「迷思」是指经由人们口口相传,但又难以证明证伪的现象。由于 GPU 硬件实现、驱动实现是一个黑盒,我们只能通过厂商提供的 API、经过抽象的架构来了解并猜测其原理。因此坊间流传着各种关于与 GPU 打交道时的性能迷思。比如「移动端的瓶颈是带宽」、「移动端不需要太在意 Overdraw」、「植被需要做 PrePass」等等。这些优化手段,有时候我们对后面的原理一知半解,有时候又会随着硬件的发展而逐渐变得不适用,逐渐会变成一种神秘主义。
「迷思」是指经由人们口口相传,但又难以证明证伪的现象。由于 GPU 硬件实现、驱动实现是一个黑盒,我们只能通过厂商提供的 API、经过抽象的架构来了解并猜测其原理。因此坊间流传着各种关于与 GPU 打交道时的性能迷思。比如「移动端的瓶颈是带宽」、「移动端不需要太在意 Overdraw」、「植被需要做 PrePass」等等。这些优化手段,有时候我们对后面的原理一知半解,有时候又会随着硬件的发展而逐渐变得不适用,逐渐会变成一种神秘主义。
作者:mobiuschen
我希望可以结合一些现有资料,对这些「迷思」做定性的分析,避免一不小心变成了负优化。有条件时,甚至希望可以做一些定量分析的实验。
移动端架构
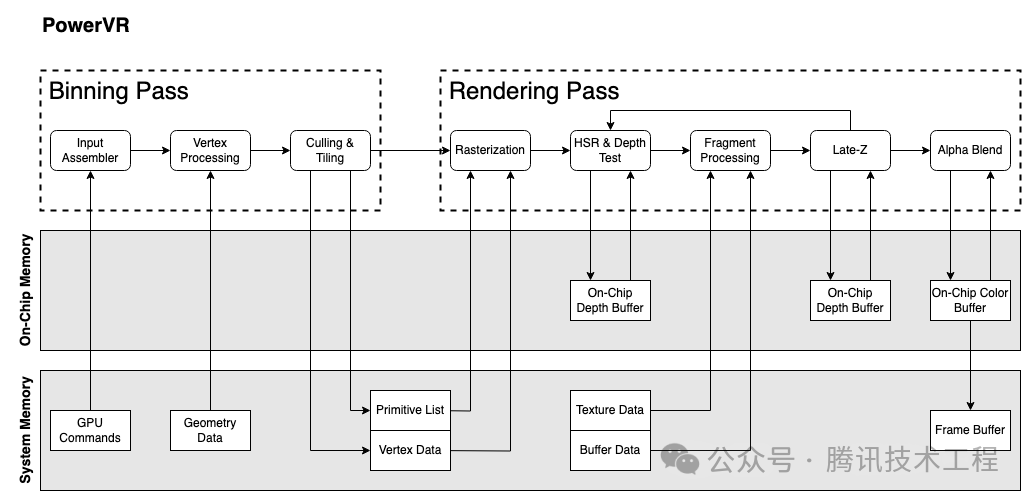
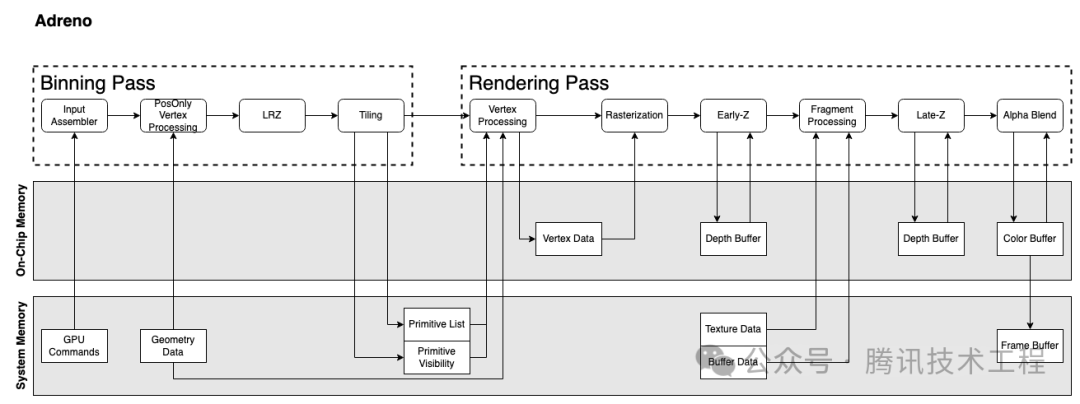
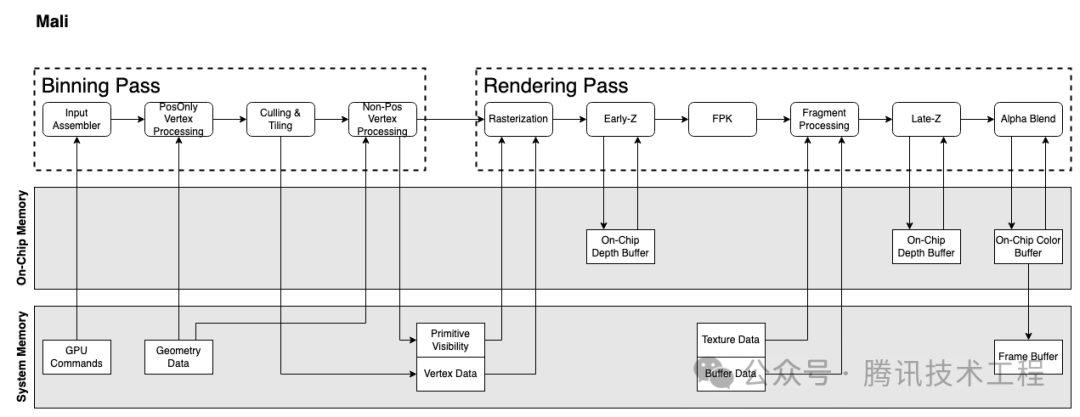
我们先简单过一下几个厂商的 GPU 架构。苹果的 GPU 架构查不到任何文档,只能姑且以多年前 PowerVR 的架构文档来替代。移动端的 GPU 现在都是 TBDR 架构,分为两个 Pass:Binning Pass 和 Rendering Pass。Binning Pass 将各个 Primitive 分到各个 Tile,Rendering pass 再在对这些 tile 进行渲染。
讲 GPU 结构的资料还是比较多,这里不再赘述。我们只着重讲几点不同架构上有差异、与后面「迷思」相关的功能点。
隐面剔除
「隐面剔除」技术这一术语来自于 PowerVR 的 HSR (Hidden Surface Removal),通常用来指代 GPU 对最终被遮挡的 Primitive/Fragment 做剔除,避免执行其 PS,以达到减少 Overdraw 的效果。
Adreno/Mali/PowerVR 三家在处理隐面剔除除的方式是不一样的。
PowerVR 的 HSR 原理是生成一个 visibility buffer,记录了每一个 pixel 的深度,用于对 fragment 做像素级的剔除。因为是逐像素级的剔除,因此需要放到 Rasterization 之后,也就是说每个三角形都需要做 Rasterization。根据 visibility buffer 来决定每一个像素执行哪个 fragment 的 ps。也因此,PowerVR 将自己 TBR (Tile Based Rendering) 称为 TBDR (Tile Based Deferred Rendering)。而且特别提到了一点,如果当出现一个 fragment 的深度无法在 vs 阶段就确定,那么就会等到 fragment 的 ps 执行完,确定了深度,再来填充对应的 visibility buffer。也就是说这个 fragment 会阻塞了 visibility buffer 的生成。这个架构来自于 PowerVR 2015年左右的文档,后续 Apple 继承了其架构,但是后面是否有做更进一步的架构优化不得而知。
Adreno 实现隐面剔除技术的流程称为 LRZ (Low Resolution Depth),其剔除的颗粒度是 Primitive 而不是 Fragment。在 Binning pass 阶段执行 Position-Only VS 时的会生成一张 LRZ buffer (低分辨率的 z buffer),将三角形的最小深度与 z buffer 做对比,以此判断三角形的可见性。Binning pass 之后,将可见的 triangle list 存入 SYSMEM,在 render pass 中再根据 triangle list 来绘制。相比于 PowerVR 的 HSR,LRZ 由于是 binning pass 做的,可以减少 Rasterization 的开销。并且在 render pass 中,也会有 early-z stage 来做 fragment 级别的剔除。对于那种需要在 ps 阶段才能决定深度的 fragment,就会跳过 LRZ,但是并不会阻塞管线。
Mali 实现隐面剔除的技术称为 FPK (Forward Pixel Killing)。其原理是所有经过 Early-Z 之后的 Quad,都会放入一个 FIFO 队列中,记录其位置与深度,等待执行。如果在执行完之前,队列中新进来一个 Quad A,位置与现队列中的某个 Quad B 相同,但是 A 深度更小,那么队列中的 B 就会被 kill 掉,不再执行。Early-Z 只可以根据历史数据,剔除掉当前的 Quad。而 FPK 可以使用当前的 Quad,在一定程度上剔除掉老的 Quad。FPK 与 HSR 类似,但是区别是 HSR 是阻塞性的,只有只有完全生成 visibility buffer 之后,才会执行 PS。但 FPK 不会阻塞,只会kill 掉还没来得及执行或者执行到一半的 PS。
