Are Bigger Encoders Always Better in Vision Large Models?
➡️ 论文标题:Are Bigger Encoders Always Better in Vision Large Models?
➡️ 论文作者:Bozhou Li, Hao Liang, Zimo Meng, Wentao Zhang
➡️ 研究机构: 北京大学
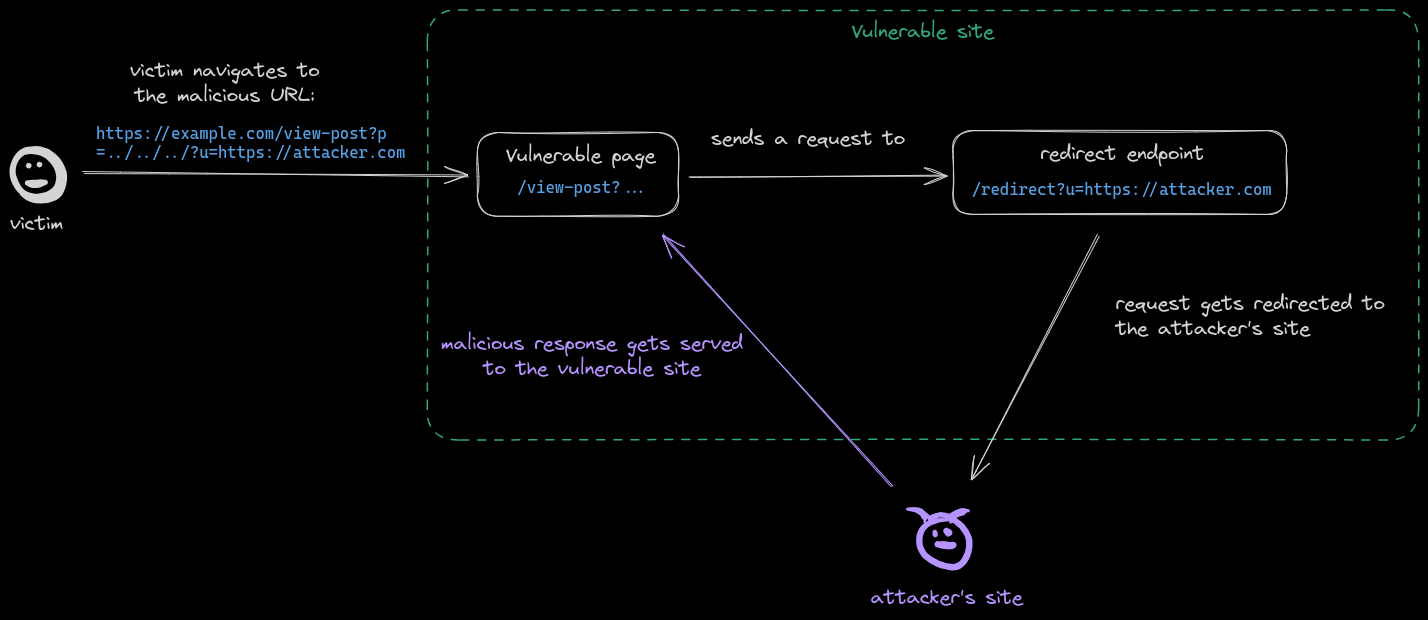
➡️ 问题背景:近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在现实世界应用中展现出强大的潜力。这些模型因其卓越的多模态信息理解能力和强大的认知推理能力而迅速发展。在MLLMs中,视觉语言模型(Vision Language Models, VLMs)因其理解视觉信息的能力而尤为突出。然而,当前主流范式下的VLMs的扩展趋势尚未得到广泛研究,是否通过训练更大的模型可以实现更好的性能仍不清楚。
➡️ 研究动机:现有的研究尚未充分探讨连接视觉范式(Connected Vision Paradigm)下的VLMs的扩展规律。为了填补这一空白,研究团队通过实验探讨了不同编码器大小和大语言模型(LLMs)大小对VLMs性能的影响,旨在为未来的模型设计和优化提供有价值的见解。
➡️ 方法简介:研究团队采用LLaVA1.5模型作为研究的骨干,利用7亿和13亿参数的模型进行实验。实验数据集包括从CC12M和Laion400M中提取的100万到1000万张图像-文本对。通过这些实验,研究团队系统地评估了不同数据量和模型大小对VLMs性能的影响。
➡️ 实验设计:实验分为两个阶段:多模态预训练(Multimodal Pretraining, MM PT)和多模态指令微调(Multimodal Instruction Fine-tuning, MM IT)。在MM PT阶段,研究团队使用不同的ViT模型大小和Vicuna系列的LLM模型进行训练,通过评估损失函数的变化来分析模型性能。实验结果表明,增加数据量和使用更大的LLM骨干可以提高模型性能,但单纯增加ViT的参数规模并不一定能提升VLMs的性能。此外,高质量的数据集对模型性能的提升至关重要。
Coarse Correspondences Boost Spatial-Temporal Reasoning in Multimodal Language Model
➡️ 论文标题:Coarse Correspondences Boost Spatial-Temporal Reasoning in Multimodal Language Model
➡️ 论文作者:Benlin Liu, Yuhao Dong, Yiqin Wang, Zixian Ma, Yansong Tang, Luming Tang, Yongming Rao, Wei-Chiu Ma, Ranjay Krishna
➡️ 研究机构: University of Washington, Tsinghua University, Tencent, Google Deepmind, Allen Institute for AI, Cornell University
➡️ 问题背景:多模态语言模型(Multimodal Language Models, MLLMs)在现实世界的应用中,需要具备解释3D空间和理解时间动态的能力。然而,现有的方法通常依赖于专门的架构设计或特定任务的微调来实现这一点。这些方法在3D和长视频理解基准测试中的表现仅略好于仅基于文本的基线模型,表明空间-时间推理是MLLMs通向通用视觉智能的主要瓶颈。
➡️ 研究动机:为了增强MLLMs的空间-时间推理能力,研究团队提出了一种简单且无需训练的视觉提示方法——COARSE CORRESPONDENCES。该方法通过2D图像输入,无需修改架构或特定任务的微调,即可显著提升MLLMs的空间-时间推理能力。
