Content
- 线性层 (Linear Layers)
- **核心原理:线性变换**
- **关键组件**
- **示例代码**
- **示例1:基础线性层 (`nn.Linear`)**
- **示例2:双线性层 (`nn.Bilinear`)**
- **应用场景**
- 非线性激活函数 (Non-linear Activations)
- **常用非线性激活函数**
- **1. ReLU(Rectified Linear Unit)**
- **2. LeakyReLU**
- **3. Sigmoid**
- **4. Tanh**
- **5. Softmax**
- **6. GELU(Gaussian Error Linear Unit)**
- **7. ELU(Exponential Linear Unit)**
- **8. SiLU(Sigmoid Linear Unit)/ Swish**
- **其他激活函数**
- **应用示例**
- 1. CNN中的激活函数
- 2. Transformer中的激活函数
- **选择激活函数的经验法则**
- **可视化比较**
- 损失函数(Loss Functions)
- **回归任务损失函数**
- **1. `nn.MSELoss` (均方误差)**
- **2. `nn.L1Loss` (平均绝对误差)**
- **3. `nn.SmoothL1Loss` (Huber Loss)**
- **分类任务损失函数**
- **4. `nn.CrossEntropyLoss` (交叉熵损失)**
- **5. `nn.BCELoss` (二分类交叉熵)**
- **6. `nn.BCEWithLogitsLoss`**
- **特殊任务损失函数**
- **7. `nn.NLLLoss` (负对数似然损失)**
- **8. `nn.KLDivLoss` (KL散度)**
- **9. `nn.TripletMarginLoss` (三元组损失)**
- **10. `nn.CosineEmbeddingLoss` (余弦相似度损失)**
- **损失函数选择**
- **其他**
- 归一化层(Normalization Layers)
- 1. **BatchNorm (批归一化)**
- 2. **LayerNorm (层归一化)**
- 3. **InstanceNorm (实例归一化)**
- 4. **GroupNorm (组归一化)**
- **关键对比总结**
- **选择建议**
- Dropout 层
- 核心思想
- Dropout 层类型
- (1) `nn.Dropout` (标准 Dropout)
- (2) `nn.Dropout1d/2d/3d` (通道级 Dropout)
- 关键参数
- 使用示例
- 最佳实践
- 稀疏层(Sparse Layers)
- 核心概念
- nn.Embedding
- 直观理解
- 关键特性
- 参数说明
- 可视化理解
- 使用示例
- 示例1:基本用法(词嵌入)
- 示例2:处理填充值(padding_idx)
- 应用示例
- NLP 模型示例
- 推荐系统示例
- 稀疏层最佳实践
- 预训练嵌入
- 循环层(Recurrent Layers)
- 1. **RNN (Recurrent Neural Network)**
- 2. **LSTM (Long Short-Term Memory)**
- 3. **GRU (Gated Recurrent Unit)**
- 关键参数说明
- 何时使用哪种循环层?
- Transformer Layers
- 核心组件
- 1. **自注意力机制 (Self-Attention)**
- 2. **多头注意力 (Multi-Head Attention)**
- 3. **位置编码 (Positional Encoding)**
- 4. **Transformer架构**
- Transformer组件
- 完整示例:文本情感分类(从HuggingFace下载数据和模型)
- 关键参数说明
- 卷积层 (Convolution Layers)
- 核心原理
- 参数说明
- 应用代码
- 示例:边缘检测
- 输入数据 (5x5 单通道图像)
- 创建垂直边缘检测卷积核
- 执行卷积操作
- 输出结果
- 结果分析
- 不同卷积核效果示例
- 池化层(Pooling Layers)
- **核心原理**
- **示例**
- **最大池化(MaxPool2d)**
- **平均池化(AvgPool2d)**
- **关键参数解析**
- **应用场景**
- **代码示例**
- 填充层 (Padding Layers)
- 常见填充类型
- 示例
- 示例1:零填充 (ZeroPad2d)
- 示例2:反射填充 (ReflectionPad2d)
- 示例3:常数填充 (ConstantPad2d)
- 填充层与卷积层的配合使用
- 保持尺寸不变的卷积
- 与卷积层的尺寸关系
线性层 (Linear Layers)
Linear Layers(线性层) 是最基础的神经网络层,用于实现全连接(Fully Connected)操作。核心原理是通过矩阵乘法将输入特征空间线性映射到输出特征空间。
核心原理:线性变换
线性层的数学表达:
output = input × weightᵀ + bias
其中:
input:输入数据,形状为(batch_size, in_features)weight:可学习权重,形状为(out_features, in_features)bias:可学习偏置,形状为(out_features,)output:输出数据,形状为(batch_size, out_features)
关键组件
-
nn.Linear- 功能:基础线性变换层。
- 参数:
in_features:输入特征维度out_features:输出特征维度bias=True:是否启用偏置(默认启用)
-
nn.Bilinear(双线性层)- 功能:对两个输入进行双线性变换:
y = x1ᵀ · A · x2 + b - 参数:
in1_features:输入1的维度in2_features:输入2的维度out_features:输出维度
- 功能:对两个输入进行双线性变换:
示例代码
示例1:基础线性层 (nn.Linear)
import torch
import torch.nn as nn# 创建输入:batch_size=2, in_features=3
input = torch.tensor([[1.0, 2.0, 3.0],[4.0, 5.0, 6.0]])# 定义线性层:3维输入 -> 2维输出
linear_layer = nn.Linear(in_features=3, out_features=2)# 手动设置权重和偏置(便于理解)
linear_layer.weight.data = torch.tensor([[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]])
linear_layer.bias.data = torch.tensor([0.01, 0.02])# 前向传播
output = linear_layer(input)
print(output)
输出:
tensor([[1.3100, 3.0200], # 计算过程:[1*0.1+2*0.2+3*0.3+0.01, 1*0.4+2*0.5+3*0.6+0.02][3.1400, 6.9200]], grad_fn=<AddmmBackward>)
示例2:双线性层 (nn.Bilinear)
# 输入1: batch_size=2, in_features=2
x1 = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
# 输入2: batch_size=2, in_features=3
x2 = torch.tensor([[5.0, 6.0, 7.0], [8.0, 9.0, 10.0]])# 定义双线性层:x1(2维) + x2(3维) -> 输出(4维)
bilinear_layer = nn.Bilinear(in1_features=2, in2_features=3, out_features=4)# 前向传播
output = bilinear_layer(x1, x2)
print(output.shape) # 输出形状: torch.Size([2, 4])
应用场景
- 分类网络最后一层:
model = nn.Sequential(nn.Flatten(),nn.Linear(784, 256), # MNIST图像: 28x28=784 -> 256维隐藏层nn.ReLU(),nn.Linear(256, 10) # 输出10个类别 ) - 注意力机制中的投影:
# 将查询向量投影到键/值空间 query_proj = nn.Linear(d_model, d_k) key_proj = nn.Linear(d_model, d_k)
非线性激活函数 (Non-linear Activations)
如果神经网络只有线性层,无论多深都等价于单个线性变换(y = Wx + b)。非线性激活函数为模型引入非线性能力,使网络能够学习复杂模式。
常用非线性激活函数
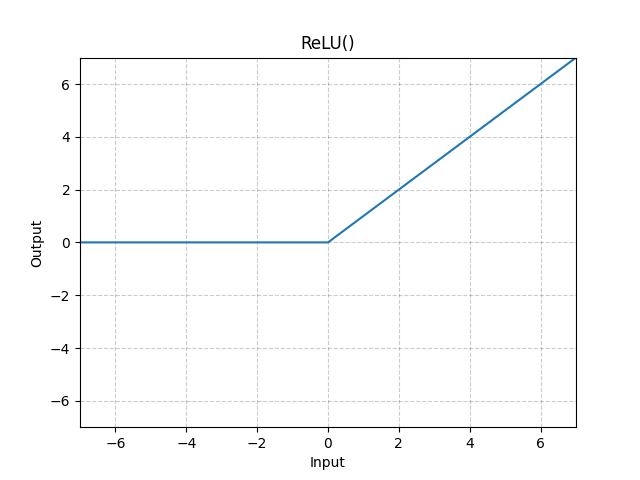
1. ReLU(Rectified Linear Unit)
-
公式:
f(x) = max(0, x)
-
直观解释:所有负输入变为0,正输入保持不变
-
优点:计算高效,缓解梯度消失
-
缺点:"Dying ReLU"问题(负输入梯度为0)
-
示例:
relu = nn.ReLU() input = torch.tensor([-1.0, 2.0, -3.0, 4.0]) output = relu(input) # [0., 2., 0., 4.]
