一、dom4j
dom4j 是一个基于 Java 的开源 XML 解析和操作库。它可以方便地对 XML 文档进行读取、创建、修改和写入操作。dom4j 支持 XPath、XSLT 等标准,具有性能高、功能强大、易于使用等特点,常用于 Java 项目中对 XML 数据的处理。
二、dom4j优点
高性能:Dom4j被设计为高性能的XML处理库,适用于处理大型XML文档。在处理大型XML文件时,Dom4j显示出较好的性能,尤其是读取速度较快。这得益于其高效的内部数据结构和算法,使得XML文档的解析和操作更加迅速。
简单易用:Dom4j提供了简单而强大的API,使得解析、生成和操作XML文档变得容易。它允许开发者以多种方式解析和操作XML文档,如DOM风格、SAX风格以及JAXP兼容的方式。此外,Dom4j还支持XPath查询,可以通过XPath表达式来定位和选择XML文档中的元素,进一步简化了XML文档的处理过程。
灵活性:Dom4j提供了丰富的API和接口,使得开发者可以轻松实现自定义功能。它支持XML命名空间,允许处理具有命名空间的XML文档。同时,Dom4j还支持扩展和自定义,开发者可以通过继承现有类来实现特定需求。
开源社区支持:作为一个成熟的库,Dom4j拥有活跃的用户社区和开发者社区。社区成员积极贡献代码、分享经验和解决问题,为Dom4j的持续发展提供了有力支持。此外,Dom4j的文档和示例也相对丰富,有助于开发者更快地学习和掌握其使用方法。
良好的兼容性:Dom4j与流行的XML解析库如JAXP/SAX等兼容性良好,这使得开发者可以在现有的Java项目中轻松集成Dom4j,而无需担心兼容性问题。
三、dom4j官网
dom4j 下载dom4j-2.1.4版本

四、 dom4j常用 API
1、节点操作
| 操作类型 | API 示例 |
|---|---|
| 获取根节点 | Element root = document.getRootElement(); |
| 添加子节点 | Element child = parent.addElement("childTag"); |
| 遍历子节点 | List<Element> children = element.elements(); |
| 删除节点 | parent.remove(childElement); |
2、属性操作
| 操作类型 | API 示例 |
|---|---|
| 添加属性 | element.addAttribute("key", "value"); |
| 获取属性值 | String value = element.attributeValue("key"); |
| 属性迭代器 | Iterator<Attribute> iter = element.attributeIterator(); |
3、内容操作
| 操作类型 | API 示例 |
|---|---|
| 获取文本内容 | String text = element.getText(); |
| 设置文本内容 | element.setText("new content"); |
| XML 转字符串 | String xmlStr = document.asXML(); |
五、dom4j解析XML
1、学生类Student 和测试类TestXML (省...)
2、业务逻辑类StudentBiz