➡️ 方法简介:COARSE CORRESPONDENCES方法包含四个步骤:(1)跟踪对应关系,(2)稀疏化帧,(3)选择粗略对应关系,(4)可视化粗略对应关系。通过这些步骤,该方法能够从视频或不同视角的图像中提取主要对象的对应关系,并通过视觉提示将这些信息传达给MLLMs。
➡️ 实验设计:研究团队在六个基准测试上进行了广泛的实验,包括空间理解(如ScanQA和OpenEQA)和时间理解(如EgoSchema)任务。实验结果表明,COARSE CORRESPONDENCES不仅能够显著提升MLLMs在这些任务上的表现,而且在使用较少输入图像的情况下,其性能甚至超过了经过专门微调的模型。此外,该方法在导航任务(如R2R)中也表现出色,进一步证明了其在增强MLLMs空间-时间推理能力方面的有效性和效率。
Piculet: Specialized Models-Guided Hallucination Decrease for MultiModal Large Language Models
➡️ 论文标题:Piculet: Specialized Models-Guided Hallucination Decrease for MultiModal Large Language Models
➡️ 论文作者:Kohou Wang, Xiang Liu, Zhaoxiang Liu, Kai Wang, Shiguo Lian
➡️ 研究机构: AI Innovation Center, China Unicom, Beijing; Unicom Digital Technology, China Unicom, Beijing
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在连接视觉和语言模态方面取得了显著进展。然而,这些模型在生成文本时经常出现幻觉(hallucinations),即生成的文本与图像内容不一致,这严重限制了MLLMs的实际应用。
➡️ 研究动机:现有的解决MLLMs幻觉问题的方法主要分为基于训练和无训练两类。基于训练的方法通常需要重新训练模型,这不仅耗时且成本高昂;而无训练的方法则主要集中在后处理阶段,利用其他大型模型来纠正MLLMs的输出,这种方法同样耗时且经济性差。为了解决这些问题,研究团队提出了一种新的无训练框架Piculet,通过利用多个专门的小型深度学习模型来增强MLLMs的输入表示,从而减少幻觉。
➡️ 方法简介:Piculet框架通过使用多个专门的小型深度学习模型(如对象检测、OCR和人脸识别模型)来提取输入图像中的事实信息,并将这些信息与原始图像和用户查询一起输入到MLLMs中。这些专门模型的输出作为外部知识,帮助MLLMs生成更准确的结果。
➡️ 实验设计:研究团队在POPE、MME和LLaVA-QA90三个数据集上进行了实验,评估了Piculet框架的有效性。实验结果表明,Piculet在减少MLLMs幻觉方面表现出色,特别是在LLaVA-QA90基准上,Piculet将Qwen-VL-Chat的准确率从6.1提高到了7.3。此外,Piculet框架仅需一次MLLMs的推理和几个小型深度学习模型的推理,具有高效、经济和易于集成的特点。
A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
➡️ 论文标题:A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
➡️ 论文作者:Jiaqi Wang, Hanqi Jiang, Yiheng Liu, Chong Ma, Xu Zhang, Yi Pan, Mengyuan Liu, Peiran Gu, Sichen Xia, Wenjun Li, Yutong Zhang, Zihao Wu, Zhengliang Liu, Tianyang Zhong, Bao Ge, Tuo Zhang, Ning Qiang, Xintao Hu, Xi Jiang, Xin Zhang, Wei Zhang, Dinggang Shen, Tianming Liu, Shu Zhang
