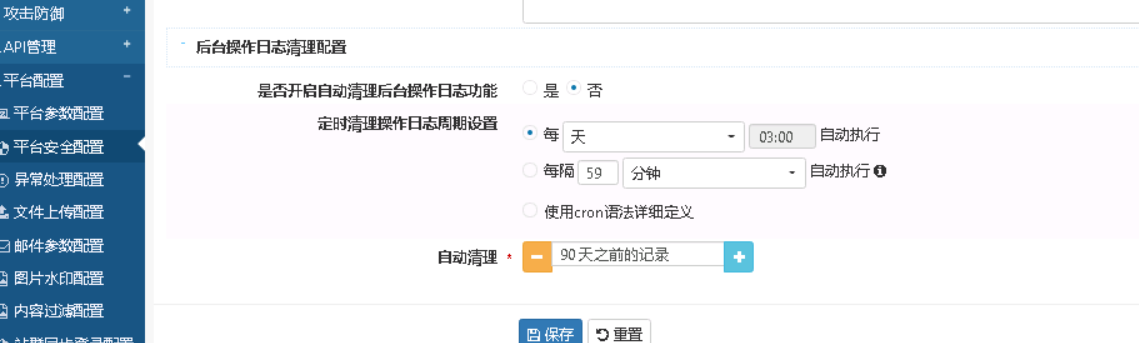
在 fastai 第一部分中,我们学习了如何对 MNIST 数据集进行分类。在本教程中,我们将更深入地了解其底层原理。首先,我们将详细探索 MNIST 数据集。
数据探索
# 第一部分的代码
import torch
import random
from fastai.vision.all import *# 下载简单的 MNIST 数据集(稍后我们会下载完整数据集)
path = untar_data(URLs.MNIST_SAMPLE)
train_path = path/'train'
img_files = list((train_path/'7').ls())
img = PILImage.create(img_files[0])
img.show();

print(f"图像模式为: {img.mode}")
图像模式为: RGB
MNIST 图像本是灰度(单通道),但通过 PILImage 创建后会被转换为 RGB,这通常是为了模型兼容性。因此如上所示,图像模式为 RGB。灰度图像的模式应为 “L”(1 通道),而 RGB 为 3 通道。如果你想保持灰度,可以这样:
img = PILImage.create(img_files[0])
img.show();
print(f"图像模式为: {img.mode}")
arr = array(img)
print(arr.shape)
(28, 28, 3)
(28, 28, 3) 是一个三维 NumPy 数组,表示高、宽和通道数。28x28 像素,3 表示 RGB 通道。由于原图为灰度,三个通道的值通常相同。
print(np.unique(arr))
[ 0 9 23 24 34 38 44 46 47 64 69 71 76 93 99 104 107 109111 115 128 137 138 139 145 146 149 151 154 161 168 174 176 180 184 185207 208 214 215 221 230 231 240 244 245 251 253 254 255]
np.unique(arr) 显示像素值范围为 0~255,0 为黑,255 为白,中间为灰度。
np.all(arr[:, :, 0] == arr[:, :, 1]) and np.all(arr[:, :, 1] == arr[:, :, 2])
np.True_
上面代码检查三个通道的像素值是否一致。由于是灰度图,结果为 True。
img_t = tensor(arr[:, :, 0])
print(img_t.shape)
df = pd.DataFrame(img_t)
df.style.set_properties(**{'font-size':'6pt'}).background_gradient('Greys')
torch.Size([28, 28])
在上述代码中:
arr[:,:,0] 是常见的三维数组索引方式,: 表示所有元素,0 表示第一个通道。
# 对比选择通道 0 与不选通道时的形状
print(arr[:,:,0].shape)
print(arr[:,:,:].shape)
(28, 28)
(28, 28, 3)
# 查看数组中的唯一值
print(np.unique(arr))
[ 0 9 23 24 34 38 44 46 47 64 69 71 76 93 99 104 107 109111 115 128 137 138 139 145 146 149 151 154 161 168 174 176 180 184 185207 208 214 215 221 230 231 240 244 245 251 253 254 255]
这些值就是你看到的数字 7 的灰度图像。计算机就是用这些数字存储图像!手写数字识别的任务本质上就是在数值层面上比较图像与参考数字的相似性。我们将所有图片转为数值向量,分别对 3 和 7 求平均向量,作为数字的代表。这就是"向量空间模型",也是我们模型的基线。之后用它来预测新图片,看其更像 3 还是 7。这是最简单直观的机器学习方法。注意我们将 NumPy 数组转为 tensor(img_t=tensor(arr[:,:,0])),因为 fastai 基于 PyTorch,后者的模型都以 torch.Tensor 为输入输出。Tensor 支持自动微分和 GPU 加速,而 NumPy 仅限 CPU。
tensor(arr).permute(2,0,1).shape
torch.Size([3, 28, 28])
上述代码将 NumPy 数组转为 PyTorch tensor,并调整维度顺序。原始为 (28, 28, 3),调整后为 (3, 28, 28),这是 PyTorch 期望的图像格式(通道,高,宽)。
基线图像
堆叠
torch.stack(seven_tensors):seven_tensors 是数字 7 的二维张量列表,每个张量为 [高, 宽](28x28)。堆叠后变为三维张量 [图片数, 高, 宽]。.mean(0) 沿第 0 维(图片数)求均值,得到一张平均 7 的图片。
# 查看 3 和 7 的图片
three_path = train_path/'3'
seven_path = train_path/'7'three_tensors = [tensor(Image.open(o)) for o in three_path.ls()]
seven_tensors = [tensor(Image.open(o)) for o in seven_path.ls()]# 堆叠所有 3 和 7
stacked_threes = torch.stack(three_tensors).float()/255
stacked_sevens = torch.stack(seven_tensors).float()/255# 计算所有 3 和 7 的均值
mean3 = stacked_threes.mean(0)
mean7 = stacked_sevens.mean(0)# 显示均值图片
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.imshow(mean3)
plt.title('3 的均值')
plt.subplot(1, 2, 2)
plt.imshow(mean7)
plt.title('7 的均值')
plt.tight_layout()