2. LeakyReLU
-
公式:
f(x) = max(0.01x, x)(0.01可调整)
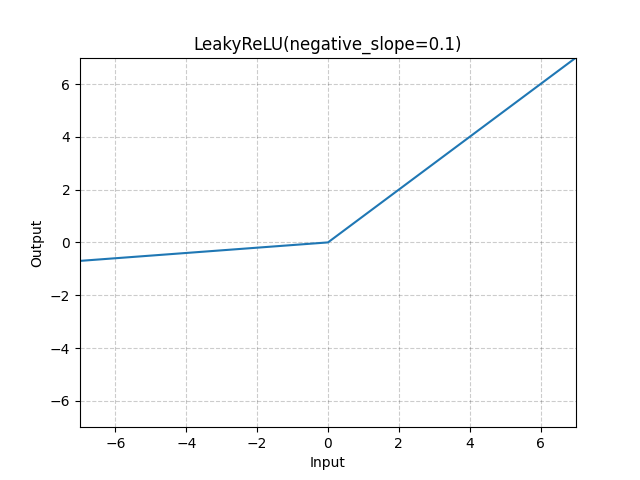
-
直观解释:给负输入小的斜率,避免"死亡神经元"
-
优点:解决Dying ReLU问题
-
示例:
leaky = nn.LeakyReLU(negative_slope=0.01) input = torch.tensor([-1.0, 2.0]) output = leaky(input) # [-0.01, 2.0]
3. Sigmoid
-
公式:
f(x) = 1 / (1 + exp(-x))
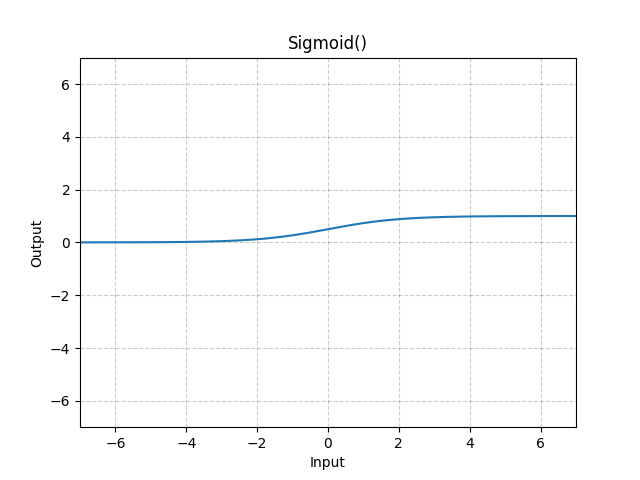
-
直观解释:将输入压缩到(0,1)区间
-
用途:二分类输出层、概率估计
-
缺点:梯度消失(两端饱和区)
-
示例:
sigmoid = nn.Sigmoid() input = torch.tensor([0.0, -2.0, 1.0]) output = sigmoid(input) # [0.5, ~0.119, ~0.731]
4. Tanh
-
公式:
f(x) = (e^x - e^{-x}) / (e^x + e^{-x})
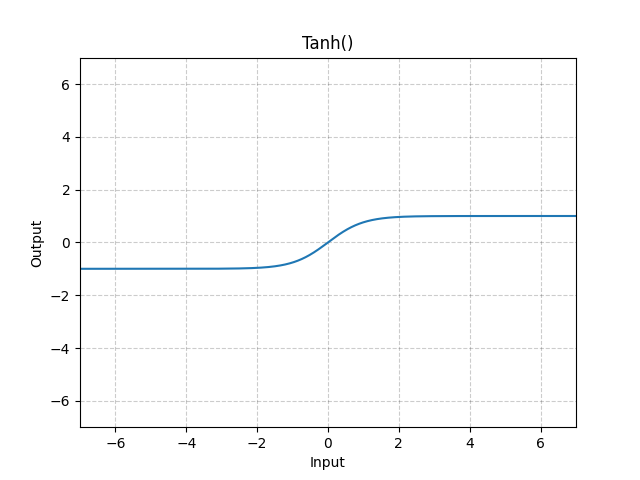
-
直观解释:将输入压缩到(-1,1)区间,以0为中心
-
优点:比sigmoid梯度更强
-
示例:
tanh = nn.Tanh() input = torch.tensor([0.0, -1.0, 2.0]) output = tanh(input) # [0., ~-0.761, ~0.964]
5. Softmax
- 公式:
f(x_i) = exp(x_i) / ∑_j exp(x_j) - 直观解释:将向量转换为概率分布(和为1)
- 用途:多分类输出层
- 示例:
softmax = nn.Softmax(dim=1) input = torch.tensor([[1.0, 2.0, 3.0]]) output = softmax(input) # [[0.0900, 0.2447, 0.6652]]
6. GELU(Gaussian Error Linear Unit)
-
公式:
x * Φ(x)(Φ是标准正态CDF)
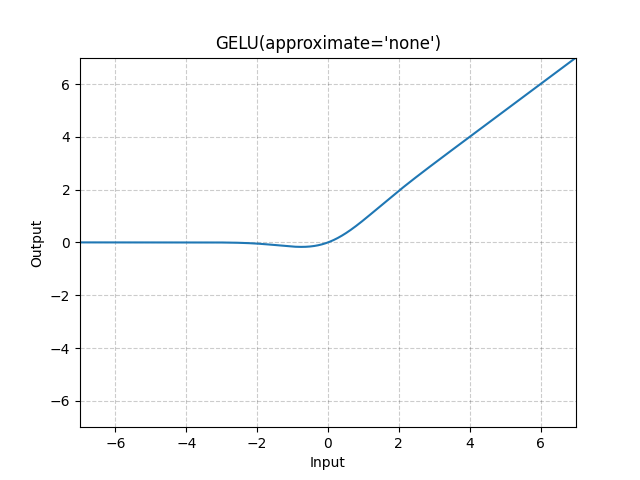
-
直观解释:ReLU的平滑版本,被BERT/GPT使用
-
优点:更符合神经元的实际激活行为
-
示例:
gelu = nn.GELU() input = torch.tensor([1.0, -1.0]) output = gelu(input) # [0.841, -0.159] (近似值)
7. ELU(Exponential Linear Unit)
-
公式:
x if x>0 else α*(exp(x)-1)
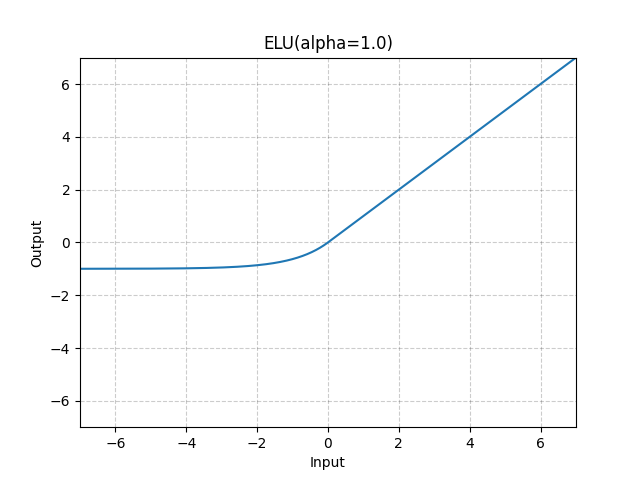
-
直观解释:负值区域有指数曲线
-
优点:缓解梯度消失,输出均值接近0
-
示例:
elu = nn.ELU(alpha=1.0) input = torch.tensor([-1.0, 2.0]) output = elu(input) # [-0.632, 2.0]
8. SiLU(Sigmoid Linear Unit)/ Swish
-
公式:
x * sigmoid(x)
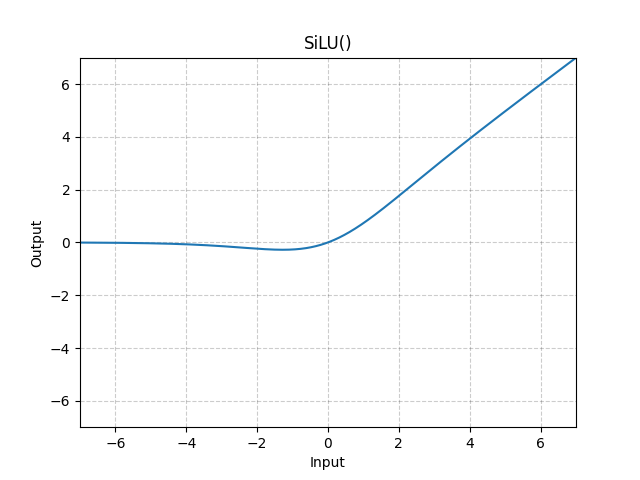
-
直观解释:ReLU的平滑替代,Google提出
-
优点:在深层网络中表现优异
-
示例:
silu = nn.SiLU() input = torch.tensor([1.0, -1.0]) output = silu(input) # [1.0*sigmoid(1.0)≈0.731, -0.269]
其他激活函数
| 激活函数 | 特点 | 适用场景 |
|---|---|---|
nn.Softplus | 平滑的ReLU替代 (log(1+e^x)) | 需要处处可微的场景 |
nn.Softsign | 比tanh更平滑 (`x/(1+ | x |
nn.Mish | 自门控激活 (x*tanh(softplus(x))) | 计算机视觉模型 |
nn.CELU | ELU的复数版本 | 复数神经网络 |
nn.SELU | 自归一化网络的专用激活 | SNN架构 |
应用示例
1. CNN中的激活函数
model = nn.Sequential(nn.Conv2d(3, 16, 3),nn.ReLU(), # 卷积后常用ReLUnn.MaxPool2d(2),nn.Conv2d(16, 32, 3),nn.LeakyReLU(0.1), # 防止梯度消失nn.Flatten(),nn.Linear(32*6*6, 128),nn.GELU(), # 全连接层用GELUnn.Linear(128, 10)
)
2. Transformer中的激活函数
class TransformerBlock(nn.Module):def __init__(self, d_model):super().__init__()self.attn = nn.MultiheadAttention(d_model, 8)self.ff = nn.Sequential(nn.Linear(d_model, 4*d_model),nn.GELU(), # Transformer常用GELUnn.Linear(4*d_model, d_model))
选择激活函数的经验法则
- 隐藏层:优先尝试 ReLU → LeakyReLU → GELU
- 输出层:
- 二分类:Sigmoid
- 多分类:Softmax
- 回归:不使用激活(线性输出)
- 特殊架构:
- Transformer:GELU
- SNN:SELU
- 梯度消失敏感:LeakyReLU/ELU
可视化比较
输入范围: [-4, 4]ReLU: [0,0,0,0,0,1,2,3,4]
LeakyReLU: [-0.04,-0.03,-0.02,-0.01,0,1,2,3,4]
Sigmoid: [0.018,0.047,0.119,0.269,0.5,0.731,0.881,0.952,0.982]
Tanh: [-0.96,-0.76,-0.46,-0.1,0,0.76,0.96,0.995,0.999]
GELU: [-0.28,-0.16,-0.04,0.14,0.5,1.05,1.94,2.99,3.99]
损失函数(Loss Functions)
损失函数(Loss Functions) 用于量化模型预测与真实目标之间的差异,为优化算法提供梯度方向。
回归任务损失函数
1. nn.MSELoss (均方误差)
- 公式: 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \frac{1}{n}\sum_{i=1}^n(y_i - \hat{y}_i)^2 n1∑i=1n(yi−y^i)2
- 直观解释:预测值与真实值差的平方的平均值
- 应用场景:连续值预测(房价预测、温度预测等)
- 特点:对异常值敏感
- 示例:
mse_loss = nn.MSELoss() output = torch.tensor([1.8, 2.4]) # 模型预测值 target = torch.tensor([2.0, 2.0]) # 真实值 loss = mse_loss(output, target) # ((1.8-2.0)**2 + (2.4-2.0)**2)/2 = 0.1
2. nn.L1Loss (平均绝对误差)
- 公式: 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \frac{1}{n}\sum_{i=1}^n|y_i - \hat{y}_i| n1∑i=1n∣yi−y^i∣
- 直观解释:预测值与真实值绝对差的平均值
- 应用场景:对异常值稳健的回归任务
- 示例:
l1_loss = nn.L1Loss() output = torch.tensor([1.5, 2.5]) target = torch.tensor([2.0, 2.0]) loss = l1_loss(output, target) # (|1.5-2.0| + |2.5-2.0|)/2 = 0.5
3. nn.SmoothL1Loss (Huber Loss)
- 公式:
{ 0.5 ( x − y ) 2 if ∣ x − y ∣ < 1 ∣ x − y ∣ − 0.5 otherwise \begin{cases} 0.5(x-y)^2 & \text{if } |x-y| < 1 \\ |x-y| - 0.5 & \text{otherwise} \end{cases} {0.5(x−y)2∣x−y∣−0.5if ∣x−y∣<1otherwise - 直观解释:MSELoss和L1Loss的结合,对异常值不敏感
- 应用场景:目标检测中的边界框回归(Faster R-CNN)
- 示例:
smooth_l1 = nn.SmoothL1Loss() output = torch.tensor([0.5, 1.5]) target = torch.tensor([1.0, 1.0]) loss = smooth_l1(output, target) # [0.5*(0.5)^2, |1.5-1.0|-0.5] = [0.125, 0]
分类任务损失函数
4. nn.CrossEntropyLoss (交叉熵损失)
