一、SSD:单次多框检测器
1.1、基本信息
-
标题:SSD: Single Shot MultiBox Detector
-
作者:Wei Liu (UNC Chapel Hill), Dragomir Anguelov (Zoox Inc.), Dumitru Erhan, Christian Szegedy (Google Inc.), Scott Reed (University of Michigan), Cheng-Yang Fu, Alexander C. Berg (UNC Chapel Hill)
-
发表时间:2016年(基于参考文献中最新引用为2016年)
-
代码开源:weiliu89/caffe at ssd
原文地址:
[1512.02325] SSD: Single Shot MultiBox Detector
SSD: Single Shot MultiBox Detector | SpringerLink
1.2、主要内容
SSD(Single Shot MultiBox Detector)是一种单阶段目标检测模型,其核心创新包括:
多尺度特征图预测:
在不同层级的卷积特征图上生成不同尺度和长宽比的默认边界框(default boxes),覆盖多种物体尺寸。
通过卷积操作直接预测类别得分和边界框偏移量,无需候选区域生成(如Faster R-CNN中的RPN)。
高效的单次检测框架:
消除了传统方法中的像素重采样和特征池化步骤,所有计算集成在单一网络中,显著提升速度。
使用小卷积核(3×3)进行预测,保留空间信息的同时减少参数量。
数据增强与训练策略:
采用随机裁剪、缩放和颜色扰动增强数据,提升模型对小物体的检测能力。
通过“难例挖掘”(hard negative mining)平衡正负样本比例,优化训练过程。
性能优势:
