abstract
神经网络泛化中最神奇的现象之一是grokking:一个具有完美训练accuracy但泛化能力差的网络,在进一步的训练后,会过渡到完美的泛化。 本文提出,当任务存在一个泛化解和一个记忆解时,就会发生泛化。其中泛化解学习速度较慢,但效率更高。 我们假设,记忆电路在较大的训练数据集上变得更低效,而泛化电路则不会,这表明存在一个关键数据集大小,在这个数据集大小上,记忆和泛化的效率是一样的。 我们展示了两种新颖的行为:
- ungrokking,其中网络从完美acc回归到低测试acc
- semi-grokking,延迟泛化到不完美的测试acc。
1. Introduction
在训练神经网络时,我们期望一旦训练损失收敛到一个较低的值,网络就不再有太大的变化。 Power等人(2021)发现了一种被称为grokking的现象,它大大违反了这一预期。 网络首先“记忆”数据,以较差的泛化实现低而稳定的训练损失,但随着进一步的训练,神经网络过渡到完美的泛化。 我们的问题是:为什么网络的测试性能在已经达到近乎完美的训练性能的情况下,在继续训练后会显著提高?
这个问题的答案差异很大,包括表征学习的难度(Liu et al., 2022)、初始化时的参数规模(Liu et al., 2023)、损失峰值(“弹射”)(Thilak et al., 2022)、最优解之间的随机漫步(Millidge, 2022)以及泛化解的简单性(Nanda et al., 2023,附录E)。 在本文中,我们认为最后一种解释是正确的,通过陈述一个特定的理论,从理论中得出新的预测,并通过经验证实这些预测。
我们分析了神经网络用于计算输出的内部机制之间的相互作用,这些机制被统称为“电路”(Olah et al., 2020)。我们假设存在两类均能实现良好训练性能的电路:一类具有强泛化能力(),另一类则主要记忆训练数据集(
)。 关键的见解是,当有多个电路达到较强的训练性能时,权值衰减倾向于具有高“效率”的电路,即需要较少参数范数来产生给定logit值的电路。
效率回答了上文提出的问题:若泛化比记忆
更高效,梯度下降算法可通过强化
同时弱化
来进一步降低近乎完美的训练损失,进而引发测试性能的转变。 基于这一认识,我们在第3节证明以下三个关键性质足以实现顿悟(grokking):
泛化性能良好,而
则不然,
由于具有良好的泛化能力,它能够自动适用于训练数据集中新增的任何数据点,因此其效率应与训练数据集规模无关。相比之下,
必须记忆训练数据集中新增的所有数据点,因此其效率应随训练数据集规模的增大而降低。我们通过量化不同数据集规模下
和
的效率验证了这些预测。
