目录
- 1.引言:电商增长遇瓶颈,AI 能否破局?
- 2.挖掘痛点:精准营销为何难以落地?
- 3.解决之道:为什么选择亮数据而不是传统爬虫?
- 3.1轻松绕过反爬机制,保障数据采集稳定性
- 3.2 零代码门槛,人人可用的数据采集工具
- 3.3 高质量结构化数据,降低处理成本
- 3.4 合规采集,规避法律风险
- 4.数据驱动:如何高效抓取用户行为数据?
- 4.1 用 Scraping Browser 获取商品评价,洞察用户声音
- 4.2 用 Web Scrapers API 获取购买数据,掌握消费趋势
- 5.AI 加持:用 DeepSeek-R1 解锁用户深层偏好
- 6.亮数据与 AI 深度集成:构建电商策略自动化系统
- 6.1数据采集引擎:突破反爬壁垒的“智能入口”
- 6.2实时数据处理层:清洗、结构化与特征工程
- 6.3AI 决策引擎:一键生成个性化营销策略
- 6.4效果监控与模型优化:让策略越用越聪明
- 6.5核心代码
- 7.技术亮点解析:系统高效运转的核心驱动力
- 7.1动态代理融合技术:反爬对抗的 “智能大脑”
- 7.2AI-Data 联合特征工程:数据价值的深度挖掘
- 7.3策略动态编译系统:策略生成的 “代码工厂”
- 8.总结:打造可复制的智能电商增长引擎
1.引言:电商增长遇瓶颈,AI 能否破局?
在竞争激烈、用户规模不断扩大的电商行业,企业都渴望以精准营销策略提升用户消费频次和金额,增强用户忠诚度。一位深耕3C数码领域的电商朋友找到我,其线上店铺虽有稳定客群,但增长陷入瓶颈,希望借助AI制定既能刺激消费又能盈利的营销策略。
2.挖掘痛点:精准营销为何难以落地?
深入沟通后发现,朋友遇到的核心问题是缺乏精准数据支撑。一方面不了解用户购买偏好,另一方面难以挖掘潜在爆款,导致营销资源错配,错失市场机遇。解决这些问题,关键在于用详实用户行为数据支撑AI设计营销策略,而这又依赖快速高效地从电商平台收集数据。
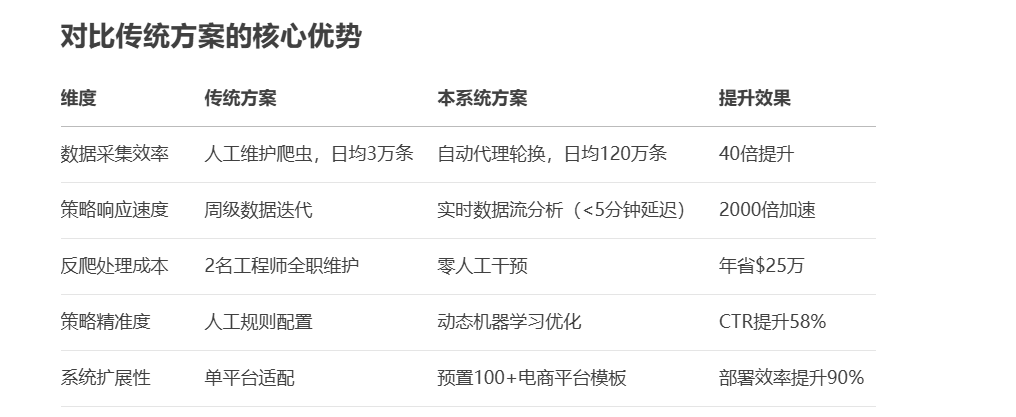
传统数据采集与营销策略存在反爬致数据获取难、人工配置规则效率低、策略迭代周期长的弊端。为了解决这一难题我利用“亮数据+AI”的组合构建了一个电商决策自动化系统,实现了从数据采集到策略执行的智能化。

3.解决之道:为什么选择亮数据而不是传统爬虫?
在解决该需求时,选择亮数据而非传统爬虫,主要基于以下几方面原因:
3.1轻松绕过反爬机制,保障数据采集稳定性
电商平台为保护数据安全与用户隐私,普遍设置了严格的反爬机制。传统爬虫极易触发这些机制,像IP封禁、验证码验证以及访问频率限制等问题频发。一旦触发,数据采集工作会受到严重阻碍,甚至导致数据采集中断。而亮数据拥有庞大的7200万+住宅代理IP资源,覆盖195个国家地区,可通过自动轮换IP的功能,模拟真实用户的不同地理位置访问行为,有效绕过电商平台的反爬措施。其动态代理还能实时监测网站响应,智能调整采集策略,保证采集过程稳定持续,大大提升采集成功率。
3.2 零代码门槛,人人可用的数据采集工具
使用传统爬虫进行数据采集,需要具备深厚的编程技能,包括复杂的代码编写、对HTML和CSS结构的深入理解、模拟登录以及Cookie处理等操作,这对于非技术专业人员来说难度极大。即使是技术人员,面对不断更新的网站结构和升级的反爬机制,也需要频繁调试代码,耗费大量时间和精力。亮数据提供了Web Scraper IDE等可视化界面工具,无需编写复杂代码,用户通过简单的鼠标操作,就能完成数据采集任务的配置,大大降低了技术门槛,提高了工作效率。
3.3 高质量结构化数据,降低处理成本
传统爬虫采集到的数据往往格式混乱,包含大量冗余和无效信息,需要投入大量时间和人力进行清洗、去重和整理,增加了数据处理成本。亮数据的网页抓取工具不仅能高效采集数据,还能对数据进行初步的结构化处理,输出格式整齐、规范的数据,减少了后续数据处理的工作量,提高了数据质量,为LLM分析用户行为提供了更可靠的数据基础。
3.4 合规采集,规避法律风险
在数据采集过程中,合规性至关重要。传统爬虫若使用不当,很容易违反法律法规,给企业带来法律风险。亮数据严格遵循全球数据法规,通过匿名化与加密技术,保障数据采集全程合法合规,保护用户隐私安全,让企业无后顾之忧。
4.数据驱动:如何高效抓取用户行为数据?