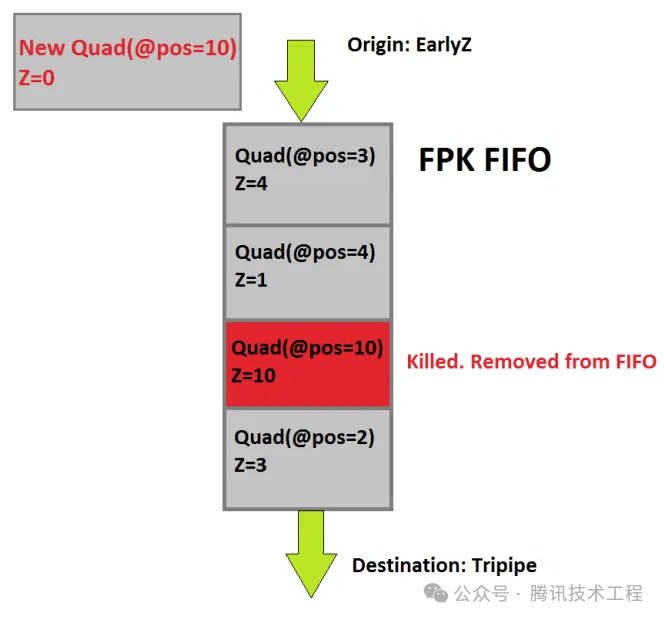
Vertex Shader 的执行
PowerVR 下,VS 是在 Binning Pass 阶段执行的,只会执行一次。
Adreno 和 Mali 都是会执行两次 VS。第一次都是 "PosOnly Vertex Processing",就是只执行 VS 中产出 position 相关的指令,只算出 Position 信息给 Binning 阶段使用。
第二次 VS 的执行,Mali 是在 binning 阶段,称为 "Varying Shading",只执行非 Position 的那部分逻辑。而 Adreno 的第二次 VS 的执行会放到 rendering 阶段,并且是执行全量的 VS。
为什么有这个区别呢?下个点 "VS Output" 会讲到。
VS Output
VS 阶段产出的数据称为 VS Output,或者称为 Post-VS Attributes。对这些数据的处理,不同架构也不大一样。
PowerVR,Binning Pass 阶段就已经执行了全量的 VS,然后会将 VS Output 写到 system memory。在 Rendering Pass 再重新读回来。
Adreno 架构下,Binning Pass 之后只产出两种数据并会将其写到 system memory:Primitive List 和 Primitive Visibility。在 Rendering Pass 会重新执行一遍 VS,产出 VS Output。这些数据不回写回 system memory,而是存在 On-Chip Memory (LocalBuffer),PS 阶段直接可以从 Local Buffer 读取。
这样就节省了很多的带宽消耗。
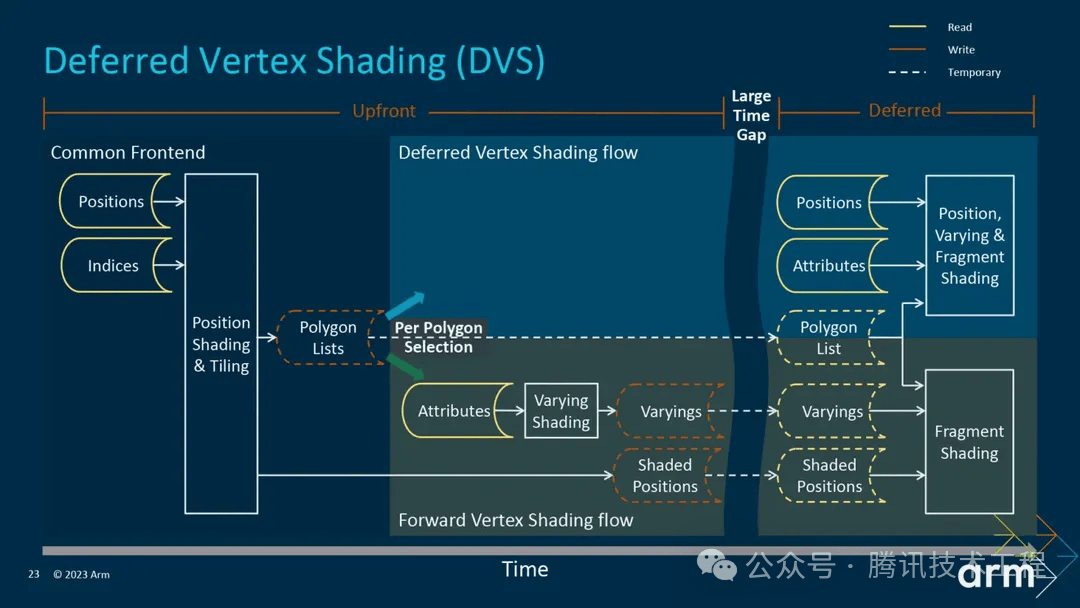
Mali 在第五代 GPU 架构 Immortalis 之前,第二遍 VS 会在 Binning Pass 执行完,并且把 VS Output 都写入 system memory,在 rendering pass 重新读出来。这样就会有带宽的消耗。于是第五代架构推出了 Deferred Vertex Shading (DVS),就是将 Varying Shading 延迟到 rendering 阶段再执行,这样就直接可以把数据存到 On-Chip Memory 给后面的 PS 使用,达到节省带宽的目的。
号称可以节省 20% -40% 的带宽。
移动端带宽是瓶颈
带宽就是单位时间内数据的传输量,其量化标准为「位宽 (bit wide) * 频率」。在位宽确定的情况下,只能通过增加工作频率来提高带宽。更高的频率意味着需要更高的电压,进而造成更高的功耗。功率 (P) 与电压 (V) 的关系 ,也就是说功耗与电压平方成正比。
「在移动端带宽是瓶颈」,源自于两方面:
带宽的发展与算力的发展不匹配
带宽的增加带来了大功耗
带宽的发展与算力的发展不匹配
带宽的增加带来了大功耗
下面这张图对比了算力、内存带宽、内部带宽的发展,可以看到 20 年间,硬件算力提升了 60000 倍,内存带宽提升了 100 倍,而内部带宽只提升了 30 倍。公路宽度提升了几十倍,车流量却变成了几万倍,当然公路的宽度就变成了瓶颈了。
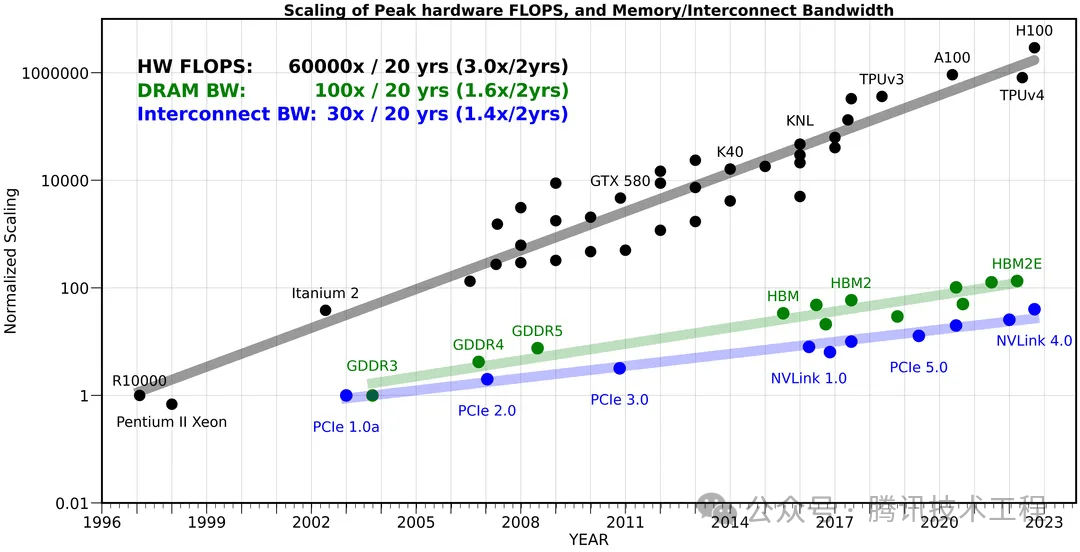
这个问题在移动端变得更加严重。因为在移动端,芯片面积有限,位宽无法做得很大。在手机上,内存位宽一般是 64-bit wide 或者 128-bit wide;而桌面端可以是 1024-bit wide,甚至搭配了 HBM (High Bandwidth Memory) 的显卡可以到 4096-bit wide。更高的位宽意味更高的面积和成本。因此,手机上只能通过提高电压来增加带宽。按照前面的公式,功率 (P) 与电压 (V) 的平方成正比。电压的增加指数级地增加了手机的功耗。所以我们经常说「手机功耗的大头就是带宽」。
不要在 Shader 中使用分支
这是一个经典的迷思:「不要在 Shader 中使用分支,使用了之后相当于 Shader 需要在分支两边各执行一遍」。
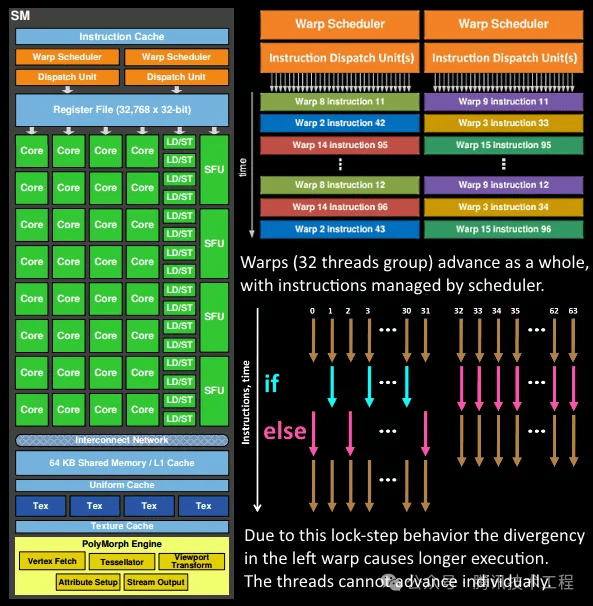
这个说法是基于 GPU SP 并行执行的原理。SP 在执行时,是使用 lockstep 的方式执行同一个 wave (或者 warp) 中的所有 fiber (或者 thread)的。也就是说,使用 SIMD 的指令,在一个 cycle 内同时执行所有的 fiber 相同指令。每一个 fiber 都是同时往前步进的。SP 有个 Mask 的功能,可以在执行时屏蔽某些 fiber。这个功能就是用来处理分支的。当遇到分支时,先 mask 掉应该走 false 的 fiber,执行 true 的分支;再 mask 掉应该走 true 的 fiber,执行 false 的分支。这也就是前面说到的,需要 shader 在分支两边各执行一遍。
