多组学时代(multi-omics era)已然到来!前几年基因组的研究如火如荼,因为基因组最接近生命的本质;近几年,代谢组的研究也在逐渐火热起来,因为代谢组最接近生命的表象,即各种表型,包括人的生理表型,高矮胖瘦等,也包括人的生老病死。今天为大家解读的就是一篇关注临床代谢组学研究的文献,2018年初发表于Hepatology(2016 IF = 13.25)。本文的Last author是中科院大连化学物理研究所代谢组研究分析中心主任许国旺院士,国内代谢组分析的大牛!

Title:A Large-Scale, Multicenter Serum Metabolite Biomarker Identification Study for the Early Detection of Hepatocellular Carcinoma
Journal:HEPATOLOGY, DOI 10.1002/hep.29561
问题引入
1.流行病学背景
肝细胞癌(HCC,ps:HCC是原发性肝癌[liver cancer]的一种病理类型,占肝癌的90%左右)是最恶性的肿瘤之一,每年造成7百万人死亡,而且1年生存率和5年生存率都很不理想。此外,大约一半的HCC新发病例和相关死亡发生在中国。(ps:中国是肝癌大国!在大多数地区,肝癌并不是一个十分罕见的肿瘤,其发病率可能仅次于肺癌。再加上肝癌的预后相对较差,而且发病高峰通常比其他恶性肿瘤要早,大约在55-60岁,这意味着肝癌给我国带来了极大的公共卫生负担!是一个亟需研究的疾病。正是由于肝癌的高发,我国的肝癌研究在世界范围内也一直处于领先地位,就像岛国的胃癌研究。)
2.临床现状与不足
虽然HCC的几大危险因素已经得到了广泛研究和证实,但是,由于HCC早期的症状隐匿,以及难以与肝硬化相鉴别诊断,导致临床上HCC的早诊依然是一个非常大的挑战!(ps:作者一句话就道出了HCC临床诊断、治疗面临的困难,为后面叙述做铺垫)。临床上通常使用影像手段,比如CT和超声,以及血清生物标志物,比如AFP(甲胎蛋白),对肝癌进行早诊,但是依然难以通过此类手段鉴别诊断小HCC和肝硬化结节。此外,AFP对于HCC的诊断灵敏度不高。这些因素导致我们亟需研究一种新的生物标志物,用于HCC的早诊和筛查(ps:作者列举了当前临床上HCC的诊断方法,同时毫不客气的指出了它们的不足,这也就是作者开展此项研究的意义所在。