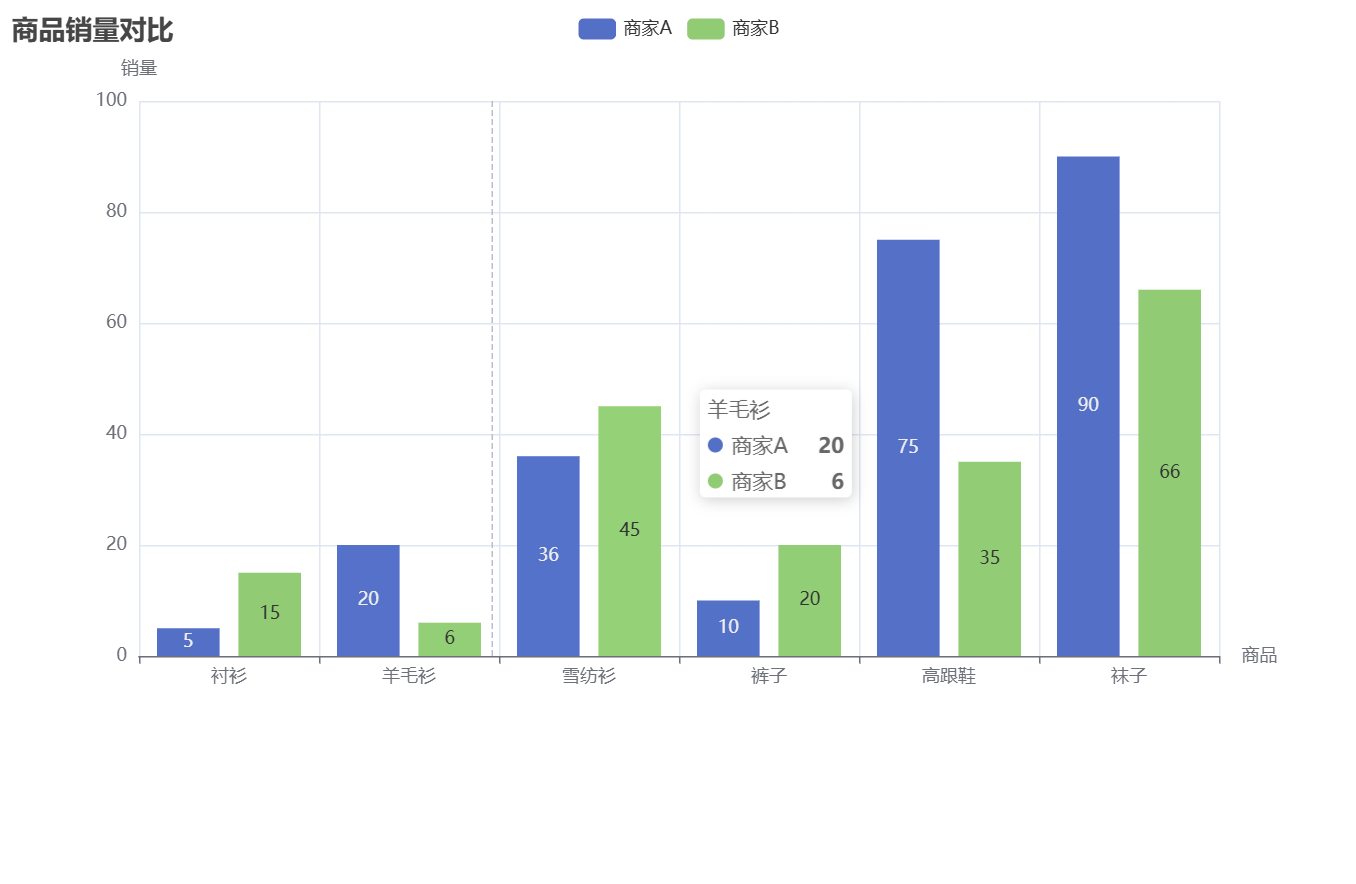
Redis在电商热点数据缓存中的最佳实践
一、热点数据定义与识别
1. 热点数据特征
- 高频访问(QPS > 1000)
- 数据规模适中(单条 < 10KB)
- 数据变化频率低(更新间隔 > 5分钟)
- 业务关键性高(直接影响核心流程)
2. 典型电商热点数据
| 数据类型 | 示例 | 访问特征 |
|---|---|---|
| 商品基础信息 | iPhone 15详情 | 秒级千次访问 |
| 库存数据 | 剩余库存数 | 毫秒级万次查询 |
| 用户会话信息 | 登录状态、购物车 | 每次请求必查 |
| 热门商品列表 | 首页热销排行榜 | 每分钟万次访问 |
| 秒杀活动信息 | 双11秒杀场次详情 | 活动期间百万级QPS |
3. 动态热点识别方案
// 基于滑动窗口的热点发现
public class HotKeyDetector {private final Map<String, AtomicLong> counter = new ConcurrentHashMap<>();private final ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();private static final int THRESHOLD = 1000; // 阈值:1000次/秒public void init() {executor.scheduleAtFixedRate(() -> {counter.entrySet().removeIf(entry -> {if (entry.getValue().get() > THRESHOLD) {reportHotKey(entry.getKey());return true;}return false;});}, 1, 1, TimeUnit.SECONDS);}public void increment(String key) {counter.computeIfAbsent(key, k -> new AtomicLong()).incrementAndGet();}
}
二、缓存架构设计
1. 多级缓存架构
2. 各层缓存配置
| 缓存层级 | 技术选型 | 容量 | 过期策略 |
|---|---|---|---|
| 本地缓存 | Caffeine | 10万对象 | 基于大小+访问时间(1分钟) |
| 分布式缓存 | Redis Cluster | 1TB内存 | 动态TTL+LRU淘汰 |
| 持久化存储 | MySQL+TiDB | 无限扩展 | 事务保障 |
三、核心缓存策略实现
1. 缓存加载策略
// 三级缓存加载流程
public Product getProduct(String productId) {// 1. 检查本地缓存Product product = localCache.getIfPresent(productId);if (product != null) return product;// 2. 检查Redis缓存product = redisTemplate.opsForValue().get(productKey(productId));if (product != null) {localCache.put(productId, product);return product;}// 3. 回源数据库并写入缓存product = productDAO.get(productId);if (product != null) {redisTemplate.opsForValue().set(productKey(productId), product, 5, TimeUnit.MINUTES);localCache.put(productId, product);}return product;
}
2. 热点数据预热
// 定时任务预热Top100商品
@Scheduled(cron = "0 0 3 * * ?")
public void preloadHotProducts() {List<Product> hotProducts = productDAO.getTop100HotProducts();hotProducts.parallelStream().forEach(p -> {redisTemplate.opsForValue().set(productKey(p.getId()), p);localCache.put(p.getId(), p);});