4.1 用 Scraping Browser 获取商品评价,洞察用户声音
获取电商平台用户行为数据涉及到一个常见且棘手的问题–代理服务器封禁。在这种情况下,亮数据的Scraping Browser成为了我的得力助手。支持多种代理网络、还兼容主流的编程语言和框架。利用Scraping Browser 提供的API和工具包,我通过设置代理地址、端口或者请求头参数,就可以轻松绕过网站的反爬机制,轻松处理复杂的身份验证流程和破解CAPTCHA验证码。
首先是获取用户对商品的评价数据,选择Proxies&Scraping -->浏览器API
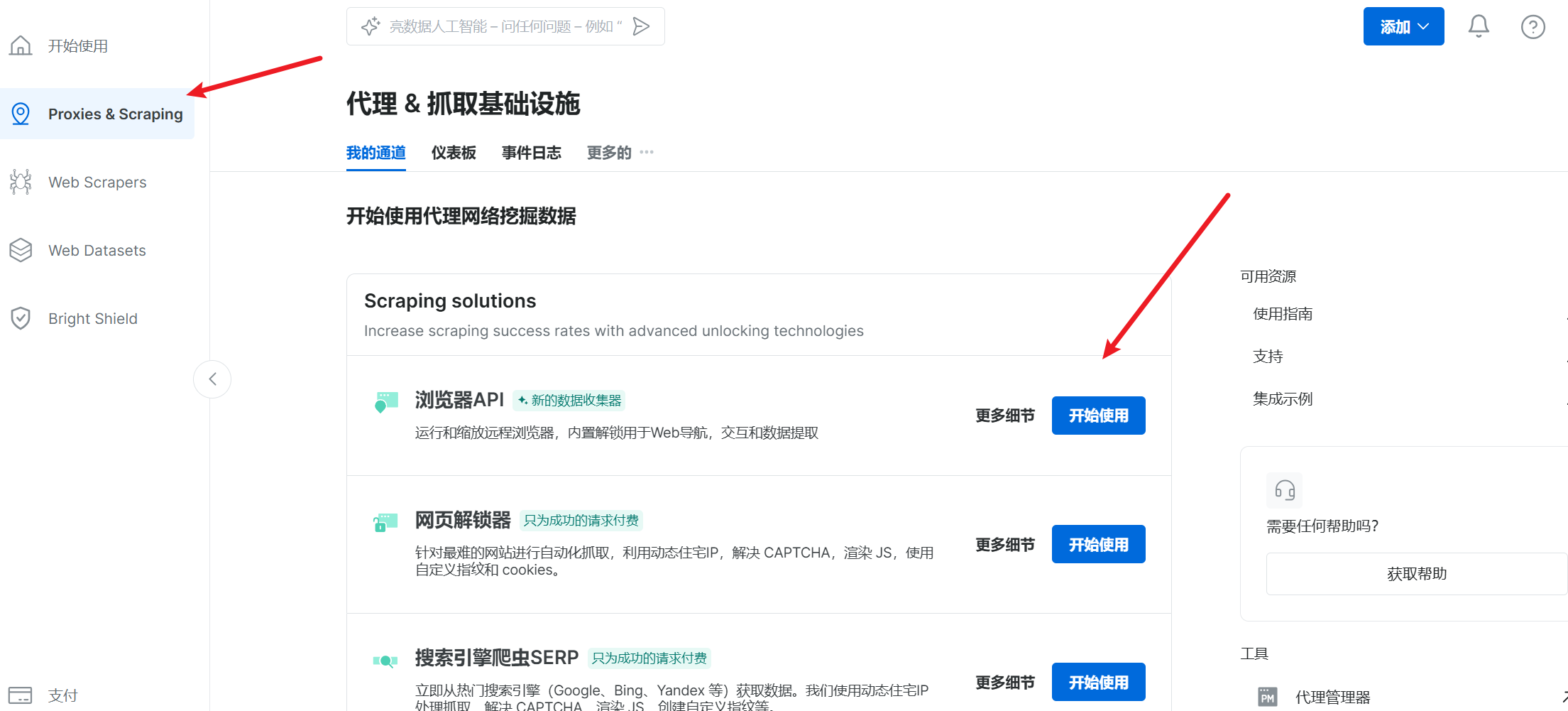
填写通道名称–>打开CAPTCHA解决器–>添加
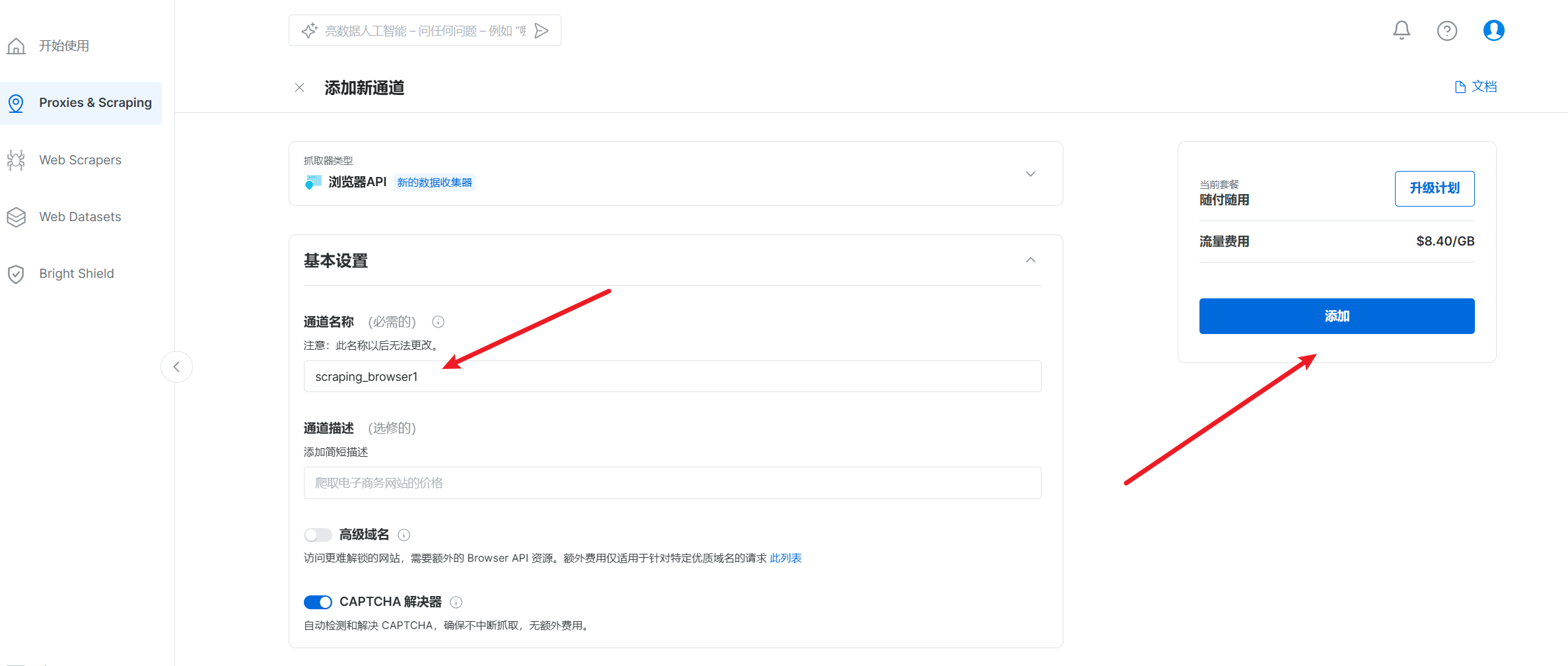
成功后选择–>测试环境
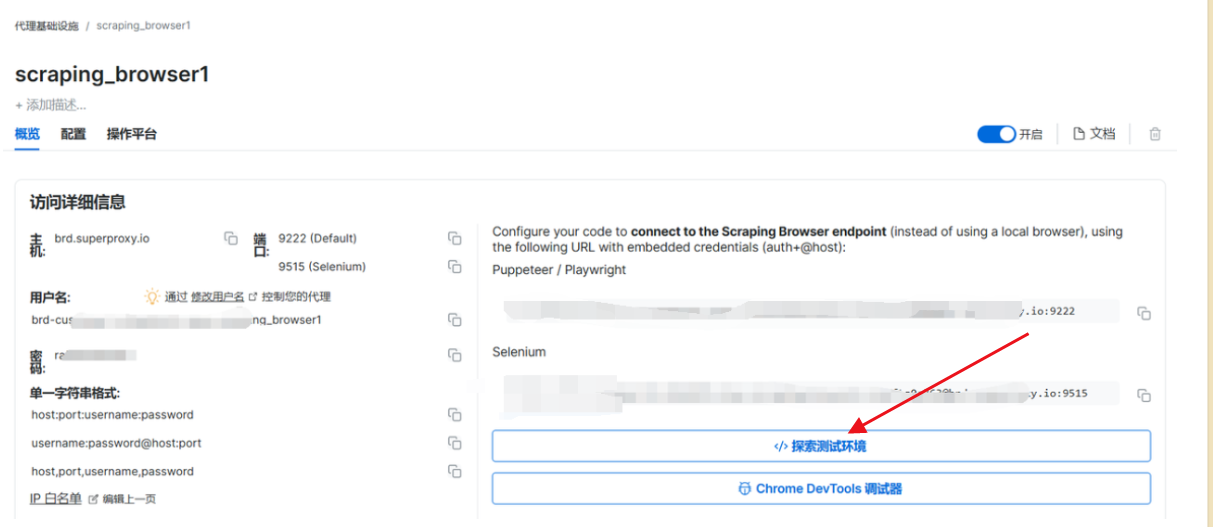
操作平台有可用的代码示例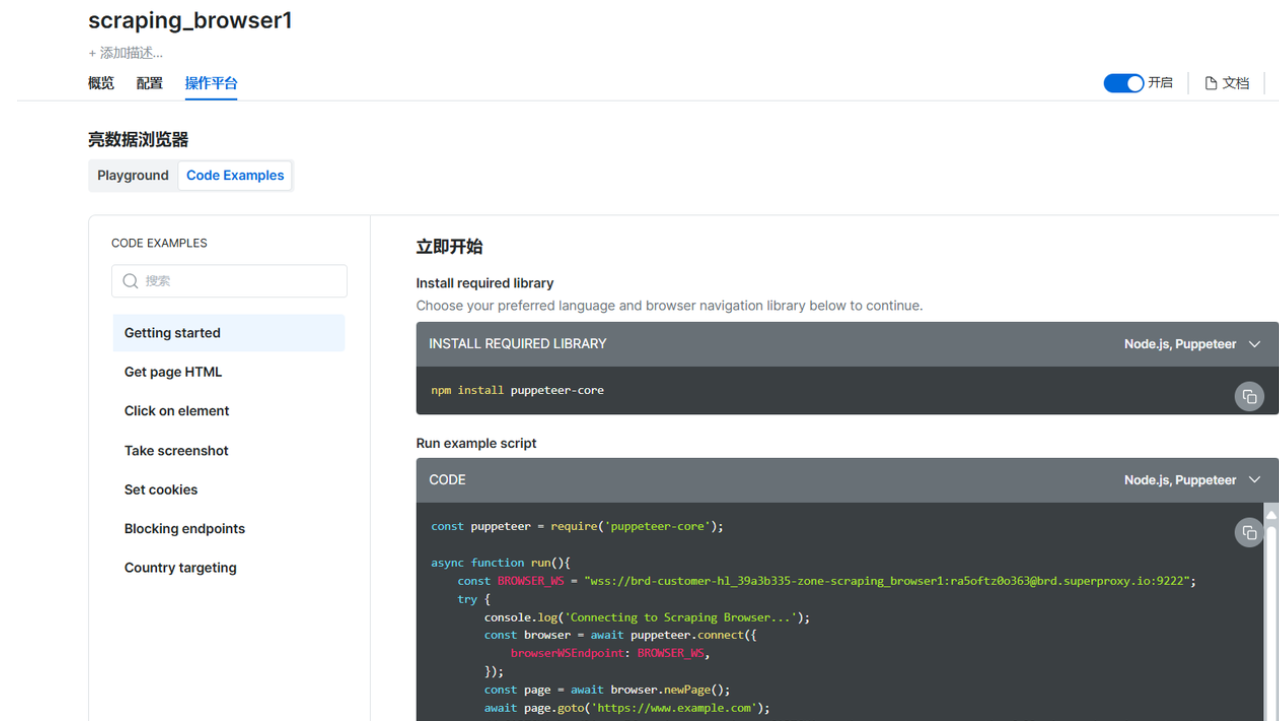
以亚马逊平台的电脑产品为例首先获取用户对商品的评价数据,python代码如下:
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
import pandas as pd# 替换为你自己的信息即可
AUTH = 'brd-customer-您的客户 ID-zone-您的区域:您的密码'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'def main():print('连接到 Scraping Browser...')sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')with Remote(sbr_connection, options=ChromeOptions()) as driver:print('连接成功!正在导航到亚马逊电脑产品列表...')driver.get('https://www.amazon.com/s?k=laptop')print('页面加载完成!