这表明存在一个临界点,当数据集规模达到该点时,的效率将超过
,我们称此临界点为临界数据集规模
。通过分析
处的动力学行为,我们预测并验证了两种新现象(图1):
- ungrokking:当模型在远小于
的数据集上继续训练时,已实现顿悟的模型会重新表现出较低的测试准确率;
- semi-grokking:若选择

我们的主要贡献包括:1.通过构建的模拟实验,证明了三种要素对"顿悟"现象的充分性(第3节);2.通过分析理论隐含的"临界数据集规模"动态特性,预测了两种新行为模式:半顿悟与反顿悟(第4节);3.通过精密实验验证了预测,包括实际观测到半顿悟与反顿悟现象(第5节)。
2.符号说明
我们研究基于交叉熵损失的深度神经网络分类问题。具体而言,给定输入集、标签集
以及训练数据集
。对于任意分类器
,其softmax交叉熵损失定义为:
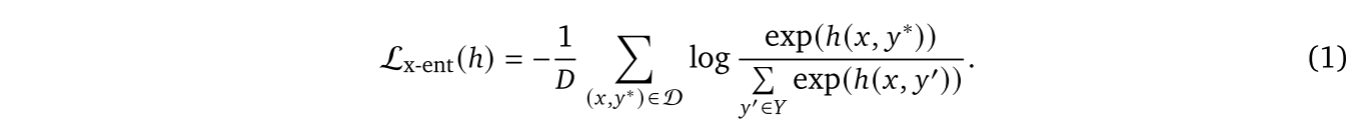
分类器针对特定类别的输出是该类别的逻辑值(logit),记作。当输入
可从上下文明确时,我们将逻辑值记为
。对于给定输入的所有类别逻辑值向量,我们记为
或简写为
(当
可从上下文明确时)。
参数化分类器(如神经网络)通过参数向量进行参数化,该向量诱导出分类器
。分类器的参数范数定义为
。通常会增加权重衰减正则化项,其损失函数为
。总体损失函数由下式给出:
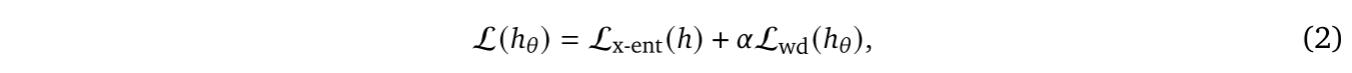
其中,为调节 softmax交叉熵与权重衰减的平衡常数。
Circuits. 电路。受 Olah et al. (2020)启发,我们使用术语"电路"指代神经网络工作的内部机制。我们仅考虑将输入映射到逻辑值的电路,因此电路会为整体任务诱导出一个分类器
。我们忽略这一区别,直接以
表示
,此时逻辑值为
,损失函数为
,参数范数为
。对于任意给定算法,存在多个实现该算法的电路。在不引起歧义的前提下,我们用
(
)表示实现泛化(记忆)算法的电路族,或该族中的某个具体电路。
3.顿悟的三个要素
对于一个具有完美训练精度的电路(如纯记忆化方法或完全泛化解
),交叉熵损失
会激励梯度下降放大分类器的逻辑值,因为这使其预测结果更具置信度,从而降低损失(参见定理 D.1)。对于典型神经网络,这通常通过增大参数实现。与此同时,权重衰减
则施加反向作用力,直接减小参数值。这两种作用力必须在整体损失的任意局部极小点处达到平衡。
当存在多个能够实现较高训练精度的电路时,该约束条件将分别适用于每个电路。但这些电路之间会呈现何种关联?直观而言,答案取决于各电路的效率——即该电路将较小参数转化为较大逻辑值的能力。对于更高效的电路: 1.推动参数增大的 **Lx-ent**作用力更强; 2.促使参数减小的 **Lwd**作用力更弱。 因此我们预期:在任意局部极小值点,效率更高的电路将表现出更强的优势。