上述代码计算了所有 3 和 7 的均值。均值图片显示了该数字所有图片的平均像素值,给出了典型 3 和 7 的模板。
# 计算 3 和 7 的均值差异
diff = mean3 - mean7
plt.imshow(diff)

差异图片显示了两者差异最大的区域。亮区表示 3 的像素值高于 7,暗区则相反。
# 计算每个 3 与均值 3、均值 7 的相似度
three_similarity = [((t - mean3)**2).mean().item() for t in stacked_threes]
three_to_seven_similarity = [((t - mean7)**2).mean().item() for t in stacked_threes]# 计算每个 7 与均值 7、均值 3 的相似度
seven_similarity = [((t - mean7)**2).mean().item() for t in stacked_sevens]
seven_to_three_similarity = [((t - mean3)**2).mean().item() for t in stacked_sevens]# 绘制相似度
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(three_similarity, label='3 到均值 3')
plt.plot(three_to_seven_similarity, label='3 到均值 7')
plt.legend()
plt.title('3: 与均值 3 和 7 的相似度')plt.subplot(1, 2, 2)
plt.plot(seven_similarity, label='7 到均值 7')
plt.plot(seven_to_three_similarity, label='7 到均值 3')
plt.legend()
plt.title('7: 与均值 7 和 3 的相似度')
plt.tight_layout()

相似度计算
((tensor(Image.open(o)).float() - seven_avg)**2).mean() 计算图片 o 与平均 7 的均方误差(MSE),MSE 越低相似度越高。MSE 是衡量预测与实际差异的常用指标。
图示
- y 轴为 MSE。
- x 轴为图片索引。
- 可以看到每个 3 与均值 3 的 MSE 通常低于与均值 7。
在完整 MNIST 上训练神经网络
现在我们用完整的 MNIST 数据集训练神经网络。
# 下载完整 MNIST 数据集
path = untar_data(URLs.MNIST)
path

# 创建 DataBlock
mnist = DataBlock(blocks=(ImageBlock(cls=PILImageBW), CategoryBlock), get_items=get_image_files, splitter=GrandparentSplitter(train_name='training', valid_name='testing'),get_y=parent_label,batch_tfms=Normalize()
)
DataBlock
fastai 的 DataBlock 是数据处理的高级 API。它定义了数据获取、标签、变换、划分和输入输出类型。
blocks=(ImageBlock(cls=PILImageBW), CategoryBlock):输入为黑白图片,输出为类别。get_items=get_image_files:获取所有图片文件。splitter=GrandparentSplitter(train_name='training', valid_name='testing'):按上级文件夹划分训练/验证集。get_y=parent_label:标签为父文件夹名。batch_tfms=Normalize():归一化图片。
# 创建 DataLoaders
dls = mnist.dataloaders(path, bs=64)
# 显示一批图片
dls.show_batch(max_n=9, figsize=(4,4))