- 公式: − ∑ c = 1 C y c log ( y ^ c ) -\sum_{c=1}^C y_c \log(\hat{y}_c) −∑c=1Cyclog(y^c)
- 直观解释:衡量预测概率分布与真实分布的差异
- 应用场景:多分类任务(图像分类、文本分类)
- 特点:内部自动应用Softmax
- 示例:
ce_loss = nn.CrossEntropyLoss() # 3个样本,每个样本预测5个类别的logits output = torch.randn(3, 5) # 模型输出(未归一化) target = torch.tensor([1, 0, 4]) # 真实类别索引 loss = ce_loss(output, target)
5. nn.BCELoss (二分类交叉熵)
- 公式: − 1 n ∑ i [ y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ] -\frac{1}{n}\sum_i [y_i \log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i)] −n1∑i[yilog(y^i)+(1−yi)log(1−y^i)]
- 直观解释:针对二分类任务的交叉熵
- 应用场景:二分类任务(垃圾邮件检测)
- 要求:输入必须经过Sigmoid(值在[0,1])
- 示例:
bce_loss = nn.BCELoss() output = torch.sigmoid(model(input)) # 预测概率 target = torch.tensor([1., 0., 1.]) # 二分类标签 loss = bce_loss(output, target)
6. nn.BCEWithLogitsLoss
- 功能:BCELoss + Sigmoid(数值稳定版)
- 应用场景:同BCELoss,但避免数值不稳定
- 示例:
bce_logits_loss = nn.BCEWithLogitsLoss() output = model(input) # 原始logits target = torch.tensor([1., 0., 1.]) loss = bce_logits_loss(output, target)
特殊任务损失函数
7. nn.NLLLoss (负对数似然损失)
- 公式: − ∑ y i log ( y ^ i ) -\sum y_i \log(\hat{y}_i) −∑yilog(y^i)
- 应用场景:配合LogSoftmax使用,用于多分类
- 示例:
nll_loss = nn.NLLLoss() output = torch.log_softmax(model(input), dim=1) # 对数概率 target = torch.tensor([1, 0, 3]) # 类别索引 loss = nll_loss(output, target)
8. nn.KLDivLoss (KL散度)
- 公式: ∑ y i ( log y i − log y ^ i ) \sum y_i (\log y_i - \log \hat{y}_i) ∑yi(logyi−logy^i)
- 直观解释:衡量两个概率分布的差异
- 应用场景:知识蒸馏、变分自编码器(VAE)
- 示例:
kl_loss = nn.KLDivLoss(reduction="batchmean") output = torch.log_softmax(model(input), dim=1) target = torch.softmax(teacher_output, dim=1) loss = kl_loss(output, target)
9. nn.TripletMarginLoss (三元组损失)
- 公式: max ( 0 , ∥ anchor − positive ∥ 2 − ∥ anchor − negative ∥ 2 + margin ) \max(0, \| \text{anchor} - \text{positive} \|^2 - \| \text{anchor} - \text{negative} \|^2 + \text{margin}) max(0,∥anchor−positive∥2−∥anchor−negative∥2+margin)
- 直观解释:拉近正样本,推远负样本
- 应用场景:人脸识别、相似度学习
- 示例:
triplet_loss = nn.TripletMarginLoss(margin=0.3) anchor = torch.randn(10, 128) # 锚点样本 positive = torch.randn(10, 128) # 同类样本 negative = torch.randn(10, 128) # 异类样本 loss = triplet_loss(anchor, positive, negative)
10. nn.CosineEmbeddingLoss (余弦相似度损失)
- 公式: { 1 − cos ( x 1 , x 2 ) if y = 1 max ( 0 , cos ( x 1 , x 2 ) − margin ) if y = − 1 \begin{cases} 1 - \cos(x1,x2) & \text{if } y=1 \\ \max(0, \cos(x1,x2) - \text{margin}) & \text{if } y=-1 \end{cases} {1−cos(x1,x2)max(0,cos(x1,x2)−margin)if y=1if y=−1
- 应用场景:文本相似度、推荐系统
- 示例:
cos_loss = nn.CosineEmbeddingLoss() input1 = torch.randn(3, 128) # 样本1 input2 = torch.randn(3, 128) # 样本2 target = torch.tensor([1, -1, 1]) # 1:相似, -1:不相似 loss = cos_loss(input1, input2, target)
损失函数选择
| 任务类型 | 推荐损失函数 | 应用场景示例 |
|---|---|---|
| 多分类 | CrossEntropyLoss | MNIST手写数字识别 |
| 二分类 | BCEWithLogitsLoss | 垃圾邮件检测 |
| 多标签分类 | BCEWithLogitsLoss | 图像多标签分类 |
| 回归 | MSELoss / SmoothL1Loss | 房价预测 |
| 目标检测 | SmoothL1Loss + CrossEntropyLoss | Faster R-CNN |
| 相似度学习 | TripletMarginLoss | 人脸识别 |
| 知识蒸馏 | KLDivLoss | 模型压缩 |
| 序列生成 | NLLLoss | 机器翻译 |
其他
-
分类不平衡问题:
# 为不同类别设置权重 weights = torch.tensor([0.1, 0.9]) # 类别1样本少,权重高 ce_loss = nn.CrossEntropyLoss(weight=weights) -
自定义损失组合:
def custom_loss(output, target):mse = nn.MSELoss()(output[:, 0], target[:, 0])ce = nn.CrossEntropyLoss()(output[:, 1:], target[:, 1])return 0.7*mse + 0.3*ce -
标签平滑(防止过拟合):
ce_loss = nn.CrossEntropyLoss(label_smoothing=0.1)
归一化层(Normalization Layers)
归一化层(Normalization Layers) 通过标准化输入数据来加速训练、提高模型稳定性和泛化能力。
1. BatchNorm (批归一化)
核心思想:对每个特征通道,在整个批次的样本上计算均值和方差(按通道独立归一化)。
适用场景:全连接网络和卷积网络(batch size 较大时)。
操作维度:(N, C, H, W) 输入中,对每个通道 c,沿 N, H, W 维度计算统计量。
公式:
x ^ = x − μ c σ c 2 + ϵ ; y = γ c x ^ + β c \hat{x} = \frac{x - \mu_c}{\sqrt{\sigma_c^2 + \epsilon}} \quad ; \quad y = \gamma_c \hat{x} + \beta_c x^=σc2+ϵx−μc;y=γcx^+βc
示例:
import torch.nn as nn# 卷积网络中的 BatchNorm (通道数=3)
bn = nn.BatchNorm2d(num_features=3)
input = torch.randn(16, 3, 32, 32) # [batch, channels, height, width]
output = bn(input) # 输出形状不变
2. LayerNorm (层归一化)
核心思想:对单个样本的所有特征计算均值和方差(按样本独立归一化)。
适用场景:RNN/Transformer 等序列模型(对序列长度变化鲁棒)。
操作维度:在 (N, C, H, W) 输入中,对每个样本 n,沿 C, H, W 维度计算统计量。
示例:
# 用于 NLP 的 Transformer 模型
ln = nn.LayerNorm([512]) # 归一化特征维度=512