基于这一效率概念,我们可以将"顿悟"现象解释如下:第一阶段,记忆性组件被快速习得,导致训练表现强劲而测试表现欠佳;第二阶段,泛化性组件
开始被学习,参数范数从
向
"重新分配",最终形成强
与弱
的混合状态,从而提升测试表现。这一完整解释依赖于三个关键要素的存在:
- 泛化电路:存在两类能实现良好训练性能的电路:一类是测试性能较差的记忆型电路族
- 效率性:
- 慢速与快速学习:
为验证这些要素的充分性,我们构建了一个包含全部三个要素的最小示例,并证明其会导致顿悟现象。需要强调的是,该示例旨在将所述三个要素视为验证性框架,而非对现有"顿悟"(grokking)实例动态的定量预测。模型中的多数假设与设计选择基于简化分析可行性的考量,而非旨在反映实际中的顿悟现象。最显著的差异在于:模型中和
被构建为硬编码的输入-输出查找表,其输出通过可学习的标量权重增强;而现有顿悟实例中,
和
是神经网络内部通过学习形成的机制,通过扩大实现这些机制的参数规模来增强其效能。
泛化性建模。为描述泛化性,我们引入训练数据集 和测试数据集
。其中
是一个能产生对数几率(logits)的查找表,其在训练集和测试集上均达到完美准确率;
则是仅在训练集上达到完美准确率,但对测试数据会做出高置信度的错误预测。我们用
表示
在测试输入上的预测结果,其特性是
与
不存在交集。由此可得:
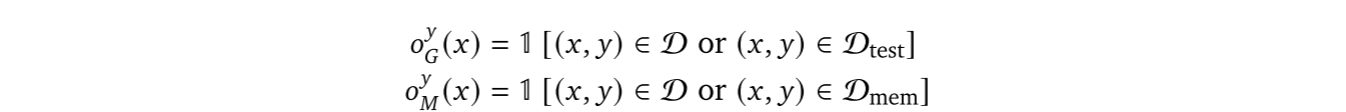 慢速学习与快速学习。为建模学习过程,我们为每条电路引入权重,并采用梯度下降法更新权重。因此,整体逻辑值由下式给出:
慢速学习与快速学习。为建模学习过程,我们为每条电路引入权重,并采用梯度下降法更新权重。因此,整体逻辑值由下式给出:
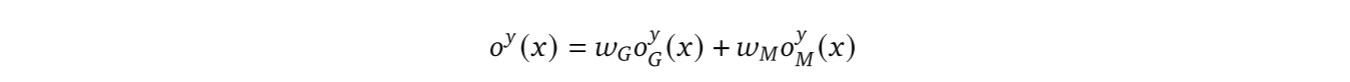
遗憾的是,若直接通过梯度下降学习 和
,我们将无法控制权重的学习速度。受 Jermyn和 Shlegeris (2022)的启发,我们改为将权重计算为两个"子权重"的乘积,随后通过梯度下降学习这些子权重。具体而言,令
且
,并按照
更新每个子权重。此时,梯度下降强化权重的速度可通过权重的初始值进行控制。直观上,第一个子权重的梯度
取决于第二个子权重的强度
,反之亦然,因此较低的初始值会导致缓慢的学习过程。初始化时,我们设定
以确保逻辑值初始为零,随后设定
以保证
的学习速度慢于
。
