目录
摘要
Abstract
1 引言
2 准备工作
3 LaViLa
3.1 NARRATOR
3.2 REPHRASER
3.3 双编码器训练
总结
摘要
本周阅读的论文题目是《Learning Video Representations from Large Language Models》(《从大型语言模型中学习视频表征信息》)。本文中提出了LaViLa,这是一种通过利用大型语言模型来学习视频-语言表示的新方法。LaViLa将预训练的LLMs重新用于视觉输入,并对其进行微调以创建自动视频叙述者。与传统的视频文本对齐方法相比,自动生成的叙述具有许多优点,包括对长视频的密集覆盖、视觉信息和文本的更好时间同步以及文本的更高多样性。LaViLa通过这些额外的自动生成叙述进行对比学习的视频-文本嵌入在多个第一人称和第三人称视频任务上,无论是在零样本还是微调设置中都优于之前的最佳水平。
Abstract
This week's paper is titled "Learning Video Representations from Large Language Models." In this paper, LaViLa, a new method for learning video-language representations by utilizing large language models, is proposed. LaViLa repurposes pre-trained LLMs for visual input and fine-tunes them to create automated video narrators. Auto-generated narratives have a number of advantages over traditional video-text alignment methods, including dense coverage of long videos, better time synchronization of visual information and text, and greater diversity of text. LaViLa uses these additional auto-generated narratives for contrastive learning video-text embedded on multiple first-person and third-person video tasks, both at zero shot and in fine-tuned settings, which are better than the previous best.
1 引言