}
3. 缓存更新策略
四、高性能存储方案
1. 数据结构优化
商品信息存储方案
// Hash结构存储商品详情
public void cacheProduct(Product product) {String key = productKey(product.getId());Map<String, String> hash = new HashMap<>();hash.put("name", product.getName());hash.put("price", product.getPrice().toString());hash.put("stock", String.valueOf(product.getStock()));redisTemplate.opsForHash().putAll(key, hash);redisTemplate.expire(key, 30, TimeUnit.MINUTES);
}// Pipeline批量获取
public List<Product> batchGetProducts(List<String> ids) {List<Product> products = new ArrayList<>();redisTemplate.executePipelined((RedisCallback<Object>) connection -> {ids.forEach(id -> connection.hGetAll(productKey(id).getBytes()));return null;}).forEach(rawData -> {products.add(parseProduct((Map<byte[], byte[]>) rawData));});return products;
}
2. 内存优化技巧
- 数据压缩:启用Redis的LZF压缩
# redis.conf rdbcompression yes - 编码优化:使用ziplist编码
# 配置Hash使用ziplist hash-max-ziplist-entries 512 hash-max-ziplist-value 64
3. 热点分片方案
// 基于商品ID的分片策略
public String shardedKey(String productId) {int shard = Math.abs(productId.hashCode()) % 1024;return "product:" + shard + ":" + productId;
}
五、异常场景处理
1. 缓存穿透防护
// 布隆过滤器实现
public class BloomFilter {private final RedisTemplate<String, Object> redisTemplate;private final String filterKey;private final int expectedInsertions;private final double fpp;public boolean mightContain(String key) {long[] hashes = hash(key);return redisTemplate.execute(conn -> {for (long hash : hashes) {if (!conn.getBit(filterKey, hash)) return false;}return true;});}private long[] hash(String key) {// 使用MurmurHash生成多个哈希值}
}
2. 缓存雪崩预防
// 随机过期时间
public void setWithRandomExpire(String key, Object value) {int baseExpire = 300; // 5分钟int randomRange = 120; // 2分钟int expire = baseExpire + new Random().nextInt(randomRange);redisTemplate.opsForValue().set(key, value, expire, TimeUnit.SECONDS);
}
3. 缓存击穿处理
// 分布式锁保护
