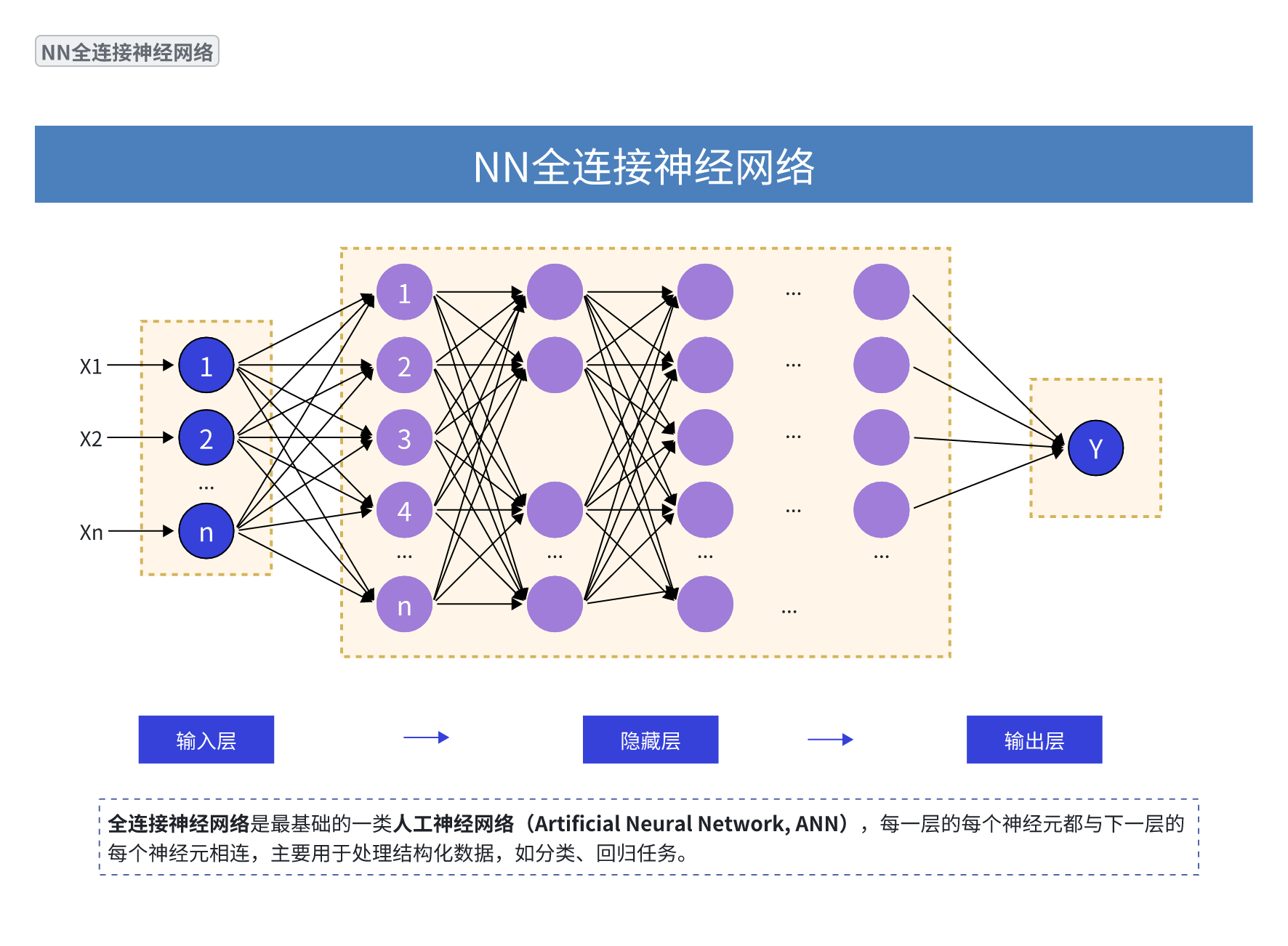
Yolov8改进 C2f中添加注意力机制代码 包括SE、CA、CBAM、MHSA等)的具体实现代码,以及如何将这些模块集成到YOLOv8模型中的示例。
文章目录
- 1. **Channel Attention (CA)**
- 2. **Spatial Attention (SA)**
- 3. **CBAM (Convolutional Block Attention Module)**
- 4. **SE (Squeeze and Excitation)**
- 5. **MHSA (Multi-Head Self-Attention)**
- 6. **Triplet Attention**
- 2. **Channel Attention (CA) 模块**
- 3. **CBAM (Convolutional Block Attention Module)**
- 4. **MHSA (Multi-Head Self-Attention)**
- 集成到C2f模块中
- 将其集成到YOLOv8模型中
为了在YOLOv8的C2f模块中添加不同的注意力机制,我们需要定义这些注意力机制并在C2f模块中集成它。以下是具体的代码实现:
文章代码仅供参考。
1. Channel Attention (CA)
import torch
import torch.nn as nnclass ChannelAttention(nn.Module):def __init__(self, in_channels, reduction=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(in_channels // reduction, in_channels, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)class C2f_CA(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super(C2f_CA, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1, 1)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])self.ca = ChannelAttention(c2)def forward(self, x):return self.ca(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)))
2. Spatial Attention (SA)
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size % 2 == 1, "Kernel size must be odd"self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size // 2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)x = self.conv(x)return x * self.sigmoid(x)class C2f_SA(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super(C2f_SA, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1, 1)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])self.sa = SpatialAttention()def forward(self, x):return self.sa(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)))
3. CBAM (Convolutional Block Attention Module)