input = torch.randn(10, 20, 512) # [batch, seq_len, features]
output = ln(input) # 每个样本独立归一化
3. InstanceNorm (实例归一化)
核心思想:对每个样本的每个通道独立计算均值和方差(分离内容与风格)。
适用场景:风格迁移、GANs(对单个样本做归一化)。
操作维度:在 (N, C, H, W) 输入中,对每个样本 n 和通道 c,沿 H, W 维度计算统计量。
示例:
# 风格迁移网络
in_norm = nn.InstanceNorm2d(num_features=3)
input = torch.randn(1, 3, 256, 256) # 单张图像
output = in_norm(input) # 每个通道独立归一化
4. GroupNorm (组归一化)
核心思想:将通道分组,对每个样本的组内通道计算统计量(BatchNorm 的替代方案)。
适用场景:小 batch 任务(如目标检测、视频处理)。
操作维度:在 (N, C, H, W) 输入中,将 C 个通道分为 G 组,对每个样本 n 和组 g,沿组内通道和 H, W 计算统计量。
示例:
# 小 batch 场景 (batch_size=2)
gn = nn.GroupNorm(num_groups=2, num_channels=4) # 4个通道分成2组
input = torch.randn(2, 4, 32, 32)
output = gn(input) # 不依赖 batch 统计
关键对比总结
| 方法 | 统计量计算范围 | 适用场景 |
|---|---|---|
| BatchNorm | 整个批次 + 空间维度 | 大 batch 的 CNN/FCN |
| LayerNorm | 单个样本的所有特征 | RNN/Transformer 等序列模型 |
| InstanceNorm | 单个样本的单个通道 | 风格迁移、GANs |
| GroupNorm | 单个样本的通道组 | 小 batch 任务 |
选择建议
- 默认 CNN 使用 BatchNorm(batch size ≥ 16)。
- 序列模型(如 Transformer)用 LayerNorm。
- 风格迁移用 InstanceNorm。
- batch size 过小时用 GroupNorm(如检测/分割任务)。
Dropout 层
Dropout 层用于防止神经网络过拟合。它的工作原理简单却高效:在训练过程中随机"丢弃"(置零)一部分神经元,迫使网络不依赖任何单个神经元,从而学习到更鲁棒的特征。
核心思想
- 训练阶段:每次前向传播时,随机选择一部分神经元将其输出置零(通常比例为 p)
- 测试阶段:所有神经元保持激活,但输出值乘以 (1-p) 进行缩放(补偿训练时的丢弃)
- 效果:
- 打破神经元间的复杂共适应关系
- 相当于训练多个子网络的集成
- 提高模型的泛化能力
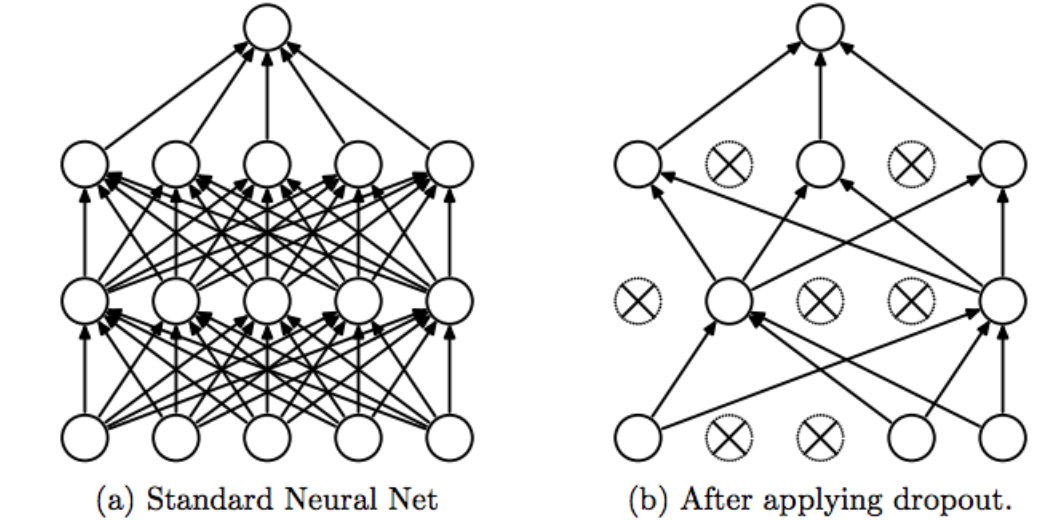
Dropout 层类型
(1) nn.Dropout (标准 Dropout)
- 适用场景:全连接层
- 工作方式:随机将输入张量的元素置零
- 缩放机制:训练时保留值乘以
1/(1-p)(保持期望值不变)
import torch.nn as nn# 创建 Dropout 层(丢弃概率 30%)
dropout = nn.Dropout(p=0.3)# 示例输入(全连接层输出)
fc_output = torch.randn(5, 10) # [batch_size, features]# 训练模式(应用 dropout)
train_output = dropout(fc_output)
print(train_output) # 约30%元素为0,其他元素放大1.43倍(1/0.7≈1.43)# 评估模式(无 dropout)
dropout.eval()
eval_output = dropout(fc_output)
print(eval_output)
(2) nn.Dropout1d/2d/3d (通道级 Dropout)
- 适用场景:卷积网络
- 特殊之处:随机丢弃整个特征通道(而不是单个元素)
- 优势:更适合卷积层的结构特性
# 2D Dropout(适用于卷积层输出)
dropout2d = nn.Dropout2d(p=0.2)# 卷积层输出 [batch, channels, height, width]
conv_output = torch.randn(4, 6, 28, 28) # 4张图像,6个通道# 训练时:随机丢弃20%的通道(整张特征图置零)
output = dropout2d(conv_output)
关键参数
| 参数 | 说明 | 默认值 |
|---|---|---|
p | 神经元被丢弃的概率 | 0.5 |
inplace | 是否原地操作(节省内存) | False |
使用示例
class NeuralNet(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(784, 512)self.drop1 = nn.Dropout(0.5) # 50% 丢弃率self.fc2 = nn.Linear(512, 256)self.drop2 = nn.Dropout(0.3) # 30% 丢弃率self.fc3 = nn.Linear(256, 10)def forward(self, x):x = torch.flatten(x, 1) # 展平输入x = torch.relu(self.fc1(x))x = self.drop1(x) # 在第一个全连接层后应用x = torch.relu(self.fc2(x))x = self.drop2(x) # 在第二个全连接层后应用x = self.fc3(x)return x# 使用注意事项
model = NeuralNet()
model.train() # 训练模式 → 启用 Dropout
model.eval() # 评估模式 → 禁用 Dropout
最佳实践
- 放置位置:通常放在激活函数之后(ReLU等非线性层后)
- 丢弃概率:
- 输入层:0.1-0.3
- 隐藏层:0.3-0.5
- 输出层:通常不使用
- 与批归一化配合:Dropout → BatchNorm 的顺序更有效
- 避免过度使用:太高的丢弃率或过多Dropout层会阻碍学习
- 模式切换:训练和测试时务必使用
.train()和.eval()
稀疏层(Sparse Layers)
稀疏层(Sparse Layers) 是用于处理高维稀疏数据的神经网络层,特别适合自然语言处理(NLP)和推荐系统等场景。这些层能够高效地处理包含大量零值的输入数据,避免不必要的计算。
核心概念
- 稀疏数据:数据中大部分元素为零(例如:词袋模型、用户-物品交互矩阵)
- 密集数据:大部分元素非零(例如:图像像素)
- 优势:稀疏层仅处理非零元素,大幅减少内存和计算开销
nn.Embedding
直观理解
nn.Embedding 是一个查找表(Lookup Table),它将离散的类别索引(如单词ID)映射到连续的稠密向量(嵌入向量)。想象成一本词典:
- 输入:单词的页码(整数索引)
- 输出:该页的详细解释(固定长度的向量)
关键特性
- 高效存储:仅存储嵌入向量,不存储零值
- 可学习参数:嵌入向量在训练过程中自动更新
- 降维效果:将高维稀疏输入转换为低维稠密表示
参数说明
nn.Embedding(num_embeddings, # 嵌入字典大小(不同类别的总数)embedding_dim, # 每个嵌入向量的维度padding_idx=None # 指定填充索引(可选)
)
可视化理解
词汇表:
索引0: <pad>
索引1: "猫" → 嵌入向量 [-0.2, 0.8, 0.1]
索引2: "狗" → 嵌入向量 [0.5, 0.3, -0.4]
索引3: "苹果" → 嵌入向量 [0.1, -0.2, 0.6]输入句子: "猫 吃 苹果" → 索引 [1, 4, 3]嵌入层输出:
[-0.2, 0.8, 0.1] # "猫"
[0.0, 0.0, 0.0] # "吃"(未登录词,假设索引4未初始化)
[0.1, -0.2, 0.6] # "苹果"
使用示例
示例1:基本用法(词嵌入)
import torch
import torch.nn as nn# 创建嵌入层:词汇表大小=10, 嵌入维度=3
embedding = nn.Embedding(num_embeddings=10, embedding_dim=3)# 输入数据(两个样本,每个样本包含3个单词ID)
input_indices = torch.tensor([[1, 2, 4], [4, 3, 0]]) # 形状 [2, 3]# 获取嵌入向量
output = embedding(input_indices)
print(output.shape) # 输出: torch.Size([2, 3, 3])
print(output)
"""
tensor([[[-0.7892, 1.2345, 0.5678], # 单词1的嵌入[ 0.1234, -0.9876, 0.5432], # 单词2的嵌入[ 0.8765, 0.2345, -1.1111]], # 单词4的嵌入[[ 0.8765, 0.2345, -1.1111], # 单词4的嵌入[-0.2222, 0.3333, 0.4444], # 单词3的嵌入[ 0.0000, 0.0000, 0.0000]]], # 单词0的嵌入(若未指定padding_idx)grad_fn=<EmbeddingBackward>)