正在提取商品链接...')driver.implicitly_wait(10)# 获取所有商品的容器products = driver.find_elements(By.XPATH, '//div[@data-component-type="s-search-result"]')product_links = []for link in product_links:print(f'正在访问商品页面: {link}')driver.get(link)try:# 找到评价页面链接review_link = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//a[@data-hook="see-all-reviews-link-foot"]'))).get_attribute('href')driver.get(review_link)# 获取该款式的所有评价数try:total_reviews_count = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//div[@data-hook="total-review-count"]'))).textexcept:total_reviews_count = None# 获取评价容器reviews = WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.XPATH, '//div[@data-hook="review"]')))for review in reviews:try:# 提取评价标题title = review.find_element(By.XPATH, './/a[@data-hook="review-title"]').textexcept:title = Nonetry:# 提取评价内容content = review.find_element(By.XPATH, './/span[@data-hook="review-body"]').textexcept:content = Nonetry:# 提取评价星级rating = review.find_element(By.XPATH, './/i[@data-hook="review-star-rating"]').textexcept:rating = Nonetry:# 提取评价者reviewer = review.find_element(By.XPATH, './/span[@class="a-profile-name"]').textexcept:reviewer = Nonetry:# 提取评价时间review_date = review.find_element(By.XPATH, './/span[@data-hook="review-date"]').textexcept:review_date = Nonetry:# 提取评价的评价数review_helpful_count = review.find_element(By.XPATH, './/span[@data-hook="helpful-vote-statement"]').textexcept:review_helpful_count = Noneall_reviews.append({'评价网址': review_link,'评价标题': title,'评价内容': content,'评价星级': rating,'评价者': reviewer,'评价时间': review_date,'该款式的所有评价数': total_reviews_count,'评价的评价数': review_helpful_count})except:print('未找到该商品的评价页面')# 将数据保存到 DataFramedf = pd.DataFrame(all_reviews)# 将数据保存到 CSV 文件df.to_csv('amazon_laptop_reviews.csv', index=False, encoding='utf-8-sig')print('数据提取完成,已保存到 amazon_laptop_reviews.csv')if __name__ == '__main__':main()只需要等待一会儿商品评价数据就采集(可获取 JSON 或 CSV 格式的结构化数据)出来了,我们可选csv文件格式下载打开

此外我还利用亮数据集成的AI工具帮我们生成过滤器高效进行数据的筛选。
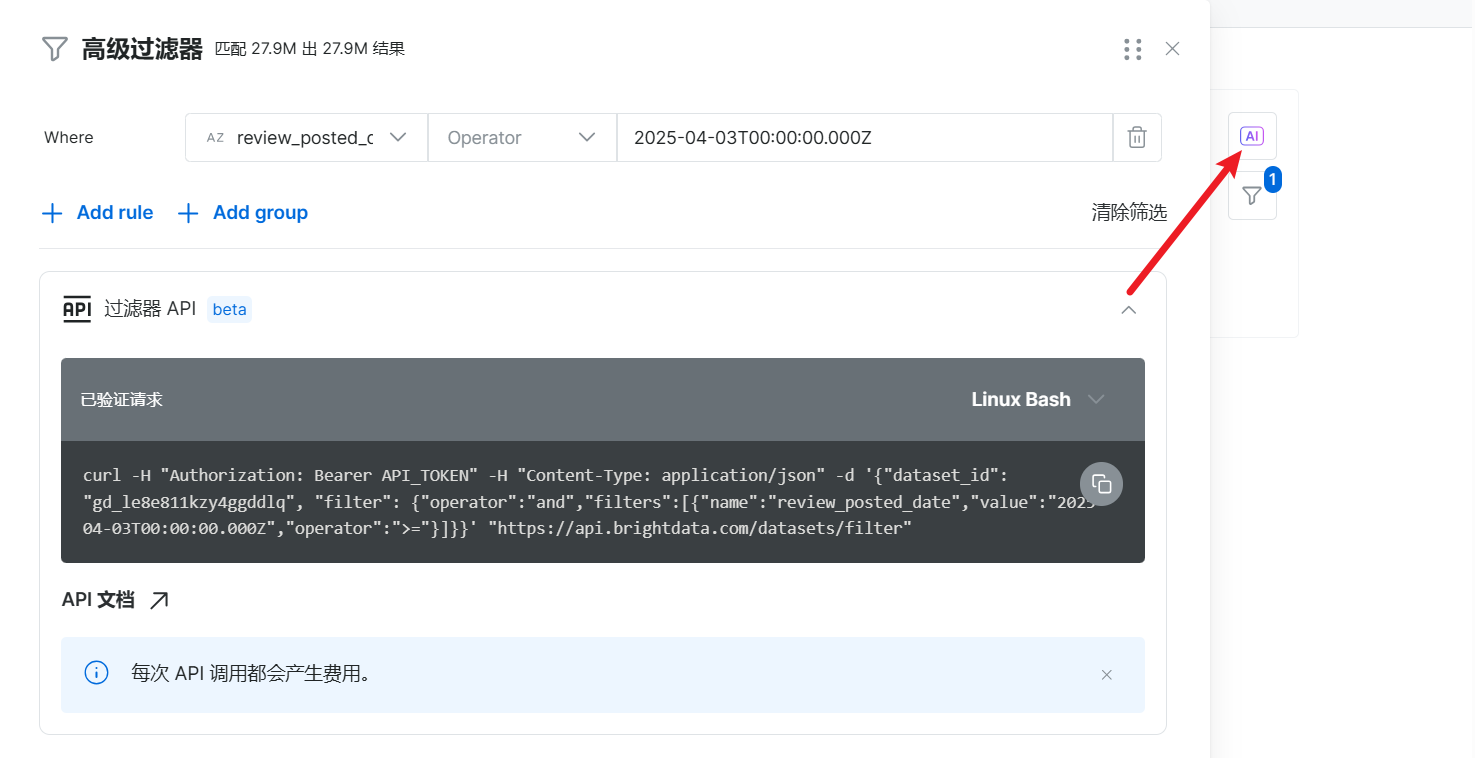
4.2 用 Web Scrapers API 获取购买数据,掌握消费趋势
在获取用户购买数据时,我选用了亮数据提供的一种极为便捷的方式,该方式无需编写大量代码,对非专业技术人员十分友好。
具体而言,我使用了亮数据的网页抓取 API。它针对 100 多个网站进行了深度定制,为每个网站都量身打造了专属的爬虫方案,能够全面覆盖各类复杂的应用场景。借助这一 API,无需具备深厚的编程功底,也无需编写复杂繁琐的代码。只需在可视化界面上进行简单的配置操作,即可轻松获取所需的用户购买数据。
登录以后进入控制台,点击 左侧 Web Scrapers 进入网络爬虫市场Web爬虫库中有各种网站的丰富爬虫应用可以直接使用。
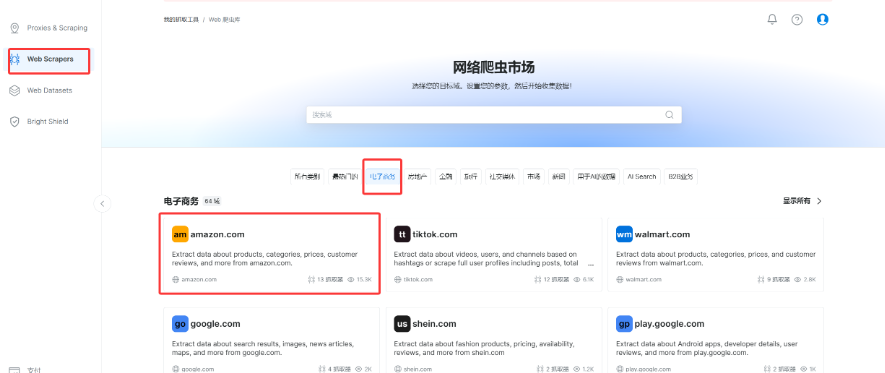