输入分辨率300×300时,在VOC2007测试集上达到74.3% mAP,速度59 FPS(Titan X GPU),优于Faster R-CNN(73.2% mAP,7 FPS)和YOLO(63.4% mAP,45 FPS)。更
高分辨率(512×512)下,mAP提升至76.9%,速度仍接近实时(22 FPS)。
1.3、影响和作用
推动实时检测发展:
SSD是首个在保持高精度(>70% mAP)的同时实现实时检测(59 FPS)的模型,为嵌入式系统和实时应用(如自动驾驶、视频监控)提供了高效解决方案。
技术启发性:
多尺度特征图与默认框设计被后续模型(如RetinaNet、EfficientDet)广泛借鉴,成为单阶段检测器的经典范式。
证明了单阶段方法在速度和精度上可超越两阶段方法(如Faster R-CNN),推动目标检测领域向轻量化发展。
实际应用价值:
模型结构简单,易于与其他系统(如视频跟踪、多任务学习)集成,促进了工业界的快速落地。
在COCO等复杂场景数据集上表现优异,为密集和小物体检测提供了新思路。
学术贡献:
论文通过系统实验(如消融分析)验证了多尺度预测、数据增强等关键设计的有效性,为目标检测研究提供了重要参考。
开源代码极大推动了社区复现与改进,累计引用量超万次(截至2023年),成为目标检测领域的里程碑工作之一。
二、SSD
2.1、SSD介绍
注意:SSD是2016年的网络,它要比2015年的YOLOV1晚出来一年。
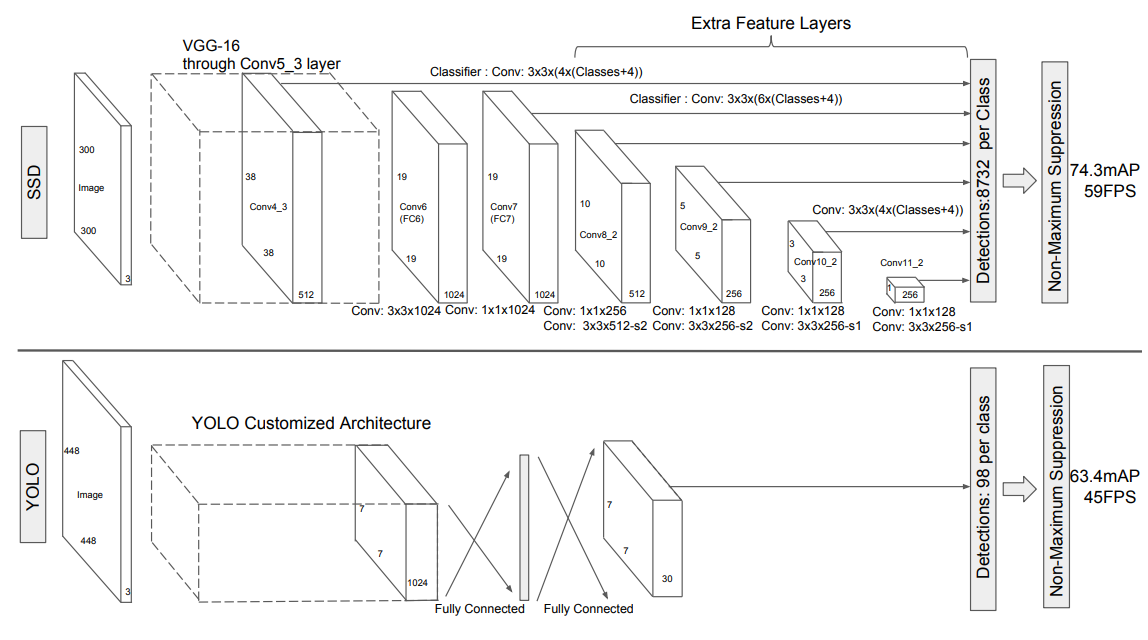
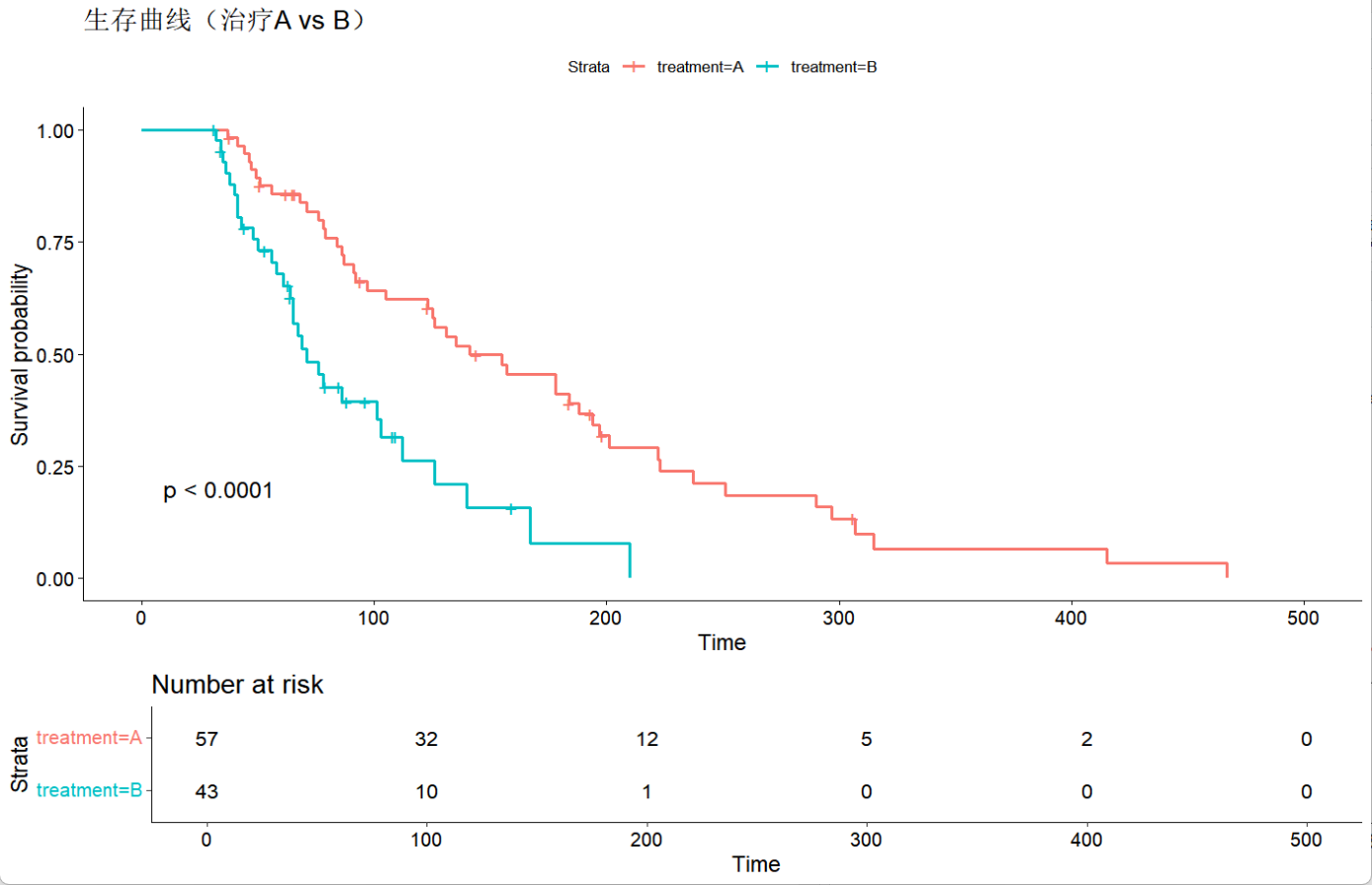
SSD速度与性能:
输入尺寸300x300的网络:使用NVIDIA Titan X帧率为59FPS,在 VOC2007测试集上74.3%mAP。