➡️ 研究机构: 西北工业大学、乔治亚大学、陕西师范大学、电子科技大学、奥古斯塔大学、上海科技大学
➡️ 问题背景:随着数据量的爆炸性增长和技术的快速发展,多模态大语言模型(MLLMs)成为人工智能系统中的前沿技术。这些模型旨在无缝集成多种数据类型,包括文本、图像、视频、音频和生理序列数据,以应对现实世界应用中的复杂性,超越单模态系统的功能。
➡️ 研究动机:现有的多模态大语言模型在多种任务中表现出色,但它们在不同任务中的表现和挑战仍需深入研究。本文系统地回顾了MLLMs在多模态任务中的应用,分析了不同MLLMs的焦点,并指出了当前模型的不足,为未来的研究提供了方向。
➡️ 方法简介:研究团队通过构建一个全面的框架,从基本概念、主要架构、不同领域的性能、比较分析到未来研究的路线图,系统地回顾了MLLMs的发展。文章详细介绍了MLLMs的多模态输入编码器、特征融合机制和多模态输出解码器,以及如何通过预训练的大型语言模型(LLMs)处理多模态数据。
➡️ 实验设计:文章在视觉和音频任务中详细探讨了MLLMs的应用,包括图像理解和生成任务。实验设计了不同阶段的图像理解技术,从传统的特征提取方法到深度学习技术的应用,再到多模态图像理解和跨模态学习,以及强化学习在图像理解中的应用。通过这些实验,文章全面评估了MLLMs在不同任务中的表现和潜力。
Hallu-PI: Evaluating Hallucination in Multi-modal Large Language Models within Perturbed Inputs
➡️ 论文标题:Hallu-PI: Evaluating Hallucination in Multi-modal Large Language Models within Perturbed Inputs
➡️ 论文作者:Peng Ding, Jingyu Wu, Jun Kuang, Dan Ma, Xuezhi Cao, Xunliang Cai, Shi Chen, Jiajun Chen, Shujian Huang
➡️ 研究机构: 南京大学、浙江大学、美团、新加坡-浙江创新与人工智能联合实验室
➡️ 问题背景:多模态大语言模型(MLLMs)在多种视觉-语言理解和生成任务中表现出色。然而,这些模型有时会生成与给定图像不一致的内容,这种现象被称为“幻觉”(hallucination)。现有的研究主要集中在使用标准的、未受干扰的基准数据集来评估幻觉,忽略了现实世界中输入图像经常遇到的各种干扰(如裁剪、模糊等),这些干扰对于全面评估MLLMs的幻觉至关重要。
➡️ 研究动机:为了填补这一空白,研究团队提出了Hallu-PI,这是第一个专门用于评估多模态大语言模型在受干扰输入下的幻觉表现的基准数据集。Hallu-PI旨在通过引入多种图像干扰场景,全面评估MLLMs在处理受干扰输入时的幻觉问题,揭示现有模型的局限性,并为未来的改进提供方向。
➡️ 方法简介:研究团队构建了Hallu-PI数据集,该数据集包含7种干扰场景,共1,260张受干扰图像,涉及11种不同的对象类别。每个图像都配有详细的注释,包括存在性、属性和关系等细粒度的幻觉类型。此外,数据集还包含了一系列问题,适用于判别性和生成性任务。
➡️ 实验设计:研究团队在12个主流的MLLMs上进行了广泛的实验,包括GPT-4V和Gemini-Pro Vision等模型。实验设计了多种干扰类型(如噪声、模糊、天气、数字、图像拼接、图像裁剪和提示误导),以及不同类型的评估任务(如判别性和生成性任务),以全面评估模型在受干扰输入下的幻觉表现。实验结果表明,这些模型在处理受干扰输入时表现出显著的幻觉问题,尤其是在图像拼接、图像裁剪和提示误导等特定类型的干扰下。为了缓解这些问题,研究团队还设计了两个基线方法:Perturbed-Reminder和Perturbed-ICL,实验结果表明这些方法在一定程度上有效减少了模型的幻觉。
![[ElasticSearch] RestAPI](https://i-blog.csdnimg.cn/direct/ef5ee4a6bccf4b08a672c87b9ed962c0.png)