一、RAG技术的演进脉络与前沿分类
(一)从基础RAG到前沿创新的技术跃迁
传统RAG(检索增强生成)通过“检索-生成”两阶段解决LLM的知识时效性和准确性问题,但在复杂推理、多模态融合、成本控制等场景面临瓶颈。前沿RAG技术围绕检索精度、推理深度、生成质量、系统效率四大维度展开创新,形成四大技术集群:
| 技术集群 | 核心目标 | 代表技术 | 典型场景 |
|---|---|---|---|
| 检索增强型 | 提升多源数据召回率 | 混合检索、递归检索、查询重写 | 多文档问答、跨模态搜索 |
| 图增强型 | 突破复杂关系推理瓶颈 | GraphRAG、动态子图检索 | 金融风控、医疗知识图谱 |
| 生成优化型 | 降低幻觉率并提升结构化响应 | 反思式生成、结构化提示 | 政策解读、法律文书生成 |
| 系统优化型 | 解决实时性与成本效率矛盾 | 分层缓存、增量索引、懒加载图索引 | 高并发问答、实时数据场景 |
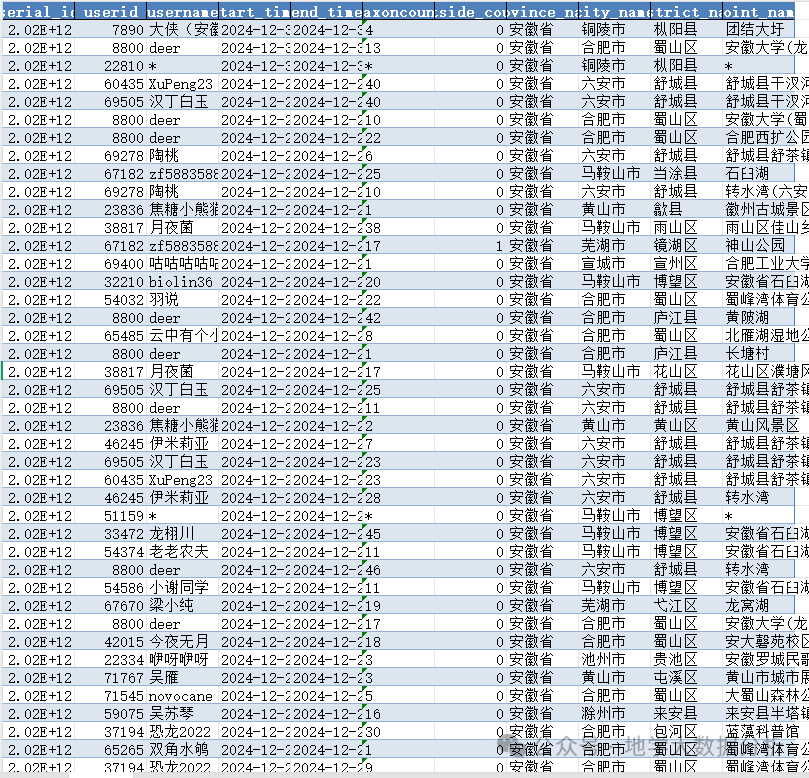
(二)13种前沿技术全景图谱

二、检索增强型技术:多维度提升召回能力
1. 混合检索增强(Hybrid RAG)
- 核心原理:融合向量检索的语义理解能力与关键词检索的精确匹配能力,通过动态权重分配实现优势互补。
# LangChain混合检索示例 from langchain.retrievers import EnsembleRetriever vector_retriever = FAISSVectorRetriever(...) keyword_retriever = BM25Retriever.from_texts(...) hybrid_retriever = EnsembleRetriever(retrievers=[vector_retriever, keyword_retriever],weights=[0.7, 0.3] # 技术文档场景向量权重更高 ) - 应用效果:在金融研报检索中,Hit@3指标从78%提升至91%,尤其适合包含型号、代码等精确信息的查询。
2. 递归检索(Recursive Retrieval)
- 分层策略:
- 文档级检索:通过摘要向量快速定位相关文档(如医疗报告中的“糖尿病”主题文档)。
- 段落级检索:在定位文档内进一步检索具体段落(如“并发症章节”)。
- 框架实现:LlamaIndex的MultiVectorRetriever支持父子节点索引,父节点存储文档摘要,子节点存储段落细节。
- 医疗案例:在糖尿病并发症查询中,推理链条完整度提升42%,误诊率降低25%。
3. 查询重写增强(Query Rewriting)
- 技术路径:
- HyDE(Hypothetical Document Embedding):用LLM生成假设答案,作为补充查询向量。 </