效率。前文将电路效率操作化定义为电路将较小参数转换为较大逻辑值的能力。当所有权重均为1时,每个电路生成的逻辑值为独热向量,此时逻辑值尺度相同,效率完全由参数范数决定。我们定义 $P_G$和 $P_M$为所有权重为1时的参数范数。为使比
更高效,设定
。
这引出一个关键问题:当权重非全1时,如何建模参数范数?直观而言,增加权重相当于增大神经网络参数以放大输出。在具有Relu激活函数且无偏置项的层MLP中,将所有参数缩放常数
会使输出放大
倍。受此启发,我们将
的参数范数建模为
(其中
),对
同理处理。
理论分析。我们首先分析上述设置的最优解。由于子权重仅影响学习速度,可以忽略不计:损失函数 和
仅取决于权重,与子权重无关。直观而言,为获得最小损失,必须将更高权重分配给更高效的电路——但尚不清楚是否应对低效电路分配零权重,还是分配较小但仍非零的权重。定理 D.4表明,在我们的示例中这两种情况均可能出现:具体结果取决于参数
的取值。
实验分析。我们针对不同超参数运行示例,并在图2中绘制了训练损失与测试损失曲线。结果显示:当同时具备全部三个要素时(图2a),可观察到标准的顿悟曲线,表现为测试损失的延迟下降;相比之下,若降低泛化电路效率(图2b),测试损失始终未下降;而移除慢速/快速学习机制时(图2c),测试损失会立即下降。详见附录C。
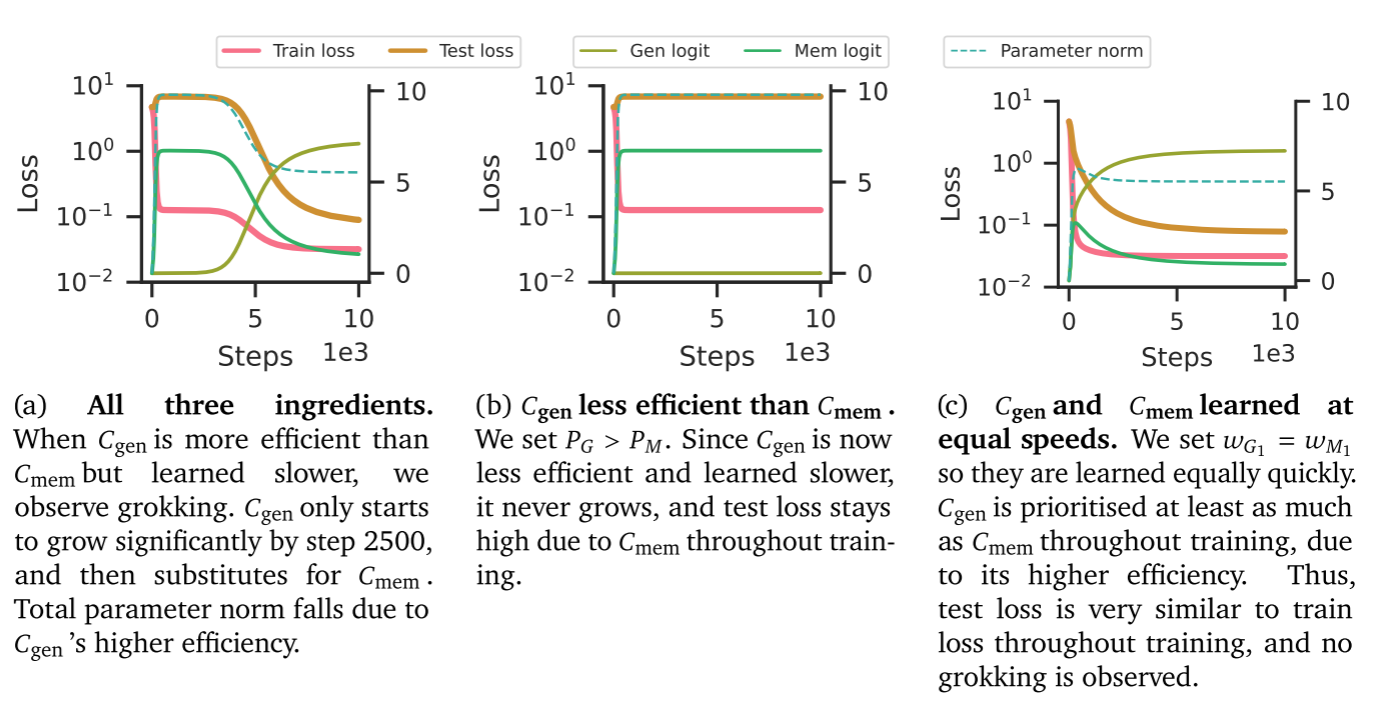
4. Why generalising circuits are more efficient
第3节证明了当比
更高效时会出现顿悟现象,但未解决
为何更高效的问题。本节基于训练数据集规模
建立理论框架,并据此预测两种新行为:反顿悟与半顿悟。
4.1.效率与数据集规模的关系
考虑在规模为的数据集
上通过权重衰减训练得到的分类器
,以及在扩充单点
后训练得到的分类器
。直观上,
的效率不可能超过
:若存在这种情况,则
$即使在原数据集
上也会优于
,因为两者在
-熵相近时,前者通过权重衰减获得了更好的效果。因此可以预期:分类器效率随数据集规模增大呈单调非增趋势。泛化性如何影响这一结论?假设
能成功泛化并预测新输入
对应的
。那么当数据从
扩展到
时,
-熵(
)通常不会因新增数据点而恶化。此时可能观察到相同的分类器,其平均逻辑值、参数范数及效率均保持不变。
现在假设 $\mathcal{h}_D$未能正确预测新数据点。此时,针对该数据点学习得到的分类器$D'$的效率可能会降低:由于新增数据点的存在,交叉熵损失
会显著升高,因此新分类器必须通过额外的正则化损失来降低该新数据点上的
。将此分析应用于我们的电路模型时,可以预期
的效率会随着
的任意增大而保持不变,因为
无需调整即可适应新增训练样本。相反,
