scrapy练习
文章目录
- scrapy练习
- 一、scrapy安装
- 二、scrapy基本流程
- 2.1 学习目标
- 2.2 创建一个新项目
- 2.3 创建Item
- 2.4 解析 Response
- 2.5 使用 Item
- 2.6 开始爬取
- 三、爬取多页
- 3.1 练习
- 3.2 输出格式
- 3.3 使用 Item Pipeline
- 暂时到这

一、scrapy安装
官网:https://www.scrapy.org/
官方文档:https://docs.scrapy.org/en/latest/
首先创建一个新环境:
conda create -n pachong python==3.10
#激活环境
conda activate pachong
我用的是官方文档提供的conda下载指令:
conda install -c conda-forge scrapy
二、scrapy基本流程
2.1 学习目标
1.创建一个 Scrapy 项目,熟悉 Scrapy 项目的创建流程。
2.编写一个 Spider 来抓取站点和处理数据,了解 Spider 的基本用法。
3.初步了解 Item Pipeline 的功能,将抓取的内容保存到 MongoDB 数据库。
4.运行 Scrapy 爬虫项目,了解 Scrapy 项目的运行流程。
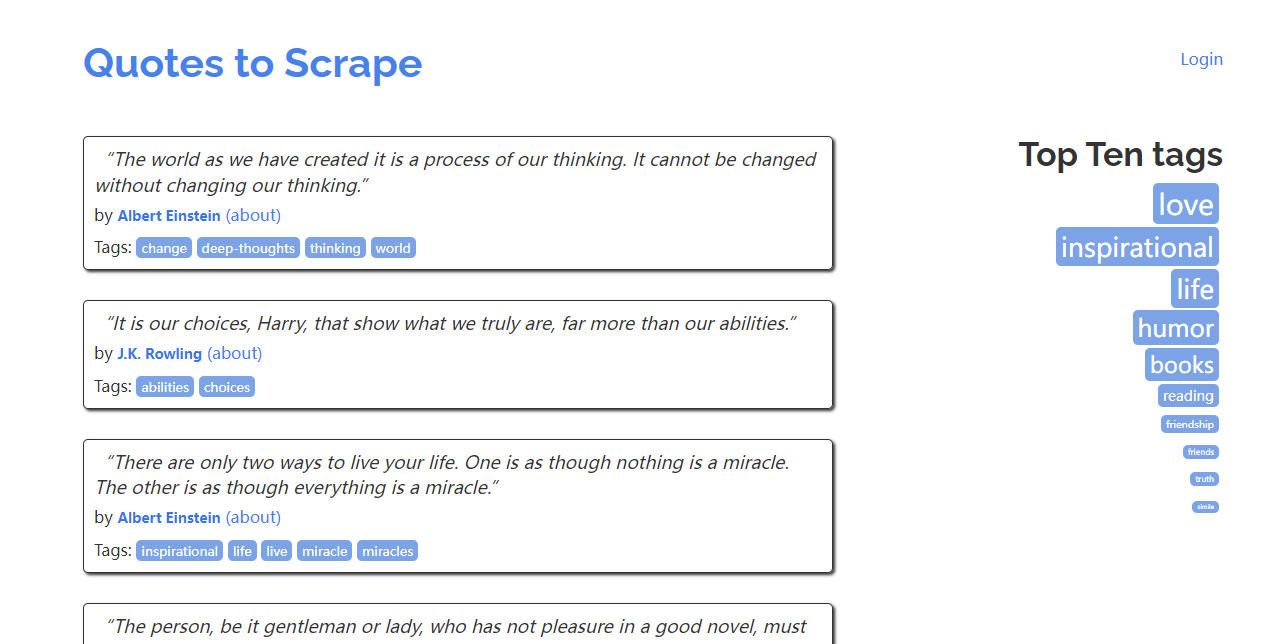
以 Scrapy 官方推荐的练习项目为例进行实战演练,抓取的目标站点为:https://quotes.toscrape.com/,页面如下图所示:
这个站点包含了一系列名人名言、作者和标签,我们需要使用 Scrapy 将其中的内容爬取并保存下来。
2.2 创建一个新项目
scrapy startproject ScrapyQuotes
运行完毕后,当前文件夹下会生成一个名为 ScrapyQuotes 的文件夹:

创建 Spider: Spider 是自己定义的类,Scrapy 用它来从网页里抓取内容,并解析抓取结果。不过这个类必须继承 Scrapy 提供的 Spider 类 scrapy.Spider,还要定义 Spider 的名称和起始 Request,以及怎样处理爬取后的结果的方法。也可以使用命令行创建一个 Spider,比如要生成 Quotes 这个 Spider,可以执行如下命令:

scrapy genspider quotes https://quotes.toscrape.com/
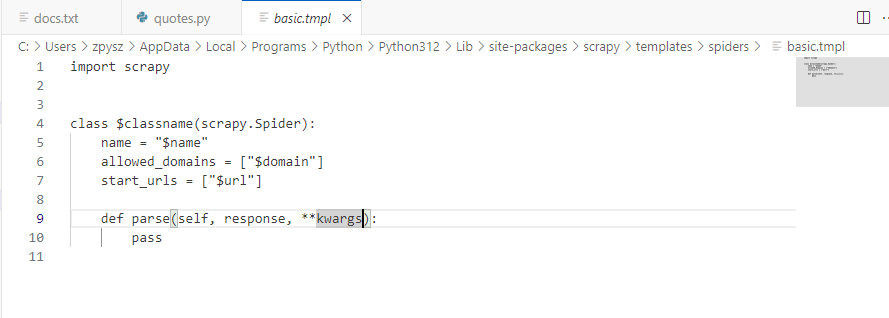
spiders 文件夹中多了一个 quotes.py,它就是刚刚创建的 Spider,内容如下所示:
import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com/"]def parse(self, response, **kwargs):pass'''name: 是每个项目唯一的名字,用来区分不同的 Spider
allowed_domains: 是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉
start_urls: 包含了 Spider 在启动时爬取的 URL 列表,初始请求是由它来定义的
parse: Spider 的一个方法。在默认情况下,start_urls 里面的链接构成的请求完成下载后,parse 方法就会被调用,返回的响应就会作
为唯一的参数传递给 parse 方法。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
'''
修改配置文件,不然生成的quotes.py文件没有这个参数==**kwargs==,或者手动在quotes.py文件里加上
2.3 创建Item
Item 是保存爬取数据的容器,定义了爬取结果的数据结构。它的使用方法和字典类似。不过相比字典,Item 多了额外的保护机制,可以避免拼写错误或者定义字段错误。创建 Item 需要继承 scrapy 的 Item 类,并且定义类型为 Field 的字段,这个字段就是我们要爬取的字段。
观察目标网站,我们可以获取到的内容有下面几项:
text: 文本,即每条名言的内容,是一个字符串
author: 作者,即每条名言的作者,是一个字符串
tags: 标签,即每条名言的标签,是字符串组成的列表
这样的话,每条爬取数据就包含这3个字段,那么我们就可以定义对应的 Item,此时将 items.py 修改如下:
这里我们声明了 ScrapyQuotesItem,继承了 Item 类,然后使用 Field 定义了3个字段,爬取时我们就会用到这个 Item
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy#
class ScrapyQuotesItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()text = scrapy.Field() # 每条名言的内容author = scrapy.Field() # 作者tags = scrapy.Field() # 标签2.4 解析 Response
关于 Response 更详细的解释可以参考官方文档:https://docs.scrapy.org/en/latest/topics/request-response.html#response-objects
# ① url:Request URL
# ② status:Response 状态码,一般情况下请求成功状态码为200
# ③ headers:Response Headers,是一个字典,字段是一一对应的
# ④ body:Response Body,这个通常就是访问页面之后得到的源代码结果了,比如里面包含的是HTML或者JSON字符串,但注意其结果是
# bytes 类型。与requests模块请求后得到的响应属性content类似
# ⑤ request:Response 对应的 Request 对象
# ⑥ certificate:是twisted.internet.ssl.Certifucate类型的对象,通常代表一个SSL证书对象
# ⑦ ip_address:是一个ipaddress.IPv4Address或IPv6Address类型的对象,代表服务器的IP地址
# ⑧ urljoin:是对URL的一个处理方法,可以传入当前页面的相对URL,该方法处理后返回的就是绝对URL
# urljoin 其实使用的就是: from urllib.parse import urljoin 可以去看源码
# ⑨ follow/follow_all:是一个根据URL来生成后续Request的方法,和直接构造Request不同的是,该方法接收的url可以是相对URL,不必
# 一定是绝对URL,因为follow方法中有做url拼接的操作,源码如下:
if isinstance(url, Link):url = url.url
elif url is None:raise ValueError("url can't be None")
url = self.urljoin(url)# ① text: 同body属性,但结果是str类型
# ② encoding: Response的编码,默认是utf-8
# ③ selector: 根据Response的内容构造而成的Selector对象,利用它我们可以进一步调用xpath、css等方法进行结果的提取
# ④ xpath()方法: 传入XPath进行内容提取,等同于调用selector的xpath方法
# ⑤ css()方法: 传入CSS选择器进行内容提取,等同于调用selector的css方法
# ⑥ json()方法: 是Scrapy2.2新增的方法,利用该方法可以直接将text属性转换为JSON对象,本质其实使用的就是json.loads,源码如下:
if self._cached_decoded_json is _NONE:self._cached_decoded_json = json.loads(self.body)
return self._cached_decoded_json改写quotes.py的parse函数
class QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com/"]
'''
这里首先利用 CSS 选择器选取所有的 quote 并将其赋值为 quotes 变量,然后利用 for 循环遍历每个 quote,
解析每个 quote 的内容。单独调用 css 方法我们得到的是 Selector 对象组成的列表;调用 extract 方法会进
一步从 Selector 对象里提取其内容,再加上 ::text 则会从 HTML 代码中提取出正文文本。因此对于 text,我
们只需要获取结果的第一个元素即可,所以使用 extract_first 方法,得到的就是一个字符串。而对于 tags,
我们想要获取所有结果组成的列表,所以使用 extract 方法,得到的就是所有标签字符串组成的列表。
'''def parse(self, response, **kwargs):quotes = response.css("div.quote")for quote in quotes:text = quote.css("span.text::text").extract_first("")author = quote.css("small.author::text").extract_first("")tags = quote.css("div.tags a.tag::text").extract()
2.5 使用 Item
之前已经定义好了 ScrapyQuotesItem,接下来就要使用它了。我们可以把 Item 理解为一个字典,和字典还不太相同,其本质是一个类,所以在使用的时候需要实例化。实例化之后,我们依次用刚才解析的结果赋值 Item 的每一个字段,最后将 Item 返回。QuotesSpider 的改写如下所示:
from ScrapyQuotes.ScrapyQuotes.items import ScrapyQuotesItem
import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com/"]def parse(self, response, **kwargs):quotes = response.css("div.quote")for quote in quotes:item = ScrapyQuotesItem()item["text"] = quote.css("span.text::text").extract_first("")item["author"] = quote.css("small.author::text").extract_first("")item["tags"] = quote.css("div.tags a.tag::text").extract()yield item
2.6 开始爬取
首先使用cd命令转到当前文件夹
cd C:\Users\zpysz\Desktop\pythonproject\scrapy_pachong\ScrapyQuotes
运行下面的指令,会把爬取结果存放在quotes.json文件夹里
scrapy crawl quotes -o quotes.json