输入尺寸512x512的网络:在VOC2007测试集上76.9%mAP,超越当时最 强的FasterRCNN的73.2%mAP。
two-stage:找框+回归与分类。
one-stage:全部放在一个网络中实现。
Faster RCNN的问题:模型大速度慢、对小目标检测效果差(经过多次卷 积后,feature map的维度太高,3*3的感受野很大了,所以Anchor Box 很大导致很难预测小目标)(FPN优化了对小目标检测效果差的问题)。
原理:
SSD结合了多尺度特征图来检测不同大小的目标。其基本原理与实现流程 包括:
使用卷积神经网络(CNN)提取图像特征。
在不同层级的特征图上应用预测器来检测和定位目标。
使用默认框(default boxes)来处理不同尺度和比例的目标。
结合多层特征图的预测结果来提高检测性能和精度。
2.2、SSD网络结构
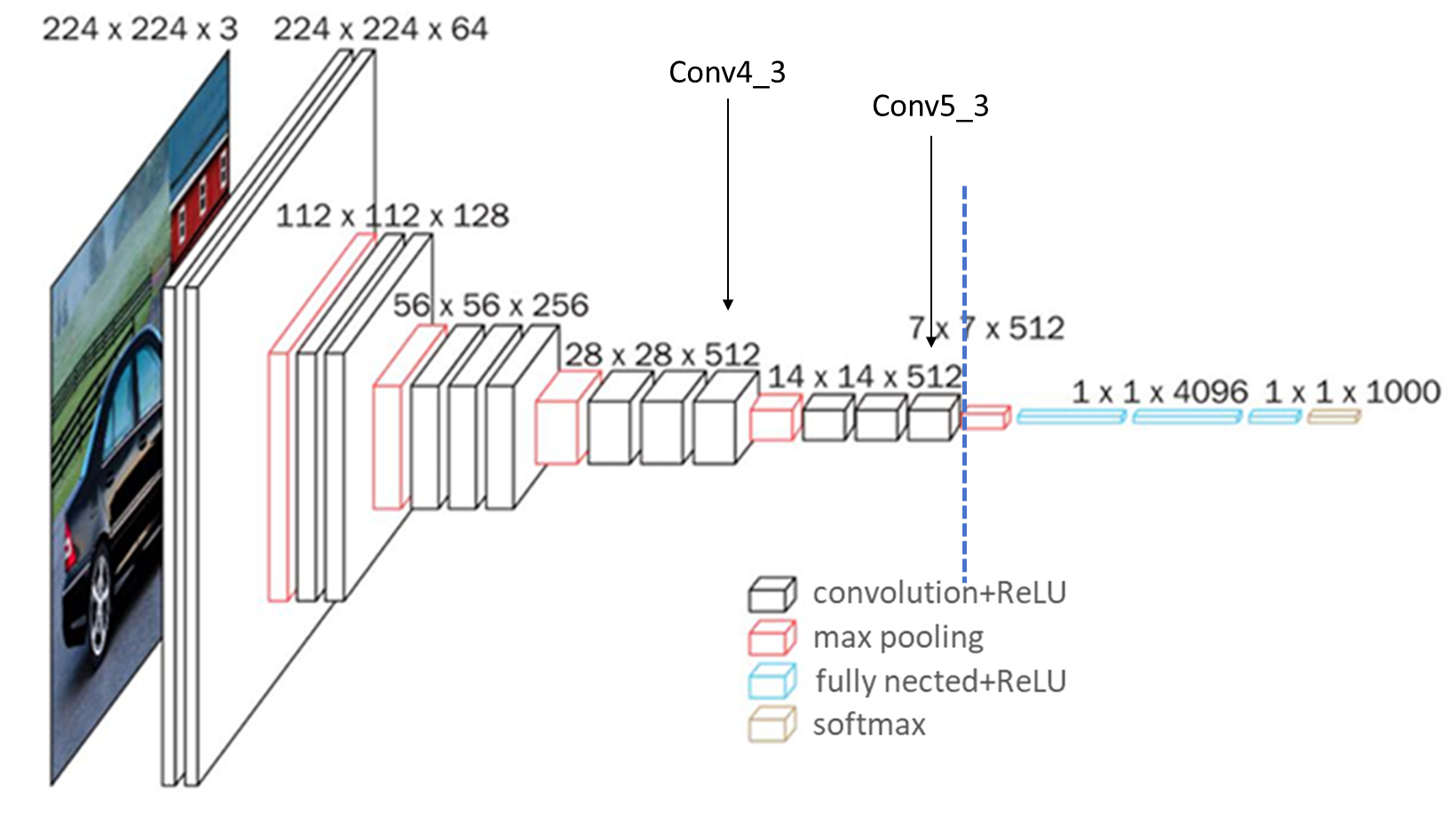
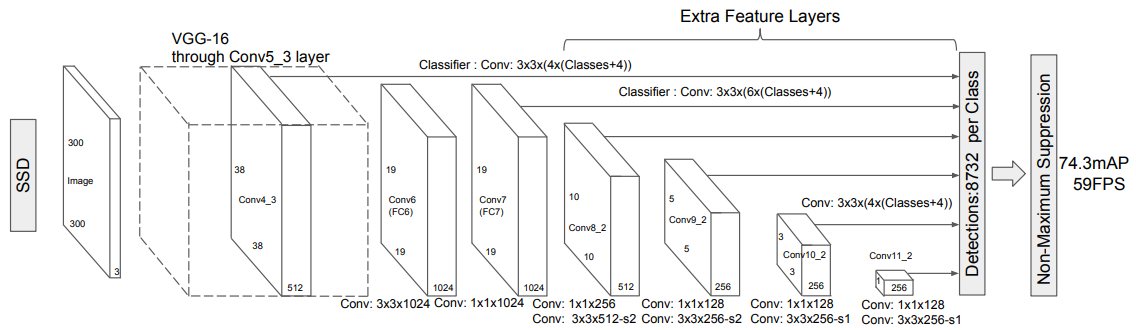
1. 将图片缩放到300x300,类似于OpenCV的resize,channels为3。
2. 通过到Pool5层:可以参考附录1的VGGNet16的网络特征图变化,输 入是300x300,经过5个conv组之后分别为:150->75->38->19,所以 显示的Conv4_3是38x38x512(这是一个预测特征层,称为预测特征层 1),在经过Conv4_3是19x19x512,正常的VGGNet-16接下来经过 Pool5(池化核2,步长2),但是SSD对Pool5做了修改(池化核3,步 长1,padding=1),所以在经过Pool5后,输出为19x19x512。
3. 经过Conv: 3x3x1024,得到19x19x1024的卷积结果,原始VGGNet16 的第一个全连接层(FC6)。