package net.xml;import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;import java.io.FileWriter;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;public class StudentBiz {//文件路径private String filePath = "student.xml";/*** 1.获取文档对象** @return* @throws Exception*/private Document getDocument() throws Exception {//创建SAXReader对象SAXReader saxReader = new SAXReader();//创建Document对象return saxReader.read(filePath);}/*** 2.显示所有学生信息*/public List<Student> show() {try {//创建集合对象List<Student> stus = new ArrayList<>();//获取文档对象Document document = getDocument();//获取根节点Element rootElement = document.getRootElement();
// System.out.println("根节点名称:" + rootElement.getName());//获取所有子节点集合List<Element> elements = rootElement.elements();//判断if (elements.size() == 0) {System.out.println("没有学生信息!");} else {//遍历集合for (Element element : elements) {//获取属性值String id = element.attributeValue("id");//获取属性值String name = element.elementText("name");int age = Integer.parseInt(element.elementText("age"));//封装对象Student student = new Student(id, name, age);//添加到集合中stus.add(student);}return stus;}} catch (Exception e) {e.printStackTrace();}return null;}/*** 5.排序年龄从大到小*/public void sort(){List<Student> stus = show();Collections.sort(stus, Comparator.comparing(Student::getAge).reversed());stus.forEach(System.out::println);}/*** 3.