class CBAM(nn.Module):def __init__(self, in_channels, reduction=16, kernel_size=7):super(CBAM, self).__init__()self.ca = ChannelAttention(in_channels, reduction)self.sa = SpatialAttention(kernel_size)def forward(self, x):out = self.ca(x)out = self.sa(out)return outclass C2f_CBAM(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super(C2f_CBAM, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1, 1)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])self.cbam = CBAM(c2)def forward(self, x):return self.cbam(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)))
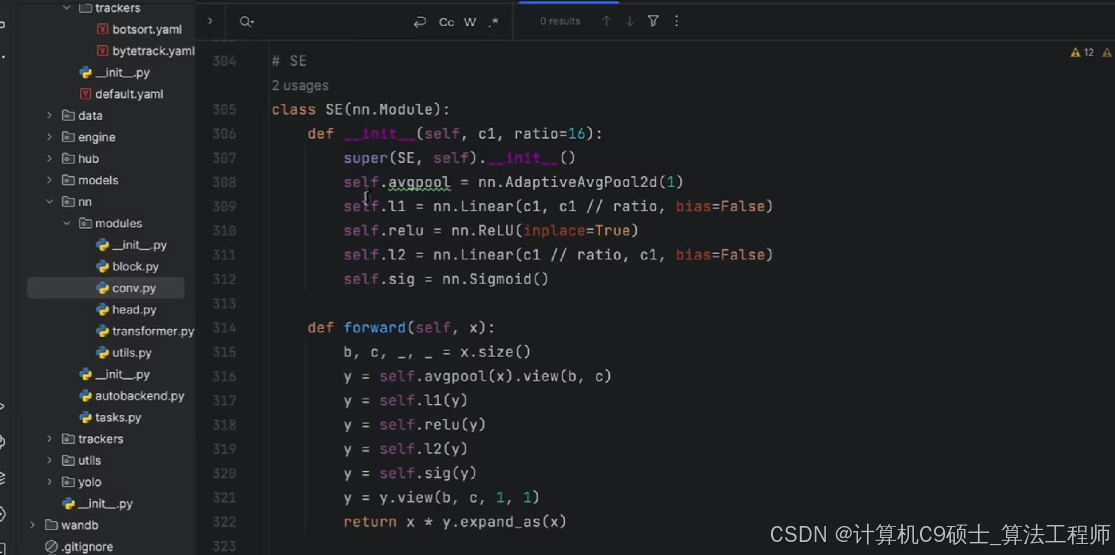
4. SE (Squeeze and Excitation)
class SELayer(nn.Module):def __init__(self, channel, reduction=16):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)class C2f_SE(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super(C2f_SE, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1, 1)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])self.se = SELayer(c2)def forward(self, x):return self.se(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)))
5. MHSA (Multi-Head Self-Attention)
class MHSA(nn.Module):def __init__(self, in_channels, num_heads=8):super(MHSA, self).__init__()self.num_heads = num_headsself.head_dim = in_channels // num_headsself.qkv = nn.Linear(in_channels, in_channels * 3, bias=False)self.out_proj = nn.Linear(in_channels, in_channels)def forward(self, x):B, C, H, W = x.shapeqkv = self.qkv(x.flatten(start_dim=2)).reshape(B, 3, self.num_heads, -1, self.head_dim)q, k, v = qkv.unbind(1)attn = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5)attn = attn.softmax(dim=-1)x = (attn @ v).transpose(1, 2).reshape(B, C, H, W)return self.out_proj(x)class C2f_MHSA(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super(C2f_MHSA, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1, 1)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])self.mhsa = MHSA(c2)def forward(self, x):return self.mhsa(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)))