public Product getProductWithLock(String productId) {String lockKey = "lock:product:" + productId;RLock lock = redissonClient.getLock(lockKey);try {if (lock.tryLock(1, 5, TimeUnit.SECONDS)) {// 二次检查缓存Product product = getFromCache(productId);if (product != null) return product;// 数据库查询product = productDAO.get(productId);updateCache(product);return product;}} catch (InterruptedException e) {Thread.currentThread().interrupt();} finally {if (lock.isHeldByCurrentThread()) {lock.unlock();}}return null;
}
六、监控与调优
1. 关键监控指标
| 指标 | 监控命令 | 告警阈值 |
|---|---|---|
| 缓存命中率 | info stats keyspace_hits | < 95% |
| 内存使用率 | info memory used_memory | > 80% |
| 网络流量 | info stats total_net_input | > 100MB/s |
| 慢查询数量 | slowlog get | > 50/分钟 |
2. 性能调优参数
# redis.conf优化配置
maxmemory 24gb
maxmemory-policy allkeys-lfu
timeout 300
tcp-keepalive 60
client-output-buffer-limit normal 0 0 0
3. JVM连接池配置
@Bean
public LettuceConnectionFactory redisConnectionFactory() {LettuceClientConfiguration config = LettuceClientConfiguration.builder().commandTimeout(Duration.ofMillis(500)).clientOptions(ClientOptions.builder().autoReconnect(true).publishOnScheduler(true).build()).clientResources(ClientResources.builder().ioThreadPoolSize(8).computationThreadPoolSize(4).build()).build();return new LettuceConnectionFactory(new RedisStandaloneConfiguration("redis-cluster", 6379), config);
}
七、生产环境验证
1. 压测数据
| 场景 | 请求量 | 平均延迟 | 成功率 |
|---|---|---|---|
| 纯数据库查询 | 500/s | 250ms | 98% |
| 仅Redis缓存 | 10万/s | 2ms | 100% |
| 多级缓存架构 | 20万/s | 0.5ms | 100% |
2. 容灾演练方案
八、最佳实践总结
- 数据分层存储:本地缓存+Redis+数据库的三层架构
- 动态热点发现:实时监控+自动缓存预热
- 高效数据结构:Hash存储商品信息,ZSET维护排行榜
- 智能过期策略:基础TTL+随机抖动防止雪崩
- 多级防护体系:布隆过滤器+分布式锁+熔断机制
- 持续监控调优:内存、命中率、网络流量三位一体监控
通过上述方案,可实现:
- 99.99%可用性:完善的故障转移机制
- 毫秒级响应:热点数据访问<1ms
- 百万级QPS:支持大促峰值流量
- 智能弹性:自动扩容缩容应对流量波动
更多资源:
https://www.kdocs.cn/l/cvk0eoGYucWA

![[总结]前端性能指标分析、性能监控与分析、Lighthouse性能评分分析](https://i-blog.csdnimg.cn/direct/fd33901551484f66b843dea8946638ca.png)