通过组合多个弱学习器构建的高性能模型;
核心目标:减少过拟合(降低方差)或欠拟合(降低偏差)。
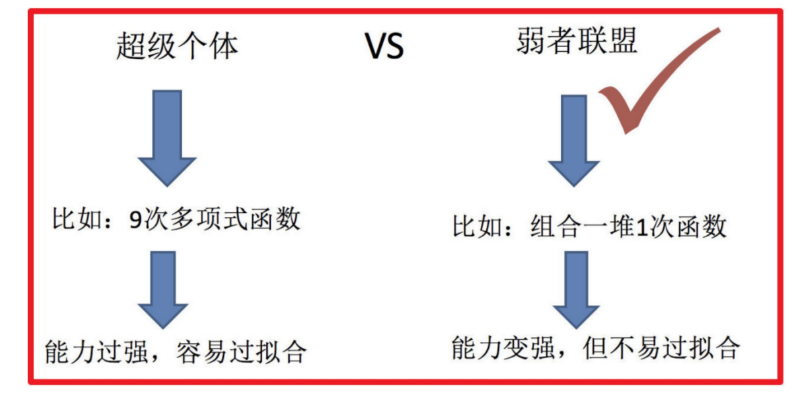
传统机器学习算法 (例如:决策树,逻辑回归等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。
二、集成学习分类
集成学习算法一般分为:bagging和boosting
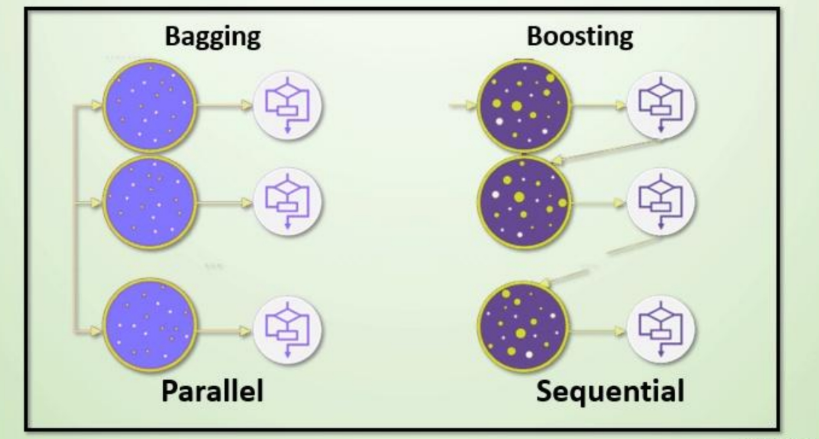
(一)Bagging集成
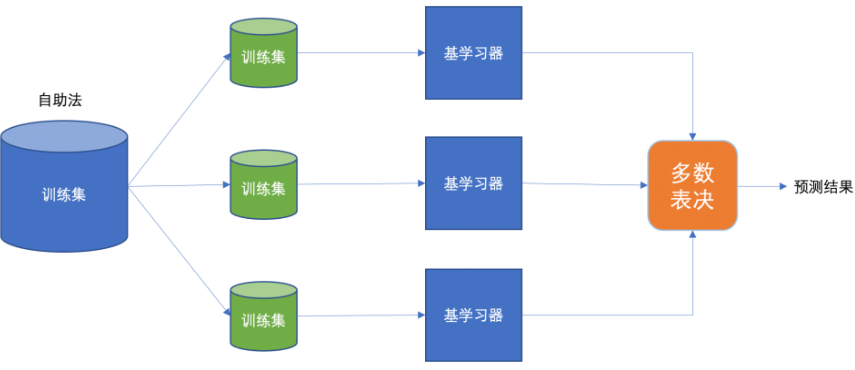
Bagging 框架通过有放回的抽样产生不同的训练集,从而训练具有差异性的弱学习器,然后通过平权投票、多数表决的方式决定预测结果。
(二)Boosting集成
Boosting 体现了提升思想,每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,得出预测结果。
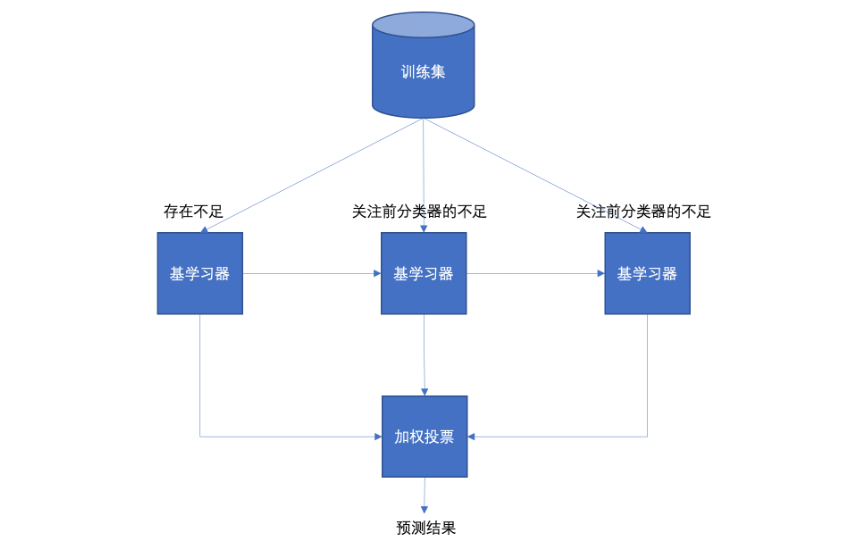
Boosting是一组可将弱学习器升为强学习器算法,这类算法的工作机制类似:
1.先从初始训练集训练出一个基学习器;
2.在根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本(增加权重)在后续得到最大的关注;
3.然后基于调整后的样本分布来训练下一个基学习器;
4.如此重复进行,直至基学习器数目达到实现指定的值T为止。
5.再将这T个基学习器进行加权结合得到集成学习器。
简而言之:每新加入一个弱学习器,整体能力就会得到提升

