知识点回顾:
- 过拟合的判断:测试集和训练集同步打印指标
- 模型的保存和加载
- 仅保存权重
- 保存权重和模型
- 保存全部信息checkpoint,还包含训练状态
- 早停策略


作业:对信贷数据集训练后保存权重,加载权重后继续训练50轮,并采取早停策略
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 导入tqdm库用于进度条显示
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息# 设置中文字体,确保中文正常显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams['axes.unicode_minus'] = False # 确保负号正确显示# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每200个epoch的损失值和对应的epoch数
train_losses = [] # 存储训练集损失
test_losses = [] # 存储测试集损失
epochs = []start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数train_loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()train_loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:# 计算测试集损失model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'训练损失': f'{train_loss.item():.4f}', '测试损失': f'{test_loss.item():.4f}'})# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'训练时间: {time_all:.2f} 秒')# 可视化损失曲线
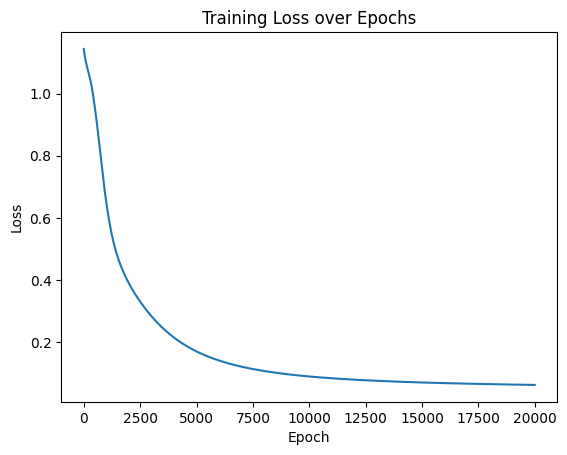
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='训练损失')
plt.plot(epochs, test_losses, label='测试损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('不同Epoch下的训练和测试损失')
plt.legend()
plt.grid(True)
plt.show()# 在测试集上评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 禁用梯度计算,提高推理速度# 确保所有操作在GPU上执行outputs = model(X_test).to(device)_, predicted = torch.max(outputs, 1)# 计算准确率correct = (predicted == y_test).sum().item()total = y_test.size(0)accuracy = correct / total# 计算各类别的精确率、召回率和F1分数classes = ['山鸢尾', '变色鸢尾', '维吉尼亚鸢尾']class_correct = [0. for _ in range(len(classes))]class_total = [0. for _ in range(len(classes))]# 计算每个类别的正确预测数c = (predicted == y_test).squeeze()for i in range(len(y_test)):label = y_test[i]class_correct[label] += c[i].item()class_total[label] += 1# 打印总体准确率print(f'\n测试集总体准确率: {accuracy * 100:.2f}%')# 打印每个类别的准确率print('\n各类别的准确率:')for i in range(len(classes)):if class_total[i] > 0:print(f' {classes[i]}: {100 * class_correct[i] / class_total[i]:.2f}%')else:print(f' {classes[i]}: N/A')
使用设备: cuda:0
训练进度: 100%|██████████| 20000/20000 [00:11<00:00, 1666.69epoch/s, 训练损失=0.0625, 测试损失=0.0562]
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
...
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
训练时间: 12.00 秒
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
...