目前来看,肿瘤的早期诊断依然是一个非常热门的临床问题,随着组学技术的不断发展和完善,以及各种计算机算法的应用,在不久的未来,会有越来越多的早诊方法被开发出来,应用于恶性肿瘤的筛查和早诊,与此相关的文章也会越来越多,Bob觉得也许再过五年,与本文相类似的文章可能就再也发表不了10+的杂志了,所以,各位看官,如有意向,趁早动手呀!时间不等人!)。
3.疾病诊断的新兴技术
(ps:作者在这一段开始介绍本文所使用的新兴技术了,以便同之前介绍的一些“旧”技术相区别,凸显优势)近年来,循环生物标志物被广泛运用到肿瘤的筛查、肿瘤的生物基础研究以及肿瘤的复发和侵袭研究上来。但是由于血液中生物大分子种类繁多,比如有蛋白质、代谢物、miRNA等,这为血液循环生物标志物的应用带来了挑战。不过,液相色谱-质谱法(LC-MS)是一个发现新型疾病生物标志物的强有力工具!之前已经有不少研究使用了这一方法,从体液(血液和尿液)中鉴别出新型的有意义的生物标志物,用于HCC的诊断。但是,那些研究都是基于小样本的pilot研究。我们之前也进行了一些类似的研究,发现了一些生物标志物的panel,但是一是受限于样本量,二是缺乏外部验证的人群,再加上不同个体之间生物背景的异质性很大,所以,我们需要开展一个大型的多中心的研究,来发现更加稳定的生物标志物(ps:作者一方面肯定了前人的工作,这是先礼后兵,然后立马话锋一转,一个however,点出之前的研究样本量不够,都是小打小闹啦)。
4.我们干了啥
(ps:估计到了这一段,各位童鞋用膝盖也能想到作者写了啥,毫无疑问,第一点,开展了一个大型的多中心的研究,第二点,应用了powerful的LC-MS方法,目的就是发现最具有临床意义的HCC早诊生物标志物。总的来说,这样一个introduction,逻辑十分清晰,要点十分明确,作者的目的也达到了,编辑和审稿人也被他带了进去,迫不及待想知道研究的结果怎么样了……)
材料方法
1.研究设计和纳入患者
本研究共纳入了1488名研究对象,其中包括正常对照、慢性乙肝病人、肝硬化患者、HCC患者、胃癌患者(GSC)以及肝内胆管细胞癌(ICC)。研究对象来源于中国6个临床机构,纳入的时间为2008年9月至2014年5月。研究对象的排除标准为:对于正常对照,如果①肝功能不正常,②有肝病家族史以及其他系统疾病则排除;对于肝病患者,如果患有其他急性病或者其他恶性肿瘤,则排除。研究设计如下图所示:
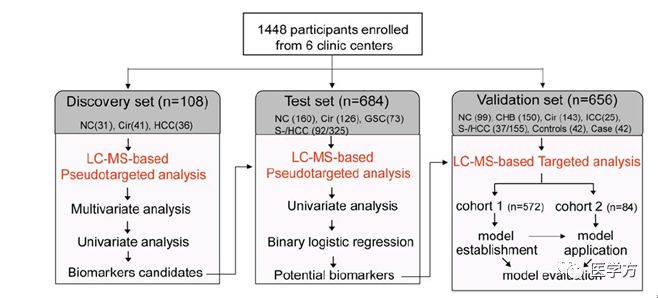
从上图可以看出,整个研究分为三个阶段,第一阶段为“发现阶段”,共纳入了108名研究对象,目的在于发现候选的生物标志物;第二阶段为“测试阶段”,共纳入了684名研究对象,包括325名HCC患者,目的在于验证第一阶段发现的候选生物标志物;第三阶段为“验证阶段”,该阶段共纳入了两个队列,队列1观察了572个对象,用于确定最终的生物标志物panel;队列2包含84个对象,包括42例新发HCC患者,以及为这42名HCC患者挑选的 42名对照,构成了一个巢式病例对照设计,用于最终的验证。另外,值得注意的是,在第二阶段和第三阶段,作者都纳入了S-HCC,目的在于验证候选生物标志物的HCC临床早诊能力;此外,作者还纳入了胃癌和ICC患者,目的在于检验候选生物标志物的特异性。(ps:整个研究设计看着很复杂,但是很有层次,前两个阶段较容易理解,主要是第三阶段的设计,作者不仅纳入了已经明确诊断的HCC病例,还通过前瞻性的队列获得了部分HCC病例,用于候选生物标志物的验证。这种设计其实是一种非常精彩的做法。通常情况下,我们较容易获取横断面的资料,包括常见的病例对照设计,也容易获取回顾性的资料,比如回顾性的队列,作者通过容易获取的资料进行了前面的大部分“发现”工作,而验证是通过前瞻性的队列研究来实现的。在队列基线或者队列初期,作者就收集了研究对象的血液,然后进行随访观察,最终发现部分对象发展成为了HCC,这时候,在前期采集的血液就显得十分珍贵了,因为这些血液中生物标志物很有可能与最终没有发展成HCC的对象存在不同,而应用在前面的工作中已经“发现”的候选生物标志物,就可以验证它们对于HCC发生的预测功能(pre-clinical diagnosis)。此外,假如这一步无法实现,因为队列不能无止境的观察下去,我们可以在新发HCC患者确定后,采集他们的血液,与队列中的非HCC对象,进行相应的比较分析,确定候选生物标志物的诊断功能。)
2.血浆采集和质谱分析
这一部分无特别之处,大部分是代谢组的常规操作,不过Bob对此也不是很熟悉,请各位看官浏览原文,Bob在此不做讲解。唯一值得借鉴的地方是,作者人为构建了一些用于质量控制的sample,即quality control samples,具体做法是将他们实验室之前收集的很多血清混合在一起,然后构成多个QC样本,目的就在于监测后续分析的稳定性。