4. 经过Conv: 1x1x1024,得到19x19x1024的卷积结果(这是一个预测特 征层,称为预测特征层2),原始VGGNet16的第一个全连接层(FC7)。
5. 经过Conv: 1x1x256降维,在经过Conv: 3x3x512(s=2, padding=1)得到10x10x512(这是一个预测特征层,称为预测特征层 3)。
6. 经过Conv: 1x1x128降维,在经过Conv: 3x3x256(s=2, padding=1)得到5x5x256(这是一个预测特征层,称为预测特征层 4)。
7. 经过Conv: 1x1x128降维,在经过Conv: 3x3x256(s=1, padding=0)得到3x3x256(这是一个预测特征层,称为预测特征层 5)。
8. 经过Conv: 1x1x128降维,在经过Conv: 3x3x256(s=1, padding=0)得到1x1x256(这是一个预测特征层,称为预测特征层 6)。
卷积公式:feature-kernel+2*P/stride+1,向下取整。
在预测特征层上会预测不同大小的目标,在前面的预测特征层上会预测较 小的目标,在后面的预测特征层上会预测较大的目标。
2.3、在预测特征层进行预测
SSD中的具有一个叫默认框(default boxes)的东西,有时也称为先验框 (prior boxes),是预定义的一组边界框,用于在训练过程中预测目标的 位置和大小。
默认框的设计和使用是SSD算法的重要部分,其主要目的是高效地处理不 同尺度和不同宽高比的目标,有点像默认的Anchor Box。
默认框是在不同尺度和宽高比下,预先定义的一组边界框。每个默认框与 特定的特征图位置(像素)相关联,并且在训练过程中,网络会预测这些 默认框与实际目标边界框的偏移量和类别。
