0.背景
a.访问一个文件,都必须先把对应的文件打开(打开文件就是把它从磁盘加载到内存中)
b.如果一个文件,压根就没有被打开,那么它就在磁盘上
c.谁来打开??用户通过bash,启动进程打开这个文件的->fopen(系统调用)->操作系统->进程通过操作系统打开文件
d.OS内,一定同时存在大量的被打开的文件->OS如何管理这些被打开的文件呢(先描述,再组织)->一定存在一种数据结构体,描述被打开的文件!!如同pcb一样!
e.进程有task_struct,未来进程也有打开的文件,我们研究打开文件,本质是研究:进程与文件的关系!!!
1.理解“文件”
1.0 结论:
打开文件,必须先找到文件,要找到文件,就必须知道文件的路径+文件名,这就是为什么进程要有cwd(查找文件的默认路径!)的原因之一。
#include<>从系统默认目录中查找;#include“”优先从当前源文件目录找,找不到再从系统默认目录中查找。
1.1狭义理解:
• ⽂件在磁盘⾥
• 磁盘是永久性存储介质,因此⽂件在磁盘上的存储是永久性的
• 磁盘是外设(即是输出设备也是输⼊设备)
• 磁盘上的⽂件 本质是对⽂件的所有操作,都是对外设的输⼊和输出 简称 IO1.2广义理解:
Linux下一切皆文件(键盘、显⽰器、⽹卡、磁盘…… 这些都是抽象化的过程)
1.3文件操作:
• 对于 0KB 的空⽂件是占⽤磁盘空间的
• ⽂件是⽂件属性(元数据)和⽂件内容的集合(⽂件 = 属性(元数据)+ 内容)
• 所有的⽂件操作本质是⽂件内容操作和⽂件属性操作1.4系统角度:
• 对⽂件的操作本质是进程对⽂件的操作
• 磁盘的管理者是操作系统
• ⽂件的读写本质不是通过 C 语⾔ / C++ 的库函数来操作的(这些库函数只是为⽤⼾提供⽅便),⽽
是通过⽂件相关的系统调⽤接⼝来实现的2.回顾C文件接口
2.0背景知识:

fopen是用于打开文件的标准库函数 。