3.统计分析
本文的统计部分稍显复杂。作者首先对于来自不同人群(HCC患者,正常对照,肝硬化患者,还有QC样本)的血清代谢物进行了一个主成分分析,对组间整体代谢组的变化进行评价,并监测研究的稳定性。随后采用了一个偏最小二乘判别分析对不同组别进行鉴别,目的在于找到一个“分类标准”,使组间的差异最大,而组内的差异最小,并且顺便找到对于分类贡献最大的几个变量。作者随后使用了permutation test对构建的模型进行了拟合度验证,目的在于避免模型的过拟合(over fitting),而这个permutation test,其作用与bootstrap类似,有时候又被称作randomization test。
结 果
1
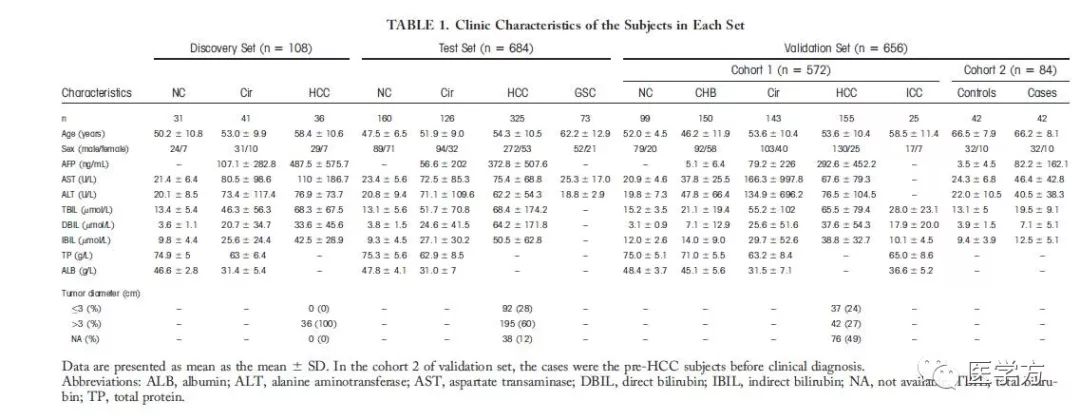
纳入对象的人口学信息和基本特征
2
血清生物标志物分析
下图展示了研究第一阶段数据(发现阶段)和第二阶段(测试阶段)的数据的PCA结果。
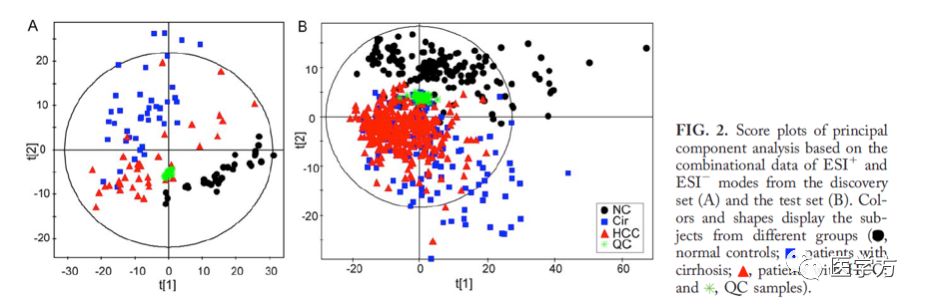
上图中,不同颜色的点代表不同的sample,其中大家注意到绿色的点,这些点是QC sample,明显可以看到这些点在A、B两张图中都聚到一起了,这表明前面的质谱实验结果是稳定可靠的。此外,我们也可以看到,不同组别的sample,其在主成分散点图上的分布是有区别的,同一类型的倾向于聚在一块。作者通过数据库的比对,最终发现了239个候选代谢物,进入下一步分析。
3
候选代谢物的确定
偏最小二乘判别分析显示不同组别之间区分明显,如下图所示:
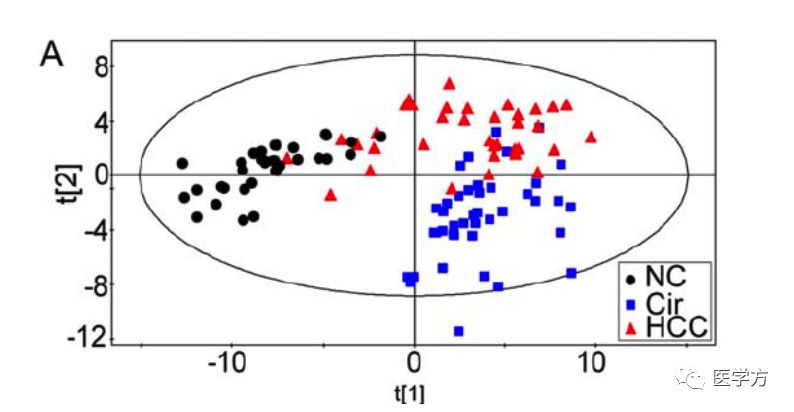
最终作者发现了57个候选代谢物,它们对于两个主成分的贡献都大于1(VIP>1.0),然后,作者构建了一个简单的单因素回归分析,去判断这57个候选代谢物与HCC的关系是否具有统计学意义,最终17个代谢物满足条件。
作者进一步希望从候选的17个代谢物中继续筛选出最有意义的那些。而入选的标准是:1)在不同组别的比较中,比如HCC vs. 正常对照,HCC vs. S-HCC,都有显著的差异;2)在不同组别的比较中,保持相同的变化趋势,比如在HCC vs. 正常对照中,A代谢物表现为上升,那么在其他组的比较中,也应该表现为上升。最终作者选出了8种符合上述条件的代谢物。然后,作者又构建了一个logistic回归模型,并采用逐步回归的方式,从8种代谢物中最终挑选了2种出来,获得最后的胜利!它们分别是Phe-Trp(苯丙酰胺-色氨酸)和GCA(甘胺胆酸盐)。