保存数据到XML文件中** @param document*/public void saveToXml(Document document) {//创建字符输出流对象try (FileWriter fw = new FileWriter(filePath);) {//格式化OutputFormat of = OutputFormat.createPrettyPrint();//创建XMLWriter对象XMLWriter xmlWriter = new XMLWriter(fw, of);//写入文档对象xmlWriter.write(document);//关闭流xmlWriter.close();} catch (Exception e) {e.printStackTrace();}}/*** 6.判断id是否存在* @param root* @param id* @return*/public boolean findById(Element root,String id){//定义标记位boolean flag = false;try {//获取所有子节点集合List<Element> elements = root.elements();for (Element element : elements) {if (id.equals(element.attributeValue("id"))) {flag= true;break;}}} catch (Exception e) {e.printStackTrace();}return flag;}/*** 4.添加学生信息** @param student <student id="10001">* <name>张三</name>* <age>18</age>* </student>*/public void add(Student student) {try {//获取文档对象Document document = getDocument();//获取根节点对象Element rootElement = document.getRootElement();//判断id是否存在if (findById(rootElement,student.getId())) {System.out.println(student.getId()+"已存在!");return;}else { //不存在,添加学生信息//创建子节点对象student//<student></student>Element element = rootElement.addElement("student");//添加属性值 id
// <student id="10001">element.addAttribute("id", student.getId());//添加元素内容 name age//<name>张三</name>element.addElement("name").addText(student.getName());//<age>18</age>element.addElement("age").addText(String.valueOf(student.getAge()));//保存数据到XML文件中saveToXml(document);System.out.println("添加成功!");}} catch (Exception e) {e.printStackTrace();}}/*** 5.