这个功能称为 "Divergency",不止用在了处理逻辑分支,还用于处理很多其他功能。比如后面会说到的 quad overdraw。
但是,分支条件分为几种情况:
常量条件:这种在编译时就会被优化掉,是不会产生分支的。
Uniform 作为条件:如果同个 wave 中的所有 fiber 都是走同一个条件分支,理应也是不会产生分支的。
运行时的变量决定:这种产生对于性能的影响是最大的
常量条件:这种在编译时就会被优化掉,是不会产生分支的。
Uniform 作为条件:如果同个 wave 中的所有 fiber 都是走同一个条件分支,理应也是不会产生分支的。
运行时的变量决定:这种产生对于性能的影响是最大的
第二点是容易被忽略的
另外,不同的 GPU 架构对于 divergency 的性能敏感程度是不同的。从原理上我们可以猜到,每个 wave 中的 fiber 数量越多,divergency 的代价就越大。Adreno 中每个 wave 中 fiber 数量较多,因此收 Divergency 影响会更大。
在 Snapdragon Profiler 中,通过这两个指标来观察 Divergency 的情况:% Shader ALU Capacity Utilized 、 % Time ALUs Working。
下面是这俩指标的含义:
% Shader ALU Capacity Utilized:重要指标。当存在 Divergence 时,此 Metrics 会小于 "% Time ALUs Working". 比如 % Time ALUs Working" 为 50%, "% Shader ALU Capacity Utilized" 为 25%,那么意味着一半的 fibers 不工作 (masked due to divergence, or triangle coverage)。
% Time ALUs Working. SP busy 的 Cycles 里,多少比例的 Cycle ALU Engine is Working。一个 Wave 即使只有一个 fiber active,这个 Metrics 也加一。这点与 Fragment ALU Instructions Full/Half 不同。
% Shader ALU Capacity Utilized:重要指标。当存在 Divergence 时,此 Metrics 会小于 "% Time ALUs Working". 比如 % Time ALUs Working" 为 50%, "% Shader ALU Capacity Utilized" 为 25%,那么意味着一半的 fibers 不工作 (masked due to divergence, or triangle coverage)。
% Time ALUs Working. SP busy 的 Cycles 里,多少比例的 Cycle ALU Engine is Working。一个 Wave 即使只有一个 fiber active,这个 Metrics 也加一。这点与 Fragment ALU Instructions Full/Half 不同。
也就是说,Divergence 的比例 = % Time ALUs Working - % Shader ALU Capacity Utilized
移动端不需要太关注 Overdraw
"Overdraw" 字面意思就是「画多了」,做多了不必要的工作。通常我们说的 overdraw 是指多个三角形重叠,先画远处再画近处,远的像素就会被抛弃掉,那么远的像素这部分的 PS 就被浪费了。
在目前的 TBDR 架构中,在 binning 阶段之后,由于通过 vs 有了深度信息,可以利用这个深度信息来剔除远处的三角形(或像素)的绘制,减少后面 ps 的 overdraw。这个机制,Adreno GPU 称为 LRZ (Low Resolution Depth),PowerVR GPU 称为 HSR (Hidden Surface Removal),Mali 称为 FPK (Forward Pixel Killing)。因此,在这个层面上,这个迷思是正确的。
但是有另外一种 overdraw 原理完全不同,称为 "Quad Overdraw"。SP 在做 PS 绘制时,并不是以 pixel 为单位,而是以 quad 为单位的,每个 quad 是 4 个像素。如下图
一个 quad 中画多了的那些 pixel,就是 quad overdraw。一个三角形的面积越大,quad overdraw 的比例就会越小。极端情况下,如果三角形只占据了 1 pixel,那么就会有 3 pixel 的绘制是浪费的,75% 的 quad overdraw。
