目录
内存(Memory)基础
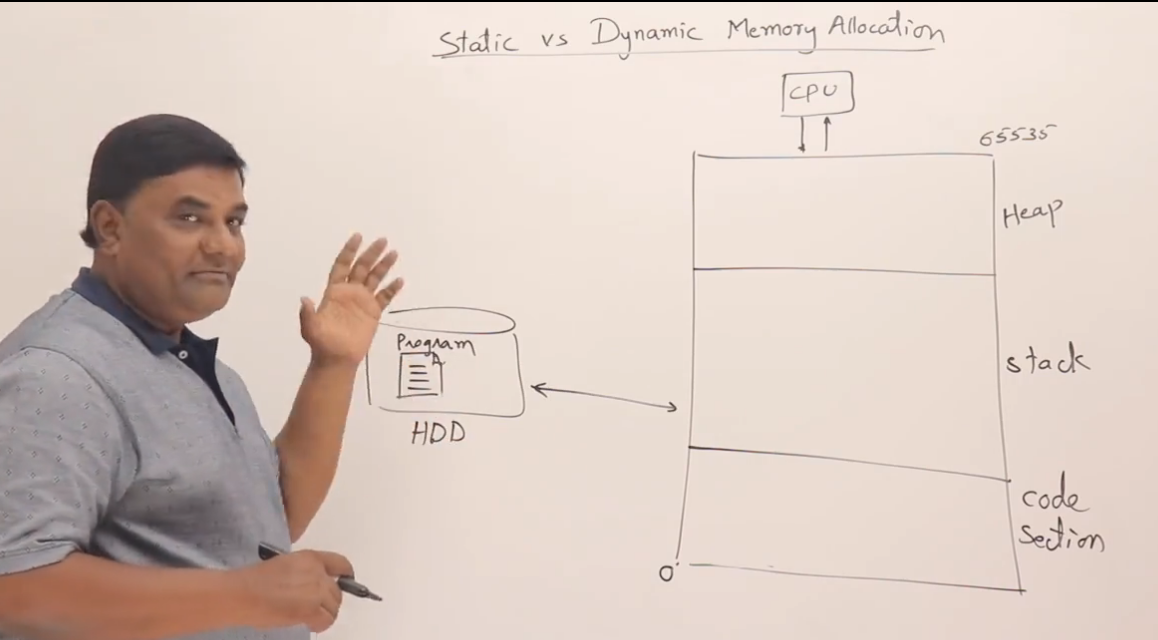
程序是如何利用主存的?
🎯 静态内存分配 vs 动态内存分配
栈(stack)
程序执行过程与栈帧变化
堆(Heap)
程序运行时的主存布局
内存(Memory)基础
计算机运行程序时,需要在某个地方存储数据和指令,这个地方就是内存,也叫主存或 RAM(随机存取存储器)。
内存被划分为一个个小的单位,每个单位称为字节(byte)。
-
1字节 = 8位(bit),每个位可以是0或1。
-
每个字节都有一个唯一的地址,CPU通过这些地址来访问内存中的数据。
-
内存的地址通常从0开始,依次递增。例如,主存64KB的内存,地址范围是0到65,535(因为64KB = 64 × 1024 = 65,536字节)。
你可以把内存想象成一个超大的格子仓库,每个格子能存放一个数据单位(字节),而程序运行时会不断地从这个仓库取数据、放数据。
程序是如何利用主存的?
当一个程序被加载进内存运行时,主存会被划分成几个不同的区域来完成不同的任务,常见的有三部分:
+-------------------+ ← 低地址(地址编号小)
| 代码区(Text) | ← 存储编译后的程序指令
+-------------------+
| 栈区(Stack) | ← 自动变量、函数调用相关的数据
| |
| ↓ 向下增长 |
+-------------------+
| |
| ↑ 向上增长 |
| 堆区(Heap) | ← 动态分配的内存(malloc/new)
+-------------------+ ← 高地址(地址编号大)
| 区域 | 作用 |
|---|---|
| 代码区 | 存放程序编译后的“机器指令”,CPU会按顺序执行这些代码。 |
| 栈区 | 存储局部变量,如函数里的变量,随着函数调用和退出自动分配和释放。 |
| 堆区 | 程序运行时用来“手动”申请的内存区域,由程序员自己管理(使用 new 或 malloc 等)。 |
我们来写一段简单的代码:
#include <iostream>
using namespace std;int main() {int a = 10; // 栈上的 int 变量float* p = new float(3.14f); // 堆上的 float 变量return 0;
}
这段代码里:
🎯1. int a = 10;:
-
a是一个局部变量,在main()函数中声明。 -
它会被分配在 栈区 中。
-
如果
int占 4 字节,比如从地址0x1000开始,则a占用地址0x1000 ~ 0x1003。
🎯2. new float(3.14f):
-
这是通过
new申请的内存,分配在 堆区。 -
它返回一个指针
p,指向堆上某块内存(比如地址0x5000),那里存着3.14。 -
p本身是一个局部变量(指针变量),也放在 栈区,但它指向的内容在 堆区。
🔍 内存示意图
地址 内容 所属区域
0x1000 10 a(int 类型,栈上)
0x1004 0x5000 p(指向堆内 float 的地址,栈上)
...