filename : 是一个指向字符串的指针,该字符串包含了要打开文件的路径及文件名 。
mode :也是一个指向字符串的指针,用于指定打开文件的方式,r读,w写,a追加等等。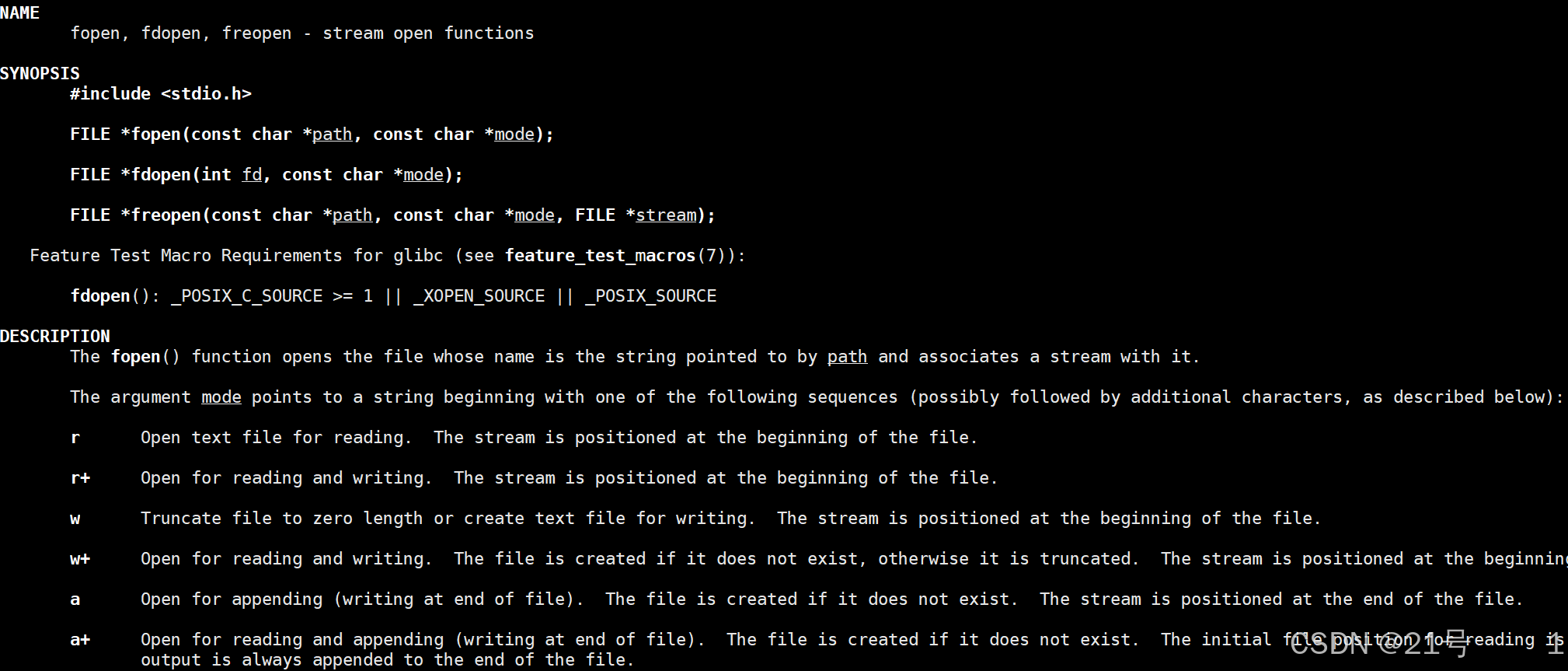
函数调用成功时,返回一个指向 FILE 类型结构体的指针,该指针指向已打开文件的相关信息,后续可通过这个指针进行文件读写等操作;若文件打开失败,返回 NULL ,并且会设置全局变量 errno 来指示错误类型 。

fclose用于关闭一个已经打开的文件
stream 是指向需要关闭的文件的指针 ,该指针是通过 fopen 等函数打开文件时返回的
2.1 hello.c打开文件

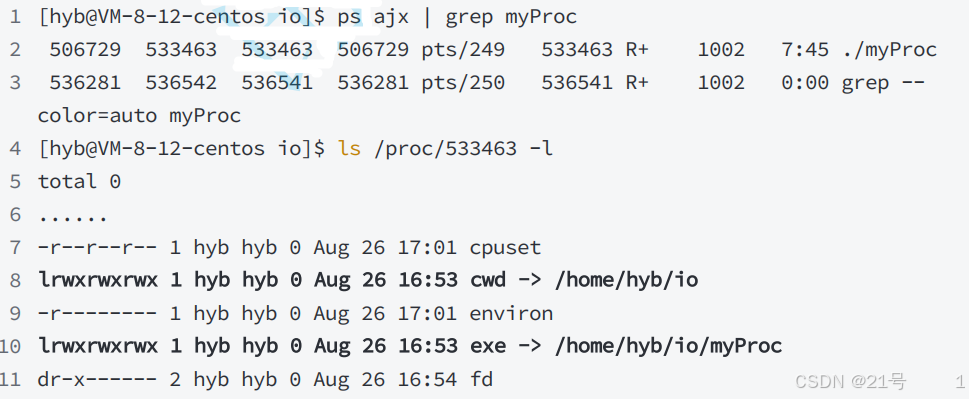
1.cwd:指向当前进程运行目录的一个符号链接
2.exe:指向启动当前进程的可执行文件(完整路径)的符号链接
打开⽂件,本质是进程打开,所以,进程知道⾃⼰在哪⾥,即便⽂件不带路径,进程也知道。由此OS就能知道要创建的⽂件放在哪⾥。
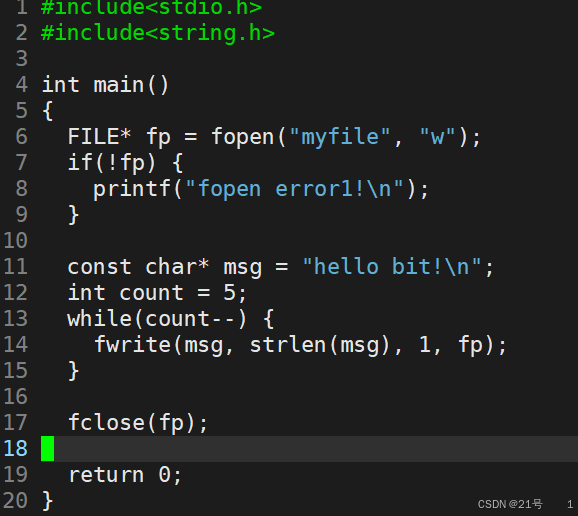
2.2 hello.c写文件

fwrite用于向文件写入数据块

写入位置与文件打开模式有关,比如 w+ 模式从文件指针位置开始写,可能覆盖原有内容;a+ 模式从文件末尾追加内容 。
若成功执行,返回实际写入的数据项个数。若此返回值与 nmemb 不同,表明写入过程出错。比如磁盘空间不足、文件权限问题等会导致写入错误。
注意:fwrite 写入的数据先存于用户空间缓冲区,不会立即同步到文件,若要及时更新文件内容,可调用 fflush 函数。
2.3 hello.c读文件

fread用于从文件中读取数据(函数参数与fwrite类似)
fread 函数从 stream 所指向的文件中,按二进制形式读取数据,并将其存储到 ptr 指向的内存区域