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
测试集总体准确率: 96.67% 各类别的准确率: 山鸢尾: 100.00% 变色鸢尾: 88.89% 维吉尼亚鸢尾: 100.00%
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
import time
import matplotlib.pyplot as plt
from tqdm import tqdm
import warnings
import pandas as pd
import numpy as np
import oswarnings.filterwarnings("ignore")# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载信贷数据集
try:# 使用原始字符串表示Windows路径data = pd.read_csv(r'D:\代码\项目一信贷风险预测\data.csv')# 假设最后一列是目标变量,其余列是特征X = data.iloc[:, :-1]y = data.iloc[:, -1].values
except Exception as e:print(f"无法加载数据: {e}")print("使用模拟数据进行演示...")# 创建模拟数据np.random.seed(42)n_samples = 1000X = pd.DataFrame({'age': np.random.normal(35, 10, n_samples),'income': np.random.normal(50000, 20000, n_samples),'credit_history': np.random.choice(['good', 'bad', 'neutral'], n_samples),'home_ownership': np.random.choice(['Rent', 'Own', 'Mortgage'], n_samples),'loan_amount': np.random.normal(10000, 5000, n_samples)})# 创建目标变量y = ((X['age'] > 30) & (X['income'] > 40000) & (X['credit_history'] == 'good') |(X['home_ownership'] == 'Own')).astype(int).values# 识别分类特征和数值特征
categorical_features = X.select_dtypes(include=['object', 'category']).columns.tolist()
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns.tolist()# 创建预处理管道
preprocessor = ColumnTransformer(transformers=[('num', MinMaxScaler(), numeric_features),('cat', OneHotEncoder(), categorical_features)])# 应用预处理
X_transformed = preprocessor.fit_transform(X)# 检查转换后的数据类型,如果是稀疏矩阵则转换为密集数组
if hasattr(X_transformed, 'toarray'):X_transformed = X_transformed.toarray()# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_transformed, y, test_size=0.2, random_state=42)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)# 定义模型
class MLP(nn.Module):def __init__(self, input_size, num_classes):super(MLP, self).__init__()self.fc1 = nn.Linear(input_size, 10)self.relu = nn.ReLU()self.fc2 = nn.Linear(10, num_classes)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
input_size = X_train.shape[1]
num_classes = len(torch.unique(y_train))
model = MLP(input_size, num_classes).to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000
# 用于存储每200个epoch的损失值和对应的epoch数
train_losses = []
test_losses = []
epochs = []# 早停相关参数
best_test_loss = float('inf')
best_epoch = 0
patience = 50
counter = 0
early_stopped = Falsestart_time = time.time()# 创建保存模型的目录
model_dir = 'models'
os.makedirs(model_dir, exist_ok=True)
best_model_path = os.path.join(model_dir, 'best_model.pth')# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:for epoch in range(num_epochs):# 前向传播outputs = model(X_train)train_loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()train_loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:# 计算测试集损失model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})# 早停逻辑if test_loss.item() < best_test_loss:best_test_loss = test_loss.item()best_epoch = epoch + 1counter = 0# 保存最佳模型torch.save(model.state_dict(), best_model_path)print(f"在第{epoch+1}轮保存了最佳模型,测试集损失: {test_loss.item():.4f}")else:counter += 1if counter >= patience:print(f"早停触发!在第{epoch+1}轮,测试集损失已有{patience}轮未改善。")print(f"最佳测试集损失出现在第{best_epoch}轮,损失值为{best_test_loss:.4f}")early_stopped = Truebreak# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000)# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n)time_all = time.time() - start_time
print(f'Training time: {time_all:.2f} seconds')# 检查是否保存了最佳模型
if os.path.exists(best_model_path):print(f"加载最佳模型(第{best_epoch}轮)进行最终评估...")model.load_state_dict(torch.load(best_model_path))
else:print("没有找到保存的最佳模型,使用最后一轮训练的模型进行评估")# 可视化损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss')
plt.plot(epochs, test_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend()
plt.grid(True)
plt.show()# 在测试集上评估模型
model.eval()
with torch.no_grad():outputs = model(X_test)_, predicted = torch.max(outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%')# 加载权重后继续训练50轮
if os.path.exists(best_model_path):print("加载最佳模型权重,继续训练50轮...")model.load_state_dict(torch.load(best_model_path))
else:print("没有找到保存的最佳模型,使用当前模型继续训练")num_additional_epochs = 50
with tqdm(total=num_additional_epochs, desc="继续训练进度", unit="epoch") as pbar:for epoch in range(num_additional_epochs):# 前向传播outputs = model(X_train)train_loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()train_loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 1 == 0:# 计算测试集损失model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()# 更新进度条的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})pbar.update(1)# 再次在测试集上评估模型
model.eval()
with torch.no_grad():outputs = model(X_test)_, predicted = torch.max(outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)print(f'继续训练50轮后的测试集准确率: {accuracy * 100:.2f}%')
使用设备: cuda:0
训练进度: 100%|██████████| 20000/20000 [00:06<00:00, 3264.31epoch/s, Train Loss=nan, Test Loss=nan]
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
...
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
早停触发!在第10000轮,测试集损失已有50轮未改善。
最佳测试集损失出现在第0轮,损失值为inf
Training time: 6.13 seconds
没有找到保存的最佳模型,使用最后一轮训练的模型进行评估
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
...
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
findfont: Font family 'WenQuanYi Micro Hei' not found.
findfont: Font family 'Heiti TC' not found.
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...孩子们,因为停的太早,甚至画不出图
测试集准确率: 70.60% 没有找到保存的最佳模型,使用当前模型继续训练
继续训练进度: 100%|██████████| 50/50 [00:00<00:00, 413.56epoch/s, Train Loss=nan, Test Loss=nan]
继续训练50轮后的测试集准确率: 70.60%
@浙大疏锦行