Quad overdraw 在 GPU 的实现逻辑,就是 Divergency。因此,在 Adreno 这种对于 divergency 更敏感的架构中,这个问题会变得更严重。Adreno 架构一个 wave 最多只能处理 4 个三角形,但却有 128 个 fiber。极端情况下,每个三角形只占据 1 个像素,那么 128 fiber 只画了 4 个有效像素,浪费了 96.9% 的算力。
因此,我们需要尽量减少微小的三角形的出现,最直接的办法就是使用合适的 LOD。这不仅会让绘制的三角数量更少,减少带宽使用,还会让绘制效率更高。Arm 对此的建议是,建议每个三角形至少覆盖 10-20 个 fragment。
- Use models that create at least 10-20 fragments per primitive.
- Use models that create at least 10-20 fragments per primitive.
验证 Quad Overdraw,一样还是用 % Shader ALU Capacity Utilized、% Time ALUs Working 这俩指标。Divergency 比例 = % Time ALUs Working - % Shader ALU Capacity Utilized
为了排除 shader 分支造成的 divergency 的干扰,可以将 shader 都替换为没有任何分支的简单 shader。
Shader 复杂度
当我们在说「shader 复杂度」的时候,我们是在说:
Shader 静态指令数
Shader 动态指令数
Shader 使用的寄存器数量
Shader 静态指令数
Shader 动态指令数
Shader 使用的寄存器数量
分别讨论一下这几个指标过多过大之后的问题
指令数量
「指令数量」分为:静态指令数(static instruction count)和动态指令数(dynamic instruction count)。静态指令数是指编译后的 shader 程序里的指令数量;动态指令数则是被执行的指令数量。比如,使用 [unroll] 展开 for 循环,那么编译出来的程序的静态指令数就会比没有展开的多。但无论是否展开,运行两个程序的动态指令数应该是一样的。
Offline compiler 统计出来的都是静态指令数,但是可能会也会统计出的最短执行路径的动态指令数。
当静态指令数量过多时,cache 就会装不下。Snapdragon Profiler 中有对应的指标:
% Instruction Cache Miss: 不要让 Shader (编译后机器)指令超过 2000 条(VS+PS),用 SDP 的 Offline Compiler 可以看到指令数
% Instruction Cache Miss: 不要让 Shader (编译后机器)指令超过 2000 条(VS+PS),用 SDP 的 Offline Compiler 可以看到指令数
Shader Processor (SP) 中使用寄存器来保存 shader 的上下文。如果 shader 的寄存器使用过多,当需要通过切换执行的 shader 来 hide latency 时,寄存器数量不足而无法切换,进而导致执行效率下降。
什么是 "Hide Latency" 呢?就是当 SP 当前执行的 shader 发生 long latency 时(比如贴图采样),为了提高利用率,SP 会切换到另一个 shader 来执行而不是干等。这就称为 "Hide Latency"。是否可以切换成功的条件是,寄存器在保留原 shader 上下文的基础上,是否足以可以容纳新 shader 的上下文。如果某个 shader 需要多寄存器较多,当前的寄存器已经放不下了,就会导致切换失败。
贴图采样、Storage Buffer 访问都会造成 latency,寄存器使用的数量会影响 hide latency 的效率。因此,我们要避免同时贴图采样数量多而又计算过程复杂(寄存器使用数量多)的 shader。
当占用寄存器数量继续增大,大于 on-chip memory 的尺寸时,会出现 "Register Spilling"。也就是寄存器存不下来,只能放到 system memory 里了,那么性能就会出现断崖式下降。
寄存器数量是移动端 GPU 和桌面端一个大的差异点。骁龙888 是 64KB 每 64 ALU,而 nVidia/AMD 是 256KB 每 64 ALU。这直接决定了两端 shader 的复杂程度。桌面端的 shader 拿到移动端来跑,性能的下降并不是和指令数量不是成线性关系,而会因为寄存器容量不足,导致 shader 无法充分地切换、甚至出现 spilling 而执行效率非常低下。
使用 Offline Compiler 中的: register footprint per shader instance 来看 shader 寄存器的使用数量。
在 Snapdragon Profiler 中可以通过 % Shader Stalled 来判断 shader 的执行效率。当 SP 无法切换到其他 shader 去执行时,就会出现 stall。