使用网络规模的图像文本数据学习视觉表征信息是计算机视觉的一个强大工具,并且视觉语言方法在各种任务中推动了最前沿的发展,包括零样本分类、新颖物体检测甚至图像生成。然而,与数十亿规模的图像文本数据集相比,类似的方法在视频方面受到了配对视频文本语料库规模较小的限制,尽管在过去十年中原始视频数据的获取激增。生成式视觉语言模型(VLM)最初用于图像/视频标题,使用循环网络和基于Transformer的架构,生成式VLM通过在视觉-文本对上训练多模态Transformer统一了多个视觉任务,并且生成式VLM也擅长通过零样本或小样本提示进行多模态任务。所以,在本文中展示了通过利用生成式VLM自动生成此类视频的文本配对,从而充分利用大量视频数据,再使用这些自动生成的注释学习视频语言模型得到更强的表征信息。
本文中使用的方法为LaViLa,即Language-model augmented Video-Language pre-trainin(语言模型增强视频语言预训练),利用预训练的LLMs,其权重中包含丰富的知识宝库和对话能力,来用于“视觉条件叙述者”,并在所有可用的视频-文本配对片段上进行微调。如下图所示,LaViLa利用LLMs对长视频进行密集叙述,并使用这些叙述来训练强大的双编码器模型:
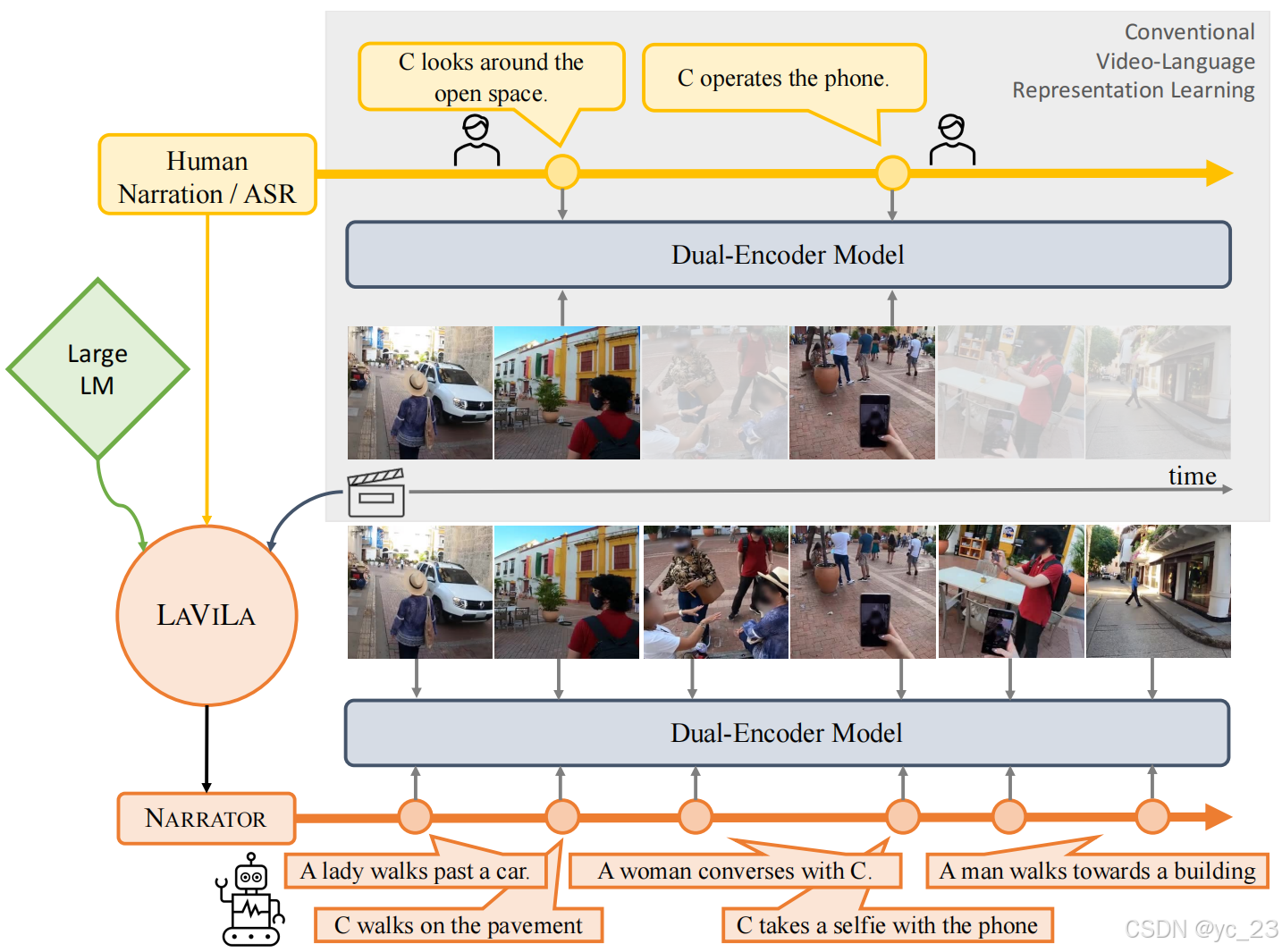
而先前的工作使用的是人类标注的稀疏文本,或者从语音转录的弱对齐文本,而LaViLa能够利用由LLM生成的密集、多样且对齐良好的文本。一旦训练完成,使用该模型通过生成丰富的文本描述来密集标注数千小时的视频。这种伪监督可以渗透整个视频,包括注释片段之间和之外。与另一个训练用于改写现有叙述的LLM相结合,LaViLa能够为视频-文本对比学习创建更大、更多样化的文本目标。
LaViLa的出色表现可以归因于多个因素:
- 可以提供时间上的密集监督长视频;
- 生成的文本与视觉输入很好地对齐;
- 能够自动对每个视频进行多次且密度更高的叙述,从而在只有少量可用的情况下显著扩展注释学习到更强的表征。
2 准备工作
视频 是一系列动态图像
的流,视频的帧数
可以任意长,而视频模型通常在较短的剪辑上操作,这些剪辑通常在几秒钟的范围内。因此,在浏览长篇视频时使用一组
个短剪辑来表示它,即
,每个剪辑
由特定的起始和结束帧定义,
,其中
,并且通常与某些注释
相关联,这种注释可以是类别标签或剪辑的自由形式文本描述。然后用带有相应注释的注释剪辑集来表示视频,即
。但是由于注释成本和视觉冗余,注释剪辑通常不能密集地覆盖整个视频,即
。
典型的视频模型 通过标准训练目标(如交叉熵损失)从这些剪辑级别注释中学习,当注释是具有固定词汇的分类标签时。然而,最近基于双编码器的对比方法(如CLIP)已经变得流行。它们使用自由形式的文本注释,这些注释被标记化成离散符号的序列,即
。该模型由一个视觉编码器
,一个投影头
和一个文本编码器
,以及一个投影头
并行获得全局视觉和文本嵌入分别:
,
.