(三)两种集成方法对比

三、随机森林
随机森林是基于 Bagging 思想实现的一种集成学习算法,通过构建多棵决策树并结合它们的预测结果来提高模型的准确性和鲁棒性。它由Leo Breiman在2001年提出,广泛应用于分类和回归任务。
其构造过程是:
- 训练:
(1)有放回的产生训练样本;
(2)随机挑选 n 个特征(n 小于总特征数量)。 - 预测:
(1)分类任务:投票(多数表决);
(2)回归任务:平均预测值。
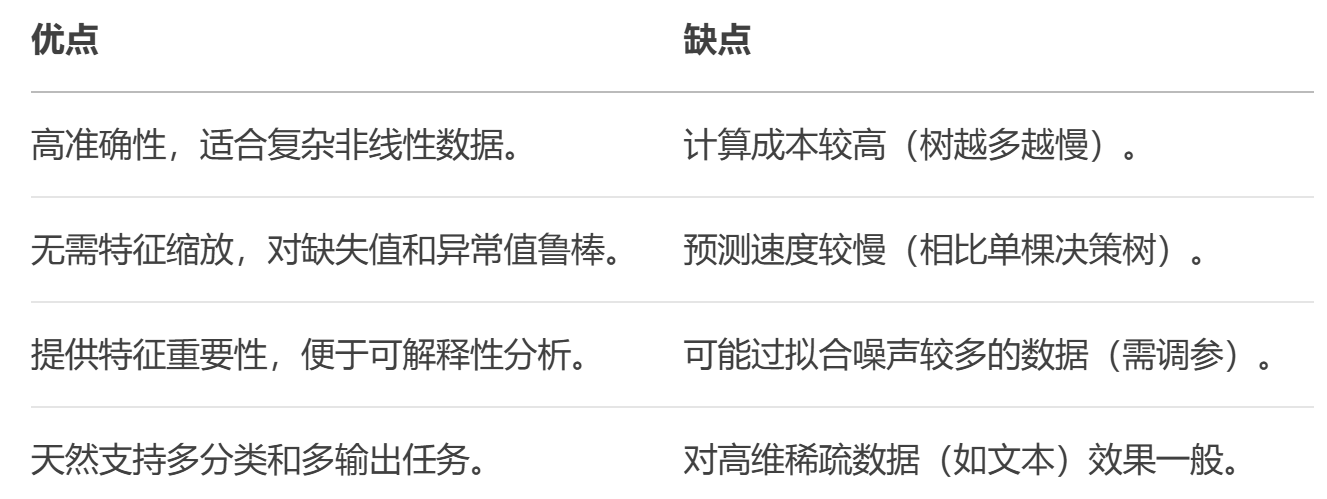
优点与缺点:
实例:
#1.数据导入
#1.1导入数据
import pandas as pd
#1.2.利用pandas的read.csv模块从互联网中收集泰坦尼克号数据集
titanic=pd.read_csv("data/泰坦尼克号.csv")
titanic.info() #查看信息
#2人工选择特征pclass,age,sex
X=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#3.特征工程
#数据的填补
X['Age'].fillna(X['Age'].mean(),inplace=True)
X = pd.get_dummies(X)
#数据的切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.25,random_state=22)#4.使用单一的决策树进行模型的训练及预测分析
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred=dtc.predict(X_test)
dtc.score(X_test,y_test)#5.随机森林进行模型的训练和预测分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(max_depth=6,random_state=9)
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
rfc.score(X_test,y_test)#6.性能评估
from sklearn.metrics import classification_report
print("dtc_report:",classification_report(dtc_y_pred,y_test))
print("rfc_report:",classification_report(rfc_y_pred,y_test))# 随机森林做预测
# 1 实例化随机森林
rf = RandomForestClassifier()
# 2 定义超参数的选择列表
param={"n_estimators":[80,100,200], "max_depth": [2,4,6,8,10,12],"random_state":[9]}
# 超参数调优
# 3 使用GridSearchCV进行网格搜索
from sklearn.model_selection import GridSearchCV
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(X_train, y_train)
print("随机森林预测的准确率为:", gc.score(X_test, y_test))

![[Linux] MySQL源码编译安装](https://i-blog.csdnimg.cn/direct/7b4ffcfc5b754fd8b1d1ba1aa2e112de.png)