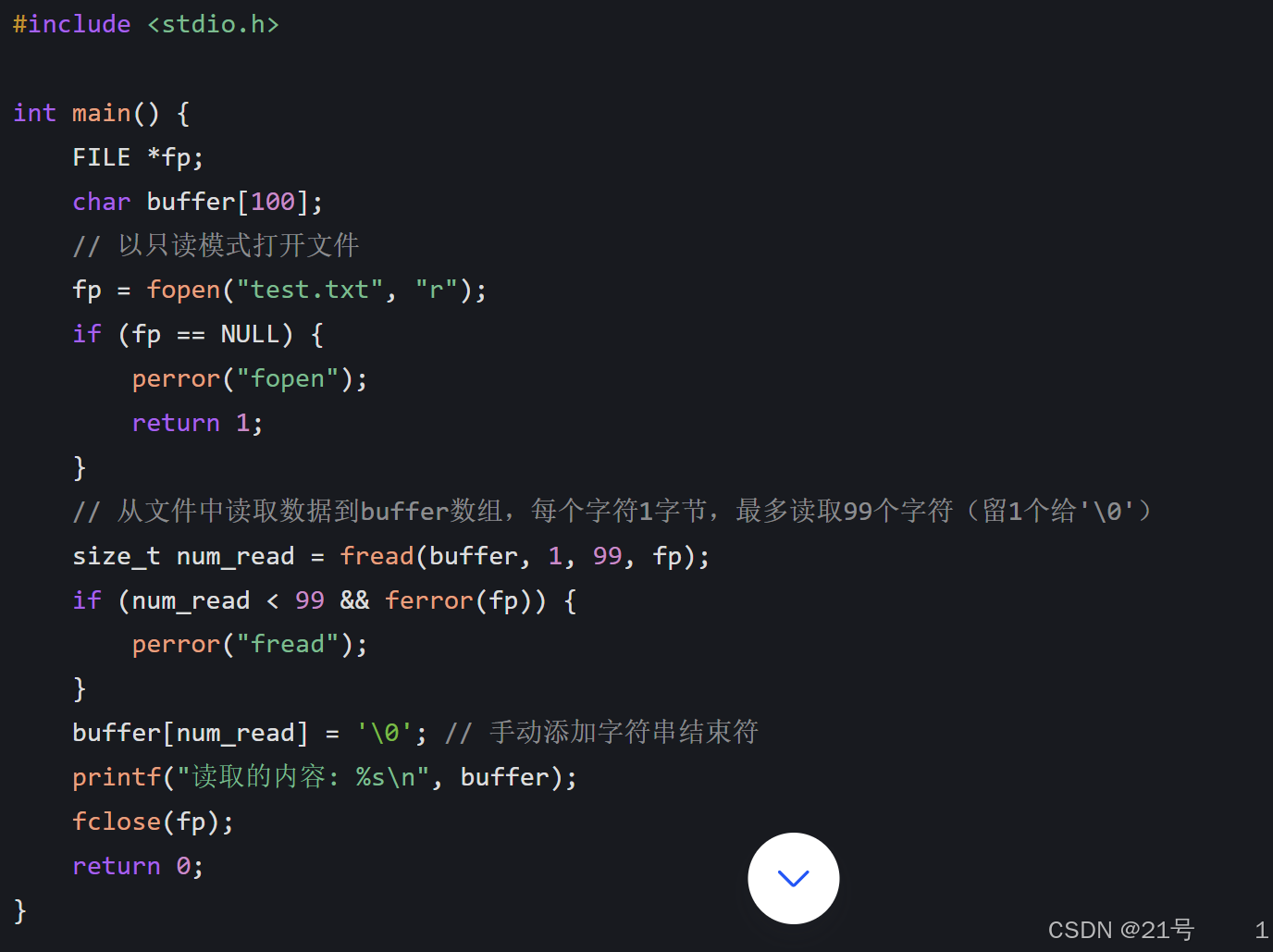 feof用于判断文件指针是否已经到达文件末尾。在循环读取文件内容时,可以帮助我们确定何时停止读取。
feof用于判断文件指针是否已经到达文件末尾。在循环读取文件内容时,可以帮助我们确定何时停止读取。

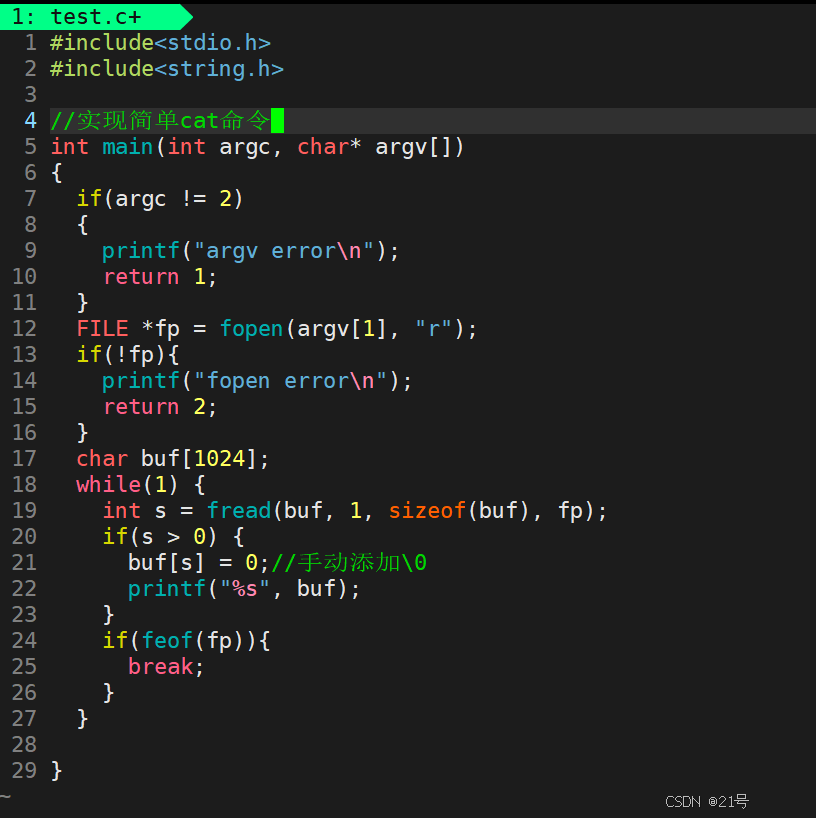 2.4 输出信息到显示器
2.4 输出信息到显示器
我今天向显示器写入12345,我并不是写入了一个int 12345,而是向显示器写入了‘1’ ‘2’ ‘3’ ‘4’ ‘5’
同理我今天通过键盘,输入12345,其实是输入了‘1’ ‘2’ ‘3’ ‘4’ ‘5’。所以,显示器和键盘都叫做字符设备,他们都是文本文件。
int x = 12345;
printf("%d", x);12345->'1','2','3','4','5' --->格式化输出scanf()
1,2,3,4,5 -> 12345 -> &a --->格式化输入 二进制文件和文本文件是由文件本身属性决定的。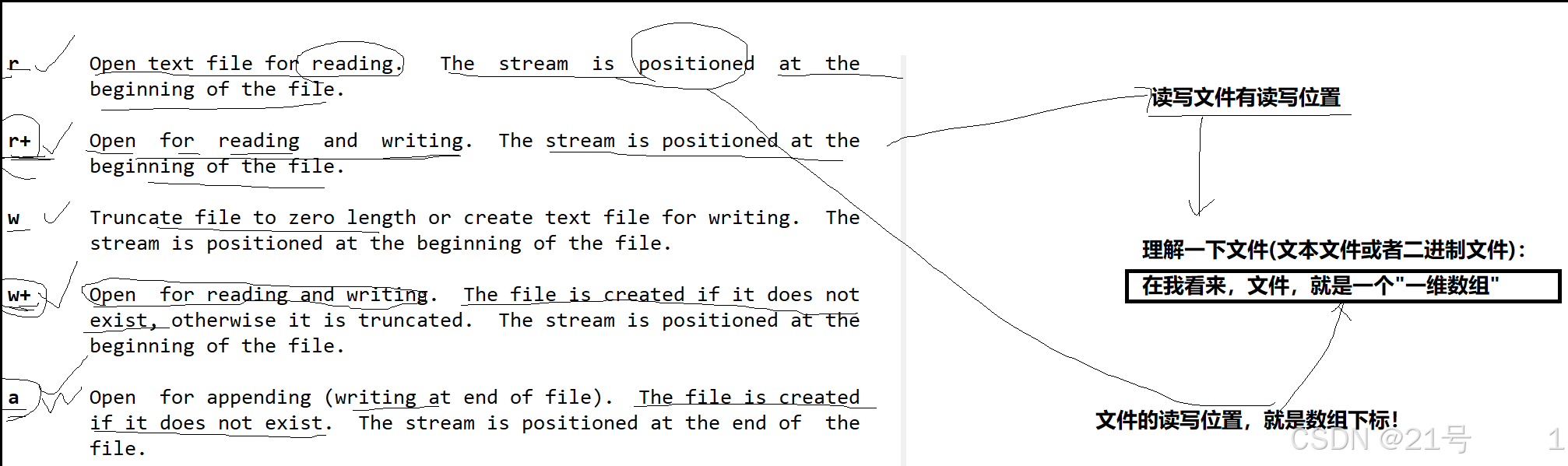


2.5 stdin & stdout & stderr
• C默认会打开三个输⼊输出流,分别是stdin, stdout, stderr
• 仔细观察发现,这三个流的类型都是FILE*, fopen返回值类型,⽂件指针#include <stdio.h>
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;3.系统文件I/O
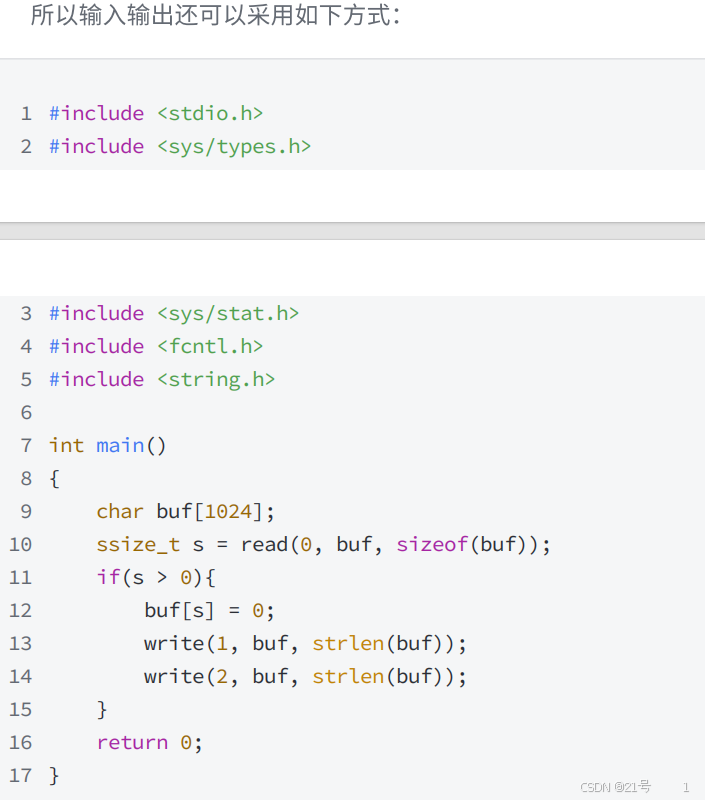
3.1 一种传递标志位的方法
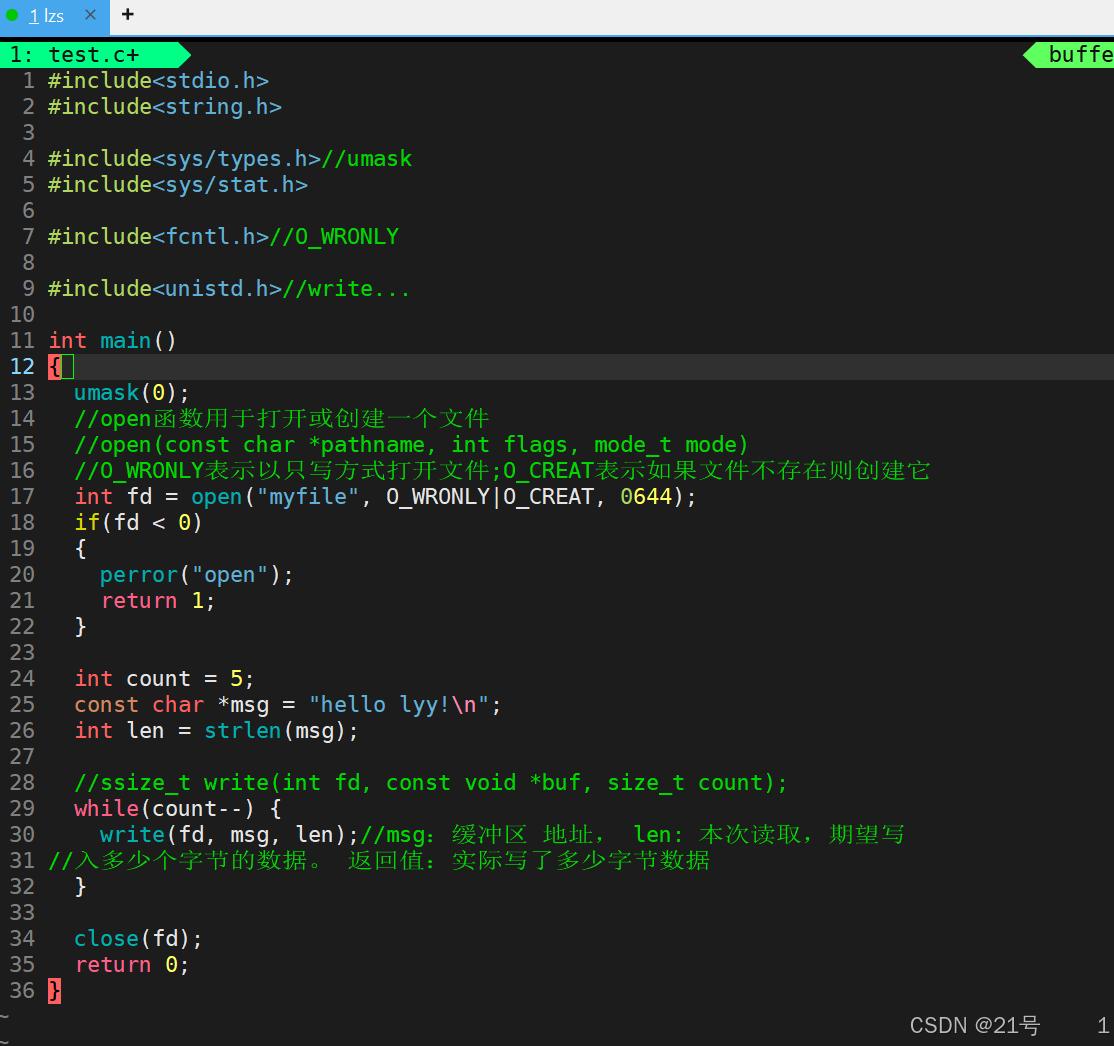
3.2 hello.c 写文件:

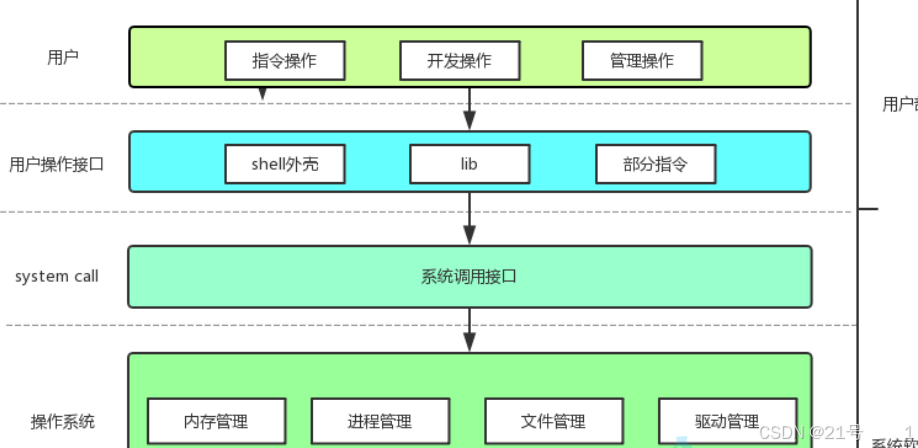
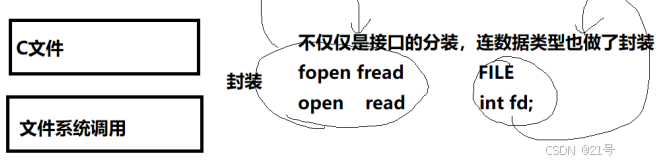
• 上⾯的 fopen fclose fread fwrite 都是C标准库当中的函数,我们称之为库函数
(libc)。
• ⽽ open close read write lseek 都属于系统提供的接⼝,称之为系统调⽤接⼝系统调用接口和库函数的关系,一目了然。
所以,可以认为,f#系列的函数,都是对系统调用的封装,方便二次开发。

1.为什么C语言要封装文件操作接口?2.为什么大部分语言,都要对系统调用做封装?
跨平台性(主要原因,来增加语言竞争力);系统调用麻烦(次要原因)。

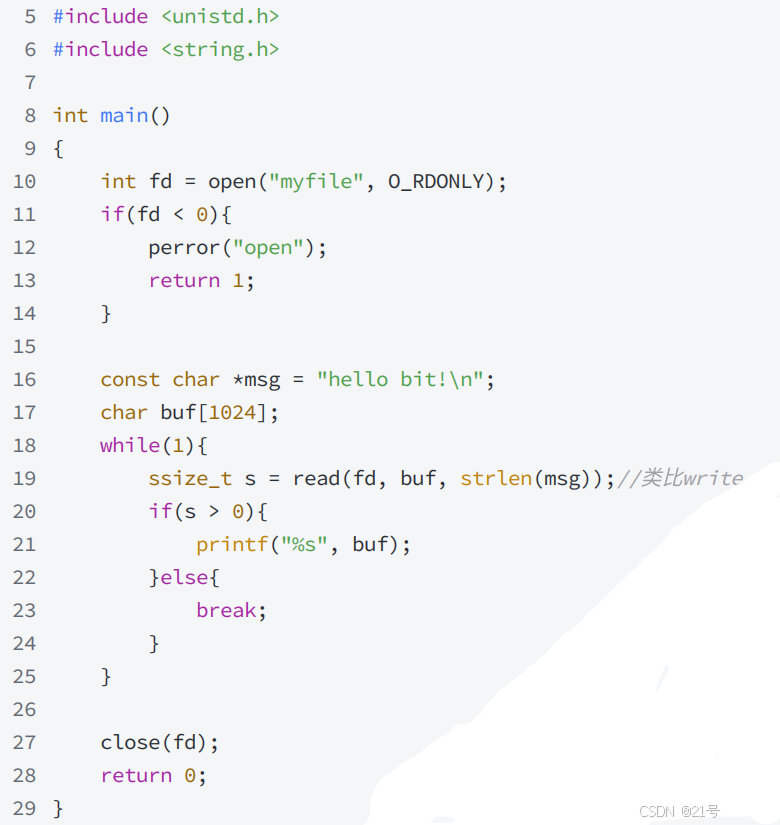
3.3 hello.c 读文件:
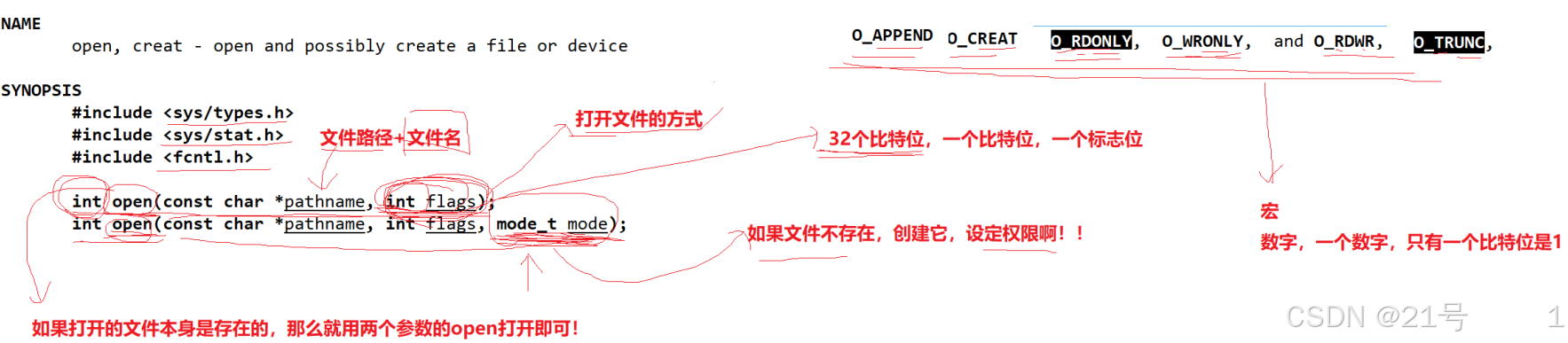
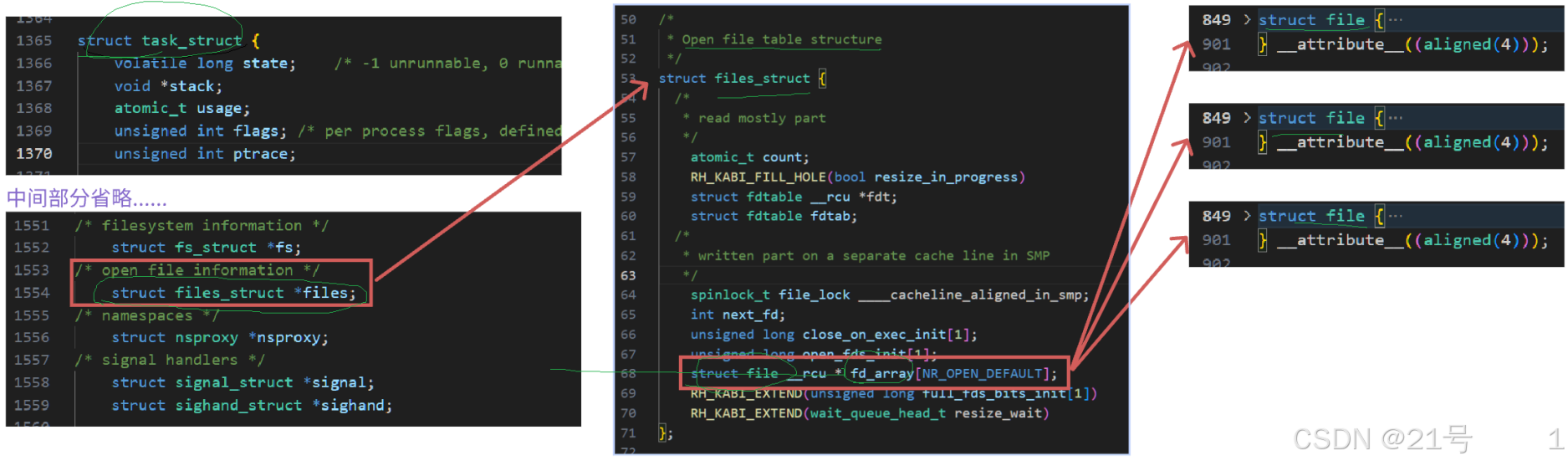
*3.4 文件描述符fd(本质是进程的文件描述符表的下标)
通过对open函数的了解(其返回值是文件描述符),文件描述符是一个小整数。
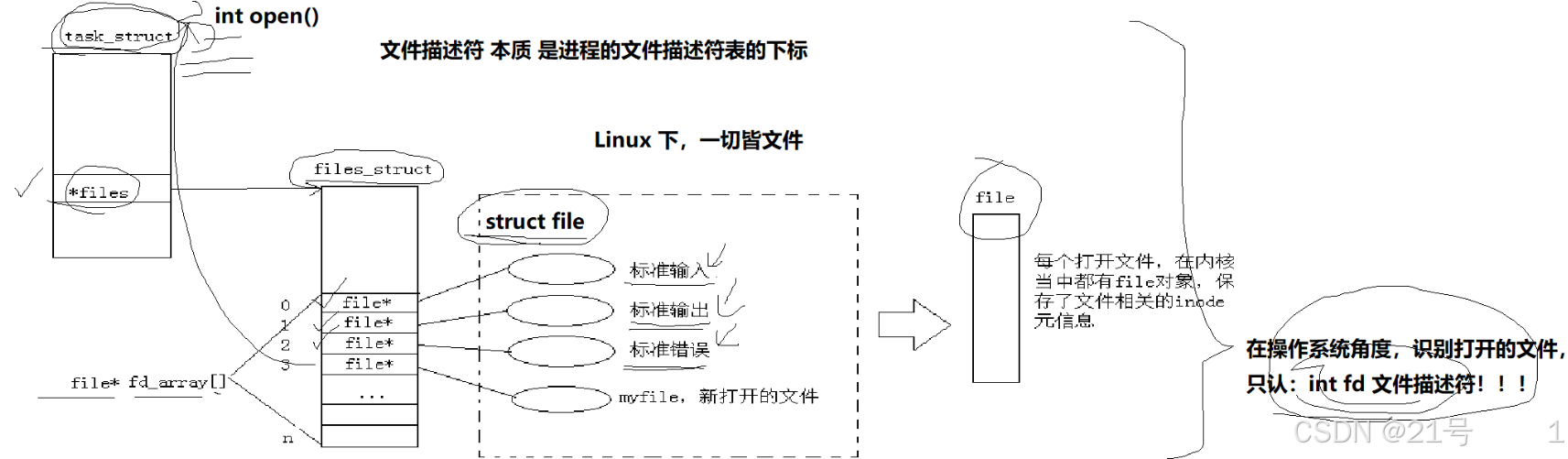
FILE是什么?->C标准库内定义的一个结构体!->推测FILE结构体里面,一定要封装一个整数,一定是fd
write(3,“hello world”) ->用户定义的缓冲区内部保存的数据!->所以:write根本就不是写入到文件,write的本质:是拷贝函数!把数据从用户空间拷贝到对应文件的内核缓冲区中!
3.4.2 文件描述符分配规则
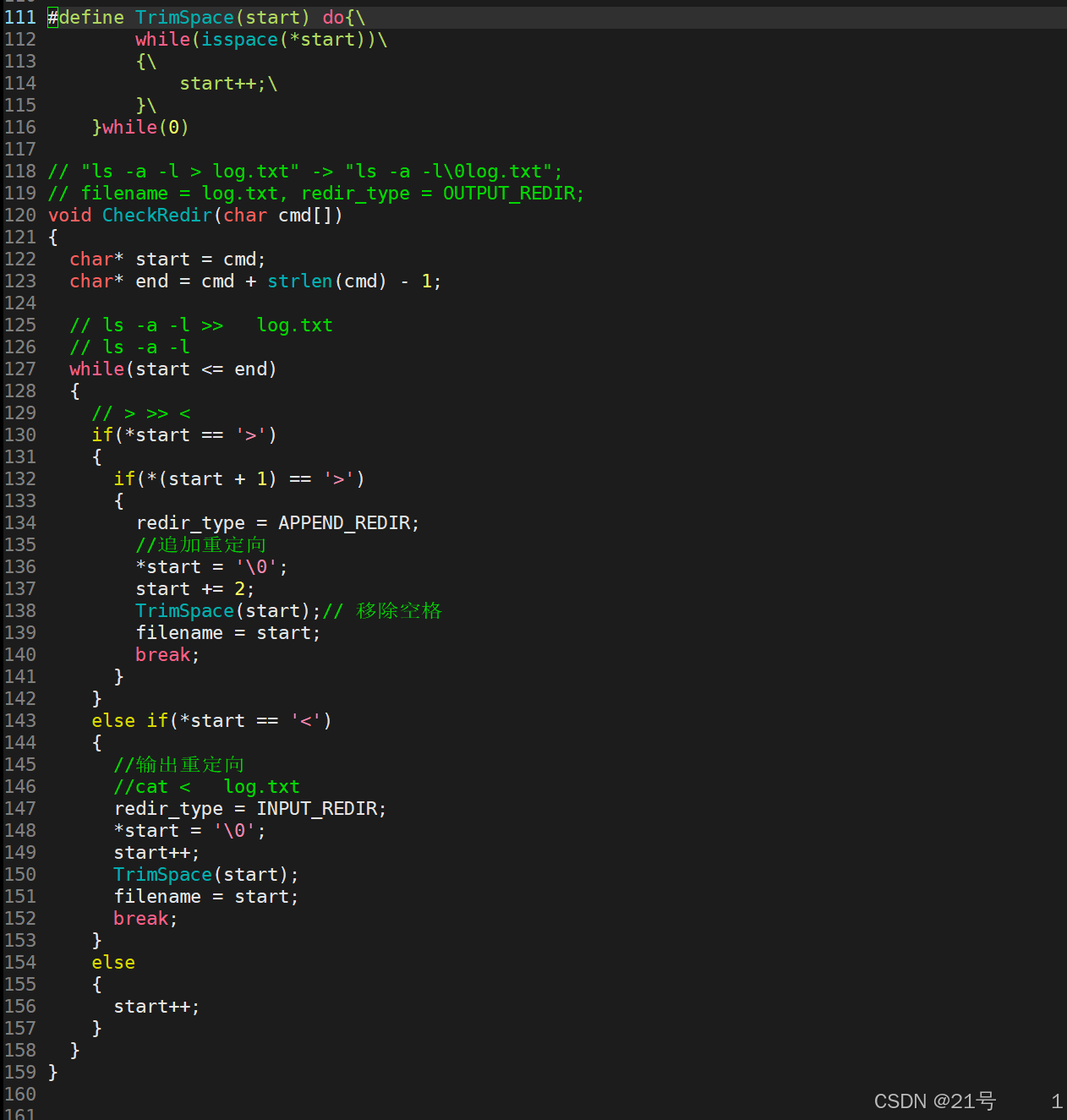
3.4.3 重定向
系统进行重定向必须先打开这个文件!
那么,关闭1会发生什么?