CLIP代码如下:
class CLIP(nn.Module):def __init__(self,embed_dim: int,# visionvision_width: int,vision_model: nn.Module,# textcontext_length: int,vocab_size: int,transformer_width: int,transformer_heads: int,transformer_layers: int,tempearture_init=0.07,**kwargs,):super().__init__()self.context_length = context_lengthself.vision_width = vision_widthself.visual = vision_modelself.transformer = Transformer(width=transformer_width,layers=transformer_layers,heads=transformer_heads,attn_mask=self.build_attention_mask(),)self.vocab_size = vocab_sizeself.token_embedding = nn.Embedding(vocab_size, transformer_width)self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))self.ln_final = nn.LayerNorm(transformer_width) # used to be `models.transformer.LayerNorm``self.image_projection = nn.Parameter(torch.empty(vision_width, embed_dim))self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))print("=> initialize initial temperature with {}".format(tempearture_init))self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / tempearture_init))self.initialize_parameters()def initialize_parameters(self):nn.init.normal_(self.token_embedding.weight, std=0.02)nn.init.normal_(self.positional_embedding, std=0.01)proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)attn_std = self.transformer.width ** -0.5fc_std = (2 * self.transformer.width) ** -0.5for block in self.transformer.resblocks:nn.init.normal_(block.attn.in_proj_weight, std=attn_std)nn.init.normal_(block.attn.out_proj.weight, std=proj_std)nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)nn.init.normal_(self.image_projection, std=self.vision_width ** -0.5)nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)def build_attention_mask(self):# lazily create causal attention mask, with full attention between the vision tokens# pytorch uses additive attention mask; fill with -infmask = torch.empty(self.context_length, self.context_length)mask.fill_(float("-inf"))mask.triu_(1) # zero out the lower diagonalreturn maskdef encode_image(self, image, use_checkpoint=False, apply_project=True):x = self.visual(image, use_checkpoint=use_checkpoint)if isinstance(x, list):assert len(x) == 1x = x[0]if not apply_project:return xx = x @ self.image_projectionreturn xdef encode_text(self, text, use_checkpoint=False):x = self.token_embedding(text) # [batch_size, n_ctx, d_model]x = x + self.positional_embeddingx = x.permute(1, 0, 2) # NLD -> LNDx = self.transformer(x, use_checkpoint=use_checkpoint)x = x.permute(1, 0, 2) # LND -> NLDx = self.ln_final(x)# x.shape = [batch_size, n_ctx, transformer.width]# take features from the eot embedding (eot_token is the highest number in each sequence)x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projectionreturn xdef forward(self, image, text, use_checkpoint=False, norm_embed=False):image_embed = self.encode_image(image, use_checkpoint=use_checkpoint)text_embed = self.encode_text(text, use_checkpoint=use_checkpoint)if norm_embed:image_embed = F.normalize(image_embed, dim=-1)text_embed = F.normalize(text_embed, dim=-1)return {'image_embed': image_embed,'text_embed': text_embed,'logit_scale': self.logit_scale.exp()}一个对比损失(如InfoNCE)学习全局嵌入,将批次样本 中的对应视频和文本嵌入关联起来,得到:
.
损失函数代码如下:
class CLIPLoss(nn.Module):def __init__(self,use_vissl=False,local_loss=False,gather_with_grad=False,cache_labels=False,rank=0,world_size=1,):super().__init__()self.use_vissl = use_visslself.local_loss = local_lossself.gather_with_grad = gather_with_gradself.cache_labels = cache_labelsself.rank = rankself.world_size = world_size# cache stateself.prev_num_logits = 0self.labels = {}def forward(self, outputs):image_features = outputs['image_embed']text_features = outputs['text_embed']logit_scale = outputs['logit_scale']device = image_features.deviceif self.world_size > 1:if self.use_vissl:all_image_features = gather_from_all(image_features)all_text_features = gather_from_all(text_features)logits_per_image = logit_scale * all_image_features @ all_text_features.Tlogits_per_text = logits_per_image.Telse:all_image_features, all_text_features = gather_features(image_features, text_features,self.local_loss, self.gather_with_grad, self.rank, self.world_size)if self.local_loss:logits_per_image = logit_scale * image_features @ all_text_features.Tlogits_per_text = logit_scale * text_features @ all_image_features.Telse:logits_per_image = logit_scale * all_image_features @ all_text_features.Tlogits_per_text = logits_per_image.Telse:logits_per_image = logit_scale * image_features @ text_features.Tlogits_per_text = logit_scale * text_features @ image_features.T# calculated ground-truth and cache if enablednum_logits = logits_per_image.shape[0]if self.prev_num_logits != num_logits or device not in self.labels:labels = torch.arange(num_logits, device=device, dtype=torch.long)if self.world_size > 1 and self.local_loss:labels = labels + num_logits * self.rankif self.cache_labels:self.labels[device] = labelsself.prev_num_logits = num_logitselse:labels = self.labels[device]loss = (F.cross_entropy(logits_per_image, labels) +F.cross_entropy(logits_per_text, labels)) / 2# compute accuracywith torch.no_grad():pred = torch.argmax(logits_per_image, dim=-1)correct = pred.eq(labels).sum()acc = 100 * correct / logits_per_image.size(0)return {'loss': loss, 'clip_loss': loss, 'clip_acc': acc}3 LaViLa
在LaViLa 中,使用LLMs作为监督来训练双编码器模型,其中LLMs作为视觉条件叙述者自动从视频片段生成文本描述。LaViLa使用了来自两个LLMs的监督:
- NARRATOR:一种视觉条件下的LLM,用叙述对现有和新剪辑进行伪标签,生成新的注释
;
- REPHRASER:一种标准的LLM,对现有剪辑中的叙述进行释义,增强这些注释到
。
如下图所示,NARRATOR生成对正在发生的行为的新描述,可能关注其他与之交互的对象;REPHRASER用于增强文本输入,例如改变人类叙述的词序,并替换常见的动词或名词,使注释更加多样化:

最后,在所有这些注释的组合上训练双编码器,即。
3.1 NARRATOR
传统LLMs被训练从头开始生成一系列文本标记 ,通过建模给定所有已看到的标记的下一个标记的概率:
。NARRATOR将现有的LLMs重新用于条件化视觉输入,并在原始注释
上训练,然后在完整视频上产生密集的新注释
。遵循语言模型中因子概率的公式,建模视觉条件化文本似然:
.