现在我们创建并训练一个卷积神经网络(CNN)用于数字分类。
# 自定义 MNIST CNN 模型
class MnistCNN(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2)self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2)self.conv3 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.relu3 = nn.ReLU()self.pool3 = nn.MaxPool2d(kernel_size=2)self.fc1 = nn.Linear(64 * 3 * 3, 128)self.relu4 = nn.ReLU()self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.pool1(self.relu1(self.conv1(x)))x = self.pool2(self.relu2(self.conv2(x)))x = self.pool3(self.relu3(self.conv3(x)))x = x.view(x.size(0), -1)x = self.relu4(self.fc1(x))x = self.fc2(x)return xmodel = MnistCNN()
learn = Learner(dls, model, loss_func=nn.CrossEntropyLoss(), metrics=accuracy)
print("模型结构:")
print(learn.model)
模型结构:
MnistCNN((conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu2): ReLU()(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu3): ReLU()(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(fc1): Linear(in_features=576, out_features=128, bias=True)(relu4): ReLU()(fc2): Linear(in_features=128, out_features=10, bias=True)
)
# 训练模型 1 轮
dls = mnist.dataloaders(path, bs=64)
learn = Learner(dls, model, loss_func=nn.CrossEntropyLoss(), metrics=accuracy)
learn.fine_tune(1)
模型评估
让我们在验证集上评估模型表现:
# 获取预测
preds, targets = learn.get_preds()
pred_classes = preds.argmax(dim=1)# 混淆矩阵
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as snscm = confusion_matrix(targets, pred_classes)
plt.figure(figsize=(5, 4))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('预测')
plt.ylabel('实际')
plt.title('混淆矩阵')
plt.show()

预测
用训练好的模型对测试图片进行预测:
# 获取测试图片
test_files = get_image_files(path/'testing')
random_test_files = random.sample(test_files, 10)
test_dl = learn.dls.test_dl(random_test_files)
# 预测
preds, _ = learn.get_preds(dl=test_dl)
pred_classes = preds.argmax(dim=1)
# 显示图片和预测
fig, axes = plt.subplots(2, 5, figsize=(6, 3))
axes = axes.flatten()
for i, (img_file, pred) in enumerate(zip(random_test_files, pred_classes)):img = PILImage.create(img_file)axes[i].imshow(img, cmap='gray')axes[i].set_title(f"预测: {pred.item()}")axes[i].axis('off')
plt.tight_layout()
plt.show()

与模板匹配法对比
前面我们用均方误差(MSE)模板匹配区分 3 和 7。现在对比神经网络的表现:
# 获取所有测试集中的 3 和 7
test_3_files = get_image_files(path/'testing'/'3')
test_7_files = get_image_files(path/'testing'/'7')# 创建只包含 3 和 7 的测试集
test_files_3_7 = test_3_files[:50] + test_7_files[:50]
test_dl_3_7 = learn.dls.test_dl(test_files_3_7)# 预测
preds, _ = learn.get_preds(dl=test_dl_3_7)
pred_classes = preds.argmax(dim=1)# 计算 3 和 7 的准确率
true_labels = torch.tensor([3] * 50 + [7] * 50)
correct = (pred_classes == true_labels).float().mean()
print(f"神经网络在 3 和 7 上的准确率: {correct.item():.4f}")
神经网络在 3 和 7 上的准确率: 0.9900
可视化特征图
让我们通过查看第一层卷积的激活来可视化我们的 CNN 学到的特征:
# 获取一批图片
x, y = dls.one_batch()# 获取自定义模型的第一层卷积
conv1 = learn.model.conv1# 应用第一层卷积获取激活
with torch.no_grad():activations = conv1(x)# 可视化第一张图片的激活
# 我们的自定义模型第一层有 16 个滤波器
fig, axes = plt.subplots(4, 4, figsize=(10, 10))
axes = axes.flatten()# 显示原图
axes[0].imshow(x[0][0].cpu(), cmap='gray')
axes[0].set_title(f"原图: {y[0].item()}")
axes[0].axis('off')# 显示前 15 个滤波器的激活图
for i in range(1, 16):axes[i].imshow(activations[0, i-1].detach().cpu(), cmap='viridis')axes[i].set_title(f"滤波器 {i}")axes[i].axis('off')plt.tight_layout()
plt.show()# 同时可视化滤波器权重
weights = conv1.weight.data.cpu()
fig, axes = plt.subplots(4, 4, figsize=(10, 10))
axes = axes.flatten()# 再次显示原图
axes[0].imshow(x[0][0].cpu(), cmap='gray')
axes[0].set_title(f"原图: {y[0].item()}")
axes[0].axis('off')# 显示前 15 个滤波器的权重
for i in range(1, 16):# 每个滤波器只有一个输入通道(灰度)axes[i].imshow(weights[i-1, 0], cmap='viridis')axes[i].set_title(f"滤波器 {i} 权重")axes[i].axis('off')plt.tight_layout()
plt.show()


结论
在本教程中,我们深入探索了 MNIST 数据集,并训练了一个卷积神经网络来对手写数字进行分类。我们看到了模型的表现,并可视化了其部分内部表示。
主要收获:
- 神经网络可以在数字分类任务上取得很高的准确率。
- CNN 的第一层会学习到边缘和纹理等简单特征。
- 我们之前的模板匹配方法虽然更简单,但准确率远不如完整的神经网络。
- fastai 让构建、训练和解释深度学习模型变得非常容易。