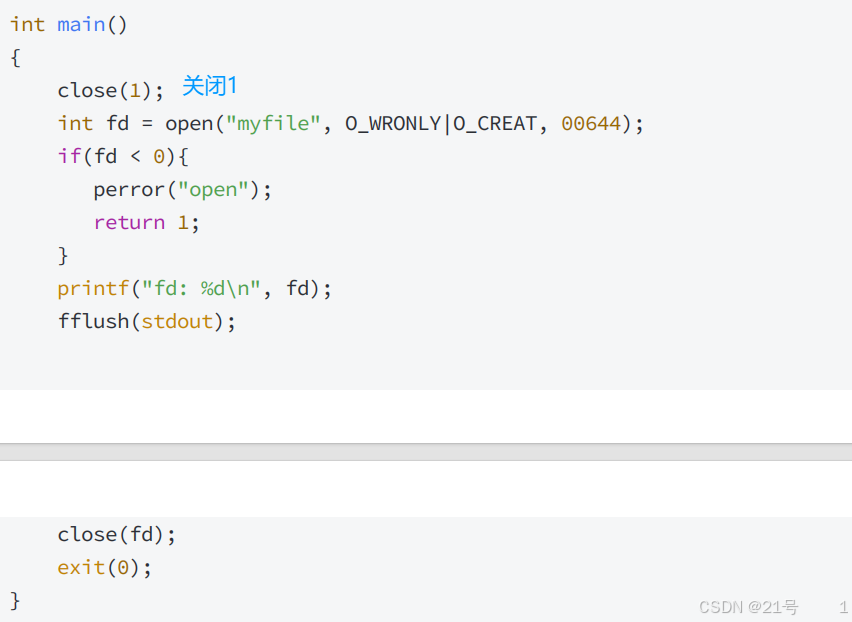
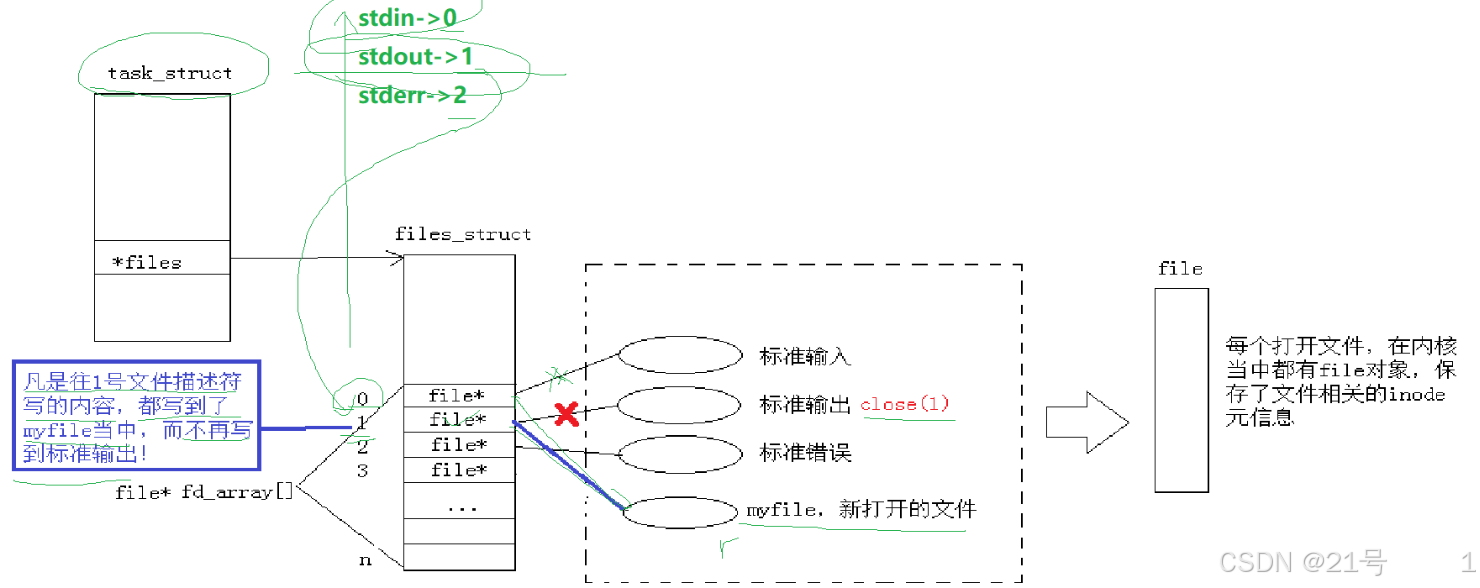
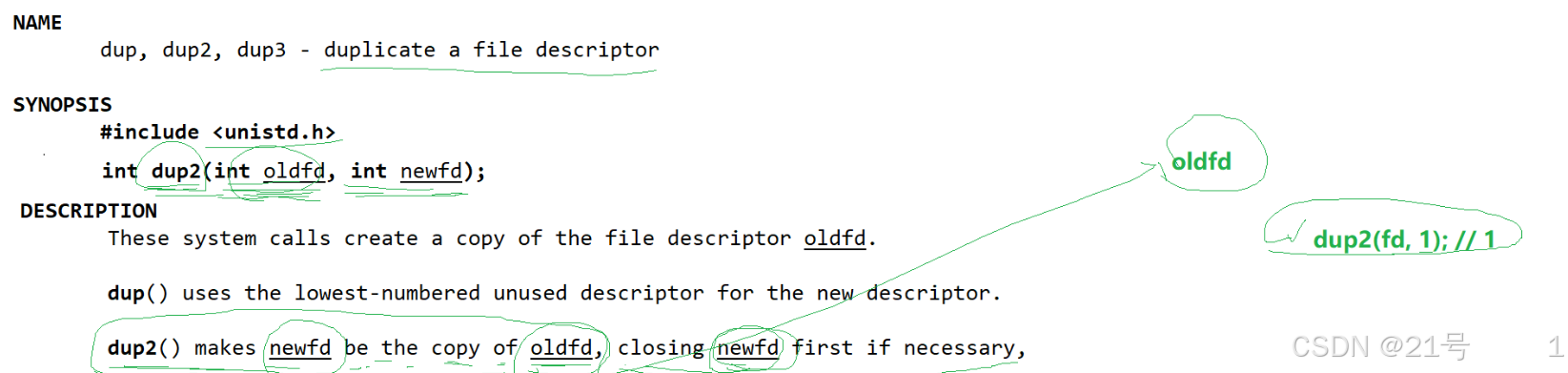
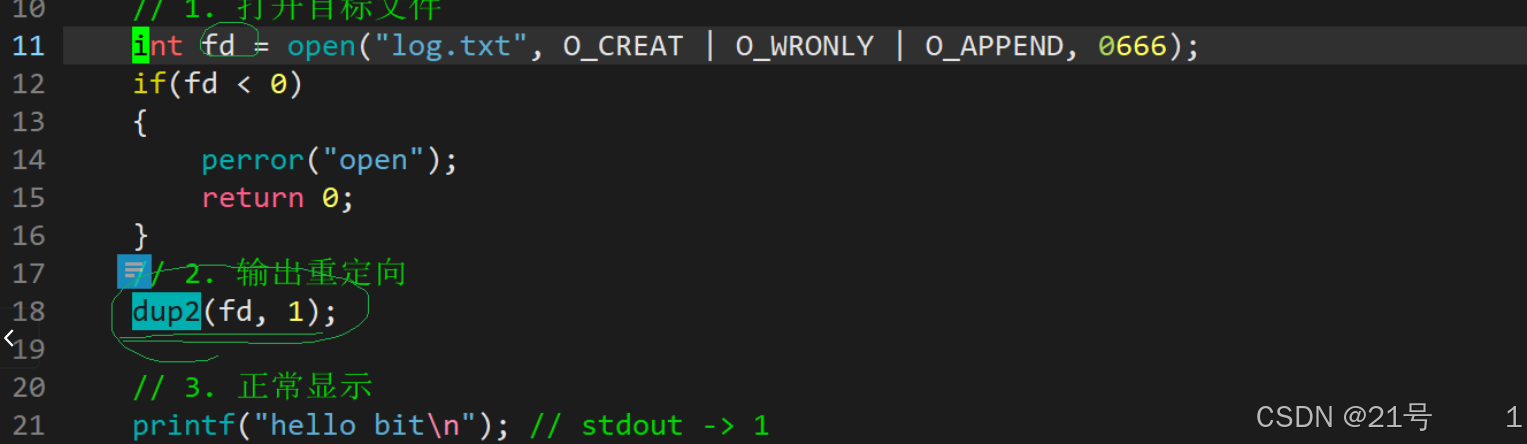
*3.4.4 使用 dup2 系统调用(还得写)
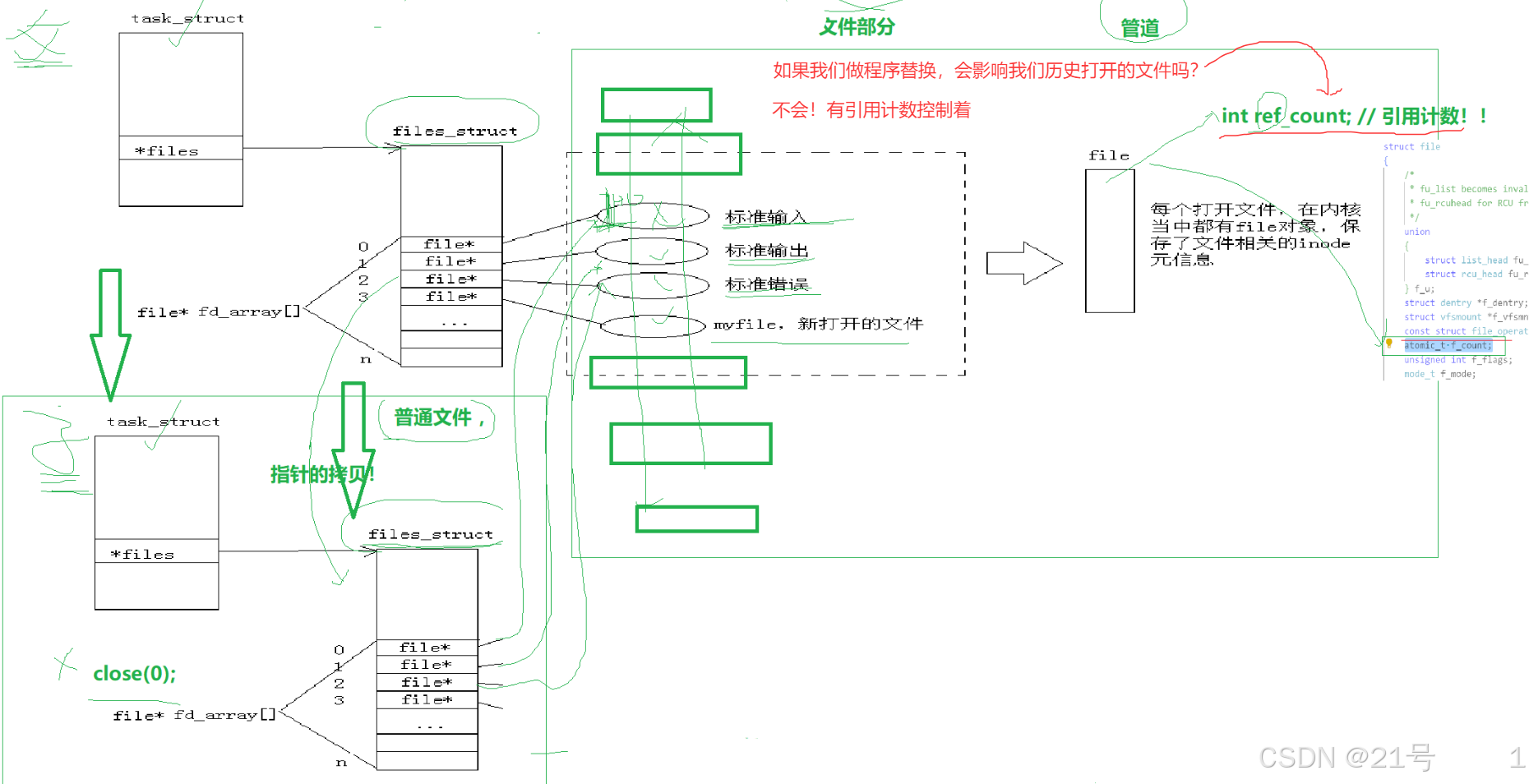
 所以我们有了重定向的概念和本质理解,那么我们创建子进程,子进程是如何看待父进程打开的文件的?子进程会继承父进程的PCB,并对文件描述符表(files_struct)进行指针的拷贝(就是浅拷贝,指针指向的仍是父进程的files_struct), 所以,父子printf的时候,会同时向同一个显示器文件打印。