如下图所示,NARRATOR紧密遵循标准LLMs的架构以视频帧为输入,通过视频编码器获得视觉嵌入,然后通过注意力池化获得。仅添加了几个额外的交叉注意力模块以提供视觉约束,文本解码器自回归地为这些新帧生成新的叙述:
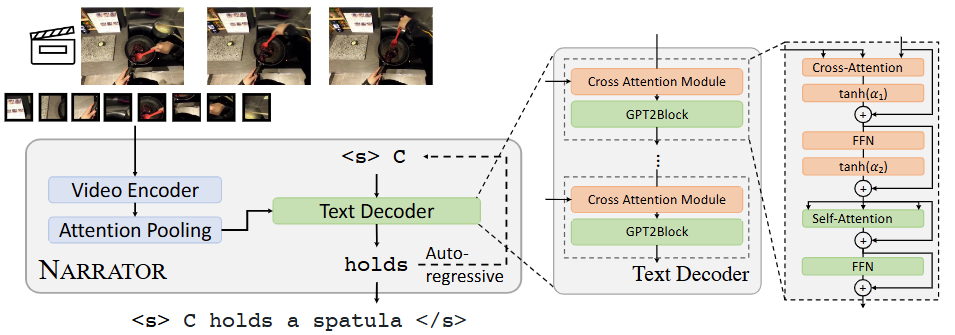
这使得NARRATOR能够从预训练的权重初始化,从而使得用于训练NARRATOR(与视频片段相关的叙述)的数据规模远小于通常用于训练LLMs的大规模文本语料库。
此外,视频叙述的多样性较低且噪声较大,因为它们要么是由少数注释员收集的,要么是从语音自动转录的。由此,在多模态少样本自适应中使用“冻结-LM”方法。在冻结的预训练模型LLM中:
- 在每个Transformer解码器层之前添加一个交叉注意力模块,以便文本输入可以关注视觉信息;
- 然后,通过残差连接将交叉注意力输出与输入文本特征相加,并进入 Transformer 解码器层;
- 每个交叉注意力模块包含一个交叉注意力层,该层将文本标记作为查询,将视觉嵌入作为键和值;
- 之后是一个前馈网络(FFN);
- 在交叉注意力和 FFN 的开始处应用层归一化;
- 还添加了tanh门,初始值为零,使得新模型的输出在开始时与原始语言模型相同。
虽然任何视频模型的特征都适用于条件化,但为了方便,本文中采用上一节中的视频编码器 ,该编码器在真实数据
上进行了对比训练。然后使用全局池化之前的特征,以便LLM能够利用细粒度的时空信息。
在训练过程中,训练NARRATOR非所有或真实标注的子集 。对于每一对
,字幕损失是每个步骤中正确单词的负对数似然之和:
.
在推理时,通过输入视觉输入 加上一个特殊的句子起始标记
来查询NARRATOR ,然后递归地从分布中进行采样,即
直到到达句尾标记
。在每一步中,从包含绝大多数概率质量的词元子集中采样,这被称为原子核采样,核采样效果有两方面:
- 一方面,它比基于最大似然的方法生成更多样化、开放式和类似人类的文本;
- 另一方面,由于没有基于句子级似然的后处理采样,生成的文本可能包含无关或噪声信息。
为了解决这个问题,在相同的视觉输入上重复采样过程 次,对比预训练目标对采样引起的噪声具有鲁棒性,最终性能得益于更多样化的叙述集。
为了对视频片段进行字幕采样:
- 首先,简单地重新为数据集
中标记的现有片段添加字幕,从而扩展了注释;
- 此外,长视频通常叙述稀疏,这意味着所有标记片段的时间总和无法覆盖整个视频;
- 因此,使用NARRATOR来注释视频的剩余部分,通过伪字幕获得额外的注释;
- 在简单地假设视频是平稳过程的前提下,从视频中均匀地采样片段未标记的区间,剪辑时长等于所有真实剪辑的平均值,即
,当采样步长同样计算后;
- 最后,通过结合重新配对的和伪配对的叙述,称NARRATOR为生成的最终标注集
最后进行后处理,来彻底的伪配对可能包含一些无信息的视觉片段,并生成无用的文本。因此,添加一个过滤过程以消除低质量片段及其相关描述。使用在真实配对片段上训练的基线双编码器模型 ,计算伪标签对的视觉和文本嵌入,并根据相似度分数进行过滤,即
,其中
可以是所有生成文本的前百分之几或阈值过滤。在本实验中,使用 0.5 的阈值。
代码如下:
class VCLM_HF(nn.Module):def __init__(self,# visionvision_width: int,vision_model: nn.Module,# texttext_width: int,text_decoder: nn.Module,num_img_queries=256,dim_head=64,heads=8,**kwargs,):super().__init__()self.vision_width = vision_widthself.visual = vision_modelself.text_width = text_widthself.text_decoder = text_decoderself.img_queries = nn.Parameter(torch.empty(num_img_queries, text_width))self.img_attn_pool = CrossAttention(dim=text_width, context_dim=vision_width,dim_head=dim_head, heads=heads,norm_context=True)self.img_attn_pool_norm = LayerNorm(text_width)self.initialize_parameters()def initialize_parameters(self):nn.init.normal_(self.img_queries, std=self.text_width ** -0.5)def encode_image(self, image, use_checkpoint=False):if isinstance(self.visual, VisionTransformer):# openai_model.VisionTransformer accepts (N, C, H, W) instead of (N, C, T, H, W)image = image.permute(0, 2, 1, 3, 4) # BCTHW -> BTCHWbb, tt, _, _, _ = image.shapex = self.visual(image.reshape(-1, *image.shape[2:]), use_checkpoint=use_checkpoint, cls_at_last=False) # NLDx = x.view(bb, tt, *x.shape[1:])x = x.permute(0, 3, 1, 2)elif isinstance(self.visual, SpaceTimeTransformer):image = image.permute(0, 2, 1, 3, 4).contiguous() # BCTHW -> BTCHWbb, tt, _, _, _ = image.shapex = self.visual.forward_features(image, use_checkpoint=use_checkpoint, cls_at_last=False) # NLDx = x.permute(0, 2, 1)else:x = self.visual(image, use_checkpoint=use_checkpoint, mean_at_last=False)if isinstance(x, list):assert len(x) == 1x = x[0]x = x.flatten(start_dim=2) # BDTHW -> BD(THW)x = x.permute(0, 2, 1) # BDN -> BNDimg_queries = repeat(self.img_queries, 'n d -> b n d', b=x.shape[0])img_queries = self.img_attn_pool(img_queries, x)img_queries = self.img_attn_pool_norm(img_queries)return img_queriesdef forward(self, image, text, mask=None, use_checkpoint=False, norm_embed=False):if use_checkpoint:self.text_decoder.gradient_checkpointing_enable()else:self.text_decoder.gradient_checkpointing_disable()text, labels = text[:, :-1], text[:, 1:]# mask = mask[:, :-1]image_tokens = self.encode_image(image, use_checkpoint=use_checkpoint)output_decoder = self.text_decoder(text.contiguous(), encoder_hidden_states=image_tokens)text_tokens_logits = output_decoder.logitstext_tokens_logits = rearrange(text_tokens_logits, 'b n c -> b c n')return {'text_tokens_logits': text_tokens_logits,'labels': labels}def