"""
示例2:处理填充值(padding_idx)
# 指定索引0为填充值
embedding = nn.Embedding(10, 3, padding_idx=0)input_indices = torch.tensor([[0, 2, 4], [4, 0, 1]]) # 0表示填充output = embedding(input_indices)
print(output[0, 0]) # 输出: tensor([0., 0., 0.]) 填充位置返回零向量
应用示例
NLP 模型示例
class TextClassifier(nn.Module):def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):super().__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.rnn = nn.LSTM(embed_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, num_classes)def forward(self, text_ids):# text_ids: [batch_size, seq_len]embedded = self.embedding(text_ids) # [batch_size, seq_len, embed_dim]_, (hidden, _) = self.rnn(embedded)return self.fc(hidden[-1])# 使用示例
model = TextClassifier(vocab_size=10000, embed_dim=128, hidden_dim=256, num_classes=5)
input_ids = torch.randint(0, 10000, (32, 50)) # 32个样本,每个50个单词ID
output = model(input_ids) # 输出形状: [32, 5]
推荐系统示例
class Recommender(nn.Module):def __init__(self, num_users, num_items, embed_dim):super().__init__()self.user_embed = nn.Embedding(num_users, embed_dim)self.item_embed = nn.Embedding(num_items, embed_dim)def forward(self, user_ids, item_ids):user_emb = self.user_embed(user_ids) # [batch_size, embed_dim]item_emb = self.item_embed(item_ids) # [batch_size, embed_dim]return torch.sum(user_emb * item_emb, dim=1) # 点积得分# 使用示例
model = Recommender(num_users=10000, num_items=5000, embed_dim=64)
users = torch.tensor([123, 456, 789]) # 用户ID
items = torch.tensor([42, 87, 105]) # 物品ID
scores = model(users, items) # 预测得分 [3]
稀疏层最佳实践
- 使用
padding_idx处理可变长度序列 - 对于冻结的嵌入(如预训练词向量),设置
freeze=True - 嵌入维度通常选择32-1024(根据任务复杂度调整)
- 配合
nn.EmbeddingBag处理变长序列(更高效)
预训练嵌入
# 加载预训练词向量(例如GloVe)
pretrained_embeddings = torch.tensor([[0.1, 0.2, 0.3], # 索引0[0.4, 0.5, 0.6], # 索引1[0.7, 0.8, 0.9] # 索引2
])# 创建嵌入层并初始化
embedding = nn.Embedding.from_pretrained(pretrained_embeddings,freeze=False, # 是否冻结参数(不更新)padding_idx=0
)# 使用方式相同
input_indices = torch.tensor([1, 2])
print(embedding(input_indices))
# 输出: tensor([[0.4000, 0.5000, 0.6000],
# [0.7000, 0.8000, 0.9000]])
循环层(Recurrent Layers)
Recurrent Layers(循环层) 是处理序列数据(如时间序列、文本、语音)的核心组件。它们通过循环连接保留历史信息,使网络具有"记忆"能力。
1. RNN (Recurrent Neural Network)
- 核心思想:每一步接收当前输入和上一步的隐藏状态,输出新状态:
新状态 = f(当前输入 + 上一步状态) - 问题:长序列中容易出现梯度消失/爆炸,难以学习长期依赖
示例代码:预测正弦序列的下一个值
import torch
import torch.nn as nn# 创建正弦波序列 (100个时间步)
data = torch.sin(torch.linspace(0, 10, 100)).unsqueeze(1) # 形状: [100, 1]# 准备训练数据 (用前3步预测下一步)
X = [data[i:i+3] for i in range(97)] # 输入序列
y = [data[i+3] for i in range(97)] # 目标值
X = torch.stack(X) # [97, 3, 1]
y = torch.stack(y) # [97, 1]# 定义RNN模型
class SimpleRNN(nn.Module):def __init__(self):super().__init__()self.rnn = nn.RNN(input_size=1, # 每个时间步输入的特征数hidden_size=20, # 隐藏状态维度batch_first=True # 输入形状为 [batch, seq_len, features])self.fc = nn.Linear(20, 1) # 输出层def forward(self, x):# x形状: [batch_size, seq_len=3, input_size=1]out, _ = self.rnn(x) # out: [batch_size, 3, 20]return self.fc(out[:, -1, :]) # 取最后时间步 -> [batch_size, 1]# 训练
model = SimpleRNN()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)for epoch in range(100):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()print(f'Epoch {epoch+1}, Loss: {loss.item():.4f}')
2. LSTM (Long Short-Term Memory)
- 核心改进:引入门控机制(输入门/遗忘门/输出门)和记忆单元
- 优势:能有效捕捉长期依赖,解决梯度消失问题
- 关键组件:
- 遗忘门:决定丢弃哪些历史信息
- 输入门:决定更新哪些新信息
- 输出门:决定输出的隐藏状态
示例代码(修改自RNN示例):
class SimpleLSTM(nn.Module):def __init__(self):super().__init__()self.lstm = nn.LSTM(input_size=1,hidden_size=20,batch_first=True)self.fc = nn.Linear(20, 1)def forward(self, x):out, (h_n, c_n) = self.lstm(x) # LSTM返回隐藏状态和细胞状态return self.fc(out[:, -1, :])# 只需将RNN替换为LSTM,其余代码相同
model = SimpleLSTM()
# ...训练过程与RNN示例一致
3. GRU (Gated Recurrent Unit)
-
核心思想:LSTM的简化版,合并隐藏状态和细胞状态
-
优势:计算效率更高,参数更少,效果常与LSTM相当
示例代码:
class SimpleGRU(nn.Module):def __init__(self):super().__init__()self.gru = nn.GRU(input_size=1,hidden_size=20,batch_first=True)self.fc = nn.Linear(20, 1)def forward(self, x):out, h_n = self.gru(x) # GRU只有一个隐藏状态输出return self.fc(out[:, -1, :])
关键参数说明
| 参数 | 说明 |
|---|---|
input_size | 输入特征的维度(如词向量维度) |
hidden_size | 隐藏状态的维度(记忆容量) |
num_layers | 堆叠的循环层数(默认1) |
batch_first | 若为True,输入形状为 [batch, seq_len, features] |
dropout | 层间dropout概率(>0时生效) |
何时使用哪种循环层?