所以我们有了重定向的概念和本质理解,那么我们创建子进程,子进程是如何看待父进程打开的文件的?子进程会继承父进程的PCB,并对文件描述符表(files_struct)进行指针的拷贝(就是浅拷贝,指针指向的仍是父进程的files_struct), 所以,父子printf的时候,会同时向同一个显示器文件打印。
那么对于子进程来讲,它有没有自己打开0,1,2呢?->事实上子进程默认打开了标准输入,标准输出,标准错误。->所以它是通过父进程继承下来的->父进程本来就是打开的。
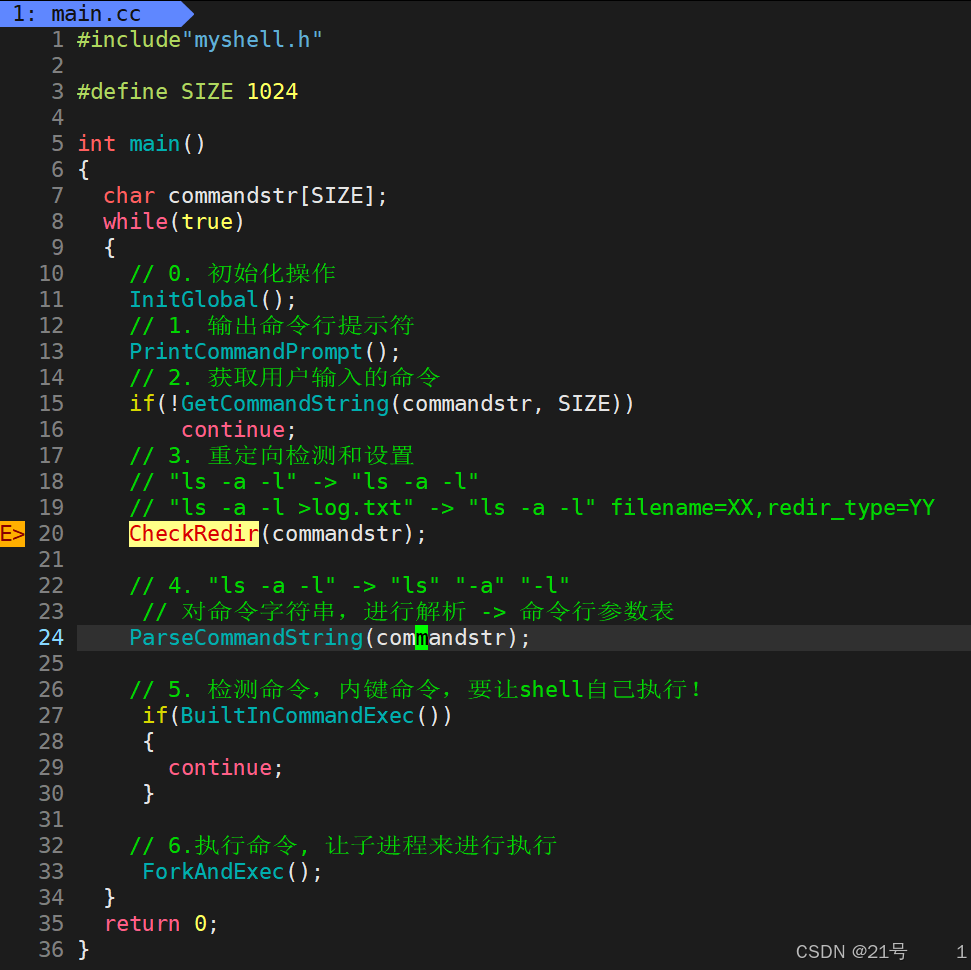
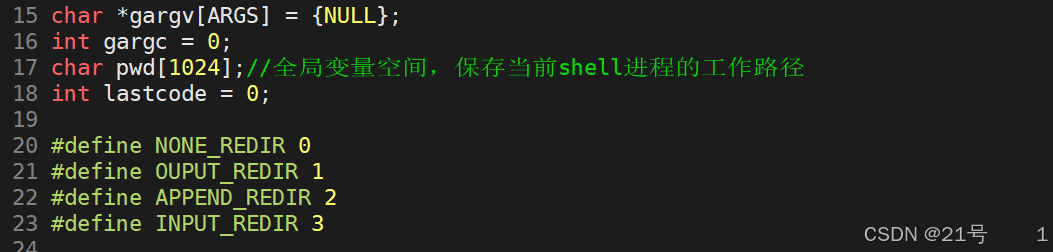
*3.4.5 在myshell中添加重定向功能
4.理解一切皆文件
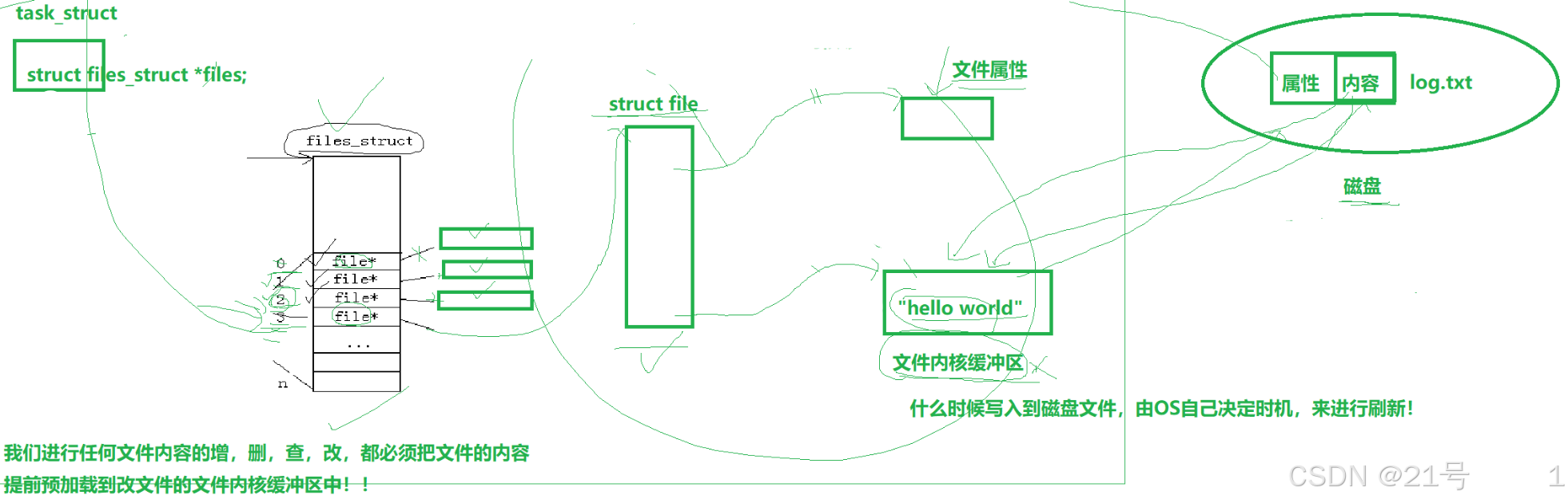
一切皆文件!是站在进程的视角,在struct file结构体之上,看待文件的视角!!