generate(self, image_tokens, tokenizer, target=None, max_text_length=77, top_k=None, top_p=None,num_return_sequences=1, temperature=1.0, teacher_forcing=False, early_stopping=False):image_tokens = image_tokens.repeat_interleave(num_return_sequences, dim=0)device = image_tokens.devicegenerated_text_ids = torch.LongTensor([[tokenizer.bos_token_id]] * image_tokens.shape[0]).to(device)condition_text_ids = generated_text_ids.clone()logits_warper = self._get_logits_warper(top_k=top_k, top_p=top_p, typical_p=None, temperature=temperature, num_beams=1)nlls, num_tokens = torch.zeros(image_tokens.shape[0]).to(device), torch.zeros(image_tokens.shape[0]).to(device)is_reach_eos = torch.zeros(image_tokens.shape[0]).bool().to(device)with torch.no_grad():for i in range(max_text_length - 1):output_decoder = self.text_decoder(condition_text_ids, encoder_hidden_states=image_tokens)decoded_token_logits = output_decoder.logitsnext_token_logits = decoded_token_logits[:, -1, :]if target is not None:nll = F.cross_entropy(next_token_logits, target[:, i+1], ignore_index=tokenizer.pad_token_id, reduction='none')nlls += nllnum_tokens += target[:, i+1].ne(tokenizer.pad_token_id)else:nll = torch.special.entr(F.softmax(next_token_logits, dim=1)).sum(dim=1)nlls += nll * (~is_reach_eos)num_tokens += (~is_reach_eos)# filtered_p = top_k_top_p_filtering(next_token_logits, top_k=top_k, top_p=top_p, device=device)next_token_logits = logits_warper(generated_text_ids, next_token_logits)filtered_p = F.softmax(next_token_logits, dim=-1)next_token = torch.multinomial(filtered_p, num_samples=1)is_reach_eos = is_reach_eos | (next_token[:, 0] == tokenizer.eos_token_id)if early_stopping and torch.all(is_reach_eos):breakif teacher_forcing:condition_text_ids = target[:, :i+2]else:condition_text_ids = torch.cat((generated_text_ids, next_token), dim=1)generated_text_ids = torch.cat((generated_text_ids, next_token), dim=1)if target is not None:return generated_text_ids, torch.exp(nlls / num_tokens)else:return generated_text_ids, torch.exp(nlls / num_tokens)def beam_sample(self, image_tokens, tokenizer, target=None, max_text_length=77, top_k=None, top_p=None,temperature=1.0, length_penalty=1.,num_beams=3, num_return_sequences=1, teacher_forcing=False, early_stopping=False):batch_size = image_tokens.shape[0]device = image_tokens.deviceinput_ids = torch.ones((batch_size, 1), device=device, dtype=torch.long)input_ids = input_ids * tokenizer.bos_token_idexpanded_return_idx = (torch.arange(input_ids.shape[0]).view(-1, 1).repeat(1, num_beams * num_return_sequences).view(-1).to(device))input_ids = input_ids.index_select(0, expanded_return_idx)batch_beam_size, cur_len = input_ids.shapelogits_warper = self._get_logits_warper(top_k=top_k, top_p=top_p, typical_p=None, temperature=temperature, num_beams=num_beams)beam_scorer = BeamSearchScorer(batch_size=batch_size * num_return_sequences, num_beams=num_beams,device=device,length_penalty=length_penalty,)batch_size = len(beam_scorer._beam_hyps)num_beams = beam_scorer.num_beamsbeam_scores = torch.zeros((batch_size, num_beams)).to(device)beam_scores = beam_scores.view((batch_size * num_beams,))is_reach_eos = torch.zeros(batch_beam_size).bool().to(device)with torch.no_grad():for i in range(max_text_length - 1):output_decoder = self.text_decoder(input_ids,encoder_hidden_states=image_tokens.repeat_interleave(num_beams * num_return_sequences, dim=0))decoded_token_logits = output_decoder.logitsnext_token_logits = decoded_token_logits[:, -1, :]next_token_scores = F.log_softmax(next_token_logits, dim=-1) # (batch_size * num_beams, vocab_size)# supposed to be the line below, but ignore temporarily# next_token_scores_processed = logits_processor(input_ids, next_token_scores)next_token_scores_processed = next_token_scoresnext_token_scores = next_token_scores_processed + beam_scores[:, None].expand_as(next_token_scores)# supposed to be the line below, but do a simple top_k+top_p temporarilynext_token_scores = logits_warper(input_ids, next_token_scores)# next_token_scores = top_k_top_p_filtering(next_token_scores, top_k=top_k, top_p=top_p, device=device)vocab_size = next_token_scores.shape[-1]next_token_scores = next_token_scores.view(batch_size, num_beams * vocab_size)probs = F.softmax(next_token_scores, dim=-1)next_tokens = torch.multinomial(probs, num_samples=2 * num_beams)next_token_scores = torch.gather(next_token_scores, -1, next_tokens)next_token_scores, _indices = torch.sort(next_token_scores, descending=True, dim=1)next_tokens = torch.gather(next_tokens, -1, _indices)next_indices = torch.div(next_tokens, vocab_size, rounding_mode="floor")next_tokens = next_tokens % vocab_size# statelessbeam_outputs = beam_scorer.process(input_ids,next_token_scores,next_tokens,next_indices,pad_token_id=tokenizer.pad_token_id,eos_token_id=tokenizer.eos_token_id,)beam_scores = beam_outputs["next_beam_scores"]beam_next_tokens = beam_outputs["next_beam_tokens"]beam_idx = beam_outputs["next_beam_indices"]input_ids = torch.cat([input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)is_reach_eos = is_reach_eos | (input_ids[:, -1] == tokenizer.eos_token_id)if beam_scorer.is_done or torch.all(is_reach_eos):breaksequence_outputs = beam_scorer.finalize(input_ids,beam_scores,next_tokens,next_indices,pad_token_id=tokenizer.pad_token_id,eos_token_id=tokenizer.eos_token_id,max_length=max_text_length,)sequences = sequence_outputs["sequences"]sequence_scores = sequence_outputs["sequence_scores"]return sequences, sequence_scoresdef group_beam_search(self, image_tokens, tokenizer, target=None, max_text_length=77, top_k=None, top_p=None,temperature=1.0, length_penalty=1.,num_beams=6, num_beam_groups=3,num_return_sequences=1, teacher_forcing=False, early_stopping=False):batch_size = image_tokens.shape[0]device = image_tokens.deviceinput_ids = torch.ones((batch_size, 1), device=device, dtype=torch.long)input_ids = input_ids * tokenizer.bos_token_idexpanded_return_idx = (torch.arange(input_ids.shape[0]).view(-1, 1).repeat(1, num_beams).view(-1).to(device))input_ids = input_ids.index_select(0, expanded_return_idx)batch_beam_size, cur_len = input_ids.shapelogits_warper = self._get_logits_warper(top_k=top_k, top_p=top_p, typical_p=None, temperature=temperature, num_beams=num_beams)beam_scorer = BeamSearchScorer(batch_size=batch_size, num_beams=num_beams,num_beam_groups=num_beam_groups,num_beam_hyps_to_keep=num_return_sequences, device=device,length_penalty=length_penalty,)num_sub_beams = num_beams // num_beam_groupsbeam_scores = torch.full((batch_size, num_beams), -1e9, dtype=torch.float, device=device)beam_scores[:, ::num_sub_beams] = 0beam_scores = beam_scores.view((batch_size * num_beams,))is_reach_eos = torch.zeros(batch_beam_size).bool().to(device)with torch.no_grad():# predicted tokens in cur_len stepcurrent_tokens = torch.zeros(batch_size * num_beams, dtype=input_ids.dtype, device=device)# indices which will form the beams in the next time stepreordering_indices = torch.zeros(batch_size * num_beams, dtype=torch.long, device=device)for i in range(max_text_length - 1):output_decoder = self.text_decoder(input_ids,encoder_hidden_states=image_tokens.repeat_interleave(num_beams, dim=0))decoded_token_logits = output_decoder.logitsfor beam_group_idx in range(num_beam_groups):group_start_idx = beam_group_idx * num_sub_beamsgroup_end_idx = min(group_start_idx + num_sub_beams, num_beams)group_size = group_end_idx - group_start_idx# indices of beams