% Shader Stalled: 指没有任何 execution units (主要是指 alu, texture & load/store) 在工作的 cycles 占总 Cycle 数的比例。Memory fetch stalled 不一定意味着 Shader Stalled,因为如果 shader 还能找个某个 wave 执行 ALU,那么不算 stall。% Shader Stalled 意味着 IPC (instruction per cycle) 下降。
% Shader Stalled: 指没有任何 execution units (主要是指 alu, texture & load/store) 在工作的 cycles 占总 Cycle 数的比例。Memory fetch stalled 不一定意味着 Shader Stalled,因为如果 shader 还能找个某个 wave 执行 ALU,那么不算 stall。% Shader Stalled 意味着 IPC (instruction per cycle) 下降。
移动端 Vertex Shader 是性能敏感的
移动端,vertex shader 性能敏感有几层原因:
首先,在 TBR 架构中,跨 tile 的三角形在每个 tile 中都会被执行。如果开启了 MSAA,那么 tile size 就会变小,那么跨 tile 的三角形数量就会变多,vs 压力会变得更大。
其次,就是前面架构部分说到的,在 Adreno/Mali 架构中,VS 都会被执行 2 次。在 iOS 中只在 binning pass 阶段执行一次 VS,render pass 只执行 PS。
Adreno/Mali 在 binning pass 中,并不是执行全量的 VS,而是只执行与 position 相关的指令。一般里说,position 的计算只需要做座标系转换。但如果涉及复杂计算或者贴图采样,那么这部分开销就被放大。比如,在地形绘制时通过采样高度图来计算顶点位置。
第三,Vertex Output 也会影响管线执行效率。这是跟硬件实现相关的。
在 Adreno 架构中,vertex output 是不需要 resolve 到 SYSMEM 的。每个 SP 中的 Local Buffer 里有一小块区域是用来存 vs output 的,可以在 ps 阶段使用。但是这部分的区域是有限的,在 8Gen2 中只有 8KB。如果 SP 中这块区域满了,就会出现 vs stall。如果一个 vs output 是 12 个 float4 attribute,那么 8KB 可以装 64 个 fragment。
在 Mali 的第五代 GPU 架构 Immortalis 之前,在 render pass 中执行的 vs 产生的 vs output 是会 resolve 到 SYSMEM,在 ps 中再 load 回来。这样就产生了带宽开销。第五代 GPU 架构引入了 Deferred vertex shading (DVS) pipeline,可以省去 vs output resolve/unresolve 的过程,对带宽有较大的改善。官方的说法是 20% - 40% 的带宽。但可以想象,这部分肯定也是有存储上限的。
总结来说,就是
启用 MSAA 会加重 VS 的压力
VS 中 position 计算部分不要用过重的逻辑,尤其不要使用 data fetch、贴图采样。
要控制 VS Output 的数据量,数据量过大,可能会造成 vs stall;对于 mali 旧机型、iOS,会增加带宽使用。
启用 MSAA 会加重 VS 的压力
VS 中 position 计算部分不要用过重的逻辑,尤其不要使用 data fetch、贴图采样。
要控制 VS Output 的数据量,数据量过大,可能会造成 vs stall;对于 mali 旧机型、iOS,会增加带宽使用。
是否要做 PrePass
这个问题会比较复杂。
我们重新看看前面 Adreno 的架构图:在 Binning pass 阶段会做 LRZ (Low Resolution Z,也就是低分辨率的深度图) 剔除。接着在 Rendering pass 阶段会做 early-z 和 late-z。LRZ Test 是做低分辨率、primitive 颗粒度的深度剔除;Early-Z、Late-Z 是做全分辨率、quad 颗粒度的深度剔除。
对于 Opaque 物体,在 LRZ/Early-Z 阶段,会去做不同颗粒度的 Test & Write;在 Late-Z 就无需再做测试了。
对于 Translucent (Alpha Blend) 物体,不可以 Write。但是因为有可能会被更近的深度剔除掉,所以可以 Test。
对于 Mask (Alpha Test) 物体,深度其实在 VS 阶段就可以确定了,但是因为可能在 ps 阶段被 discard 掉,所以在 LRZ、Early-Z 阶段都只能 Test 不能 Write,需要到 Late-Z 才能 Write。
对于 Custom Depth (oDepth) 的物体,只会在 Late-Z 写深度,且不会被深度剔除。oDepth 是 pixel shader output depth register,专门指 ps 阶段写深度的寄存器。