- RNN:仅用于教学或极短序列(实际应用较少)
- LSTM:需要捕捉长期依赖的复杂任务(如机器翻译)
- GRU:资源受限时的高效选择(效果常与LSTM相当)
Transformer Layers
Transformer模型完全依赖注意力机制而非循环结构来处理序列数据。与RNN/LSTM相比,Transformer的优势在于:
- 更好的长距离依赖处理
- 高度并行化,训练更快
- 更强大的表示能力
实际应用中,通常会使用预训练的Transformer模型(如BERT、GPT)作为基础,然后进行微调以适应特定任务。
核心组件
1. 自注意力机制 (Self-Attention)
- 直观理解:想象你在阅读文章时,每个单词都会关注与它相关的其他单词
- 数学表达:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V - 三个核心向量:
- Query (查询):当前关注的词
- Key (键):其他所有词
- Value (值):实际提供的信息
2. 多头注意力 (Multi-Head Attention)
- 将注意力机制并行执行多次(“多头”),每个头学习不同的关注模式
- 最后将结果拼接融合
- 优势:模型可以同时关注不同位置的不同关系(如语法和语义关系)
3. 位置编码 (Positional Encoding)
- 由于Transformer没有循环结构,需要显式添加位置信息
- 使用正弦/余弦函数生成位置嵌入:
P E ( p o s , 2 i ) = sin ( p o s / 10000 2 i / d m o d e l ) PE_{(pos,2i)} = \sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = cos ( p o s / 10000 2 i / d m o d e l ) PE_{(pos,2i+1)} = \cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
4. Transformer架构
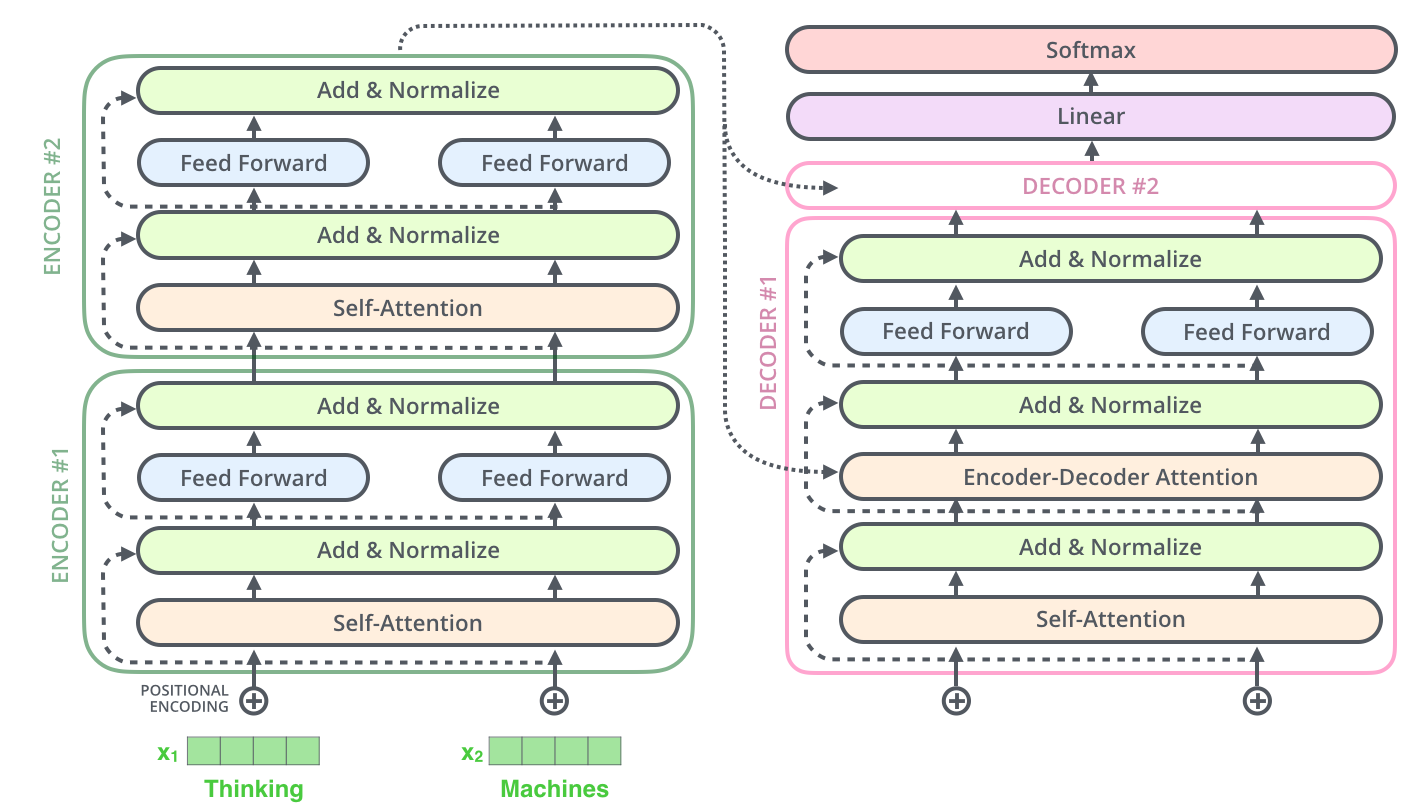
- 编码器 (Encoder):处理输入序列
- 解码器 (Decoder):生成输出序列
- 前馈网络 (Feed Forward Network):位置独立的非线性变换
Transformer组件
nn.Transformer- 完整Transformer模型nn.TransformerEncoder- Transformer编码器堆栈nn.TransformerDecoder- Transformer解码器堆栈nn.TransformerEncoderLayer- 单个编码器层nn.TransformerDecoderLayer- 单个解码器层nn.MultiheadAttention- 多头注意力机制
完整示例:文本情感分类(从HuggingFace下载数据和模型)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from datasets import load_dataset
from transformers import AutoTokenizer
from tqdm import tqdm
import numpy as np# 设置随机种子确保可复现性
torch.manual_seed(42)
np.random.seed(42)# 1. 加载HuggingFace的IMDB数据集
print("正在加载数据集...")
dataset = load_dataset('imdb') # 此处也可以指定本地的模型文件路径
train_dataset = dataset['train']
test_dataset = dataset['test']# 2. 加载分词器 - 使用BERT基础模型的分词器
print("正在加载分词器...")
