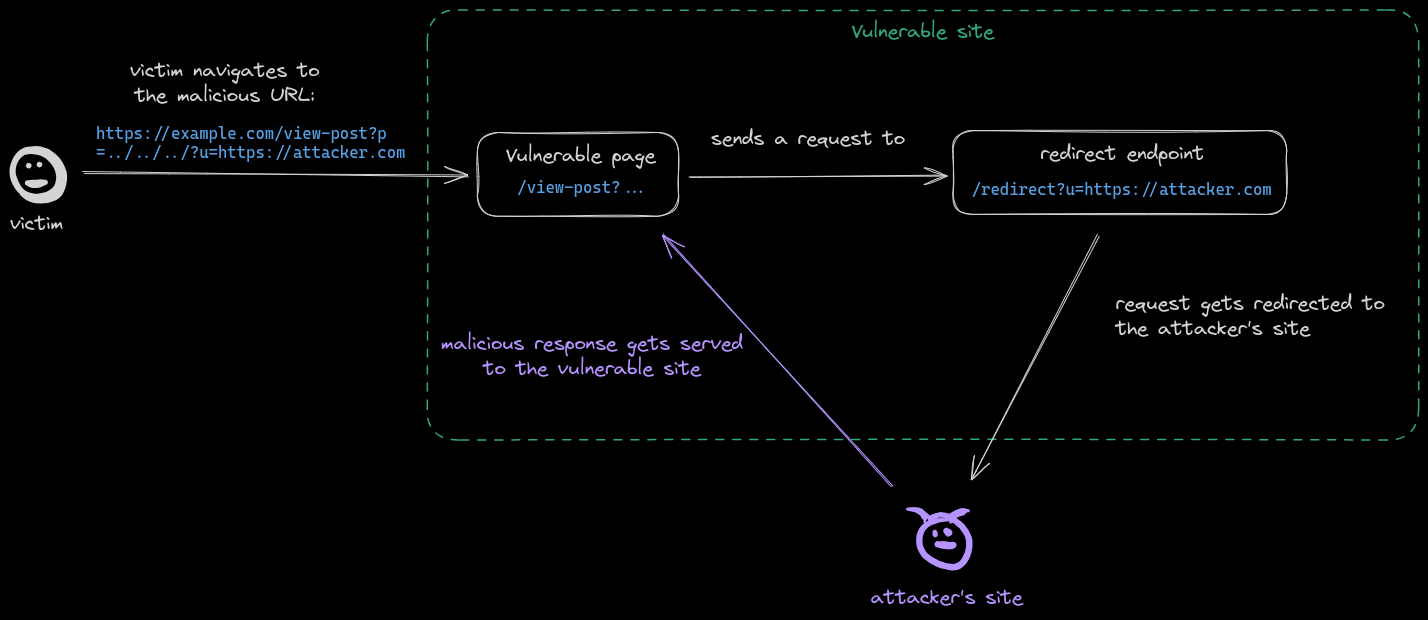
最大边际相关性(MMR,max_marginal_relevance_search)的基本思想是同时考量查询与文档的 相关度,以及文档之间的 相似度。相关度 确保返回结果对查询高度相关,相似度 则鼓励不同语义的文档被包含进结果集。具体来说,它计算每个候选文档与查询的 相关度,并减去与已经入选结果集的文档的最大 相似度,这样更不相似的文档会有更高分。
而在 LangChain 中MMR 的实现过程和 FAISS 的 带过滤器的相似性搜索 非常接近,同样也是先执行相似性搜索,并得到一个远大于 k 的结果列表,例如 fetch_k 条数据,然后对搜索得到的 fetch_k 条数据计算文档之间的相似度,通过加权得分找到最终的 k 条数据。
简单来说,MMR 就是在一大堆最相似的文档中查找最不相似的,从而保证 结果多样化。
所以 MMR 在保证查询准确的同时,尽可能提供 多样化结果,以增加信息检索的有效性和多样性,MMR 的运行演示图如下: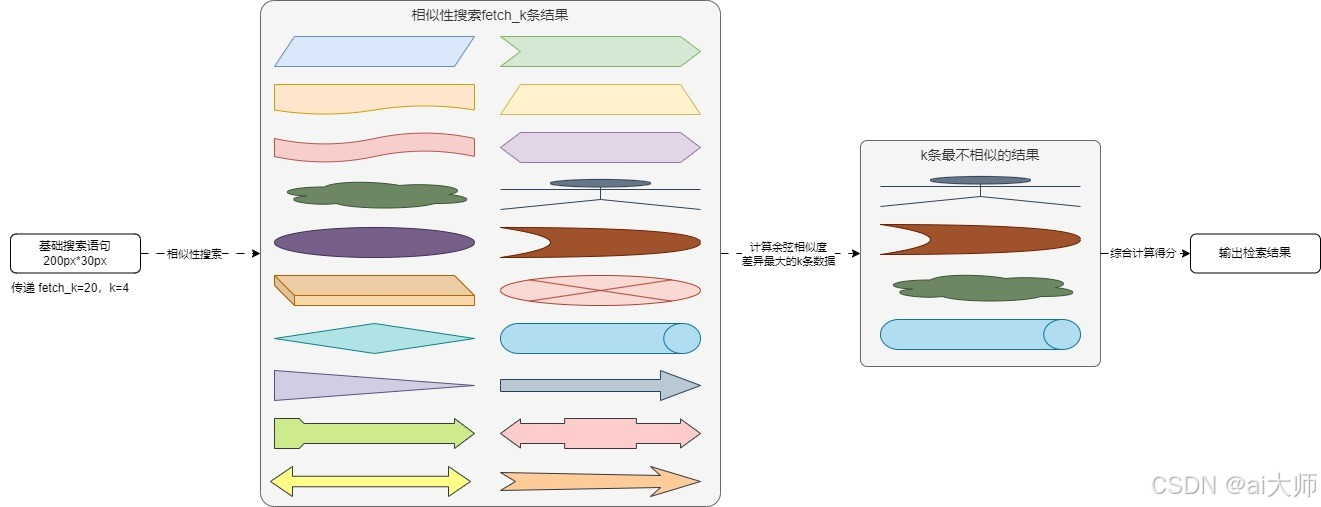
根据上面的运行流程,执行一个 MMR 最大边际相似性搜索需要的参数为:搜索语句、k条搜索结果数据、fetch_k条中间数据、多样性系数(0代表最大多样性,1代表最小多样性),在 LangChain 中也是基于这个思想进行封装,max_marginal_relevance_search() 函数的参数如下:
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
- ✨模型优惠查询
query:搜索语句,类型为字符串,必填参数。
k:搜索的结果条数,类型为整型,默认为 4。
fetch_k:要传递给 MMR 算法的的文档数,默认为 20。
lambda_mult:函数系数,数值范围从0-1,底层计算得分 = lambda_mult *相关性 - (1 - lambda_mult)*相似性,所以 0 代表最大多样性、1 代表最小多样性。
kwargs:其他传递给搜索方法的参数,例如 filter 等,这个参数使用和相似性搜索类似,具体取决于使用的向量数据库。
使用示例:
import dotenv
import weaviate
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_weaviate import WeaviateVectorStoredotenv.load_dotenv()# 1.构建加载器与分割器
loader = UnstructuredMarkdownLoader("./项目API文档.md")
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", "。|!|?", "\.\s|\!\s|\?\s", ";|;\s", ",|,\s", " ", "", ],is_separator_regex=True,chunk_size=500,chunk_overlap=50,add_start_index=True,
)# 2.加载文档并分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)# 3.将数据存储到向量数据库