三、爬取多页
3.1 练习
在第二章学习了爬取第一页内容,接下来学习爬取多页内容

这里发现有一个 Next 按钮,查看一下源代码,可以看到它的链接是 /page/2/,实际上全链接是 https://quotes.toscrape.com/page/2/,通过这个链接我们就可以构造下一个 Request 了。
接下来我们要做的就是利用选择器得到下一页链接并生成请求,在 parse 方法后追加如下的代码:
from ScrapyQuotes.items import ScrapyQuotesItem
import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com"]def parse(self, response, **kwargs):quotes = response.css("div.quote")for quote in quotes:item = ScrapyQuotesItem()item["text"] = quote.css("span.text::text").extract_first("")item["author"] = quote.css("small.author::text").extract_first("")item["tags"] = quote.css("div.tags a.tag::text").extract()yield itemhref = response.css("li.next a::attr(href)").extract_first("")next_url = response.urljoin(href)yield scrapy.Request(url=next_url, callback=self.parse)
运行
scrapy crawl quotes -o quotes.json
3.2 输出格式
Feed Exports 支持输出的格式还有很多,例如 csv、xml、pickle、marshal 等,同时它支持 ftp、s3 等远程输出,另外还可以通过自定义 ItemExporter 来实现其他的输出。例如,下面命令对应的输出分别为 csv、xml、pickle、marshal 格式以及 ftp 远程输出:
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csv
3.3 使用 Item Pipeline
清洗 HTML 数据
验证爬取数据,检查爬取字段
查重并丢弃重复内容
将爬取结果存储到数据库