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
vocab_size = tokenizer.vocab_size# 3. 数据处理配置
MAX_LEN = 256
BATCH_SIZE = 32# 4. 创建PyTorch自定义数据集
class IMDBDataset(Dataset):def __init__(self, dataset, tokenizer, max_len):self.texts = []self.labels = []self.tokenizer = tokenizerself.max_len = max_len# 处理数据集for item in tqdm(dataset, desc="处理数据集"):self.texts.append(item['text'])self.labels.append(item['label'])def __len__(self):return len(self.texts)def __getitem__(self, idx):text = self.texts[idx]label = self.labels[idx]# 使用分词器编码文本encoding = self.tokenizer.encode_plus(text,add_special_tokens=True,max_length=self.max_len,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt',)return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'label': torch.tensor(label, dtype=torch.long)}# 5. 创建数据集和数据加载器
print("创建训练和测试数据集...")
train_ds = IMDBDataset(train_dataset, tokenizer, MAX_LEN)
test_ds = IMDBDataset(test_dataset, tokenizer, MAX_LEN)train_loader = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_ds, batch_size=BATCH_SIZE)# 6. 创建Transformer模型(与之前相同)
class TransformerClassifier(nn.Module):def __init__(self, vocab_size, embed_dim, num_heads, num_layers, hidden_dim, num_classes, max_seq_len=256):super().__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)# 位置编码 (学习式而非公式计算)self.positional_encoding = nn.Embedding(max_seq_len, embed_dim)# Transformer编码器encoder_layer = nn.TransformerEncoderLayer(d_model=embed_dim,nhead=num_heads,dim_feedforward=hidden_dim,batch_first=True # 使用(batch, seq, features)格式)self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)# 分类头self.fc = nn.Linear(embed_dim, num_classes)def forward(self, input_ids, attention_mask=None):# 创建位置IDseq_length = input_ids.size(1)positions = torch.arange(0, seq_length, device=input_ids.device).unsqueeze(0)# 词嵌入 + 位置编码x_embed = self.embedding(input_ids)pos_embed = self.positional_encoding(positions)x = x_embed + pos_embed# 创建注意力掩码(如果需要)if attention_mask is not None:# 将attention_mask转换为Transformer需要的格式# 需要将0的位置设为True(表示需要mask),1的位置设为Falsekey_padding_mask = attention_mask == 0else:key_padding_mask = None# Transformer编码器处理x = self.transformer_encoder(x, src_key_padding_mask=key_padding_mask)# 取序列第一个位置的输出([CLS]位置)x = x[:, 0, :] return self.fc(x)# 7. 模型参数
EMBED_DIM = 128
NUM_HEADS = 8
NUM_LAYERS = 3
HIDDEN_DIM = 256
NUM_CLASSES = 2# 8. 创建模型实例
print("创建模型...")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")model = TransformerClassifier(vocab_size=vocab_size,embed_dim=EMBED_DIM,num_heads=NUM_HEADS,num_layers=NUM_LAYERS,hidden_dim=HIDDEN_DIM,num_classes=NUM_CLASSES,max_seq_len=MAX_LEN
).to(device)# 9. 训练准备
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)# 10. 训练函数
def train_epoch(model, data_loader, optimizer, criterion, device):model.train()total_loss = 0correct_predictions = 0for batch in tqdm(data_loader, desc="训练中"):input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)labels = batch['label'].to(device)optimizer.zero_grad()outputs = model(input_ids, attention_mask)loss = criterion(outputs, labels)loss.backward()optimizer.step()total_loss += loss.item()_, preds = torch.max(outputs, dim=1)correct_predictions += torch.sum(preds == labels).item()avg_loss = total_loss / len(data_loader)accuracy = correct_predictions / len(data_loader.dataset)return avg_loss, accuracy# 11. 评估函数
def eval_model(model, data_loader, criterion, device):model.eval()total_loss = 0correct_predictions = 0with torch.no_grad():for batch in tqdm(data_loader, desc="评估中"):input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)labels = batch['label'].to(device)outputs = model(input_ids, attention_mask)loss = criterion(outputs, labels)total_loss += loss.item()_, preds = torch.max(outputs, dim=1)correct_predictions += torch.sum(preds == labels).item()avg_loss = total_loss / len(data_loader)accuracy = correct_predictions / len(data_loader.dataset)return avg_loss, accuracy# 12. 训练模型
EPOCHS = 3 # 可根据实际情况适当调大print("开始训练...")
for epoch in range(EPOCHS):print(f"\nEpoch {epoch + 1}/{EPOCHS}")train_loss, train_acc = train_epoch(model, train_loader, optimizer, criterion, device)test_loss, test_acc = eval_model(model, test_loader, criterion, device)print(f"训练损失: {train_loss:.4f} | 训练准确率: {train_acc * 100:.2f}%")print(f"测试损失: {test_loss:.4f} | 测试准确率: {test_acc * 100:.2f}%")print("-" * 10)# 13. 保存模型
torch.save(model.state_dict(), 'transformer_sentiment_model.pt')
print("模型已保存为 'transformer_sentiment_model.pt'")# 14. 示例预测函数
def predict_sentiment(text, model, tokenizer, device, max_len=MAX_LEN):model.eval()# 编码文本encoding = tokenizer.encode_plus(text,add_special_tokens=True,max_length=max_len,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt',)input_ids = encoding['input_ids'].to(device)attention_mask = encoding['attention_mask'].to(device)with torch.no_grad():outputs = model(input_ids, attention_mask)_, prediction = torch.max(outputs, dim=1)return "positive" if prediction.item() == 1 else "negative"# 15. 测试预测
print("\n测试预测:")
sample_texts = ["This movie was absolutely fantastic! The acting was superb and the plot was engaging.","I found this film to be terribly boring. The storyline was weak and the acting was poor.","The director has done an amazing job with this film. The cinematography is breathtaking.","Worst movie I've seen this year. I can't believe I wasted two hours of my life on this.","A masterpiece that will be remembered for generations. Truly inspiring and thought-provoking."
]for text in sample_texts:sentiment = predict_sentiment(text, model, tokenizer, device)print(f"文本: {text[:60]}...")print(f"预测情感: {sentiment}")print("-" * 10)
关键参数说明
| 参数 | 说明 | 典型值 |
|---|---|---|
d_model | 输入/输出维度(嵌入维度) | 512 |
nhead | 多头注意力的头数 | 8 |