几乎需要为每个新数据点进行调整,因此其效率应会随着
的增大而下降。由此可见,当
足够大时,
将比
更高效。(但需注意:当可能输入集较小时,即使最大化的
也可能达不到"足够大"的条件。)
数据集规模的临界阈值。直观而言,我们预期当数据集极小时(例如
),模型极易记住训练数据。因此假设:在极小数据集下,记忆
增大而降低,故存在临界数据集规模
时,
时,
权重衰减对 的影响。由于
仅由
与
的相对效率决定,且二者均不依赖于权重衰减的具体数值(仅需其存在性),理论预测
不应随权重衰减强度变化。当然,权重衰减强度仍可能影响其他性质(例如达到顿悟所需的训练周期数)。
4.2 交叉现象的启示:ungrokking与 semi-grokking。
通过分析数据集规模临界阈值附近的行为特征,我们预测存在两种未被报道过的现象(据我们所知)。
Ungrokking.逆顿悟。假设我们选取一个已在数据集规模条件下完成训练并表现出顿悟行为的网络,继续在规模
的较小数据集上训练。此时在新训练环境中,记忆组件
的效率将高于泛化组件
,因此我们预测:经过充分训练后,梯度下降算法会将权重从
重新分配至
,从而导致测试性能从高位向低位跃迁。由于该现象与常规顿悟完全相反,我们将其命名为"逆顿悟"。
Ungrokking可以看作是灾难性遗忘的一种特殊情况(McCloskey and Cohen, 1989; Ratcliff, 1990),在那里我们可以做出更精确的预测。 首先,因为ungrokking应该只在,如果我们改变𝐷’,我们预测会有一个从非常强到接近随机的测试精度的急剧转变(𝐷crit左右)。 其次,我们预测,即使我们只从训练数据集中删除示例,也会出现ungrokking,而灾难性遗忘通常也涉及对新示例的训练。 第三,由于𝐷crit不依赖于权重衰减,我们预测“遗忘”的数量(即收敛时的测试精度)也不依赖于权重衰减。
Semi-grokking半顿悟。 假设我们在一个数据集𝐷≈𝐷crit上训练一个网络。 𝐶gen和𝐶mem的效率相似,我们期望观察到的情况有两种可能的情况(见定理D.4)。
在第一种情况下,梯度下降会选择 和
之一,并将其作为最大电路。这可能以一致的方式发生(例如,由于
学习速度更快,它总是成为最大电路),也可能依赖于随机初始化的方式。无论哪种情况,我们都只能观察到顿悟现象的存在或缺失。
在第二种情况下,梯度下降会产生和
的混合。由于
和
都不会主导测试集的预测,我们预期测试性能表现中等。
仍会被更快学习,因此这种现象与"顿悟"(grokking)类似:初始阶段训练性能良好但测试性能较差,随后过渡到测试性能显著提升。由于我们仅获得中等程度的泛化能力(不同于典型的顿悟现象),故将这种行为称为"半顿悟"(semi-grokking)。我们的理论并未说明实践中会出现哪种情况,但在第5.3节中,我们发现在当前设定下确实会出现半顿悟现象。