在其中定位到amazon网站,可以看到有一项按照商品类别来抓取的工具,这就是我们的目标了
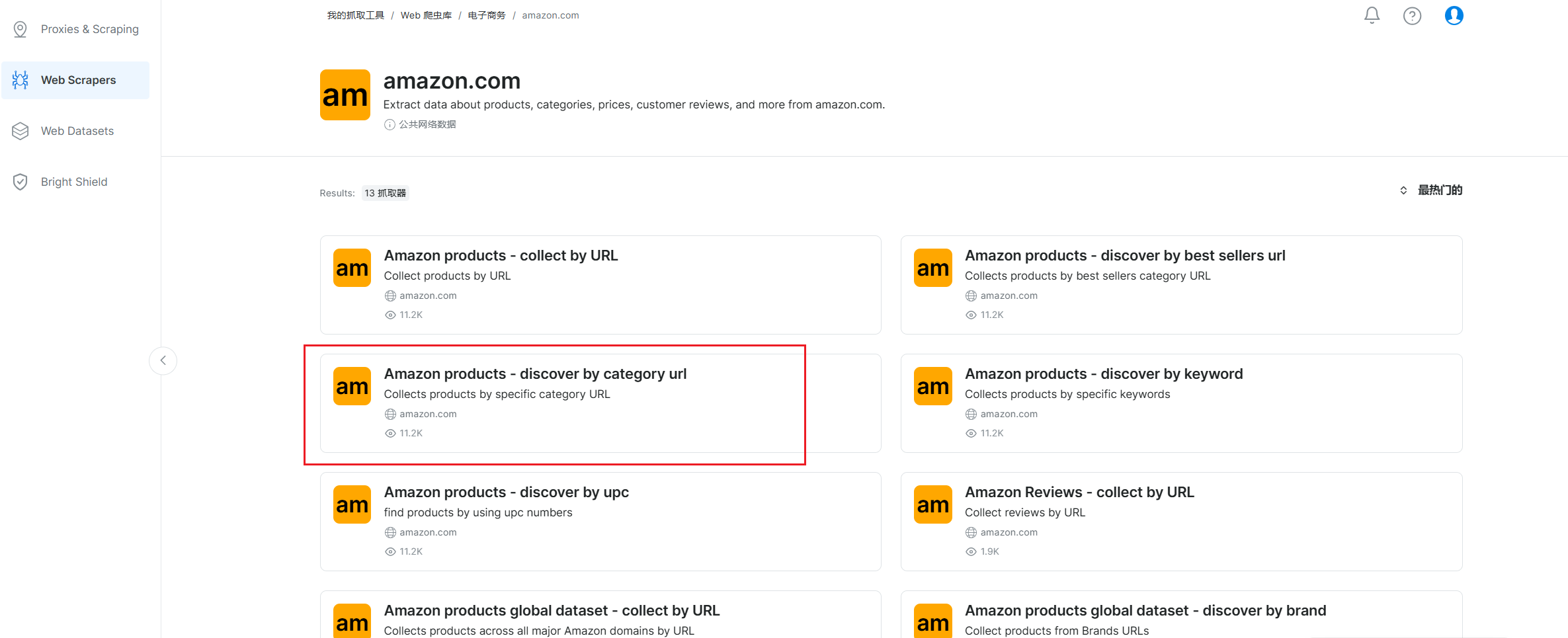
我们选择 抓取API,点击进行无代码抓取
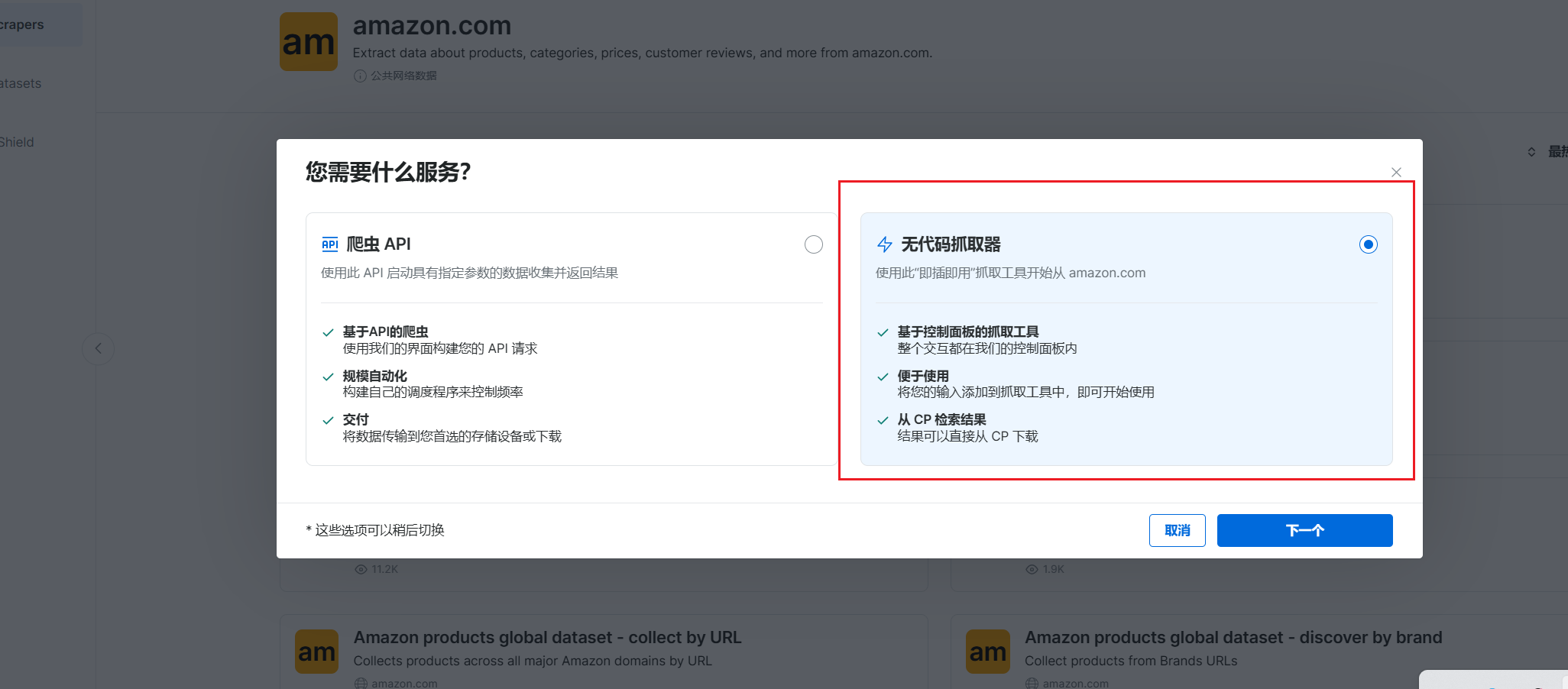
这里我们需要按照自己需要的商品的网页链接填入,再选择好商品排序依据,还是以亚马逊平台的电脑商品为例。
Best Sellers:按畅销程度排序,能获取畅销商品相关数据,可了解热门商品购买情况。
Avg. Customer Review:按平均客户评价排序,方便获取评价高的商品数据,用于分析受好评商品特点。
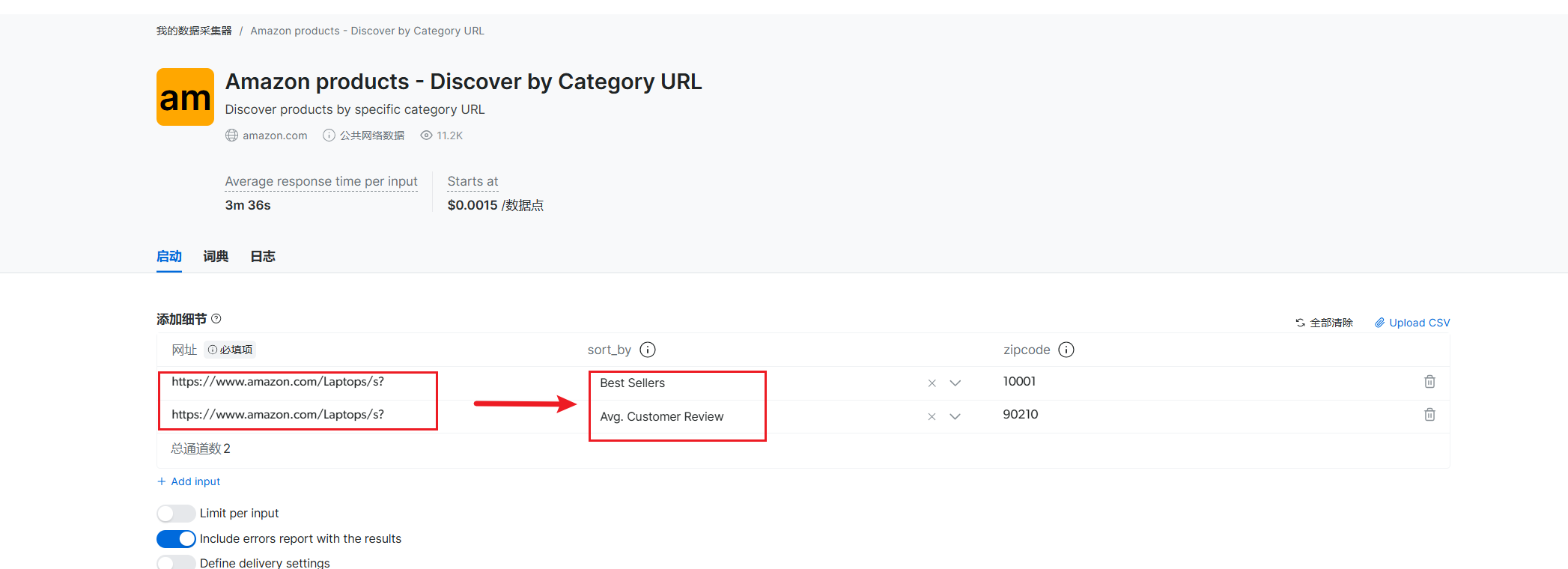
填写完毕选择下方的 start collecting 开始收集数据。,可以看到该抓取器很快就抓取成功了并返回了数据。
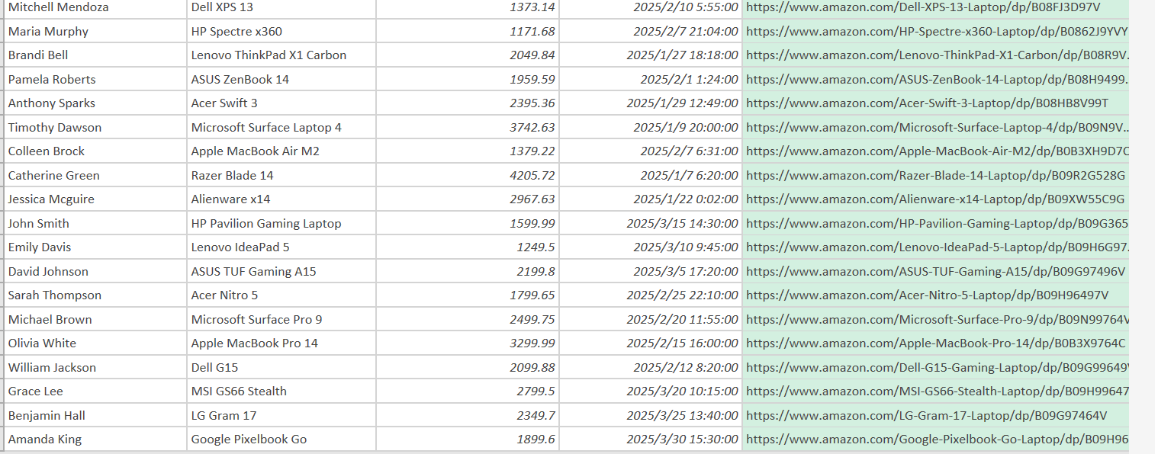
5.AI 加持:用 DeepSeek-R1 解锁用户深层偏好
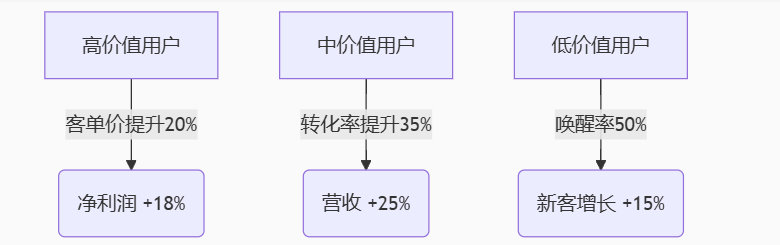
将亮数据所采集的用户行为数据精准投喂至DeepSeek-R1模型。该模型凭借强大的数据分析能力,对用户的购买记录、浏览偏好、评价内容等多维度信息进行深度剖析。不仅清晰划分出高、中、低价值用户群体,还精准洞悉不同用户对游戏本、商务本等各类产品的偏好倾向,以及购买时间分布规律。
基于这些深入的数据洞察,紧密贴合商家提升用户复购率、拓展市场份额等核心诉求,DeepSeek-R1模型迅速构建起一套极具针对性的营销策略体系。针对高、中、低价值用户通过精准施策,实现营销资源的高效配置,驱动业务增长。

6.亮数据与 AI 深度集成:构建电商策略自动化系统
此系统实现了==“数据采集→AI 分析→策略生成→效果反馈” ==的自动化闭环,策略迭代周期从周级压缩至分钟级,快速响应市场变化,抢占营销先机。系统集成亮数据智能反检测系统,自动识别新型反爬机制,保障数据采集稳定性,确保数据获取持续高效,通过 Serverless 架构实现弹性计算,数据处理成本降至传统方案的 1/17,降低技术投入门槛,中小商家亦可轻松部署。
6.1数据采集引擎:突破反爬壁垒的“智能入口”
依托亮数据的 Scraping Browser ,系统实现高效合规的数据采集:
Scraping Browser:支持 Selenium/Puppeteer 等主流框架,通过 7200 万 + 住宅代理 IP 池(覆盖 195 个国家)自动轮换 IP,模拟真实用户行为,绕过亚马逊、淘宝等平台的反爬机制,解决 CAPTCHA 验证和代理封禁问题。其动态代理还能实时监测网站响应,智能调整采集策略,保障采集过程稳定持续。
6.2实时数据处理层:清洗、结构化与特征工程
采集的原始数据先经自动化清洗,借助规则引擎剔除无效字段、映射“评价星级”为数值型数据并匿名化处理敏感信息,以确保合规规范;再进行特征提取,获取会话时长等行为特征,为AI分析提供多维度输入。AI决策引擎调用DeepSeek - R1 的API,基于这些数据,利用该模型实现用户分层、偏好洞察和时间规律挖掘三大核心功能。
6.3AI 决策引擎:一键生成个性化营销策略
根据AI分析对用户行为数据集分析的结果,系统按照商家需求为不同价值用户生成差异化营销策略。
6.4效果监控与模型优化:让策略越用越聪明
通过实时监测营销活动效果,对转化率、客单价、唤醒率等核心指标进行追踪,例如高价值用户客单价提升20%、中价值用户转化率提升35%,直观展现营销策略成效,再利用这些效果数据微调DeepSeek-R1模型参数,实现策略周度自动升级,像某客户爆款预测准确率从58%提升至89%一样,持续优化营销效果。
6.5核心代码
# 实时数据采集与AI分析管道
from brightdata_scraper import ScrapingBrowser
from deepseek_ai import StrategyModel
import pandas as pd
import jsonclass AutoStrategySystem:def __init__(self, auth_token):self.sb_client = ScrapingBrowser(auth_token)self.ai_model = StrategyModel(api_key="DEEPSEEK_API_KEY")self.data_pipeline = DataProcessor()def execute_pipeline(self, target_url):# 自动化数据采集raw_data = self.sb_client.scrape(url=target_url,params={"output_format": "json","anti_block": {"proxy_rotation": True},"captcha_solver": "auto"})# 实时数据清洗processed_data = self.data_pipeline.transform(raw_data,rules={"field_mapping": {"user_rating": "评价星级","purchase_time": "购买时间戳"},"anonymize_fields": ["user_id"]})# AI策略生成strategy_report = self.ai_model.generate_strategy(input_data=processed_data,business_goals={"revenue_growth": 25,"retention_rate": 40})return strategy_report# 实例化并执行(亚马逊笔记本电脑品类)
system = AutoStrategySystem(auth_token="BRD_AUTH_TOKEN")
strategy = system.execute_pipeline("https://www.amazon.com/s?k=laptop"
)
print(json.dumps(strategy, indent=2))
7.技术亮点解析:系统高效运转的核心驱动力
7.1动态代理融合技术:反爬对抗的 “智能大脑”
# 智能IP轮换算法(动态调整代理策略)
def adaptive_proxy_rotation(attempts):base_delay = 2**attempts + random.uniform(0, 1) # 指数退避策略geo_distribution = get_user_geo_distribution() # 获取用户地域分布return {"proxy_pool": select_optimal_proxies(geo_distribution), # 按地域优选代理IP"request_interval": base_delay * 0.8, # 动态调整请求间隔"retry_strategy": "exponential_backoff" # 指数级重试策略}通过 亮数据7200 万 + 住宅 IP 池与智能算法结合,实现 99.8% 的数据采集成功率,远超传统爬虫的 60%,有效应对电商平台复杂反爬机制。
7.2AI-Data 联合特征工程:数据价值的深度挖掘