2.3.1、默认框的生成
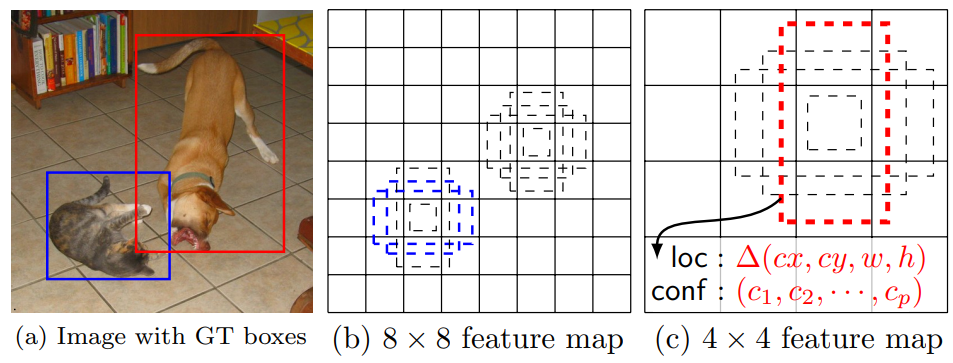
1. 特征图尺度: SSD在不同的特征图上生成默认框。通常,网络的早期层具有高分 辨率的特征图,用于检测小目标;后期层具有低分辨率的特征图, 用于检测大目标。
2. 框的数量和比例: 在每个特征图位置,SSD生成多个默认框,每个框具有不同的比例 和宽高比(如1:1、2:1、1:2、3:1、1:3等)。这使得默认框能够覆 盖不同形状和大小的目标。
3. 框的中心和大小: 每个默认框的中心与特征图的一个位置对齐,框的大小根据特征图 层的比例进行设置。具体公式如下: 假设特征图大小为m*m ,每个特征图位置会生成多个默认 框。 默认框的宽度和高度根据不同的比例和尺度进行设置。
2.3.2、PyTorch默认框的生成方案
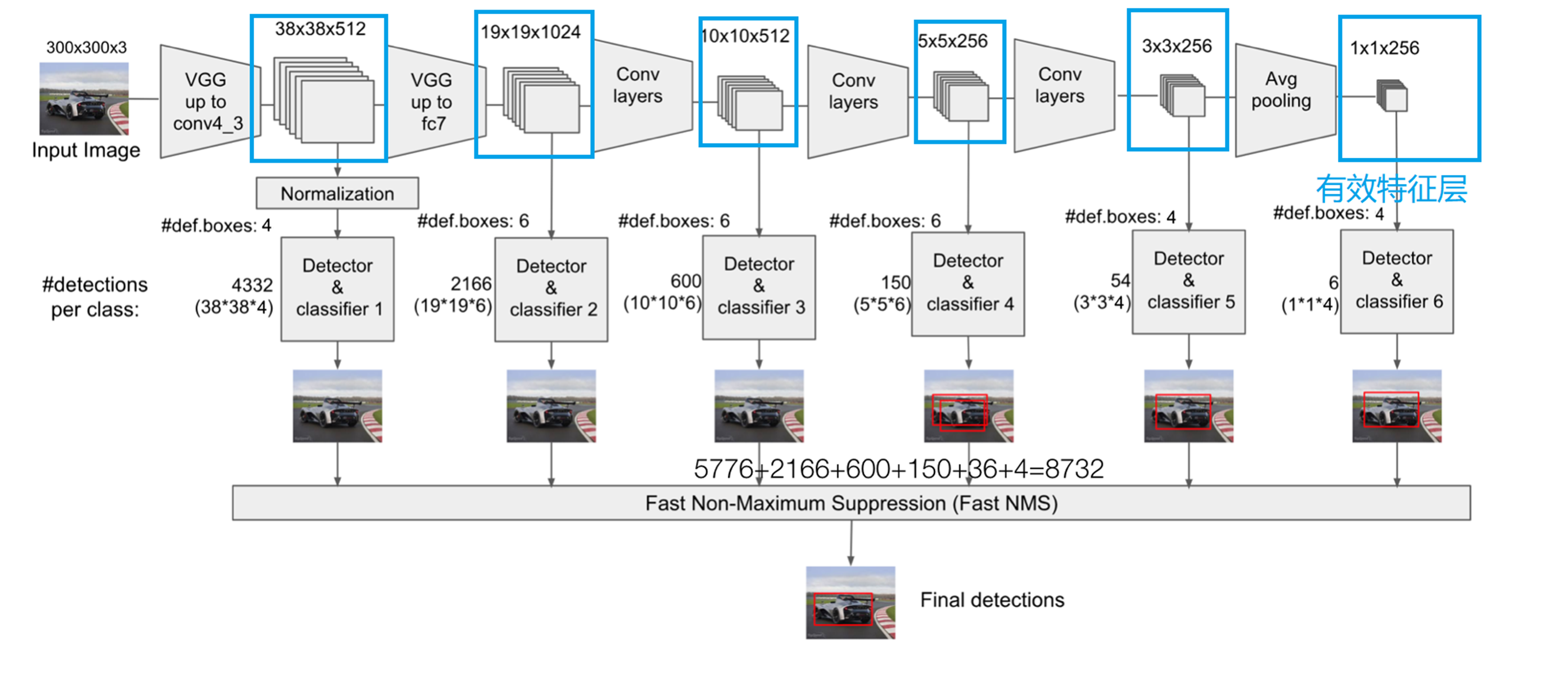
一共有6层预测特征层,分别为conv4_3、fc7、conv8_2、conv9_2、 conv10_2、conv11_2。
conv4_3 ==> 38 x 38
fc7 ==> 19 x 19
conv8_2 ==> 10 x 10
conv9_2 ==> 5 x 5
conv10_2 ==> 3 x 3
conv11_2 ==> 1 x 1
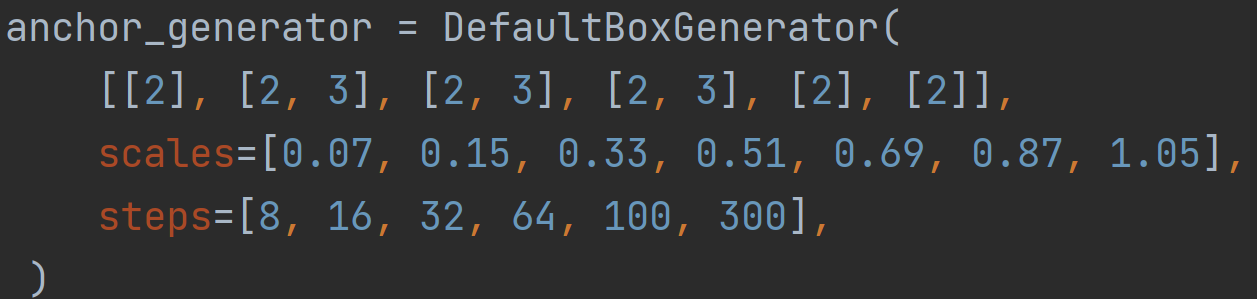
其中,DefaultBoxGenerator类: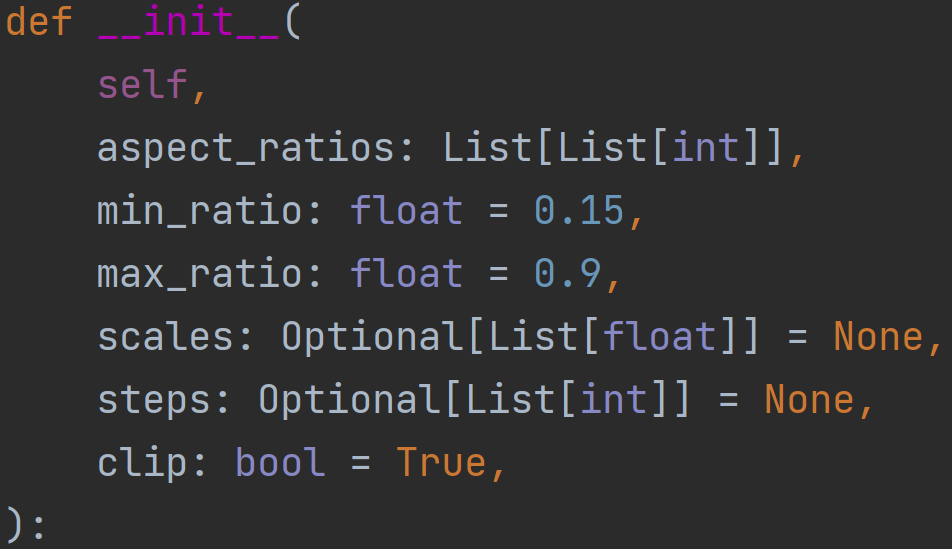
aspect_ratios参数
纵横比,输入的是 [[2], [2, 3], [2, 3], [2, 3], [2], [2]],对应 每一层的预测特征层的默认框的纵横比,这里的[2]指的是:比例为2,实 际上会附加上1:1的,结合上1:2,2:1的,也就是3个纵横比1:1、1:2, 2:1。