db = WeaviateVectorStore(client=weaviate.connect_to_local("192.168.2.120", "8080"),index_name="DatasetDemo",text_key="text",embedding=OpenAIEmbeddings(model="text-embedding-3-small"),
)
db.add_documents(chunks)# 4.执行最大边际相关性搜索
search_documents = db.max_marginal_relevance_search("关于应用配置的接口有哪些?")# 5.打印搜索的结果
print(list(document.page_content[:100] for document in search_documents))
返回结果:
['1.2 [todo]更新应用草稿配置信息\n\n接口说明:更新应用的草稿配置信息,涵盖:模型配置、长记忆模式等,该接口会查找该应用原始的草稿配置并进行更新,如果没有原始草稿配置,则创建一个新配置作为草稿配', 'LLMOps 项目 API 文档\n\n应用 API 接口统一以 JSON 格式返回,并且包含 3 个字段:code、data 和 message,分别代表业务状态码、业务数据和接口附加信息。\n\n业务状态', '如果接口需要授权,需要在 headers 中添加 Authorization ,并附加 access_token 即可完成授权登录,示例:\n\njson\nAuthorization: Bearer ey', 'memory_mode -> string:记忆类型,涵盖长记忆 long_term_memory 和 none 代表无。\nstatus -> string:应用配置的状态,drafted 代表草稿、']
在 LangChain 封装的 VectorStore 组件中,内置了两种搜索策略:相似性搜索、最大边际相关性搜索,这两种策略有不同的使用场景,一般来说 80% 的场合使用相似性搜索都可以得到不错的效果,对于一些追求创新/创意/多样性的 RAG 场景,可以考虑使用 最大边际相关性搜索。
并且在执行 MMR 搜索时,如果向量数据库的规模越大,一般 fetch_k 设置的值越大,在 k 的大概2~3倍左右,如果添加了 filter 对数据进行筛选,则可以考虑在将 fetch_k 扩大到 k 的 4~6 倍。
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
- ✨模型优惠查询
在使用 相似性搜索 时,尽可能使用 similarity_search_with_relevance_scores() 方法并传递阈值信息,确保在向量数据库数据较少的情况下,不将一些不相关的数据也检索出来,并且着重调试 得分阈值(score_threshold),对于不同的文档/分割策略/向量数据库,得分阈值并不一致,需要经过调试才能得到一个相对比较正确的值(阈值过大检索不到内容,阈值过小容易检索到不相关内容)。


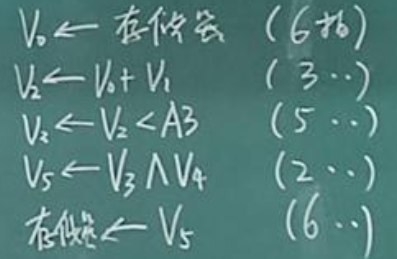

![[ElasticSearch] RestAPI](https://i-blog.csdnimg.cn/direct/ef5ee4a6bccf4b08a672c87b9ed962c0.png)