5. Experimental evidence
我们对"顿悟"(grokking)现象的解释得到以下先前研究的支持:
- **泛化电路机制**:Nanda等人(2023,图1)在模加法任务中识别并表征了顿悟后期习得的泛化电路结构。
- **慢速与快速学习**:Nanda等人(2023,图7)通过"进展度量"证明,在模加法任务中,当网络已达到100%训练精度后,泛化电路仍会持续发育并强化。
为进一步验证我们的解释,我们通过实验检验第4节提出的预测:
(P1) Efficiency:证实了生成成本效率与数据集规模无关,而记忆成本
效率随训练数据集增大而降低的预测。
(P2) Ungrokking (phase transition) **逆顿悟(相变)**:验证了逆顿悟现象在临界维度$D_{crit}$附近发生相变的预测。
(P3) Ungrokking (weight decay) **逆顿悟(权重衰减)**:证实了权重衰减强度不影响逆顿悟后最终测试精度的预测。
(P4)Semi-grokking **半顿悟**:实证了半顿悟现象的实际存在性。
训练细节:我们采用AdamW优化器(Loshchilov and Hutter,2019)在交叉熵损失函数下训练单层Transformer模型(详见附录A)。本节所有实验结果均基于模加法任务(计算,其中
且
),其他9个任务的实验结果见附录A。
5.1.效率与数据集规模的关系
我们首先检验关于记忆化效率与泛化效率的预测:(P1)效率。根据4.1节的预测,记忆化效率随训练数据集规模增大而降低,而泛化效率保持恒定。为验证(P1),我们观察仅含单一电路的训练过程,分析逻辑输出$o_{y_i}$如何随参数范数$P_i$(通过权重衰减调节)和数据集规模$D$变化。
实验设置。我们通过为训练数据使用完全随机标签来生成仅含的网络(Zhang等人,2021),并假设收敛时的全部参数范数均分配给记忆任务。通过在大规模数据集上训练并验证超过95%的logit范数仅来自三角子空间(详见附录B),我们构建了仅含
的网络。
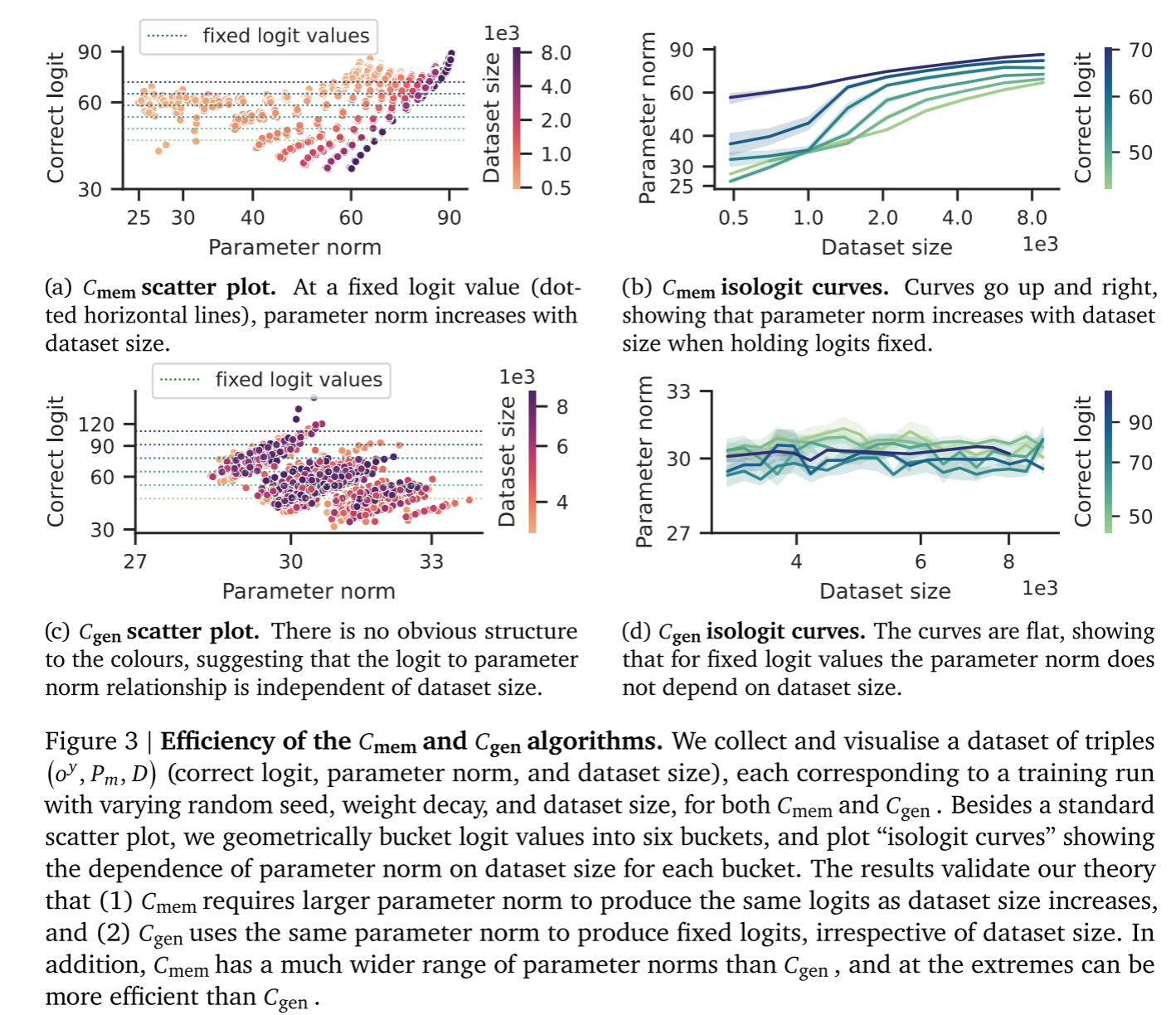