0x5000 3.14 堆上 float
🎯 静态内存分配 vs 动态内存分配
在 C/C++ 中,int 类型的大小不是写死的,而是取决于以下几个因素:
| 决定因素 | 说明 |
|---|---|
| 平台架构 | 32 位系统中通常是 4 字节(32 位);64 位系统也通常是 4 字节(但不一定)。 |
| 编译器的实现 | 不同编译器(如 gcc、MSVC)可能会有不同的默认设置。 |
| 数据模型(如 LP64) | C/C++ 标准没有规定 int 的精确大小,只规定了大小关系(比如 int ≥ short)。 |
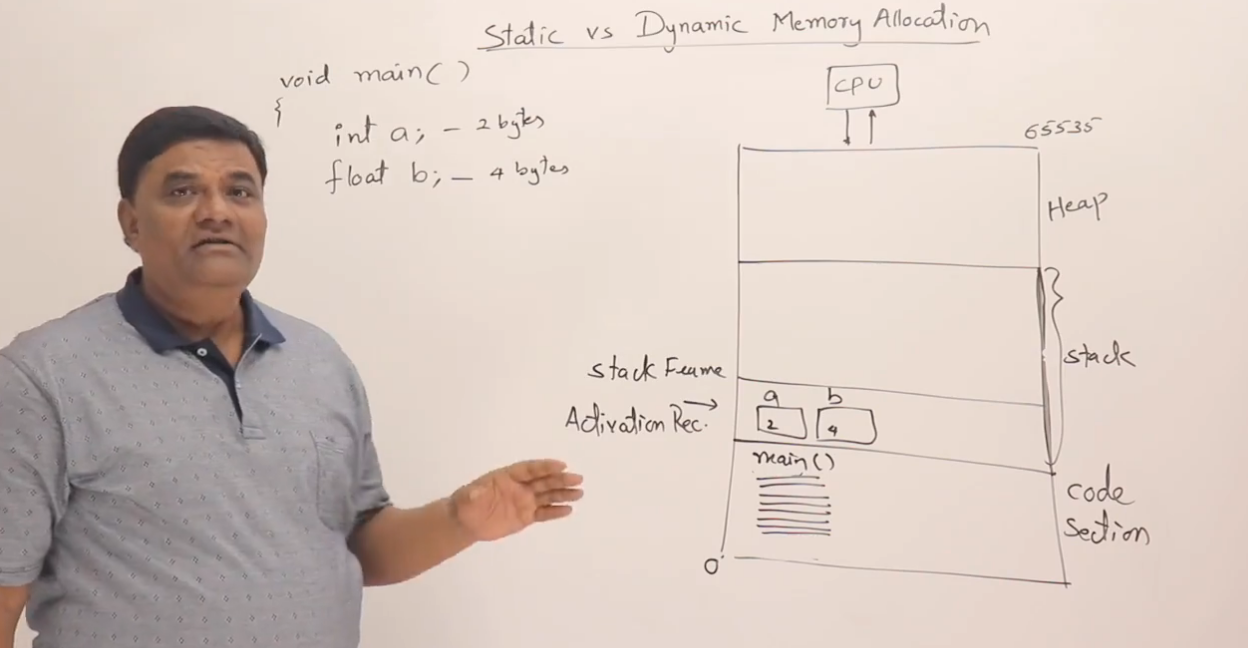
静态内存分配(Static Memory Allocation)
定义:在编译时确定变量的大小和存储位置,程序运行时自动分配和释放。通常发生在栈区或全局/静态区。
示例:int a = 10;
-
变量
a是局部变量,分配在栈上。 -
编译器知道它的类型(int),所以知道它需要 4 个字节。
-
编译时就决定:
a需要多大、存哪里、何时释放。
动态内存分配(Dynamic Memory Allocation)
定义:程序运行时,向堆区申请内存。程序员需要自己手动释放。
示例:float* p = new float(3.14f);
-
new float(3.14f)会在堆上开辟 4 字节(float 大小)的空间。 -
返回一个地址(比如
0x5000)给p,p是一个放在栈上的指针变量。 -
你必须
delete p;否则会造成内存泄漏。
栈(stack)
栈是一块在主存中专门用于管理函数调用和局部变量的区域。
它遵循的是一种 “先进后出(FILO)” 的数据结构。
在程序运行时,每次函数调用都会创建一个“栈帧(stack frame)”,这个栈帧保存:
-
函数的参数(如
int i) -
函数内部定义的局部变量(如
int a、float b) -
返回地址(调用完了返回哪)
函数退出后,对应的栈帧就会被销毁,空间自动回收。
