历史:
在C++98版本后,C++11是一次大版本的更新。在C++11中新增了许多有用的东西。接下来将由小编来带领大家介绍C++11中新增的内容。
列表初始化:
在C++中,列表初始化(也称为统一初始化或花括号初始化)是一种使用花括号 `{}` 来初始化对象的语法。
在C++98时,花括号初始化一般用于数组或者结构体初始化。
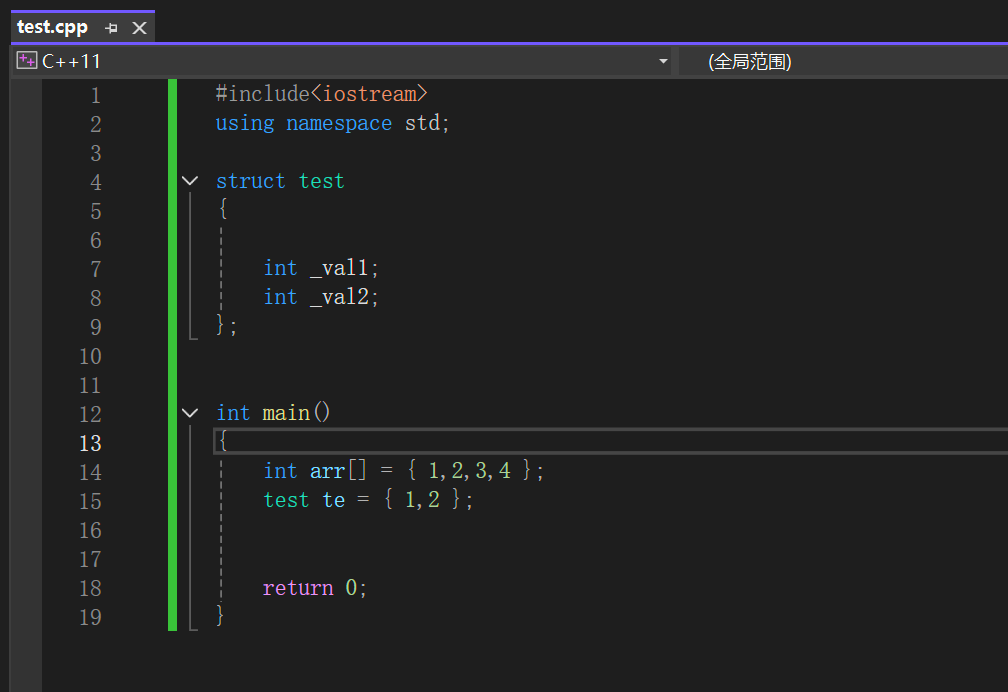
而在C++11中,提出了万物皆可”{}”初始化的概念。不仅内置类型支持列表初始化,自定义类型也同样支持。
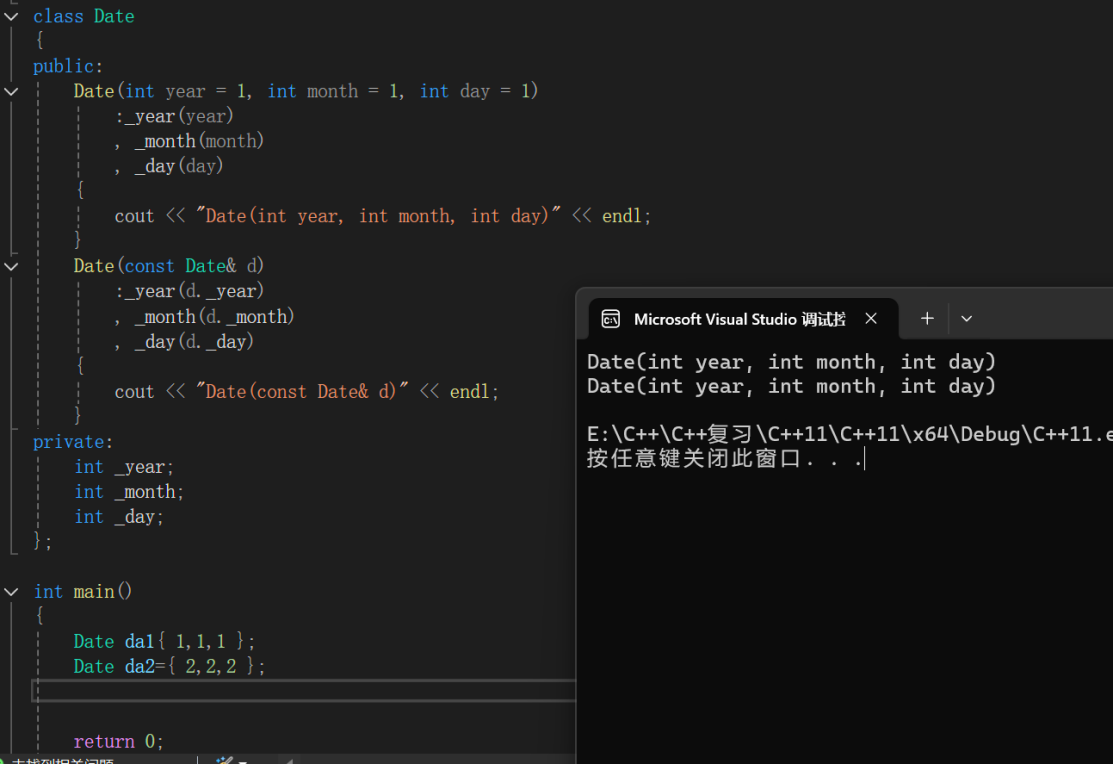
initializer_list:
std::initializer_list 是 C++11 引入的一个轻量级模板类(定义在 <initializer_list> 头文件中),用于表示由相同类型元素组成的编译期常量数组。它是实现列表初始化({} 初始化)的核心机制,也就是说其实initializer_list就是”{}”,再更简单理解的话initializer_list就是一个数组,只是通过类模板编译后的数组,后续再根据需求实例化出相应类型的数组。
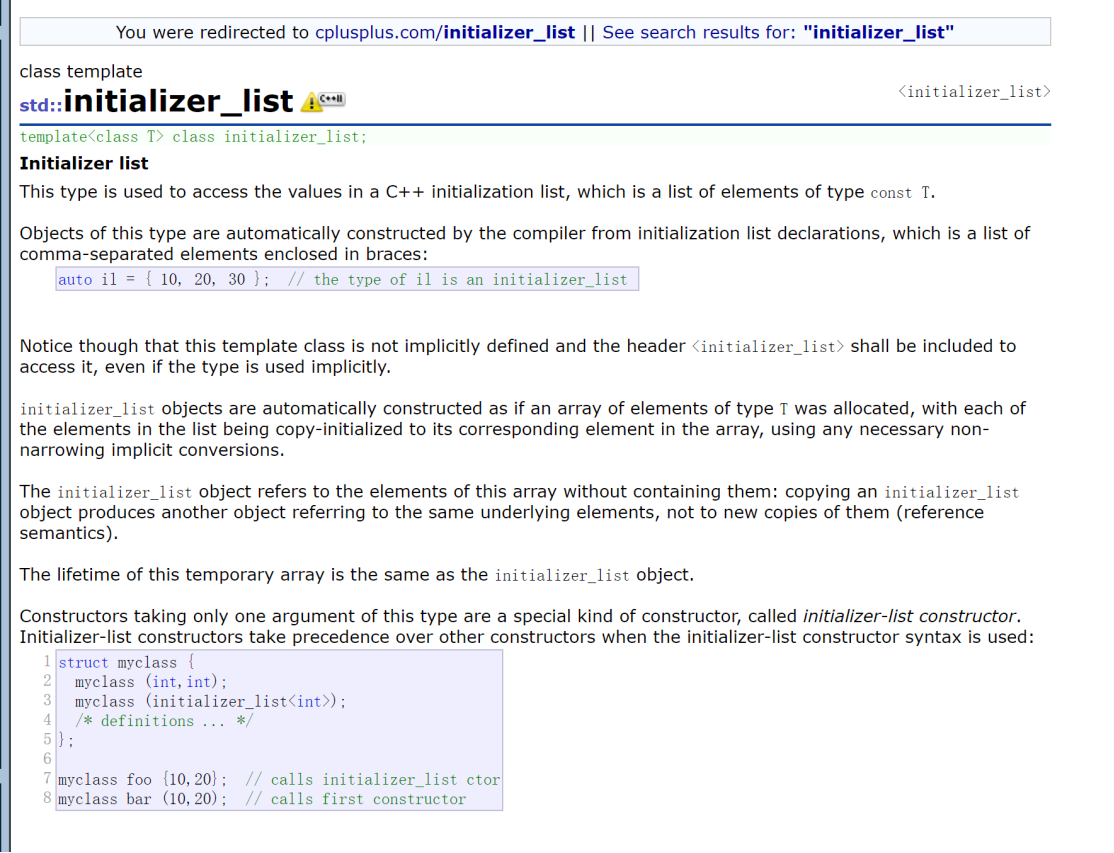
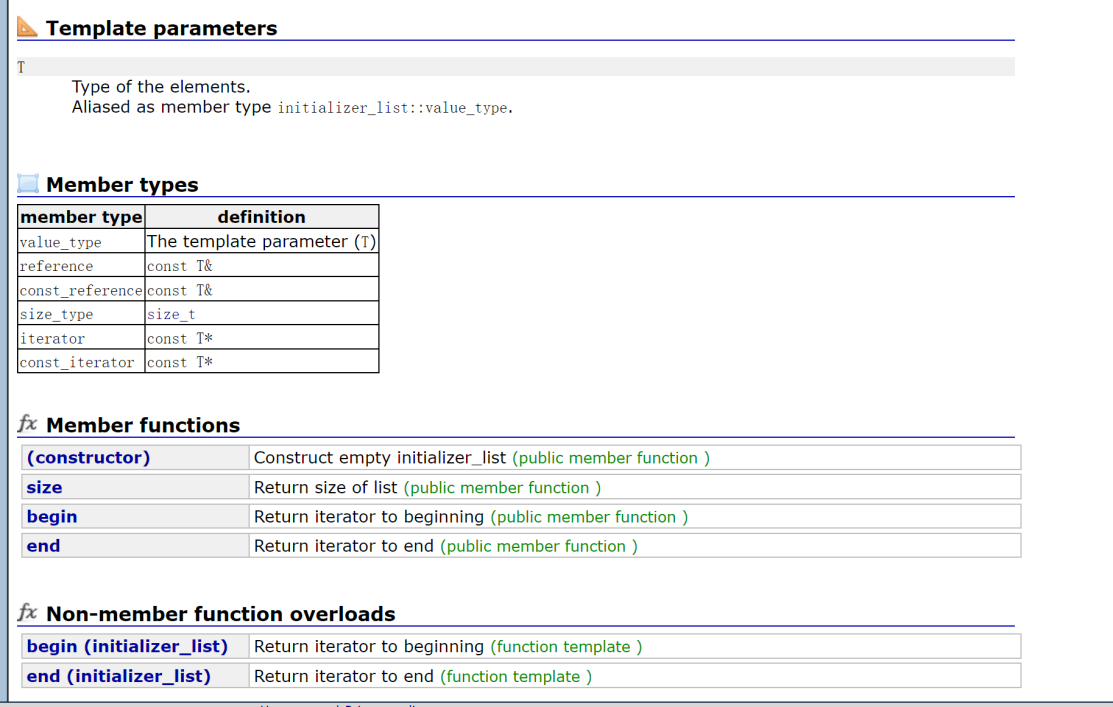
为什么要有initializer_list?
我们可以看到initializer_list是支持迭代器,支持迭代器就意味着支持迭代器构造。
并且initializer_list支持多个值进行初始化,而我们STL大多数容器都支持多个值初始化,也是通过先创建initializer_list对象,再通过initializer_list对象的迭代器对其他容器进行初始化值操作。
右值引用与移动语义:
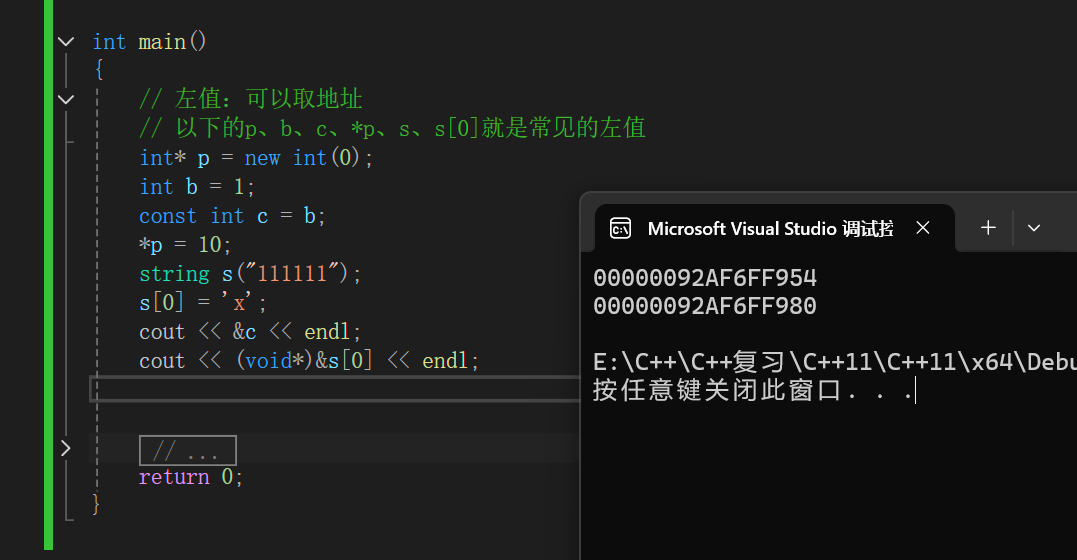
左值引用:
我们之前常见的引用,基本都可以称之为左值引用,左值引用的基本都是引用一个变量。
其特点为:
- 有明确的身份
- 生命周期长
- 能够被取地址
- 可以多次引用
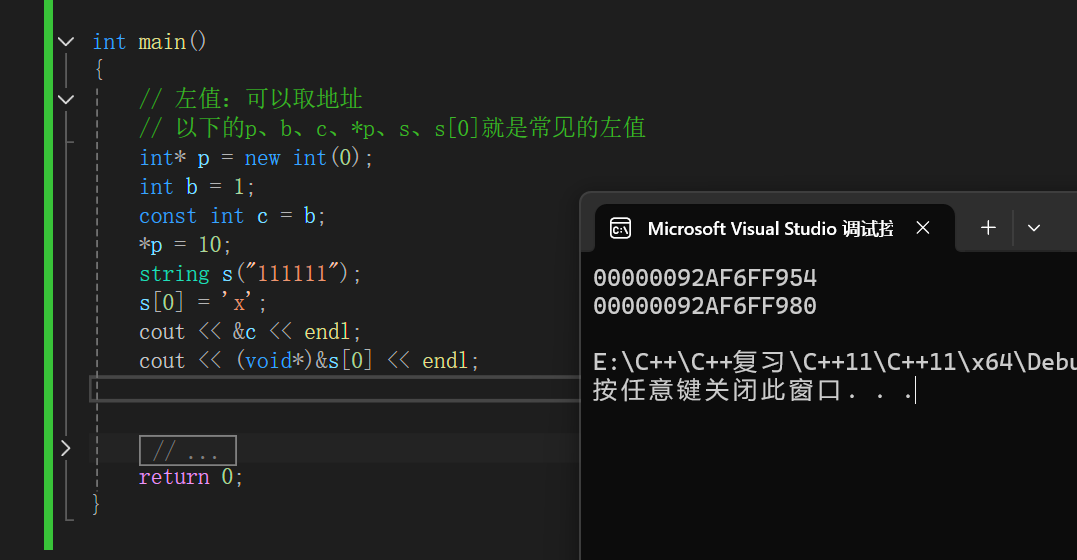
右值引用:
右值引用,引用的都是右值,右值是具有常量属性的值,并且不能被取地址,类似于被const修饰过。而具有右值属性的基本为一个函数表达式,或变量表达式。但是这里有一个特殊的点,右值引用后的变量是一个具有左值属性的值,这点可能现在看起来会有些绕,但是为了后面的准备这个是必要的。
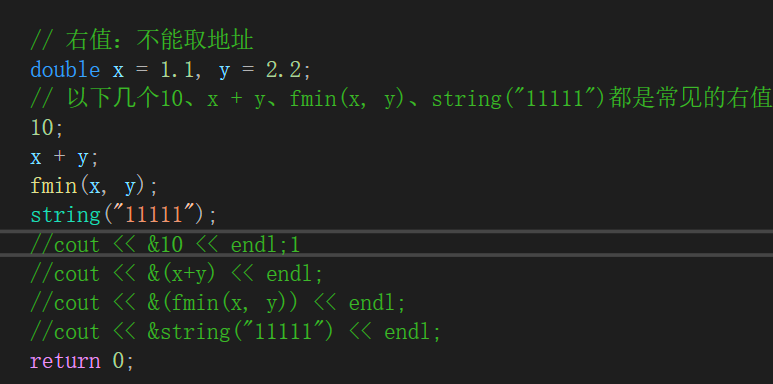
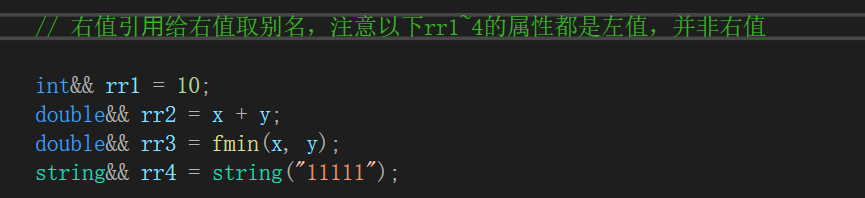
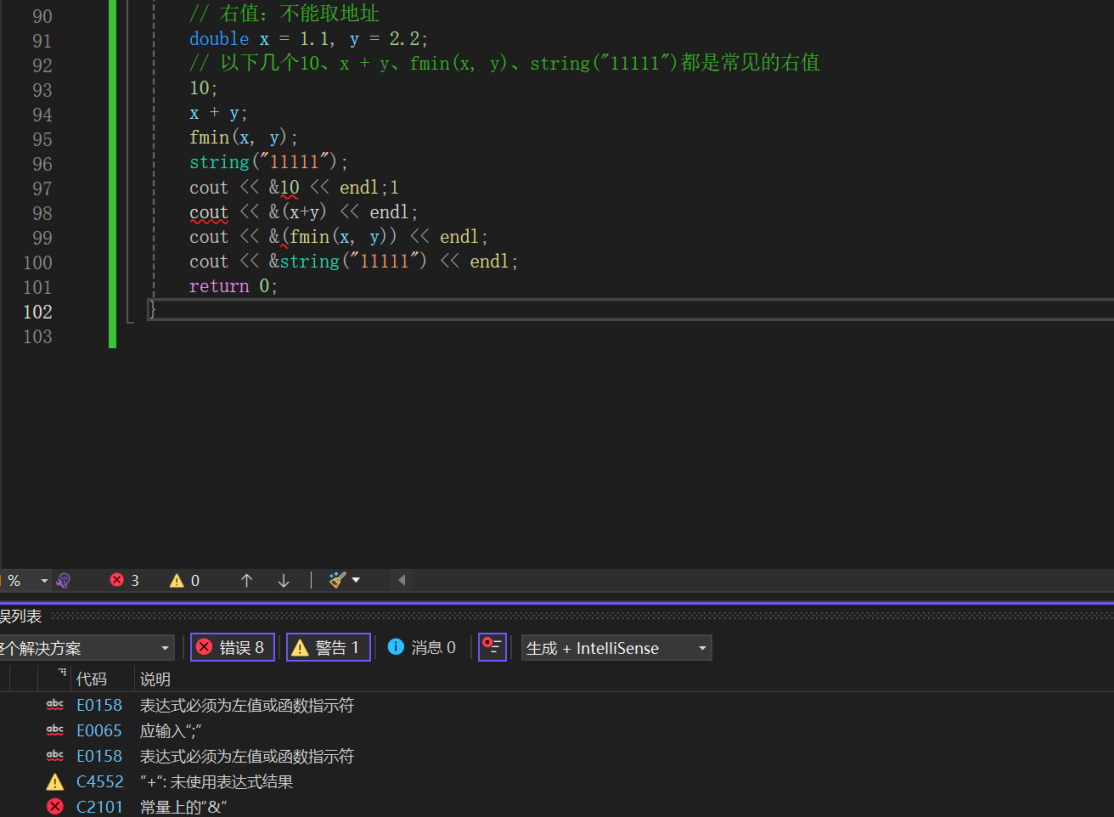
从语法层来说,无论是左值引用还是右值引用,都是给对象取别名,而给对象取别名是不开空间的。并且区分一个值是左值还是右值,就看它能否取地址。
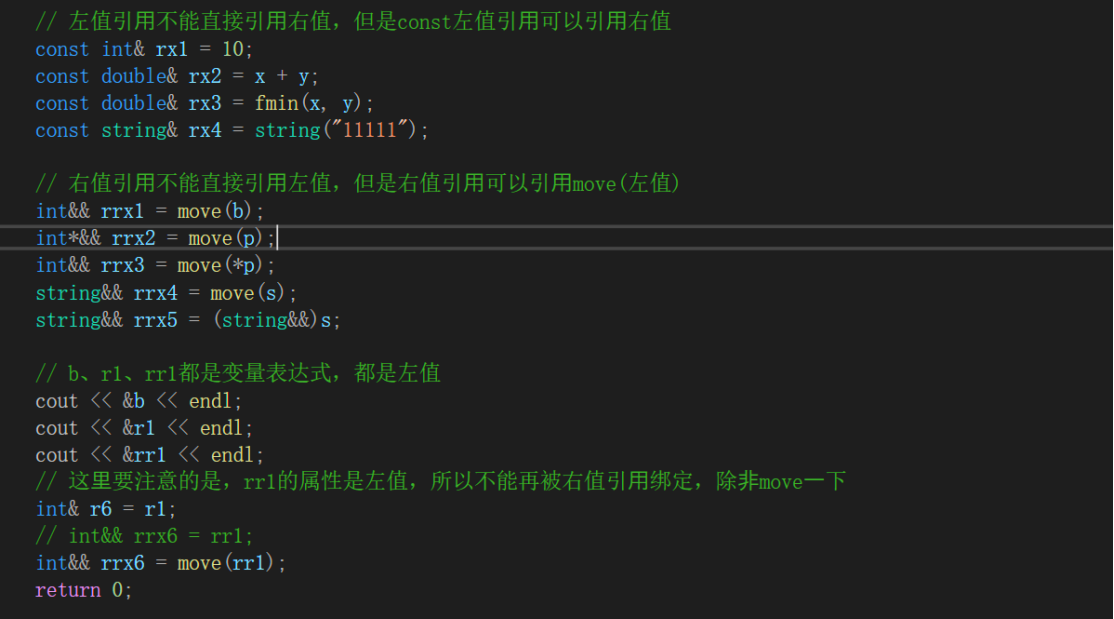
C++规定左值引用是不能直接引用右值(具有const属性),但是const 左值引用是可以引用右值的。而右值也不能直接引用左值,必须通过move函数,将左值强转成右值才能引用。
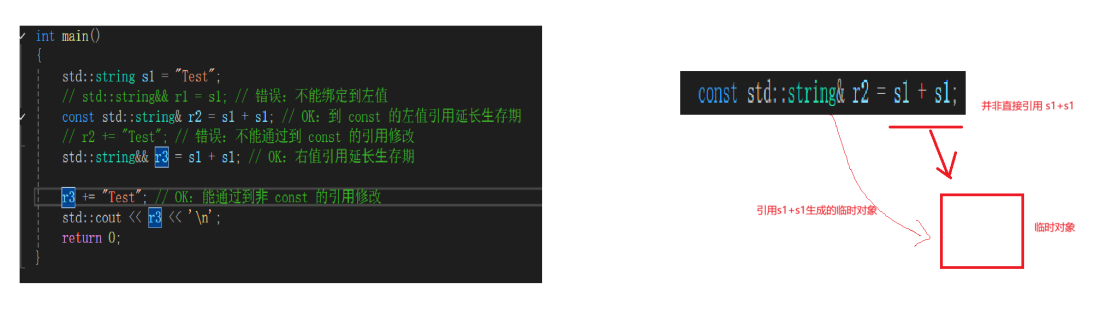
引用对对象生命周期的延长:
对于临时变量的生命周期,通常来说只存在当前行。Const 左值引用可以延长临时变量的生命周期,但无法做到修改。而右值引用可以做到这一点。
左值与右值的参数匹配
左值引用可以作为函数参数进行传递,同样的右值引用也可以,只不过在左值与右值在传递的过程中存在些许差异。
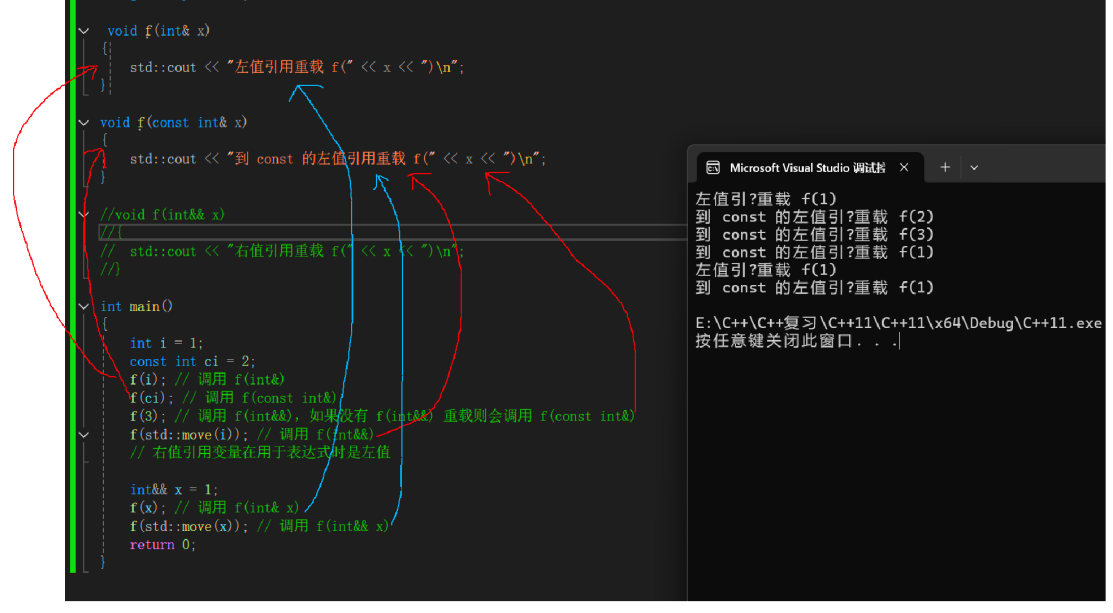
如上图,函数f完成了函数重载,暂时屏蔽了右值引用作为参数后。可以看到i,调用的是左值引用,ci是const左值引用,3因为是一个常量所以也是const 左值引用,当move了i后,i属性变为右值,但const 左值引用以及可以引用右值,所以程序能正常运行。
而可能会有点疑问的是为什么x是左值引用。不要忘记之前说的,当一个右值引用的变量绑定了一个右值后,该变量的属性依旧为左值,所以编译器这里把x识别为左值,调用的就是左值引用的f函数。
右值引⽤和移动语义的使⽤场景