删除学生信息** @param id*/public void delete(String id) {try {//定义标记位boolean flag = false;//获取文档对象Document document = getDocument();//获取根节点对象Element rootElement = document.getRootElement();//获取所有子节点集合List<Element> elements = rootElement.elements();for (Element element : elements) {//获取属性值,进行匹配idif (id.equals(element.attributeValue("id"))) {//删除节点对象rootElement.remove(element);//设置标记位flag = true;break;}}//判断标记位if (flag) {System.out.println("删除成功!");//保存数据到XML文件中saveToXml(document);} else {System.out.println("没有这个学生!"+id);}} catch (Exception e) {e.printStackTrace();}}public void update(Student student) {//定义标记位boolean flag = false;try {//获取文档对象Document document = getDocument();//获取根节点对象Element rootElement = document.getRootElement();//获取所有子节点集合List<Element> elements = rootElement.elements();for (Element element : elements) {//获取属性值,进行匹配idif (student.getId().equals(element.attributeValue("id"))) {//更新文本内容element.element("name").setText(student.getName());element.element("age").setText(String.valueOf(student.getAge()));flag = true; //设置标记位break;}}//判断标记位if (flag) {System.out.println("更新成功!");//保存数据到XML文件中saveToXml(document);} else {System.out.println("没有这个学生!"+student.getId());}} catch (Exception e) {e.printStackTrace();}}}
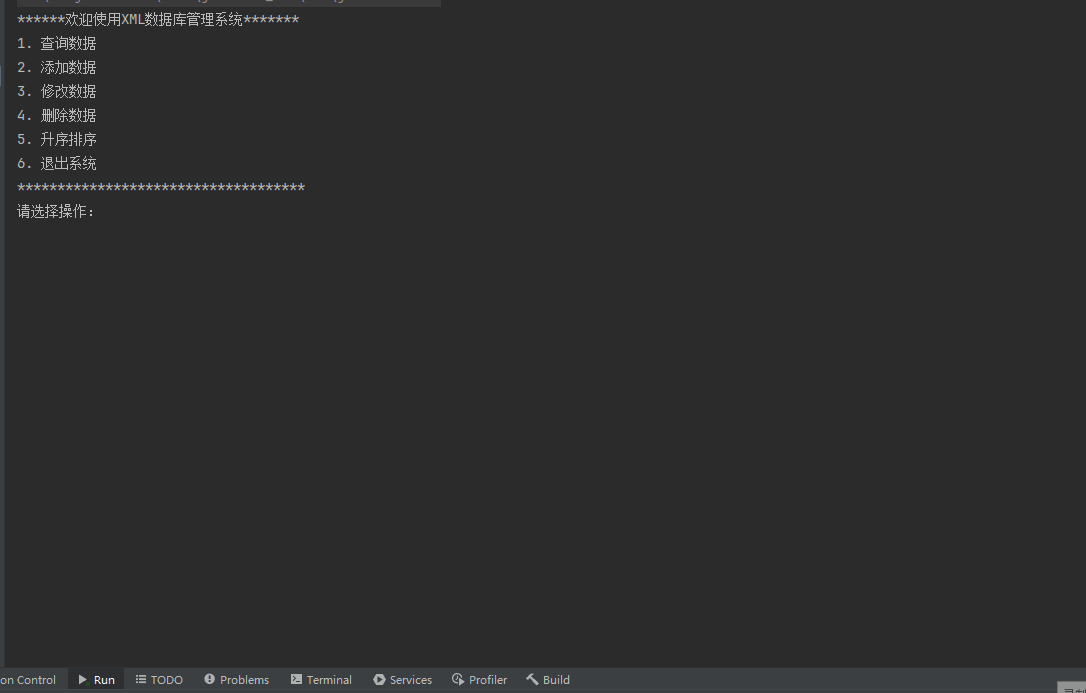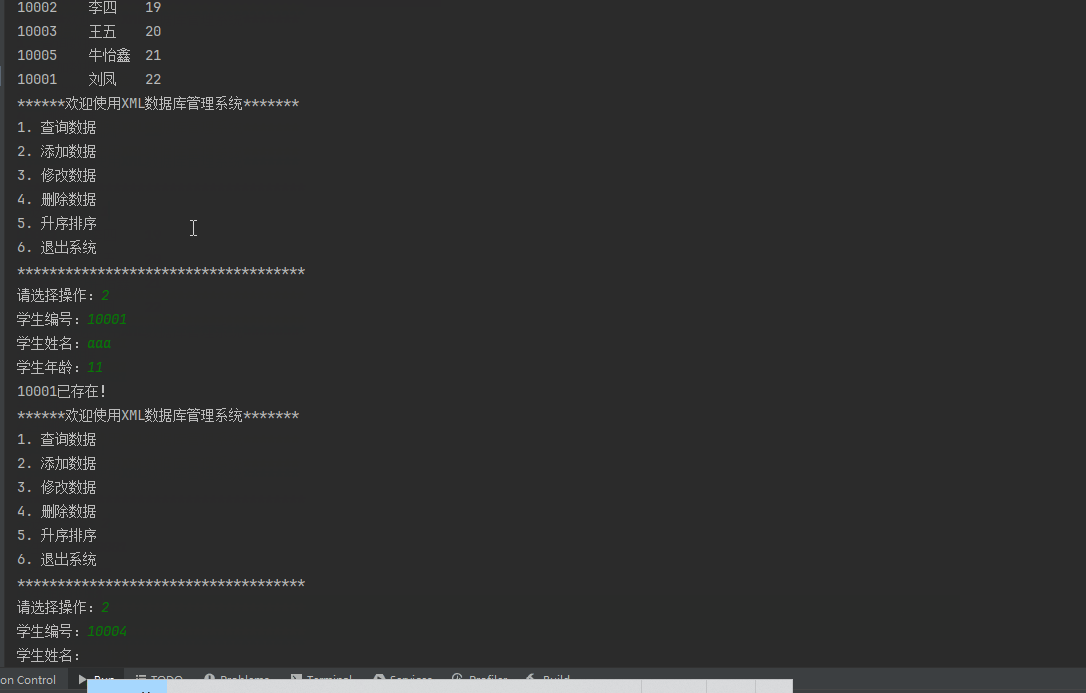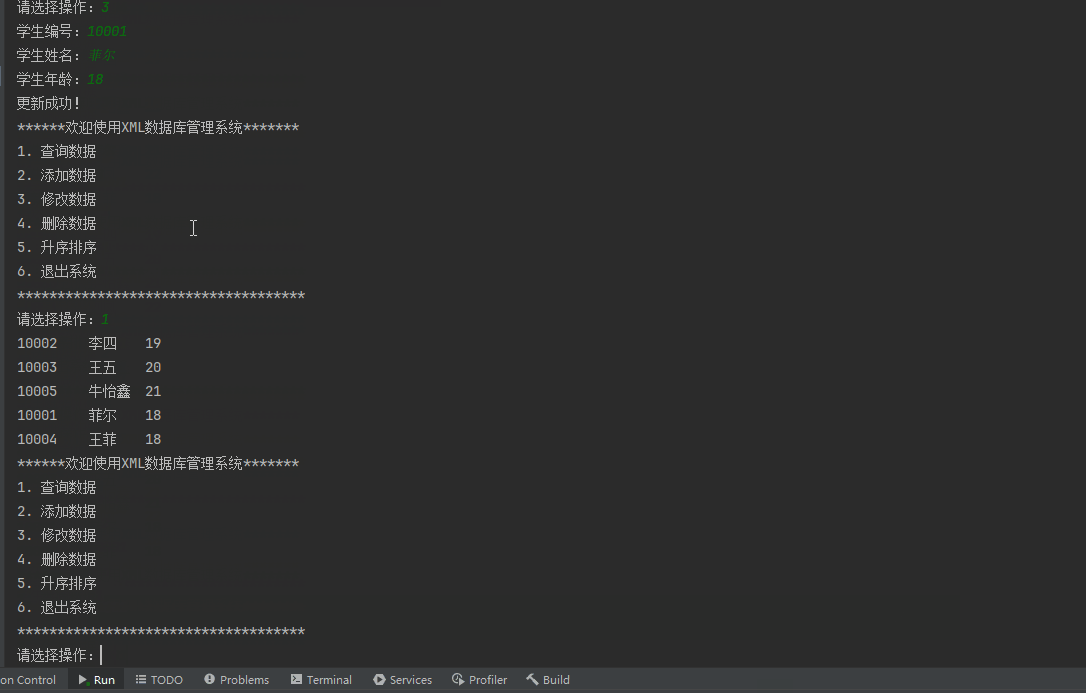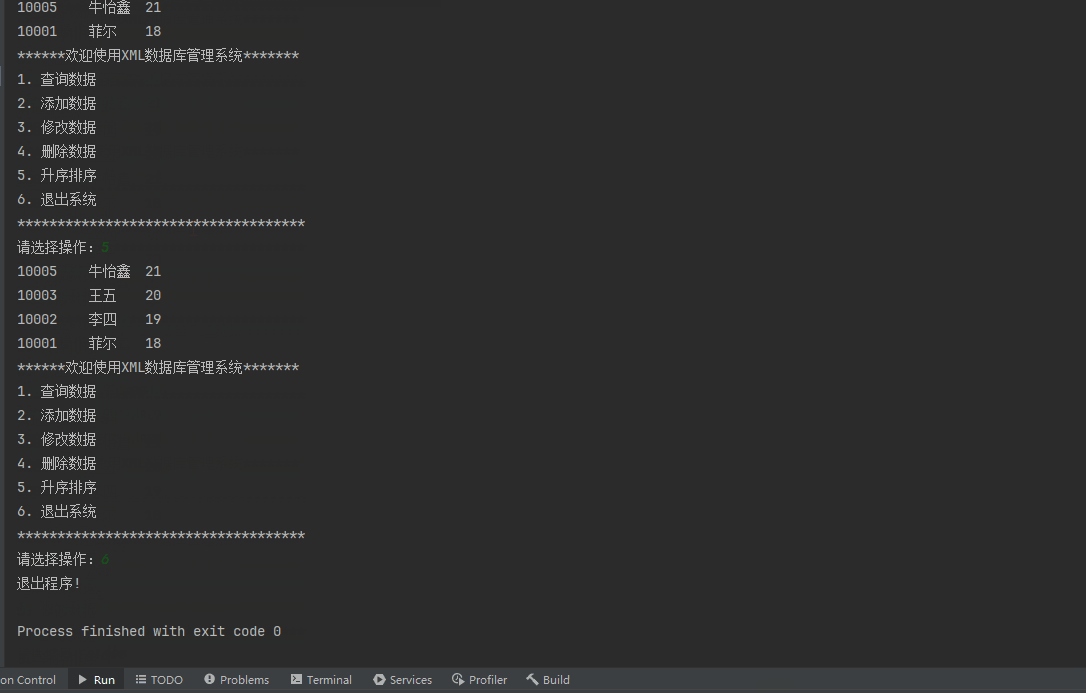
六、dom4j对比其他技术
| 解析库 | 内存消耗 | 易用性 | 功能扩展性 |
|---|---|---|---|
| W3C DOM | 高 | 较差 | 基础 |
| SAX | 低 | 复杂 | 有限 |
| JDOM | 中 | 中等 | 中等 |
| DOM4J | 可控 | 优 | 强 |