of current group among all sentences in batchbatch_group_indices = []for batch_idx in range(batch_size):batch_group_indices.extend([batch_idx * num_beams + idx for idx in range(group_start_idx, group_end_idx)])group_input_ids = input_ids[batch_group_indices]# select outputs of beams of current group onlynext_token_logits = decoded_token_logits[batch_group_indices, -1, :]next_token_scores = F.log_softmax(next_token_logits, dim=-1) # (batch_size * num_beams, vocab_size)vocab_size = next_token_scores.shape[-1]# supposed to be the line below, but ignore temporarily# next_token_scores_processed = logits_processor(input_ids, next_token_scores)next_token_scores_processed = next_token_scoresnext_token_scores = next_token_scores_processed + beam_scores[batch_group_indices].unsqueeze(-1)next_token_scores = next_token_scores.expand_as(next_token_scores_processed)next_token_scores = logits_warper(input_ids, next_token_scores)# next_token_scores = top_k_top_p_filtering(next_token_scores, top_k=top_k, top_p=top_p, device=device)# reshape for beam searchnext_token_scores = next_token_scores.view(batch_size, group_size * vocab_size)next_token_scores, next_tokens = torch.topk(next_token_scores, 2 * group_size, dim=1, largest=True, sorted=True)next_indices = torch.div(next_tokens, vocab_size, rounding_mode="floor")next_tokens = next_tokens % vocab_size# statelessbeam_outputs = beam_scorer.process(group_input_ids,next_token_scores,next_tokens,next_indices,pad_token_id=tokenizer.pad_token_id,eos_token_id=tokenizer.eos_token_id,beam_indices=None)beam_scores[batch_group_indices] = beam_outputs["next_beam_scores"]beam_next_tokens = beam_outputs["next_beam_tokens"]beam_idx = beam_outputs["next_beam_indices"]input_ids[batch_group_indices] = group_input_ids[beam_idx]group_input_ids = torch.cat([group_input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)current_tokens[batch_group_indices] = group_input_ids[:, -1]reordering_indices[batch_group_indices] = (num_beams * torch.div(beam_idx, group_size, rounding_mode="floor") + group_start_idx + (beam_idx % group_size))input_ids = torch.cat([input_ids, current_tokens.unsqueeze(-1)], dim=-1)is_reach_eos = is_reach_eos | (input_ids[:, -1] == tokenizer.eos_token_id)if beam_scorer.is_done or torch.all(is_reach_eos):breaksequence_outputs = beam_scorer.finalize(input_ids,beam_scores,next_tokens,next_indices,pad_token_id=tokenizer.pad_token_id,eos_token_id=tokenizer.eos_token_id,max_length=max_text_length,beam_indices=None,)sequences = sequence_outputs["sequences"]sequence_scores = sequence_outputs["sequence_scores"]return sequences, sequence_scoresdef _get_logits_warper(self, top_k=None, top_p=None, typical_p=None,temperature=None, num_beams=None, renormalize_logits=None,):top_k = top_k if top_k is not None else 0top_p = top_p if top_p is not None else 1.0typical_p = typical_p if typical_p is not None else 1.temperature = temperature if temperature is not None else 1.warpers = LogitsProcessorList()if temperature is not None and temperature != 1.0:warpers.append(TemperatureLogitsWarper(temperature))if top_k is not None and top_k != 0:warpers.append(TopKLogitsWarper(top_k=top_k, min_tokens_to_keep=(2 if num_beams > 1 else 1)))if top_p is not None and top_p < 1.0:warpers.append(TopPLogitsWarper(top_p=top_p, min_tokens_to_keep=(2 if num_beams > 1 else 1)))if typical_p is not None and typical_p < 1.0:warpers.append(TypicalLogitsWarper(mass=typical_p, min_tokens_to_keep=(2 if num_beams > 1 else 1)))# `LogitNormalization` should always be the last logit processor, when presentif renormalize_logits is True:warpers.append(LogitNormalization())return warpers3.2 REPHRASER
NARRATOR生成数据比真实配对大几倍,为确保不会过度拟合伪标签数据,通过释义增加真实叙述的数量,特别是使用文本到文本的LLM,该模型建模条件文本似然:
.