| 输入 | 纵横比 |
|---|---|
| [2] | 1:1 1:2 2:1 |
| [2, 3] | 1:1 1:2 2:1 1:3 3:1 |
| [2, 3] | 1:1 1:2 2:1 1:3 3:1 |
| [2, 3] | 1:1 1:2 2:1 1:3 3:1 |
| [2] | 1:1 1:2 2:1 |
| [2] | 1:1 1:2 2:1 |
min_ratio/max_ratio参数
这里即是论文中所说的Smin=0.2,Smax=0.9的初始值,经过下面的运算 即可得到min_sizes,max_sizes,只是在PyTorch中Smin=0.15,当scales 不传参的时候,使用它。

得到self.scale=[0.15, 0.3, 0.45, 0.6, 0.75, 0.9, 1.0]
scales参数

默认框数量
这6个特征层产生的特征图的大小分别为38*38、19*19、10*10、5*5、 3*3、1*1。每个n*n大小的特征图中有n*n个中心点,每个中心点产生k个 默认框,六层中每层的每个中心点产生的k分别为4、6、6、6、4、4(在 图中很大的物体和很小的物体要少于大小适中的物体的数量)。
所以6层中的每层取一个特征图共产生 38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732个默认框。
steps参数
steps参数是输入图像300x300与预测特征层的降采样的比例,即第一个参 数8,是2x2x2的结果,也就是经过3次降采样之后的比例,300/8=37.5, 即38。
这个参数的目的是为了绘制二维网格(类似于在机器学习中写代码时绘制 决策边界时的meshgrid)。最终乘以300即可得到在原图上的Anchor。