结果。图3a与图3b验证了我们关于记忆效率的理论预测。具体而言,当数据集规模增大时,为产生相同的逻辑特值(logit value)需要更高的参数范数,这表明效率降低。此外,对于固定规模的数据集,按预期扩大逻辑特值需要同步增加参数范数。图3c与图3d验证了我们关于泛化效率的理论预测:无论数据集规模如何变化,产生相同逻辑特值所需的参数范数保持不变。需注意图中不同随机种子间存在显著方差。我们推测存在多种不同电路可实现相同的整体算法,但其效率各异,而随机初始化决定了梯度下降最终找到的电路类型。例如在模加法任务中,泛化算法依赖于一组"关键频率"(Nanda et al.,2023),不同关键频率的选择可能导致效率差异。
从图3c来看,增加参数范数似乎不会提高logit值,这与我们的理论相矛盾。然而,这是由于随机种子引起的方差所导致的统计假象。我们确实观察到特定颜色的"条纹"向右上方延伸:这些条纹对应相同种子和数据集规模、但权重衰减不同的实验运行结果,表明当消除随机种子带来的噪声后,参数范数的增加确实会显著提升logit值。
5.2 逆顿悟现象:泛化后的过拟合
我们现在转向验证关于逆顿悟(ungrokking)的预测。图1b证实了逆顿悟现象的实际存在。本节重点测试其是否具备预期特性。
(P2)相变特性:根据4.2节的预测,若绘制收敛时测试准确率随缩减训练集规模的变化曲线,将在临界值
附近出现相变。
(P3)权重衰减无关性:我们预测(见4.2节),收敛时的测试准确率与权重衰减强度无关。
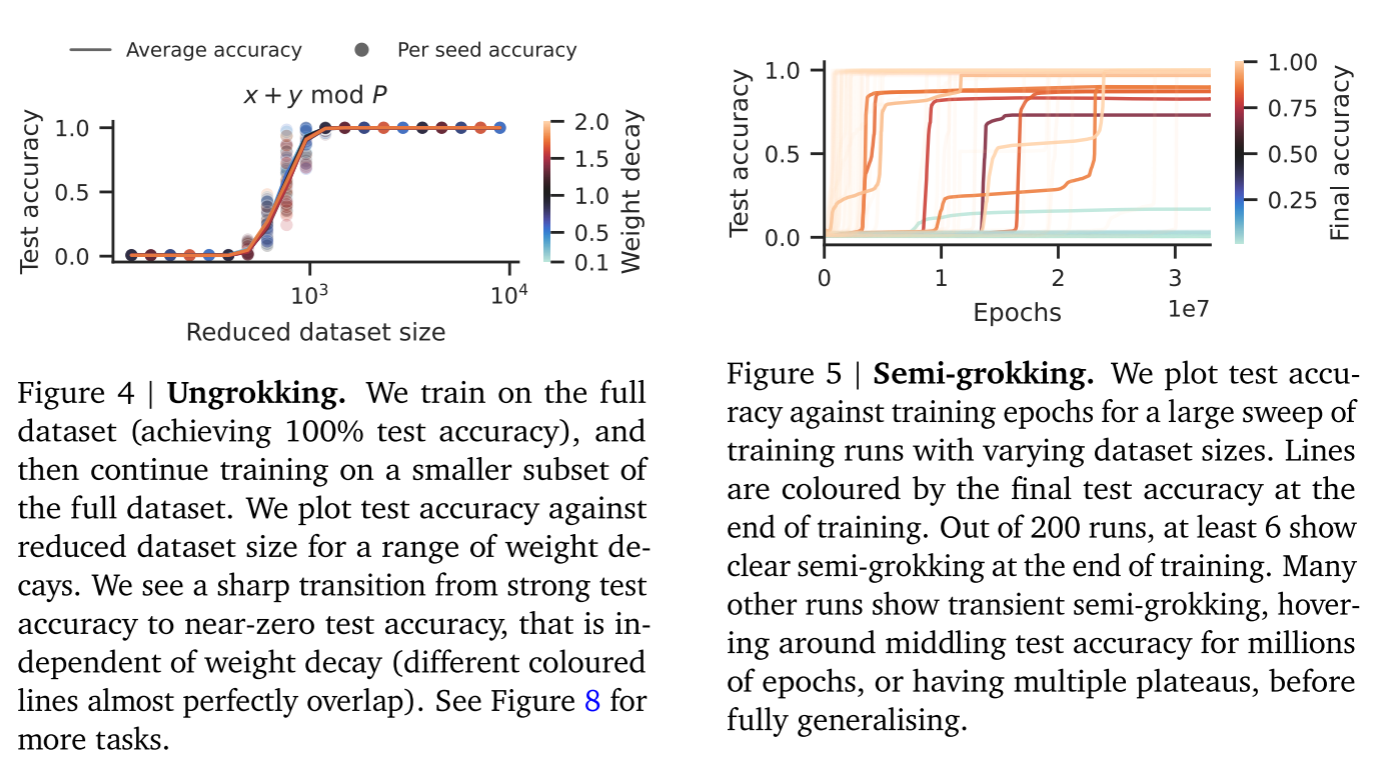
实验设置。我们首先在完整数据集上将网络训练至收敛以实现完美泛化,随后继续在完整数据集的一个小子集上训练模型,并测量收敛时的测试准确率。实验中同时调整子集规模与权重衰减强度。实验结果。图4所示结果明确验证了(P2)和(P3)两个命题。附录A包含补充结果,其中图8复现了多个附加任务的实验结果。
5.3 半顿悟:势均力敌的电路
与前述预测不同,半顿悟现象并未严格蕴含于我们的理论中。但正如后续所示,该现象确实在实践中出现。
(P4) 半顿悟定义:当训练处于 𝐷 ≈ 𝐷crit附近时(此时记忆电路 𝐶mem与泛化电路 𝐶gen的效率大致相当),收敛后的最终网络应满足以下两种情形之一:1.完全由最高效的电路构成;2. 𝐶mem与 𝐶gen以近似比例共存。若为第二种情形,我们应观察到:在训练精度接近完美后,测试精度会显著延迟地过渡至中等水平。
在实践中展示半顿悟(semi-grokking)的实例存在若干困难。首先,随着数据集规模 $D$的减小,顿悟所需时间呈超指数级增长(Power et al.,2021,图1),而临界数据集规模 显著小于能产生顿悟现象的最小数据集规模。
研究表明:首先,随机种子会导致 和
的效率产生显著波动,进而影响该次运行的临界值
;其次,准确率会随
比值发生剧烈变化(见附录A)。为观测中等准确率的相变现象,需平衡
和
的输出,但由于随机种子引起的方差效应,这种平衡难以实现。为解决这些问题,我们在略高于典型