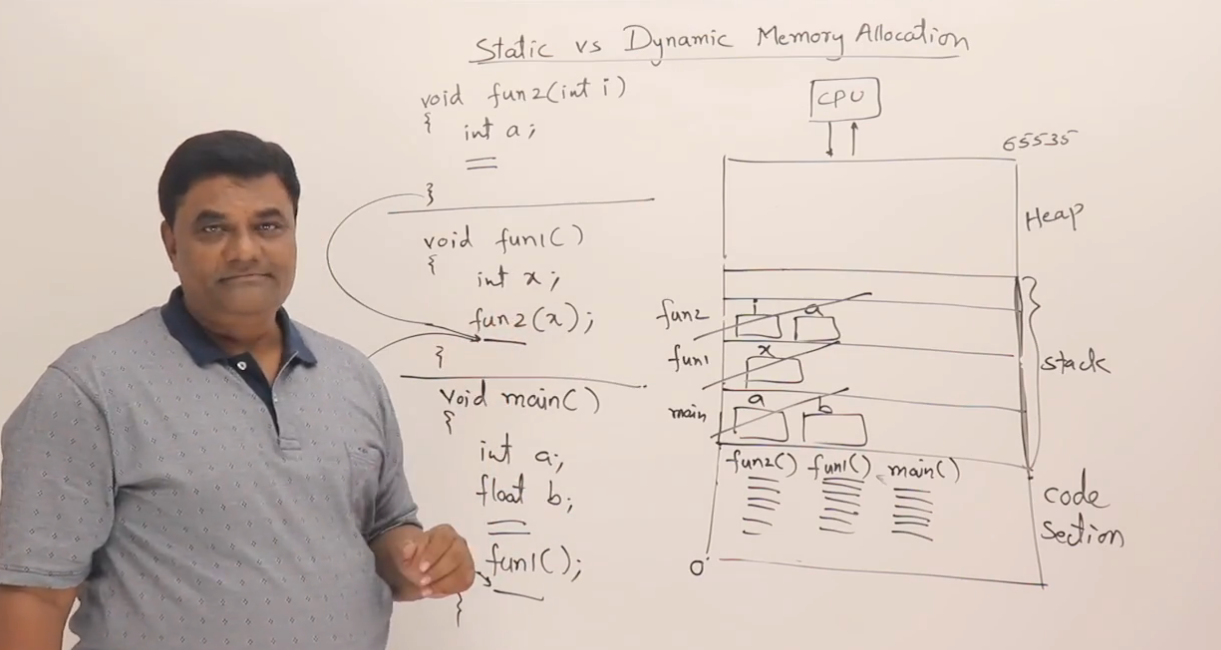
void fun2(int i)
{int a;
}
void fun1()
{int x;fun2(x);
}
int main()
{int a;float b;fun1();
}
程序执行过程与栈帧变化
假设系统中:
-
int和float都是 4 字节 -
栈从高地址向低地址生长(这是几乎所有平台上的标准)
✅ 步骤 1:程序启动
程序开始执行 main(),栈上创建 main 的栈帧:
main 栈帧:
-----------------------
| float b (4 字节) |
| int a (4 字节) |
-----------------------
✅ 步骤 2:main 调用 fun1()
此时压栈一个新的 fun1 栈帧:
fun1 栈帧:
-----------------------
| int x (4 字节) |
-----------------------
✅ 步骤 3:fun1 调用 fun2()
假设 fun2 中传入的参数是某个整数(比如默认是 0),再压一个 fun2 的栈帧:
fun2 栈帧:
-----------------------
| int a (4 字节) |
| int i (4 字节) | ← 这是参数 i
-----------------------
此时,整个栈结构如下(高地址在上):
地址 内容(栈帧) 所属函数
0x7ff0 int i ← fun2 参数
0x7fec int a ← fun2 局部变量
-------------------------------------
0x7fe8 int x ← fun1 局部变量
-------------------------------------
0x7fe4 float b ← main 局部变量
0x7fe0 int a ← main 局部变量
函数返回后的栈变化
-
当