左值引用主要使用场景主要用于函数中左值引用传参或传返回值,但无论哪种情况,其目的都是为了减少不必要的拷贝,同时还可以修改实参和修改返回对象的价值。可以说左值引用解决了大多场景中拷贝效率的问题。但在有些情况中,左值引用并不能很好的解决。


上图的函数最后都需要传值返回。第一段代码还好,仅仅只是返回一个string,而第二段代码需要返回的是vector的vector,传值返回就需要创建相同的临时变量,通过临时变量在进行拷贝构造,代价是非常大的。而右值引用也不能直接引用上图的str或vv。因为他们本质上还是一个局部对象。当函数结束时,栈帧就销毁此时就会调用他们的析构函数。
移动构造与移动赋值:
移动构造和移动赋值与拷贝构造和拷贝赋值有着本质区别。
拷贝操作的本质: 创建对象的完整副本。对于管理动态资源(如 vector、string 或自定义包含指针的类)的对象,这意味着需要分配新内存并复制所有数据(深拷贝)。性能开销可能很大,尤其当对象很大或资源层次很深时。
移动操作的本质: 转移资源的所有权,而非复制。其核心在于“窃取” 源对象的资源(如内部指针指向的内存),将其转移到目标对象,并使源对象处于有效但未指定的状态(通常是“空”状态)。移动操作通常仅涉及少量指针的交换或赋值,无需分配新内存或复制数据,因此效率极高。
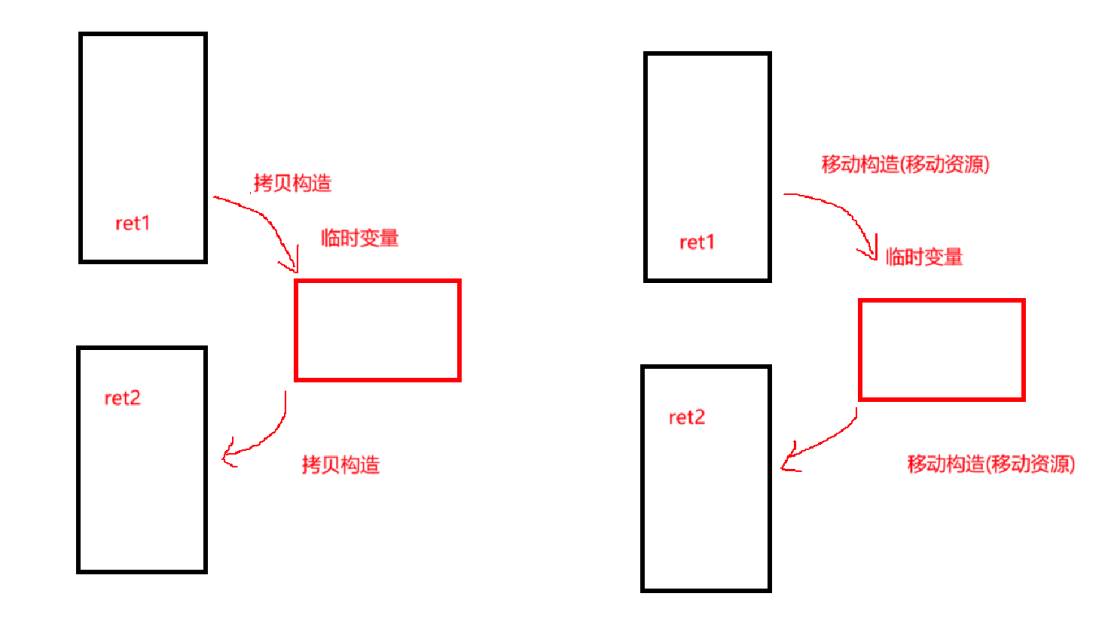
正如上图,如果是深拷贝的话,那么拷贝构造将会及其麻烦。而移动构造不会,ret移动构造给临时变量时,因为临时变量什么都没有,把两个指针交换,就变成ret1里没内容,而临时变量会有ret1里的内容,代价是非常小的。
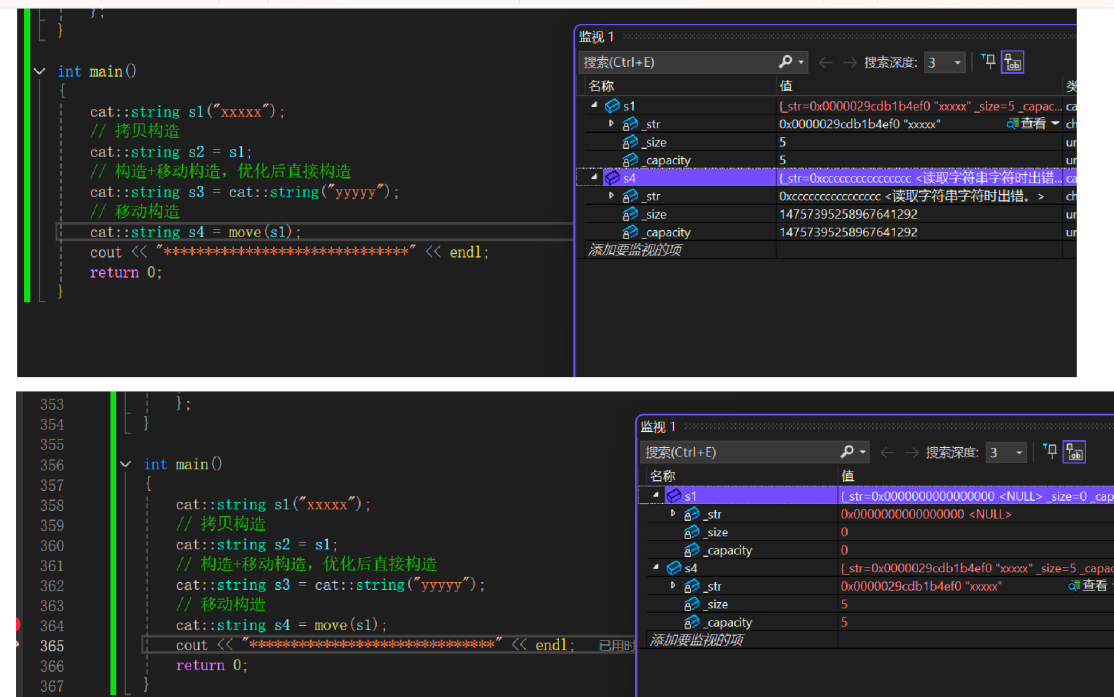
如上图,通过移动构造S4直接掠夺S1的资源,因为S4本身就为NULL,所以掠夺完S1就为空了,而因为S1已经是右值,再掠夺完后,会直接调用析构函数来析构S1。
| 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050 051 052 053 054 055 056 057 058 059 060 061 062 063 064 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 091 092 093 094 095 096 097 098 