6. Triplet Attention
class TripletAttention(nn.Module):def __init__(self, in_channels, reduction=16):super(TripletAttention, self).__init__()self.channel_attention = ChannelAttention(in_channels, reduction)self.spatial_attention = SpatialAttention()self.depth_attention = DepthwiseAttention(in_channels)def forward(self, x):ca = self.channel_attention(x)sa = self.spatial_attention(x)da = self.depth_attention(x)return x * (ca + sa + da)class DepthwiseAttention(nn.Module):def __init__(self, in_channels):super(DepthwiseAttention, self).__init__()self.dw_conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, groups=in_channels)self.bn = nn.BatchNorm2d(in_channels)self.relu = nn.ReLU(inplace=True)def forward(self, x):
C2f中添加注意力机制代码
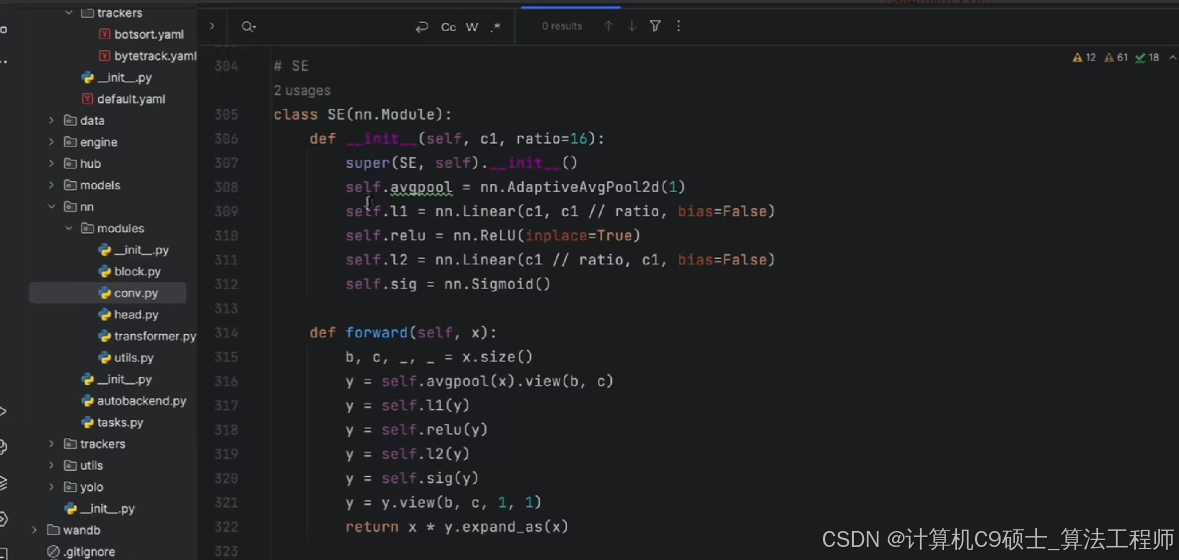
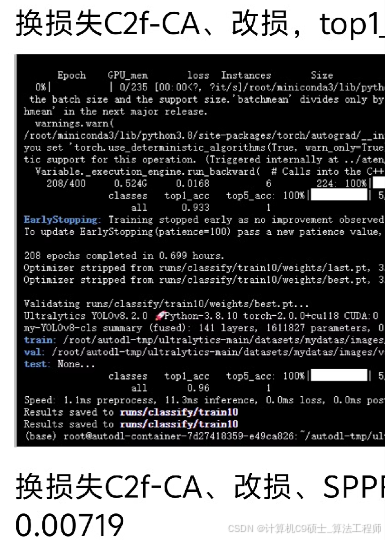
当然可以。以下是针对YOLOv8的C2f模块中添加注意力机制(包括SE、CA、CBAM、MHSA等)的具体实现代码,以及如何将这些模块集成到YOLOv8模型中的示例。### 1. **SE (Squeeze and Excitation) 模块**首先定义SE模块:```python
import torch
import torch.nn as nnclass SE(nn.Module):def __init__(self, c1, ratio=16):super(SE, self).__init__()self.avgpool = nn.AdaptiveAvgPool2d(1)self.fc1 = nn.Linear(c1, c1 // ratio, bias=False)self.relu = nn.ReLU(inplace=True)self.fc2 = nn.Linear(c1 // ratio, c1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):b, c, _, _ = x.size()y = self.avgpool(x).view(b, c)y = self.fc1(y)y = self.relu(y)y = self.fc2(y)y = self.sigmoid(y)y = y.view(b, c, 1, 1)return x * y.expand_as(x)
2. Channel Attention (CA) 模块
接下来是通道注意力模块:
class ChannelAttention(nn.Module):def __init__(self, in_channels, reduction=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(in_channels // reduction, in_channels, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)
3. CBAM (Convolutional Block Attention Module)
然后是CBAM模块,结合了通道和空间注意力:
class CBAM(nn.Module):def __init__(self, in_channels, reduction=16, kernel_size=7):super(CBAM, self).__init__()self.ca = ChannelAttention(in_channels, reduction)self.sa = SpatialAttention(kernel_size)def forward(self, x):out = self.ca(x)out = self.sa(out)return out
其中SpatialAttention的实现如下:
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size % 2 == 1, "Kernel size must be odd"self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size // 2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)x = self.conv(x)return x * self.sigmoid(x)
4. MHSA (Multi-Head Self-Attention)
最后是多头自注意力机制:
class MHSA(nn.Module):def __init__(self, in_channels, num_heads=8):super(MHSA, self).__init__()self.num_heads = num_headsself.head_dim = in_channels // num_headsself.qkv = nn.Linear(in_channels, in_channels * 3, bias=False)self.out_proj = nn.Linear(in_channels, in_channels)def forward(self, x):B, C, H, W = x.shapeqkv = self.qkv(x.flatten(start_dim=2)).reshape(B, 3, self.num_heads, -1, self.head_dim)q, k, v = qkv.unbind(1)attn = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5)attn = attn.softmax(dim=-1)x = (attn @ v).transpose(1, 2).reshape(B, C, H, W)return self.out_proj(x)
集成到C2f模块中
这里是如何在C2f模块中集成这些注意力机制的一个例子:
class C2f_SE(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super(C2f_SE, self).__init__()c_ = int(c2 * e) # 隐藏层通道数self.cv1 = nn.Conv2d(c1, c_, 1, 1)self.cv2 = nn.Conv2d(c1, c_, 1, 1)self.cv3 = nn.Conv2d(2 * c_, c2, 1, 1)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])self.se = SE(c2)def forward(self, x):return self.se(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)))
你可以在上述代码的基础上,根据需要替换或增加其他注意力机制模块(如ChannelAttention, CBAM, MHSA等),只需修改self.se为对应的注意力模块即可。
将其集成到YOLOv8模型中
要在YOLOv8模型中使用这个带有注意力机制的C2f模块,你需要在相应的网络架构文件中替换原有的C2f模块为新的实现。例如,在你的模型初始化部分,你可以这样使用:
class YOLOv8(nn.Module):def __init__(self):super(YOLOv8, self).__init__()self.c2f_se = C2f_SE(c1=64, c2=128, n=1) # 根据实际情况调整参数def forward(self, x):x = self.c2f_se(x)# 其他层...return x
请根据你的具体需求和模型结构进行适当的调整。希望这些代码能帮助你在YOLOv8模型中成功添加注意力机制。