估计值的数据集规模上进行了多组训练实验。通过随机噪声的作用,部分实验会呈现异常低效的
或异常高效的
,从而使两者效率匹配,最终获得部分顿悟(semi-grok)的机会。
实验设置。我们在区间[1500,2050]内均匀选取20个数据集规模(略高于我们估计的值),每个规模训练10个随机种子。实验结果。图1c展示了一个体现半顿悟现象的独立运行示例,图5呈现了所有运行时序的测试准确率。这些结果既验证了我们关于半顿悟可能存在的初始假设,也引出了新的问题。在图1c中,我们观察到两个半顿悟特有的现象:(1)测试准确率在最终收敛前会多次出现"尖峰";(2)训练损失在固定范围内波动。这些现象的机理研究将留待后续工作。
在图5中,我们观察到经常会出现瞬态半顿悟现象(transient semi-grokking),即训练过程会在中等测试准确率水平持续数百万个epoch,或出现多个平台期,之后才实现完美泛化。我们推测每次转变都对应梯度下降强化了一个新的泛化电路,该电路比先前强化的任何电路都更高效,但需要更长的学习时间。可以推测:若延长训练时间,多数半顿悟过程会呈现完全顿悟;而原本未泛化的训练过程至少会部分泛化,表现出半顿悟特征。鉴于验证半顿悟现象的难度,本实验仅在模加法(modular addition)任务中开展。但我们在模加法任务中的经验表明:若仅关注收敛值,通过已顿悟网络的逆向顿悟(ungrokking)能比随机初始化网络的半顿悟过程更快获得结果。因此其他任务的逆向顿悟结果(图8)间接支持了这些任务同样存在半顿悟现象的推论。
8.结论
本文的核心问题是:在顿悟(grokking)现象中,为何神经网络在训练性能已达近乎完美后,继续训练会使其测试性能显著提升?我们的解释是:泛化解(generalising solution)比记忆解(memorising solution)更“高效”,但学习速度更慢。
在快速学习记忆电路后,梯度下降仍可通过同时增强高效泛化电路与削弱低效记忆电路来进一步降低损失。基于我们的理论,我们预测并验证了两种新现象:ungrokking——当模型在低于临界阈值的数据集上继续训练时,已实现完美泛化的模型会退回到记忆状态;以及半顿悟(semi-grokking)——在临界数据集规模上训练随机初始化的网络时,会出现类似顿悟的中等测试精度跃迁。我们的理论解释是当前唯一能作出(并验证)此类惊人前瞻性预测的框架,由此我们对该解释具有高度信心。

![[蓝桥杯]高僧斗法](https://i-blog.csdnimg.cn/img_convert/2d1caafc03f4e7fa5d76a6696f2b9d74.png)