099 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 | #define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> #include<assert.h> #include<string.h> #include<algorithm> using namespace std; namespace cat { class string { public: typedef char* iterator; typedef const char* const_iterator; iterator begin() { return _str; }
iterator end() { return _str + _size; }
const_iterator begin() const { return _str; }
const_iterator end() const { return _str + _size; }
string(const char* str = "") :_size(strlen(str)) , _capacity(_size) { cout << "string(char* str)-构造" << endl; _str = new char[_capacity + 1]; strcpy(_str, str); }
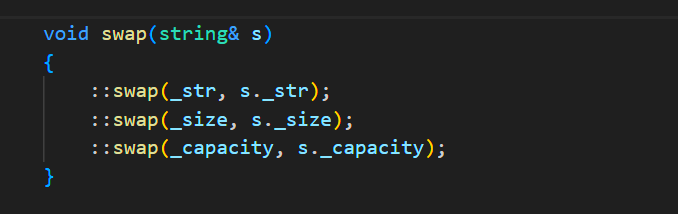
void swap(string& s) { ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); }
string(const string& s) :_str(nullptr) { cout << "string(const string& s) -- 拷⻉构造" << endl;
reserve(s._capacity); for (auto ch : s) { push_back(ch); } }
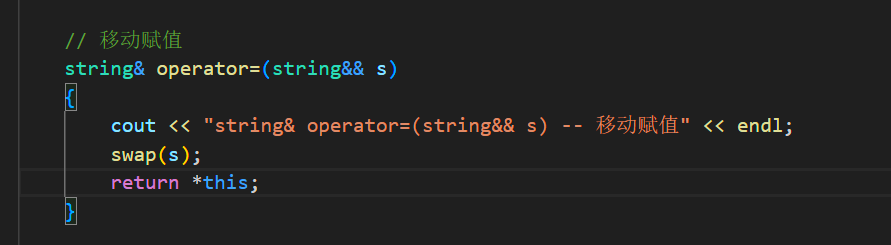