下图展示了这两种代谢物在不同组别样本中的血清浓度。*表示与正常对照比较,#表示与HCC患者比较。
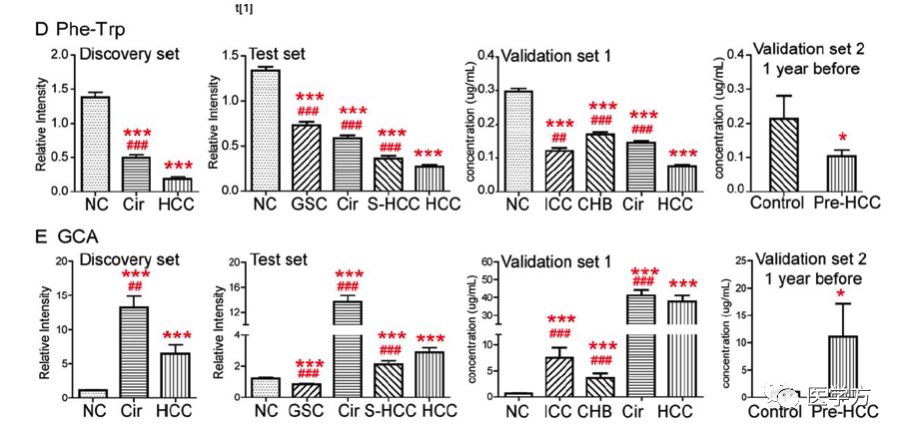
作者然后比较了这两种代谢物与常规的AFP相比,诊断的准确性更高,具体表现为AUC曲线下的面积更大。
4
代谢物诊断准确性验证
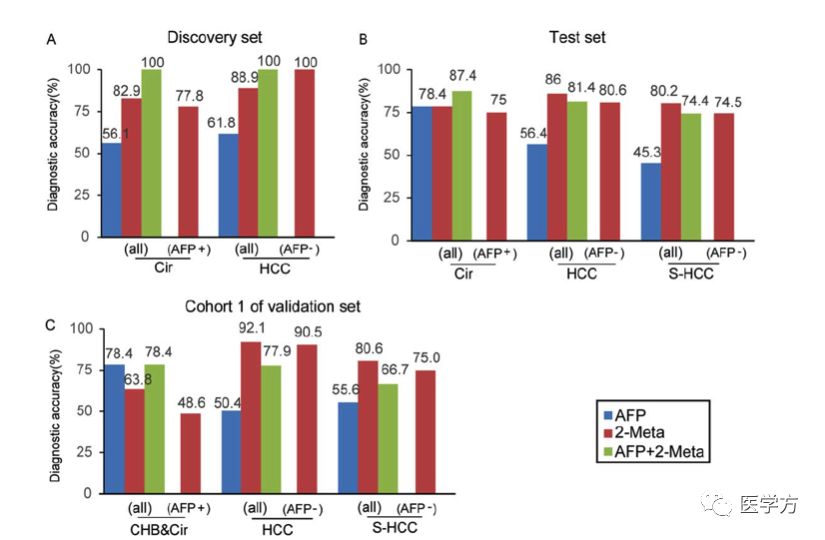
上图展示的是在三个不同阶段,AFP、两个代谢物以及二者联合的肝病诊断准确率。其中AFP+表示患者AFP浓度大于20 ng/ml,AFP-表示浓度低于20 ng/ml。此外,作者利用验证阶段的cohort2,检验了HCC诊断前的不同时间内,代谢物和AFP的预测能力。如下表所示:
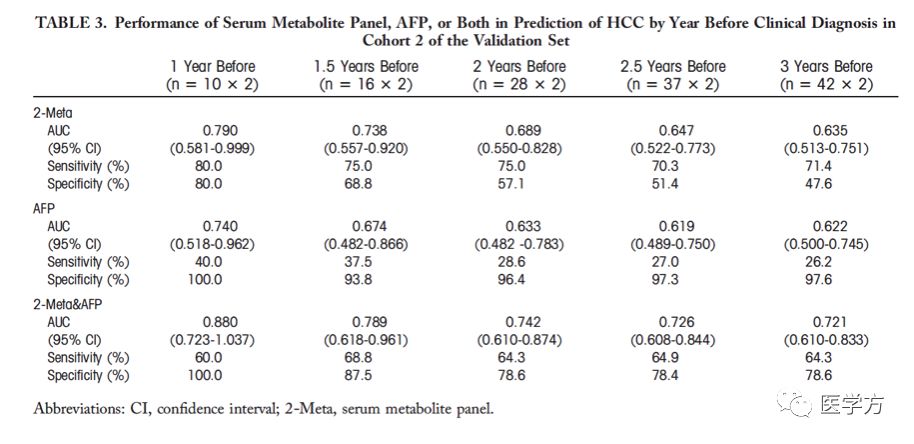
从上表可以看出,越接近于HCC的临床诊断时间,代谢物和AFP的预测能力越强,这一点显然是符合逻辑的。
在结果的最后部分,作者研究了代谢物与患者的肝功能指标之间的关系。
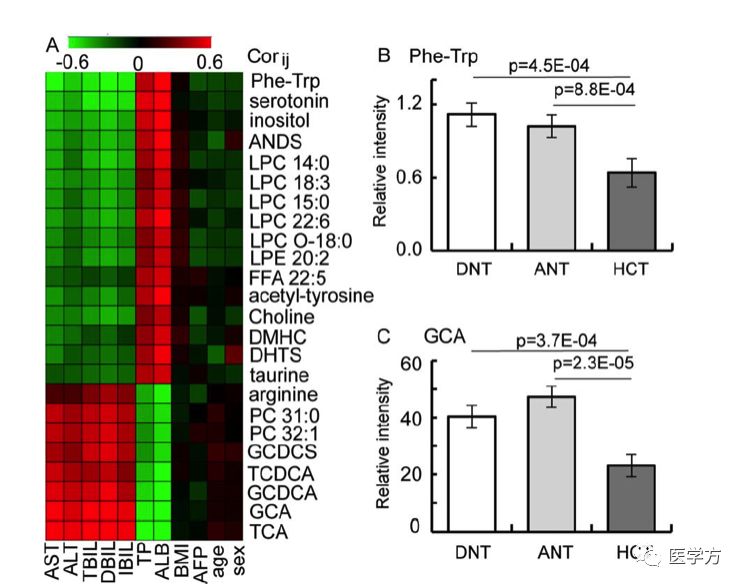
热图表示的是不同的代谢物浓度与患者肝功能指标的相关性(以相关系数表示)。图B和C展示的是在不同的组织中,两种代谢物的浓度,DNT表示远处的非癌组织,ANT表示癌旁组织,HCT表示癌症组织。在不同组织中,都可以发现两种代谢物的浓度差异!
总 结
本文是一个非常全面和严谨的临床代谢物研究,其中涉及的实验方法、统计学方法都值得我们学习。作者在行文过程中,像侦探破案一般,一层一层抽丝剥茧,最终找到了两个有意义的血清生物标志物,并在此基础上,从不同的角度对它们进行了验证。此外,本文是基于6个临床中心开展的临床研究,涉及discovery set,test set,以及validation set,既有内部验证,又有外部验证,关键是还有队列验证,值得我们借鉴!
征 稿 启 事
「医学方」现正式向粉丝们公开征稿!内容须原创首发,与科研相关,一经采用,会奉上丰厚稿酬(300-2000元),详情请戳。
“医学方”始终致力于服务“医学人”,将最前沿、最有价值的临床、科研原创文章推送给各位临床医师、科研人员。