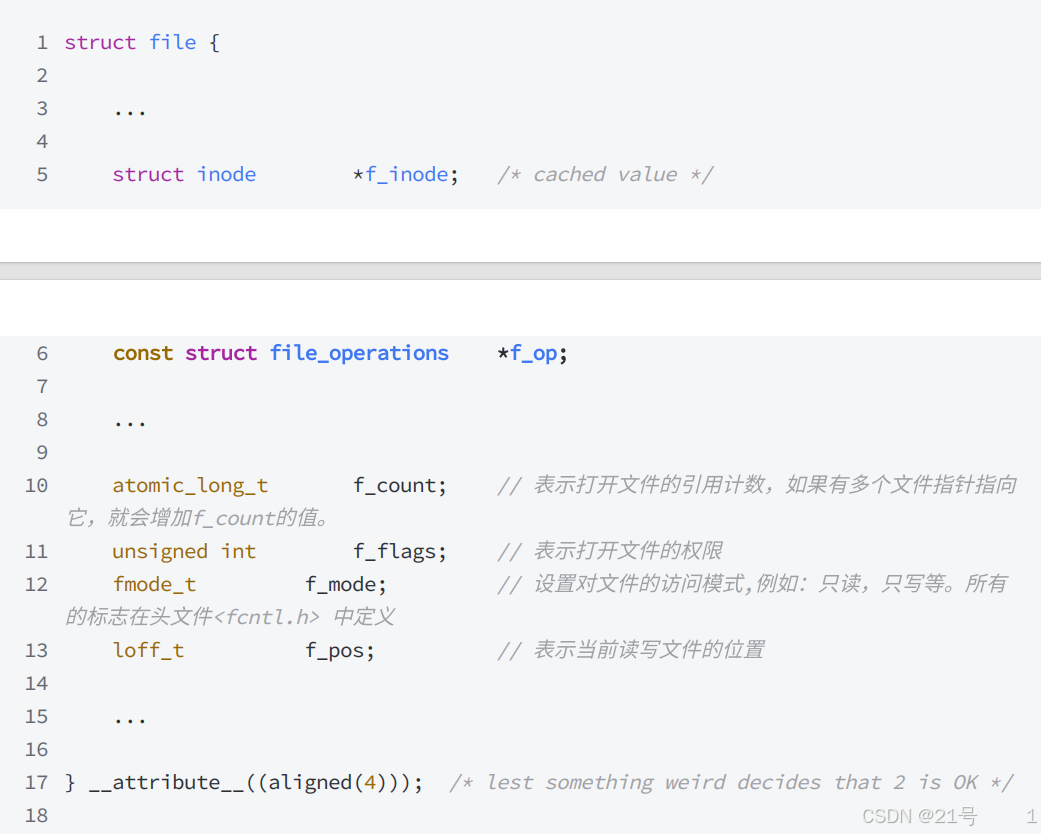
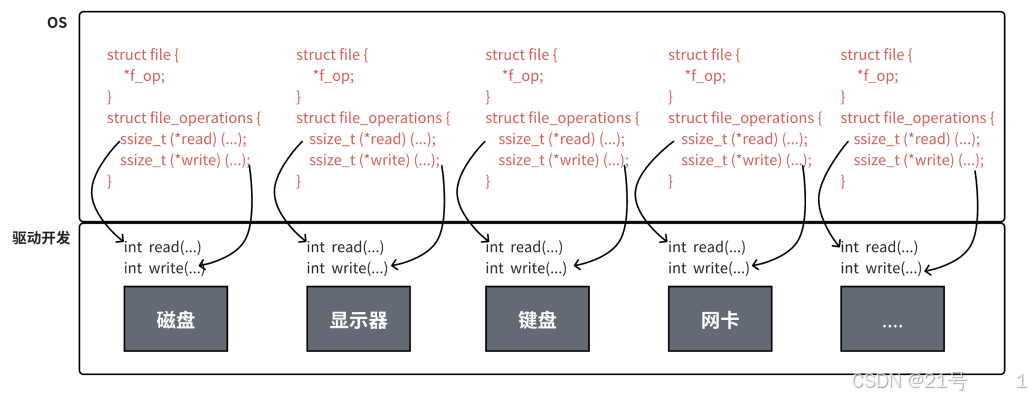
Linux中,打开文件,要为我们创建struct file,三个核心:
1.文件属性
2.文件内核缓冲区
3.底层设备文件的操作表5.缓冲区
5.1什么是缓冲区
5.2为什么要引入缓冲区机制
总结:缓存最大的意义(可以把他想象成菜鸟驿站)
1.提高使用缓存的进程的效率->允许进程单位时间内,做更多的工作2.允许数据,在缓冲区中积压,以一次,就可以刷新多次数据,变相的减少IO次数5.3缓冲类型
1.全缓冲区:这种缓冲⽅式要求填满整个缓冲区后才进⾏I/O系统调⽤操作。对于磁盘⽂件的操作通
常使⽤全缓冲的⽅式访问。2.⾏缓冲区:在⾏缓冲情况下,当在输⼊和输出中遇到换⾏符时,标准I/O库函数将会执⾏系统调⽤
操作。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使⽤⾏缓冲⽅式。因为标准
I/O库每⾏的缓冲区⻓度是固定的,所以只要填满了缓冲区,即使还没有遇到换⾏符,也会执⾏
I/O系统调⽤操作,默认⾏缓冲区的⼤⼩为1024。3.⽆缓冲区:⽆缓冲区是指标准I/O库不对字符进⾏缓存,直接调⽤系统调⽤。标准出错流stderr通
常是不带缓冲区的,这使得出错信息能够尽快地显⽰出来。除了上述列举的默认刷新⽅式,下列特殊情况也会引发缓冲区的刷新:
1. 缓冲区满时;
2. 执⾏flush语句;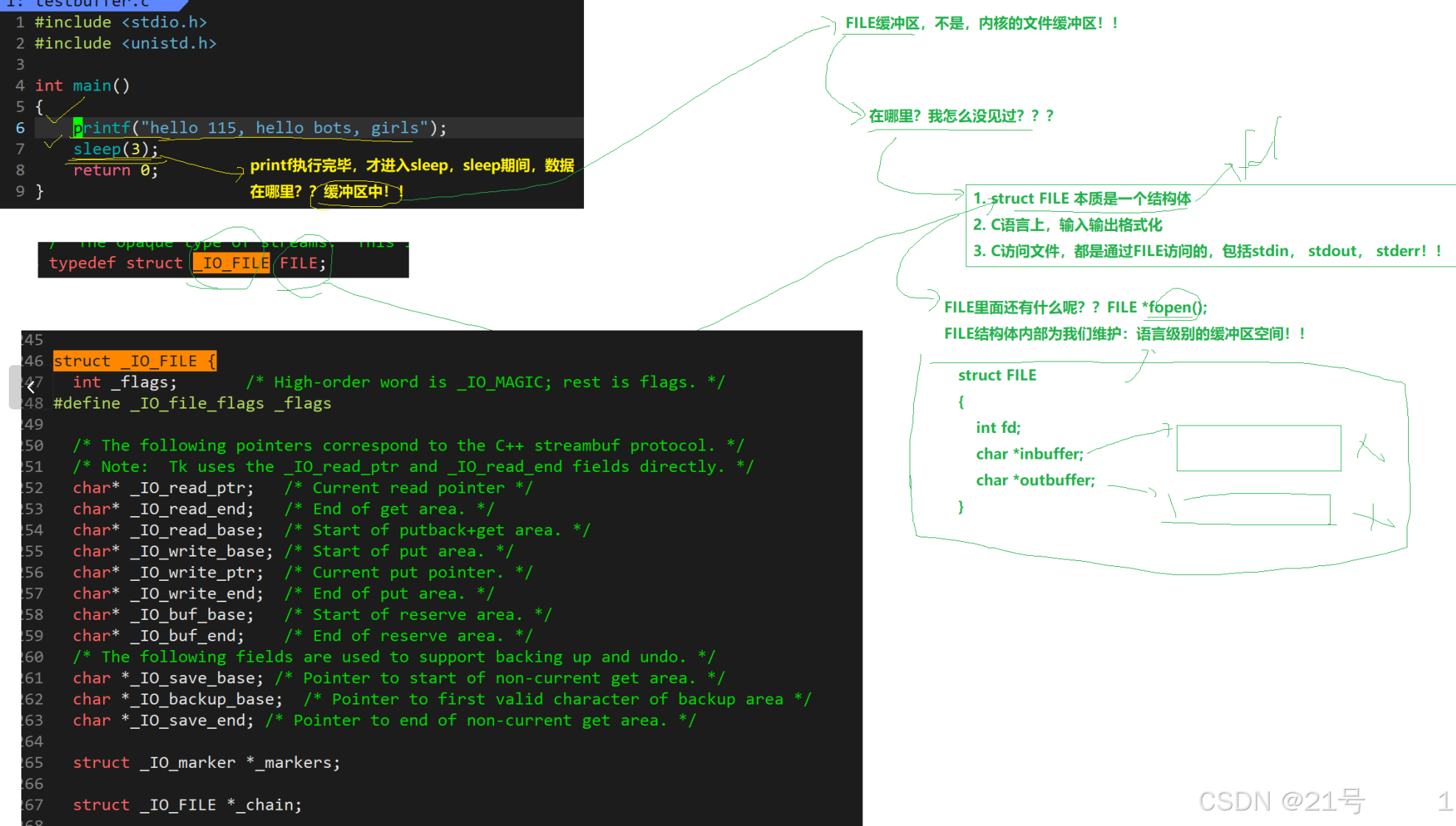
1.我们之前所说的缓冲区,全是语言级缓冲区,和内核没有关系。
2.缓冲区在哪?->FILE内部。
3.为什么要有语言级别的缓冲区?->系统调用有成本(浪费时间)->减少系统调用次数。
4.重新理解一下printf,scanf的格式化过程:printf("%d", a); ->格式化到哪里了?-> 格式化结果写入FILE缓冲区中- > 检测是否要刷新 -> write(3, outbuffer);
也就是说有语言级缓冲区,还有一个系统级缓冲区(一般而言:全缓冲;显示器:行刷新),我们平时写的会先放入语言级缓冲区,满足一定条件后才会转入系统级缓冲区
内核关于文件缓冲区的刷新方式:一般而言全缓冲;显示器,行刷新。-》但有单独的执行流,根据内存的使用情况来动态刷新,即便刷新条件不满足。

*5.4FILE
正常有\n应该是按行刷新(往显示器上写),但是,现在是往文件里重定向,所以他在底层进行了刷新策略的隐式调整-》变为全缓冲!!!