| LRZ | Early-Z | Late-Z | |
|---|---|---|---|
| Opaque | Test & Write | Test & Write | Off |
| Translucent (Alpha Blend) | Test | Test | Off |
| Masked (Alpha Test) | Test | Test | Write |
| Custom Depth (oDepth) | Off | Off | Write |
有了上面的梳理,我们再来看看这个迷思。
PrePass,在桌面端的传统做法,是针对 Opaque 先跑一遍 PositionOnly 的较为简单的 Shader,生成深度图给后面的 BasePass 使用。以达到减少 overdraw 的目的。但是对于移动端来说,由于 binning pass 的 LRZ 已经做了类似的事情,因此移动端的 Opaque 物体是没必要做这个事情的。
对于「移动端是否要做 PrePass」的讨论,一般主要集中在 Mask 物体。Mask 物体无法在 LRZ/Early-Z 阶段写深度,那么对于大面积的 Mask 物体就会造成 overdraw。如果大量的 mask 物体穿插在一起(比如植被),开销就跟画一堆透明物体一样。
并且对于不同的架构,Mask 的冲击是不一样的。
对于 PowerVR 的架构下,"Overdraw Reducing" 是使用了 HSR (Hidden Surface Removal)。这是一个 Fragment 颗粒度的可见性剔除,在 binning pass 阶段会输出一张全分辨率的 visibility map,在 render pass 中只需要执行 ps 而无需再执行 vs。因此可以无视 drawcall 提交顺序。
With PowerVR TBDR, Hidden Surface Removal (HSR) will completely remove overdraw regardless of draw call submission order.
With PowerVR TBDR, Hidden Surface Removal (HSR) will completely remove overdraw regardless of draw call submission order.
但如果遇到 alpha test,那就很难受了。需要等到 ps 执行完得到真实深度了,再 feedback 到 HSR。这个 feedback 是否会 stall 后面的 drawcall 呢?资料中没有明确地提及。由于需要根据 HSR 产生的 visibility map 去做 render pass,所以可以猜测就算不会 stall 后面的 drawcall,也会 stall 整个 HSR。
对于 Adreno/Mali 架构,虽然 Mask 不会造成管线 stall,但是混杂了 Opaque 和 Mask 的渲染 pass,对管线的执行效率也是有影响。因此也是建议将 Opaque/Mask 作为两个 pass 来渲染。
默认的处理方案,是将 Opaque 和 Mask 分成两个 pass 来渲染,避免 Mask 对渲染管线的阻塞。
在默认方案之上,可以考虑针使用专门的简化的 vs/ps 对 Mask 物体先做一遍 PrePass,然后在 BasePass 阶段 Mask 物体就无需标记为 Alpha Test 了,只需要将 Depth Test 设成 Equal。因为 Mask 物体需要执行 ps 才能得到深度,因此需要一个简化到只做采样 alpha 的专门 ps。
总结来说,Mask 的 PrePass 的意义在于用一批简单的 drawcall 来换取 BasePass 的管线执行效率、减少 overdraw。
PowerVR 架构下,不会让 alpha test 的 late-z 成为 HSR 的瓶颈;Adreno/Mali 架构下,不存在 stall pass 的问题,PrePass 更大的意义在于可以参与去剔除 BasePass 中的物体,无论是 Opaque/Translucent/Masked。
但这批「简单的 drawcall」当然也有开销,PrePass 是否一个正优化,需要根据场景类型、机型来做 perf tuning。
运行 CS 可以更高效地利用 GPU
现在都 Shader Processor (SP) 都是 unified design,一个 SP 可以执行 VS/PS/CS,不会有专门用于跑 CS 的 SP。因此单独地跑 raster pipeline 并不会造成硬件利用率不高。并且在 SP 工作在 VS/PS 下,和工作在 CS 下是两种不同「工作模式」。切换成本根据硬件而有所不同。
如果在 VS/PS 和 CS 可以「同时」跑在同一个 SP 上,这个功能称为 Async Compute。这个「同时」是打引号的,是指 SP 上可以有 graphics wave 和 compute wave 互相切换,用来 hide latency。在这个层面上讲,确实是可以更高效地利用 GPU。