// 移动构造 string(string&& s) { cout << "string(string&& s) -- 移动构造" << endl; swap(s); }
string& operator=(const string& s) { cout << "string& operator=(const string& s) -- 拷⻉赋值" << endl; if (this != &s) { _str[0] = '\0'; _size = 0; reserve(s._capacity); for (auto ch : s) { push_back(ch); } } return *this; }
// 移动赋值 string& operator=(string&& s) { cout << "string& operator=(string&& s) -- 移动赋值" << endl; swap(s); return *this; }
~string() { cout << "~string() -- 析构" << endl; delete[] _str; _str = nullptr; }
char& operator[](size_t pos) { assert(pos < _size); return _str[pos]; }
void reserve(size_t n) { if (n > _capacity) { char* tmp = new char[n + 1]; if (_str) { strcpy(tmp, _str); delete[] _str; } _str = tmp; _capacity = n; } }
void push_back(char ch) { if (_size >= _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity *2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0'; }
string& operator+=(char ch) { push_back(ch); return *this; }
const char* c_str() const { return _str; }
size_t size() const { return _size; }
private: char* _str = nullptr; size_t _size = 0; size_t _capacity = 0; };
string addStrings(string num1, string num2) { string str; int end1 = num1.size() - 1, end2 = num2.size() - 1; int next = 0; while (end1 >= 0 || end2 >= 0) { int val1 = end1 >= 0 ? num1[end1--] - '0' : 0; int val2 = end2 >= 0 ? num2[end2--] - '0' : 0; int ret = val1 + val2 + next; next = ret / 10; ret = ret % 10; str += ('0' + ret); } if (next == 1) str += '1'; reverse(str.begin(), str.end()); cout << "******************************" << endl; return str; } }
int main() { cat::string ret=cat::addStrings("11111", "2222"); cout << ret.c_str() << endl; return 0; } |
为了体现右值引用的意义,上图代码是一个自我实现的string类,我们先把移动构造和移动赋值给注释后看上图代码。
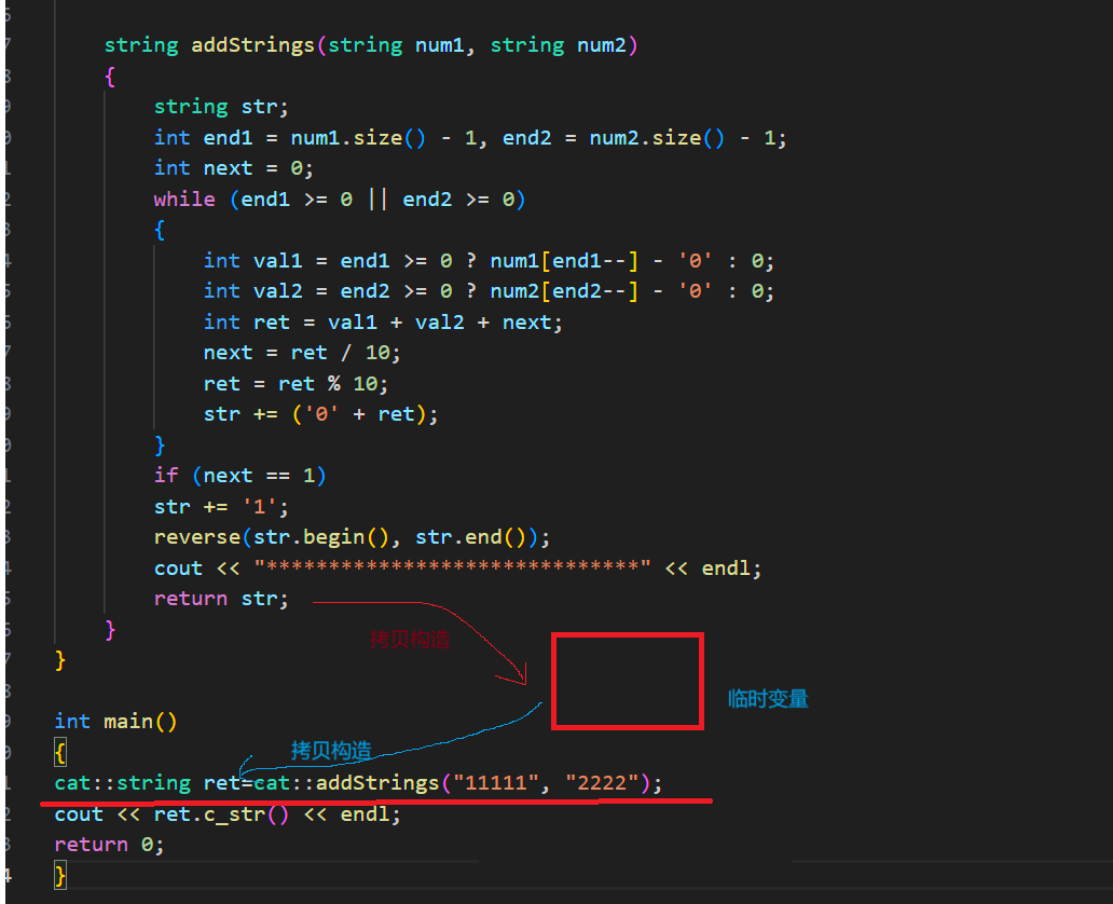
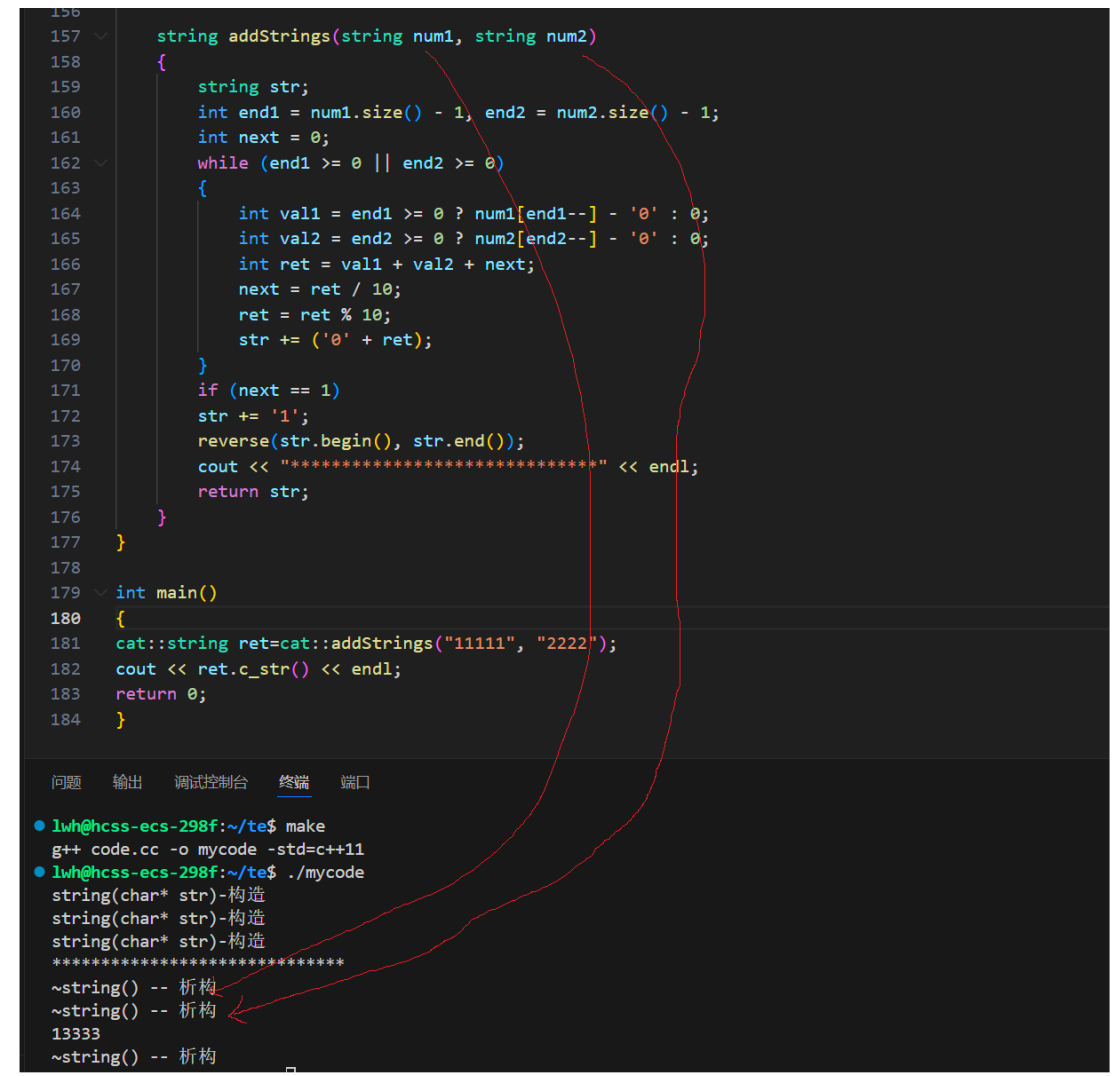
当程序运行起来后可以看见,本应该是先拷贝构造临时变量,在拷贝构造ret,但在运行后却变成了直接构造。原因是编译器会对这种行为进行优化(具体优化各不相同,根据编译器及版本不同而定,C++委员会没有硬性规定)。编译器会对拷贝构造+拷贝构造,优化为直接构造。
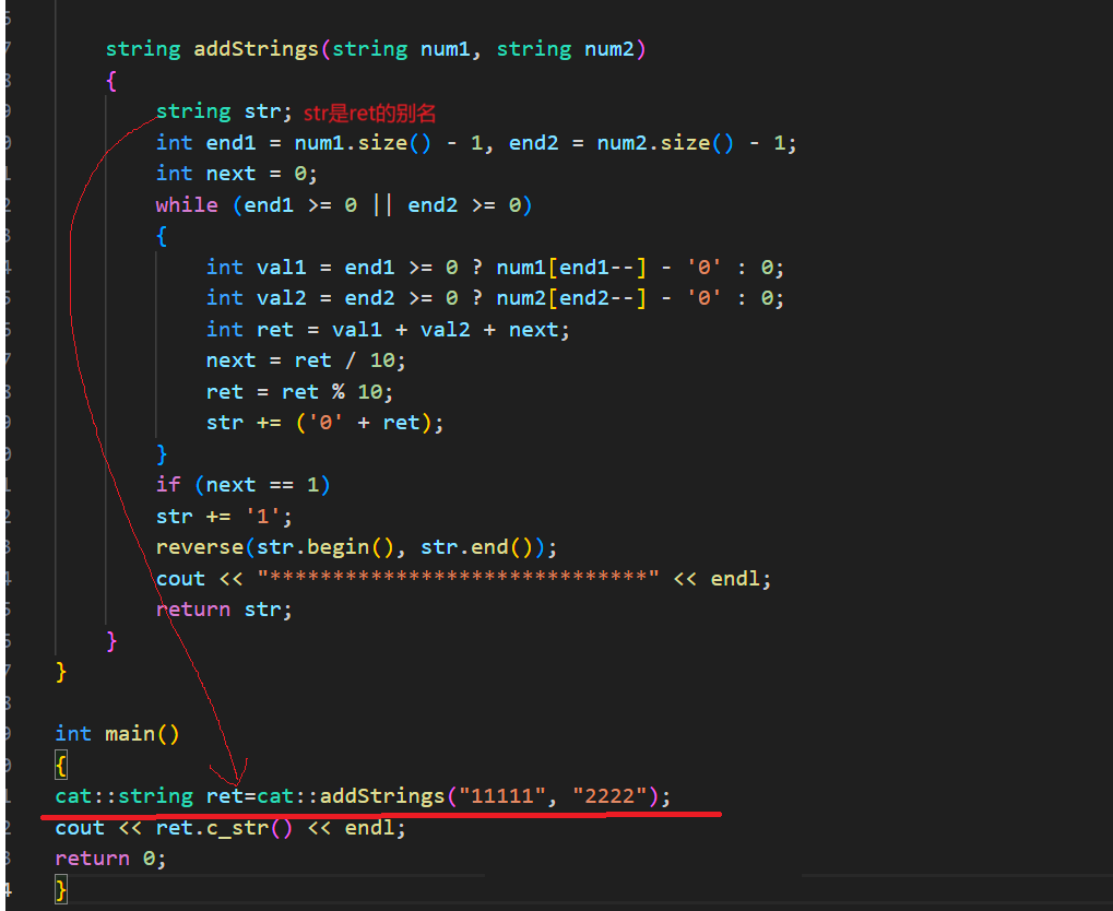