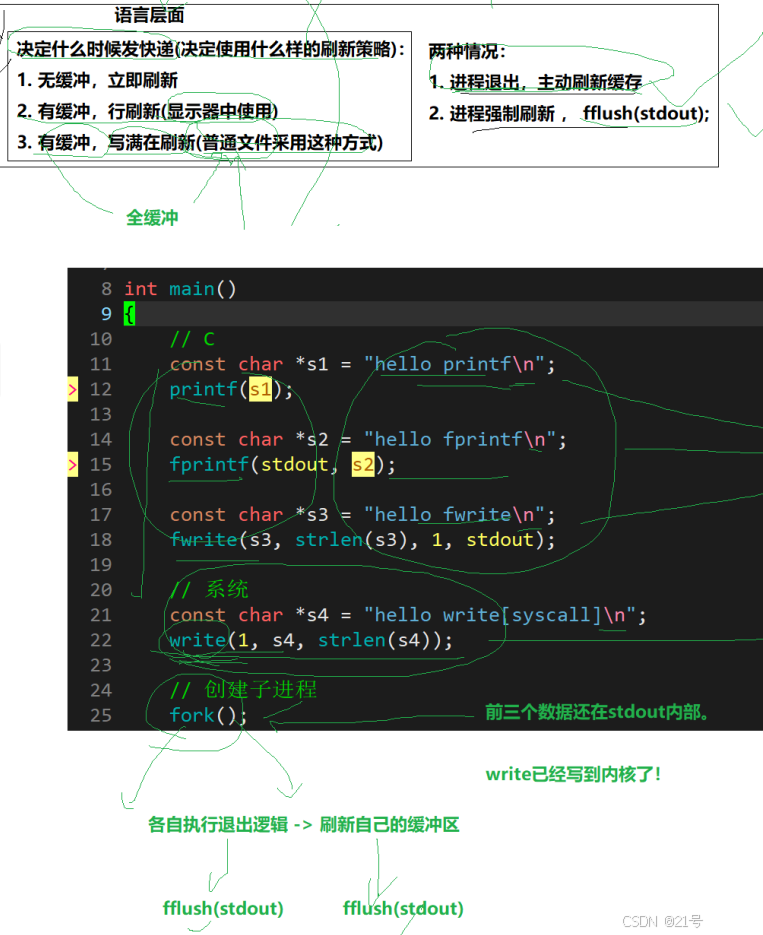
正常fork结束后不应该清空缓冲区吗?为什么还会刷新两次?清空缓冲区就是对数据修改-》写实拷贝666
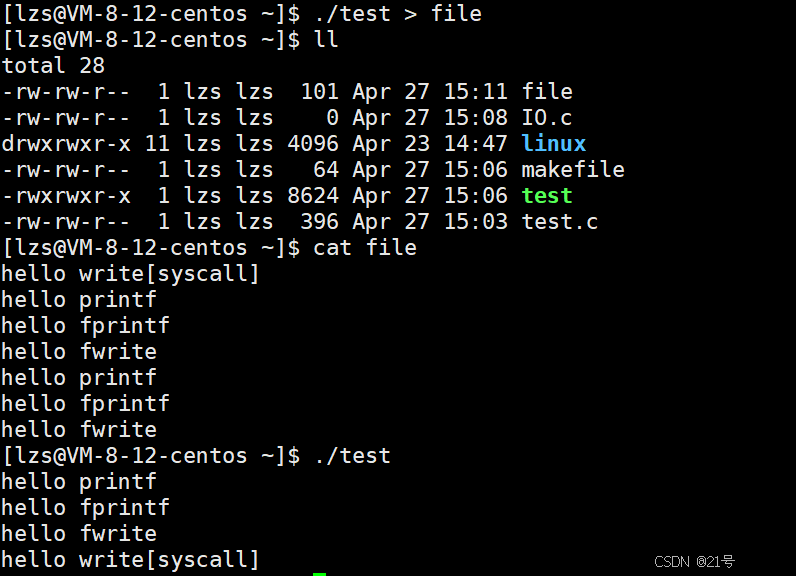
• ⼀般C库函数写⼊⽂件时是全缓冲的,⽽写⼊显⽰器是⾏缓冲。
• printf fwrite 库函数+会⾃带缓冲区(进度条例⼦就可以说明),当发⽣重定向到普通⽂
件时,数据的缓冲⽅式由⾏缓冲变成了全缓冲。
• ⽽我们放在缓冲区中的数据,就不会被⽴即刷新,甚⾄fork之后
• 但是进程退出之后,会统⼀刷新,写⼊⽂件当中。
• 但是fork的时候,⽗⼦数据会发⽣写时拷⻉,所以当你⽗进程准备刷新的时候,⼦进程也就有了
同样的⼀份数据,随即产⽣两份数据。
• write 没有变化,说明没有所谓的缓冲。所以重定向那份结果,是父/子结束一次刷新一次缓冲区,导致有两份重复的代码。
为什么要存在perror,std::cerr? 为了让正常输出和错误输出进行分离
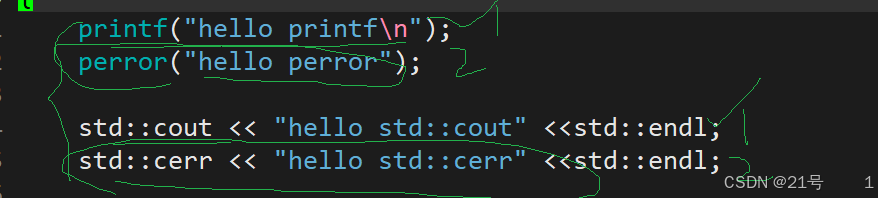
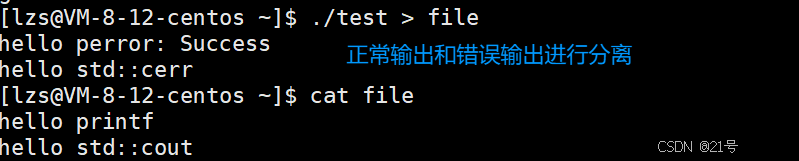
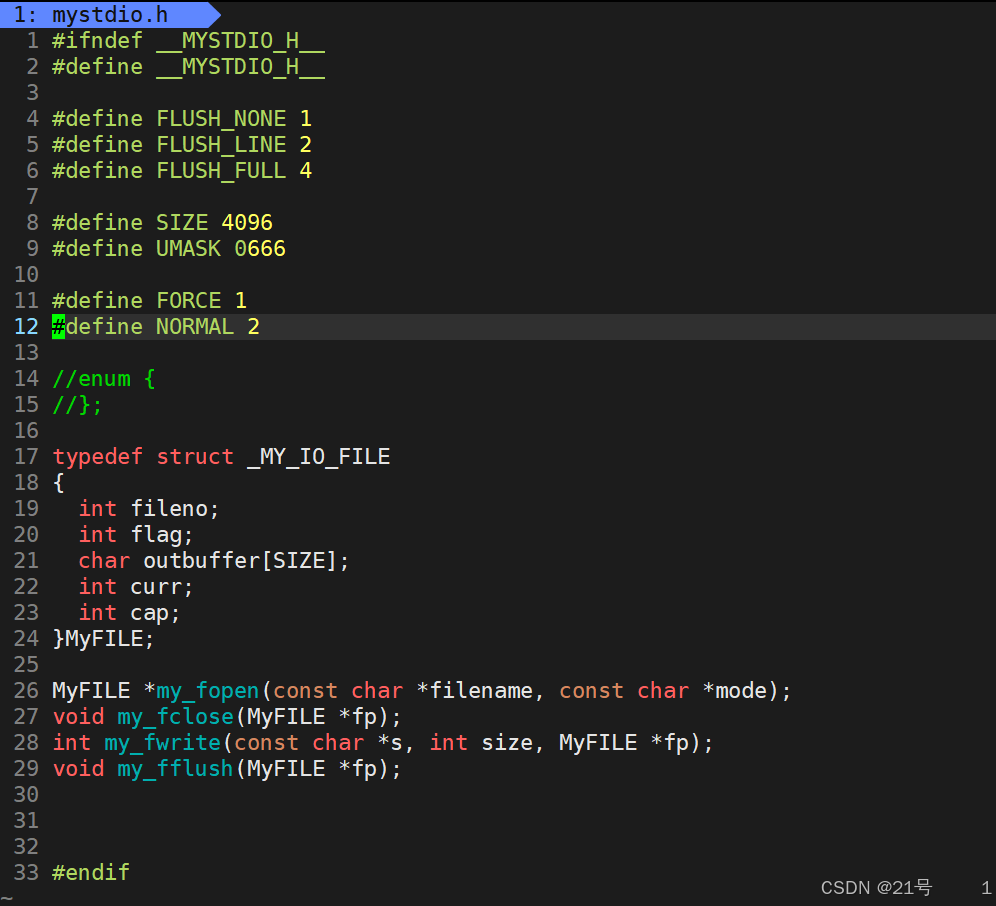
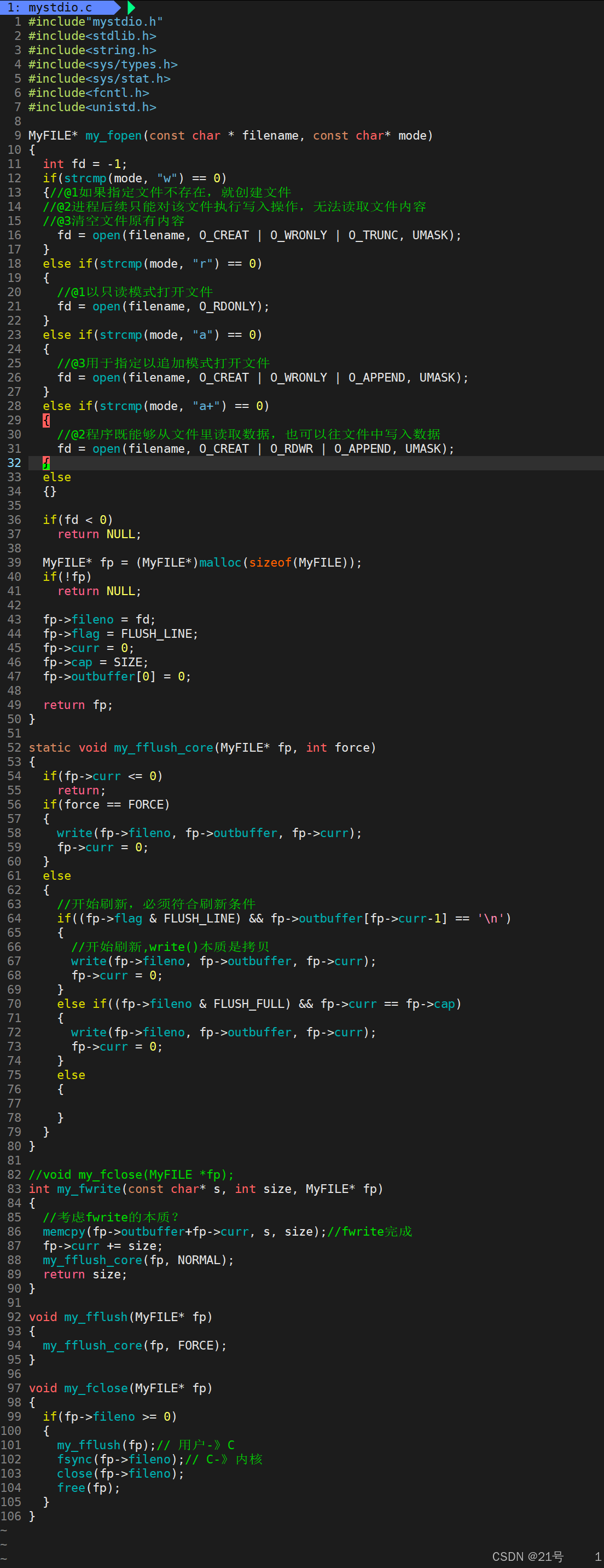
5.5简单设计一下libc库










![对于python中“FileNotFoundError: [Errno 2] No such file or directory”的解决办法](https://i-blog.csdnimg.cn/blog_migrate/a8be912159d2b6ebe42af15a795b7131.png#pic_center)