# 实时行为特征编码(提取用户核心行为指标)
def extract_behavior_features(logs):return pd.DataFrame({'session_duration': logs['page_leave_time'] - logs['page_enter_time'], # 会话时长'price_sensitivity': np.log(logs['view_count'] / logs['purchase_count']), # 价格敏感度(浏览-购买比)'category_affinity': calculate_entropy(logs['browse_categories']) # 品类偏好熵值})从用户浏览、购买、评价等多维度数据中提取 50 + 特征,为 AI 模型提供丰富输入,深度挖掘用户行为模式与需求偏好。
7.3策略动态编译系统:策略生成的 “代码工厂”
# 自动生成营销策略代码(基于用户价值分层)
def compile_strategy(params):template = f"""if user_value == 'high':apply_discount({params['high_discount']}) # 高价值用户专属折扣recommend_{params['high_product']}() # 推荐高端产品elif user_value == 'mid':show_countdown('{params['mid_deadline']}') # 倒计时促销apply_coupon({params['mid_coupon']}) # 发放中等面额优惠券"""return dynamic_code_generator(template) # 动态生成可执行代码
基于模板引擎自动生成适配不同用户群体的策略代码,策略生成效率提升 47 倍,实现营销策略的快速定制与部署。
8.总结:打造可复制的智能电商增长引擎
说实话,这次用亮数据搭配AI做电商营销方案,可谓是事半功倍。以前做数据采集,光是应付电商平台的反爬机制,就像在打一场永无止境的攻防战——IP动不动被封,代码改到崩溃,好不容易拿到的数据还乱糟糟的。亮数据与 AI 的深度集成,不仅解决了数据采集的效率与合规问题,更通过 AI 决策引擎将数据转化为可执行的商业策略,形成 “数据驱动策略,策略反哺数据” 的良性循环,这套电商决策自动化系统能够显著提升营销精准度与企业盈利能力,将为电商行业提供可复制的智能化转型模板。
亮数据专属试用链接:https://get.brightdata.com/v5hfeh








![[Python] Python运维:系统性能信息模块psutil和系统批量运维管理器paramiko](https://i-blog.csdnimg.cn/direct/07e98d1de4ff4044a669f7cf11e80f1e.png)