因为编译器在这里觉得,反正最后的值是给ret,那为什么我不直接将str变为ret的别名,不就省去了拷贝构造的过程,反正结果是一样的。为了验证这一点,我们还可以打印他们的地址,他们的地址是相同的来加以验证。
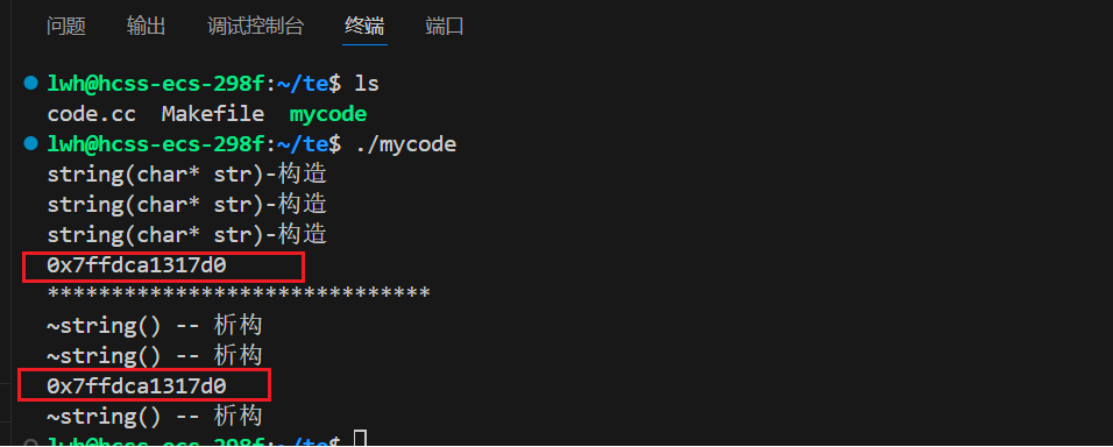
因为编译器的优化行为是自定义的,我们如果使用老版本的编译器,可能就不会优化的这么厉害。在Linux中我们可以在编译时候加入 -fno-elide-constructors 这段命令,就可以让编译器不要进行优化。
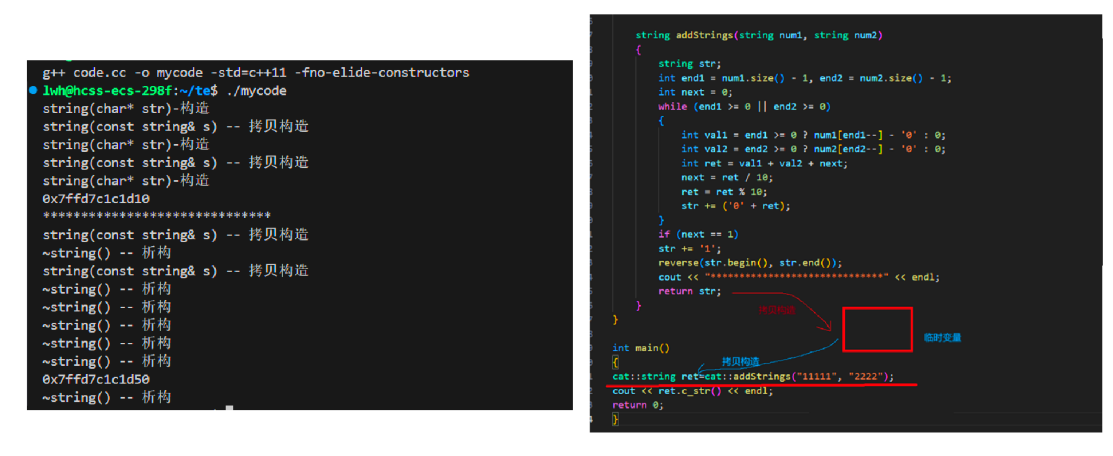
使用不优化的编译运行后,结果跟我们预想是一模一样的,先进行拷贝构造给临时对象,再拷贝构造给ret。如果是深拷贝类型,这种行为就会显得极为麻烦。那么如果我们拥有移动构造和移动赋值来看呢

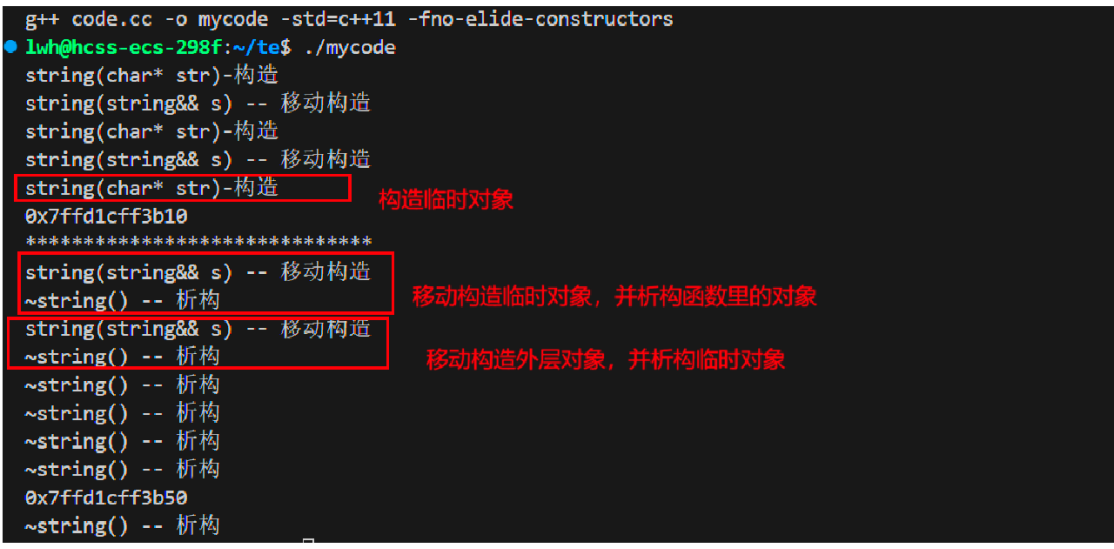
可以看到,当同时拥有移动构造与拷贝构造时,编译器就会自主选择移动构造完成。因为移动构造的代价够小,所以就算走两次移动构造也是非常快的。
引用折叠:
在 C++ 中,引用折叠(Reference Collapsing)是一组处理"引用的引用"的规则。
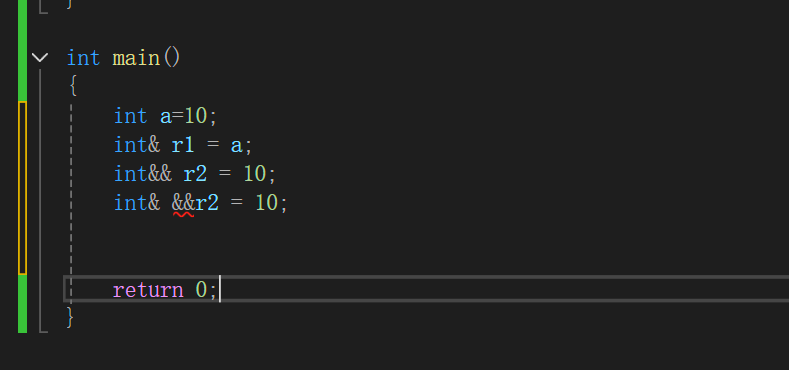
也就是说我们并不能直接对引用进行引用,但是通过类模板编译后就可以,对引用进行引用了,也就会产生引用折叠。而引用折叠也有自己的处理逻辑
当编译器遇到"引用的引用"时,会按以下规则折叠:
& + & → &(左值引用)
& + && → &(左值引用)
&& + & → &(左值引用)
&& + && → &&(右值引用)
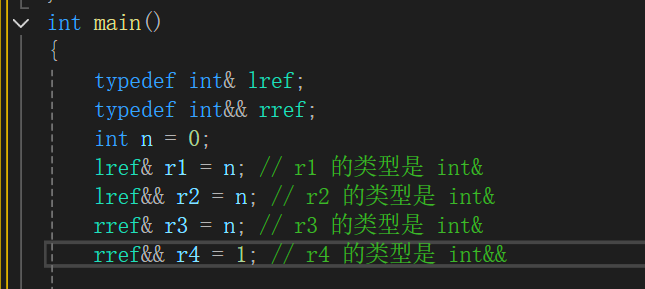
从上图也可以发现规律,左值引用碰任何引用都会变成左值引用,只有右值引用碰右值引用其属性才是右值引用。
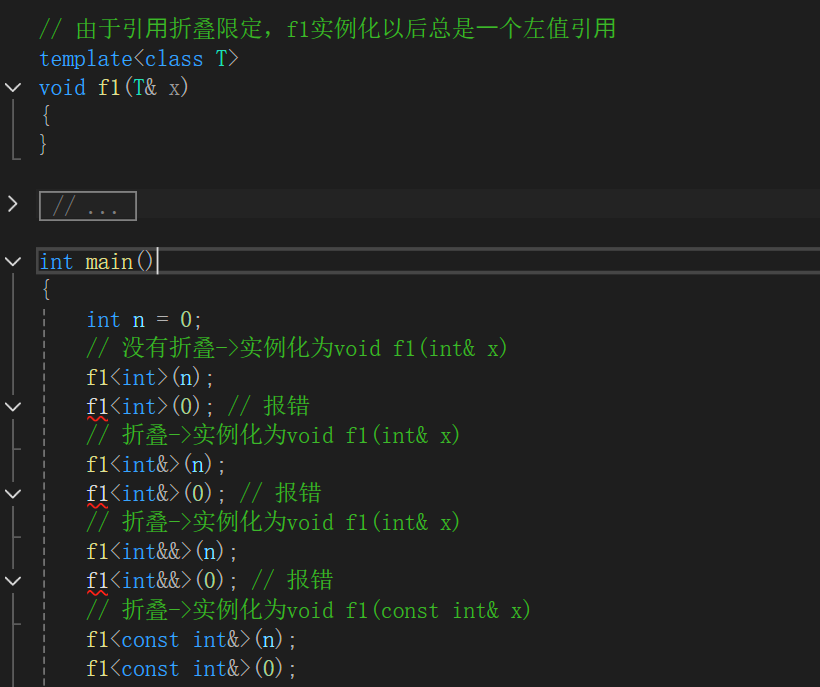
如上图示例,n是一个左值,0则是右值,
f1<int>(n);是没有任何问题。而f1<int>(0); 则会报错,因为0是一个右值,左值引用是不能直接引用一个右值。