但是对于结对同时运行的 graphics 和 compute 最好在资源使用上最好是匹配互补的。比如,好的匹配:
Graphics: Shadow Rendering (Geometry limited)
Compute: Light Culling (ALU Heavy)
Graphics: Shadow Rendering (Geometry limited)
Compute: Light Culling (ALU Heavy)
坏的匹配:
Graphics: G-Buffer (Bandwidth limited)
Compute: SSAO (Bandwidth limited)
Graphics: G-Buffer (Bandwidth limited)
Compute: SSAO (Bandwidth limited)
目前 iOS 是移动端支持 Async Compute 支持最好的。Mali 也是支持的,但更多的细节需要测试。但 Adreno 到目前为止还是不支持的。
GPU Driven 在移动端的技术限制
GPU Driven 是在桌面端一种非常细颗粒度的三角面剔除 + 合批方案,但是在移动端鲜有应用。虽然其目的是「GPU 性能换取 CPU 性能」,但在移动端对于 GPU 的性能冲击跟 CPU 的性能优化是不匹配的。
究其原因,主要有两个:
低效的 Storage Buffer 随机访问
大量的 small drawcall,以及 instanceCount=0 的 invalid drawcall
低效的 Storage Buffer 随机访问
大量的 small drawcall,以及 instanceCount=0 的 invalid drawcall
GPU Driven 中,"PerInstance" 的 vertex stream 里存放的是指向各个 storage buffer 的 index。这些 storage buffer 存的是 Instance Transform、Material Data、Primitive Data 等信息。在 VS 中通过 index 索引这些 storage buffer 获取有效数据。原先这些数据都是通过 instance buffer (vertx stream) 或者 uniform buffer 来获取的,在 on-chip memory 上就可以很快的获取到。改为 storage buffer 之后,这些 buffer 一般都比较大,on-chip memory 和 L1/L2 都是存不住的,大概率都要到 SYSMEM 去拿数据,因此效率很低。
尤其是 instance transform,是会参与 vs 的 position 计算的。在移动端就会导致这部分计算要跑两遍。
地道的 GPU Driven 会做 cluster 级别的剔除,一个 cluster 可能是 64/128 个三角形。每个 cluster 作为一个 indirect drawcall 的 sub-drawcall 来绘制。如果这个 cluster 被剔除,那么这个 sub-drawcall 的 instance count 就会被写为 0。这种处理方式,一方面产生非常多的 small drawcall,另一方面产生了很多的 instanceCount=0 的 invalid drawcall
GPU 有专门的用来生成 wave 的组件,Adreno 的叫 HLSQ (High Level Sequencer),Mali 的叫 Warp Manager。这些组件会预读取若干个 drawcall 来生成 wave,以便可以互相切换。但移动端这块能预读取的数量是比较有限的,比如 Adreno 8Gen1 的 HLSQ 就只能预读取 4 个 drawcall。如果这些是 small drawcall 或者 invalid drawcall,那就导致喂不饱后端的管线。
最后
破除迷思的办法,就是摒弃神秘主义,知其然知其所以然。希望这些可以为我们后面的优化带来更清晰的思路和方法,而不是盲人摸象。
贯彻费曼学习法,这也算是我自己个人在这方面所了解的东西的一个总结。
但作为应用层,终究只能在厂商构筑的黑盒之外摸索和猜测。所以难免会有很多不正确、不详尽、过时的东西。望见谅。
Reference
AI and Memory Wall
Arm GPU Best Practices Developer Guide | Triangle density
Arm GPUs built on new 5th Generation GPU architecture to redefine visual computing
A close look at the Arm Immortalis-G720 and its 5th Gen graphics
Arm Community (2013)Killing Pixels - A New Optimization for Shading on ARM Mali GPUs.community.arm.com/ar...