如下图所示,REPHRASER输入叙述,通过文本编码器传递,并使用文本解码器自回归地生成重述的输出:
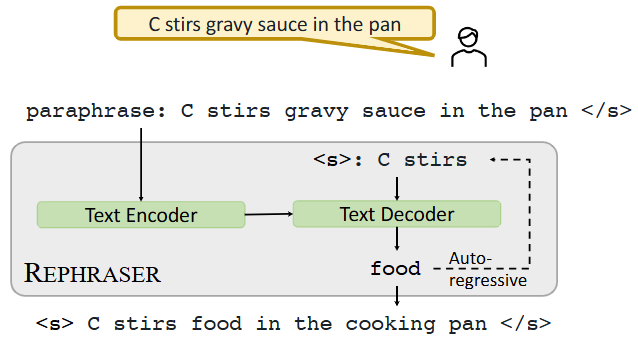
文本到文本模型通过编码器-解码器架构实现,例如T5,根据原始句子自动回归生成新句子。REPHRASER能够进行基本的操作,如替换同义词或改变词序,这作为自动数据增强的有效方式。生成的标注被称为 。
3.3 双编码器训练
在每次迭代中,首先采样一个视频片段批次 。它包括带有标记时间戳和叙述的片段子集
,以及从无叙述的视频中随机采样的片段子集
。对于片段
,通过查询NARRATOR
获得伪字幕
,从而得到带有LLM生成的叙述的片段集
。对于片段
,文本监督来自REPHRASER或NARRATOR,概率为0.5,称由此产生的对为
。类似地,遵循CLIP,在批次中样本的相似度得分上使用对称交叉熵损失
。
在实践中,提前运行REPHRASER和NARRATOR并缓存生成的视频-叙述对,以便在预训练期间没有计算开销,因此,在LaViLa中训练双编码器与训练标准双编码器对比模型一样快。
def VCLM_OPENAI_TIMESFORMER_LARGE_336PX_GPT2_XL(gated_xattn=False,freeze_lm_vclm=False,freeze_visual_vclm=False,freeze_visual_vclm_temporal=False,num_frames=4,timesformer_gated_xattn=False,**kwargs,
):vision_model = SpaceTimeTransformer(img_size=336, patch_size=14,embed_dim=1024, depth=24, num_heads=16,num_frames=num_frames,time_init='zeros',attention_style='frozen-in-time',ln_pre=True,act_layer=QuickGELU,is_tanh_gating=timesformer_gated_xattn,)clip_model, _ = load_openai_clip('ViT-L/14@336px', 'cpu')print("=> Loading CLIP (ViT-L/14@336px) weights")remapped_state_dict = remap_keys(clip_model.visual.state_dict(), transformer_layers=24)res = vision_model.load_state_dict(remapped_state_dict, strict=False)print(res)vision_model.head = nn.Identity()vision_model.pre_logits = nn.Identity()vision_model.fc = nn.Identity()gpt2 = GPT2LMHeadModel.from_pretrained("gpt2-xl",use_cache=False,)new_config = augment_gpt2_config(gpt2.config, cross_attn_freq=3, gated_xattn=gated_xattn)text_decoder = GatedGPT2LMHeadModel(new_config)for n, p in gpt2.named_parameters():rsetattr(text_decoder, n + '.data', p.data)if freeze_lm_vclm:print('Freeze the LM part of TextDecoder of VCLM')text_decoder.freeze_lm_weights()if freeze_visual_vclm:print('Freeze the spatial part of VideoEncoder of VCLM')vision_model.freeze_spatial_weights()if freeze_visual_vclm_temporal:print('Freeze the temporal part of VideoEncoder of VCLM')vision_model.freeze_temporal_weights()model = VCLM_HF(vision_width=1024,vision_model=vision_model,text_width=1600,text_decoder=text_decoder,num_img_queries=256,dim_head=64,heads=25,**kwargs,)return model总结
在本文中,提出了LaViLa,这是一种通过使用LLMs自动叙述长视频的新方法,用于视频-语言表示学习,为视频理解提供了一种高效的数据增强范式。LaViLa利用LLM生成伪标签,减少对人工标注的依赖。LaViLa的双编码器架构,即视频编码器与文本编码器通过对比学习对齐特征,支持跨模态检索和生成任务。LaViLa在使用相同数量的人叙述视频的基线模型上取得了显著的改进,并在六个流行的基准任务上取得了新的最先进成果,这些任务涵盖了第一人称和第三人称视频理解基准。当增加更多训练叙述、使用更大的视觉骨干网络和使用更强的LLMs时,LaViLa也显示出积极的缩放行为和性能。