f1<int&>(n);也是没有问题,因为左值引用碰左值引用,还是左值引用。f1<int&>(0); 因为碰撞后还是左值引用依旧报错
f1<int&&>(n);右值引用碰左值引用,会折叠成左值引用,没有问题。f1<int&&>(0);折叠还是左值引用,报错。
f1<const int&>(n);const 左值引用碰左值引用,会折叠成const左值引用,这是权限的缩小,没有问题。f1<const int&>(0);;const 左值引用可以引用右值也没有问题。
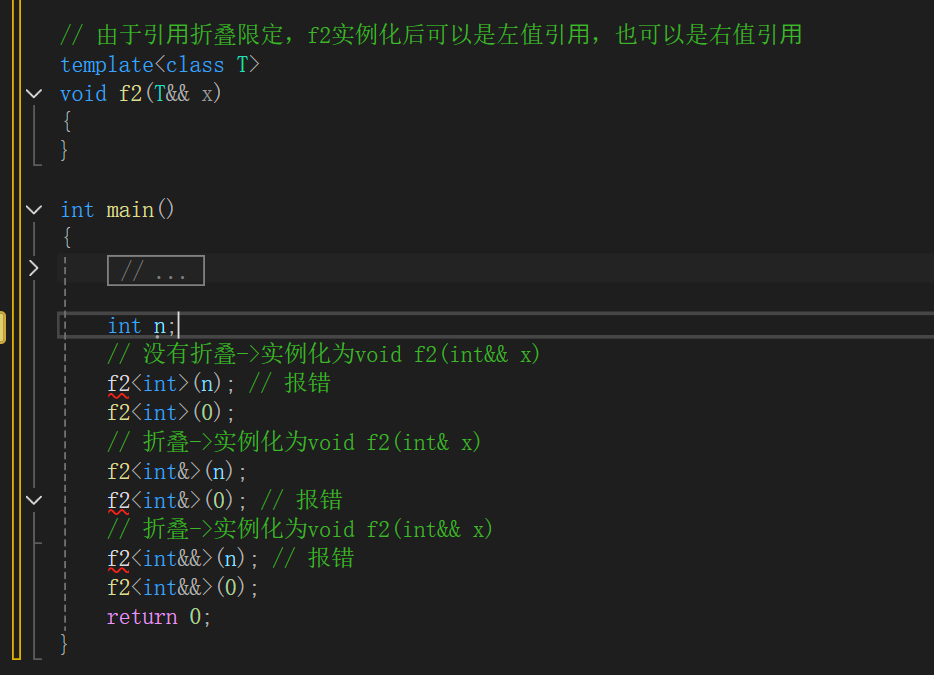
f2<int>(n); 会报错,因为n是一个左值,而f2是一个右值引用,右值不能引用左值。 f2<int>(0);没有问题,0是右值,右值引用去引用右值。
f2<int&>(n);也没问题,因为左值引用碰右值引用,会折叠为左值引用。 f2<int&>(0);折叠后依旧是左值引用,所以报错。
f2<int&&>(n); 折叠后为右值引用,而n为左值,所以报错。f2<int&&>(0);折叠为右值引用去引用右值没问题。
完美转发:

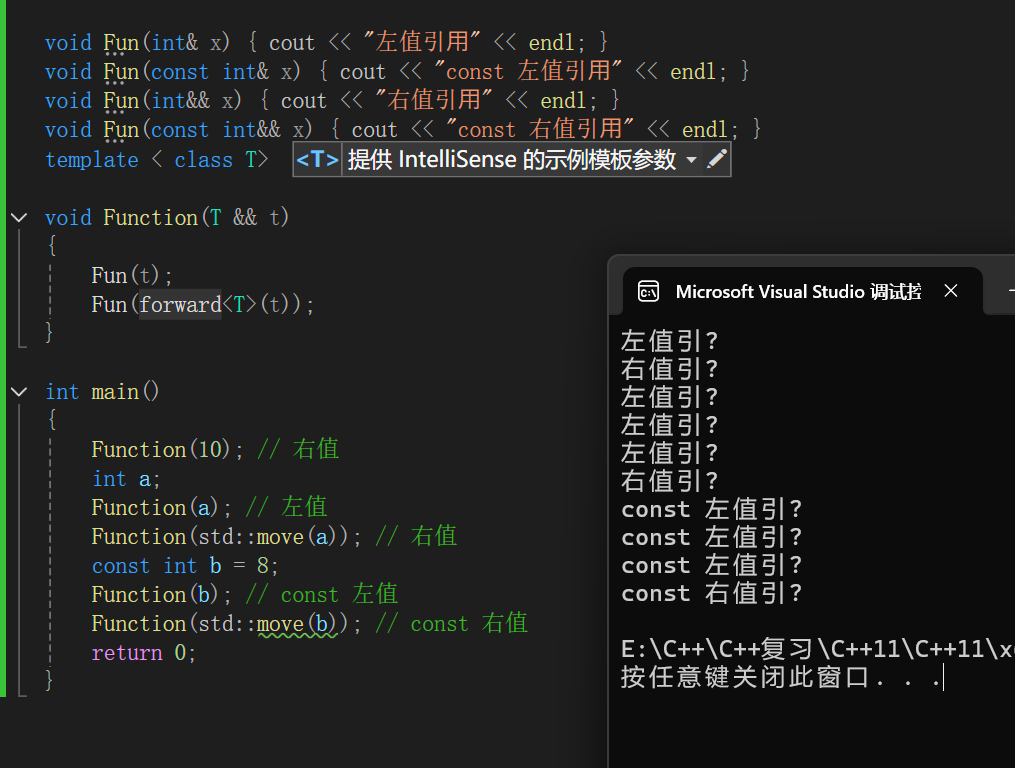
当我们看见上图代码时,大家可能会想到通过引用折叠后调用不同发fun函数。但其实实际运行后除了调用左值引用的fun函数就是调用const 左值引用的fun函数。
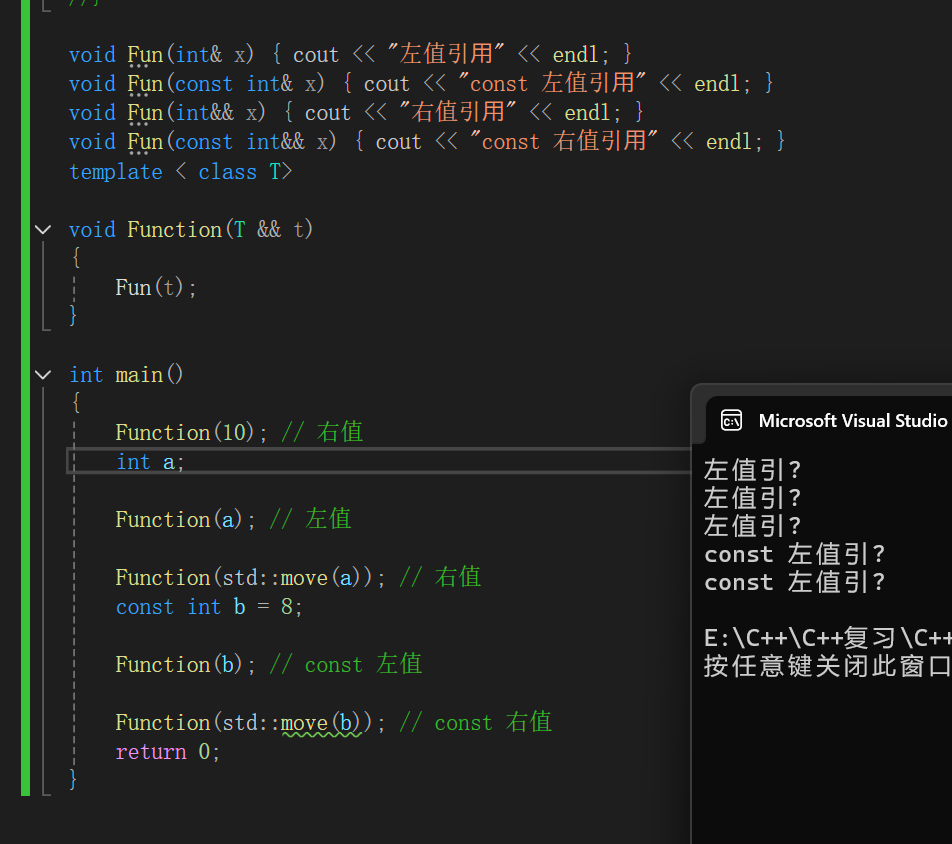
因为我们要记得一个点,右值引用的属性是一个左值,所以t在Funciton 函数里是一个左值,而左值就会调用左值引用。但我们其实想的是,如果它是右值就调用右值引用,是左值就调用左值引用。
这里就要介绍完美转发。其实完美转发它也是强转,只是通过过滤,它是右值就强转成右值,是左值就强转成左值。

---------------------------------------------------本篇文章就到这里,感谢各位观看



![[AD] Reaper NBNS+LLMNR+Logon 4624+Logon ID](https://i-blog.csdnimg.cn/img_convert/f637a972eb11fa5b163f1a2fdfd5f98a.jpeg)