fun2()执行完毕,它的栈帧会被销毁(i和a消失) -
接着
fun1()返回,它的x被销毁 -
最后
main()结束,整个栈清空,程序结束
栈的特点总结
| 特点 | 描述 |
|---|---|
| 自动管理 | 函数调用时创建,返回时销毁 |
| 生命周期短 | 局部变量只在函数内部有效 |
| 空间小但访问快 | 通常 1~8MB,访问速度快于堆 |
| 按顺序进出(先进后出) | 后调用的函数先返回 |
堆(Heap)
在程序运行时,堆(heap)是一块用于动态内存分配的区域,由操作系统统一管理。
-
与栈不同,堆上的内存不会自动释放,程序员必须手动释放(如
delete或free)。 -
在 C++ 中,使用
new/new[]来从堆中申请内存,使用delete/delete[]来释放。
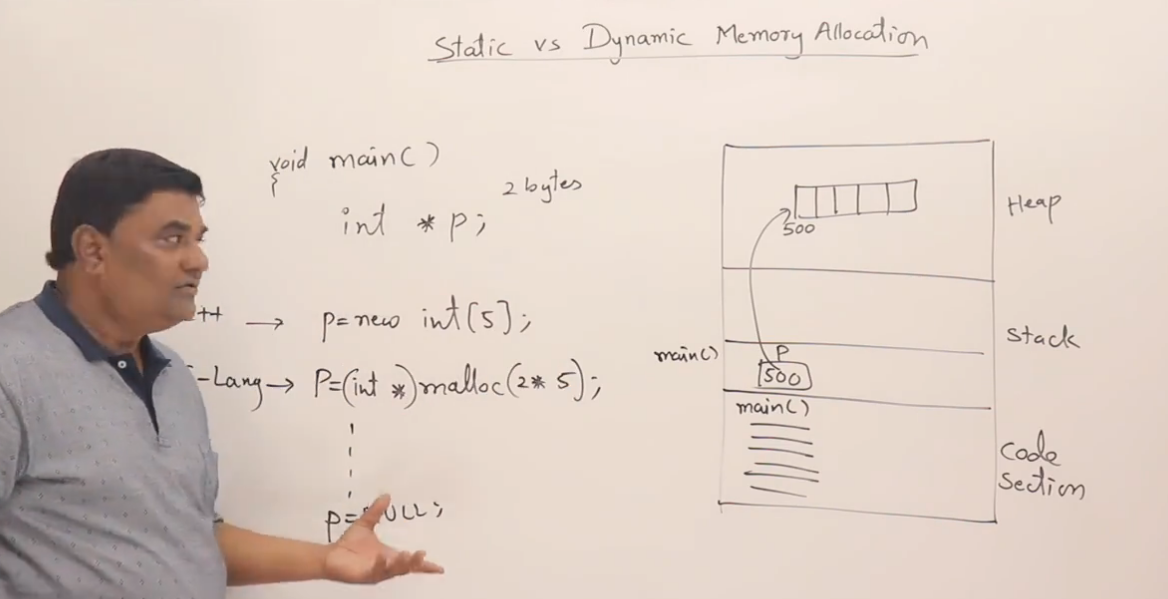

程序运行时的主存布局
int main()
{int* p;p = new int[5]; // 动态申请堆上的数组delete[] p; // 手动释放堆内存
}
栈区:
--------------------------
| p(指针,8字节) | ← 指向堆上数组的首地址
--------------------------堆区:
--------------------------
| int[0] |
| int[1] |
| int[2] |
| int[3] |
| int[4] | ← 共 20 字节
--------------------------
说明:
-
p是一个局部变量,存储在栈上。 -
new int[5]在堆上申请了一个连续的数组。 -
p指向这块堆内内存的起始地址。
💥 如果不 delete[] 会怎样?
如果你忘记 delete[] p;,这块堆内存将不会被释放,就造成了:
-
内存泄漏(Memory Leak):申请的内存没人管了,程序退出前都无法使用或释放。
在长期运行的程序中,反复申请但不释放,会导致内存耗尽、程序崩溃。