num_encoder_layers | 编码器层数 | 6 |
num_decoder_layers | 解码器层数 | 6 |
dim_feedforward | 前馈网络隐藏层维度 | 2048 |
dropout | 各层dropout概率 | 0.1 |
activation | 激活函数 | relu或gelu |
batch_first | 输入是否为(batch, seq, feature)格式 | True |
卷积层 (Convolution Layers)
卷积层是卷积神经网络(CNN)的核心组件,用于提取输入数据的局部特征。
核心原理
卷积层使用一组可学习的滤波器(filter) 或卷积核(kernel) 在输入数据上滑动,执行局部点乘操作:
- 每个滤波器专注于检测特定特征(如边缘、纹理等)
- 滤波器在输入上滑动,计算局部区域的加权和
- 输出结果形成新的特征图(feature map)
参数说明
nn.Conv2d(in_channels, # 输入通道数 (如RGB图像为3)out_channels, # 输出通道数/滤波器数量kernel_size, # 卷积核尺寸 (如3或(3,3))stride=1, # 滑动步长padding=0, # 边缘填充dilation=1, # 卷积核元素间距groups=1, # 分组卷积bias=True # 是否添加偏置
)
应用代码
# 创建包含多个滤波器的卷积层
conv_layer = nn.Conv2d(in_channels=3, # RGB输入out_channels=16, # 16个不同滤波器kernel_size=3,stride=1,padding=1 # 保持尺寸不变
)# 随机输入图像 (1张32x32的RGB图像)
fake_image = torch.randn(1, 3, 32, 32)# 前向传播
output = conv_layer(fake_image)
print("输入尺寸:", fake_image.shape)
print("输出尺寸:", output.shape) # torch.Size([1, 16, 32, 32])
示例:边缘检测
输入数据 (5x5 单通道图像)
import torch
import torch.nn as nn# 创建输入数据 (batch_size=1, channels=1, height=5, width=5)
input = torch.tensor([[[[1, 0, 1, 0, 1],[0, 1, 0, 1, 0],[1, 0, 1, 0, 1],[0, 1, 0, 1, 0],[1, 0, 1, 0, 1]
]]], dtype=torch.float32)
创建垂直边缘检测卷积核
# 定义卷积层: 输入通道1, 输出通道1, 3x3核
conv = nn.Conv2d(1, 1, kernel_size=3, bias=False)# 手动设置卷积核权重 (垂直边缘检测)
with torch.no_grad():conv.weight.data = torch.tensor([[[[1, 0, -1],[1, 0, -1],[1, 0, -1]]]], dtype=torch.float32)
执行卷积操作
output = conv(input)
print("输出特征图:\n", output)
输出结果
输出特征图:tensor([[[[ 0., 0., 0.],[ 3., 0., -3.],[ 0., 0., 0.]]]], grad_fn=<ConvolutionBackward0>)
结果分析
输入图像 卷积核 输出特征图
1 0 1 0 1 1 0 -1 0 0 0
0 1 0 1 0 1 0 -1 3 0 -3
1 0 1 0 1 × 1 0 -1 → 0 0 0
0 1 0 1 0
1 0 1 0 1
- 中间值3:检测到强垂直边缘(左侧亮到右侧暗)
- 中间值-3:检测到反向垂直边缘(左侧暗到右侧亮)
- 0值:无垂直边缘变化
不同卷积核效果示例
| 卷积核类型 | 卷积核示例 | 功能描述 |
|---|---|---|
| 边缘检测 | [[-1,-1,-1], [0,0,0], [1,1,1]] | 检测水平边缘 |
| 锐化 | [[0,-1,0], [-1,5,-1], [0,-1,0]] | 增强图像细节 |
| 模糊 | [[1,1,1], [1,1,1], [1,1,1]]/9 | 平滑图像噪声 |
| 浮雕 | [[-2,-1,0], [-1,1,1], [0,1,2]] | 创建3D浮雕效果 |
池化层(Pooling Layers)
池化层(Pooling Layers) 是卷积神经网络中的关键组件,主要用于降维和特征提取。它们通过减少特征图的空间尺寸来降低计算量,同时保留重要特征,增强模型的平移不变性。最常用的是MaxPool2d和AvgPool2d。
在PyTorch中,池化层(Pooling Layers)是卷积神经网络中的关键组件,主要用于降维和特征提取。它们通过减少特征图的空间尺寸来降低计算量,同时保留重要特征,增强模型的平移不变性。下面以最常用的MaxPool2d和AvgPool2d为例直观解释:
核心原理
-
滑动窗口操作:
- 定义一个固定大小的窗口(如2×2)
- 窗口在输入特征图上按步长(stride)滑动
- 每次覆盖一个局部区域
-
聚合局部信息:
- 最大池化(MaxPool):取窗口内的最大值 → 突出最显著特征
- 平均池化(AvgPool):取窗口内平均值 → 保留整体趋势
示例
假设输入特征图(4×4):
[[1, 2, 3, 4],[5, 6, 7, 8],[9,10,11,12],[13,14,15,16]]
最大池化(MaxPool2d)
pool = nn.MaxPool2d(kernel_size=2, stride=2)
操作过程:
- 左上窗口
[[1,2],[5,6]]→ 最大值6 - 右上窗口
[[3,4],[7,8]]→ 最大值8 - 左下窗口
[[9,10],[13,14]]→ 最大值14 - 右下窗口
[[11,12],[15,16]]→ 最大值16
输出特征图(2×2):
[[ 6, 8],[14, 16]]
平均池化(AvgPool2d)
pool = nn.AvgPool2d(kernel_size=2, stride=2)
操作过程:
- 左上窗口:
(1+2+5+6)/4 = 3.5 - 右上窗口:
(3+4+7+8)/4 = 5.5 - 左下窗口:
(9+10+13+14)/4 = 11.5 - 右下窗口:
(11+12+15+16)/4 = 13.5
输出特征图(2×2):
[[3.5, 5.5],[11.5,13.5]]
关键参数解析
nn.MaxPool2d(kernel_size, # 窗口大小(如2或(2,2))stride=None, # 步长(默认等于kernel_size)padding=0, # 边缘填充(通常为0)dilation=1, # 窗口膨胀系数(默认为1不膨胀)ceil_mode=False # 尺寸计算方式(True向上取整/False向下)
)
应用场景
| 池化类型 | 适用场景 | 特点 |
|---|---|---|
| MaxPool2d | 图像识别、物体检测 | 保留纹理等显著特征 |
| AvgPool2d | 图像平滑化、全连接层前过渡 | 保留背景信息,抑制噪声 |
| AdaptivePool | 输入尺寸不固定时(如分割网络) | 自动匹配输出尺寸 |
代码示例
import torch
import torch.nn as nn# 模拟输入数据 (batch=1, channel=1, 4x4)
input = torch.tensor([[[[1, 2, 3, 4],[5, 6, 7, 8],[9,10,11,12],[13,14,15,16]
]]], dtype=torch.float32)# 最大池化层
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
output_max = max_pool(input)
print("MaxPool输出:\n", output_max)# 平均池化层
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
output_avg = avg_pool(input)
print("AvgPool输出:\n", output_avg)
输出:
MaxPool输出:tensor([[[[ 6., 8.],[14., 16.]]]])AvgPool输出:tensor([[[[ 3.5000, 5.5000],[11.5000, 13.5000]]]])
填充层 (Padding Layers)
填充层(Padding Layers)主要用于在输入数据的边界添加额外的像素,以解决卷积操作导致的空间尺寸缩减问题。
当进行卷积操作时,特征图尺寸会缩小:
输入尺寸: (H, W)
输出尺寸: (H - kernel_size + 1, W - kernel_size + 1)
填充的主要目的:
- 保持空间尺寸:避免网络深度增加时特征图过度缩小
- 保留边缘信息:防止图像边缘特征被忽略
- 控制感受野:确保深层神经元能覆盖更大原始区域
常见填充类型
PyTorch 提供多种填充策略:
| 填充类型 | 类名 | 特点 | 适用场景 |
|---|---|---|---|
| 零填充 | ZeroPad2d | 添加0值像素 | 通用图像处理 |
| 常数填充 | ConstantPad2d | 添加指定常数 | 需要特定边界值 |
| 反射填充 | ReflectionPad2d | 镜像边界像素 | 图像修复、风格迁移 |
| 复制填充 | ReplicationPad2d | 复制边界像素 | 医学图像处理 |
| 循环填充 | CircularPad2d | 循环边界像素 | 周期性信号处理 |
示例
示例1:零填充 (ZeroPad2d)
import torch.nn as nn# 创建2x2输入
input = torch.tensor([[[[1, 2],[3, 4]
]]], dtype=torch.float32)# 四周各填充1行0值
pad = nn.ZeroPad2d(1) # 参数1表示四周各加1行
output = pad(input)
输出结果:
tensor([[[[0., 0., 0., 0.],[0., 1., 2., 0.],[0., 3., 4., 0.],[0., 0., 0., 0.]]]])
示例2:反射填充 (ReflectionPad2d)
# 创建2x2输入
input = torch.tensor([[[[1, 2],[3, 4]
]]], dtype=torch.float32)# 四周各反射填充1行
pad = nn.ReflectionPad2d(1)
output = pad(input)
输出结果:
tensor([[[[4., 3., 4., 3.],[2., 1., 2., 1.],[4., 3., 4., 3.],[2., 1., 2., 1.]]]])
解释:反射填充创建了输入数据的镜像效果
示例3:常数填充 (ConstantPad2d)
# 创建2x2输入
input = torch.tensor([[[[1, 2],[3, 4]
]]], dtype=torch.float32)# 填充配置:(左, 右, 上, 下)
pad = nn.ConstantPad2d((1, 2, 1, 0), value=5) # 左1,右2,上1,下0
output = pad(input)
输出结果:
tensor([[[[5., 5., 5., 5., 5.],[5., 1., 2., 5., 5.],[5., 3., 4., 5., 5.]]]])
填充层与卷积层的配合使用
保持尺寸不变的卷积
# 输入尺寸: 4x4
input = torch.randn(1, 1, 4, 4)# 卷积核3x3, 步长1, 无填充 → 输出尺寸: 2x2
conv_no_pad = nn.Conv2d(1, 1, kernel_size=3, stride=1, padding=0)# 添加填充使输出保持4x4
conv_with_pad = nn.Sequential(nn.ConstantPad2d(1, 0), # 四周各加1行nn.Conv2d(1, 1, kernel_size=3, stride=1, padding=0)
)print("无填充输出尺寸:", conv_no_pad(input).shape)
print("有填充输出尺寸:", conv_with_pad(input).shape)
输出:
无填充输出尺寸: torch.Size([1, 1, 2, 2])
有填充输出尺寸: torch.Size([1, 1, 4, 4])
与卷积层的尺寸关系
卷积输出高度 = (输入高度 + pad_top + pad_bottom - kernel_height) / stride + 1