Arm Community (2019)Immersive experiences with mainstream Arm Mali-G57 GPU.community.arm.com/ar...
Arm Developer Documentation (no date a)Arm Mali Offline Compiler User Guide.developer.arm.com/do...
Arm Developer Documentation (no date b)Arm Mali Offline Compiler User Guide - Mali GPU pipelines.developer.arm.com/do...
ARM Tech Forum (2016)Bifrost - The GPU architecture for next five billion.docplayer.net/907458...(Accessed: October 26, 2023).
Beets, K. (2013)Understanding PowerVR Series5XT: PowerVR, TBDR and architecture efficiency - Imagination.blog.imaginationtech...
Davies, J. (no date)The Bifrost GPU architecture and the ARM Mali-G71 GPU.community.arm.com/cf...
Frumusanu, A. (2019)Arm’s new Mali-G77 & Valhall GPU architecture: a major leap.www.anandtech.com/sh...
GPU Framebuffer Memory: Understanding Tiling | Samsung Developers(no date).developer.samsung.co...
Hidden surface removal efficiency(no date).docs.imgtec.com/star...(Accessed: October 7, 2023).
Improved culling for tiled and clustered rendering in Call of Duty: Infinite Warfare(2017).research.activision....
Life of a triangle - NVIDIA’s logical pipeline(2021).developer.nvidia.com...
Mei, X., Wang, Q. and Chu, X. (2017) 'A survey and measurement study of GPU DVFS on energy conservation,'Digital Communications and Networks, 3(2), pp. 89–100.doi.org/10.1016/j.dc...
PowerVR Developer Community Forums (2015)Alpha Test VS Alpha Blend.forums.imgtec.com/t/...
Qualcomm® AdrenoTM GPU Overview(2021).developer.qualcomm.c...(Accessed: October 7, 2023).
Qualcomm® SnapdragonTM Mobile Platform OpenCL General Programming and Optimization(2023).developer.qualcomm.c...(Accessed: September 16, 2023).
Understanding and resolving Graphics Memory Loads(2021).developer.qualcomm.c...(Accessed: October 7, 2023).
Wu, O. (no date)Mali GPU Architecture and Mobile Studio.admin.jlb.kr/upload/...
移动GPU架构 | wingstone’s blog(2020).wingstone.github.io/...
END
欢迎加入Imagination GPU与人工智能交流2群
入群请加小编微信:eetrend77
(添加请备注公司名和职称)
对话Imagination中国区董事长:以GPU为支点加强软硬件协同,助力数
Imagination CPU系列研讨会 | RISC-V 安全和Global Platform TEE
Imagination Technologies 是一家总部位于英国的公司,致力于研发芯片和软件知识产权(IP),基于Imagination IP的产品已在全球数十亿人的电话、汽车、家庭和工作 场所中使用。获取更多物联网、智能穿戴、通信、汽车电子、图形图像开发等前沿技术信息,欢迎关注 Imagination Tech!