2.3.3、默认框举例
2.3.4、默认框的使用
1. 匹配机制:
在训练过程中,将默认框与真实边界框进行匹配。如果默认框与真 实边界框的重叠(通常使用交并比,IoU)超过某个阈值,则认为 该默认框匹配该真实目标。 未匹配的默认框通常被认为是背景类。
2. 预测偏移量:
SSD不直接预测边界框的坐标,而是预测默认框相对于真实边界框 的偏移量(即坐标调整量)。网络学习这些偏移量以调整默认框, 使其更接近真实目标。
3. 多框融合:
通过非极大值抑制(NMS)技术,过滤掉重叠度较高的冗余预测 框,仅保留最高置信度的预测结果。
2.3.5、默认框优点
1. 高效:
使用默认框,可以在一个前馈网络中同时预测多个尺度和宽高比的 目标,减少了计算复杂度,提高了检测速度。
2. 多尺度检测:
通过在不同尺度的特征图上生成默认框,SSD能够有效处理不同大 小的目标,适应多尺度检测的需求。
2.4、Predictor实现
对于每一个特征层,都会再经过一个3x3x (每个点的默认框个数 x (Classes+4)) 的卷积
为什么是:每个点的默认框个数 x (Classes+4)?
每个点的默认框个数 x (Classes+4) = 每个点的默认框个数 x Classes + 每 个点的默认框个数 x 4
Classes:目标检测类别数量+背景(例如Pascal VOC是21)。
每个点的默认框个数 x Classes:每个框的类别的概率,如果是4个框,每 个框都有21类的对应的概率,那就有4x21=84个。
每个点的默认框个数 x 4:每个框的x,y,w,h偏移量。
2.5、正负样本
正样本
1.与GT BOX的IoU最大的default Box。
2. 与GT BOX的IoU大于0.5的default Box。
负样本
将正样本选完的剩下的default Box进行confidence计算,选择一些最大的 confidence的default Box作为负样本,大概是正样本个数的3倍。如果剩 下的全是负样本,会导致正负样本失衡,网络表现变差。
2.6、损失函数的定义
SSD的损失函数是对分类和位置回归的多任务损失函数的组合。
它由两部分组成:分类损失(confidence loss)和定位损失(localization loss)。这两部分损失在训练过程中相加,用于模型同时学习分类和定位。

2.6.1、分类损失(Confidence Loss)

2.6.2、定位损失(Localization Loss)

2.7、 SSD的特点
与Faster RCNN相比的特点:
速度更快:SSD是一种端到端的算法,直接预测目标的类别和边界 框,避免了像Faster RCNN那样的两阶段检测过程,因此速度更 快。
简单直接:SSD通过在单个神经网络中处理检测和分类任务,简化 了整体流程。
多尺度特征融合:SSD通过使用多层特征图来检测不同大小的目 标,从而更好地处理多尺度的目标检测问题。
优点:
高效:速度快,适合实时应用。
简单:单一模型处理多个尺度和类别的检测。
高度集成:整合了目标定位和类别预测的任务。
缺点:
定位精度稍逊:相比于两阶段方法如Faster RCNN,在定位精 度上可能稍逊一筹。
默认框设计依赖:性能受默认框设计的影响,对不同数据集可 能需要调整。
SSD通过简化的单阶段检测方法和多层特征图的使用,实现了高效的目标 检测,尽管在一些精度方面可能略逊于两阶段方法,但在速度和简便性上 有明显优势。
![[Windows]在Win上安装bash和zsh - 一个脚本搞定](https://i-blog.csdnimg.cn/direct/3dc68110aee647cd8b7321ea4fa99694.png)